基于深度学习的轮廓检测模型的交互式解码网络
2022-01-01乔亚坤林川张贞光
乔亚坤 林川 张贞光




摘 要:基于深度学习的轮廓检测模型通常由编码和解码2个部分组成,其中编码部分负责提取、分离图像特征,解码部分则解析、表征图像特征。为了尽可能利用每一个卷积层的信息,设计了一种高性能轮廓检测模型。首先,将编码网络的输出分为2组进行逐级解码;然后引入交互式连接,2组网络分别互换部分卷积层进行特征交互以获取更多的特征信息;最后,2组网络的输出传入加法层进行融合得到最终输出。在BSDS500和NYUD-v2数据集上对该神经网络模型进行实验,结果与近几年的研究相比,有着显著的提升。通过消融实验进一步证明,采用交互式解码方法的F值(ODS)由0.816提升至0.819,提高了0.003。
关键词:轮廓检测;深度学习;逐级解码;交互式连接
中图分类号:TP391.41 DOI:10.16375/j.cnki.cn45-1395/t.2022.01.008
0 引言
轮廓检测任务的目的是针对图像进行像素级的区分,常作为高级视觉任务的预处理步骤(如目标生成[1]、物体着色[2]、多目标跟踪[3-4]等),在多媒体处理中得到广泛应用。由于目标纹理和边缘等噪声信息难以区分,因此,针对自然图像的轮廓提取工作一直是一项具有挑战性的任务。近年来,随着深度学习技术的快速发展,轮廓检测模型的性能也随之得到一定的提升。
虽然之前一些优异的轮廓检测模型[5-8]在BSDS500数据集[9]上取得了较好的结果,但仍然存在2个问题:第一,未利用编码网络中每一个卷积层的特征。在卷积神经网络中,每一个卷积层之后都会采用激活函数进行作用,以保证参数的非线性变化,使得不同的卷积层具有不同的图像特征。因此,仅仅利用其中几层必然会丢失一部分重要信息。第二,解码方式过于单一。传统方法大多采用上采样处理底层信息,然后与上层信息进行融合,反复进行此操作,直到恢复图像的原分辨率。针对这些问题,本文提出了一个可靠的轮廓检测模型,有效地利用了编码中的大多数特征信息,并且采用交互式双解码网络准确地预测局部和尖锐的目标 边界。
最初的轮廓检测模型大多基于局部像素值梯度的变化方向以确定目标边界位置。这是一种普适性方法,可以有效地检测目标/非目标的全部边界信息,但是这种方法并没有考虑哪些像素是真正的轮廓。后来,模拟生物视觉的数学模型开始被应用于轮廓检测任务。研究者根据生物视网膜细胞的工作机制建立模型,如Grigorescu等[10]提出采用Gabor、DOG函数分别模拟细胞经典感受野和非经典感受野,二者形成中心增强、周围抑制的同心圆模型。Zeng等[11]则认为非经典感受野的抑制作用并非处处相等,他们提出一种蝶形非经典感受野模型[11],即根据非经典感受野与中心的不同距离而产生不同的抑制作用,同时他们认为与中心点方向在同一水平线上的点的作用效果最明显,而垂直的点对其没有任何影响。
