融合依存句法的深度学习藏语句子分割研究
2022-01-01头旦才让仁青东主尼玛扎西完么扎西才藏太
头旦才让,仁青东主,尼玛扎西,完么扎西,才藏太
(1. 青海师范大学 省部共建藏语智能信息处理及应用国家重点实验室,青海 西宁 810008;2. 青海师范大学 计算机学院,青海 西宁 810008;3. 青海师范大学 民族师范学院,青海 西宁 810008;4. 西藏大学 信息科学技术学院,西藏 拉萨 850000)
0 引言
藏语句子分割技术是自然语言处理中的一项重要且基础性的研究工作。在机器翻译、文本分类、命名实体识别和自动问答等任务中,语料往往以句子为单位进行分析和处理[1]。目前,在藏语语料构建过程中,一般都采用监督或者半监督的方法进行句子分割,这样不仅耗费了大量的人力、物力和财力,而且语料规模难以达到藏语自然语言处理的要求,所以必须解决藏语句子的自动分割问题。
在汉语句子分割方法方面,主要以规则[2]、统计[3]、机器学习[4]和深度学习方法[5]为主,这些方法给汉语句子分割技术提供了很好的理论依据和技术参考,并广泛应用于中文信息处理中。另外,汉语中表示句子间隔的标点符号的功能比较单一,通常只要找出表示汉语句子间隔的标点符号即可[6]。当汉语句子末尾出现句号、问号和感叹号时,可以表示为一个独立完整的句子,所以汉语句子分割问题已基本解决,而藏语句子边界信息模糊,无法仅凭简单的规则进行识别。
目前藏语句子分割方面的研究只有一些零散的文献报道,采用的方法主要以规则、统计以及两者结合的方法为主。2011年,李响等人[7]采用一种基于规则和最大熵模型相结合的方法来识别藏语句子边界。2012年,才藏太[8]根据藏语语法的逻辑规则以及构建的辞典,对藏语句子进行了分割,同时采用最大熵模型识别有边界歧义的藏语句子。2013年,赵维纳等人[9]通过分析藏文句子边界符号的特征,提出了一种基于藏语助动词的句子分割方法。2016年,万玛冷智[10]通过探索藏语句子的词法和语法规则,提出了一种基于句尾词性的藏语句子分割方法。2019年,却措卓玛等人[11]总结归纳藏语句子的类型以及句子边界信息特征,提出了一种基于混合策略的藏语句子分割方法。2020年,柔特等人[12]提出了一种藏语句子语义切分方法。上述这些研究成果给藏语句子分割技术的研究提供了一定的理论和技术基础。
本文根据藏语句子分割规则、特点以及难点,借鉴汉英相关技术方法,提出一种融合藏语依存句法信息的藏语句子分割模型,下文将围绕四个部分对藏语句子分割技术进行研究。
1 藏语句子分割规则与难点
藏语句子是按照其严格的语法规则,由实词和虚词组成的,具备完整的语义,具有很强的次序性和逻辑性的句子。汉语句子分割技术和藏语句子分割技术有一定的区别和差异,所以,藏语句子分割技术无法直接使用汉语句子的分割方法和理论。
1.1 藏语句子分割规则
在藏语中,如何判断某一个句点到底是否为句尾,关系到词法分析、句法分析和语义分析等不同层面。如果从藏语文本的表层词汇信息角度考虑,表示句尾的句点前面一般都会出现动词、形容词、终结词、助词、离合词等。本文通过对藏语语料进行统计,句尾出现各类词的比例如表1所示。
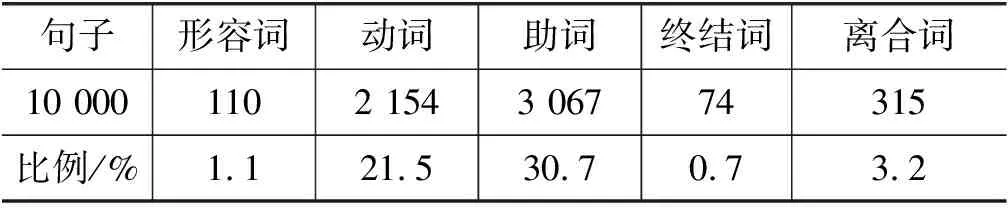
表1 句尾出现各类词的比例

