句法分析中基于词汇化树邻接语法的数据增强方法
2022-01-01陈鸿彬张玉洁徐金安陈钰枫
陈鸿彬,张玉洁,徐金安,陈钰枫
(北京交通大学 计算机与信息技术学院, 北京 100044)
0 引言
句法分析作为自然语言处理的基础技术,其精度的提高对于机器翻译[1]和语义角色标注[2]等自然语言处理任务的应用至关重要。现在主流的神经网络句法分析模型依赖大规模的标注数据,其精度受限于人工标注树库的规模和质量,目前普遍缺乏足够的汉语标注树库。为了提高句法分析模型的精度和鲁棒性,研究人员开始研究如何利用现有的标注树库进行数据增强[3-4]。
数据增强是指利用有限标注数据自动生成大量的标注数据,以提升现有模型精度和鲁棒性的一种技术[5]。现有自然语言处理的数据增强技术通常是为了提高文本分类[5]和机器翻译[6-7]等任务的精度和鲁棒性而发展起来,这些任务的数据增强目标通常是生成同语义不同表达方式的句子。但是在句法分析的数据增强任务中,我们关注的是词汇和短语的句法标注信息,生成句只要语义合理即可[8],不需要与原句保持相同的语义。因此,在句法分析中的数据增强任务上,对于给定的标注树库,数据增强方法所生成的句子应满足如下两个条件: 第一,要求生成句具有多样化且完整的句法树结构;第二,要求生成句具有合理的语义。对此,我们首次提出基于词汇化树邻接语法的数据增强方法,该方法由两部分组成,分别用于解决这两个需求。其中,针对第一个需求,我们提出利用词汇化树邻接语法进行解决,词汇化树邻接语法是计算语言学中的一种重要形式语法,基于该语法可以在句法树之间进行“接插”和“替换”的操作,从而推导生成新的句法树,并且用语言学的知识保证其生成的句法树符合语法规则且具有正确的句法结构标注。针对第二个需求,我们提出基于语言模型的生成句语义合理性评估方法,利用语言模型对生成句进行语义合理性评估,从而选出语义合理的句子作为最终的增强数据。我们通过这两种方法分别解决句法分析中数据增强的两个问题,并使用增强数据的方法提高汉语句法分析模型的精度和鲁棒性。
本文组织结构如下: 第1节介绍相关研究;第2节介绍词汇化树邻接语法;第3节介绍基于词汇化树邻接语法的数据增强方法的实现;第4节介绍所构建的增强数据在句法分析上的评测实验和实验结果分析;第5节对本文研究进行总结。
1 相关研究
现有的数据增强技术通常从文本分类[5]和机器翻译[6-7]发展而来。在文本分类和机器翻译中,为了使得数据增强方法所生成的句子也适用原来的分类标签或者译文,要求生成句和原句在语义上相近。因此,已有的数据增强方法为保证生成句和原句具有相似的语义,主要采用回译、随机词替换和非核心词替换等方法。回译的原理是利用已有的机器翻译模型,将其中一种语言的句子翻译到一个中间语言,再从中间语言翻译回去,由此获得与原有句子相同语义但具有不同表达的数据,从而提高模型的精度和鲁棒性[6-7]。随机词替换的数据增强方法包括同义词替换、随机插入、随机交换和随机删除等词级别编辑操作,主要解决文本分类中样本分布不均或者样本过少的问题[5]。由于随机词替换太过随机,容易将一些关键词进行错误替换或删除,导致生成句与原句的语义相差太大。针对此问题,Xie等人提出一种非核心词替换的方法,该方法使用TF-IDF衡量一个词对于一段文本的重要性,计算字典中每个词的TF-IDF值,再根据TF-IDF值决定是否替换该词,从而避免删除或替换掉某些关键词,确保生成句更好地保持原有的语义[9]。
