基于随机森林回归和气象参数的城市空气质量预测模型
——以重庆市为例
2022-01-05徐艳平陈义安
徐艳平, 陈义安
(重庆工商大学 数学与统计学院,重庆 400067)
0 引 言
伴随工业的发展、化石燃料的消费以及城市化进程的不断加快,中国城市空气污染问题日趋严重,给人们的生活生产带来极坏的影响。探索高效率高准确率的城市空气质量预测模型对推进城市空气污染防治意义重大。
目前,城市空气质量的预测模型主要分为三大类:通过总结前人的研究经验结合大气运动等进行预测、基于传统的统计学模型预测和基于机器学习等深度学习算法预测。沈劲等[1]将聚类方法与多元回归方法相结合进行空气质量预测,发现其具有较好的预测准确率;李博群等[2]利用模糊时间序列预测南京市的空气质量指数,并证实了该模型的预测准确率;汤泽梅[3]为构建空气质量预测模型,选取乌鲁木齐地区的空气质量指数为因变量,使用多元线性回归方法分析了相关指标数据;王建书等[4]运用ARIMA模型预测苏州市的空气质量指数并取得了较为理想的预测结果。上述学者均采用基于传统统计学方法构建的城市空气质量预测模型,这些方法在大数据时代背景下,模型容错能力较低、预测准确率相对较差,无法满足对海量数据进行智能化处理的需求。
伴随当下人工智能技术的不断发展,大数据时代已悄然来临,面对海量气象数据,更多学者选择使用机器学习方法构建城市空气质量预测模型。司志娟[5]构建了基于因素分析的灰色神经网络组合模型来预测空气质量;赵李明[6]将遗传算法与BP神经网络相结合,用于研究广州市空气质量预测并取得了较为准确的结果;张楠等[7]改进了灰狼算法并将其与支持向量机相结合,用于进行城市空气质量预测模型的构建;夏润等[8]通过改进XGBoost 算法构建了预测能力与泛化性都比较优异的空气质量预测模型;郑洋洋[9]构建了基于深度学习库Keras的长短期记忆循环神经网络预测模型,并较准确地预测了太原市空气质量指数;徐旭冉[10]运用决策树算法构建了将所有污染参数作为评估空气质量因素的空气质量预测模型。基于机器学习等深度学习算法构建的城市空气质量预测模型有着预测准确率高、数据处理能力强等优点,成为当下空气质量预测模型构建的主要方法。
随机森林算法作为一种取代神经网络等传统机器学习方法的分类回归算法,具有高准确率、不易过度拟合、对噪声及异常值容忍度高等特点。相比于传统的多元线性回归模型,随机森林算法能够克服协变量之间复杂的交互作用,且勿需预先设定函数形式;相比于神经网络,随机森林算法不易过度拟合;相比于支持向量机,随机森林算法规避了支持向量机核函数及内部函数依赖于使用者技巧的问题,因此随机森林算法被广泛应用于各领域研究并取得较好效果。孔丽英等[11]基于企业进销项发票数据,采用随机森林算法构建了税收风险预测模型;Sanjiban Sekhar Roy等[12]分别运用随机森林算法、梯度提升机和深度神经网络进行股票价格进行预测;李刚在研究电力负荷预测时对随机森林的决策树进行了基于遗传算法的改进,从而大幅度降低预测时间消耗;Koutarou Matsumoto[13]〗运用随机森林算法进行了急性缺血性卒中后脑卒中预后评分和临床结果的数据驱动预测;马冉等[14]利用随机森林算法对三峡库区草堂河流域土壤的pH值进行了空间分布预测,结果显示其平均绝对误差低、预测精度高,能够作为预测土壤pH值的有效方法。
基于此,选择区别于传统统计学方法与传统机器学习方法的随机森林算法构建城市空气质量预测模型,并相较于传统模型仅考虑大气污染物浓度,选择时间参数、气象参数及大气污染物浓度为城市空气质量预测模型影响因素,有效提升预测准确率和数据处理效率,为空气污染的防控治理提供更为准确的空气质量信息。
1 随机森林回归算法
随机森林(Random Forest,RF)算法是通过构建多棵决策树形成森林的一种分类与回归算法。它以决策树为基本单元,选取bootstrap重采样方法随机得到多个互不相同的样本子集,采用随机子空间划分的方法依据各样本子集构建决策树。构建决策树时的特征由全部特征随机抽取得到,当决策树进行节点分裂时,选取随机生成的特征子集中的最优特征进行分裂。最后对所有决策树的预测结果采取众数投票或者取平均值,得到随机森林最终的预测结果。简单来讲,随机森林就是由多个弱学习器(决策树)所集成的强学习器。
设随机向量(X,Y)是独立分布的。从(X,Y)中随机生成训练集,输入向量与输出向量分别为X、Y,则预测结果h(X)的均方泛化误差表示为
EX,Y[Y-h(X)]2
随机森林回归的预测结果是k棵决策树的预测结果{h(θ,Xk)}取均值而来的,它满足以下定理:
定理1 当k→∞,
(1)
式(1)右侧部分表示随机森林的泛化误差,将其记为PE**。PE*则表示一棵决策树的平均泛化误差,即
PE*=EθEX,Y[Y-h(X,θ)]2
定理2 对所有随机生成的训练集θ有:
(2)

