基于Elasticsearch的纺纱生产数据追溯方法
2022-01-05王波波郑小虎申兴旺鲍劲松刘天元
王波波, 郑小虎, 申兴旺, 鲍劲松, 刘天元
(1. 东华大学 机械工程学院, 上海 201620; 2. 东华大学 人工智能研究院, 上海 201620;3. 上海工业大数据与智能系统工程技术研究中心, 上海 201620)
在纺纱生产中,纱线的生产要经历原料、梳理、并条、粗纱、细纱、络筒等诸多工序,每个环节中都可能出现质量或其他问题[1-2]。引发问题的因素往往来自于各个工序问题的耦合作用,其可能隐藏在前一道或者前多道工序中。只有对两两相邻工序间的数据建立关联,实现整个纺纱生产的数据互联,才能在后面工序发现问题时,核实前面工序中的问题因素,并及时修正;在工厂实验室进行前面工序的离线检测时,发现问题后也能够立即暂停包含问题因素的后面工序,做到及时止损。只有构建合理的纺纱生产数据追溯方法,才能实现纺纱生产全过程的数据管理和数据追溯。
目前,在实际纺纱生产中严重依赖人工,且生产标识体系落后、标识联通性差导致了质量溯源困难。为此,国内研究者们基于制造执行系统(MES)和企业资源计划系统(ERP)提出了多种实现质量溯源的框架。万由顺等[2]在全流程智能化纺纱研究中以MES为核心构建了纺纱质量追溯系统。崔士涛[3]采用全面质量管理和MES,并通过设定供应标识牌,从络筒工序开始倒推实现了质量溯源。薛建昌[4]也探讨了基于MES和ERP等系统实现对纺纱生产全过程信息采集、分析和处理的框架及方案设计。纺纱生产数据追溯作为前人MES研究框架下的一个子系统或子模块,目前更多地停留在宏观层面,没有进行更深入、细致的研究。
相比于国内,目前国外有针对实现数据追溯的具体相关技术的研究。Agrawal等[5]使用区块链技术研究纺织品的追溯问题,其本质是利用哈希算法对要追溯的内容,在保证数据不变性的前提下进行加密。Agrawal等[6-7]还利用在纺织品上随机打印的颗粒和二维码进行追溯,在提供溯源信息的同时实现防伪。Fernandez-Carames等[8]认为在工业4.0中,智能标签和射频识别(RFID)是较为先进的产品追溯解决方案。Jalonen等[9]针对RFID标签易损坏和移除的问题,提出一种替代的、不会产生物理干扰的视觉产品追溯系统。不管是区块链、二维码,还是RFID,都是在数据层面进一步展开,通过提供一个类似标签的内容告诉系统要追溯的数据地址,本身并不包含数据。但这些都没有触及数据的核心,即数据的存储和搜索,需要依靠MySQL、SQL Server和Elasticsearch等方法来实现。
