基于粒子群优化和长短期记忆神经网络的气井生产动态预测
2022-01-04薛亮顾少华王嘉宝刘月田涂彬
薛亮 顾少华 王嘉宝 刘月田 涂彬
1. 中国石油大学 ( 北京 ) 石油工程学院;2. 中国石油化工股份有限公司石油勘探开发研究院
0 引言
气井生产动态分析是油藏工程研究的主要内容之一,是气井产量规划、开发方案编制及生产制度动态调整的重要依据,对于认识油藏、改造油藏,科学开发气藏具有重要的指导意义。目前主要有3种产能评价方法:第1种是基于统计分析的典型曲线方法[1],例如 Arps 产量递减分析方法,该类方法一般通过统计分析油气井生产数据得到,简单明了,但一般都建立在一定的假设条件上,适用条件苛刻,且不能考虑到开发后期生产情况的变化,具有一定局限性[2];第2种是基于流体渗流原理的数值解析方法,这种方法将实际油藏转化为物理模型,再转化为数学模型并对模型进行求解,数值解析方法一般适用于模型较为简单的油气藏;第3种是数值模拟方法,数值模拟方法依靠计算机的运算能力来模拟油气藏的实际生产情况和流体渗流规律,这需要地层资料、岩石流体资料、生产动态资料等来建立地质模型、数值模型并进行历史匹配等工作。如果想要得到一个符合实际生产情况的数值模拟结果,就需要建立一个精确的数值模型,但精确的数值模型往往是十分复杂的,建立模型耗费时间长,工作量大。
目前实际工程应用中最常使用的是油藏数值模拟方法和典型曲线方法[3-4],但复杂的气水井产量变化以及现场生产措施的调整,使得目前的常规方法难以精准描述产量变化。近年来,机器学习理论得到了迅速发展,出现了许多种新的机器学习算法,包括BP神经网络、循环神经网络、支持向量机、自回归模型等算法,并且在搜索技术、机器翻译、自然语言处理、图形识别等各个技术领域取得了很大的进展,也逐渐受到了石油领域的关注。机器学习方法由于其能够很好地处理非线性问题,通过对数据进行深度学习,捕捉生产数据与产量之间的隐藏规律,能够克服常规生产动态分析方法的缺点,依靠现场易获得的油气生产动态数据实现产量的准确预测,与传统方法相比预测结果更加可靠。
目前,许多学者通过使用BP神经网络方法实现油气产量的预测[5-7],此外,诸多学者也采用了支持向量机(SVM)、自回归模型(AR)和滑动平均自回归模型(ARIMA)等算法[8-10]来预测油气产量,且都得到了较为准确的预测结果,说明了此类基于机器学习的产量预测方法具有可行性。但应用这些方法处理数据时,都是对某个时间点产量的计算,没有充分考虑到各时间点产量的前后关系及变化趋势。基于油气产量具有时间序列的关系,且近几年发展的长短期记忆神经网络(LSTM)可以很好地处理时间序列数据的前后关系,提出使用长短期记忆神经网络模型对天然气藏产量进行预测。长短期记忆神经网络(LSTM)是基于循环神经网络(RNN)改进而来的[11],它具有自循环的网络结构,将上一时间步的信息传递至当前时间步,并通过LSTM的输入门、输出门和遗忘门来控制信息的输入输出以及哪些不重要的信息将被遗忘,以保持神经网络在较长时间内具有对数据的记忆功能。长短期记忆神经网络不仅可以考虑相关因素对产量的影响,还能反映出产量数据的变化趋势,预测精度高,更适用于油气产量时序预测。粒子群算法具有全局寻优能力强、收敛速度快的特点,使用粒子群算法对LSTM模型超参数进行优化,既能够提高模型预测精度,也可以避免繁琐的、专业性强的模型调参过程,便于现场工作人员使用。
1 原理与方法
1.1 循环神经网络(RNN)
循环神经网络(RNN)是长短期记忆神经网络的基础。传统的神经网络只能对输入和输出构建直接的映射关系,而循环神经网络在每个循环神经网络隐藏层单元中可以将上一步计算的状态信息加入到当前时间步的运算中,使得神经网络可以保留先前时间步的信息,即具有记忆能力。其中循环神经网络结构如图1所示。图1中,xt为t时刻的输入数据;ht为t时刻包含隐藏层状态信息的数据;yt为t时刻的输出数据;W、V、U分别为各层权重参数。与传统的人工神经网络相比,循环神经网络在计算过程中共享相同的权重参数,极大地减少了需要学习的网络参数。在前向传播过程中,t时刻隐含层的状态信息为

