一种基于语义特征预测N4-乙酰胞苷修饰位点的方法
2022-01-04郑杨
郑杨
(邵阳学院 食品与化学工程学院,湖南 邵阳,422000)

目前,在RNA分子中鉴定出了160多种不同的修饰[1],这些修饰影响RNA代谢的各个方面,比如稳定性、结构、翻译、定位、拼接,开辟了对基因调节的新途径[2]。目前已报道的一种可逆修饰是m1A[3],它修饰了所有类别的RNA和DNA,影响RNA代谢的各个方面,但其生物学功能需要进一步探寻。除了以上转录组学标记外,还报道了RNA中的第一个乙酰化标记,即真核mRNA中的N4-乙酰胞苷(ac4C)[4]。
THOMAS等[5]描述了ac4C是一种高度保守的修饰核碱基,其形成是由必需的胞嘧啶乙酰基转移酶NAT10催化的。ac4C可以影响mRNA解码效率,在调节mRNA翻译中起作用。JIN等[6]阐述了ac4C在翻译过程中有助于正确读取密码子,并提高翻译效率和mRNA的稳定性,总结了ac4C在基因表达调控中的作用和机制,证明了ac4C与人类的多种疾病尤其是癌症的相关性。所以,准确检测ac4C修饰至关重要。
近年来,生物物理或生物化学技术被开发用于检测ac4C,但是采用这些技术既费时又费力。为了高效准确地检测ac4C,深度学习和机器学习的检测方法也应运而生,PACES是用位置特异性二核苷酸序列分布(PSDSP)和k核苷酸的频率(KNF)结合随机森林分类器进行N4-乙酰胞苷修饰位点分类的预测方法[7]。XG-ac4C是用核苷酸的EIIP值和每个核苷酸的平均EIIP值结合XGBoost分类器进行ac4C修饰位点分类的预测方法[8]。虽然XG-ac4C各项评价指标较好,但灵敏度(SN)还是较低,且前面2种方法均使用普通机器学习方法。在此基础上设计一种基于深度学习的语义特征提取方法,通过卷积神经网络和长短时记忆网络(LSTM)提取序列中隐藏的语义特征,然后,输送到随机森林分类器模型中进行训练以及预测。提出的模型流程见图1。