1.2 藏语句子分割难点
根据藏语文法中的句子特征和语料统计结果,藏语句子分割有以下三个难点。
1.2.1 句点的歧义性
句点功能的多种歧义使藏语句子边界识别较为困难,示例如图1所示。

图1 藏语句点的歧义示例
1.2.2 借用符号的识别
随着各民族文化交流,现代藏语文本中出现了很多借用符号,如双引号、破折号和省略号等外来符号经常会出现在藏语句子中,增加了藏语句子分割的难度,示例如图2所示。

图2 藏语中出现的借用符号示例
1.2.3 长句的分割问题
长句由多个单句组成,很难在长句中找出句子内部的分割点,示例如图3所示。

图3 藏语长句子示例
2 双向LSTM+CRF模型
双向LSTM+CRF模型能够解决文本序列标注问题,我们可以将藏语句子切分任务作为一个序列标注的问题进行处理。传统的双向LSTM+CRF模型包括输入层、词嵌入层、特征提取层和分类层。模型架构如图4所示。

图4 双向LSTM+CRF模型架构
由图4可知,词嵌入层将输入的词特征序列映射成低维实值向量。若输入序列过长,则随着模型训练,将会遗失长距离词信息,致使模型不能很好的捕获长距离句子的句法信息和语义特征。为提高模型学习时序特征能力,在特征提取层采用双向LSTM,捕获输入句子中的上下文信息,获得每个输入序列的句法信息特征和隐藏层状态,随后采用CRF进行解码。生成序列的概率P(y|X)如式(1)所示。

