自适应学习率梯度下降的优化算法
2022-01-06宋美佳贾鹤鸣林志兴卢仁盛刘庆鑫
宋美佳 ,贾鹤鸣 ,林志兴 ,卢仁盛 ,刘庆鑫
(1.三明学院 网络中心,福建 三明 365004;2.三明学院 信息工程学院,福建 三明 365004;3.海南大学 计算机科学与技术学院,海南 海口 570228)
机器学习本质是求解一个目标函数,并以此目标函数判断未来数据走向,常用的求解目标函数的算法当属梯度下降(gradient descent,GD)[1],因此,提升梯度下降收敛速度、解决梯度下降算法陷入局部最优解问题、减少梯度下降在最小值附近的震荡性,对机器学习[2]、自然语言处理[3]、图像处理[4]等领域都有着有重要的理论意义和实际应用价值。
选择寻优方向和确定学习率是梯度下降优化算法研究的核心。经过近年来的相关研究,国内外已经取得大量研究成果。选择寻优方向方面,目前较流行的有Momentum、Adam、方差缩减等策略。Momentum方法[5],是在梯度下降过程中加入上一次迭代的动量,对方向相同的两次维度进行加强,方向不同的维度进行梯度减弱,以减少震荡的方式获得更快的收敛速度。 NAG(nesterov accelerated Gradient)算法[6]在计算梯度时,在动量基础上,考虑超前点梯度,使参数更新幅度适应未来梯度变化,显著提高了循环神经网络在一些任务上的性能。AdaGrad(adaptive gradient)算法[7]以历史梯度的平方和作为二阶动量,针对不同维度自适应调整学习率,适合处理稀疏数据。张德[8]等人从学习率衰减方式出发,通过设置衰减速率、结合历史梯度和当前梯度共同调整学习率,以解决常用学习率AdaGrad的历史梯度干扰、AdaDec中幂指函数相关性不强的问题。AdaDelta方法[9]是AdaGrad的扩展,仅计算有限时间区间内的梯度累积和,解决AdaGrad学习率单调下降问题。Adam(adaptive moment estimation)[10]算法相当于结合了Momentum和AdaGrad算法,同时引入了一阶动量和二阶动量,以达到更快的收敛速度。此外还有提出方差缩减概念的随机方差消减梯度(stochastic variance reduced gradient,SVRG)算法[11],解决随机梯度下降无法线性收敛的问题,SAG(stochastic average gradient)的策略[12]也与此类似。宋杰等人[13]设计了一种以SVRG为基础的新型变异方差缩减算法BSUG(batch subtraction update gradient),使用小批量样本代替全部样本进行平均梯度计算,同时对平均梯度进行减数更新。XiLin Li等人[14]研究了非凸优化设置下的随机梯度下降(stochastic gradient descent,SGD)[15],设计了适用于凸和非凸问题的预调节器,可在噪声梯度下降信息中很好预估。
上述分析的选择寻优方向算法主要通过引入一阶动量或二阶动量,结合历史梯度进行优化,虽提及“自适应学习率”,但大体方向都是使学习率随迭代次数的增加而递减,这也导致在后期收敛速度变慢,甚至训练提前结束,或在很多情况下陷入局部最优解。
学习率优化与本文的研究方向与思路一致,Duchi等人[16]提出了以单调的形式调整学习率参数的梯度下降法,提高了梯度学习的效率。金海东等人[17]通过梯度的累积平方和,使学习率随着训练过程逐步减小。如同选择寻优方向算法一样,学习率单调递减容易导致后期收敛慢或不收敛;Abraham[18]、禹建丽[19]、雷鸣等人[20]主要根据迭代过程中梯度方向或损失函数的变化来更新学习率。谢涛等人[21]使用加速因子自适应学习率,加速因子随着累加逐渐增大,后期随着迭代次数增加而逐渐变小,设置加速因子上限值,使加速因子不会过大,当参数接近全局最优值时,加速因子将接近零。
上述算法虽考虑梯度方向和损失函数的变化,但在学习率计算上主要结合阶跃函数或需要衡量多个超参数,在学习率自适应上不够灵活。
针对以上问题本文提出了一种新的自适应步长公式,可以根据损失函数的变化使自适应学习率增大或减小,且能根据损失函数的变化程度来调整学习率变化幅度。通过与已有选择寻优方向和学习率优化算法对比,应用在波士顿房价和Mnist手写数字两种数据集上,对比损失函数的收敛速度和训练效果,通过实验可知提出的算法具有前期收敛快、后期精度高的特点,且易与其他选择寻优方向的算法结合,达到更好的训练效果。
1 预备知识
无论梯度下降通过选择寻优还是学习率的方式进行优化,参数的更新服从式(1)。