图1 循环神经网络结构Fig. 1 Structure of recurrent neural network


输出层的输出值为式中,W、V、U分别为RNN输入层、隐藏层和输出层的权重参数;b、c为RNN隐藏层和输出层的偏置项;f为激活函数,一般采用tanh函数或Relu函数。
循环神经网络的权值更新采用随时间反向传播(Back-propagation through time, BPTT)的方法,基于梯度下降法,沿着权值的负梯度方向不断寻优直至收敛。在循环神经网络中,在误差的反向传播计算过程中会出现早期时间步的梯度消失或者梯度爆炸现象,即循环神经网络对较早时期的数据无法学习,导致预测误差增大[12],使其不适用于处理长时间的序列数据。在建立气藏产量预测模型时,输入数据往往是数年,甚至数十年的每日生产数据,大量数据点的输入使得循环神经网络不适用于气藏的产量预测问题。
1.2 长短期记忆神经网络(LSTM)
为了解决循环神经网络的梯度问题,有学者提出了RNN的改进结构——长短期记忆神经网络(LSTM),它是循环神经网络的一种变体,能够解决RNN的梯度问题。与RNN相比,LSTM在神经网络结构中引入了记忆单元和控制神经网络隐藏层之间信息传递的控制门,其网络结构见图2。

图2 长短期记忆神经网络结构Fig. 2 Structure of LSTM
在LSTM的神经网络隐藏层中,加入了输入门、输出门和遗忘门以控制记忆单元,t时刻时,首先通过输入门输入数据xt和上一时间步输出数据ht-1计算记忆单元遗忘门的值,输出一个0~1之间的值传递给单元状态信息Ct−1,确定前期单元状态Ct−1应该丢弃哪些信息(0表示完全舍弃,1表示完全保留)

更新输入信息it和候选单元状态

式中,ft为t时间步时的遗忘门信息;σ为sigmoid函数;it为t时间 步时 的 输 入 信 息;Wf、Uf为LSTM遗忘门的权重参数;bf为LSTM遗忘门的偏置项;Wi、Ui为LSTM输入门的权重参数;bi为LSTM输入门的偏置项;Wc、Uc为LSTM单元状态的权重参数;bc为LSTM单元状态的偏置项;为t时间步时的候选单元状态。
此时,根据更新得到的候选单元状态和上一时间步的单元状态Ct−1, 更新得到t时间步的单元状态Ct

最后在输出门中使用输出门ot输出单元状态Ct和输出数据ht
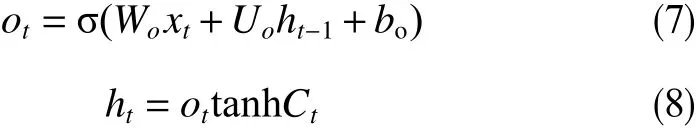
式中,Ct为t时间步时的单元状态;Wo、Uo为LSTM输出门的权重参数;bo为LSTM输出门的偏置项;ot为输出门信息; tanh为双曲正切函数。
图2中,σ为输入门、输出门和遗忘门3个门的主动函数,是变量在0~1之间的sigmoid函数。激活函数tanh是将值压缩在−1~1之间的双曲正切函数。利用这两个激活函数来增强网络的非线性


根据长短期记忆神经网络的运算结构,采用LSTM神经网络对时间序列数据进行学习并捕获、提取数据特征,可以得到更加精准的预测模型。
1.3 粒子群优化算法(PSO)
构建基于长短期记忆神经网络的产量预测模型时,模型超参数对产量预测的准确性有很大的影响,超参数影响着产量预测模型准确性和模型训练时的收敛速度,需要避免模型训练时陷入局部最优解。粒子群优化算法具有良好的自我学习能力,对最优参数的全局搜索能力很强,因此在建立预测模型时,使用粒子群算法对长短期记忆神经网络算法模型的超参数进行优选。
粒子群算法是由Kennedy和Eberhart提出的启发式优化算法,该算法通过模仿鸟群的觅食过程寻找最优解。在粒子群优化过程中,通过个体极值和群体极值更新粒子本身的位置和速度,粒子位置记为,个体极值即为单个粒子在自身移动轨迹中误差最小时所处位置,记为,群体极值即为所有粒子在移动轨迹中误差最小时某一个粒子的所处位置,记为g*。迭代更新粒子自身的更新速度和更新位置

