基于Self-Attention的句法感知汉语框架语义角色标注
2022-01-01王晓晖王智强柴清华韩孝奇
王晓晖,李 茹,2,王智强,柴清华,韩孝奇
(1. 山西大学 计算机与信息技术学院,山西 太原 030006;2. 山西大学 计算智能与中文信息处理教育部重点实验室,山西 太原 030006;3. 山西大学 智能信息处理研究所,山西 太原 030006;4. 山西大学 外国语学院,山西 太原 030006)
0 引言
框架语义角色标注的主要任务是识别出句子中给定目标词所激起框架对应的框架元素,这些框架元素被赋予特定的含义,如施动者、受动者、时间、地点等。简单来说,就是“谁”在“什么时间”“什么地点”对“谁”做了“什么”。图1为汉语框架语义角色标注示例,其中,例句下方为句法依赖标签,例句上方的为语义角色标签。例句的目标词为“参观”,该目标词激起的框架为“拜访”,该框架有两个核心框架元素agt(施动者)和ent(实体),分别对应例句中的“我们”和“吴店镇”,而例句中的“实地”则标为manr(方式)。语义角色标注的应用非常广泛,在信息抽取[1]、问答系统[2]等领域取得了一定研究成果。
传统的语义角色标注方法多采用机器学习与特征工程相结合的方式。在这类方法中,通常依赖于人工抽取的特征,并且会带来模型复杂、特征稀疏等问题[3]。语义角色标注对句法有着较强的依赖性,如图1所示,对于目标词“参观”来说,通常其主语都被标注为“施动者”,宾语被标注为“实体”,而“方式”则通常为副词或介词短语作状语。因此,句法信息在一定程度上有助于语义角色标注。
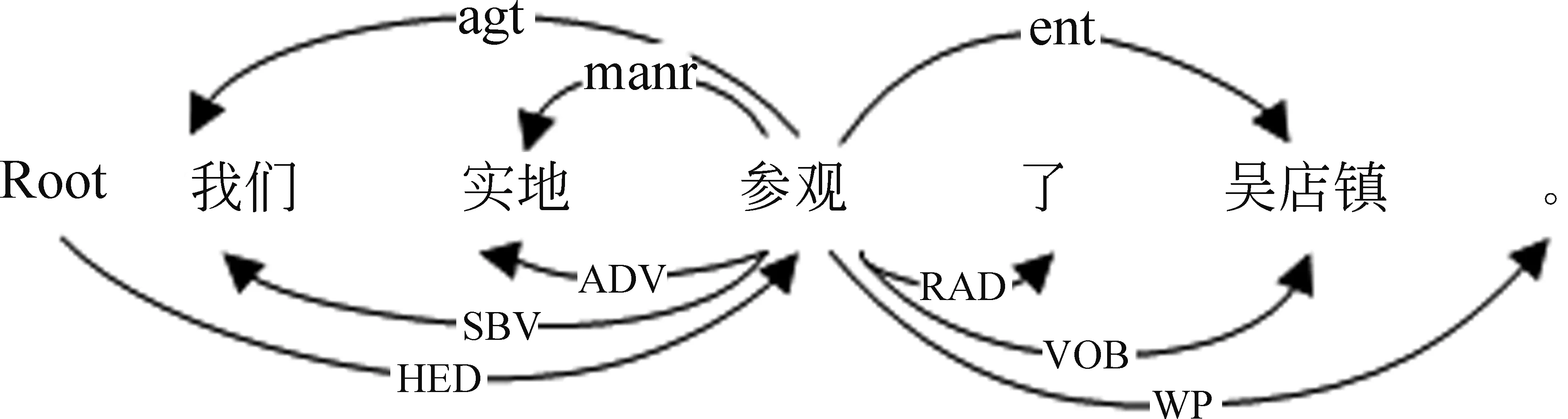
图1 汉语框架语义角色标注示例
近年来,深度学习方法逐渐被应用到自然语言处理任务中,它能自动学习文本中的特征,从而大大减少了特征工程总的工作量。特别地,Zhou和Xu[4]、He等[5]、Marcheggiani等[6]分别提出了无句法的语义角色标注模型,并且取得了较好的效果。这似乎和句法信息是高性能语义角色标注的前提条件的观点相冲突。但是,句法信息被认为与语义关系密切,在语义角色标注任务中发挥着至关重要的作用[7]。Marcheggiani和Titov[8]提出了图卷积网络模型,以相对较好的句法分析器作为输入,进一步提高了语义角色标注的性能。
由于Bi-LSTM可以有效地获取句子中的长距离依赖信息,在序列标注任务中有着天然优势。因此,现有的语义角色标注模型大多基于Bi-LSTM模型。但Bi-LSTM却无法很好地获取句子的句法信息,而近年来同样在自然语言处理领域广泛应用的自注意力(Self-Attention)机制却可以更好地处理这个问题。因此,本文在Bi-LSTM的基础上引入Self-Attention机制。同时,在序列标注任务中标签之间是有依赖关系的,如在BIO标注模式中,标签I应出现在标签B之后,而不应该出现在O之后,所以本文利用CRF进行全局标签优化预测出最优标签序列。
1 相关工作
语义角色标注是由Gildea和Jurafsky[9]在2002年提出的,同时在人工标注的FrameNet语料上提出了基于统计的分类器。已有的汉语语义角色标注方法有两类,分别是基于特征工程的方法和基于神经网络的方法。