但是,句法分析的数据增强任务有其特殊性,对于给定的标注树库,要求数据增强所生成的句子满足如下条件: ①要求生成句具有多样化的表达、完整的句法树结构和正确的句法树结构标注; ②要求生成句具有合理的语义。因此,由于此处数据增强的需求存在差异,当现有的数据增强技术应用于句法分析的标注树库时,会造成生成句的句法树结构和语义遭到破坏,引入过多噪声,从而影响句法分析模型的精度。对此,针对句法分析中数据增强的特殊需求,Zheng等人[8]使用英文的依存句法分析数据集,利用对抗学习的方法,选取句中最容易导致依存关系错误的词,进行同词性的词替换,生成对抗样本以提高依存句法分析模型的鲁棒性。我们针对汉语树库,提出基于词汇化树邻接语法数据增强方法,通过词汇化树邻接语法保证生成句具有多样化且完整的句法树结构标注。同时,通过利用语言模型对生成句进行语义合理性评估,选取语义合理的句子作为最终的增强数据,从而满足句法分析中数据增强任务的两个需求。
2 词汇化树邻接语法
句法分析从本质上说是一个句法结构的识别问题,即按一定的语法规则对句子进行识别解析,构成句法树。早期的句法分析需要语言学专业的学者人工对句子进行句法分析,构造句法树。该方法人工成本高,并且不同语言的语法不尽相同,构建树库的过程十分烦琐。针对该问题,学者提出先构造巨大的词汇化树库,通过在词汇化树之间进行“替换”和“接插”的操作,进而生成句法树,最终构建大规模树库。所以词汇化树邻接语法(Lexicalized TreeAdjoining Grammar,LTAG)越来越受到计算语言学界的重视[10]。
2.1 词汇化树邻接语法的表示
词汇化树邻接语法作为当代形式语法理论中的一种重要语法,在机器翻译[11]和信息提取[12]等任务中有众多应用。它从树邻接语法 (Tree Adjoining Grammar, TAG )演化和发展而来,LTAG在TAG的基础上将初始树和辅助树都与某个或某些具体的单词关联起来,提高句法树生成的精确度和效率,是近年计算语言学研究的重大成果之一,其理论以简洁的树形结构表示形式描述了复杂的语言现象[13]。
LTAG可以用一个五元组(VN,VT,S,I,A)[14]来表示,其中:
(1)VN为非终结符;(2)VT为终结符,即语言中的单词;(3)S为起始符号,它是一个特殊的非终结符,S∈VN;(4)I为初始树(Initialtree,简称I树)的有限集合,它有两个特征:
① 所有的非叶子节点用非终结符号标记。
② 所有的叶子节点,用终结符号(单词)标记,或者使用带下箭头(↓)的非终结符号标记,表示该节点可以被其他树结构替换。
(5)A为辅助树(Auxiliarytree,简称A树)的有限集合,它有三个特征:
① 所有的非叶子节点用非终结符号标记。
② 有一个用于“接插”操作的“足节点”(footnode),该节点带有星号(*)标记。除了足节点外,其他叶子节点都用终结符号或者使用带有下箭头(↓)的非终结符号标记。
③ 辅助树的足节点和根节点的符号相同。
下面以如图1所示的一组基础树来说明LTAG的五元组。
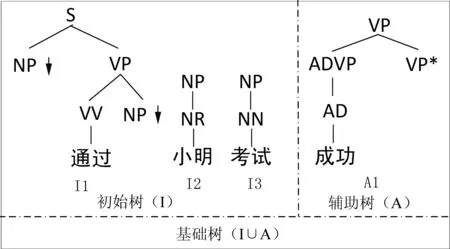
图1 词汇化树邻接语法中的基础树
