基于ILF-YOLOv3的人员在岗状态检测算法研究
2021-12-31谢斌红栗宁君陈立潮张英俊
谢斌红,栗宁君,陈立潮,张英俊
(太原科技大学计算机与技术学院,太原 030024)
人员在岗状态的智能化监测和管理已经成为许多服务型行业亟待解决的问题,而现阶段的方法和手段还停留在人工监督和传统检测算法阶段,存在着检测结果不够客观,检测精度不高和实时性较差等问题。因此,有效解决上述问题成为人员在岗状态智能化检测的一个重要研究方向。
随着深度学习技术在计算机视觉领域的不断发展和应用,基于深度学习的目标检测算法逐渐进入大众的视线。该类算法主要分为两类:第一类是two-stage模型,首先预选出候选区域,再通过卷积神经网络提取目标特征。此类算法精度较高,发展成熟,但速度较慢,无法满足实时性检测要求。典型的特征提取网络有AlexNet[1]、OverFeat[2]、GoogleNet[3]、VGG[4]和ResNet[5];2014年在ILSVRC上又提出了R-CNN[6]算法,之后在该算法基础上,又提出了Fast R-CNN[7]、DeepID-Net[8]和Faster R-CNN[9]等基于two-stage 的R-CNN系列目标检测算法。第二类算法为one-stage模型,该类方法是基于回归思想的端到端的模型算法,其网络结构简单,实时性更强。2016年,Redmon等人相继了提出了YOLO[10]和YOLOv2[11]网络模型;2018年,在YOLOv2的基础上Redmon等人又提出YOLO-v3[12]算法,该算法是时下在检测的精度和训练的速度上最均衡的目标检测算法,并已应用于各行业领域中[13-15]。
综上所述,针对目前在岗人员状态检测方法存在人力资源浪费、检测环境复杂和检测结果不客观等问题,本文以YOLOv3为检测模型的骨干网络,通过改进其目标定位与目标置信度的损失函数,并在其多尺度特征提取的基础上增加不同尺度间的特征融合密度,得到新的算法ILF-YOLOv3来检测人员在岗状态。经实验验证,该算法不仅有效缓解了随深度加深而出现的梯度不稳定情况,而且算法的检测精度也得到了显著提升。另外,本文将采集回的数据筛选并使用对抗网络作定向增强,模拟可能出现的复杂背景,设计出一套针对在岗人员状态的样本数据集StaffSData-Strong(Staff status Data-Strong).
1 YOLOv3网络