近几年,深度学习算法开始应用于各类计算机视觉任务中。研究者发现,卷积神经网络(convolutional neural networks,CNNs)在轮廓检测任务上表现出优异的性能。CNNs模型通常分为编码和解码2个部分,编码网络采用多卷积层构建深度模型以获取图像特征,解码网络则对编码中提取的特征信息进行融合、解析来获取所需的任务对象[12]。Xie等[5]提出了端到端的整体嵌套边缘检测算法(HED),采用VGG-Net作为预训练模型进行迁移学习以提高模型的收敛速度和准确率。在此基础上,Liu等[6]权衡了网络性能与运算速度,提出RCF-Net。RCF采用与HED一樣的解码方式,不同的是RCF在编码网络中做了两方面改进:①针对每一个卷积层截取部分特征通道进行解码;②采用空洞卷积替代传统卷积。RCF模型的改进同时兼顾了性能与效率,具有很好的实用意义。Wang等[7]提出逐级融合进行解码的CED模型,并采用亚像素卷积代替双线性邻近插值,对目标的弱边缘有更好的保护作用。Lin等[8]认为解码网络的拓宽可以提取更丰富的特征,提出横向精细网络LRC模型,LRC对特征的解析更加细腻,采用逐级融合的方式对不同感受野提取的特征进行融合,从而获得优异的性能。
本文受LRC模型启发,提出了交互式邻近 解码方法(interactive proximity decoding network,IPD-Net)。首先,受RCF影响,IPD利用了编码网络中所有卷积层截取之后的特征信息,一方面保证了特征的完整性,另一方面兼顾了模型的速度;其次,IPD将编码输出分为2组进行交互式解码,保证了更多特征信息被整个网络所共享,从而获取更加精细的轮廓特征。
1 模型设计
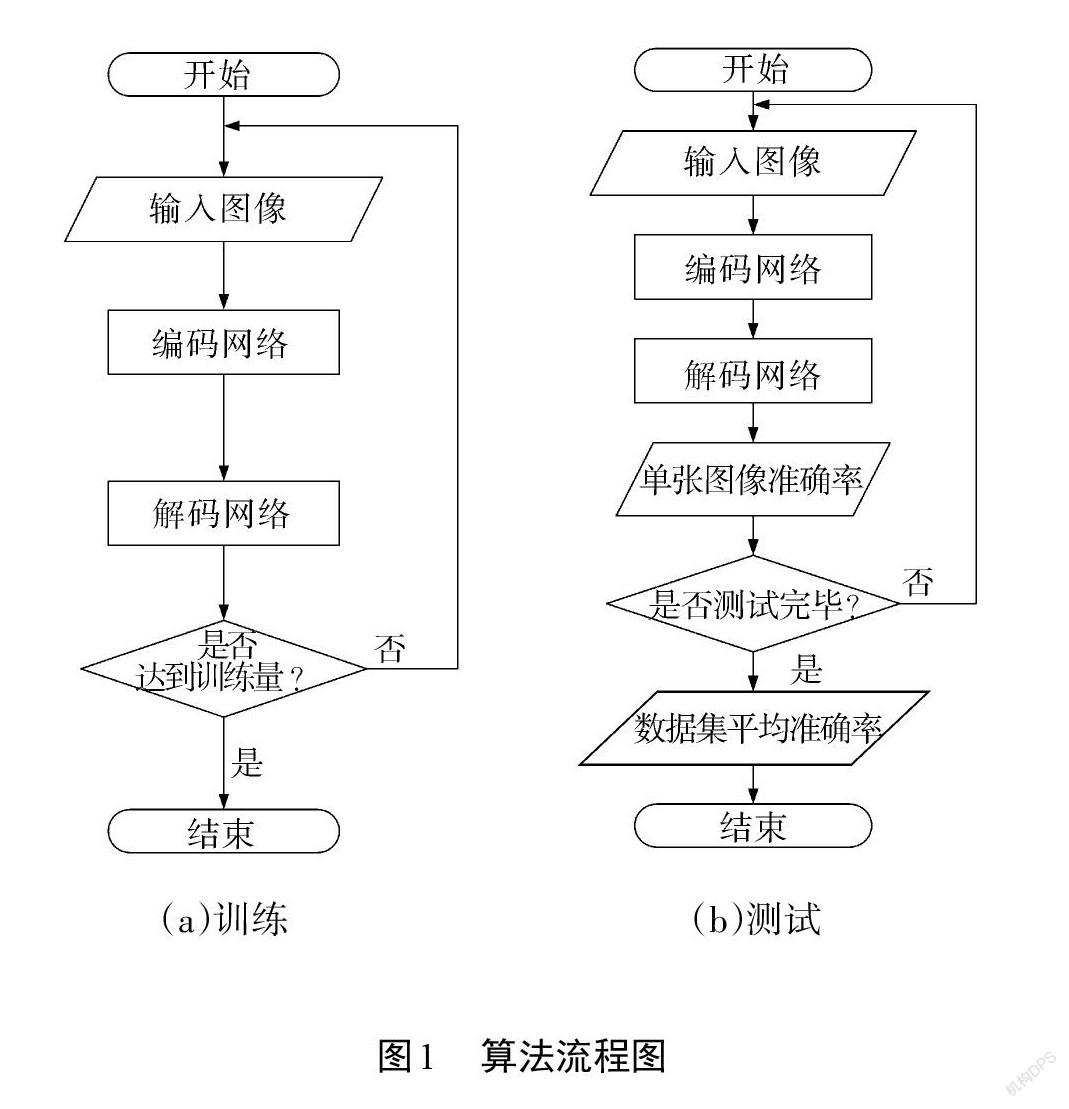
IPD-Net主要采用深度学习神经网络技术进行轮廓提取。本文算法流程如图1所示。深度学习分为训练和测试2个部分,其中IPD-Net模型的训练部分如图1(a)所示,依据预设的训练量完成整个数据集的训练任务。而测试部分如图1(b)所示。与训练不同,测试部分对每一张图像都进行准确率预估, 再采用算术平均法对整个数据集的性能进行评价。
1.1 网络架构
编码网络:受以往深度学习文献的启发,本文将修改后的VGG16网络[13]作为编码网络。VGG16网络由13个卷积层和3个全连接层组成,在图像分类、目标检测等各种任务上都取得了最先进的水平。其卷积层可分为5个阶段,每个阶段后连接一个池化层用作感受野的增大,使卷积层逐渐对全局特征进行捕获。