在图1中,以左边的初始树集合为例,非终结符有S、VP、NP、VV、NR和NN,因为这些节点都有各自的孩子节点,而NP↓是特殊的非终结符,表示该节点可以作为替换节点进行LTAG中“替换”的操作。“通过”“小明”和“考试”这些单词都是叶子节点,都属于终结符,这些词汇化树都符合初始树的两个特征。在右边的辅助树中,它和初始树的区别是有一个带(*)的足节点(VP*),并且与其根节点的VP有一样的句法标签,该节点可以进行LTAG中的“接插”操作。同时,如果一个初始树的根节点为X,我们就称它为X类型的初始树,如I1的根节点为S,我们就称I1为S类型的初始树,辅助树同理。
2.2 词汇化树邻接语法的操作
在词汇化树邻接语法中,它定义了两种语法操作,分别为“替换”和“接插”,通过这两种操作,可以将基础树推导合成为完整的句法树,下面以图2和图3两个例子详细描述这两种操作。
替换操作:如图2所示,I3的根节点和I1的可替换节点拥有相同的句法标签NP,并且I1的NP是具有(↓)的可替换非终结符,因此将I3的根节点与I1的替换节点进行合并即可生成新的句法树,组合成新的短语。
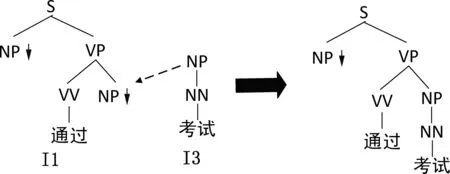
图2 词汇化树邻接语法的替换操作
接插操作:接插是将辅助树插到任何一棵树的过程,它包括三种动作,分别为“剪”“接”和“插”,用图3所示来描述这个过程。

图3 词汇化树邻接语法的“接插”操作
(1) 剪:S类型的初始树I1有一个非终结符为VP的子树,辅助树A1根节点为VP,并且有一个可以接插的足节点VP*,在I1中剪掉VP子树,只保留其根节点的语法标签VP,并将VP子树保存在副本VP′中,其根节点的语法标签也是VP。
(2) 接:副本VP′根节点与辅助树A1上标有“*”号的足节点具有相同的语法标签VP,于是将副本VP′接到辅助树带有“*”号的足节点上,形成一个新的辅助树A1′;(3) 插:将根节点为VP的辅助树A1′插到原I1上同为VP的节点上,从而完成整个接插过程。
通过这两种操作,我们可以在基础树集合中,从S类型的初始树I开始,然后不断地进行“替换”和“接插”操作,直到所有带替换标记的节点和带接插标记的节点都被成功替换和接插后,形成一棵完整的句法树;最后,再把所生成的句法树的叶子节点按顺序列出,即可获得该树邻接语法所生成的句子[15]。如图4所示,把“小明”和“考试”两个初始树I2和I3替换到S类型的初始树I1上,把辅助树“成功”也接插到I1,最后生成了句法树“小明成功通过考试”。同时,词汇化树邻接语法所定义的这些操作都是基于基础树中各子树已有的语法标签进行,当我们把这两种语法操作应用于不同的基础树集合之间时,不仅能够生成更多样化的句法结构,而且能够保证生成的句子具有完整的句法结构和正确的句法标签。如图4所示,在另一个基础树集合有“小红”和“高架桥”两个以句法标签NP为根节点的名词短语,我们即可将其拿来对当前的句法树进行替换,从而生成新句子“小红成功通过高架桥”,该句法树不仅有完整的句法树结构,还具有全新的语义,最终达到数据增强的目的。

图4 词汇化树邻接语法推导生成句法树的完整过程
3 基于词汇化树邻接语法的数据增强方法
