基于藏文Albert预训练语言模型的图采样与聚合实体关系抽取
2022-01-01尼玛次仁尼玛扎西
于 韬,尼玛次仁,拥 措,尼玛扎西
(1. 西藏大学 信息科学技术学院,西藏 拉萨 850000;2. 西藏大学 西藏自治区藏文信息技术人工智能重点实验室,西藏 拉萨 850000;3. 西藏大学 藏文信息技术教育部工程研究中心,西藏 拉萨 850000)
0 引言
实体关系抽取作为信息抽取领域的核心任务之一,其主要目的是对已标记实体对间的语义关系进行分类。该任务在汉文及英文上已被广泛研究,但在藏文上研究较少。藏文在实体关系抽取任务上缺乏公开数据集,是制约对其研究的主要因素,本文利用人工校对的藏文实体关系抽取数据集进行研究。
藏文是藏族的民族语言,语法规则较强,目前在自然语言处理领域对藏文的研究还处于起步阶段,且藏文句子特征表示存在一词多义及语义歧义现象,因此使用预先训练的藏文Albert[1]模型根据句子上下文信息表示句子特征,提升了句子特征的质量。同时,为了提升传统实体关系抽取模型的准确率,本文应用GraphSAGE模型[2]对藏文实体关系抽取进行研究。
首先,将原始数据预处理后分别输入藏文Albert模型与位置向量提取器中,生成藏文句子动态词向量及实体位置向量。然后,为了使用GraphSAGE模型学习上述的句子向量及位置向量,本文提出了图结构数据构建与表示方法,再将上述向量作为该方法的输入,以构建数据图及节点特征。最后,将获得的特征输入GraphSAGE模型中,通过该模型对周围邻居节点的采样与聚合操作,得到最终的关系分类结果。
1 相关工作
在藏文实体关系抽取任务中,首先要解决的问题是将藏文数据转换为机器可识别的语言。自从词向量表示方法[3]提出后, Bengio等[4]紧接着提出了一种N-gram神经网络概率语言模型,在模型训练过程中生成词向量。在Bengio的研究基础上,Mikolov等[5]于2013年提出Word2Vec工具,该工具利用Skip-gram与CBOW两种词向量模型生成词向量。 Facebook于2016年提出FastText[6]工具,在负采样Skip-gram模型的基础上学习词的向量表示。但传统的词向量模型生成的词向量为静态词向量,且无法解决语义歧义及一词多义问题。所以,2017年Transformer[7]的提出极大地推动了词向量的发展,随后BERT[8]的诞生带来了动态词向量,BERT模型使用掩码语言模型(Masked Language Model, MLM)和下一句预测(Next Sentence Prediction, NSP)两个无监督预测任务作为预训练任务生成词向量。