通过迭代更新粒子位置,直到达到最小误差标准或达到粒子更新的最大迭代次数为止。
2 建立生产动态分析模型
在气藏开采中,随着地层压力的不断下降,气藏物性和驱动能量逐渐发生变化,从而使得气井开发方式也随之改变,因此,根据气井生产阶段分别设计气井稳产期生产动态预测模型和气井递减期生产动态预测模型,采用python进行代码编写。根据气井油压自动识别气井生产阶段,并应用相应的生产动态预测模型。
根据国内气井实际生产情况,气井在稳产期时一般采用配产降压方式进行开发,因此选择天然气累计产量的时间序列数据为LSTM神经网络的输入数据,预测未来井底压力随天然气累计产量的变化规律;气井在递减期时一般采取定压降产方式进行开发,气井日产量的主控因素是自身的递减趋势,因此以气井日产量的时间序列数据预测未来气井日产量数据。
2.1 数据预处理
气井生产过程中往往会由于各种因素而使得气井的产量、压力等动态参数数值产生震荡波动,所以需要对原始数据进行处理以去除数据的噪音影响。
首先采用Savitzky-Golay滤波器对数据进行处理,Savitzky-Golay滤波器(通常简称为S-G滤波器)最初由Savitzky和Golay于1964年提出,之后被广泛运用于数据流平滑除噪,是一种在时域内基于多项式最小二乘法拟合的滤波方法。这种滤波器的最大特点在于滤除噪声的同时可以确保信号的形状、宽度不变。
S-G滤波器基本公式为

式中,Yi、分别为原始数据、平滑后数值;Ci为SG多项式拟合系数;N为滤波器长度,取值2m+1。
将需要预测的目标参数和其他相关参数的生产历史数据进行归一化处理。归一化是一种无量纲处理手段,使物理系统数值的绝对值变成某种相对值关系。归一化是简化计算、缩小量值的有效办法,其实质是一种线性变换。线性变换有很多良好的性质,这些性质决定了对数据转换后不会造成“失效”,反而能提高数据在模型中的预测效果。
归一化的作用有以下几点:(1)把数据映射到0~1范围之内处理,可以使数据处理更加便捷快速;(2)把有量纲表达式变成无量纲表达式,便于不同单位或量级的指标能够进行比较和加权计算;(3)避免太大的数在计算中引发数值问题。
归一化的计算公式如下

式中,xnew为归一化后的数值;xold为原始数值;xmin为数据最小值;xmax为数据最大值。
将归一化的生产数据转化为序列数据,也就是将生产数据转化为多个短时间序列的历史生产数据和对应的已知目标值,每一个短时间序列数据即一个样本,每个样本内包含的时间步的数量即时间窗口的长度,最后转换为三维矩阵(样本数×时间窗口×特征数量)作为长短期记忆深度神经网络模型的输入参数,并利用长短期记忆深度神经网络算法计算得到需要预测的生产动态数据。