其中:wt为第t次迭代参数的更新值;λ为学习率;gt为梯度。因此,学习率优化算法通常表示优化λ,而选择寻优算法通常在于优化gt。
1.1 Momentum(动量)算法[5]
式(2)和式(3)展示了动量的计算方法,主要方式是引入上一刻历史动量对当前动量进行修正。

其中:mt表示第t次迭代的累积动量;γ表示历史动量占比(动量因子),一般取值0.9左右。相比于原始的随机梯度下降算法,基于动量的梯度下降算法能够更接近真实的梯度,从而增进了算法的稳定性。
1.2 AdaGrad算法[7]
除了引入动量外,还可以引入梯度的平方来对权重进行优化。AdaGrad的基本思想是通过历史梯度的平方和更新权重,如式(4)和式(5)所示。

其中:ε是一个很小的常数,主要目的是为了避免除数为0;α为学习率,一般取值0.01即可得到很好的效果。从上式可以看出,随着迭代次数不断增加,历史梯度不断累积,学习率随之变小。相比于SGD算法,AdaGrad算法引入了历史梯度数据,减小了过度分量,其数值稳定性相对于SGD算法有了很大的提高。
1.3 RMSProp算法[22]
AdaGrad算法由于引入了历史梯度平方和,随着训练的进行,权重下降会越来越小,为了解决这个问题,RMSProp算法引入了梯度平方的指数移动平均,用于求梯度在一定时长内的平均,具体如式(6)和式(7)所示。

其中:γ的值决定了记忆历史的长度,可以看到γ越大,记忆的历史越长,一般取γ在0.9左右。
1.4 Adam算法[10]
Adam算法是对目标函数执行一阶梯度优化的算法,该算法基于适应性低阶矩估计,并且有很高的计算效率和较低的内存需求,算法整合了动量和速度,并且把它们整合进一个优化框架中。可以看到式(8)和式(9)分别计算了动量和速度的指数移动平均,然后式(10)把动量和速度整合进了优化过程中。

一般来说,β1默认取值为0.9,β2默认取值为0.999,ε默认取值为10-8,Adam算法结合了Ada-Grad算法和RMSProp算法的优点,因其能很快地实现优良的结果,在深度学习领域内十分流行。在实践中,Adam算法性能优异,相对于其他种类的随机优化算法有很大的优势。
1.5 SVRG算法[11]


1.6 线性再励的自适应变步长算法[19]
线性再励自适应变步长算法的基本思想是:如果连续两次迭代梯度方向相反,意味着步长太大导致“走过了”,应减小步长;相反如果连续两次迭代梯度方向相同,意味目前正确下降,但还没有到达极小点,应增加步长。算法公式如式(13)所示。

其中,η(n)为第n次迭代的步长值,λ为常数,范围在0.001到0.003之间,SGN为阶跃函数,服从式(14)。上述算法实际上是利用并记忆了梯度方向的变化信息,即方向相反时对其罚,方向相同时对其奖。
2 自适应学习率优化算法
梯度下降的先决条件是确认优化模型的假设函数和损失函数,以线性回归任务为例,假设θi(i=1,2,…,n)为模型参数,xi(i=1,2,…,n)为样本的 n 个特征,则假设函数表示如式(15)所示。 损失函数计算如式(16)所示。

其中:hθ为模型预测值;yi为样本实际值,通过计算预测值和真实值之间的差距来衡量模型的好坏。梯度下降的任务,如式(17),即在当前所建模型中求得梯度,通过参数减去步长与梯度的乘积来矫正参数,直到找到最优的模型(损失函数最低或在可接受范围)。

其中:θt表示所有参数在t时刻的状态;gt表示梯度;λ表示学习率。
学习率是梯度下降算法中非常重要的一个参数,现存的梯度下降算法中,大都是采取学习率递减或设置固定值的方式进行梯度下降,这存在以下两点问题:1.采用学习率递减方式,模型训练到后期学习率效率低下,若样本过大会增加时间成本。2.设置固定值方式,模型训练不够灵活。
基于以上分析,本文提出l-tanh优化算法,利用函数的非线性特点,结合损失函数变化值,使学习率自适应增大或减小,如式(18)和(19)所示。