(1)
其中,
(2)
式中,s(X,y)是标签分配得分函数,P是隐藏层序列映射到标签的得分矩阵,A是转移概率矩阵,Ai,j表示标签i到j的转移概率。
3 藏语句子分割模型
在汉语信息处理中使用的深度学习方法和理论一般都可以应用在藏语自然语言处理中,但在实际应用中,须针对藏语语法中的具体问题和藏语自身独有的语法特征做适当的改动和调整。
藏语依存句法分析可以获取句子,内部的结构信息,找出最佳句子边界。因此,本文根据藏语句子结构特征,采用多任务学习机制,在双向LSTM+CRF模型中融入了藏语依存句法信息。模型融入藏语依存句法信息的原因有以下三个方面:
(1) 根据藏语句子分割规则,动词一般出现在句尾,可以充当句子边界符号,而依存语法则是以动词为核心,用于剖析句子成分内部的依赖关系,所以通过藏语依存句法分析可以更好地获取藏语句子边界信息。
(2) 我们根据藏语传统的句法结构特征和语法理论规则,制定了符合藏语语法的依存句法标注规范,把藏语依存句法关系分为5个大类和36个小类,并研发了藏语依存句法标注系统[18],为融合藏语依存句法模型提供了可靠的数据和理论支持。
(3) 将藏语依存句法信息融入双向LSTM+CRF模型中,避免对每个输入序列都进行句法剖析,显著增加了模型的适用性。
深度学习融入外部信息有多种方式[19],本文使用双向LSTM+CRF模型进行藏语句子分割时融入了藏语依存句法信息,使模型可以学习到特征提取层和输出层的信息,模型架构如图5所示。
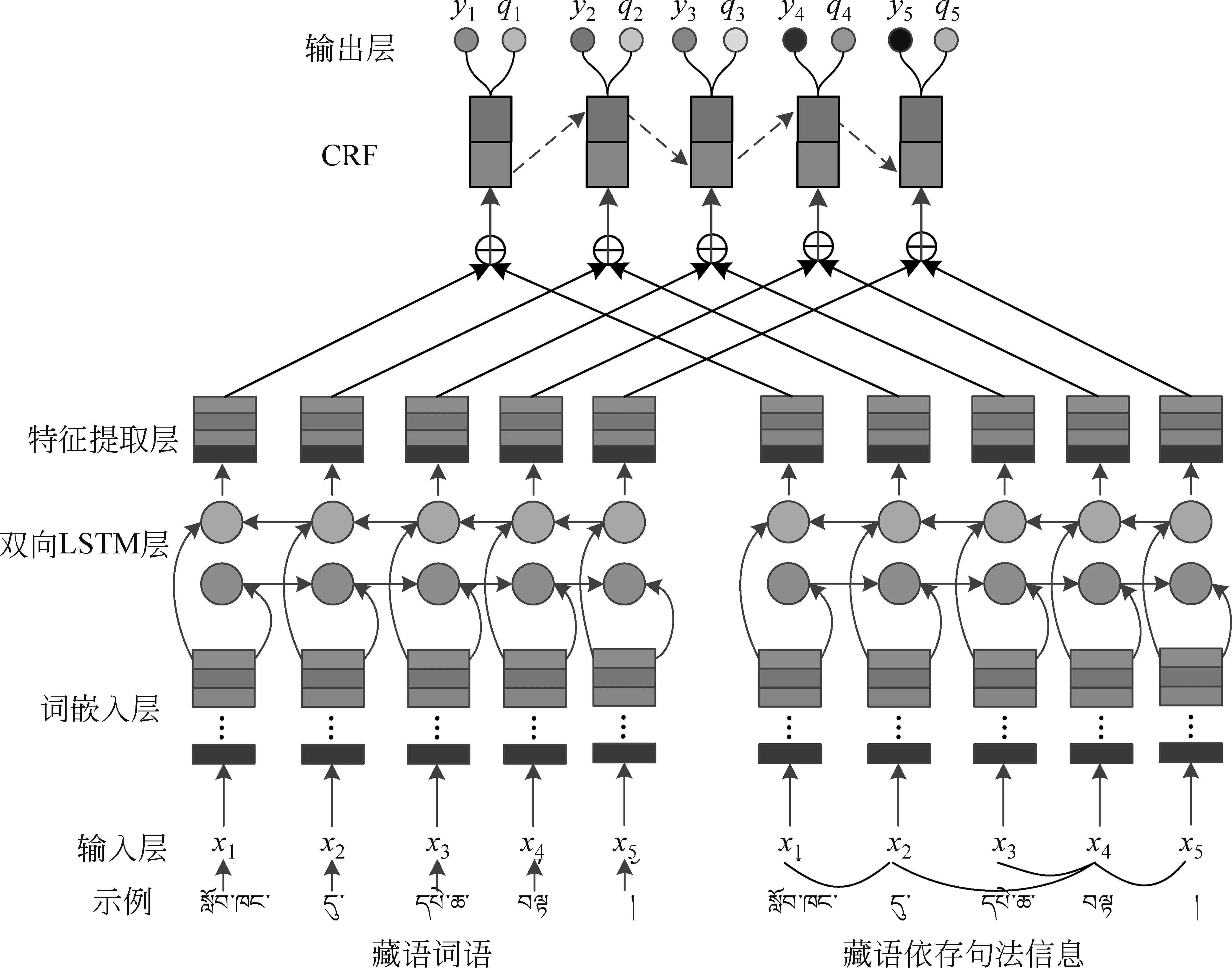
图5 融合藏语依存语法的句子分割模型
图5中,{x1,x2,x3,…,xn}是输入的词序列,{y1,y2,y3,…,yn}是模型预测出的分割标签,{q1,q2,q3,…,qn}是模型预测出的藏语依存句法标签序列。以下重点对模型的词嵌入层、融合藏语依存句法的双向LSTM层和输出层进行介绍。
3.1 词嵌入层
为融合藏语依存句法信息,模型的嵌入主要由词嵌入和藏语依存句法信息嵌入两部分组成。
模型的词嵌入层将词输入序列映射为实值向量。输入的藏语句子,都以词作为最小单位嵌入神经网络中,即图5中的{x1,x2,x3,…,x5}。在词嵌入层,首先生成一个训练语料的词表,需要将输入序列中的词都转换为该词在词表中的位置,以此来确定词的位置信息。然后构建可训练张量,维度为[vocab_size,embedding_size],该张量中的参数可以随着网络训练进行更新。其中vocab_size是词表大小,embedding_size是词嵌入的维度大小,最后在维度中找出对应的向量,将词输入序列映射为实值向量表示。