我们设计基于词汇化树邻接语法的数据增强方法,其框架如图5所示。该方法包括两个部分,第一部分是基于词汇化树邻接语法句法树生成算法,这部分负责生成句法树,并通过词汇化树邻接语法来确保所生成句法树的多样性和完整性。第二部分是语言模型,当句法树生成之后,所对应句子会被输入到语言模型中,由语言模型来评估其句子的语义是否合理。本文中我们以句子的概率这一指标进行评估,选取语义合理的句子作为最终的增强数据。通过这两部分分别解决句法分析中数据增强的两个需求。最后经过数据转换模块将所生成的句法树转换为依存句法分析和成分句法分析所需要的数据格式。

图5 基于词汇化树邻接语法的数据增强方法框架
3.1 基于词汇化树邻接语法的句法树生成算法
3.1.1 词汇化树抽取算法
根据词汇化树邻接语法的定义,在进行“替换”和“接插”的操作之前,需要构建基础树集合,其中,基础树分为“辅助树”和“初始树”。给定的标注树库都是完整的句法树,因此在使用词汇化树邻接语法生成新句法树之前,我们需要先从当前的标注树库中抽取词汇化树,构建基础树集合,为后续推导生成新句法树做准备。
为了确保词汇化树邻接语法最后生成的句法树简洁并且符合语言特性,Xia等人为词汇化树的抽取定义了如图6所示的三种类型[16],在图6中,X、Y、Z和W都表示成分句法标签,POS为单词的词性标签。
中心树:该类型属于基础树中的“初始树”,如图6(a)所示,该树的锚点(带有词的节点)是X,然后经过X1、X2……归约到根节点Xm。Xi+1是Xi的父节点,它们一般是动词短语的句法标签,如VB或VP。在每一层,Xi和它的兄弟节点都是谓词关系,即有可能是主谓关系或者是动宾关系。
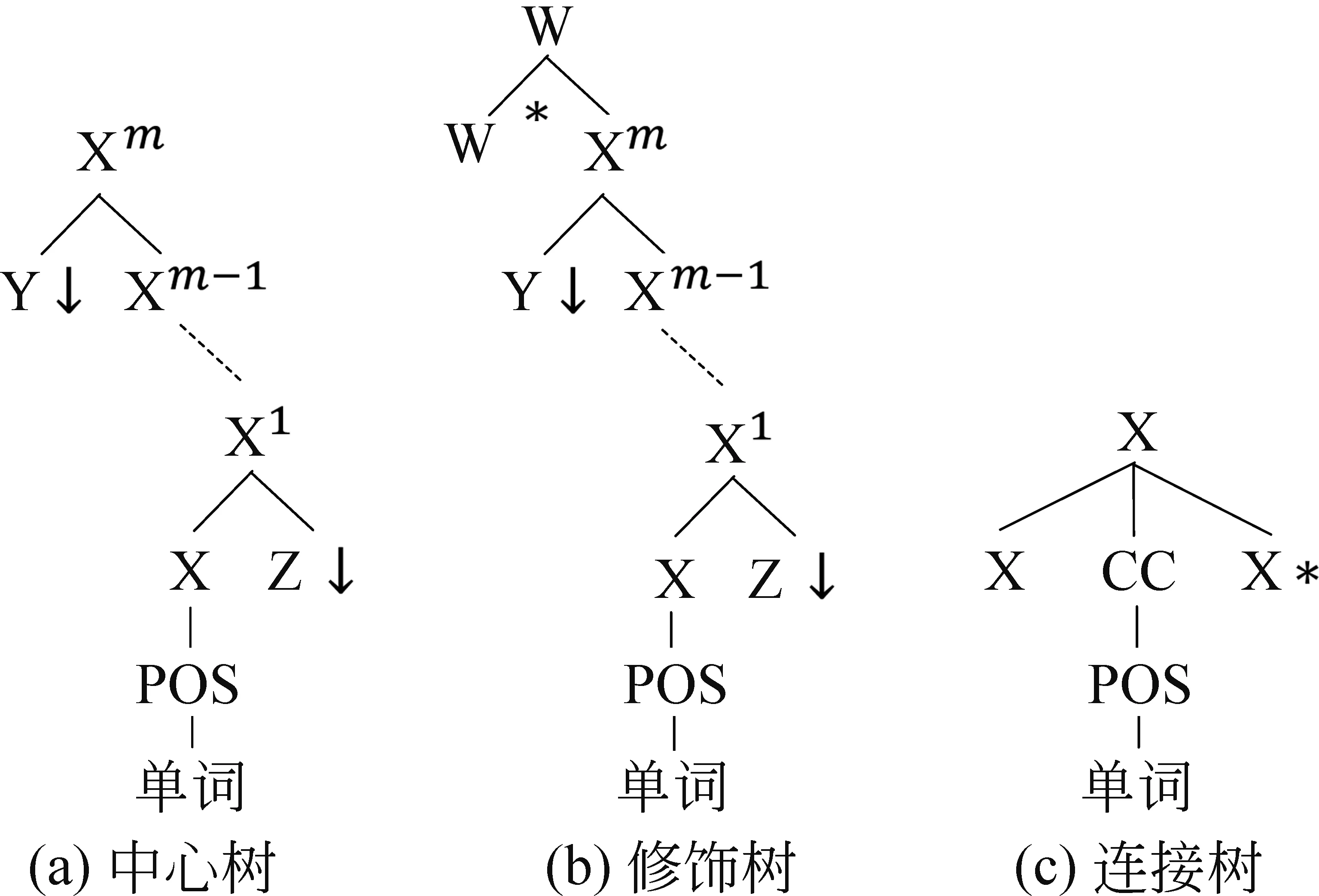
图6 词汇化树的类型
修饰树:该类型属于基础树中的“辅助树”,如图6(b)所示,这种类型的词汇化树要求根节点和一个孩子节点的成分句法标签相同,如图6(b)中的W*和W。
连接树:该类型属于基础树中的“辅助树”,如图6(c)所示,中间是一个连词,如“和”或者标点符号“、”等,连接两个并列成分。
本文的抽取算法主要关注中心树、修饰树和连接树,不符合这三种定义的子树归为普通初始树,如图7中的“小明”和“考试”这两个子树。初始树可根据其句法标签类型与其他具有相同标签类型的节点进行“替换”操作,生成新的句法树。
词汇化树的抽取算法首先从树的根节点出发,递归地遍历整个树,对当前节点进行谓语关系、修饰关系和连接关系的判断,并做相应抽取。三种判断所依据的句法标签定义如表1所示,具体的判断与抽取操作描述如下。

表1 谓语动词和连接词的句法标签集合
(1) 谓语关系:如果当前节点的句法标签X属于谓语动词。此时记录下从根节点到该节点的路径,并复制作为一棵中心树,然后将当前节点之外的其他节点的句法标签更改为↓作为替换节点。
(2) 修饰关系:如果当前节点只有一个兄弟节点,并且它在兄弟节点的左边修饰兄弟节点;同时该节点的句法标签与其父节点一样。此时记录下从父节点一直到叶子节点的路径作为一棵修饰树,然后将当前节点的句法标签W修改为W*,表示其作为足节点可以进行接插。
(3) 连接关系:如果当前节点有两个具有相同句法标签的兄弟节点,并且这两个兄弟节点中间还存在一个句法标签为连接词的兄弟节点。此时记录这三个兄弟节点与它们的父结点作为一棵连接树,保留连接树中间的连接词,而将当前节点和另一个兄弟节点的句法标签分别更改为↓作为替换节点。
3.1.2 句法树合成算法
当标注树库经过词汇化树抽取算法处理之后,标注树库中的每个句法树会形成一个词汇化树集合,该集合包含一组初始树I和一组辅助树A,I∪A统称为基础树,如图7所示。