式中,Y(t)为第t个时间步需要预测的生产动态数据;X(t)为第t个时间步的生产控制参数;n为时间窗口长度,即每个样本包含的时间步数量。
2.2 长短期记忆神经网络模型的训练和优化
将预处理好的数据分为两部分,前70%的数据用作训练集,对模型进行训练;之后10%的数据用作测试集,在测试集上对模型进行测试,验证模型的效果并根据测试结果优化模型;最后20%的数据作为模型预测集。在完成模型训练后,根据模型训练集上的拟合效果和模型在测试集上的预测误差,使用粒子群算法优化时间窗口长度和长短期记忆网络层的神经元数量,最后将训练并优化好的模型应用在预测集,对未来生产动态进行预测。
设置粒子群算法的适应度函数为预测值与实际值的均方根误差,将搜索维度设置为4,4个维度分别为时间窗口长度、第1层长短期记忆网络层的神经元数量、第2层长短期记忆网络层的神经元数量和长短期记忆神经网络模型的迭代次数,根据粒子群计算公式不断迭代寻优,可以使该点所对应的损失函数不断变小,在粒子群的搜索空间内损失函数达到最小值,这样便同时得到了最优长短期记忆深度学习模型超参数,其所对应的LSTM神经网络,即为训练得到的最优生产动态分析模型。
2.3 长短期记忆神经网络模型的循环预测
生产动态分析模型是利用历史生产动态来预测未来某个或某段时期的气层压力或日产油数据。预测时由于t时间步后面的日产油量未知,因此,后面每预测一个时间步,需要将该时间步的预测值Y(t)更新加入到下一个时间步的预测模型输入数据,使用预测值Y(t)去预测下一时刻的值Y(t+1),实现对后续产量的预测。
2.4 模型评估标准
为了验证模型的可靠性,使用平均绝对百分比误差e1、 平均绝对误差e2和 均方根误差e3评价模型。平均绝对百分比误差以百分比的方式表示误差,平均绝对误差则给出预测值与实际值的平均差值,均方根误差表示误差结果的稳定性,均方根误差越小表示模型性能越好,其计算方法如下。

式 中,yi,yˆi分别为第i个实际值和预测值。
3 应用实例
3.1 1号井生产动态分析
1号井目前油压12 MPa,处于稳产期,气井采用配产降压的方式开发,因此采用稳产期产量预测模型,通过预测未来井底压力随天然气累计产量的变化规律来指导未来生产措施调整。采用2010年3月24日—2020年3月31日未关井有效数据输入模型,其中2018年2月10日—5月30日数据作为训练集和测试集,2018年5月31日—2020年3月31日数据作为预测集进行未来生产动态预测。
采用未经粒子群优化时的模型预测效果和经过粒子群优化时的模型预测效果如图3所示,虚线左侧为训练段和测试段,虚线右侧为预测段。
从图3(a)中可看出,采用未经粒子群优化时的模型在预测段拟合效果不佳,预测值普遍低于实际值,模型在预测段的预测误差随着累计产量的增加慢慢扩大,预测效果较差。模型超参数未经粒子群优化时,超参数主要依靠经验选择,而依靠经验选择的超参数很难直接适用于模型,往往需要繁琐的调参过程。经过粒子群优化后,选择时间窗口大小为10个时间步,第1层LSTM神经网络神经元数量为11,第2层LSTM神经网络神经元数量为10,LSTM模型迭代次数为83。从图3(b)中可看出经过粒子群优化的模型预测效果良好。