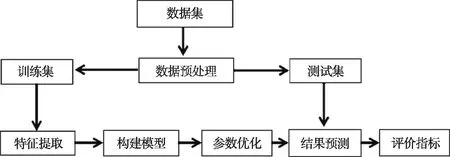
图1 流程图Fig.1 Flow chart
1 数据
用到的数据集是ZHAO等[7]划分的,他们从2 134个基因中[9]提取至少5次重复的CXX基序,把位于乙酰化峰内连续的CXX基序当作正样本,峰外的连续CXX基序当作负样本。然后,将这些样本分为训练集和测试集,训练集中有1 160个正样本,10 855个负样本,测试集中有469个正样本,4 343个负样本。
2 方法
方法包括4个主要步骤:数据收集、特征编码、随机森林分类器模型训练和ac4C预测。进一步可划分为数据收集与预处理、构建深度学习模型提取语义特征,构建随机森林分类器,优化分类器参数,训练随机森林分类器并使用训练后的分类器预测ac4C。使用ac4C数据集中的训练集进行深度学习模型的训练,将倒数第2层的输出视为ac4C语义特征,然后放到随机森林分类器中进行训练并预测。
2.1 语义特征提取
2.1.1 序列分割
假设ac4C的序列与自然语言中的句子一样,碱基间具有语义联系,如果把单个碱基(A,T,G,C,N)看做1个单词,那么只有5种表示方式,不能较好地反映句子之间的联系。如果使用双碱基,那么只有25种表示方式,对于句子之间的关系反映还是有所欠缺。使用4个或4个以上的碱基组和形式并不合适,因为实际序列中并没有这么多类型,并且还增加了计算的复杂度。如图2所示,把每3个碱基看成1个单词进行数字编码,即包含5×5×5=125个单词。
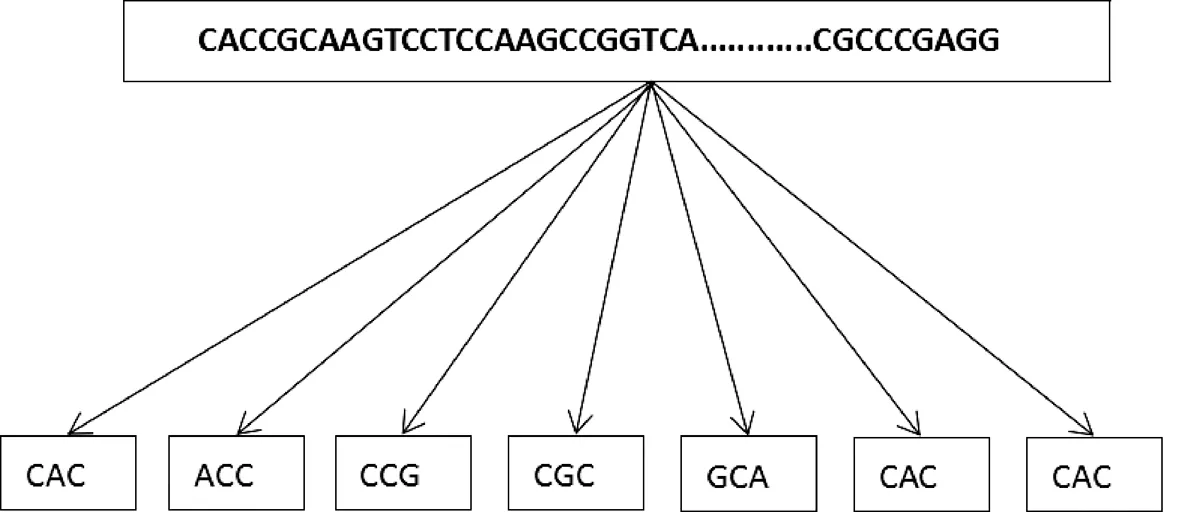
图2 词汇划分Fig.2 Vocabulary division
2.1.2 构建模型