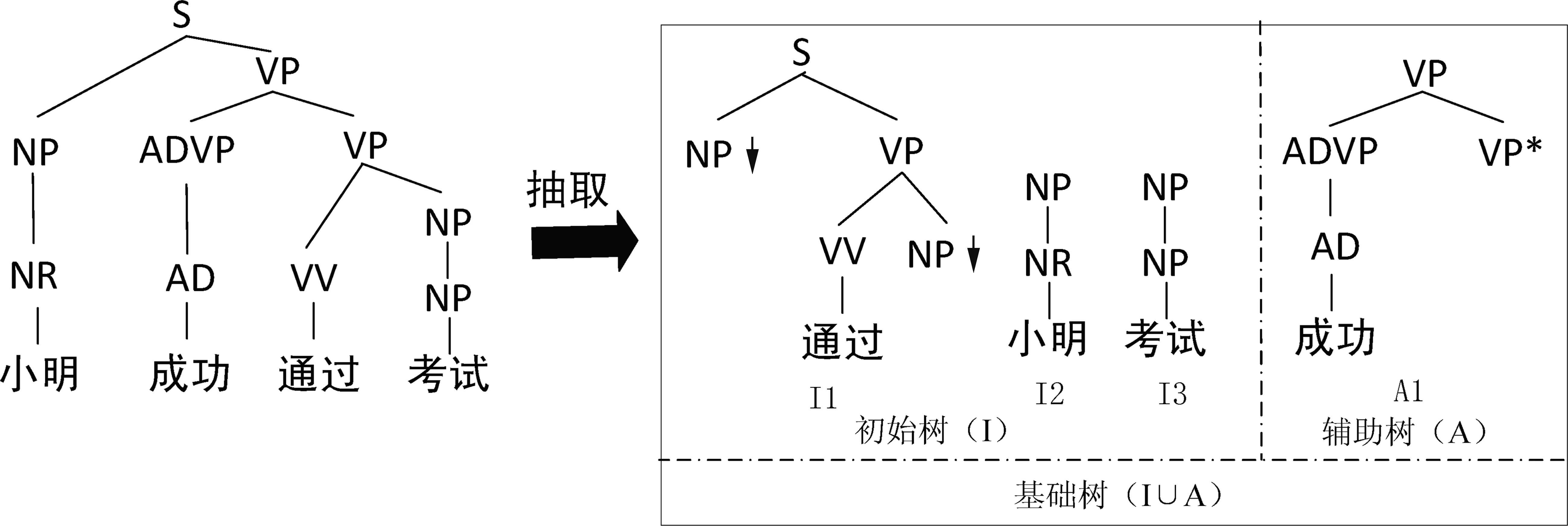
图7 词汇化树的抽取
在构建完基础树集合后,我们就可以利用词汇化树邻接语法,在不同句子对应的基础树集合之间进行“替换”和“接插”操作,从而生成新的句法树,如图8所示。
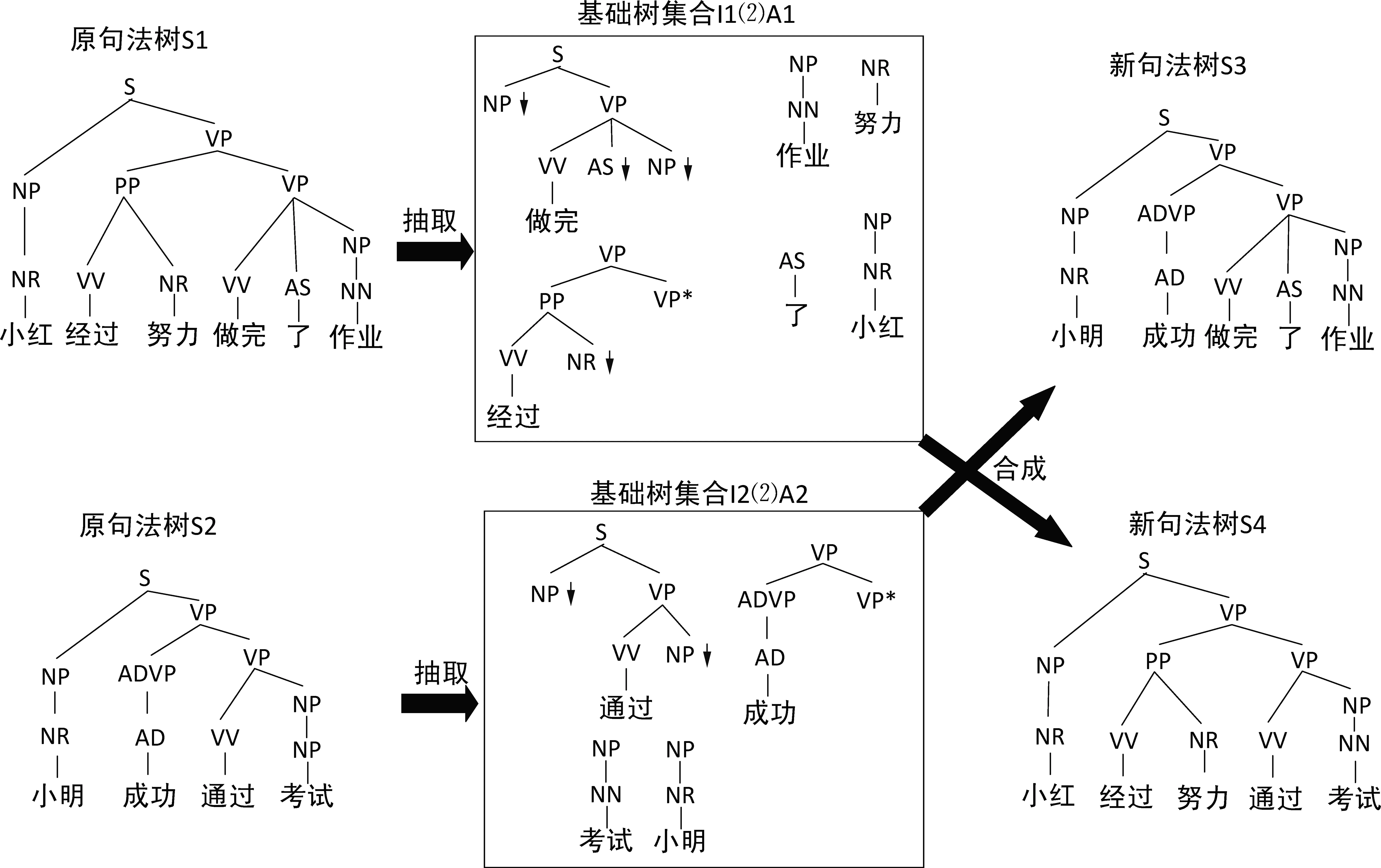
图8 不同基础树集合之间推导生成句法树
在图8中,原句法树S1=“小红经过努力做完了作业”,抽取获得基础树I1∪A1,其中 I1={做完,作业,努力,小红,了},A1={经过}。原句法树S2=“小明成功通过考试”,抽取获得基础树I2∪A2,其中I2={通过,考试,小明},A2={成功}。然后在两个基础树集合之间相互进行词汇化树邻接语法的“替换”和“接插”操作,即可生成新的句法树S3= “小明成功做完了作业”和S4= “小红经过努力通过考试”。可见,不同的基础树集合之间经过以上的操作,即可生成新的句法树,并且都具有完整的句法结构和正确的句法标注信息。基于这样两种操作,我们能够充分利用已有的标注树库自动生成具有句法结构多样且句法标注正确的句子,从而满足句法分析中数据增强的第一个需求。
3.2 基于语言模型的生成句语义合理性评估方法
3.2.1 语言模型
语言模型是一种基于概率的判别模型,通过计算一个句子的概率,判断一个句子的语义合理性[17]。换言之,就是判定句子在我们平常的自然语言表达习惯中有多大概率会出现这样的语言表达方式。因此,在语言模型中,一个句子的语义越合理,该句子出现的概率越接近于1,反之则越接近于0。在2.2节中,我们通过词汇化树邻接语法推导生成句子S1= “小明成功通过考试”,但是由于“小明”和“考试”都是名词短语,因此在推导过程中也可能生成S2= “考试成功通过小明”,显然,S2的语义是不合理的,因此在一个刻画我们日常表达的语言模型中,即可计算出P(S1)>P(S2),从而选取语义合理的句子作为我们最终的增强数据。
目前语言模型在具体的实现方式上分为概率统计语言模型和神经网络语言模型,虽然神经网络语言模型在解决数据稀疏等问题上比概率统计语言模型要好,但是概率统计语言模型以其高效的性能,仍有很大的应用空间。所以我们使用N-gram概率统计语言模型和RNN神经网络语言模型分别实现并进行对比分析。其中N-gram语言模型使用srilm语言模型工具进行建模和实验,RNN语言模型使用百度通过大规模网页语料训练所获得的DNN语言模型[18]进行实验。
3.2.2 语义合理性评估指标
语言模型计算一个句子的概率如式(1)所示,其中,s为当前句子,l为句子中单词的数量,p(wi∣w1w2…wi-1) 表示基于前i-1个单词计算得出的第i个单词的概率。P(s)表示整个句子的概率,P(s)越大,表明这个句子越合理。
P(s)=p(w1w2…wl)
(1)
4 评测实验与结果分析
4.1 实验设计
本论文设置两种实验来验证我们所提出的数据增强方法的有效性,一个是小样本实验,另一个是鲁棒性实验。
数学课堂留白,指数学教师在课堂教学的某些环节中,有意留出一定的时间和空间让学生自主思考、感悟,为学生构建属于自己的数学认知结构,从事数学探究活动,表达对数学的理解提供机会.数学课堂留白艺术的运用,为师生思维火花的碰撞提供契机,有助于提高数学课堂教学的效能.