MES框架下的质量溯源研究主要基于MySQL和SQL Server等方法进行构建[10],与之相比,Elasticsearch在电商平台的订单追溯中有较多成功应用,可为电商平台承担订单查询和产品追溯任务,且随着各行业对数据的愈加重视,纺纱生产数据的采集量也呈现不断上升的趋势。MySQL和SQL Server等已无法满足构建质量溯源的性能要求。而Elasticsearch既可以接纳非结构化数据[11],同时采用的倒排索引和分布式架构可以不断提升数据追溯性能。出于其优越的存储和搜索性能[12],本文通过构建相适应的标识体系和合理的追溯方法,以棉纺为例,研究了基于Elasticsearch的纺纱生产质量溯源方法,并通过对比实验进行验证。
1 纺纱生产质量溯源问题
目前,纺纱行业中普遍存在标识体系落后,质量溯源困难的问题,示意图如图1所示。以棉纺并条工序为例,并条机会被喂入6~8根棉条,并制成1根棉条。被喂入的多根棉条会分别用带有不同颜色标识的筒承装,见图1中的筒①、②。不同标识的筒代表承装的棉条之间的成分、质量、性能和相关数据存在差异。不止并条,这种标识体系在各纺纱工序中普遍使用,如细纱进入络筒的锭子也同样以不同颜色区分不同批次。
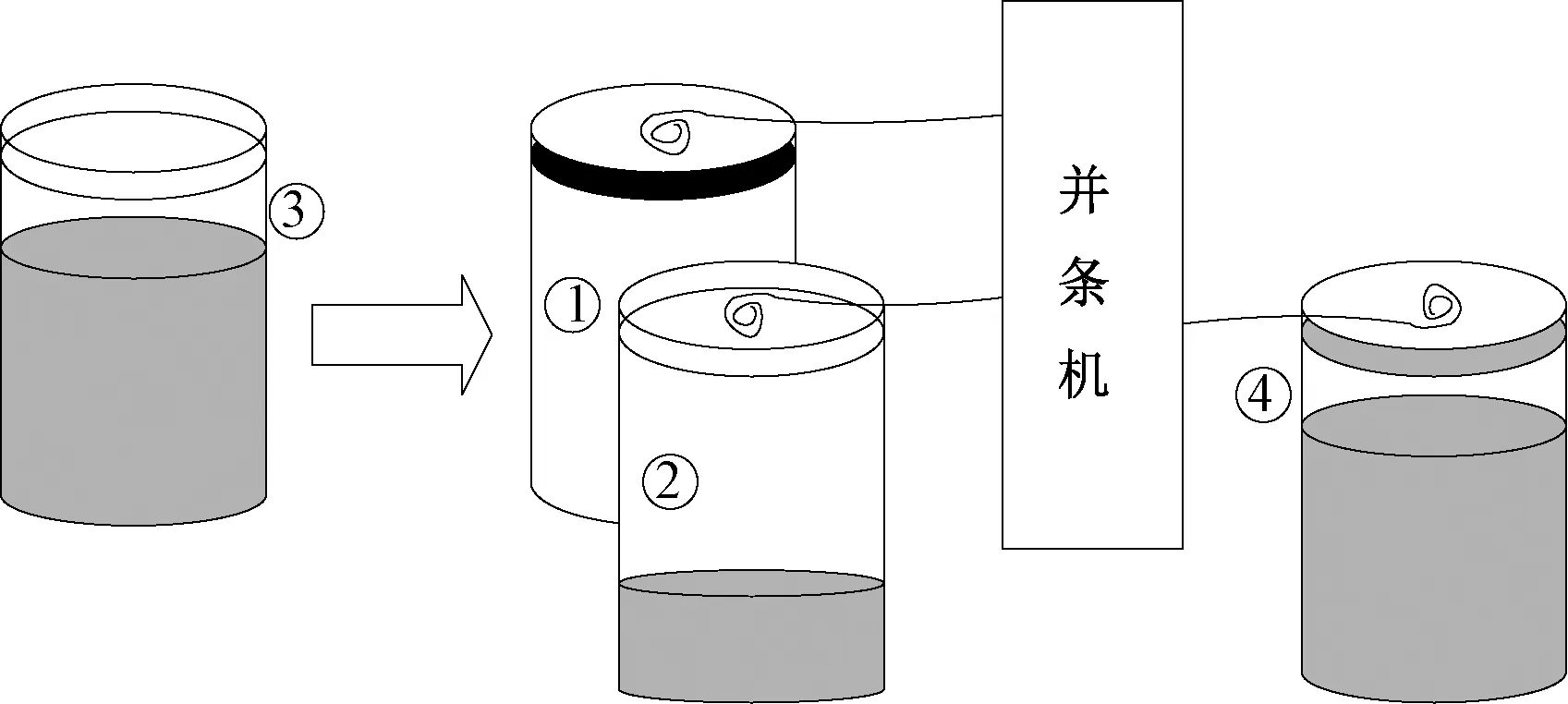
图1 纺纱生产质量溯源问题Fig.1 Realistic problems of quality tracing in spinning production
在图1中,假设筒④的容量已满,筒①的棉条用尽。筒④进入粗纱工序,筒①更换为筒③。当筒④棉条制成的粗纱出现质量问题时,并条工序加工的棉条已经改变,此时只能依靠对应工序以及2个工序之间负责物料搬运的纺纱工,通过对不同颜色标识的棉条的记忆来分析原因,容易出错且效率低下。
将图1中纺纱质量溯源的现实问题进行抽象描述,得到如图2所示的纺纱生产过程时序图,说明在粗纱中出现质量问题的时机位于Q1这个区间内,且和当前的并条工序没有重合。即使位于Q2这个重合区,如果在并条工序没有发现问题,再向梳棉工序排查时,又可能陷入非重合区。综上,目前面临的问题可以总结如下:标识和追溯体系没有数字化、规范化;标识没有在相邻工序中很好地联通,造成可追溯性差。
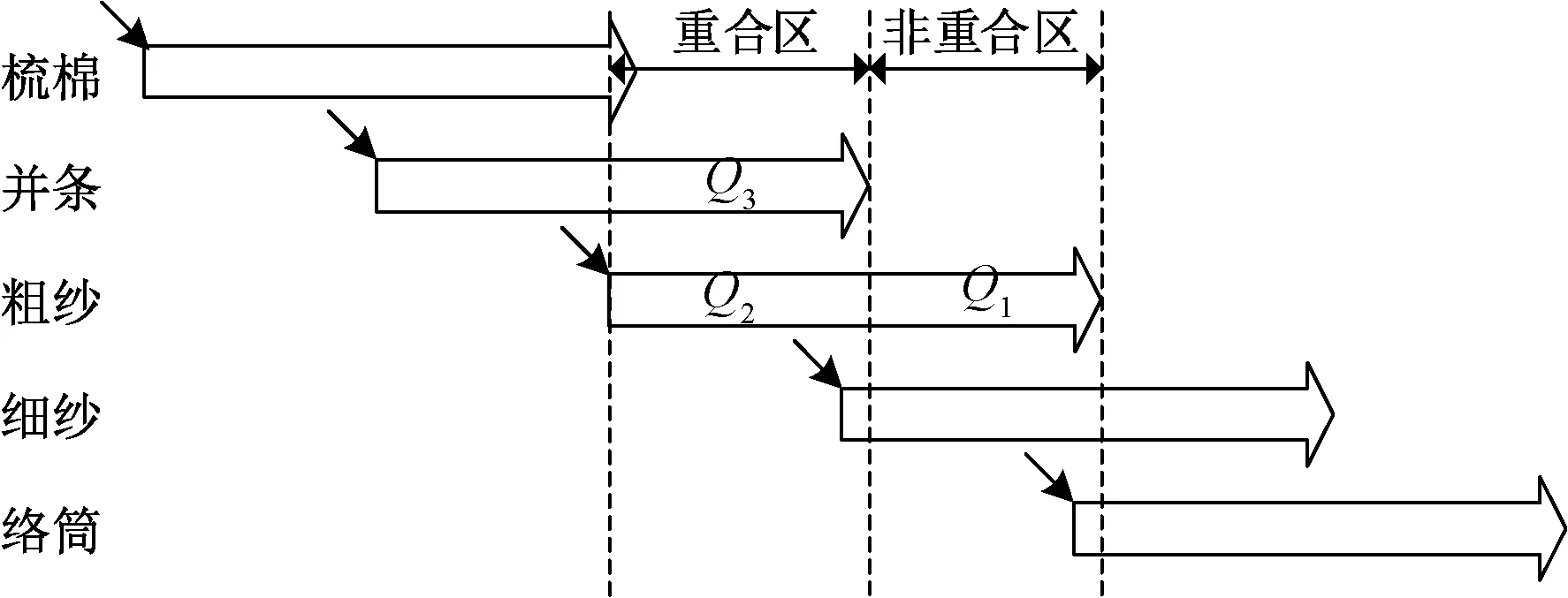
图2 纺纱生产过程时序图Fig.2 Sequence diagram of spinning production process
2 纺纱生产数据追溯方法
2.1 纺纱数据关联性
工序之间的关联关系是理解和实现数据追溯的前提。在整个纺纱生产过程中,从原料、棉条、粗纱等生产线上被加工的半成品到最终的纱线产品,不仅是承载数据的客观载体,也是串联各个工序的纽带。图3示出纺纱生产数据关联性示意图。
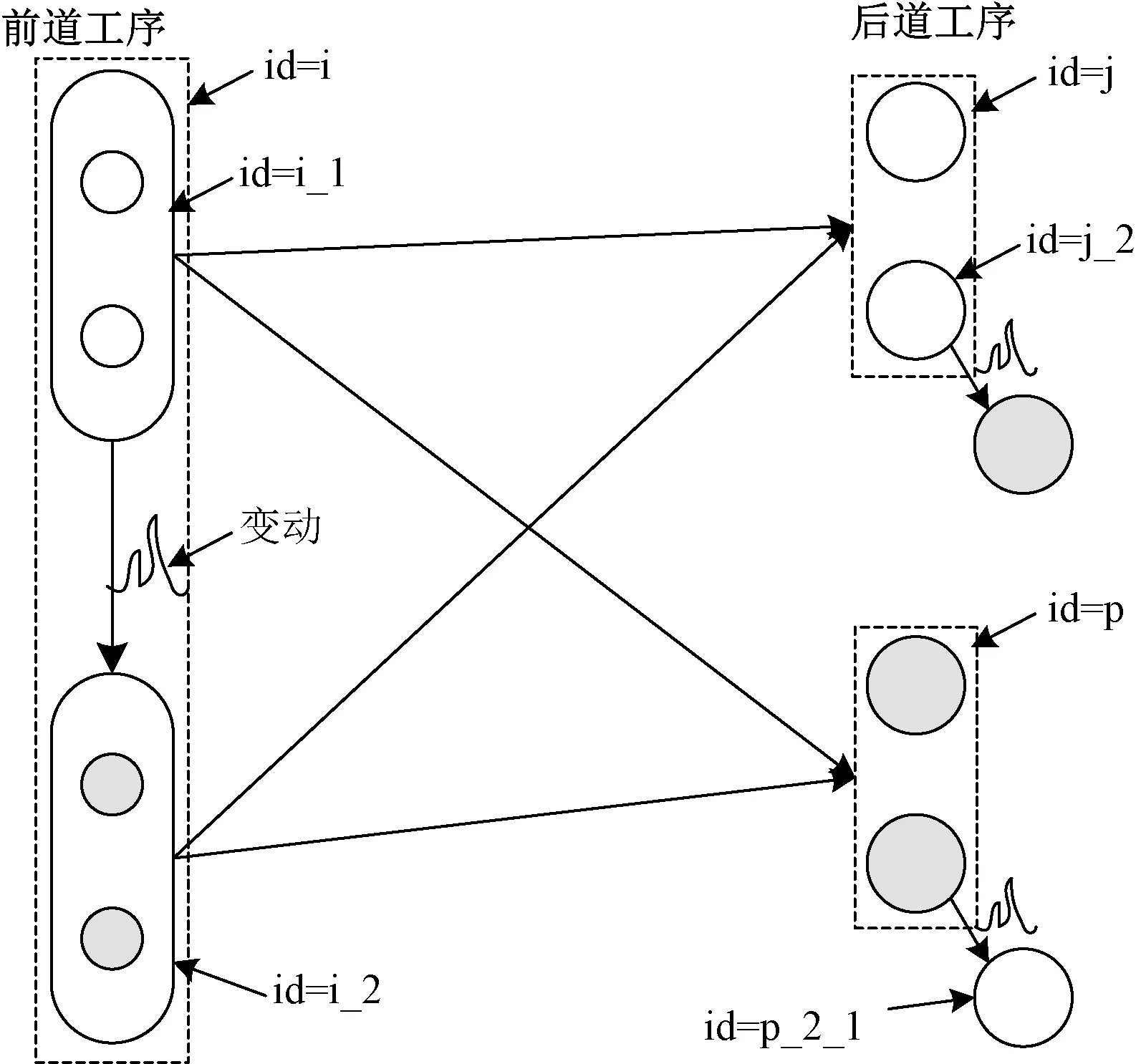