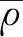
随机森林回归算法的具体步骤可概括为
步骤1:使用bootstrap方法对样本集进行重采样,进而随机生成k个训练集θ1,θ2,…,θk。依据k个训练集进一步生成与之相对用的决策树{T(x,θ1)},{T(x,θ2)},…,{T(x,θk)}。
步骤2:从所有M个特征中随机生成m个特征,并将其作为现下决策树分裂时的特征集。分裂方式则选择这m个特征中的最优分裂方式(通常来说,在随机森林构建过程中,m的值不发生变化)。
步骤3:不对单棵决策树进行剪枝,令其最大程度生长。
步骤4:通过观测叶节点l(x,θ)的值并取平均可以获得面对新数据单棵决策树T(θ)的预测结果。
假定一个不为0且包含于叶节点l(x,θ)的观测值Xi,权重wi(x,θ)表示为
(3)
式(3)中的权重和为1。
步骤5: 单棵决策树的预测值是通过因变量的观测值Yi(i=1,2,…,n)加权平均得到的。单棵决策树的预测值表示为
步骤6:对决策树的权重wi(x,θt)(t=1,2,…,k)取均值用以表示每个观测值Yi∈(1,2,…,n)的权重wi(x):
则随机森林回归算法的预测值表示为
2 变量选取与数据说明
2.1 影响因素确定
(1) 大气污染物浓度。大气污染物浓度是影响城市空气质量的直接因素,也是当前国际社会常用的城市空气质量评价指标,且各国关注的污染物种类和浓度取值时间差异较小[15]。依据国家《环境空气质量标准》(GB 3095-2012),确定了包括PM2.5、PM10、SO2、NO2、O3、CO在内的6项污染物浓度作为城市空气质量影响因素。
(2) 气象参数。人类生活生产会产生污染物进而排入大气中进而影响城市空气质量,然而当污染物的排放量相对平衡的状态下,城市空气质量依然会存在差异,这是由于气象参数的不同导致大气污染物进行沉降、传输、凝聚或者稀释。
选取了平均气温、最高气温、最低气温、平均相对湿度、平均风速、最大风速风向、日照时数、降水量、平均气压这9种气象参数作为城市空气质量影响因素,相关数据均来源于中国天气网历史气象数据。表1为2018-01-01—2020-07-31重庆市空气质量指数(AQI)与9种气象参数的相关系数,结果表明,城市空气质量与9种气象参数存在显著相关关系。

表1 空气质量指数与气象参数的相关关系
(3) 时间参数。同一城市在不同季节下的空气质量也会有所差异,冬夏两季相比于春秋季节需要更多地使用空调、暖气等,因此在预测城市空气质量时应当考虑季节因素。
2.2 数据预处理
在上述所确定的影响因素中,最大风速风向与季节均属于非数值型因素,对此,对其进行了量化,将非数值型因素转化为离散的数值型因素。之所以这样处理,是因为随机森林算法对数据的单位及量纲表现并不明显,也不需要对整理好的数据进行归一化处理,这也是选取该算法建立模型的原因之一。
(1) 最大风速风向数据处理。将风向方位分为17类,分别为北、北偏东、东北、东偏北、东、东偏南、东南、南偏东、南、南偏西、西南、西偏南、西、西偏北、西北、北偏西及无风。并对其取值为[1,2,3,…,15,16,17]。
(2) 季节数据处理。季节的取值为[1,2,3,4],分别代表春夏秋冬4个季节。
2.3 数据来源
最终选取影响因素共16项(表2),所使用的数据为2018-01-01—2020-07-31日重庆市空气质量监测站历史数据与历史气象数据。其中空气质量监测站数据来自国家环保局,包含大气污染物六项因素与空气质量指数(AQI);历史气象数据来自中国天气网,包含9项气象参数。