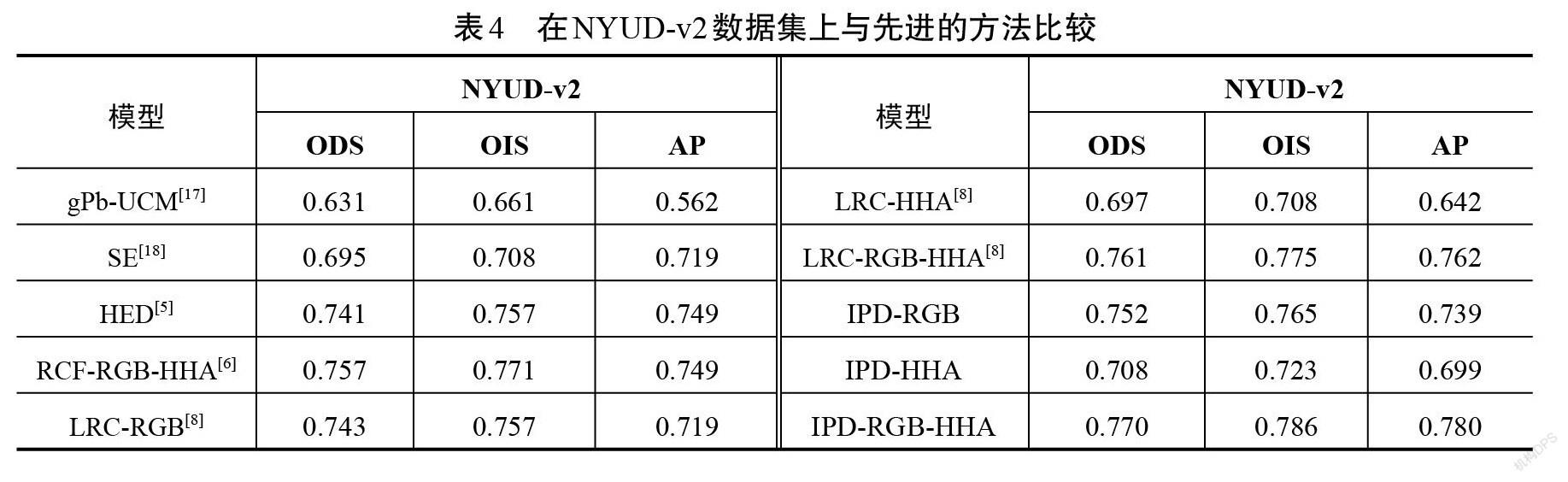
本文提出的IPD-Net如图2所示。与VGG16相比做出了如下修改:
①裁掉了所有的全连接层和最后的池化层。一方面是因为其不符合本文的全卷积理念,并且全连接层的网络参数复杂、计算量大,在基于二分类的轮廓检测任务方面并不适用;另一方面,最后的池化层会进一步缩小特征图,不利于边缘的准确 定位。
②VGG16中的每一个卷积层都连接1个内核大小为[3*3]、通道深度为32的卷积层,目的是缩小网络模型大小,以获取更快的运行速度。
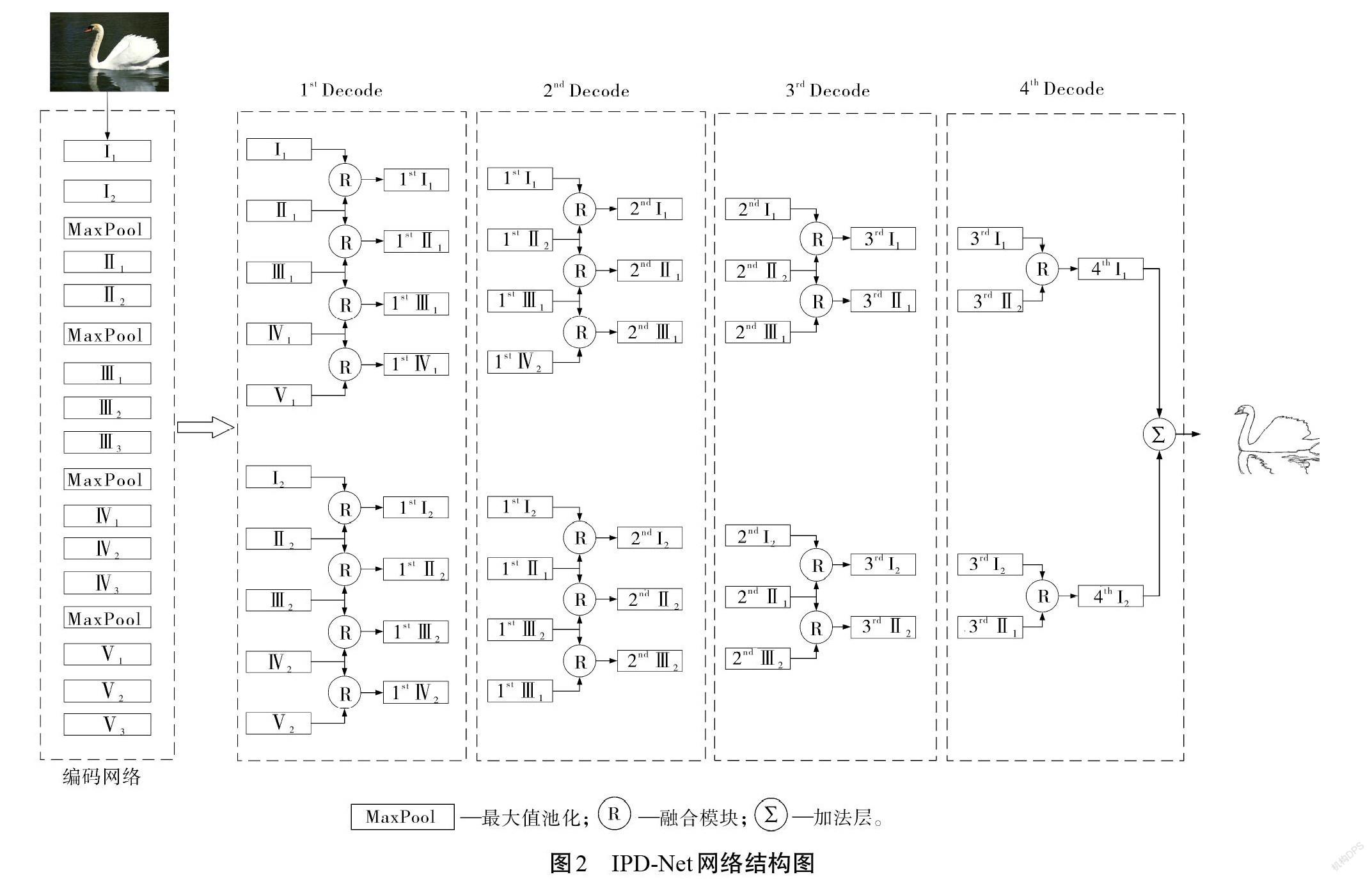
解码网络:整体结构如图2所示。首先,将编码网络中的输出分为2个子解码网络,分别用[Ni]和[Mi]表示,其中[M, N∈Ⅰ, Ⅱ, Ⅲ, Ⅳ],[i∈1, 2],[M、N]代表VGG16-Net不同阶段卷积层的输出,[i]代表构建的子解码网络。其次,根据邻近卷积层相互融合的原则将输出的卷积层进行连接,逐级进行,每个子网络依次进行4级连接。融合模块如图3所示,下层信息采用[3*3]卷积核处理,目的是处理上采样之后粗糙的特征图。因为上采样后,图像上每个点的相邻像素值之间的关系会变得更密切,导致图像整体信息出现聚集现象,因此,采用较大的卷积核既可以恢复每个像素点本身的特征,又可以代入全局信息以获得更完整的轮廓特征。为了匹配特征通道数,上层信息则采用[1*1]卷积核处理。将处理过的上层信息和下层信息共同传入加法层进行融合,得到最终的输出。最后,根据文中提出的交互式解码方法,自第2级解码开始,采用隔层交换原则,对IPD-Net中 2个子解码网络的部分特征进行互换。
1.2 损失函数
本文受HED[5]启发采用交叉熵作为损失函数。由于交叉熵损失函数主要用于解决二分类问题,而在边缘检测中,边缘像素点和非边缘像素点个数高度不平衡。为了解决这一问题,HED模型使用了加权交叉熵损失函数:
[BCEP, L=-βi∈L+logpi-(1-β)i∈L-log(1-pi)], (1)
其中:[L+]和[L-]分别表示图像中边缘像素点和非边缘像素点个数;[β=|L-|/| L |],[1-β=|L+|/| L |];[pi]是经过[sigmoid]激活之后卷积神经网络在[i]点处输出的像素值。这种方法有效地解决了训练过程中正、负样本数量不平衡的问题。本文的实验主要基于多人标注的BSDS500[9]数据集展开,因此,在[L+]和[L-]像素点类型选择上,认为[L={L+, L-, L+∈pi>0];[L-∈pi=0}]。