图3 纺纱生产数据关联性示意图Fig.3 Schematic diagram of data relevance in spinning production
由图3可见,在前道工序中,假设id为i表示纱线是在当前工序下在某个具体的设备上进行加工,同理如果id为m(mi)表示的就是另一台设备。id为i_1表示的则是纱线加工处于某个固定的加工状态,当这个固定的状态发生改变,即某个或多个因素发生变动,纱线承载的数据就由i_1变为了i_2。id为i和id为i_1、i_2的不同在于表示数据的粒度不同,同时i_1和i_2包含了id为i的信息。后道工序同理,但是像在细纱机和粗纱机上,id为p_2的粒度又可表示某个锭子,用p_2_1的粒度来表示某个锭子上纱线承载的数据。受限于数据采集的难度,本文研究和探讨的数据粒度为i_1级别。
假设当前道工序id为i_1和i_2的纱线流通到后道工序,且在后道工序中都承载了j_1、j_2、p_1和p_2的数据时,可用数据对[i_1,j_1]和[i_2,p_1]等来表示前后2道工序的关联关系。在纺纱生产的任意2道工序之间都存在这样的关联关系,故从任意的位置追溯最终都会归于原料数据。
2.2 追溯框架
基于Elasticsearch的纺纱生产数据追溯框架如图4所示。可见,纺纱生产要经历原料、清梳联、并条、粗纱、细纱和络筒等工序[1-2],每个工序都会产生相应的数据。又如图2纺纱生产过程在时序上的特性,当出现问题时不能只检测当前时刻每道工序可能存在的问题。纱线不可能再经历络筒、细纱、粗纱这样的倒序帮助分析问题因素所在,但每个工序上记录的数据可重构成一个纺纱产品从原料到某个固定工序的生产过程,从而进行辅助分析。
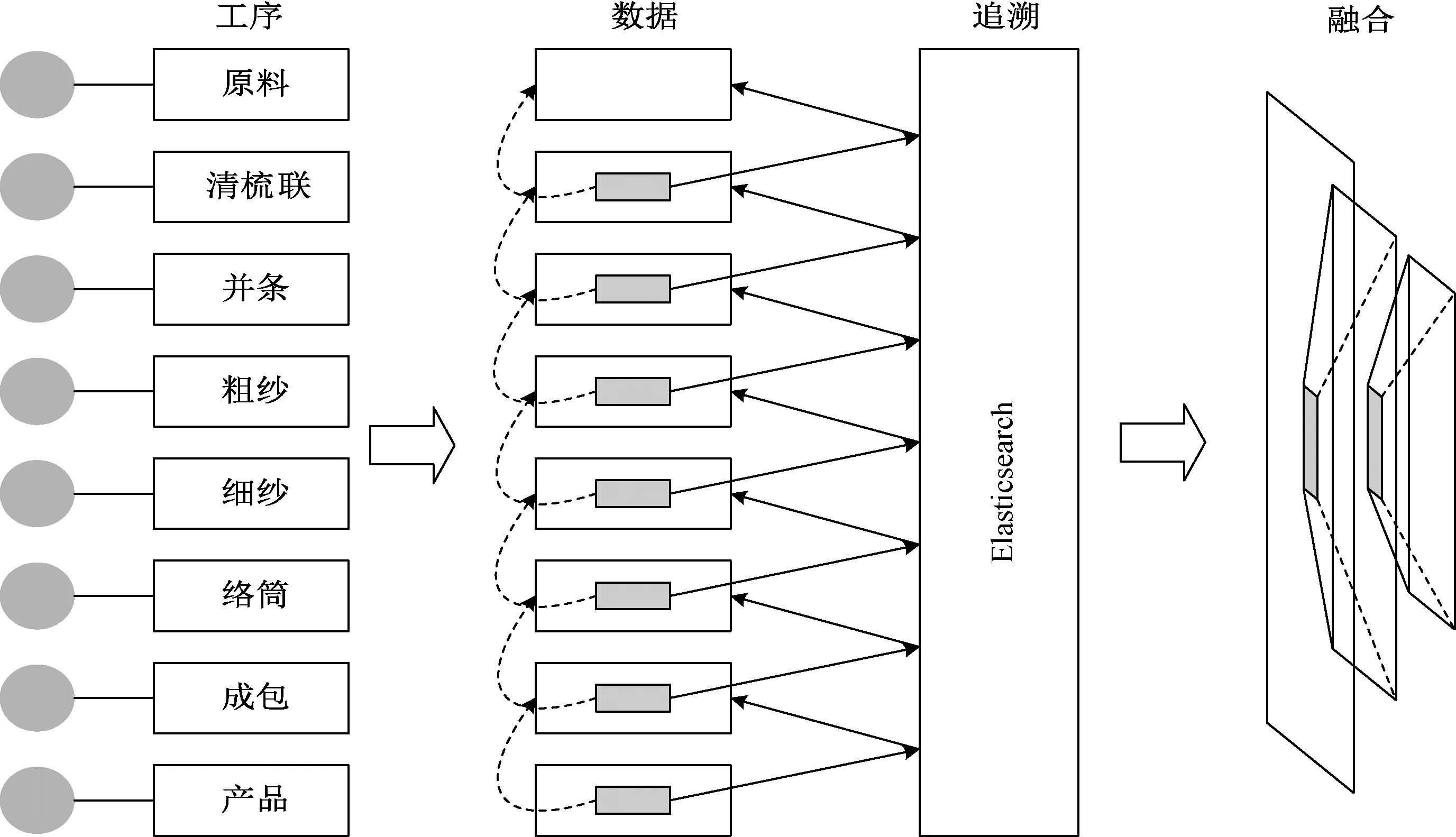
图4 基于Elasticsearch的纺纱生产数据追溯框架Fig.4 Framework of data traceing based on Elasticsearch for spinning production
为实现数据追溯和重构纺纱生产过程,需要在后道工序中增加相邻前道工序的关联数据的唯一标识。每个关联数据的标识是唯一的,但关联的数据并不唯一。如图4虚线箭头部分所示,在最终产品的记录数据中会包含指向成包数据的标识,成包数据中又会包含指向络筒数据的标识,依此类推直到指向原料的标识。本文借助开源的搜索引擎Elasticsearch,通过搜索内嵌的标识可得到从某道工序直至原料的所有相关数据,从而完成前向追溯,见图4实线箭头部分。然后将原本内嵌的标识使用其实际数据进行替换,层层递进就能够将所有相关数据融合为一个纺纱产品生产过程的完整数据块,见图4融合部分。
2.3 数据转换和存储