YOLOv3模型的特征提取网络主要由Conv和Res两种模块组成。其中,Conv模块由卷积层Conv2d、批标准化BN(Batch Normalization)层和正则化LeakyReLU层组成,主要实现目标图像的特征提取。Res表示一个残差模块,主要功能是为了减小梯度爆炸的风险,加强网络的学习能力。
YOLOv3模型的输入是一副416×416的图像;经过特征提取网络提取3种不同尺度的特征;生成大小为N的特征向量:
N=S×S×B×(C+score+tx+ty+th+tw)
(1)
其中,S表示特征尺度大小,B表示边界框个数,C表示目标类别数量,score表示预测框置信度,(tx+ty+th+tw)表示边界框的坐标及尺寸,预测边界框的转换公式图如图1所示。
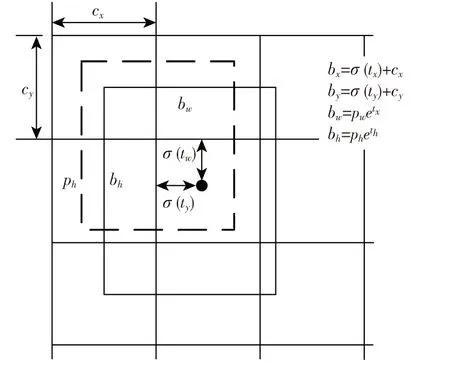
图1 bounding box prior公式图Fig.1 Formula of bounding box prior
将3种不同尺度的预测结果拼接;过滤掉score小于阈值的特征向量;然后通过掩码和类别C筛选出目标候选框并通过IOU(公式2)与非极大抑制操作,每类最多检测出20个框;作为最终的预测向量;最后计算预测量与真实框的损失并反向传播。
(2)
2 ILF-YOLOv3网络的研究
本文提出的ILF-YOLOv3(Improve Loss and Feature -YOLOv3)网络结构如图2所示。
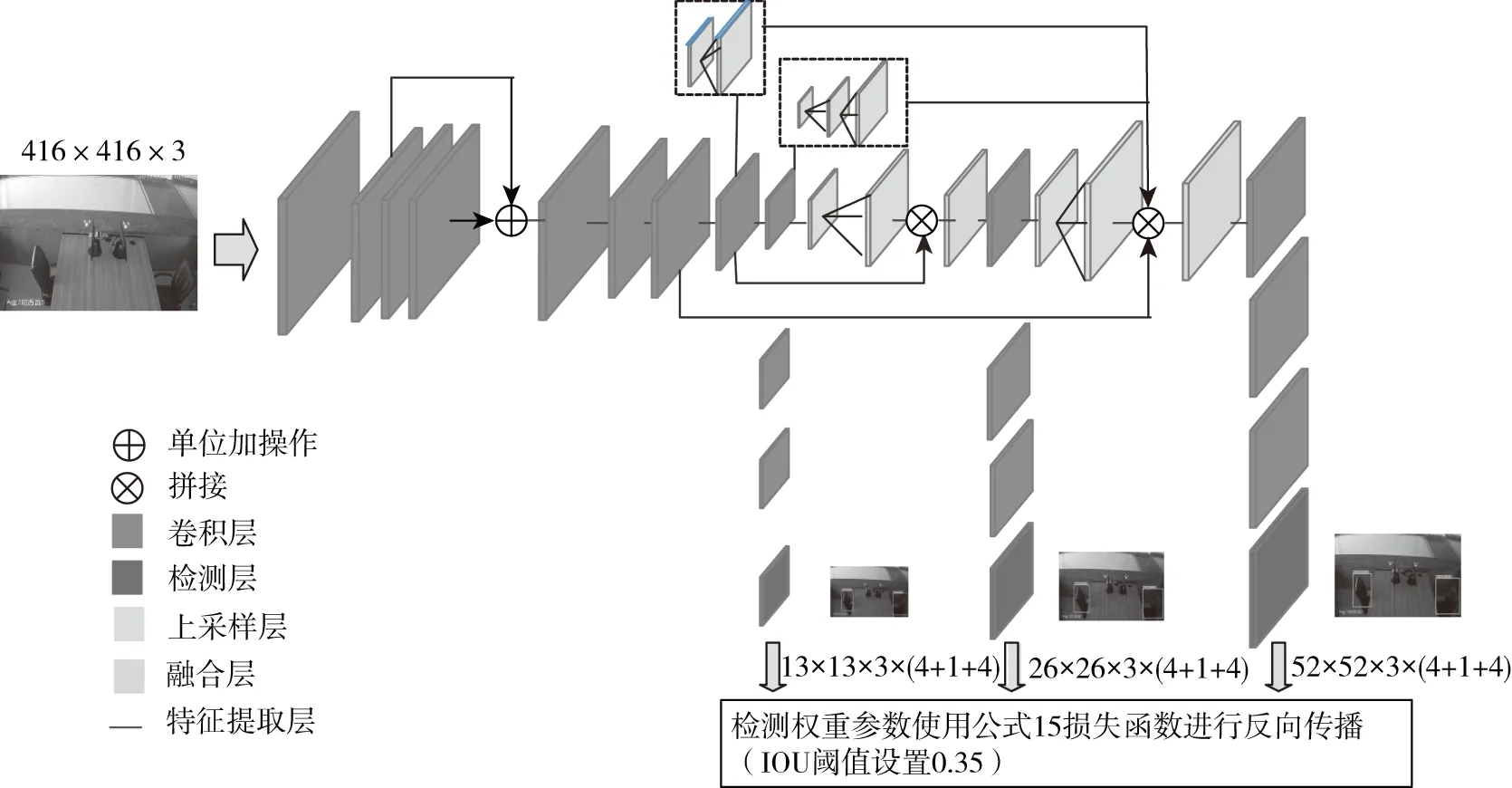
图2 ILF-YOLOv3网络结构图Fig.2 ILF-YOLOv3 network structure
ILF-YOLOv3网络以YOLOv3模型为骨干网络,并在基础上增加了特征融合的密度,改进了反向传播的损失函数和更新了数据集目标分类,并且通过实验确定了适合新损失函数的最佳IOU阈值。
2.1 YOLOv3损失函数的分析
在深度神经网络的训练中,由于梯度下降法的特性,随着网络层数的不断加深,梯度不稳的现象会更加明显,这将会导致梯度的弥散或爆炸,从而影响网络模型的收敛速度和检测精度。通过对损失函数的分析,该类问题同样存在YOLOv3算法中。
YOLOv3的损失函数由以下3部分组成:
1)目标置信度损失函数
(3)
2)目标分类损失函数
Lcla=
(4)
3)目标定位的两个损失函数
Lloc=
(5)
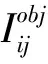