(1) 小样本实验:在小样本实验中,我们主要探讨如何使用本文方法对已有的小样本数据进行数据增强,从而提高模型的精度。对此,我们从训练集中抽取20%、40%、60%、80%和100%比例的训练数据,使用本文的数据增强方法增强0~3倍(0倍表示未使用增强数据)的数据进行实验。
(2) 鲁棒性实验:为了增加评测数据中未见数据的语言现象的多样性,我们利用所提方法在原测试集的数据上生成新的评测数据,与原测试集合并构成扩展测试集。因此,我们试图建立鲁棒性评测的方式,测试模型对多种多样的语言现象的处理能力。
我们分别在成分句法分析模型和依存句法分析模型上进行小样本和鲁棒性实验。其中,成分句法分析模型采用基于序列到序列的编码解码模型,具体细节参见文献[19];依存句法分析模型采用Biaffine和二阶子树的分词依存联合模型,具体细节参见文献[20]。在所采用的成分句法分析模型中,我们去除了Bert,一方面是为了保持与依存句法分析模型的一致(未使用Bert),另一方面是为了纯粹验证本文所提数据增强方法所带来的效果。
评价的数据增强方法包括本文提出的三种方法: ①词汇化树邻接语法(LTAG); ②LTAG + n-gram语言模型; ③LTAG + RNN语言模型,以及作为对比对象选择的同义词替换的数据增强方法; ④同义词替换。我们考虑同义词在语义上相近并且很有可能具有相同的词性标签,从而保证替换后的句子在语义上的相近、在句法结构上的完整以及句法结构标签的正确。在实验中,我们以0.3的概率对句子中的单词进行同义词替换。
4.2 实验数据及评测指标
我们使用宾州汉语树库CTB 5.1作为句法分析数据集进行实验,训练集采用编号为001~270、440~931和1 001~1 151的文章,共953篇,开发集所采用的编号为301~325的文章,共25篇,测试集采用的文章编号为271~300的文章,共30篇[19-20]。我们利用所提方法在测试集的数据上生成新的评测数据共86个,与原测试集合并作为扩展测试集,表2显示了新生成的测试数据中的几个实例。表3展示了实验数据的统计信息。

表2 扩展测试集中新生成的测试实例
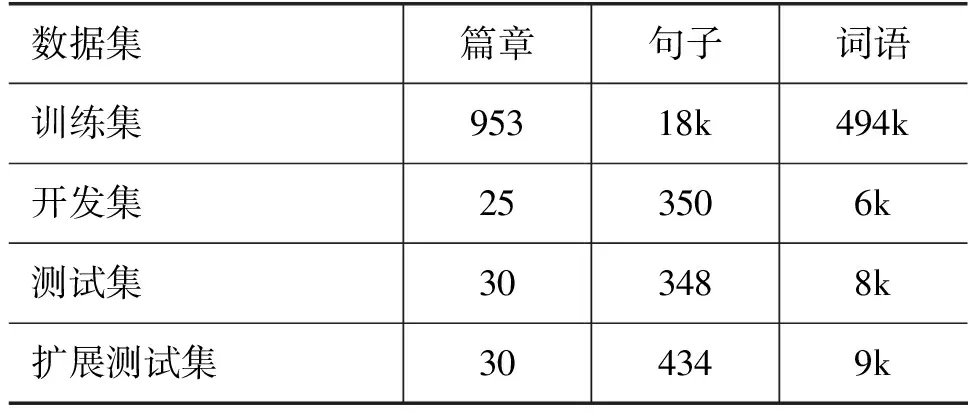
表3 宾州汉语树库CTB5.1数据集统计信息
我们采用准确率、召回率和综合性能指标F1值[19-20]对依存句法分析和成分句法分析进行评测。
4.3 评测实验结果及分析
4.3.1 依存句法分析评测结果
本实验中,我们在依存句法分析上进行小样本和鲁棒性实验,小样本的实验结果如图9所示。

图9 依存句法分析上的小样本实验结果
图9(a)~9(d)分别为四种不同数据增强方法在不同规模的小样本下增强0~3倍数据的实验结果,显示不同增强倍数对依存句法分析模型精度的影响。通过对图9(a)~9(d)的观察我们发现,四种数据增强方法都可以在小样本的情况下提升依存句法分析模型的精度,并且小样本规模越小,数据增强为模型精度所带来的提升幅度越大。上面分析表明在资源稀缺情况下,本文方法能够带来精度提升,而且提升效果显著。