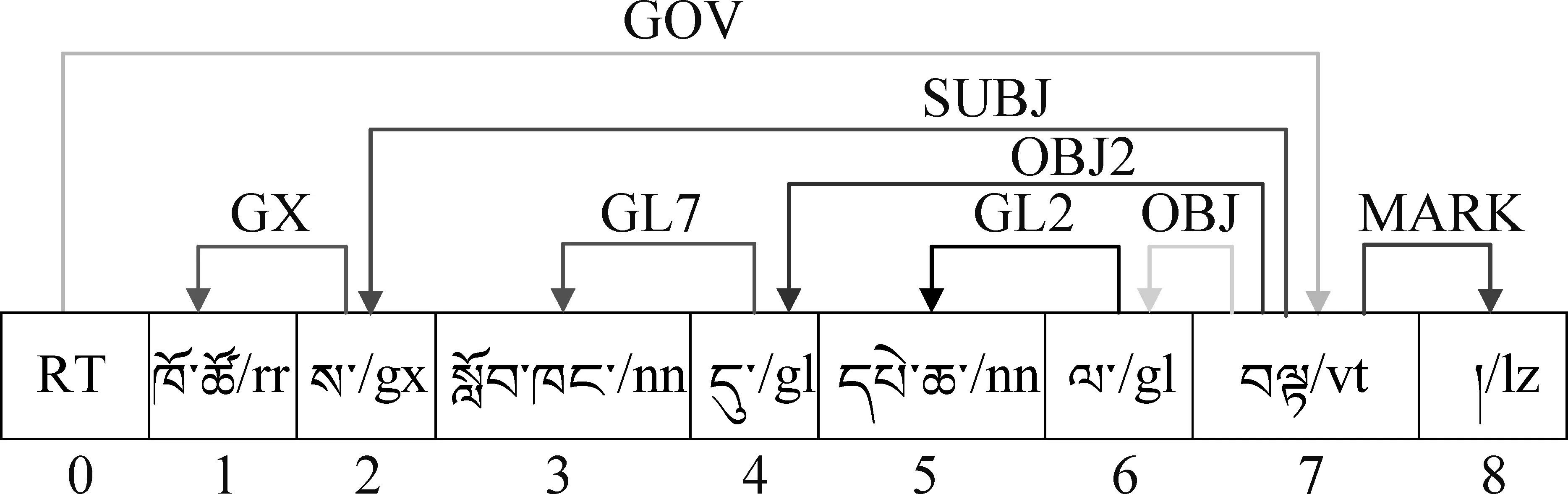
图6 藏语句子C的依存句法分析树
图6中,边表示句子中支配词与被支配词之间的依存关系。边上的标签表示词与词之间的依存关系类型[20]。
但是,双向LSTM+CRF模型无法直接使用图6所示的藏语依存句法结构,因此本文将使用如表2所示的藏语依存句法表示示例。
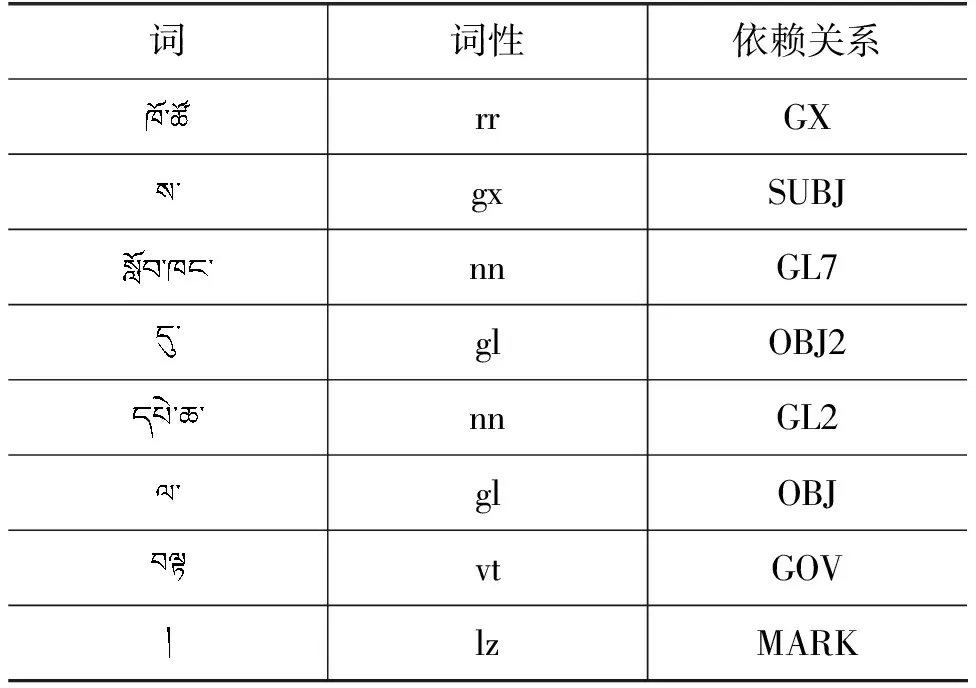
表2 藏语依存句法表示示例
从表2可以看到,通过句法解析后得到词性信息和依赖关系等。对于句法信息来说,依赖关系很重要,所以本文在藏语句子分割时使用的句法信息是依赖关系。对于每个输入语句,都将句法信息作为最小单元嵌入输入层中,并通过序列化输入标签求出最终的标签。
3.2 融合藏语依存句法的双向LSTM层
目前,未查阅到有关基于深度学习的藏语句子分割模型的文献。为了解决藏语句点的歧义性、借用符号的识别问题和长句分割问题。同时,为解决长距离数据输入和训练过程中出现的长距离依赖问题[21],本文使用深度学习中的序列标注框架,用双向LSTM模型进行藏语序列标注。
本文模型在词嵌入层后均使用双向LSTM学习时序特征,同时,拼接词的时序特征和藏语依存句法信息的时序特征来表示最终的藏语句子分割结果。LSTM 按时序接收从嵌入层输出的xn,双向LSTM 层的输出可以表示为ht,其计算过程如式(3)~式(8)所示。
X=[ht-1,xt]
(3)
it=σ[Wi·X+bi]
(4)
ft=σ[Wf·X+bf]
(5)
it=σ[Wo·X+bo]
(6)
Ct=it⊙tanh(Wc·X+bc)+ft⊙CT-1
(7)
ht=ot⊙tanh(Ct)
(8)
其中,X表示t-1时刻隐藏层的值,包含当前词的上下文信息,xt表示t时刻的输入向量,it是输入门特征值,ft是遗忘门特征值,ot是输出门特征值。Ct表示LSTM的单元状态。Wi、Wf、Wo、Wc、bi、bf、bo和bc分别为需要学习的参数[22]。
双向LSTM的输出为正反向LSTM输出的拼接,表示为ht,如式(9)所示。