但Zhenzhong Lan等通过研究发现BERT的NSP任务对于下游任务并不起作用,因此Zhenzhong Lan等于2019年提出Albert模型,删除NSP任务,使用句子顺序预测(Sentence OrderPrediction, SOP)任务代替,并通过因式分解嵌入层矩阵(Factorized Embedding Parameterization)与跨层参数共享策略(Cross-layer Parameter Sharing)压缩优化模型,提升了模型的训练效果。下文将在实体关系抽取任务中使用藏文Albert模型生成的动态词向量进行研究。
目前实体关系抽取研究大部分采用监督学习方法,2015年Santos等[9]提出CR-CNN模型,模型首先将词映射为低维向量,然后使用固定大小的滑动窗口对词向量进行卷积操作,在SemEval-2010 Task 8数据集上获得84.10%的F1值。2016年Wang等[10]提出AttentionCNNs模型,将注意力机制引入神经网络中,对反映实体关系更重要的词赋予更大的权重,在SemEval-2010 Task 8数据集上获得88.00%的F1值。Chen等[11]提出基于词依存信息类型映射的记忆神经网络,利用上下文关联的词及词与词之间的依存关系类型对上下文信息进行建模,在SemEval-2010 Task 8数据集上获得90.06%的F1值。
上文介绍了实体关系抽取在英文领域的研究,在藏文实体关系抽取领域,2018年夏天赐等[12]提出基于联合模型的藏文实体关系抽取方法,对藏文进行字级和词级的处理,并采用端到端的BiLSTM模型将藏文实体关系抽取任务转变为藏文序列标注问题,在2 400句语料上获得56.00%的F1值。2019年郭莉莉[13]等提出基于BP神经网络的实体关系抽取模型,将实体位置、实体距离、实体及其周围词特征输入至BP神经网络进行关系抽取,在4 216句语料上获得62.12%的F1值。2020年王丽客等[14]提出基于远程监督方法的藏文实体关系抽取模型,加入语言模型和注意力机制改善藏文句子的表示问题,同时使用联合得分函数改进远程监督数据的错误标签问题,在4 126句语料上获得58.9%的F1值。
2 方法与模型
为了提高词向量质量,提升实体关系抽取模型的准确率。首先,本文使用藏文Albert预训练语言模型生成句子的动态词向量,并为了表示实体在藏文句子中的位置特征,将藏文句子及实体输入至位置向量提取器以获得实体的位置向量。然后,对上述特征应用本文提出的图结构数据构建与表示方法,通过该方法将藏文实体关系抽取数据集转换为图结构及节点特征。最后,将数据图及特征输入GraphSAGE模型,利用其采样与聚合操作高效地学习数据图中的节点特征,提高了藏文实体关系抽取模型的准确率,模型整体框架如图1所示。