由于IPD-Net具有3个输出,则2个子解码网络的输出称为侧面输出[BCEmside(m=1, 2)]。模型最终的轮廓图由最后的加法层融合之后得到,其损失值用[BCEfusion]表示。通过对侧面输出和融合输出求和,得到模型最终的损失值[BCEfinal]:
[BCEfinal=BCEfusion+m=12αmBCEmside], (2)
其中[αm]表示每一级侧面输出的权重。经过多次实验证明,[αm=0.5],即每一级侧面输出损失值进行平均化之后的结果表现最好。
2 实验结果与分析
2.1 实验细节
实验平台及训练方法:实验采用单个的GTX 1080Ti GPU完成,具有352 bit显存位宽,单浮点精度达到10.8TFLOPS。本文代码采用python语言编写,IPD-Net模型在公开学习框架Pytorch机器学习库上完成。其中,编码网络VGG-Net[13]采用 ImageNet[14]开源初始化参数进行迁移学习。采用随机梯度下降(SGD)进行迭代,每次随机采样1幅图像,总共进行2.8×105次随机采样,其中每8×104次迭代之后学习率乘[10-1]。
超参数设置:网络未迁移学习的卷积核采用均匀分布初始化[~Ua, b];[a=0],[b=1],偏置项[bias=0]。初始学习率、衰减权重和动量分别设置为:[lr=1×10-2]、[decay=2×10-4]和[momentum=2×10-4]。
数据集及数据增强:使用通用数据集BSDS500[9]和NYUD-v2[15]进行实验。BSDS500是一种广泛应用于边缘检测任务的数据集,但由于其数据量有限,仅有200幅图像作为训练集,在进行一定的数据增强之后仍然无法满足实际需求。本文将BSDS500的增强数据集与PASCAL VOC上下文数据集[16]混合作为训练数据。测试选用BSDS500数据集中的200幅測试图像,评估过程中的定位公差取[Distmax=0.007 5]。NYUD-v2数据集由成对高密度标记的RGB图像和深度图像组成。Gupta等将NYUD-v2数据集划分为381张训练图像和654张测试图像,遵循其设置对网络进行训练[17]。使用HHA来获取深度信息,其中深度信息被编码为3个通道:水平视差、离地高度和重力角度,因此,HHA特征可以表示为一幅彩色图像。然后分别对RGB图像和HHA特征图像进行训练,在测试过程中,通过平均RGB图像和HHA特征图像2种模型的输出来定义最终的边缘预测。因为NYUD-v2数据集中的图像比BSDS500数据集图像大,因此,在评估过程中增加了定位公差[Distmax=0.011]。