其中:λ为学习率;Jt表示t时刻损失函数的值;Jt-Jt+1表示t时刻与下一时刻损失函数的变化值。
梯度下降前期,损失函数下降程度较大,tanh(Jt-Jt+1)值大于0;由于函数的值域为(-1,1),因此学习率不会因为损失函数变化较大而产生过大波动;由于tanh函数调节,学习率会自适应增大,有效提升前期收敛速度,解决固定学习率前期收敛速度慢的问题。后期,随着损失函数值变化接近于0,tanh(Jt-Jt+1)值接近于0,学习率几乎以原步长速度逐渐收敛,避免学习率线性下降带来的后期步长过小、收敛速度慢或不收敛问题。当损失函数值开始由小变大时,意味着梯度下降可能“走过了”,算法增加回退机制,训练会退回到损失函数最小状态,自适应减小学习率,并重新训练,有效减小了梯度下降的震荡情况。
由于公式(18)采用回退机制,虽然有效减少震荡,但是考虑在部分场景中,学习率可能减小到非常小甚至是0的情况,使后期收敛变得慢,甚至陷入局部最优解,因此采用公式(20)的优化方法,即加入超参β,在训练后期,损失函数变化几乎为0,学习率可几乎稳定在某一值,可以认为后期是以固定学习率在进行训练,以达到更好的精度。

3 数值实验
实验基于波士顿房价和Mnist手写数字两种数据集上开展,将本文提出的优化算法与目前国内外已有的Momentum、Adam、AdaGrad、SVRG等经典优化算法进行对比,基于Paddle框架进行编程,涉及的全部算法程序均在64位Windows 10系统上运行。
3.1 实验设置
实验中,随机初始化参数w的初始值,具体实验设置如表1所示。本实验通过对迭代次数和损失函数作为衡量算法性能的标准,损失值越小、收敛越快代表性能越优。
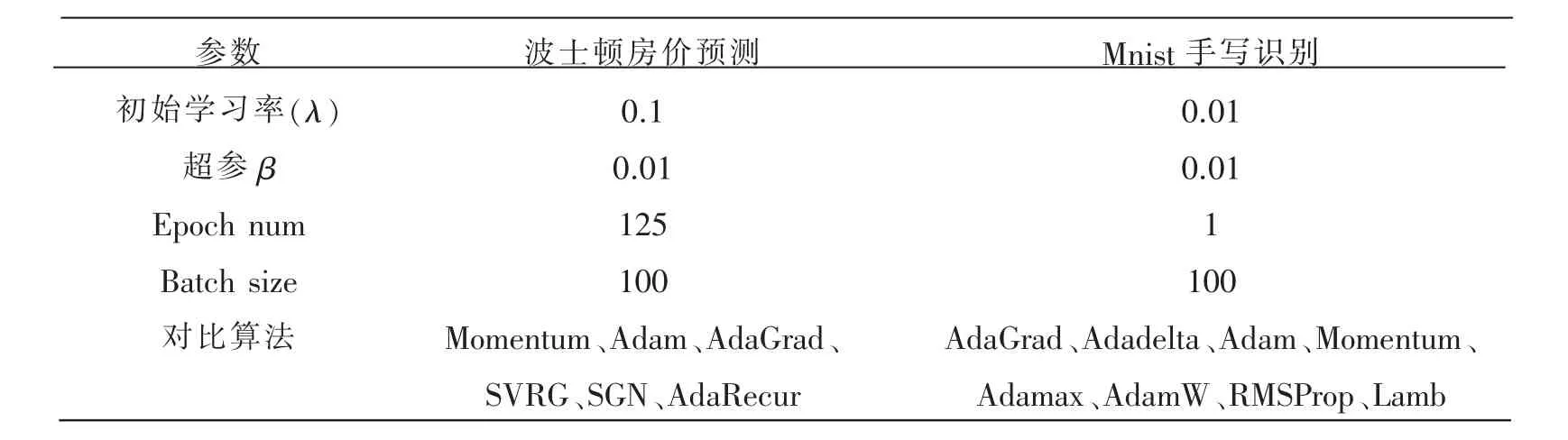
表1 实验参数
3.2 波士顿房价数据集(Boston)
通过对波士顿房价数据集进行测试,比较已有算法与本文提出的优化算法的实际性能,实验选择的数据集来自于paddle机器学习库,该数据集是由人均犯罪率、低收入人群占比等13种可能影响房价的因素和该类型的房屋的均价组成,共506条数据。
将表1中六种算法与本文提出的l-tanh算法进行比较,实验过程包含数据处理、模型设计、训练配置、训练以及保存模型五个步骤构建房价预测的神经网络模型。实验中将特征进行归一化处理,使得模型训练更高效且特征前的权重大小可以代表该变量对预测结果的贡献度。本实验使用均方误差作为评价模型好坏的指标,也称损失函数。为了比较不同初始学习率的效果,实验增加了初始学习率为0.01的实验对比,实验结果如图1所示,纵轴为损失函数值,横轴为epoch迭代次数,每5个epoch循环取一个点。
图1(a)中,初始学习率为0.1时,各个算法相对比较平稳,其中l-tanh算法收敛最快且震荡最小;图1(b)中,初始学习率为0.01时,l-tanh算法收敛结果较好,仅次于AdaRecur算法,但收敛速度和平稳性较AdaRecur算法有非常明显的提升。
从图1可以看出,本文算法l-tanh在相同的迭代次数下虽然未取得最好的精度效果,但是大幅度减小震荡,且可以最快速度稳定在一个相对较小的均方误差阈值内。l-tanh算法震荡性小的原因主要在于每次下降时会判断下一次的损失函数,若损失函数大于本次,则退回到上一步,清除当前梯度,重新寻找更优的方向,通过不断修正梯度的方向,沿最优轨迹下降至最优解,以此提高算法的性能。