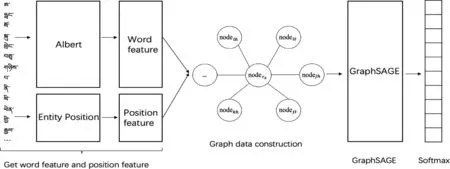
图1 模型整体框架
2.1 图结构数据构建与表示方法
由于GraphSAGE模型的输入为图结构数据,因此本文提出一种将藏文实体关系抽取数据集转换为图数据及特征的新方法。由表1可知数据集中每条数据对应两个实体及一个关系,在同一条数据中可以构建实体节点链接至关系节点的一张图。分析可知多条数据间需要通过关系节点作为关联节点进行链接,即假设第一条数据中关系为r1,第二条数据中关系也为r1,那么对于这两条数据,可链接不同实体节点至r1节点构成图结构。
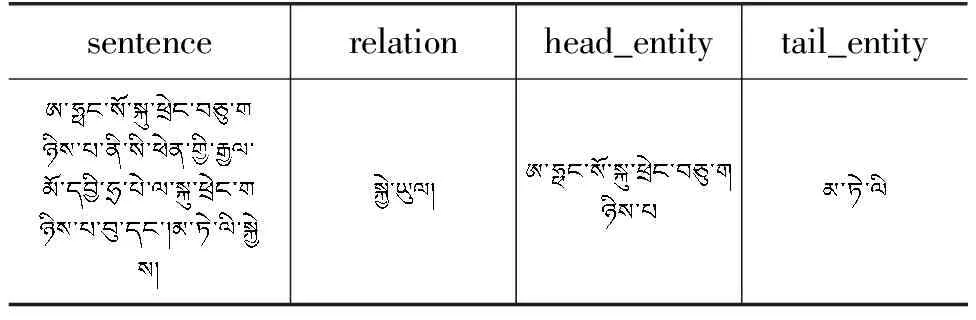
表1 数据集样例
本方法的输入数据包含6 000条数据样本,10种关系类型。在图2中,中心节点noderx(1≤x≤10)表示关系类型为rx的节点,nodeih、nodeit分别表示第i条数据中的头实体及尾实体节点,nodejh、nodejt及nodekh同理,其中,1≤i,j,k≤6 000。将所有数据中关系类型为rx的头实体以及尾实体节点链接至noderx节点上,即可将藏文实体关系抽取数据集转换为清晰的图结构。

图2 图结构数据构建与表示方法
由上述方法构建图结构之后需要继续表示图节点的特征,为了更好地进行对比实验,图节点特征使用句子向量、头实体位置向量以及尾实体位置向量表示。头实体节点特征构建方法为:feanodenh=feanoden+feanodenhead_pos(1≤n≤6 000),其中,feanodenh表示nodenh节点的特征,feanoden表示nodenh节点对应的句子向量,feanodenhead_pos表示nodenh节点对应的头实体位置向量。另外,尾实体节点特征构建方法与头实体节点特征构建方法相同:feanodent=feanoden+feanodentail_pos(1≤n≤6 000),其中feanodentail_pos表示nodent节点对应的尾实体位置向量。至此,图结构及节点特征均构建完成,将构建完成的特征输入至图神经网络进行学习。
2.2 藏文Albert预训练语言模型
藏文是我国的少数民族语言,与汉文及英文相比藏文语料稀少。使用传统词向量模型针对数据稀疏的藏文语料很难获取高质量的词向量,且无法解决一词多义等问题。因此,为了弥补传统词向量模型的不足,本文使用模型结构更为复杂的Albert预训练语言模型训练藏文语料,该模型使用Transformer进行特征抽取,并结合因式分解嵌入层矩阵、跨层参数共享与句子顺序预测三种策略,在模型参数规模降低的同时可获取句子上下文相关的双向特征表示,得到高质量的句子特征。预训练语言模型的应用,使得原本无法针对各种语境变化的静态词向量表征,向着真正基于语境的语义特征表示演进。