(10)
最后,双向LSTM作为特征抽取器,取到整个输入序列的上下文信息和每个位置的上下文内容信息。在训练过程中,使用dropout有效遗忘一些事先得到的状态信息。提高模型的泛化性能,缓解模型的过拟合现象。
3.3 输出层
得到双向LSTM的最终输出后,经过CRF进行解码。由于本文不仅要预测藏语句子分割标签序列,而且还要预测藏语依存句法标签,所以在双向LSTM+CRF模型上增加了一层CRF层,主要用于藏语依存句法标签的解码。
由此,在训练过程中,对于表3中的藏语输入序列{x1,x2,x3,…,xn},模型应该识别的输出序列是{y1,y2,y3,…,yn}和{q1,q2,q3,…,qn}。

表3 输出样例
表3中,{q1,q2,q3,…,qn}是预测藏语依存句法标签,即藏语依赖关系标签。{y1,y2,y3,…,yn}是预测的藏语句子分割标签序列。预测的藏语句子分割标签序列中的N代表不是句子边界,S表示最佳句子分割点。
在本文模型的输出层,若用yt和qt(t∈[1,5])分别表示t时刻预测到的藏语句子分割标签和藏语依存句法标签,则特征提取层提取到的特征ht经过CRF进行解码后的输出yt和qt如式(11)所示。
最终将预测分割标签序列和藏语依存句法标签序列和的损失相加,作为本模型的总损失。
4 实验结果与分析
4.1 实验数据
由于目前没有公开的藏语句子分割语料,本文将青海师范大学藏语智能信息处理及应用国家重点实验室提供的数据作为训练集,西藏大学信息科学技术学院提供的语料作为验证集和测试集。通过对藏语生语料进行拼写检查、自动校对、字词切分和依存句法分析后,得到了符合规定数据格式并拥有较高质量的11 600 条藏语数据。实验数据的内容和类型主要以新闻和法律文本为主,实验数据划分情况见表4。

表4 藏语句子分割数据集
由于藏语句子分割模型的输入序列是以词为单位的,所以分词的好坏直接影响实验数据的性能。本文根据藏文的语法特点,首先利用改进的藏文字节对编码进行了藏语分词[23],具体算法如下:
其中,分词的F1值为93.7%,藏语命名实体识别的F1值为88.45%,然后对藏语分词语料进行了人工校对,以确保实验数据的准确性。
4.2 实验环境和参数设置
本实验的操作系统为Ubuntu 18.04,CPU为Intel E5-2684 v4,GPU为NVIDIA GTX 1080Ti,深度学习框架为TensorFlow 1.12.0。训练中,最大句子长度为180个字符,预测标签数为2,词表大小为43 064。当本实验参数设置为如表5所示时,实验效果最佳。