使用的深度学习模型主要包含:嵌入层、一维卷积层、池化层、双向长短时记忆网络层、丢弃层、扁平化层和全连接层。模型结构见图3。
1)嵌入层。嵌入层是使用在深度学习模型中的第一个网络层,是将离散变量转为连续向量表示的一个方式。在神经网络中,嵌入层是比较有用的,因为它可以减少离散变量的空间维数,通常用于文本数据建模。

图3 深度学习模型结构图Fig.3 Architecture of deep learning model
2)一维卷积层。卷积神经网络(CNN)是一种前馈神经网,在图像处理、语音识别、生物信息学等各个方面应用广泛[10]。卷积神经网络将人工神经网络和深度学习技术进行了结合,构造了一种新的方法,其目的是以一定的模型对事物进行特征提取,而后根据特征对该事物进行分类、识别、预测或决策等[11]。CNN特点是可以进行局部感知,所以,对于局部信息的识别尤其精准[12]。卷积层的输入输出数据称为特征图[13]。
3)池化层。池化层是当前卷积神经网络中常用组件之一,它最早见于LeNet一文,称之为Subsample[14]。自AlexNet之后采用Pooling命名[15]。池化层通常用来实现对网络中特征图的降维,减少参数数量的同时,为网络后面各个层增加感受野,保留特征图的显著特征。实施池化的目的是防止模型过拟合。
4)双向长短时记忆网络层。循环神经网络(RNN)[16-17]是一种将以往学习的结果应用到当前学习的模型,但是一般的RNN存在着许多弊端。标准的RNN结构中只有1个神经元,1个tanh层进行重复学习,不能很好地处理长语句中相关的信息与预测词之间的联系,但长短时记忆网络(LSTM)可以解决这一问题[17-18]。LSTM处理序列问题有效的关键在于门结构,通过门结构去除或者增加信息到细胞状态的能力。LSTM由于其设计的特点,适合用于对时序数据的建模,但是,利用LSTM对句子进行建模无法编码从后到前的信息,所以,双向长短时记忆网络(BiLSTM)应运而生,它可以较好地捕捉双向的语义依赖。
