川渝地区防漏堵漏智能辅助决策平台研究与应用
2022-01-04邓正强兰太华林阳升何涛黄平罗宇峰王君谢显涛
邓正强 兰太华 林阳升 何涛 黄平 罗宇峰 王君 谢显涛
中国石油集团川庆钻探工程有限公司钻井液技术服务公司
川渝地区是中国石油“十三五”提量上产的主要区块,也是川庆钻探重要的作业区域[1-3]。地质特征及已钻井情况表明川渝地区地层疏松、裂缝发育,钻井过程中漏失严重。地层漏失的随机性、影响因素的多重性、漏失机理的不确定性,使得该区域防漏堵漏效果不佳,一次成功率低,甚至诱发其他井下复杂及事故。井漏造成的经济损失、时间损失居高不下,严重影响着川渝地区勘探开发的进程。因对漏失通道性质认识不清,井漏治理主要以经验为主,部分井需多次调整堵漏配方才堵漏成功,堵漏成功率低。为此引入大数据/人工智能技术赋能钻井工程,对漏失特征、裂缝性质进行大数据诊断,智能化地提高防漏堵漏效果。通过数据挖掘可确定并输出漏层位置、裂缝开度、漏失类型、漏失压力、安全密度窗口、堵漏措施的有效性,并分析各因素对漏失的影响程度、相互关系,得到漏失机理及特性,对漏失进行诊断与预测[4-8]。
1 防漏堵漏智能辅助决策平台组成及原理
在井漏及堵漏领域,裂缝宽度的判断以经验法为主。由于井史数据具有数据量大、噪点较多、数据分散的特点,因此选用神经网络、决策树、随机森林及支持向量机等4种算法对井史数据进行分析,分别计算了4种算法预测漏层位置并进行线性拟合,漏层位置预测值的线性拟合结果如图1所示。4种机器学习模型对训练和测试数据集进行模型性能评估的结果见表1。

图1 4种算法预测漏层位置拟合图Fig. 1 Fitting map of thief zone position predicted by 4 algorithms

表1 各类漏层位置预测模型性能评估Table 1 Performance evaluation of different thief zone position prediction models
从图1可看出,随机森林模型和支持向量机模型在预测漏层位置时收敛性更高,拟合直线斜率更接近正比例函数,并且截距更小。从表1可知,神经网络模型和支持向量机模型在漏层位置预测时具有更高的精确度和匹配度,虽然支持向量机的拟合直线斜率(k=0.974 9)更接近正比例函数,并且截距更接近0(d=33.211),但是根据RMSE指数可以推断出,神经网络模型的稳定性反而高于支持向量机,之所以神经网络模型的拟合直线斜率(k=0.946 7)表现得不如支持向量机模型,只是因为后者更偏向于两边犯错,因此拟合直线比较接近正比例函数。因此最终选择神经网络模型对漏层位置进行预测。
1.1 数据采集
使用Python语言编写小程序从上述平台或电子文档中共采集了240口井、2 796张EXCEL数据表或其他类型数据表、210万条数据、1162个漏点,数据容量大约为2.4 GB。因为有部分井数据项目缺失,按照主要相关数据统计分析,总有效率65.8%。
1.2 数据转换