表5 藏语句子分割模型参数
4.3 评测指标
本文采用准确率(P)、召回率(R)、以及F1值作为藏语句子分割模型的评价指标,具体定义如式(12)~式(14)所示。
4.4 实验结果分析
目前没有公开的藏语句子分割语料,加上相关文献的实验数据、实验环境和研究方法各不相同,实验结果的可比性较低。所以,为了验证本文模型的有效性,选用神经网络中常用于序列标注的3个经典模型作为基线模型实现了藏语句子分割任务,分别为CRF、双向LSTM、双向LSTM+CRF以及本文提出的双向LSTM+CRF+藏语依存句法等模型,对比实验结果如表6所示。

表6 不同模型的藏语句子分割结果
从表6中实验结果可以看出,第一组实验采用CRF实现了藏语句子分割,取得了较好的效果,但是CRF不能捕捉距离长的上下文特征信息,只考虑了句子的局部特征,所以该模型的F1值最低。
第二组实验采用双向LSTM实现了藏语句子分割。因双向LSTM的序列标注能力优于CRF,其既能捕获长远的上下文信息特征,还可具备拟合非线性的能力,故F1值达到了90.2%。
第三组实验采用双向LSTM+CRF实现了藏语句子分割。在特征提取层采用双向LSTM模型,捕获输入句子的上下文信息,得到每个输入的特征表示和隐藏层状态,之后利用CRF进行解码。F1值提高了4.1个百分点,达到了94.3%。基本解决了藏语句点的歧义性和长句分割问题。
最后,为了通过融合藏语依存句法结构信息,达到解决藏语句点歧义性和长句分割问题的目的,本文根据藏语句子结构特征,第四组实验在原有模型双向LSTM+CRF的基础上拼接了用于表示藏语依存句法信息的双向LSTM模型,这样模型可以通过学习特征提取层和输出层的信息,获取句子内部结构信息。然后通过藏语依存序列化标签处理、藏语句子特征提取等方法,找到最佳的句子边界。经实验,在测试集上F1值提高了5.1个百分点,达到了99.4%。验证了本文所提模型和藏语依存树库在藏语句子分割任务上的有效性。
本文融入依存句法结构信息后效果提升明显,原因主要有两点: 一是我们首先使用文献[18]提出的藏语依存标注系统构建了规模为6 000句的藏语依存树,然后对所建树库进行人工校对后将其分成了训练集和测试集,规模分别为5 000句和1 000句,最后选用依存句法分析任务中常用的USA和LAS作为评价指标进行实验,测试准确率为95.6%,确保了融入依存句法结构信息的质量。二是藏语依存句法分析可以获取以谓词为核心的句子内部结构信息,有助于找出最佳句子边界和提高句子分割性能。
为了更加直观地对比和描述四组实验效果,将实验结果用柱状图展示,其中横坐标表示四组实验,如图7所示。

图7 藏语句子分割实验效果对比
实验表明,融合藏语依存句法的双向LSTM+CRF模型在藏语句子分割任务中效果最佳,进一步优化了藏语句子分割模型,准确率、召回率、F1值分别为99.5%、99.4%和99.4%。验证了双向LSTM+CRF模型中融合藏语依存句法信息的有效性,模型能够解决藏语句点的歧义性、借用符号的识别问题和长句分割问题。

表7 藏语句子分割的例句
5 结束语
本文根据藏语句子结构特征,在分析藏语句子分割规则与难点的基础上,提出一种融合依存句法的藏语句子分割模型。该模型首先通过词嵌入和藏语依存句法信息嵌入将输入序列映射成实值向量;然后构建融合藏语依存句法的双向LSTM,拼接词语和句法信息特征, 提高上下文时序特征的学习能力;最后利用CRF预测出最佳句子分割点。通过对比实验,验证了本模型对藏语句子分割的有效性。实验结果表明,该模型的F1值为99.4%。
未来工作中,我们将扩充语料,采用联合训练模型和预训练模型等先进方法对藏语句子分割进行改进,也相信相关研究人员将会提出更多有价值和实际应用能力的藏语句子分割技术。
本文将开放藏语句子分割实验数据(1)获取地址: https://github.com/toudancairang,希望更多的研究人员参与其中,共同推动藏语句子分割的研究,促进藏语自然语言处理技术的发展。