在早期的语义角色标注工作中,大多研究都致力于特征工程。Gildea和Jurafsky[9]在没有大规模语义标注语料库的情况下对汉语语义角色标注进行了初步的研究,取得了显著效果。Xue[10]在中文PropBank(CPB)上将最大熵分类器和特征工程相结合,同时将标准的句法分析和自动句法分析分别加入到特征工程中,实验表明,汉语句法分析的性能是实现高效语义角色标注的关键;李济洪等人[11]基于CRF在CFN数据集上进行语义角色标注研究,分别取得了63.65%和61.62%的F1值;王[12]基于最大熵模型分别使用词层面和块层面特征实现了汉语框架语义角色标注;屠寒非等[13]提出了一种基于主动学习的方法,当数据规模相同时,实验结果最高提升了4.83%,同时,达到同等F1值时最高可减少30%的人工标注量。
随着深度神经网络模型在自然语言处理领域的诸多任务上得到成功应用,一系列基于神经网络的语义角色标注模型被提出。Ronan和Jason[14]提出了使用单一的卷积神经网络结构进行包括语义角色标注任务在内的多任务学习模型,整个网络共享权重,代表了一种新的共享任务半监督学习形式;王臻等人[15]将语义角色标注分为角色识别和角色分类两个步骤,利用分层输出的神经网络模型取得了64.19%的F1值。Wang等[16]提出了基于异构数据的Bi-LSTM模型,可以更方便地缓解单个标注语料库的可扩展性问题,在CPB数据集上取得了77.59%的F1值;党[17]基于词分布的汉语框架语义角色标注模型实现了72.89%的F1值;王瑞波等[18]基于分布式表示,提出了一种多特征融合的神经网络结构,同时使用Dropout正则化技术有效地缓解了模型的过拟合现象,使得模型的F1值提高了近7%。
最近,人们尝试构建基于span的无句法输入的端到端语义角色标注模型[4,19-20]。尽管无句法信息的的模型取得了成功,但是仍有许多研究致力于如何将句法优势应用到语义角色标注中。Roth 和Lapata[21]将复杂的句法结构和句法相关现象看作是句法依赖路径的子序列,并将深度Bi-LSTM应用到语义角色标注中,在PropBank数据集上取得了较好的效果;Qian[22]提出了SA-LSTM,以一种结构工程的方式对整个句法依赖树结构进行建模。
目前,大部分性能较好的语义角色标注模型都是基于Bi-LSTM的,但Bi-LSTM无法很好地获取句子的句法信息。近年来,注意力机制在自然语言处理领域广泛应用,受到He等[23]和Zhang等[24]的启发,本文引入Self-Attention机制,将其加入到词表示和Bi-LSTM编码器之间,同时使用条件随机场进行标签预测。
2 基于Self-Attention的语义角色标注
本文将语义角色标注任务转换成序列标注问题,给定一个句子序列及其目标词,在目标词所激起框架已知的条件下,识别出句子中与目标词所搭配的语义角色。即: 给定句子X=(w1,w2,w3,…,wn)和其目标词wtarget(1≤target≤n),输出角色标签序列Y*=argmaxp(Y|X,wtarget,frame)。图2为本文的模型结构,它由三个模块组成: ①Self-Attention层: 对句子中各词的语义重要性进行建模; ②Bi-LSTM编码层; ③CRF标签预测层。
2.1 词特征向量表示
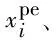