Elasticsearch完全采用JSON (JavaScript Object Notation)数据格式进行存储,所以要将原本存储在SQL Server或MySQL等关系型数据库中的原始纺纱表数据转换为JSON格式[13],并在转换成的JSON数据格式中添加标识数组,使之指向相关联的前道工序数据以实现追溯。
最终带标识数据的存储使用以下3种方案(共包括5种方法)。其中:方案1分别基于MySQL、SQL Server以数据表方法来实现;方案2分别基于MySQL、SQL Server以关联表方法来实现;方案3是本文基于Elasticsearch的方法。
1)MySQL和SQL Server数据表方法:直接在原始数据表中添加标识,包含的标识有几个则这条数据就存储几次。
2)MySQL和SQL Server关联表方法:引入1张新的表来存储当前工序数据的唯一标识和所关联工序数据的多个标识,并分别和各自的数据表以外键形式建立联系。
3)Elasticsearch方法:将每个工序的原始数据转换为JSON格式后,增加一个新的字段存储前道工序的相关标识,其值为数组形式,这样可灵活扩展多个标识。
2.4 数据追溯
Elasticsearch使用一种称为倒排索引的索引方法,适用于快速的全文搜索[14]。本文的数据追溯依托Elasticsearch来搜索数据中插入的标识和关键字段信息,从而追溯到与关注的问题数据密切相关的所有纺纱生产过程数据。
纺纱生产数据的前向追溯过程如图5所示。假设现在想要在精梳的数据集合中追溯到与并条标识为1的生产数据相关联的精梳数据,则从该并条数据的数据块中取出精梳工序的数据标识数组,如图中的1和2标识,然后在精梳数据集合中分别检索到相对应的数据,从而完成并条到精梳这个过程的追溯。
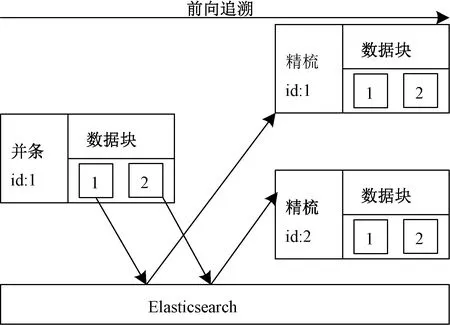
图5 纺纱生产数据前向追溯示意图Fig.5 Schematic diagram of forward tracing of spinning production data
在确定追溯的数据起点和工序终点后,假设每个追溯过程只包含2个标识,则从某个确定的络筒数据追溯到并条工序的路径如图6所示。图中的数字从小到大代表了追溯的先后顺序。首先从该络筒数据中取出相关的标识数组;然后从该数组中选择一个标识追溯到细纱数据;此时紧接着以该细纱数据为起点进行追溯,后面依此类推,并不是完成所有细纱数据的追溯,然后进行粗纱数据的追溯。

图6 纺纱生产数据追溯路径图Fig.6 Tracking diagram of spinning production data