表2 影响因素选取
3 预测模型的构建
基于随机森林回归的城市空气质量预测模型的整体思想是:确定影响城市空气质量的特征因素并收集整理数据集,然后应用随机森林回归进行模型构建,通过调整参数的最佳组合,不断优化模型。
3.1 测试集与训练集划分
共选取2018-01-01—2020-07-31共943条相关指标数据作为模型样本集。其中训练集与测试集样本比例为8∶2,训练集样本756条,测试集数据样本188条。
3.2 网格搜索法参数寻优
随机森林算法性能的影响因素主要有两个:构建决策树时所用特征的数目及随机森林中决策树的数目,不同的参数选择会得到的预测结果与精准度也会不尽相同。对此,使用网格搜索法进行最优参数选取。网格搜索法的本质是指定参数值的穷举搜索方法,即将各参数的可能取值进行排列组合形成网格,进而使用交叉验证对网格中的所有点的表现进行评估,从而寻找出最优参数。具体步骤如下:
步骤1:设定随机森林决策树棵数范围[1,160];决策树最大特征数范围[1,16]。
步骤2:考虑到计算量,将决策树棵数的寻优参数步长设置为10,决策树最大特征数的寻优参数步长设置为1。
步骤3:采用Python默认的5折交叉验证,其中4份作为训练数据,剩下的一份作为验证数据,从而生成不同的参数组合。
步骤4:求不同参数组合在验证集上的测试误差,选取测试误差最小的参数组合作为最终参数。
通过对重庆市2018-01-01—2020-07-31的指标数据通过网格搜索法进行参数寻优后,共得到240组参数组合。部分参数组合结果见表3。

表3 部分参数组合及其测试误差
各参数组合中,测试误差最小的组合为决策树数目71,决策树的最大特征数目15。因此将其作为随机森林算法的最终参数。
3.3 预测结果度量指标
采用通用的R2(决定系数)、DMSE(均方误差)、DMAE(平均绝对误差)作为度量指标,进行基于随机森林回归的城市空气质量预测模型的性能分析。
(4)
(5)
(6)
4 预测及结果分析
在Python环境下,采用构造决策树为71、特征数为15的最优参数组合对训练集进行训练,利用测试集对训练好的模型进行城市空气质量预测。各影响因子在模型中的重要程度见图1。

图1 各影响因子相对重要性
通过图1可以看出,O3、PM2.5、PM10、NO2、最高气温、日照时数、平均气温这几项因素的重要性程度较高,说明污染物浓度、气温、日照对城市空气质量的影响相对较大;相反,季节、CO、降水量、平均气温、平均风速等因素对城市空气质量的影响相对较小。
图2为模型预测值与实际值散点图,其中蓝色圆形点为空气质量预测值,黑色星形点为空气质量实际值。模型的预测值与实际值基本相吻合,但存在少数空气质量实际值偏高情况下的预测偏差。图3展示了模型预测结果和实际值的线性拟合效果。

图2 模型预测值与实际值散点
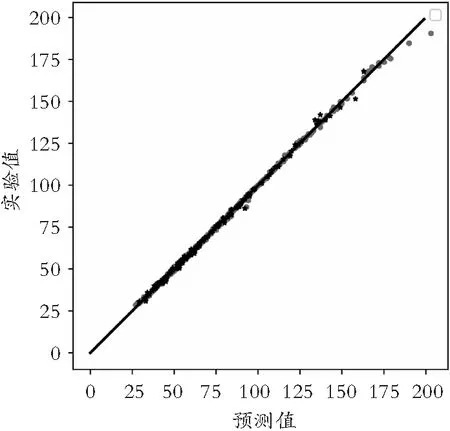
图3 模型预测结果和实际值拟合效果
此外,分别计算训练集与测试集的R2(决定系数)、DMSE(均方误差)、DMAE(平均绝对误差),见表4。

表4 模型性能分析
其中无论是训练集还是测试集,模型的确定性系数R2都达到99%以上,说明模型具有较好的学习能力与泛化能力;就误差而言,DMSE与DMAE在训练集与测试集上的取值均在可接受范围内。总体来说,提出的基于随机森林回归与气象参数的城市空气质量预测模型具有运行速度快、预测误差小、具有较高的预测精度等优点,具备较好的学习能力与泛化能力。
5 结束语
伴随当下人工智能技术的不断发展、大数据时来临,传统统计学方法劣势凸显,面对海量气象数据愈多学者选择使用机器学习方法构建城市空气质量预测模型。在此背景下,综合考虑污染物浓度、气象参数、时间参数等多方面影响因素,通过网格搜索法调整参数的最优组合,构建基于随机森林回归算法的城市空气质量预测模型,并以重庆市2017-01-01—2020-07-31的指标数据进行实证,结果表明,在模型下,训练集与测试集的确定性系数R2都达到99%以上,证实了模型具有运行快速、预测准确、不易过度拟合等优点。此外,针对预测中出现的高值空气质量预估偏差问题,是下一步的研究内容。