由于采集到的数据类型各异,包含EXCEL、WORD和其他格式数据文件,数量非常大,本项目使用Python语言开发数据转换软件将每口井对应的数据转换并迁移(导入)到数据库系统中(MYSQL),共形成类型相同的140余万条数据库记录用于后续分析使用。
1.3 数据清洗
上述数据收集并迁移到数据库后,经数据探索分析发现原始数据存在缺失和不一致性,不能直接用于数据挖掘和预测,必须对其进行清洗后才能使用[9-11]。为了消除输入数据之间的相互影响,调用Python中的Pandas模块对钻井数据实施归一化处理,将9个输入参数转化在[−1,1]之间。归一化函数的数学公式为
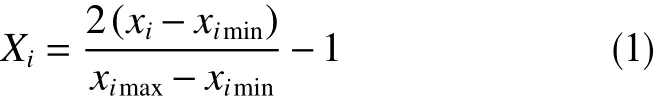
式中,Xi与xi分别代表规范化后和规范化前的数值;ximax和ximin分别表示规范化前最大与最小数值。具体处理的流程如图2所示。

图2 数据规范化流程图Fig. 2 Flow chart of data normalization
1.4 数据参数与井漏的相关性
从一体化平台取得的钻井数据具体包括岩性(YX)、100转读数(DS100)、钻头型号(ZTXH)、井径扩大率(JJKDL)、钻速(ZS)、钻头尺寸(ZTCC)、3转读数(DS3)、当量密度(DLMD)、平均井径(PJJJ)、入口流量(RKLL)、300转读数(DS300)、600转读数(DS600)、转速(ZS1)、钻压(ZY)、漏斗黏度(LDND)、层位(CW)、扭矩(NJ)、入口密度(RKMD)、钻井液类型(ZJJLX)、出口密度(CKMD)、泵压(BY1)、钻井液密度(ZJJMD)等22个参数,加上必定和井漏相关的井深共23个输入参数。其中部分参数包含的井漏信息较少,对井漏的影响微乎其微。将这种参数输入模型不仅会使网络冗余,降低学习速度和效率,甚至还会影响其他输入参数,导致重要参数被淹没[12-14]。因此,寻找与井漏解相关的最佳有效变量集是非常必要的。
采用相关系数法分析相关性。采用IBM公司的数据统计软件SPSS对22个参数与钻井漏失进行相关系数测试,并通过相关系数绝对值的大小确定变量的重要性,以选择建立模型的最佳相关预测因子,结果如图3所示。

图3 数据挖掘模型参数的相关性分析Fig. 3 Correlation analysis on the parameters of data mining model
由图3可以看出,在研究的22个变量中,排除掉2个常数或接近常数的变量(平均井径PJJJ和当量密度DLMD),其余20个变量被确定是预测井漏解的输入参数。这些变量的范围是非常重要的因素,数据挖掘模型输入参数中缺失了任何一种都可能会导致最终产生的井漏解决方案不可靠。
2 数据挖掘模型
以川渝地区240口井的井史详细数据为基础,研究这些数据与井漏之间的关系。首先,利用基于大数据的机器学习技术提取井史数据中的有用信息,并按照一定的规则对这些信息进行特征化处理,进而得到可以进行数据挖掘的数据集合;其次,将此数据集代入相应的机器学习算法中进行学习,生成对应的学习模型;最后,对该学习模型进行评估,看模型准确率是否符合要求,如果不符合则对数据挖掘数据集重新进行特征化处理,如果符合要求则保存该学习模型。具体步骤如图4所示。