在纺纱生产中,除自动络筒机上的电子清纱器在线监测纱线中的粗节、细节、棉结和杂质等质量问题外,还需要离线在工厂实验室检测条干和捻度等纱线性能。此时,被抽样检测的同批次纱线已经进入后面的工序。后向追溯可追溯到同批次或包含相同问题因素的纺纱产品,从精梳到并条的后向追溯示意图如图7所示。当察觉到标识为1的精梳数据有问题时,在并条的数据集合中检索数据块的关联标识数组中包含标识1的所有并条数据,则这些数据所代表的纺纱产品可能会存在相同的质量问题。

图7 纺纱生产数据后向追溯示意图Fig.7 Schematic diagram of backward tracing of spinning production data
假设此时以图6的追溯路径完成图5从并条到精梳的数据追溯,将原本在并条数据中的标识数组使用相应的精梳数据数组代替,结果如图8所示。则该融合结果形成了纺纱产品在并条和精梳工序上的完整数据块,并通过对比问题纺纱产品和紧邻的正常纺纱产品在追溯结果融合后的差异,从而找出可能导致问题的相关因素。
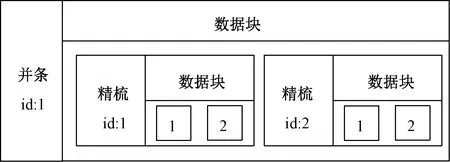
图8 纺纱生产数据融合示意图Fig.8 Schematic diagram of data fusion of spinning production
不同于追溯路径,假设每个追溯过程只包含2个标识,具体的融合路径如图9所示。图中的数字从小到大代表了融合的先后顺序。
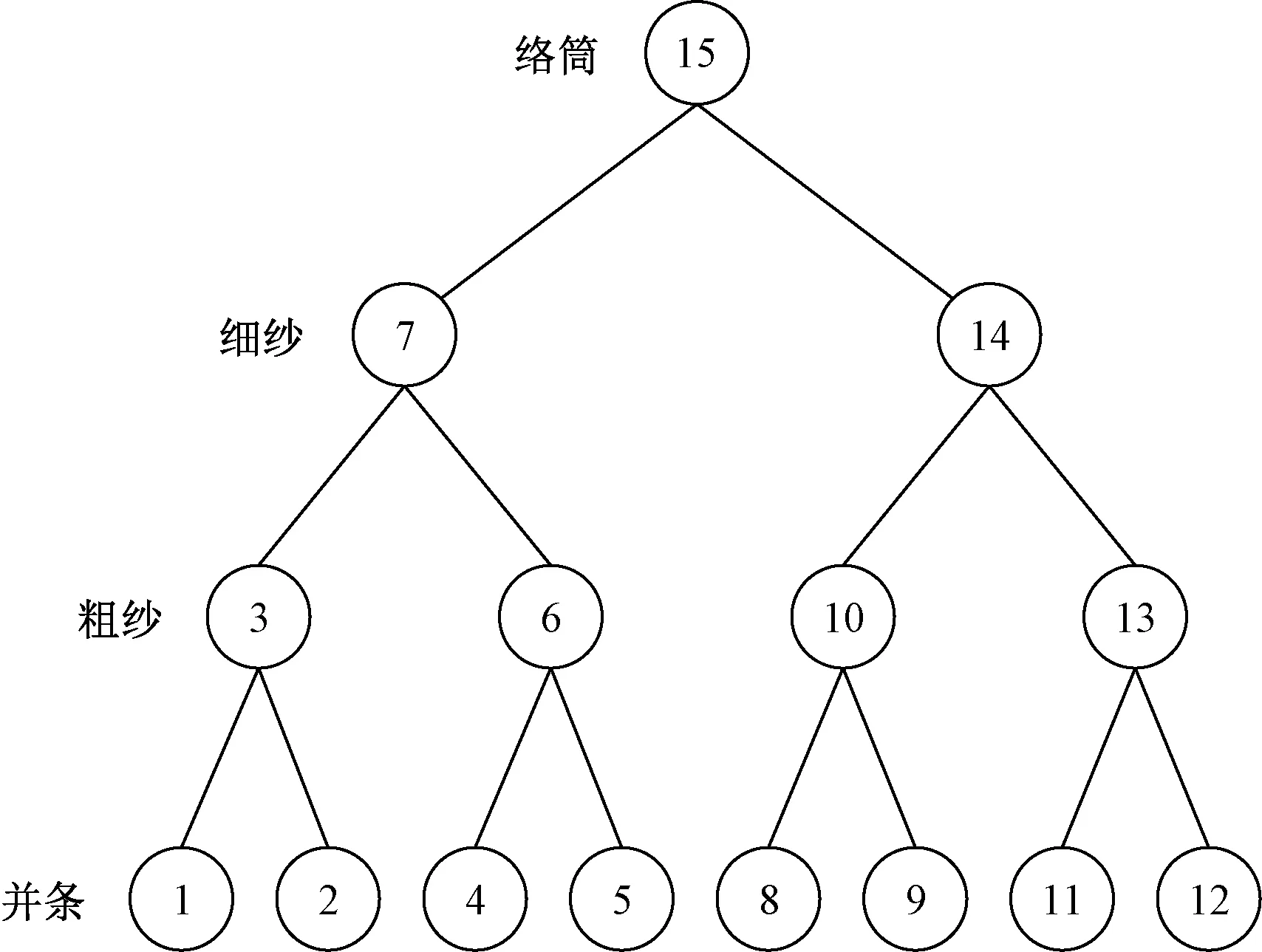
图9 纺纱生产数据融合路径图Fig.9 Road map of data fusion for spinning production
3 实验案例
3.1 实验环境
实验使用的纺纱生产数据采集自无锡某纺纱厂的现场数据,数据的产生时间为2018-06-30至2019-03-30。 实验数据涉及的纺纱生产设备有JWF1211型梳棉机、JWF1312B型并条机、JWF1418型粗纱机、JWF1562型细纱机和SMARO-E型络筒机,得到后续实验结果的数据和代码见GitHub仓库地址:https://github.com/WangBaobaoLOVE/ES-for-data-provenance-of-spinning。
3.2 实验对比
为测试基于Elasticsearch的纺纱生产数据追溯方法的性能,后续通过实验对比了和MySQL、SQL Server在存储及追溯时间上的差异,并展示了数据追溯和数据融合的结果。
3.2.1 原始数据存储对比
为显示纺纱数据在标识添加前后其内存的变化,表1示出原始细纱数据在不同数据量情况下各方法的内存占用,而添加标识后的存储分析将在后文讨论。
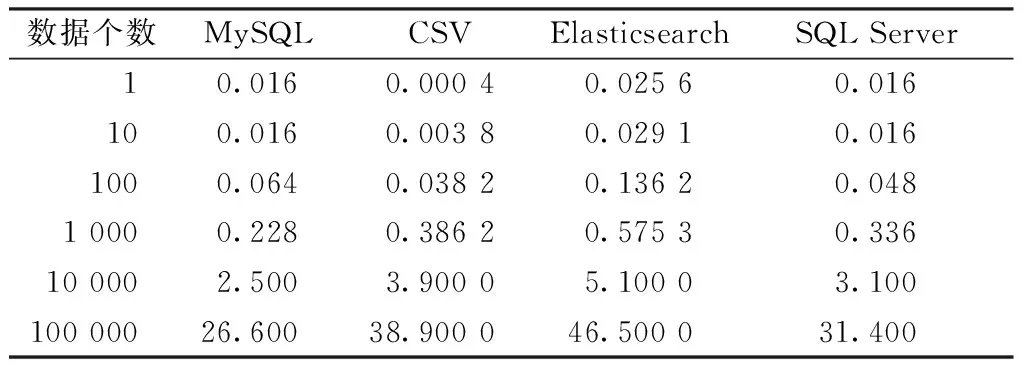