5)丢弃层。在深度学习的模型中,如果模型参数太多训练样本太少,训练出来的模型容易产生过拟合。HINTON等[19]提出Dropout可以比较有效地缓解过拟合的发生,在一定程度上达到正则化的效果。Dropout的原理为通过阻止特征检测器的共同作用来提高神经网络的性能[20]。
6)扁平化层和全连接层。扁平化层用来将多维的输入一维化,常用于从卷积层到全连接层的过渡,且扁平化不影响批次的大小。全连接层在整个卷积神经网络中起到“分类器”的作用。全连接层实质是一个矩阵乘法,进行一个特征空间变换,目的把有用的信息提取整合。
2.1.3 提取特征
搭建好深度学习模型后,用训练集的数据训练CNNLSTM模型,因为数据庞大,为了提高训练速度,节省内存利用,分批次进行训练。训练时,因为正负样本数量差别过大,容易造成数据失衡,所以,采取加权的方式来平衡正负样本。将ac4C的序列输入到此深度模型中,获取全连接层的输出视作语义特征,获得26 464维语义特征。
2.2 随机森林
随机森林是一种集成算法[21],它是袋装算法的1种,组合多个弱分类器,最终输出的类别由个别树输出类别的众数而定,随机抽样方法使它具有抗过拟合能力,而组合多个弱分类器使它预测更加精准。
随机森林的弱分类器是决策树[22],当数据集的因变量为连续性数值时,该树算法就是一个回归树;当数据集的因变量为离散型数值时,该树算法就是一个分类树[23]。决策树算法是1个二叉树,每一个不是叶子的节点都能分出2个子节点。
特征选择目前常用的方法是信息增益、增益率、基尼系数和卡方检验。随机森林采用的分类回归树(CART)就是基于基尼系数(GiNi)选择特征的[24]。
对于一般的决策树,假如总共有k类,样本属于第k类的概率为pk,则该概率分布的基尼指数为
(1)