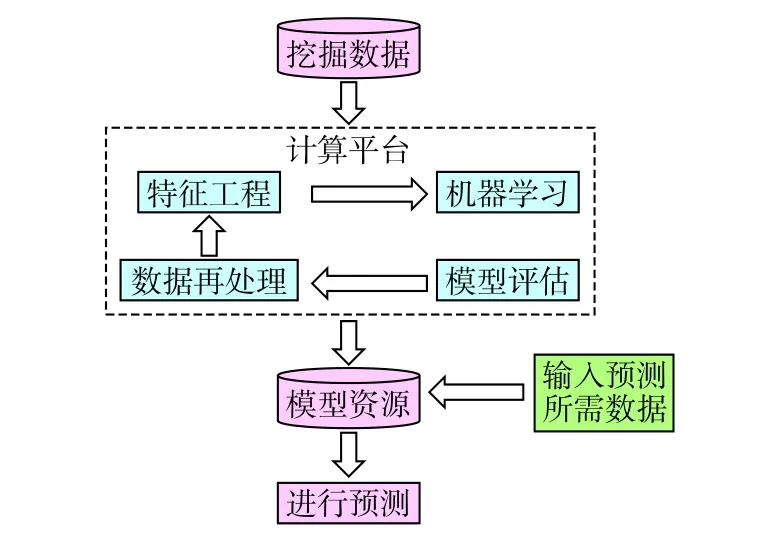
图4 数据挖掘模型构建步骤Fig. 4 Building procedure of data mining model
2.1 文本型参数的数字化处理
数据库中存在很多以汉字或英文描述的信息,如岩性、层位、钻头类型、钻井液类型等,这类文字信息无法直接进行数据挖掘,需要进一步处理将其数字化。由于类别之间是无序的,不能采用自然序数编码,为了解决此类问题,采用了独热编码(One-Hot Encoding)技术[15-17]。其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有其独立的寄存器位,并且在任意时候,其中只有一位有效。经过独热编码后,无序的汉字或英文信息转化为有序的数字,为数据挖掘奠定了基础。
2.2 相似井段聚类
如果能通过区块井史数据分析,将漏前相关参数(如钻压、岩性等)发生了类似变化的井漏倾向相似井段都归并到相同类别中,那么会对同一类井段的井漏倾向风险预测预警提供很好的判据。所以,数据挖掘领域中的聚类分析对于防漏堵漏辅助决策的智能推荐服务具有重要意义[18-20]。文本型参数经数字化处理后,进一步采用K-mean算法对相似井段进行聚类分析。
2.3 改进Apriori关联规则挖掘
经过聚类分析后,有相似井漏倾向的井段被归并到一个类别中,这个井段类别所关联的井漏倾向也就成为提供智能预测预警的初始依据。即,某一井段如果有相关参数发生了类似的变化,则这一井段就有很大可能发生和类内井段相同的井漏倾向事件,但这需要进一步利用关联规则数据挖掘算法去实现。
Apriori算法是关联规则挖掘的常用方法,但其形成的关联规则很多是冗余的,并且需要执行的扫描次数也比较多。为此,在传统的Apriori算法的基础上进行了改进,流程如图5所示。
图5 关联规则改进算法Fig. 5 Improved association rules algorithm
3 防漏堵漏智能辅助决策平台构建及应用
3.1 平台构建
依据上文提出的聚类分析、关联规则挖掘等数据挖掘算法,调用数据库数据,构建了防漏堵漏智能辅助决策平台。其功能模块包括:控制台模块、权限管理模块、数据导入模块、数据预处理模块、井漏风险预测模块及漏层位置预测模块。
防漏堵漏智能辅助决策平台可以在用户登录之后针对平台内不同区块的钻井数据进行检索查看服务,并提供部分数据统计功能,帮助工程师更加直观地看到钻井数据中的可用信息。智能决策平台可以与一体化平台实现跨平台连接,既可以根据用户设置自动导入实时钻井数据,也可以手动导入一些平台以外的新数据。
防漏堵漏智能辅助决策平台提供了包括神经网络、K近邻、随机森林在内的多种数据挖掘算法,用户既可以根据区块规律、算法特征来自行选择,也可以通过平台推荐来选择最优模型。
3.2 现场应用
使用软件对已完钻井和正钻井进行堵漏方案推送验证,结果见表2、表3,其中符合率指软件推送的配方与实际堵漏配方的匹配程度。
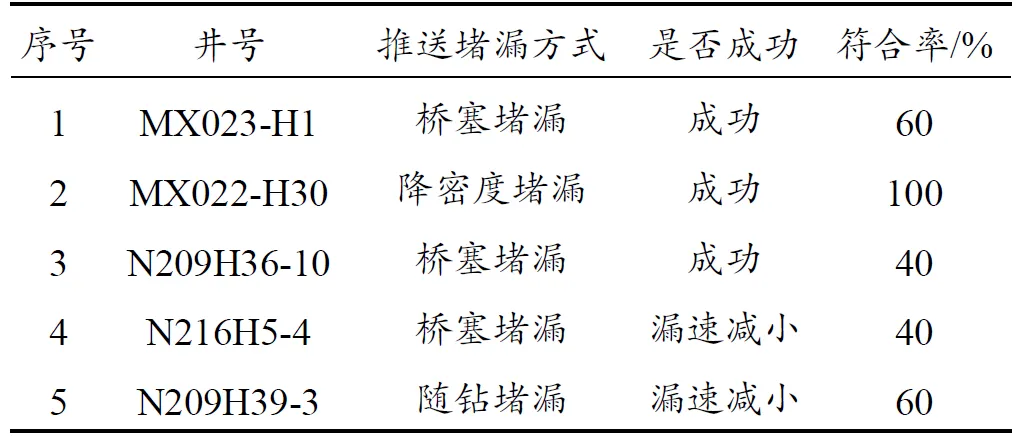