同时我们看到,随着小样本规模的增大,模型精度也的确有所提升,只是没有数据较少情况下提升得幅度大;精度没有随着小样本数据规模的增大有相应幅度的提升,说明增强数据中存在冗余。关于解决冗余的方案,我们考虑可以从数据制作策略和增强数据筛选方面进行研究,一方面可以考虑针对容易发生分析错误的语言现象进行数据增强;另一方面也可以考虑利用当前模型从增强数据中筛选出无法正确分析的句子作为有效的增强数据使用。
我们进一步观察图9(a)~9(d)发现,尽管模型精度随着增强数据倍数的增大而有所提升,但是提升的幅度呈减小趋势,其中增强3倍和增强2倍的效果非常接近,说明在依存句法分析的小样本情况下,增强1~2倍即可达到大幅精度提升的效果。
在小样本规模相同且增强数据1倍情况下,不同数据增强方法的对比实验结果如图9(e)所示,具体数值如表4所示。表4和图9(e)中的对比结果表明,在本文的三种方法中,使用语言模型的两种方法比不使用语言模型的方法能够带来更大精度提升,且均超过同义词替换的方法,其中LTAG+RNN语言模型的表现更好,在小样本规模为40%的情况下对比差异最显著。上面的对比说明,语言模型能够进一步提升增强数据的质量,从而提升依存句法分析模型的性能。
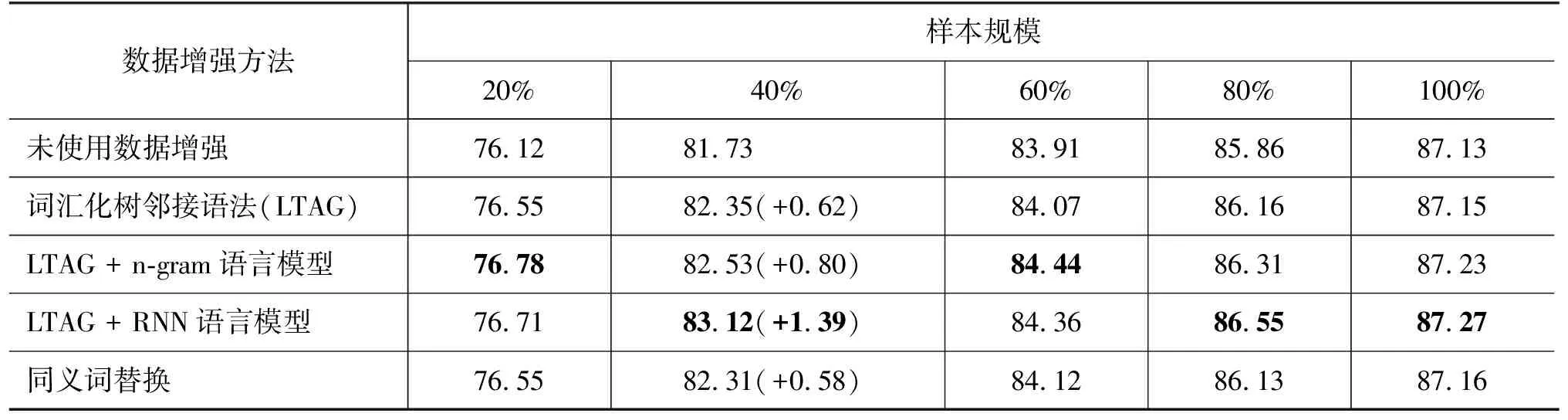
表4 不同数据增强方法在增强1倍数据下的依存句法小样本实验结果
我们在扩展测试集上进行依存句法分析的鲁棒性实验,其结果如表5所示。通过分析表5我们可以看到,四种数据增强方法都可以提升模型的鲁棒性,并且增强1倍的数据即可带来不错的性能提升,而继续扩大增强数据的倍数并未带来明显的精度提升。在增强1倍数据量的情况下进行对比发现,本文的数据增强方法为模型所带来的性能提升均比同义词替换方法高,说明我们所提的数据增强方法能够有效提高依存句法分析模型的鲁棒性。
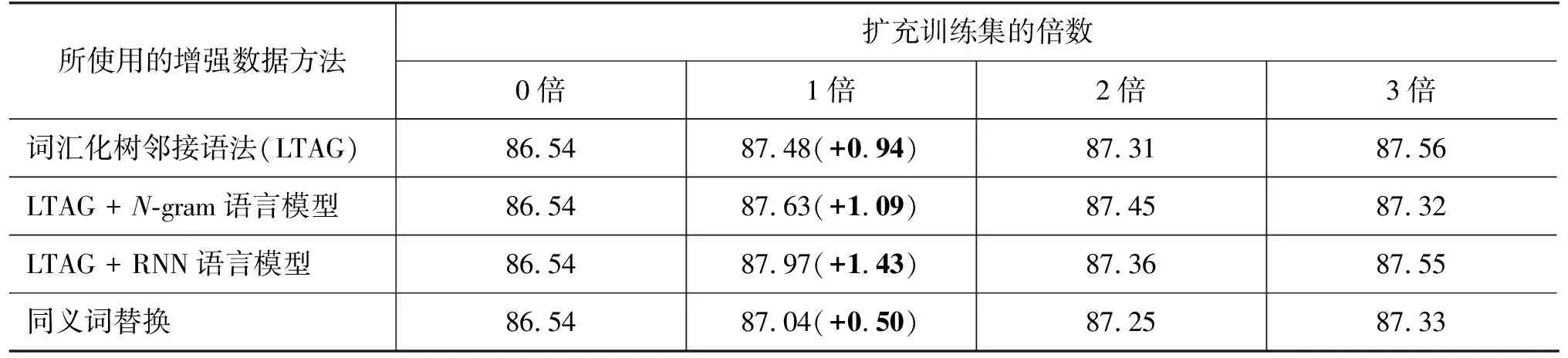
表5 依存句法分析的鲁棒性实验结果 (单位: %)
为进一步验证使用本文方法所得到的增强数据集所训练的模型具有更好的鲁棒性,我们专门分析模型在新加入的86个句子上的分析结果,并以根节点的分析结果作为评测对象。我们之所以评测根节点,主要考虑根节点的预测通常很难,同时对于句子的句法结构和语义理解很重要,故可以作为鲁棒性评测的一个方面。具体的,我们使用根节点正确率(Root Accuracy, RA)进行评测,其结果如表6所示。从表6可以看到,使用本文方法获得的增强数据可以使模型在86个新的测试数据上,表现出更好的根节点正确率。上面分析结果表明本文数据增强方法可以提升模型应对新句子的能力,对新的测试句具有更好的适应性。
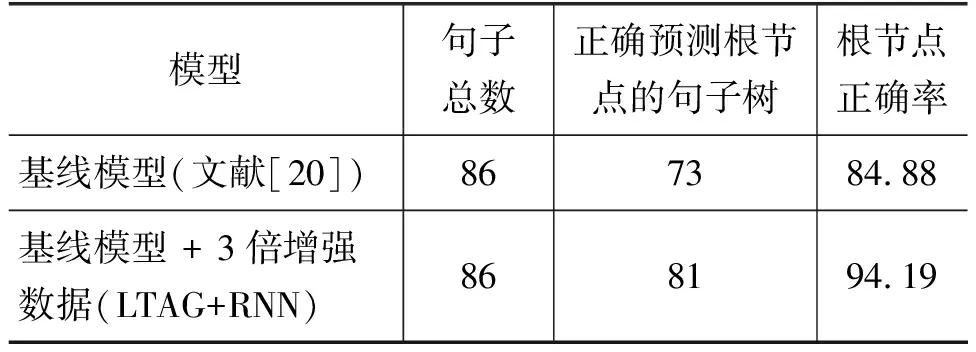