训练藏文Albert模型共使用1.7GB藏文新闻领域数据,以音节分词的方式构建模型的输入数据。批训练大小为32,使用RTX 2080Ti GPU进行加速,总训练步数为2 126 622,评价指标在第2 119 000步取得最佳,各评价指标如表2所示,其中,mask_loss表示Albert模型在MLM任务上的损失;sop_loss表示Albert模型在SOP任务上的损失;mask_accuracy是在MLM任务中预测遮掩单词的精确度;sop_accuracy是在SOP任务中预测句子顺序的精确度;loss表示两部分损失的和。为了测试预训练语言模型的实际效果,下游任务将应用藏文Albert模型进行实体关系抽取。

表2 藏文Albert预训练语言模型评价指标
2.3 GraphSAGE模型
GraphSAGE模型是图神经网络(Graph Neural Network, GNN)的一种,其主要思想是节点的信息在节点间传递,当前节点通过聚合函数(Aggregate Function)聚合其周围邻居节点的信息,并使用神经网络作为更新函数更新当前节点的信息。随着不断地迭代更新,节点可聚合更多外层邻居节点的信息,使节点信息更加丰富。GraphSAGE模型在进行特征学习时,与图卷积网络(Graph Convolution Network, GCN)[15]使用全图信息学习的方式不同,而是可以通过批训练的方式学习节点特征,对大规模图数据的训练提供了帮助。本文使用GraphSAGE模型批训练的方式与其余实验的训练方式进行对比。
GraphSAGE模型的学习过程主要分为三部分: 邻居节点采样、邻居节点聚合、学习聚合后的节点信息。首先,对邻居节点进行采样,但不需要采样全部的邻居节点。根据作者的假设,节点v的采样节点层数k取2时模型表现最好,即采用两层GraphSAGE模型。
然后,聚合节点v的邻居节点,如式(1)所示。其中,N(v)表示节点v的邻居节点集合;AGGREGATE()表示聚合函数,采用均值函数或长短时记忆网络均可。获取节点v的邻居节点后,可获得邻居节点u在第k-1层的特征表示,并使用聚合函数聚合邻居节点特征,将聚合后的特征作为节点v在第k层的邻居节点特征表示。

(1)
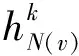
GraphSAGE模型的采样与聚合操作是学习采样节点的邻居节点与自身节点的特征,最终将聚合邻居节点后的采样节点特征输入神经网络进行特征学习。应用GraphSAGE模型是对使用图结构数据进行藏文实体关系抽取任务的探索,GraphSAGE为推导式GNN,泛化性好,可以根据新节点的邻居节点表示该节点特征,适合关系抽取模型的实际应用。