在训练集数量有限的情况下,数据增强是提高网络性能的有效方法。根据之前的研究,本文对图像与标签同时进行0.75~1.25倍的随机缩放。对于BSDS500数据集,通过将每幅图像进行16个不同角度的旋转,并在每个角度翻转图像,使得训练集从200张图像增强至超过10 000张。对于NYUD-v2数据集,由于其本身图像分辨率要优于BSDS500,因此,仅需对图像进行4个不同角度(0°、90°、180°、270°)的旋转,并在每个角度翻转。
多尺度策略:受RCF模型[6]启发,以原图像大小作为单尺度样本进行训练,采用不同尺度图像结合的方式进行样本测试,以进一步提高轮廓检测准确率。首先,使用双线性邻近插值法调整图像大小以构建图像金字塔模型;然后,将不同尺度的样本分别输入单尺度检测器中;最后,对不同尺度的检测器通过平均的方式求得最终的轮廓模型。通过以往经验以及不断的测试,最终确定使用0.5、1.0、2.0这3个尺度进行样本测试。在BSDS500数据集[9]的测试中,IPD-Net在多尺度策略下的[F]值(ODS)从0.803提升至0.819。
实验数据处理:基于通用[F]-measure性能评测体系对IPD-Net模型的性能进行定性与定量分析。[F]-measure具体计算如下:
[F=2PRP+R], (3)
[P=NTPNTP+NFP], (4)
[R=NTPNTP+NFN], (5)
其中:[P]表示精确率(Precision),[R]代表召回率(Recall),[F]则是[P]与[R]二者的调和平均,[NTP]表示图像中轮廓像素点被正确检测出的个数,[NFP]表示误将背景像素点检测为轮廓像素点的个数,[NFN]表示属于轮廓像素点但漏检的个数。在轮廓检测领域,通常以3个标准来判断轮廓检测模型的性能指标:ODS(整个数据集取最优阈值)、OIS(每幅图像取最优阈值)和AP(平均精确率),三者统称为[F]-measure。
2.2 消融实验分析
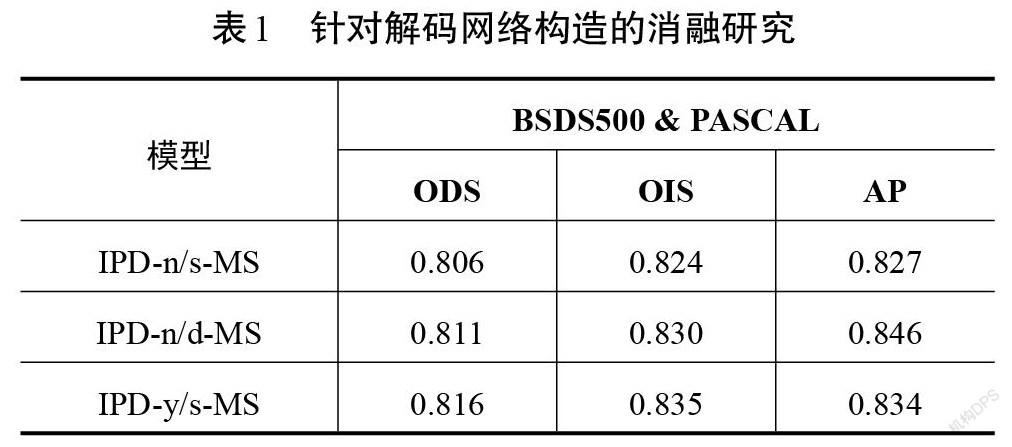
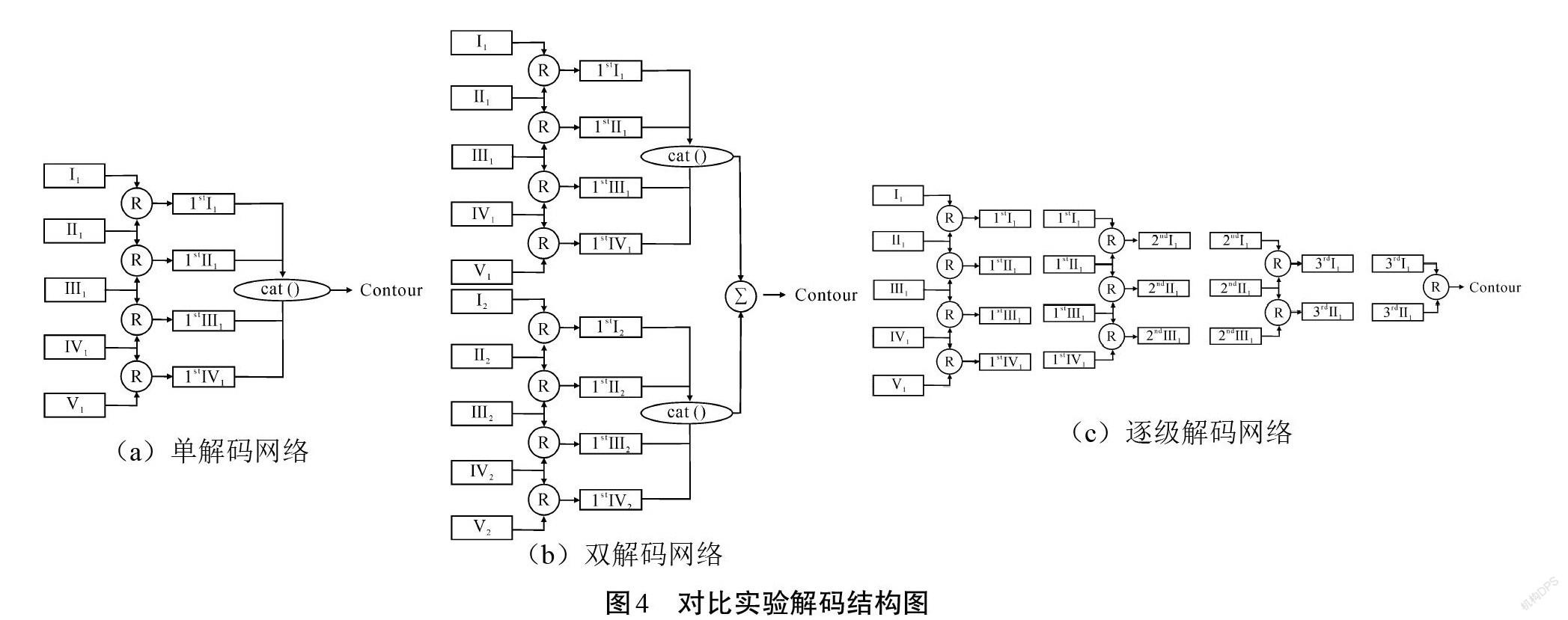
本文提出的IPD模型的新颖之处有2点:①利用了编码网络中大部分的特征信息,组成双解码网路进行特征解析;②双解码网络采用逐级交互式解码,交换部分特征信息,从而达到了信息交流的效果。本文提出的对比实验模型结构如图4所示。为了证实IPD-Net模型的性能,在BSDS500数据集中对IPD-Net进行了消融研究。首先,在图4(a)所示的解码结构中放弃逐级解码方式,仅使用第一级信息进行解码。