表1 原始细纱数据内存占用表Tab.1 Memory occupancy table of original spinning data MB
表1结果使用了JWF1562型系列细纱机上采集到的92个字段的原始数据。可知,在未添加标识前,MySQL的内存占用要明显小于逗号分隔值(CSV)文件、Elasticsearch和SQL Server。这里CSV文件主要是作为MySQL、Elasticsearch和SQL Server的中间转换文件,即导入数据的源文件,其内存消耗仅优于Elasticsearch。此外,Elasticsearch的内存消耗最大,且数据存储量从1~10万的各情况下平均内存消耗分别是MySQL和SQL Server的1.89和1.85倍。这主要是因为在原始数据存储过程中会自动建立倒排索引,从而增加了内存消耗,但也使得数据搜索的速度达到毫秒级别。而这时MySQL中只有数据消耗内存,并没有建立数据索引;SQL Server则会建立正排索引,所以综合形成表1 的情况。
3.2.2 带标识存储对比
在本节依然如3.2.1节以同样细纱数据为例,分析了2.2节5种方法在标识数量变化下的内存占用情况。注意在实际生产中,各工序数据中标识数量是不统一的,且是较多的,这里假设标识数量一致进行研究分析。将1万条数据分别按照2.2节的5种方法添加标识,结果如图10所示。MySQL和SQL Server数据表的内存消耗随标识数量的增加呈现明显的增加趋势,并与添加的标识数量成线性关系,其比例系数分别为2.68和3.27。MySQL和SQL Server关联表相较其各自的数据表方法增加趋势明显减小,且同样与添加的标识数量成线性关系,其比例系数分别为0.89和0.25。而Elasticsearch方法的存储消耗基本稳定在5.0 MB左右。其次在少于2个标识时,Elasticsearch的内存消耗大于SQL Server关联表,和MySQL关联表持平,优于另外2种数据表方法。在大于2个、少于8个标识时,Elasticsearch的内存消耗仅大于SQL Server关联表。在大于8个标识后,Elasticsearch方法最优。显然,本文方法更适应各纺纱工序数据中标识数量不统一并且较多的实际应用场景。
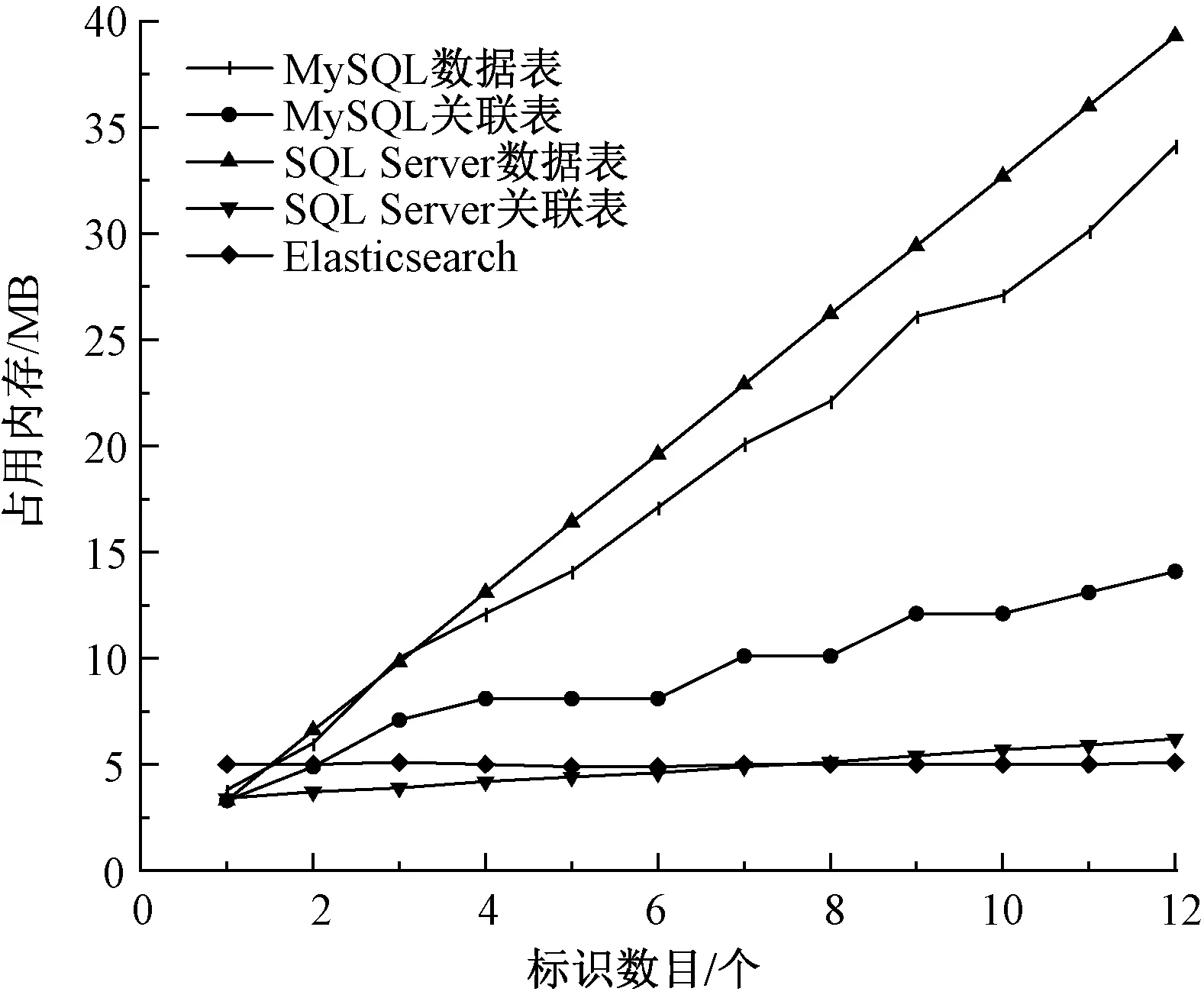
图10 带标识细纱数据的占用内存Fig.10 Memory usage of marked spinning data
3.2.3 追溯速度对比