3 数据集及评测指标
3.1 数据集
藏文实体关系抽取无开源数据集,本文选择通识类汉文实体关系抽取数据集,通过机器翻译后进行人工校对确保藏文语句、语法的正确性。预处理后的数据样例如表1所示。sentence字段表示包含实体的描述句子;relation字段表示两实体间的关系;head_entity字段表示头实体信息;tail_entity字段表示尾实体信息。
本文数据集中共6 000条数据样本,10种关系类型。在不包含GraphSAGE模型的实验中,以4 000条原始数据作为训练数据,1 000条原始数据作为校验数据,将校验数据顺序打乱作为测试数据;在包含GraphSAGE模型的实验中,使用上述训练集、校验集与测试集共6 000条数据样本构建动态词向量及实体位置向量后,将向量作为图结构数据构建与表示方法的输入,从而获得不同数据集对应的图结构,再将这三种图结构应用GraphSAGE模型学习。
3.2 评测指标
由于数据集中共有10种关系类型,因此需采用多分类模型精确度的评测指标MacroF1与MicroF1进行评价,即宏平均与微平均。MacroF1是不同类别F1值的和的平均值,如式(3)所示,其中,F1*c1表示类别1的F1值,n为类别数;MicroF1是总体F1值的平均值,如式(4)所示,其中,F1*sum表示不分类别的总体F1值。实验部分中将以MacroF1与MicroF1作为模型评测指标。
4 实验
4.1 实验设置
在进行下文实验前,本文通过数据的正态分布确定实验句子长度(seq_len)。首先统计数据集中每条句子的长度及频次,在统计频次过程中使用区间统计法,如句子长度位于1~100之间,则使用100来表示当前区间的句子长度,统计后构建的数据正态分布图如图3所示。然后计算正态分布的μ与σ,如式(5)与式(6)所示,可知该数据服从N(217.2,127.42)的正态分布。
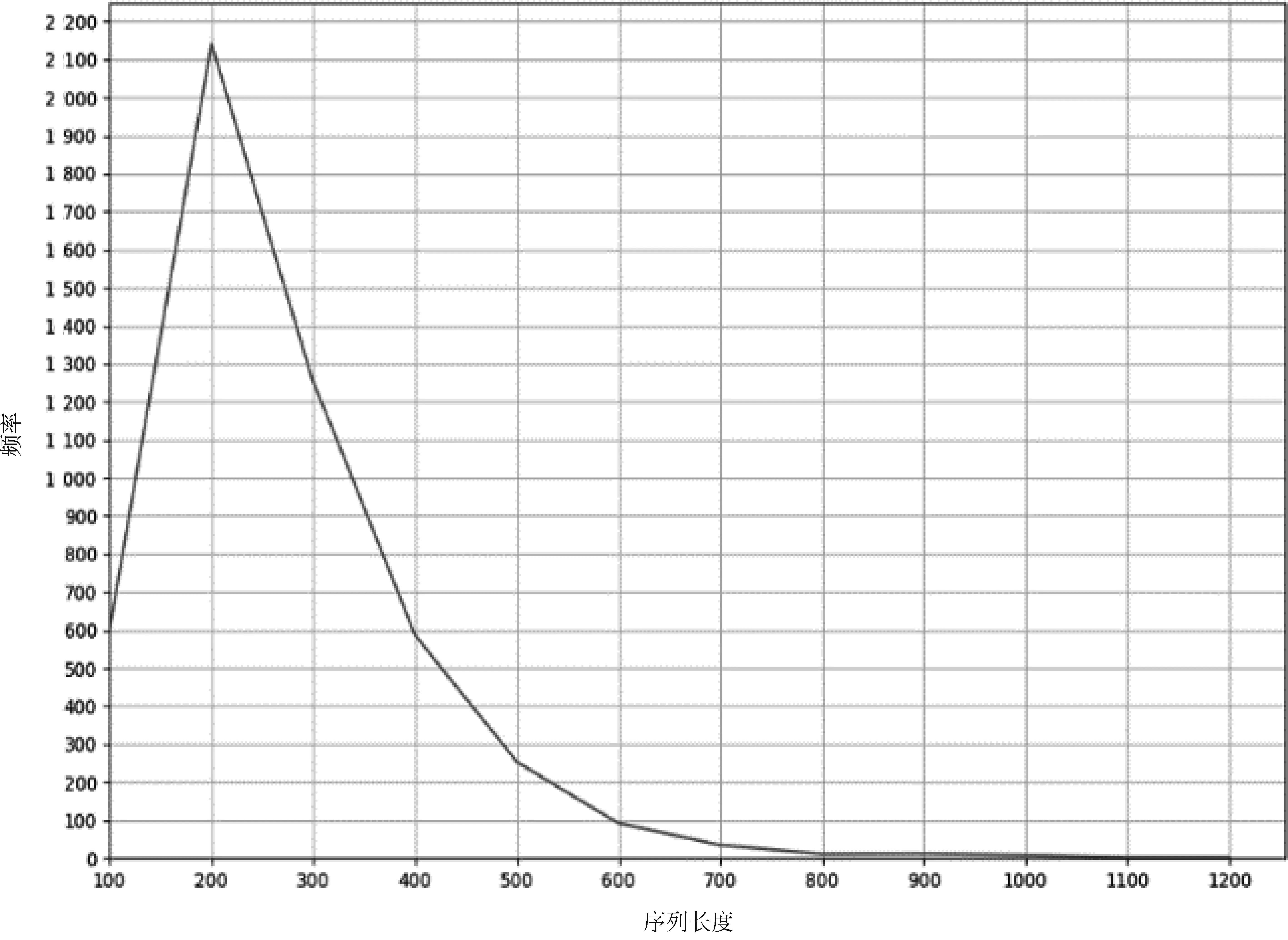
图3 数据正态分布
在绘制数据正态分布图时,使用句子长度区间作为该图的横坐标,因此在图3中μ值并不是曲线的最高点。为了全方面考虑不同句子长度对实验的影响,本文采用μ+nσ(n=0,1,2,3)的方式进行选择,代入μ、σ后分别获得217.2、344.6、472、599.4,在下文实验中采用上述长度的取整结果。
句子长度选择对比实验采用Albert+FC模型,其中FC为全连接神经网络(Fully Connected Network)。实验环境为搭配RTX 2080Ti GPU的Ubuntu服务器,显存为11GB,模型输入特征为词向量、位置向量与隐码向量。在此硬件环境下最大的批训练大小(batch_size)为8,句子长度选择对比实验结果如表3所示。