随机森林是一个基于树的集合,每棵树都取决于随机变量的集合。对于表示实值输入或预测变量的p维随机向量X(X1,…,Xp)T和表示实值响应的随机变量Y,假定未知的联合分布为PXY(X,Y)。目标是找到预测函数f(X)用于预测Y。预测函数由损失函数L(Y,f(X))确定,并定义为使损失的期望值最小化:
EXY(L(Y,f(x)))
(2)
其中:下标表示对X和Y的联合分布的期望。
L(Y,f(X))是衡量f(X)到Y的接近程度,它的值越大,表示f(X)与Y距离越远。L的典型应用是平方误差损失L(Y,f(X))=(Y-f(X))2,通常用于回归和0-1损失分类:
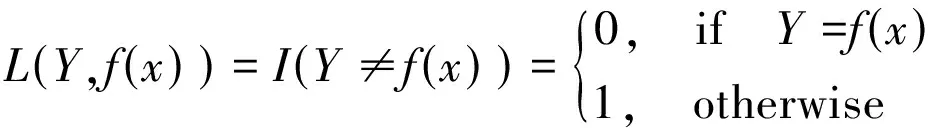
(3)
实际上,可以通过方法[25]可使EXY(L(Y,f(X)))最小化,对于平方误差损失给出条件期望:
f(x)=E(Y|X=x)
(4)

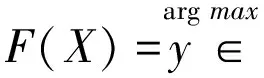
(5)
此过程也称为贝叶斯规则。
集合构造f根据一组所谓的“基础学习者”h1(x),…,hj(x)与这些基础学习器组合在一起,得出“整体预测器”f(X)。在回归中,基础学习者被平均:
(6)
在分类时,f(X)是最常预测的类别:
(7)
在随机森林中,第j个基础学习者是1棵树,表示为hj(X,Θj),这里的Θj是随机变量的集合,Θj与j=1,…,J是独立的。
3 评价指标
为了评估的方法和当前的预测ac4C位点预测方法的实施情况,使用2种评估技术对的方法进行了评估。第一种技术是通过5倍交叉验证建立的。具体来说,将数据分为5个部分,其中1个用于验证,而另外4个用于训练。第二种技术是使用独立测试集来评估方法的整体质量。
为了定量比较方法的性能,使用了以下指标:灵敏度(SN)、特异性(SP)、精度(ACC)和马修斯相关系数(MCC)。