不同的是,在图4(a)中并没有利用编码网络中的每一级信息,而是采用每一个阶段的最后一级的卷积层信息进行解码。此外,采用[cat()]函数将第一级解码之后得到的4组特征信息进行拼接以获取最终的轮廓特征,将该解码网络称为无逐级连接的单解码网络(以IPD-n/s代替)。其次,在图4(b)所示解码结构中,利用了编码网络大部分卷积层组成双解码网络。与图4(a)类似,仅使用一级解码,之后将双解码网络的输出传入加法层得到最终轮廓,该解码网络可以称之为无逐级连接的双解码网络(以IPD-n/d代替)。最后,在图4(c)所示的解码结构中,使用单个解码网络逐级解码(以IPD-y/s代替)的方式得到最终的轮廓结果。将实验中多尺度策略下的网络性能进行对比,其结果如表1所示。由表1可知,相比本文提出的逐级交互式解码,消融实验中的3个性能指标均有所下降,以此可以证明逐级交互式解码网络在轮廓检测任务中的优势:可以不断地融合、交互特征信息以获取更细致的轮廓。
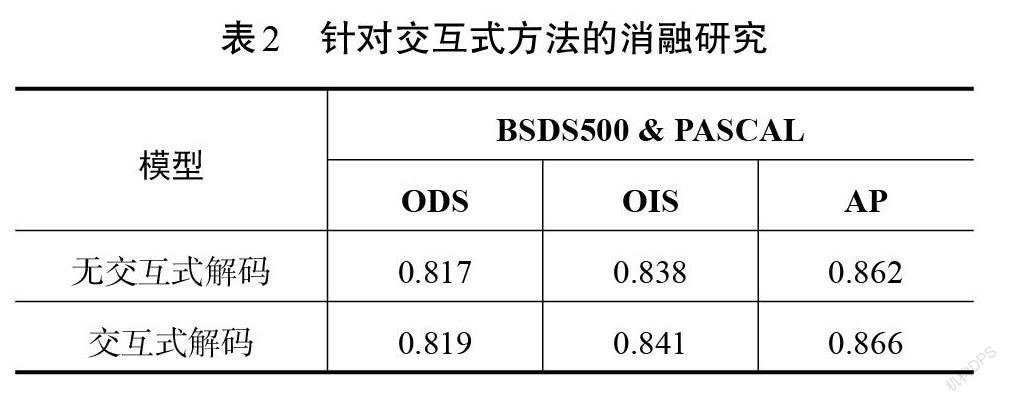
图1中的解码部分,子网络从第2级至第4级均交换部分信息。针对交互式解码,同样进行消融对比,即子网络每一级均使用自身的特征信息而不进行交互,结果如表2所示。可以看出交互式解码方法使网络的性能指标ODS由0.817提升至0.819。
2.3 模型性能对比
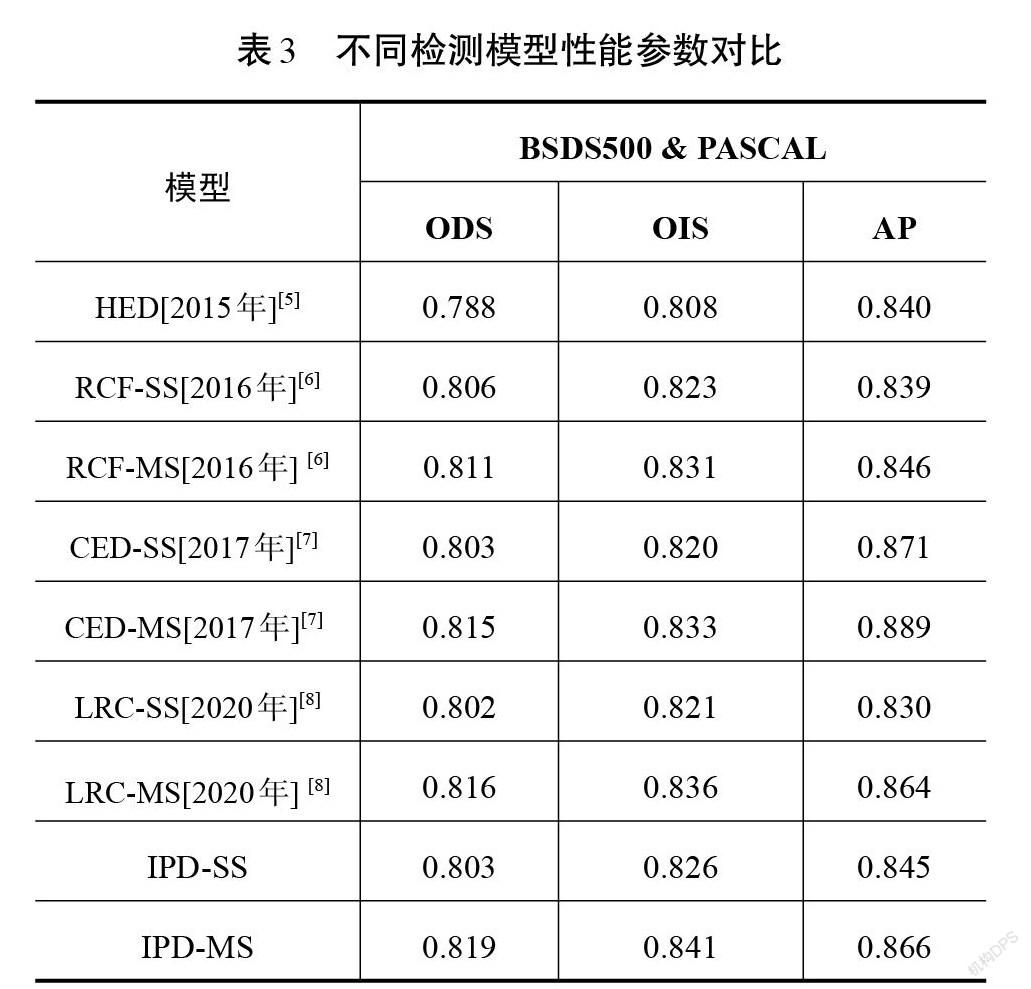
基于深度学习的轮廓检测模型性能已经远超传统算法,因此,本文没有加入与传统算法的比较。由于在编码网络中进行了以VGG16-Net为骨干网络的迁移学习,故选擇同类型网络进行性能对比,包括HED[5]、CED[7]、RCF[6]、LRC[8],结果如表3所示。可以看到在ODS和OIS这2个性能指标上,IPD-Net已经领先最新的算法LRC,其中IPD (ODS=0.819)与LRC(ODS=0.816)相比,ODS提升了0.003。多尺度策略对于本文的结果也有重要的影响,可以看到IPD-Net多尺度ODS值为0.819,单尺度为0.803,多尺度相比单尺度提升了0.016。但是本文方法的平均准确率(AP)结果并不理想,尤其与CED算法相比。原因是由于BSDS500[9]数据集是由多人标注,其真实轮廓图并不是二值化图像,边缘像素点以概率形式存在,如何判断概率、确定边缘点成为该数据集条件下轮廓检测的关键。
CED算法默认概率大于0的点为边缘点,但本文选择了一个折中的方法,认为概率大于0.5的点作为边缘点。因此,在平均精度上CED要明显高于其他方法,但是相比最重要的ODS性能来说,IPD-Net的方法更加适用。如图5所示是从BSDS500[9]的测试结果选取5幅性能优异的结果图,由图5可知,IPD-Net对轮廓部分的检测更加趋于真实轮廓图。