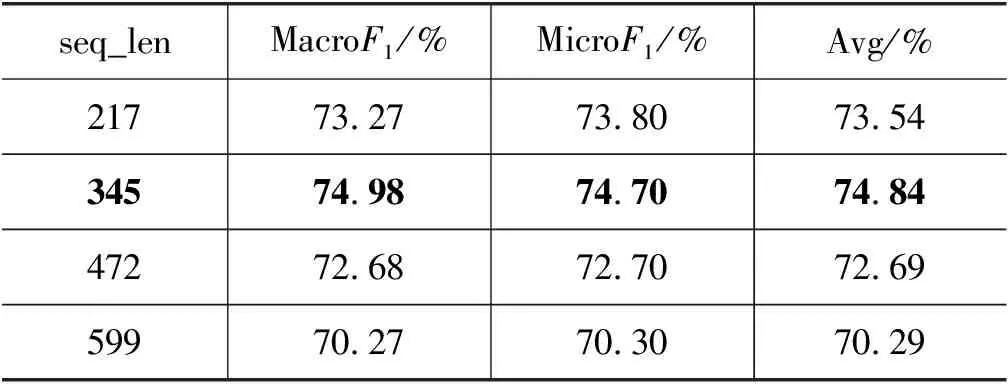
表3 句子长度选择对比实验
由表3可知,当seq_len为345时Albert+FC模型的效果最好,其MacroF1为74.98%,MicroF1为74.70%,平均F1值为74.84%,因此选择345作为下文实验的句子长度。
在实验部分,首先使用基线模型进行藏文实体关系抽取,再使用Albert模型结合基线模型进行对比实验,Albert模型及基线模型参数如表4与表5所示。
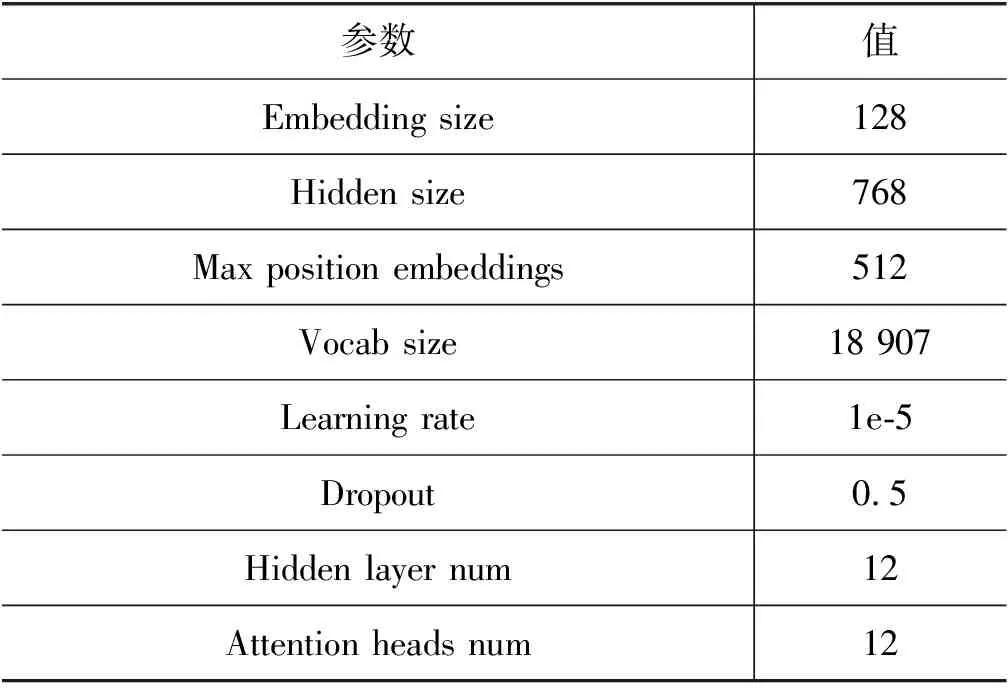
表4 Albert模型主要参数

表5 基线模型主要参数
4.2 结果分析
在基线实验部分,分别采用循环神经网络(Recurrent Neural Network, RNN)[16]及其变体、卷积神经网络(Convolutional Neural Network, CNN)[17]、深层卷积神经网络(Deep Pyramid Convolutional Neural Networks, DPCNN)[18]、区域卷积神经网络(Region-CNN, RCNN)[19]及GraphSAGE模型;在Albert实验部分,分别使用上述模型结合Albert模型。为了更好地进行对比,Albert实验与基线实验构建词向量的方式相同,即通过词典构建,以上实验均按照音节分词方式处理数据。
4.2.1 基线实验结果分析
表6中(O)与(H)分别表示使用当前模型的output及隐藏层输出进行关系分类,CNN模型效果最好,其MacroF1为75.20%,MicroF1为75.40%,优于第一部分实验中的所有序列模型;RNN(O)模型效果最差,其MacroF1为8.30%,MicroF1为11.20%;RNN及BiRNN模型整体效果比较差,主要原因是基线实验的词向量仅使用词典构建,未通过高效的模型对其进行学习,并且RNN模型自身具有梯度弥散与梯度爆炸的问题,导致模型效果差。

表6 基线实验第一部分实验结果 (单位: %)
由于本文数据集大多为短句且通过词典构建的词向量不能携带较多的句子信息,而CNN模型以n-gram[20]方式学习特征,因此DPCNN实验结果低于CNN模型,两者平均F1值相差11.00%。另外,在上述基线实验中,BiRNN及BiLSTM模型效果均优于单向RNN及LSTM模型;而单向GRU模型效果优于BiGRU模型,表明对于不同任务,模型的单双向选择效果也是不同的。针对这一不定性,RCNN模型实验将探究表6中的所有RNN及其变体模型,结果如表7所示。