表6 扩展测试数据根节点正确率对比 (单位: %)
4.3.2 成分句法分析评测结果
本实验中,我们在成分句法分析上进行小样本和鲁棒性实验,小样本的实验结果如图10所示。

图10 成分句法分析小样本实验结果
图10(a)~10(d)分别为四种不同数据增强方法在不同规模的小样本下增强0~3倍数据的实验结果,显示不同增强倍数对成分句法分析模型精度的影响。分析图10(a)~10(d)的结果发现,四种数据增强方法都可以在小样本的情况下提升成分句法分析模型的精度。同时,我们看到随着小样本规模的增大,模型精度也的确有所提升,只是没有数据较少情况下提升的幅度大。这一现象与前面依存句法分析实验的表现类似,具体的分析已在4.3.1小节给出。
图10(e)显示在增强1倍数据情况下的不同数据增强方法的对比结果,具体数值表现如表7所示。
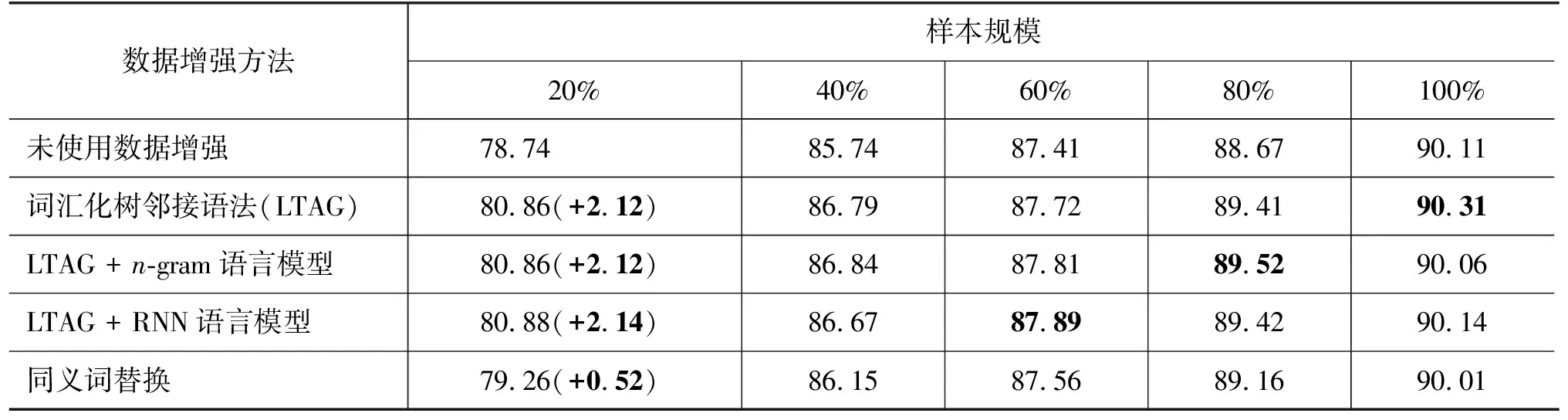
表7 不同数据增强方法在增强1倍数据下的成分句法小样本实验结果 (单位: %)
分析表7和图10(e)的结果发现,本文所提的三种数据增强方法均超过同义词替换的数据增强方法,其中在样本规模为20%的时候,对比最为显著。同时我们也发现,加入语言模型后的数据增强方法对模型性能提升幅度较小。我们分析这一现象与成分句法分析任务的特点有关,这里主要对句中的短语进行识别和层次划分,更多关注句法树结构的多样性;而LTAG已经能够提供足够多样化的句法树,语言模型的加入只是提升增强数据在语义上的合理性,对于句法树结构多样化的贡献有限。
同时,我们也在扩展测试集中进行依存句法分析的鲁棒性实验,其结果如表8所示。我们分析表8发现,本文所提的三种方法都能为成分句法分析模型带来精度上的提升,其中LTAG+RNN语言模型所带来的提升幅度最大,为0.44,而使用同义词替换的方法却导致模型精度下降0.21。鲁棒性对比实验的结果表明本文所提的数据增强方法可以提升模型应对新句子的能力,对新的测试句具有更好的适应性。

表8 成分句法分析的鲁棒性实验结果 (单位: %)
5 总结
本文首次提出基于词汇化树邻接语法的数据增强方法,针对句法分析中数据增强的两个问题分别提出解决方案。我们设计实现了基于词汇化树邻接语法的词汇化树抽取算法与句法树合成算法,利用词汇化树邻接语法确保生成的句法树具有多样且完整的句法结构,并结合n-gram语言模型与RNN语言模型对生成句进行语义评估,选取语义合理的句子作为最终的增强数据。最后我们进行小样本和鲁棒性的评测实验,实验结果证明所提出的数据增强方法能够有效提升现有汉语句法分析模型的精度和鲁棒性。
本文主要提出了一种新的基于树邻接文法的数据增强方法,利用已有树库生成新的语句及句法结构标注。关于该方法的应用方式有待进一步探索,特别是增强数据中的冗余性问题,因此如何结合对抗样本生成方法的思想解决该问题成为下一步的研究课题。