与BSDS500数据集比较方法同理,同样选择以VGG16-Net作为骨干网络的算法模型作为对比。但是因为研究者对NYUD-v2数据的关注度并不如BSDS500,对比量不足,所以加入基于机器学习的方法gPb-UCM[17]与SE[18]进行性能对比。在实验中,将单独使用原图像的测试结果称为IPD-RGB,同理使用深度信息的测试结果称为IPD-HHA,而二者加权平均之后的结果用IPD-RGB-HHA来表示。如表4所示,本文在ODS、OIS、AP等3个性能上均领先最新的算法,其中与LRC[8]算法相比,ODS性能值由0.761提升至0.770,提升了0.009。NYUD测试集具有654张图像,选取其中5幅进行展示,如图6所示,可以看到室内场景较为复杂,目标与背景颜色接近,光线相比自然图像也很差,目标轮廓极为复杂。
3 结论
针对轮廓检测任务的深度学习模型,本文提出了一种新的解码方法,采用双解码网络以利用编码中更多的特征信息,逐级交互式解码可以使不同网络中的信息相互交流。通过大量的消融实验可以明显看出,IPD-Net具有以下2个优点:①双解码网络在运算之前缩小了中卷积层的通道数,节约了计算机内存,在性能与效率之间作了权衡,因此,可以完全利用编码网络中不同卷积层的特征信息,使得“脆弱”轮廓得到更完整的保留;②逐级交互式解码有效地进行了卷积层之间的特征信息交流,对纹理的抑制、边缘的保护产生了积极的效果。与近几年的优秀算法比较,IPD-Net在BSDS500&PASCAL数据集上取得了ODS=0.819,在NYUD-v2数据集上取得ODS=0.770的好成绩。
通过实验可以看出,尽管IPD-Net在BSDS500数据集中已经取得优异的性能,但对于NYUD-v2这种比较复杂的室内场景数据集,还是无法达到理想的效果,在更加细节性的边缘检测上仍需要继续探寻一种更为可靠的方法。同时针对数据增强方法,也不能局限于翻转与平移,可以通过改变图像本身的明暗以及色调来获取更庞大的数据集。
参考文献
[1] SUN T-H,LAI C-H,WONG S-K,et al.Adversarial colorization of icons based on structure and color conditions[C]//Proceedings of the 27th ACM International Conference on Multimedia,Nice,France,2019:683-691.