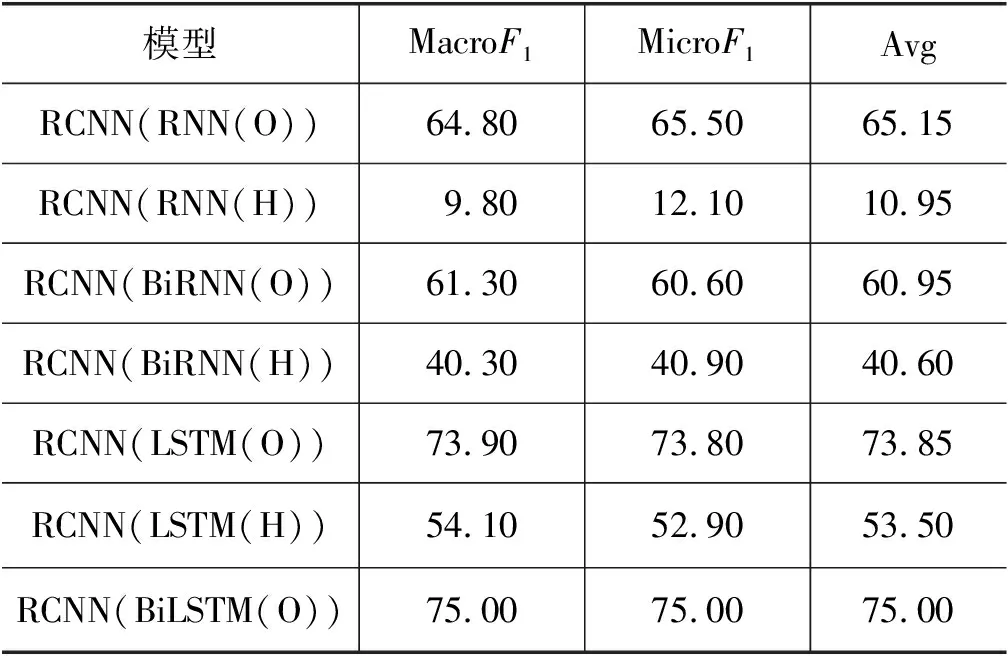
表7 基线实验第二部分实验结果 (单位: %)
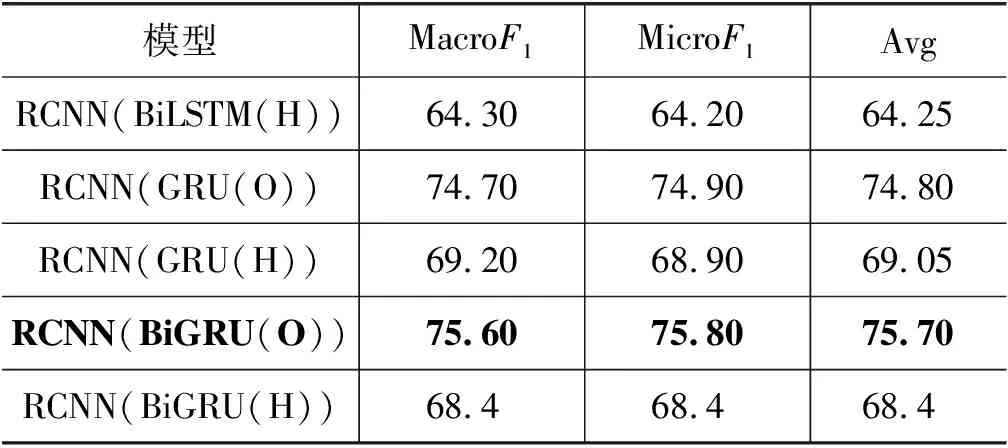
续表
表7中RCNN(BiGRU(O)) 模型表示RCNN模型采用BiGRU模型作为序列模型,该模型效果最好,其MacroF1为75.60%,MicroF1为75.80%,且相对CNN模型在F1值上提升0.40%。表明对于序列学习任务,首先使用序列模型学习藏文句子特征,提取句子中的重要信息,再通过CNN模型的卷积与池化操作可以加深模型对于句子的理解与学习。表8为基线实验高效模型结果对比。

表8 基线实验高效模型结果对比 (单位: %)
由图4与表8可知,GraphSAGE模型在所有基线实验中效果最 优, 其MacroF1为77.9%,MicroF1为78.09%,较RCNN(BiGRU(O))、CNN模型F1值提高2.30%与2.70%。GraphSAGE模型对图节点进行采样与聚合操作后可以学习到藏文文本中更多有效的信息,从而提高模型的准确率。同时通过图4中连续的折线变化了解到添加RCNN模型后,不同序列模型使用output作为输出时,关系分类实验效果更好。

图4 基线实验所有模型结果
4.2.2 Albert实验结果分析
下文结果均为Albert结合表中模型实验获得。例如,表9中RNN(O)表示Albert模型结合RNN模型,其中RNN模型以output作为输出,下文表中的模型同理。
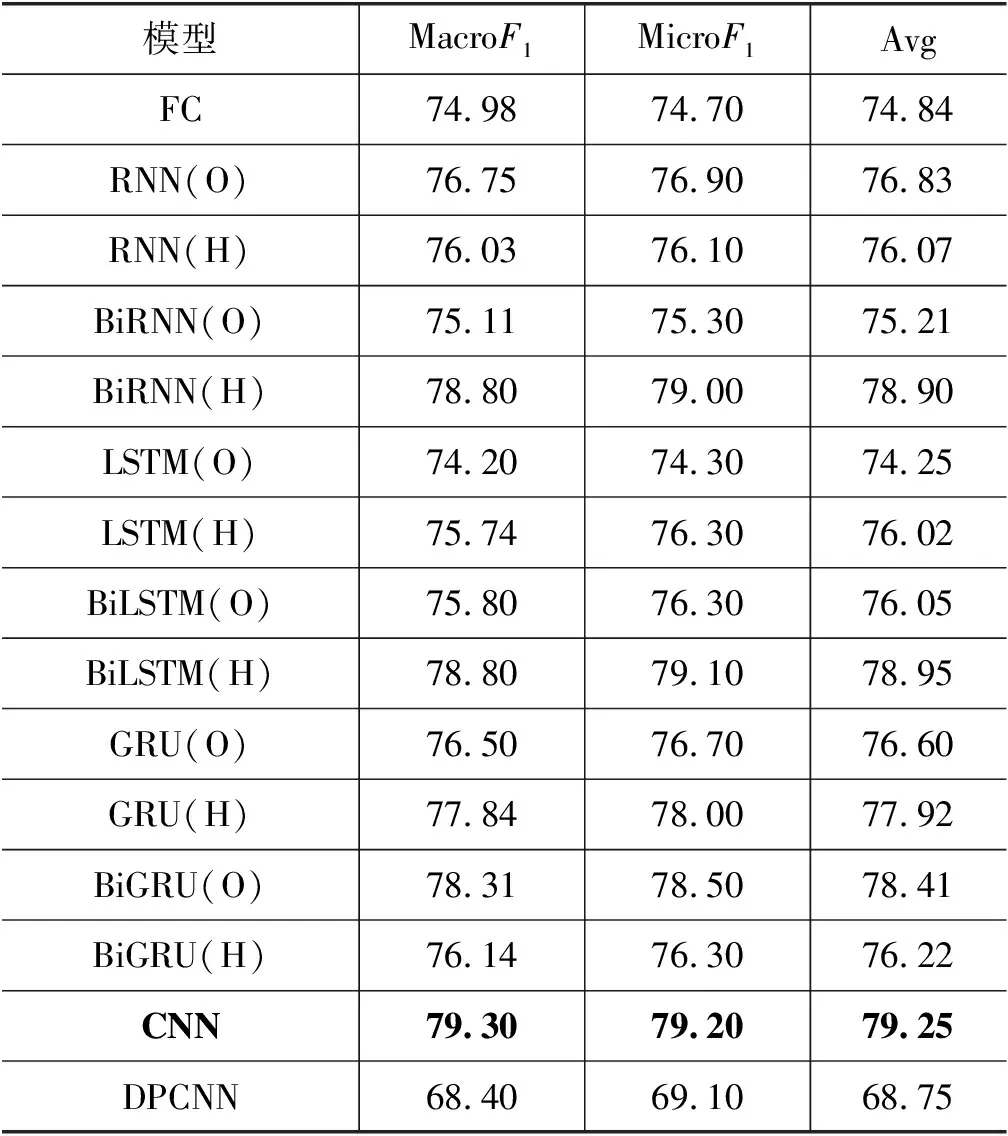
表9 Albert第一部分实验结果 (单位: %)
由表9可知CNN模型效果最好,其MacroF1与MicroF1分别为79.30%与79.20%,这表明传统的浅层CNN模型可以较好地学习藏文Albert预训练语言模型生成的句子动态词向量,而与浅层CNN模型相反的DPCNN模型在实验中表现效果最差。同时在所有序列模型中,BiLSTM(H)模型表现最好,其MacroF1与MicroF1分别为78.80%与79.10%,平均F1值低于CNN模型0.30%,两模型效果相近,主要原因是以隐层作为输出的BiLSTM模型可以更加高效地学习Albert生成的词向量,使得学习后的参数矩阵携带更多有效的句子信息。
在表10中,RCNN(BiGRU(H))模型表现最好,优于表9中的CNN模型,该模型的MacroF1与MicroF1分别为79.95%与80.0%,平均F1值高于CNN模型0.73%。表明使用序列模型学习Albert生成的句子动态词向量后,再使用CNN模型提取特征,可提高实体关系抽取模型的准确率。
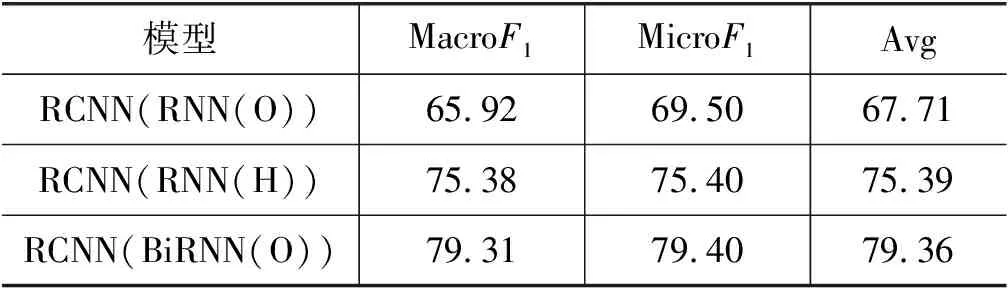