图3 粒子群优化前后的1号井模型预测结果对比Fig. 3 Comparison of prediction result of No.1 well model before and after particle swarm optimization
对模型在预测集上的预测结果进行了进一步分析。图4为2种预测模型预测值偏离实际值的分布情况,可以看出,经过粒子群优化后的模型预测值更加接近斜率为1的直线,说明预测值更加接近实际值,而未经过粒子群优化后的模型预测值更加偏离实际值,预测效果较差。
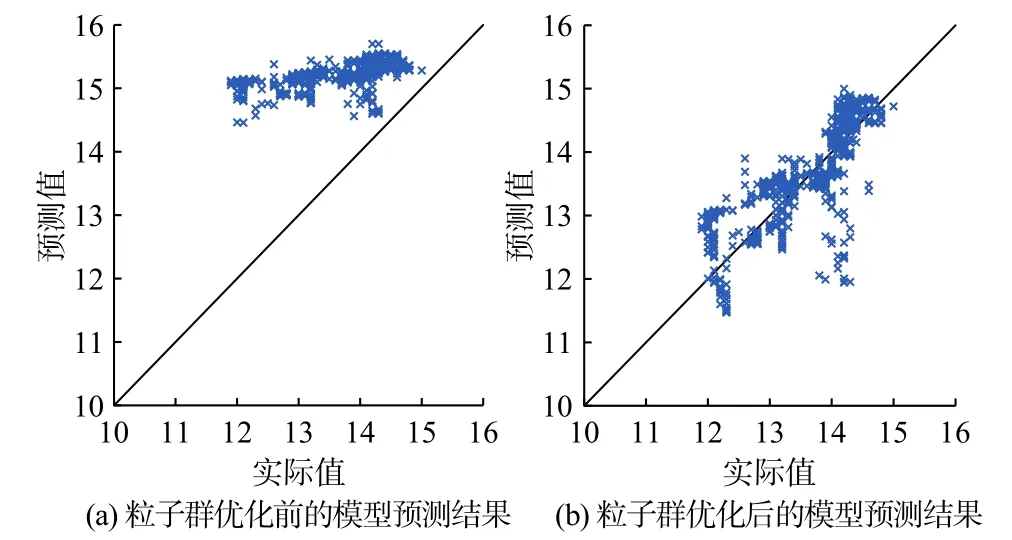
图4 模型预测值和实际值的偏离情况Fig. 4 Deviation of model prediction from actual value
可以观察到计算模型在预测集上的预测结果与实际值的均方根误差、平均绝对误差和平均绝对百分比误差在粒子群优化后都发生下降,均方根误差从1.72256降至0.52508,平均绝对误差从1.56841降至0.38646,平均绝对百分比误差从11.857%降至2.911%。研究认为,经过粒子群优化的LSTM模型预测效果更好,且能很好地预测未来生产动态。
3.2 2号井生产动态分析
2号井目前油压8.3 MPa,处于递减期,气井采用定压降产的方式开发,因此采用递减期产量预测模型,预测未来日产气量随生产时间的变化规律,以指导未来生产措施调整。采用2017年8月31日—2019年5月12日中的未关井的有效数据作为输入数据,其中2017年8月31日—2018年10月18日的数据作为训练集和测试集,训练并优化模型,2018年10月19日—2019年5月12日的数据作为预测集对气井未来生产动态进行预测。
采用未经粒子群优化的模型预测效果和经过粒子群优化的模型预测效果如图5所示,虚线左侧为训练段和测试段,虚线右侧为预测段。

图5 粒子群优化前后的2号井模型预测结果对比Fig. 5 Comparison of prediction result of No.2 well model before and after particle swarm optimization
从图5可以看出,应用未经粒子群优化时的模型在训练集拟合效果较好,但在预测段预测效果较差,说明模型的泛化能力较弱,而采用经过粒子群优化的模型预测值更贴合实际值。经过粒子群优化后,优化的时间窗大小为4个时间步,第1层LSTM神经网络神经元数量为6,第2层LSTM神经网络神经元数量为3,LSTM模型迭代次数为272次。可以发现优化的参数值除迭代次数外都相对较小,且从图5中可以看到模型的预测值在训练集和测试集上的极值点表现较差,分析数据后得出结论,由于2号井已进入见水期,气井见水后产量波动较大,使模型很难预测到精确的产气量,而粒子群优化后选择的较小的超参数,降低了模型的复杂程度,可以使预测模型具有更好的泛化能力,从而使预测效果在整体上表现更加良好。
计算在预测集上实际值与预测值的均方根误差、平均绝对误差和平均绝对百分比误差后发现,由于2号井见水后产量波动较大,数据的不稳定程度大幅度增加,导致误差增大,但在粒子群优化后,均方根误差从2.12160降至1.14898,平均绝对误差从1.76625降至0.77692,平均绝对百分比误差从21.153%降至9.425%。分析两种条件下在预测段的误差大小,可以明显观察到经过粒子群优化后的LSTM模型预测效果更好,且能够很好地预测未来生产动态。
4 结论
(1)将机器学习中的长短期记忆神经网络应用到生产动态分析中,并采用粒子群算法优化神经网络,实现了对气井生产动态的准确预测。
(2)使用粒子群优化算法对建立的长短期记忆神经网络模型进行优化,实现了神经网络超参数的自动优化,避免了常规神经网络繁琐的调参过程,大幅度简化了预测模型的优化过程,操作简单,便于实现自动化和现场人员使用。
(3)实例应用说明,建立的产量预测模型可以精准地预测未来生产动态变化,平均绝对百分比误差小于10%,预测精度符合现场要求。