本节研究了单过程和多过程数据追溯、标识数量及MySQL、Elasticsearch和SQL Server这3种方法对追溯时间的影响。其中单过程是指从细纱向粗纱或粗纱向并条单过程的数据追溯,这里以细纱向粗纱为例,细纱数据来自JWF1562型细纱机,粗纱数据来自JWF1418型粗纱机。多过程是指数据追溯的过程多于1个,这里以络筒→细纱→粗纱→并条→梳棉4个过程的追溯为例,细纱、粗纱数据同单过程,络筒、并条、梳棉数据分别来自SMARO-E型络筒机、JWF1312B型并条机和JWF1211型梳棉机。单过程数据追溯方法见图5,而多过程追溯是由多个单过程构建而成。
在单过程数据追溯中,随机选择10个细纱数据,每个数据追溯10次,然后计算其平均耗时作为该过程数据追溯时间,结果如图11所示。3种方法追溯时间都随标识数量的增加而增加。但MySQL追溯时间始终远远高于Elasticsearch和SQL Server,分别是其2.2和1.9倍;而Elasticsearch和SQL Server则比较接近,且Elasticsearch略优。
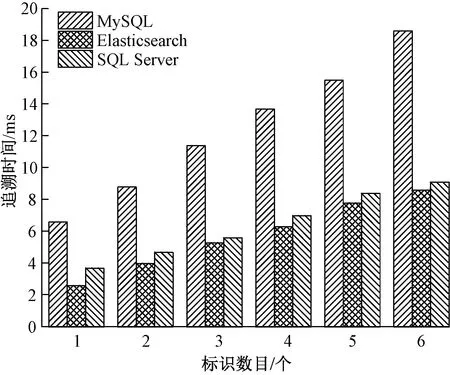
图11 单过程数据追溯时间随标识添加数量的变化Fig.11 Data tracing time varies with number of labels added in single process
在多过程数据追溯中,随机选择10个络筒数据,然后不断追溯到对应的梳棉数据,并计算其平均耗时作为该过程追溯时间,结果如图12所示。可知,MySQL、Elasticsearch和SQL Server的数据追溯时间都随标识数量的增加而增加,且每次追溯时间由少到多依次是Elasticsearch、SQL Server和MySQL。在Excel中使用多项式对3条曲线进行拟合,其最高次幂的系数分别为0.15、0.18和0.24,说明Elasticsearch的追溯速度分别大约是MySQL和SQL Server的1.6和1.2倍。
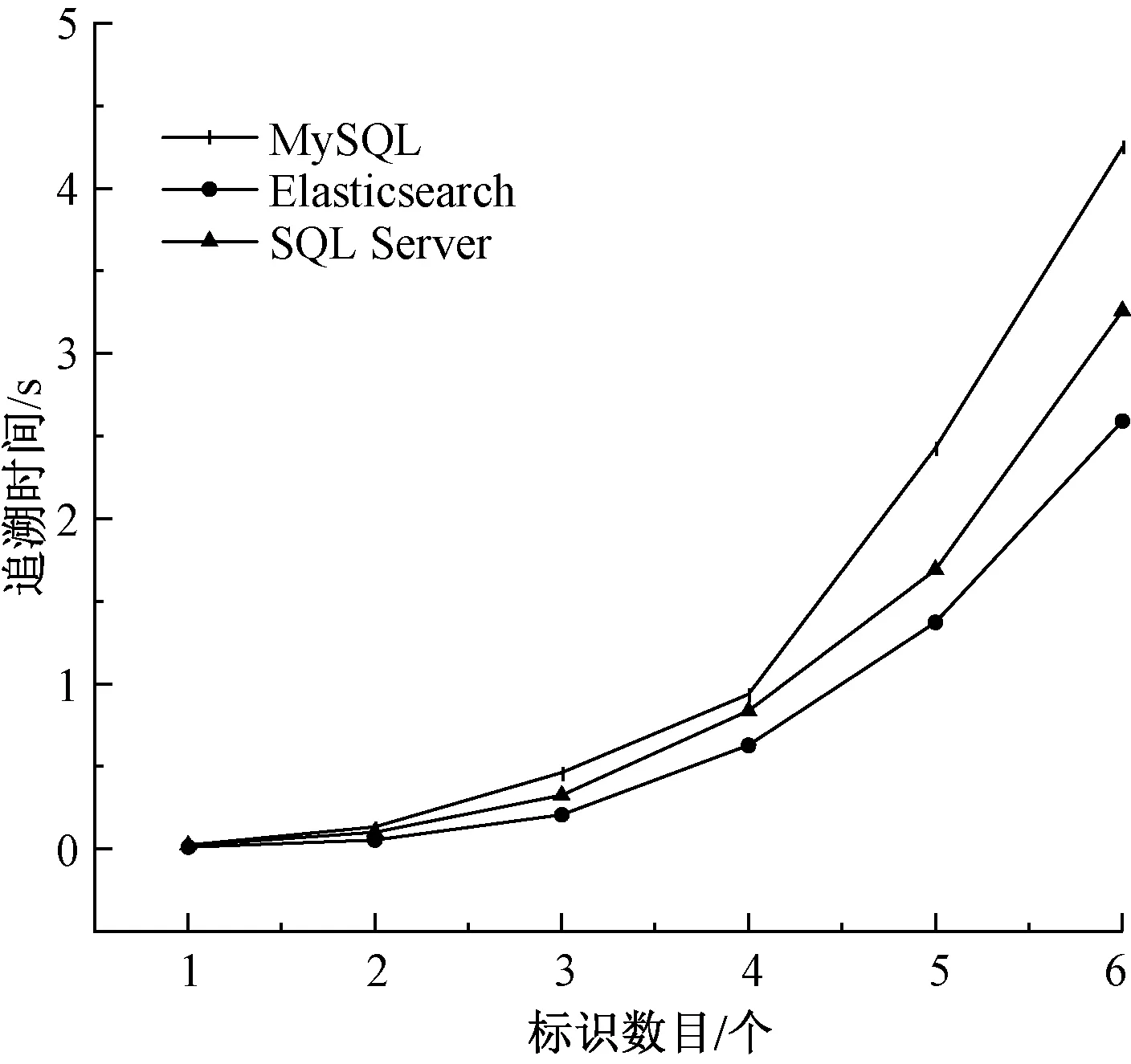
图12 多过程数据追溯时间随标识添加数量的变化Fig.12 Data tracing time varies with number of labels added in multi-process
在图12中,追溯时间随添加标识数量呈现的增长趋势主要是实验设定每个加工过程数据其包含的标识数目是相同的。由图5可看出,这是1个单过程两标识的数据追溯示意图,2个箭头表示执行2次搜索操作完成该追溯过程。在图12的多过程追溯中,4个过程的搜索次数就是30。其查询次数N与标识数量b和追溯过程数p的关系可用下式[15]表示:
之前得到的实验结果可得Elasticsearch的追溯速度分别约是MySQL和SQL Server的1.6和1.2倍, 可以归结为每次搜索操作,Elasticsearch的追溯速度是MySQL和SQL Server的1.6和1.2倍。