2.2 Self-Attention层
在语义角色标注任务中,通常对句法的依赖性较强,但是Bi-LSTM模型虽然擅长获取句子中的长距离依赖信息,却不能很好地提取句法信息。因此本文在词表示和Bi-LSTM编码层之间引入Self-Attention机制捕获句子中每个词的句法信息,同时还可以进一步增强Bi-LSTM获取长距离依赖信息的能力。
将词表示矩阵X映射为不同的表示K,Q,V,首先对Q和K执行点积操作,并对其进行缩放操作,如式(1)所示。再对其执行softmax操作进行归一化,得到句子中每个词之间的注意力权重ai。最后,将注意力权重ai点乘V并求和,得到每个词的表示矩阵A。
2.3 Bi-LSTM编码层
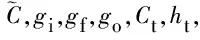
(4)
gj=sigmoid(Wjzt+Ujht-1+bj),j∈{i,f,o}
(5)
(6)
ht=go⊙f(Ct)
(7)
2.4 CRF标签预测层
我们在Bi-LSTM编码层之后,添加一层CRF进行标签预测。因为在序列标注问题中,相邻词的标签间存在很强的依赖关系,单独考虑每个词的标签得分是不合适的。所以使用CRF对整个序列进行全局归一化,得到概率最大的最优序列。
假设输入序列为X=(x1,x2,…,xn),输出序列为y=(y1,y2,…,yn),约定H是Bi-LSTM层的输出矩阵,而Hi,j对应于句子中第i个单词的第j个标签的得分。那么,它的得分定义如式(8)所示,其中,S是标签的转移得分矩阵,Si,j表示从标签i到标签j的转移得分。
对于输出序列y所有可能的标签序列的概率的softmax形式如式(9)所示,其中,YX表示输入序列X的所有可能的标签序列。在解码时,我们通过式(10)预测输出序列。
3 实验设计与分析
3.1 实验数据
本文实验数据来自汉语框架网例句库,该例句库的标注数据由人工标注。本文选取其中的25个框架658个词元共19 355条标注数据。本实验将上述数据按框架分割成训练集、验证集、测试集,分割比例为6:2:2。
3.2 评价指标
本文使用准确率(Precision,P)、召回率(Recall,R)、F1值作为评价指标。具体如下:
3.3 实验设置
使用Glove在CFN例句库上预训练的词向量,词向量维度为100。词性、句法路径特征等特征的维度为10,其中,使用LTP(语言技术平台)进行句法分析。此外,其它超参数设置为学习率learning_rate=0.015,丢弃率dropout=0.5,隐藏层个数hidden_dim=200,优化函数为SGD(随机梯度下降),正则化系数L2=1e-8。
3.4 实验结果与实验分析
为了验证Self-Attention机制的效果,设置了两个对比实验: BLC和BLAC,前者未引入Self-Attention机制,后者将Self-Attention机制加入到Bi-LSTM编码器之后,实验结果如表1所示。首先,无句法路径特征时, 本文模型ABLC比BLAC和BLC分别提高了7.39%、4.49%,而加入路径特征时,ABLC比BLAC和BLC分别提高了5.94%、3.98%;其次,本文的ABLC模型比BLAC的性能分别高了2.9%和1.96%。因此验证了本文模型引入Self-Attention机制在汉语框架语义角色标注任务中的有效性。此外,引入Self-Attention机制后,即BLAC和ABLC,加入句法路径特征对结果提升不是很明显,分别提高了0.92%和-0.02%,表明本文模型可以获取一定句法信息。