表10 Albert第二部分实验结果 (单位: %)
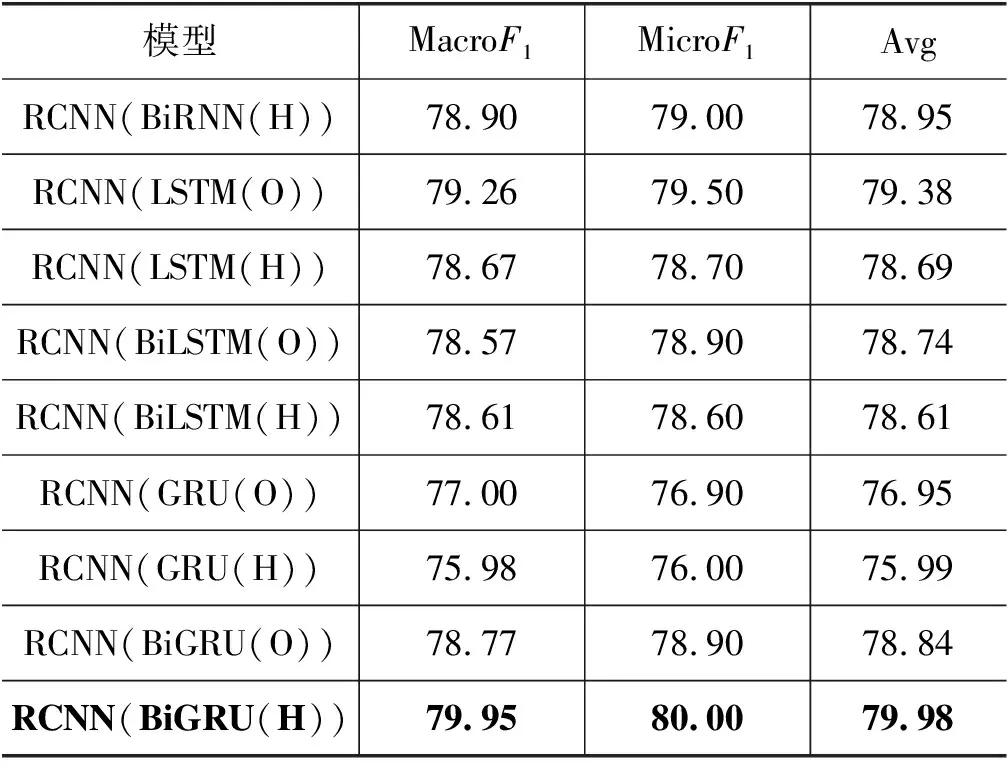
续表
分析表9与表10可以发现,LSTM(O)、DPCNN及RCNN(RNN(O))模型效果低于FC模型,主要原因是Albert模型使用12层Transformer学习词向量特征,并且模型自身结构十分复杂,因此连接简单的FC模型可以更高效地完成实体关系抽取任务,对于较复杂的模型则会适得其反。
由表11可知,GraphSAGE模型效果最好,平均F1值为82.25%,较RCNN(BiGRU(H))与CNN模型F1值提升了2.28%与3.00%。主要原因是使用藏文Albert预训练语言模型获得高质量的句子动态词向量,改善了一词多义及语义歧义问题。然后使用本文提出的方法将动态词向量表示为图结构与节点特征后作为GraphSAGE模型的输入,GraphSAGE模型不断地聚合邻居信息并进行迭代更新,以批训练的方式高效地学习图结构特征,从而提升了模型的准确率。
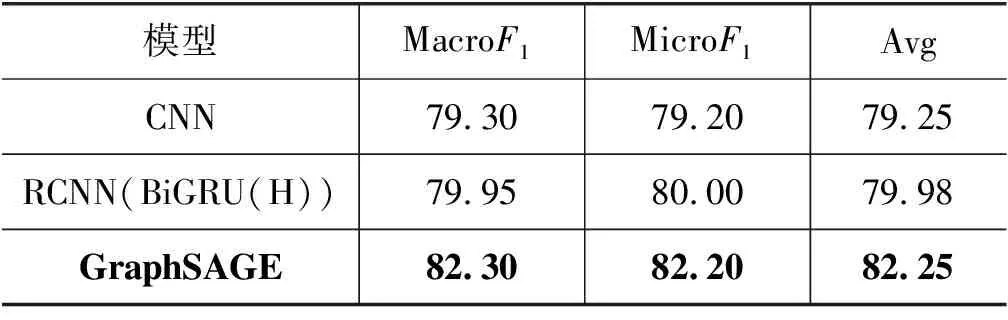
表11 Albert实验高效模型结果对比 (单位: %)
由图5可知,两类实验结果曲线整体趋势不同, Albert实验结果曲线较基线实验结果曲线更加稳定,前者并无过大波动,而后者波动较为明显;Albert实验结果均优于基线实验结果,并且在两类实验中GraphSAGE模型均获得了最优效果。根本原因是,通过Albert预训练语言模型获得的词向量质量较高,将此词向量输入不同的关系抽取器中可以减小词向量对实验结果的影响,所以Albert实验曲线更加稳定且结果优于基线实验,证明了本文训练的藏文Albert模型的有效性。GraphSAGE模型通过复杂图结构并结合采样与聚合操作表达与学习藏文文本句子特征,获得了更好的关系抽取效果,证明了本文提出的关系抽取数据表示为图结构数据方法的有效性。
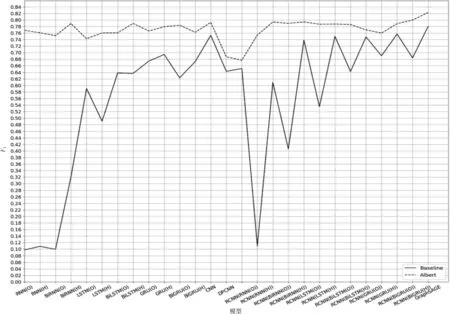
图5 所有实验结果对比图
5 总结与展望
本文主要介绍了基于藏文Albert预训练语言模型的图采样与聚合实体关系抽取方法,提出使用图结构进行藏文实体关系抽取任务,有效提升了藏文实体关系抽取模型的准确率。其中,藏文实体关系抽取数据集转化为图结构与节点特征的方法的效果良好,实验最终F1值为82.25%且优于基线实验效果。
但本文用于有监督学习的藏文实体关系抽取数据集规模较小,且在实验中并未考虑藏文词法、句法等特征。未来工作中,我们会扩大数据集规模并提升数据集质量,在提取藏文句子特征时还应加入依存句法分析等方法,从而提升藏文实体关系抽取任务的准确率。