其中:TP和TN分别是真阳性和真阴性样本的数量;FP和FN分别是假阳性和假阴性样本的数量。
受试者工作特征曲线(ROC曲线)是衡量二分类模型优劣的1种评价指标,它可以根据一系列不同的二分类方式,以真阳性率(TPR)为纵坐标,假阳性率(FPR)为横坐标绘制的曲线。ROC曲线下面积在0到1之间,其中,TPR和FPR的计算方法为
4 结果
用主成分分析(PCA)[26]可视化语义特征,PCA是一种用于探索高维数据结构的技术,通常用于高维数据的探索与可视化,PCA将数据映射到一个低维子空间实现降维。如图4所示,语义特征对于区分ac4C修饰与非修饰有很好的效果。
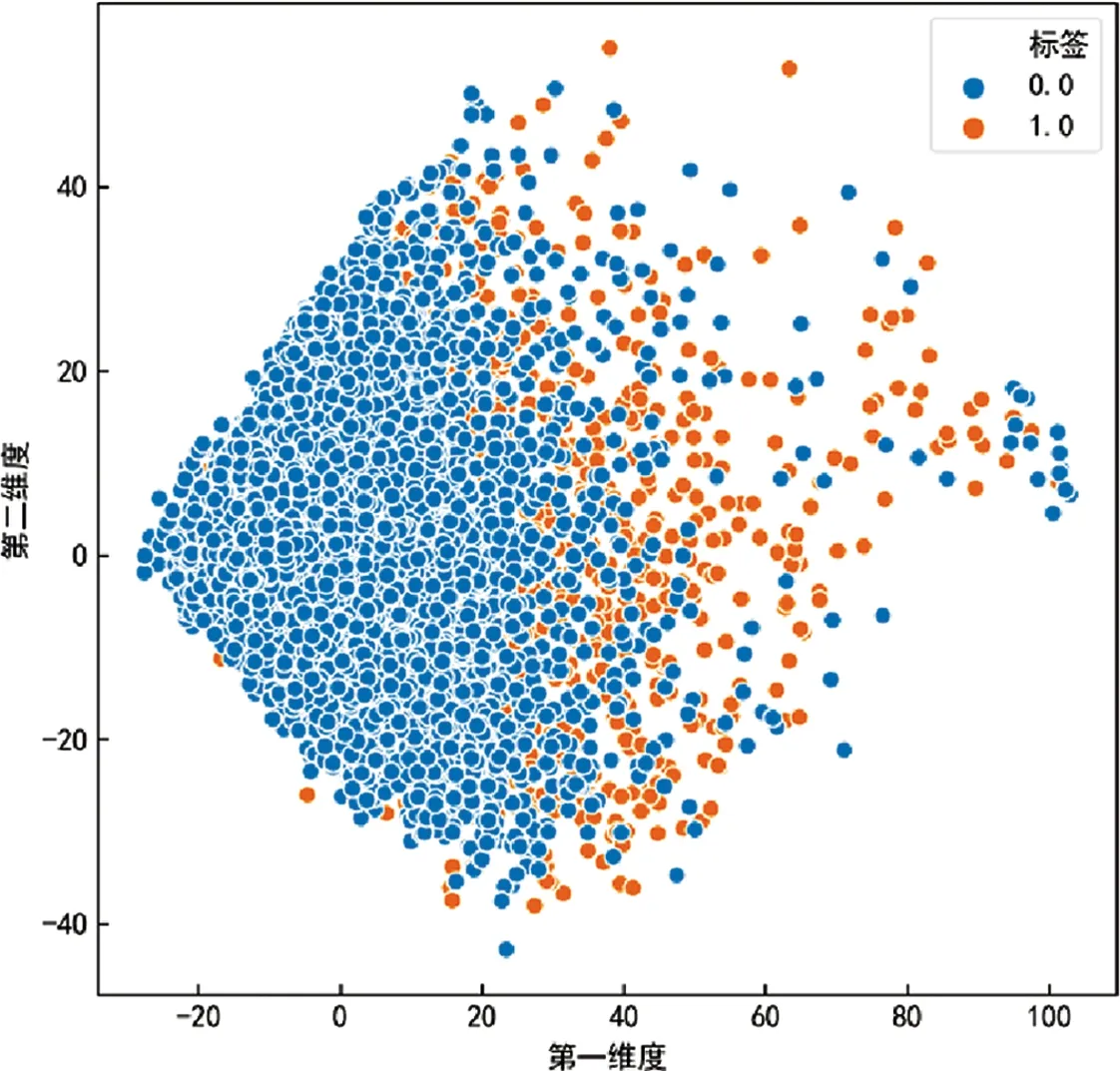
图4 PCA可视化语义特征Fig.4 Semantic features visualized with PCA
设置随机森林分类器时,为了使每次结果一致,将随机状态(random_state)设置1个固定值,即random_state=100。使用训练集经深度学习模型提取的语义特征进行5倍交叉验证,用来优化随机森林分类器中的参数,将最佳性能的参数保留下来,见表1。

表1 随机森林分类器参数Table 1 Parameters of random forest classifier
因为ac4C数据中正样本、负样本的数量差距太大,所以,要进行平衡处理。随机森林分类器中的类型权重参数(class_weight)可以用作平衡正样本、负样本的不均衡问题,可以把其设置为“balanced”,该设置会自动计算权重,使输入样本中各类别之间的权重自动平衡。
如图5所示,语义特征在交叉验证上的ROC曲线方法在5倍交叉验证上达到了较好的性能(AUC=0.879 6)。语义特征在独立测试上的ROC曲线见图6,这种方法在独立测试中效果较好(AUC=0.871 8)。