表1 Self-Attention在不同位置的实验结果 (单位: %)
为了分析不同路径特征对实验结果的影响, 本文分别使用了三种不同的路径特征进行实验, 结果如表2 所示。 总体而言, 使用一级路径特征的实验结果相对较好。
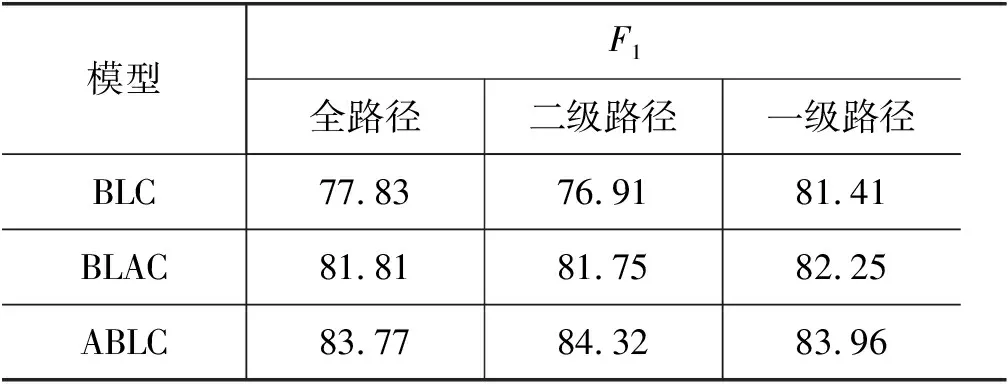
表2 不同路径特征的实验结果 (单位: %)
由于数据稀疏对实验的影响,本文对利用框架关系对实验数据的扩充进行初步探索。本文使用两种方式进行数据扩充。将目标框架的数据与关系数据的train、dev分别合并后作为扩充数据的train、dev,扩充后的数据集称为Data1;为了验证扩充数据在无例句的框架中的性能,将关系数据的train、dev作为扩充数据的train、dev,称为Data2。
除[放置]框架外,其他框架在扩充数据集Data1上均可以提升目标框架的实验结果,表明利用框架关系扩充实验数据可以提高汉语框架语义角色标注的性能。同时,在Data2上的实验结果略微于原始数据的结果,因为在CFN中,核心框架元素是框架自身个性的体现,当框架之间的核心框架元素存在较大差异时,也会对实验结果产生影响。但实验结果表明,利用框架关系扩充无例句框架数据集可以在一定程度上帮助,无例白框架进特框架语义角色注。
表3为汉语框架语义角色标注中的句法路径特征示例,“母子”、“俩”同属框架语义角色“args”,二者的一级句法路径特征均为“HED->SBV”;同理,“为”、“些”、“小事”的一级句法路径特征为“HED->ADV”,对应汉语框架语义角色标签“issue”。由此可见,一级句法路径特征与框架语义角色块有较强的相关性。另外,从表2中可以看出,不同路径特征对基线模型BLC的性能影响较大,而引入自注意力机制的BLAC模型和ABLC模型的性能受句法路径特征的影响较小。进一步证明了本文模型可以更好地获取一定的句法信息。

表3 句法路径特征示例

续表

表4 扩充数据上的F1值 (单位: %)
为了分析本文模型对句子中长距离依赖的影响,记录了不同的角色与目标词的距离集合的F1值,如图3所示。从图中可以看出,所有距离的F1值都得到了改进。这表明了我们的模型在引入Self-Attention机制后可以增强模型捕获长距离信息的能力,进而提升汉语框架语义角色标注性能。
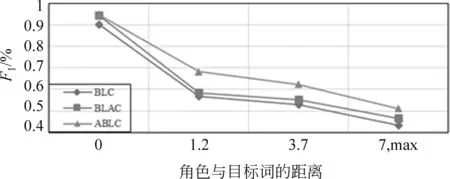
图3 不同角色与目标词距离上的F1值
4 总结
本文提出了一种基于Self-Attention机制的句法感知汉语框架语义角色标注模型,同时,本文利用框架关系对实验数据进行扩充,以减少数据稀疏对语义角色标注的影响。实验结果表明,本文模型的实验结果较之前模型中有了显著提升,并且验证了本文模型可以获取一定句法信息;同时,利用框架关系对数据进行扩充,有助于缓解汉语框架语义角色标注中的数据稀疏问题,尤其对无例句框架的汉语框架语义角色标注的帮助更大。此外,在未来工作中,在更好地融入句法信息以及数据稀疏方面还有很多工作需要完成。