图1 波士顿房价预测任务的算法对比
由于l-tanh算法主要优化,可以很容易与其他选择寻优算法结合。为了验证与经典优化算法结合的效果,本文将Momentum、Adam、AdaGrad、SVRG 4个算法的学习率公式改为式(18),形成4种优化算法,分为 Momentum-tanh、Adam-tanh、AdaGrad-tanh、SVRG-tanh。
如图2~5所示,将 Momentum-tanh、Adam-tanh、AdaGrad-tanh、SVRG-tanh依次与原算法比较,发现在加入tanh函数后,收敛效果明显优于原算法。

图2 Momentum-tanh

图3 Adam-tanh

图4 AdaGrad-tanh

图5 SVRG-tanh
3.3 Mnist手写数据集
选取飞浆(paddle)提供封装好的数据集API,通过paddle.vision.datasets.MNIST直接获取处理好的Mnist训练集、测试集。
由于本文主要验证梯度下降的优化效果,所以在波士顿房价预测的深度学习任务中使用了单层且无非线性变换的模型,在手写数字识别任务中,仍然使用该模型进行训练。模型的输入为784维(28×28)数据,输出维度为1维数据。通过调用paddle内置优化器AdaGrad、Adadelta、Adam、Momentum、Adamax、AdamW、RMSProp和Lamb 8种算法与l-tanh对比,实验结果如图6所示。

图6 mnist手写数字识别算法的数据对比
由图6可见,跟波士顿房价预测实验效果相似,l-tanh算法下降速度较快且震荡小,结合表2和表3的损失函数结果来看,l-tanh在所有对比算法中取得了最好的训练效果。

表2 图6(a)的实验结果

表3 图6(b)的实验结果
4 结论
综上所述,针对梯度下降问题,本文提出一种自适应学习率梯度下降算法l-tanh,结合波士顿房价预测任务和Mnist手写数字识别任务开展实验,结果表明l-tanh算法具有前期收敛速度快、后期精度高、且易与其他算法结合的特点。但存在一定的问题,即算法不能适应所有的场景,虽提及两种模式,但算法本身并不能根据训练情况选择适当的模式,需人工加以选择和调整。
本文提出了一种新的自适应学习率梯度下降算法l-tanh,该算法通过判断损失函数变化及变化程度进行更灵活的自适应学习率变化,并通过回退机制保证算法的稳定性,结合超参保证算法训练后期不会陷入局部最优或无法收敛的问题。选取两个数据集Boston和Mnist,将经典算法SVRG、AdaGrad、Adam、Momentum、SGN、AdaRecur、Adadelta、Adamax、AdamW、RMSProp 和 Lamb 与本文的算法进行实验比较分析,验证了本文算法的可行性和高效性。
随着大数据和人工智能技术的发展,大数据智能成为一个高速发展的领域,如何将梯度下降优化算法与大数据技术结合,将本研究架构在分布式框架基础上,是本文下一步的研究方向。