表2 已完钻井进行堵漏方案推送验证Table 2 Recommendation and verification of lost circulation control scheme of drilled well

表3 正钻井进行堵漏方案推送验证Table 3 Recommendation and verification of lost circulation control scheme of being drilled well
以MX023-H1井为例。该井邻井用密度2.17~2.24 g/cm3钻井液在峨眉山玄武岩段精细控压钻进,多次出现气侵、井漏,累计漏失钻井液189 m3。本井用密度2.35 g/cm3钻井液钻至峨眉山玄武岩前,软件提示本井此段发生漏失概率为80%,应做好相应预防措施。
MX023-H1井00:33取心钻进至5 354.38 m见井漏,漏失钻井液0.2 m3;至00:52割心上提钻具至5 345.27 m,循环观察,泵压13.6~19.8 MPa、排量320 L/min,实测最大漏速9.0 m3/h、最小漏速3.0 m3/h、平均漏速6.0 m3/h,漏失钻井液2.5 m3;至07:00降排量循环,泵压3.2~11.8 MPa、排量58~219 L/min,漏失3.7 m3;至07:20提排量循环,泵压13.6~19.8 MPa、排量180~270 L/min (排量234 L/min时漏速9.0 m3/h、排量156 L/min时漏速6.0 m3/h)漏失钻井液3.0 m3;至08:00降排量循环,泵压6.5 MPa、排量78 L/min,漏失1.3 m3。MX023-H1井发生漏失时,根据现场漏失实时参数,软件推送出堵漏方式及堵漏配方供现场参考。
软件推荐堵漏方案:采用桥塞堵漏方式,配制密度2.05 g/cm3、浓度15%的堵漏浆20 m3,配方:3%~6%随堵+6%~10%刚性粒子+5%~8%片状材料+5%~8%桥塞材料;现场施工人员参考软件给出的堵漏配方确定实际堵漏配方:3%随钻+7%刚性粒子+4%片状材料+4%桥塞材料,符合率60%。
从表2、3可知,对已完钻井进行堵漏方案推送验证符合率达60%,对正钻井进行堵漏方案推送符合率50%,其中N209H36-10、N216H5-4井符合率低于50%的主要原因是数据库内容不够丰富,随着学习样本的增加,符合率会逐步提高。该软件在页岩气、高磨区块累计现场试验17井次,一次堵漏成功率达52.9%,较未使用软件时的一次堵漏成功率39.1%提高了13.8个百分点,现场应用效果良好。
4 结论
(1)基于大数据构建的防漏堵漏智能辅助决策平台推送的堵漏方案对实际堵漏方案制定具有一定的指导性,可提高一次堵漏成功率百分比。
(2)神经网络、决策树、.随机森林、支持向量机4种算法中,选择神经网络模型对漏层位置进行预测,稳定性最好。
(3)智能防漏堵漏辅助决策平台先采用聚类分析方法对样本数据进行聚类,再通过关联分析的方法分析聚类簇中样本的因素,实现了聚类+关联规则预测井漏风险及堵漏方案推送。