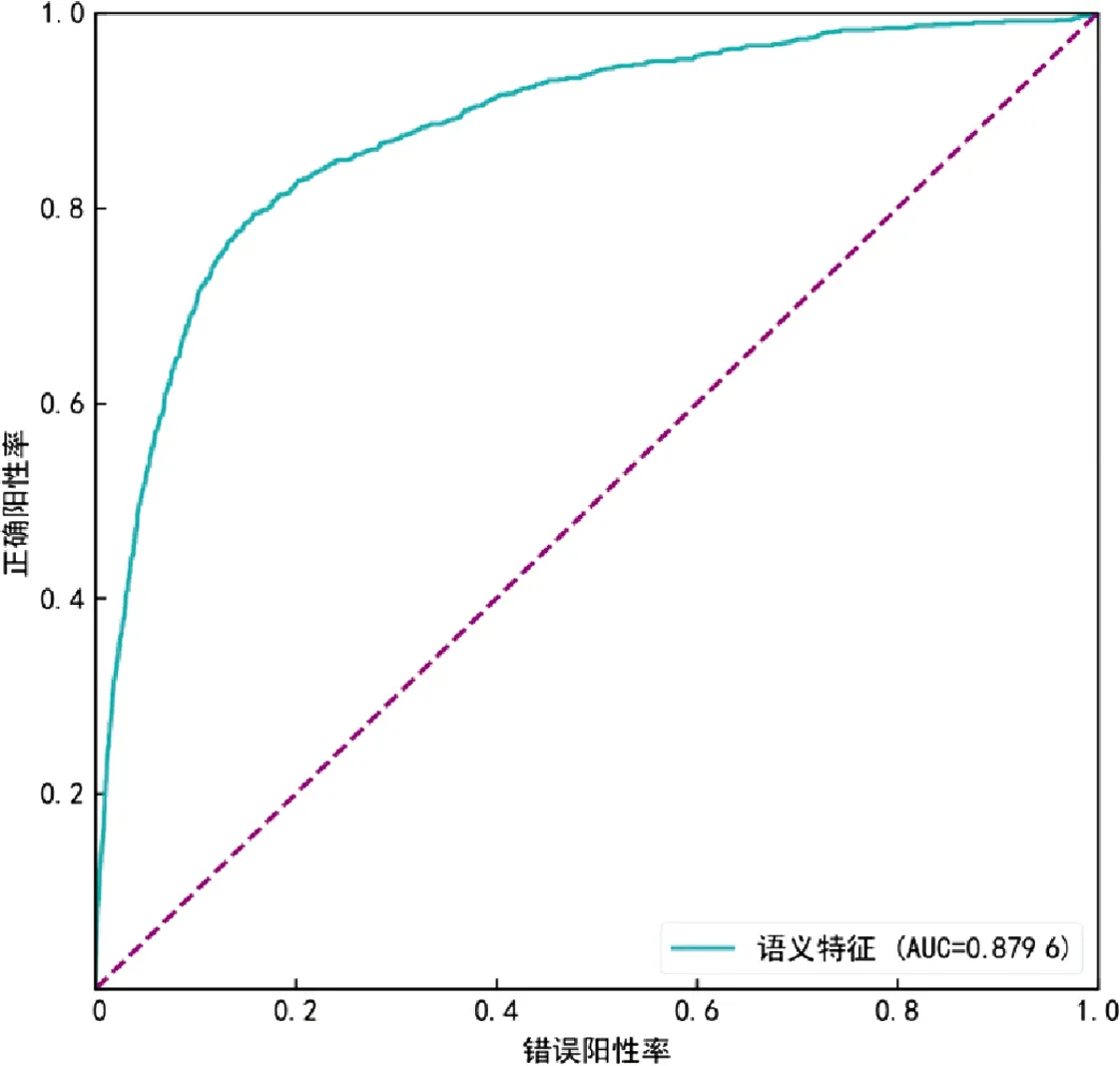
图5 交叉验证的ROC曲线Fig.5 ROC curve of cross validation
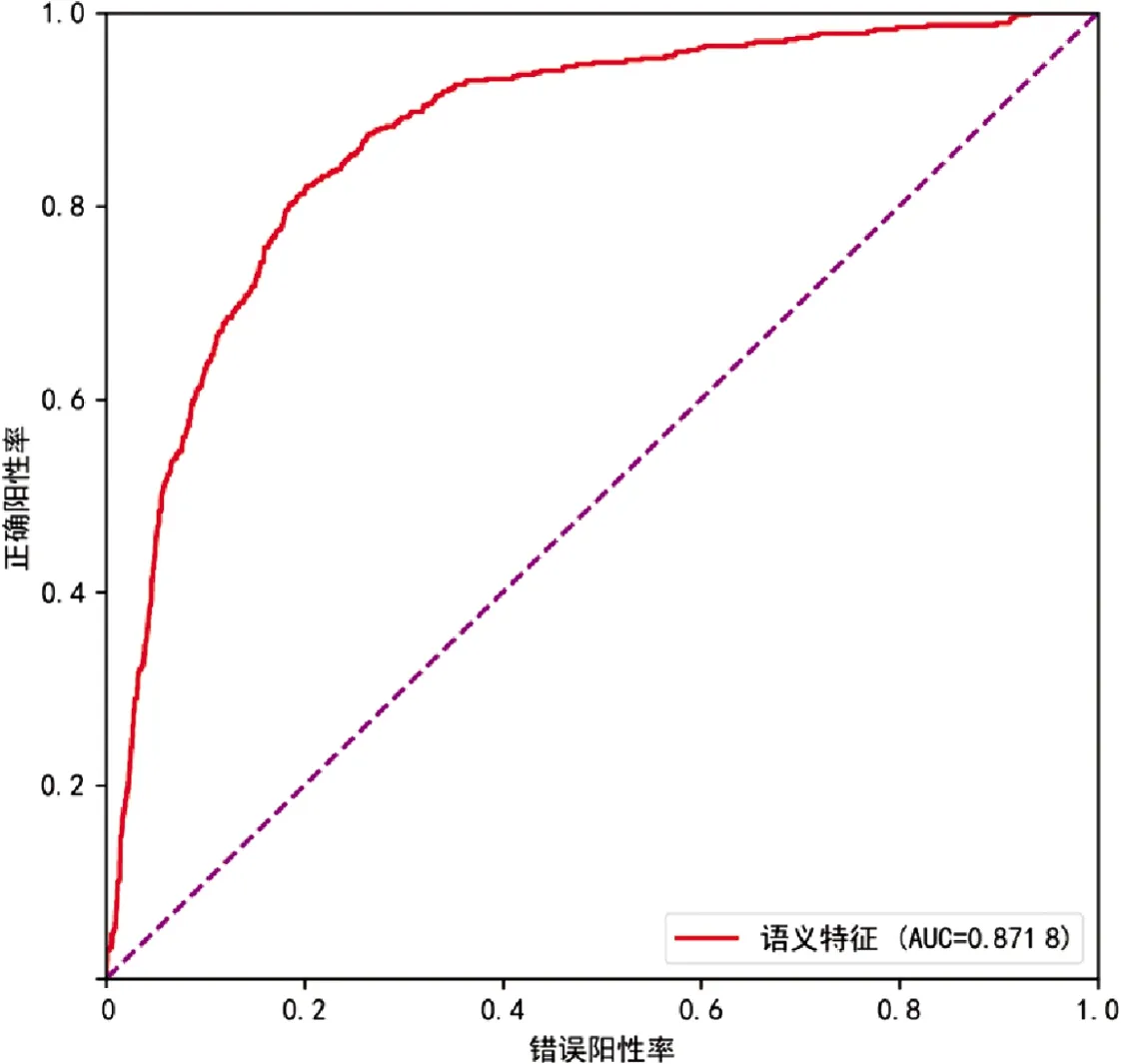
图6 独立测试的ROC曲线Fig.6 ROC curve of independent test
近年来,预测ac4C修饰位点的方法有PACES[6]和XG-ac4C[7]。表2列出了3种方法所有特征的性能比较,所提出的方法在AUC的值上与之前方法相差不大,但是在单个特征对比上,使用的语义特征远超出单个特征的效果,证明了在ac4C修饰的数据中是存在语义的。如果把语义特征与其他特征进行组合,在AUC上一定比之前的方法高。

表2 3种方法的AUC的性能比较Table 2 Comparison of AUC performance by three methods
对于XG-ac4C比较来说,它的各项评估指标都比较好。但是其灵敏度(SN)较低,不能准确分辨出正样本。SFac4C-RF与XG-ac4C方法性能比较见表3。

表3 SFac4C-RF与XG-ac4C方法的性能比较Table 3 Performance comparison between the method in the paper and XG-ac4C
5 结论
N4-乙酰基胞苷(ac4C)在调节mRNA翻译中起到了重要作用,能准确理解RNA的ac4C修饰,有望在发育和疾病中发挥重要的生物学功能。在对ac4C进行深入研究中,提出了一种基于深度学习的特征提取方法,通过长短时记忆网络和卷积神经网络搭建的深度学习模型提取序列中隐藏的语义特征,与使用的传统特征进行对比,语义特征具有更好的性能,有助于更准确识别ac4C的修饰位点。