[2] HUANG Y-C,TUNG Y-S,CHEN J-C,et al.An adaptive edge detection based colorization algorithm and its applications[C]//Proceedings of the 13th ACM International Conference on Multimedia,Singapore,2005:351-354.
[3] ZHANG W W,ZHOU H,SUN S Y,et al.Robust multi-modality multi-object tracking[C]//Proceedings of the CVF International Conference on Computer Vision,2019:2365-2374.
[4] 刘亚,艾海舟,徐光佑.一种基于背景模型的运动目标检测与跟踪算法[J].信息与控制,2002,31(4):315-319.
[5] XIE S N,TU Z W.Holistically-nested edge detection[J].International Journal of Computer Vision,2017,125(1-3):3-18.
[6] LIU Y,CHENG M M,HU X W,et al.Richer convolutional features for edge detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2017:3000-3009.
[7] WANG Y P,ZHAO X,HUANG K Q.Deep crisp boundaries[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2017:3892-3900.
[8] LIN C,CUI L H,LI F Z,et al.Lateral refinement network for contour detection[J].Neurocomputing,2020,409:361-371.
[9] ARBELAEZ P,MAIRE M,FOWLKES C,et al. Contour detection and hierarchical image segmentation[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2011,33(5):898-916.
[10] GRIGORESCU C,PETKOV N,WESTENBERG M A.Contour detection based on nonclassical receptive field inhibition[J].IEEE Transactions on Image Processing,2003,12(7):729-739.
[11] ZENG C,LI Y,YANG K,et al.Contour detection based on a non-classical receptive field model with butterfly-shaped inhibition subregions[J].Neurocomputing,2011,74(10):1527-1534.
[12] 林川,曹以雋.基于深度学习的轮廓检测算法:综述[J].广西科技大学学报,2019,30(2):1-12.
[13] SIMONYAN K,ZISSERMAN A.Very deep convolutional networks for large-scale image recognition[J/OL]. Computer Vision and Pattern Recognition,2014[2021-06-01]. https://arxiv.org/abs/1409.1556.
[14] DENG J,DONG W,SOCHER R,et al. Imagenet:a large-scale hierarchical image database[C]//2009 IEEE Conference on Computer Vision and Pattern Recognition,2009:248-255.
[15] SILBERMAN N,HOIEM D,KOHLI P,et al.Indoor segmentation and support inference from RGBD images[J]. Lecture Notes in Computer Science,2012,7576(1):746-760.
[16] MOTTAGHI R,CHEN X J,LIU X B,et al.The role of context for object detection and semantic segmentation in the wild[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2014:891-898.
[17] ARBELÁEZ P,MAIRE M,FOWLKES C,et al. Contour detection and hierarchical image segmentation[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2011,33(5):898-916.
[18] DOLLAR P,ZITNICK C L.Fast edge detection using structured forests[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2015,37(8):1558-1570.
Interactive decoding network of contour detection model
based on deep learning
QIAO Yakun, LIN Chuan*, ZHANG Zhenguang
(School of Electrical, Electronic and Computer Science, Guangxi University of Science and Technology,
Liuzhou 545616, China)
Abstract: The contour detection model based on deep learning is usually composed of encoding and decoding, in which encoding extracts and separates image features, while decoding analyzes and characterizes image features. A high-performance contour detection model is designed by using the information of each convolutional layer as much as possible. Firstly, the output of the coding network is divided into two groups to decode step by step. In addition, with the introduction of interactive connection, the two groups of networks exchange part of the convolutional layer to perform feature interaction for more feature information. Finally, the output of the two networks is passed to the addition layer for fusion to obtain the final output. This neural network model has conducted a lot of experiments on the BSDS500 and NYUD-v2 data sets, and the results have been significantly improved compared with the research in recent years. The ablation experiment further proves that the F value (ODS) of the interactive decoding method is increased from 0.816 to 0.819, an increase of about 0.003.
Key words: contour detection; deep learning; successive decoding;interactive connection
(責任编辑:黎 娅)