3.2.4 数据融合和对比分析
在完成数据追溯后,将追溯到的数据按照图8、9进行数据融合,得到图13所示为一个单过程追溯结果数据融合的实例。图中“115”是该追溯起点数据的唯一标识,“16”是产生该数据的纺纱设备编号,“before_record”中以数组形式记录了前道工序相关联的数据,如标识为“774”和“826”的数据。
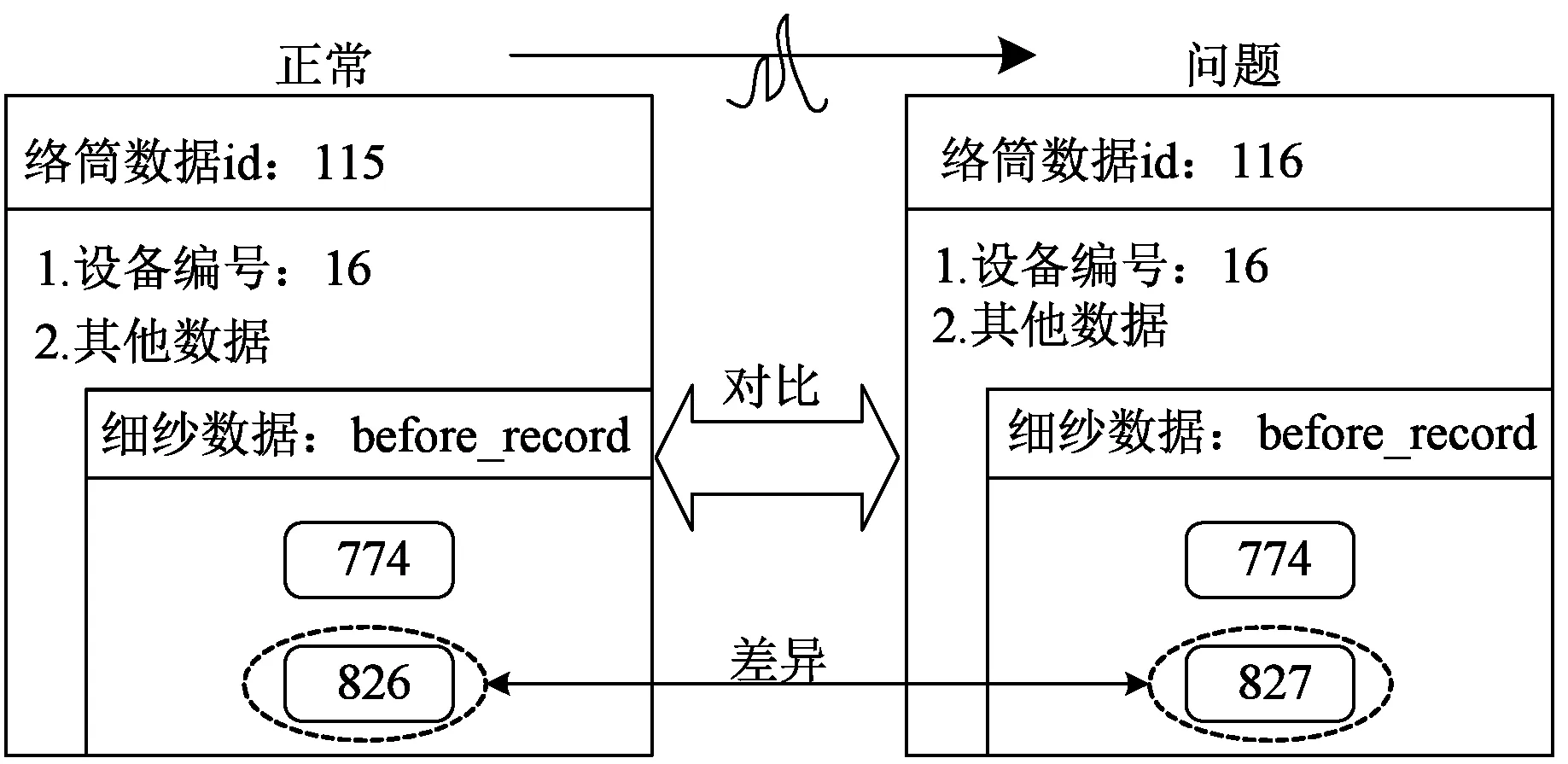
图13 数据融合结果图Fig.13 Chart of data fusion results
通过对比图13所示紧邻的正常和问题纺纱产品的追溯结果融合数据块,分析二者之间的差异,包括但不限于是某个或多个参数的变动,某道工序少了或多了几个标识数据等,从而辅助分析可能的问题产生因素。
3.3 结果分析
纺纱生产过程的数据追溯使用本文提出的基于Elasticsearch的方法和MySQL、SQL Server等方法都可以实现。但本文基于Elasticsearch的方法其内存消耗对标识数量更加具有稳定性,在图10所代表的实验中基本维持在5.0 MB左右。另外,Elasticsearch在追溯速度上均优于另外2种方案。之所以造成3种方法在存储和时间上的性能差异,原因分析如下。
1)存储上:使用数据表方法不能适应标识数量变化的情况,会造成数据冗余和更多的内存消耗。使用关联表以多对多关系和相关联的2张数据表通过外键建立联系的方法会生成索引数据,同样会消耗较多的内存,但在JSON中,以一个字段的数组值来存储标识,可灵活扩展标识的数量,相当于在数组中增加了若干数据,所以其对带标识数据存储的稳定性表现最好。
2)时间上:主要得益于Elasticsearch的倒排索引,而MySQL、SQL Server等主流关系型数据库使用的是正排索引方式。从实验结果可以看出,针对纺纱数据,倒排索引的机制是适用的。
4 结 论
本文通过研究基于Elasticsearch的纺纱生产数据追溯方法,使得在纺纱生产中实现数字化管理和质量管控的数据存储性能和追溯速度得到提升。通过对MySQL、Elasticsearch和SQL Server实现的数据追溯方法进行充分的对比实验发现,所提追溯方法在添加标识情况下更具存储稳定性,且追溯速度分别是MySQL、SQL Server的1.6和1.2倍;使用JSON结构可很好的扩展追溯到的数据,形成数据融合结果,从而进行分析比对,实现质量溯源。
在实际生产环境中,该方法可有效解决现实纺纱生产中人工依赖严重、标识体系落后和联通性差导致的质量溯源困难问题,具有一定的应用价值,但也要清晰意识到MySQL、SQL Server和Elasticsearch具有各自的优势和缺陷,在不同的实际应用中还需要根据实际情况进行实验分析。