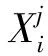
(6)
(7)
(8)
(9)
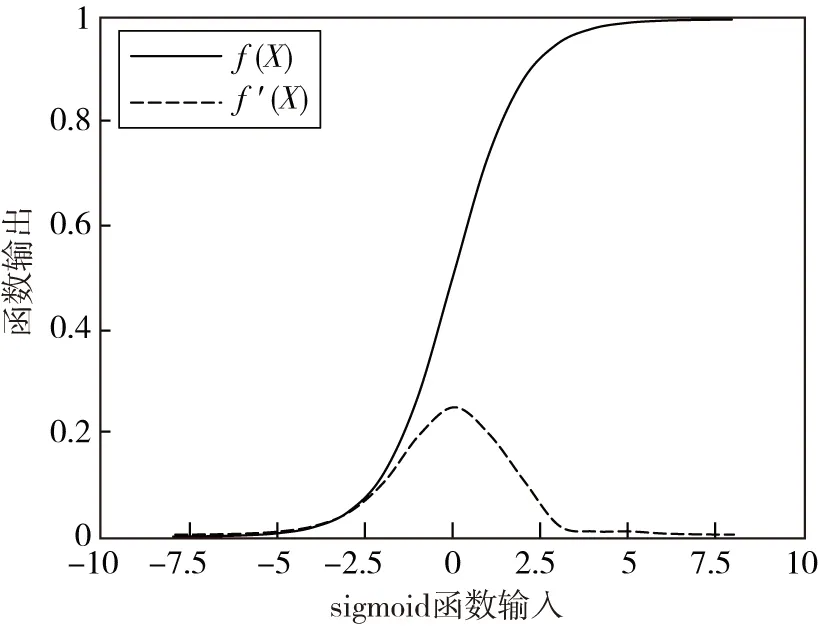
图3 sigmoid函数及导函数图像Fig.3 Sigmoid function and derivative function
2.2 ILF-YOLOv3损失函数的调整
2.2.1 目标定位损失函数的改进
通过2.1对目标定位损失函数的分析,原平方损失函数容易出现梯度弥散现象,所以本文使用了交叉熵损失函数来代替原损失函数。

LI-locx=
(10)

图时的函数图像Fig.4 The graph of the function when
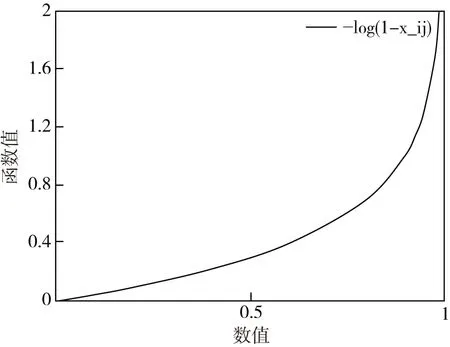
图时的函数图像Fig.5 The graph of the function when

(11)
综上所述,交叉函数不但符合预测输出值与实际样本之间的差距越大,损失函数值越大的特性,并且还能有效避免梯度消失,加速模型的收敛速度。所以,将二分交叉熵函数作为ILF-YOLOv3算法的目标定位损失函数,具体如公式式12所示。
(12)
2.2.2 置信度损失函数的改进
YOLOv3检测算法是基于回归思想的one-stage模型,该类模型由于前景背景类别不均衡导致与基于two-stage的检测模型在检测精度上存在一定差距[16]。且在人员在岗检测中,给类型问题更加突出,即待检测目标的特征多以员工在岗状态特征信息为基础,打手机、睡觉等状态的特征都以人员在岗特征为背景,所以导致在岗状态成为易检测目标,而打手机、睡觉样本的检测变的困难。从而造成在检测中经常出现打手机、睡觉等异常状态的漏检的现象。

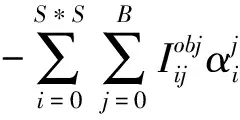
(13)
(14)
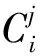
本文还通过调整无目标预测函数项的权重系数λnoobj=0.5来降低无目标部分损失计算的贡献比重,使网络更加侧重有目标物体出现的边界框部分的损失计算。有效降低了one-stage模型中存在的大量背景对目标检测效果的影响。
最后,在2.2.1目标定位损失函数改进和调整IOU阈值的基础上对自制数据集进行实验得到最佳的β值,当β=0.5时达到最佳效果。在目标损失函数改进的基础上召回率提高了5%,精确度提高了1.3%.如表1所示。
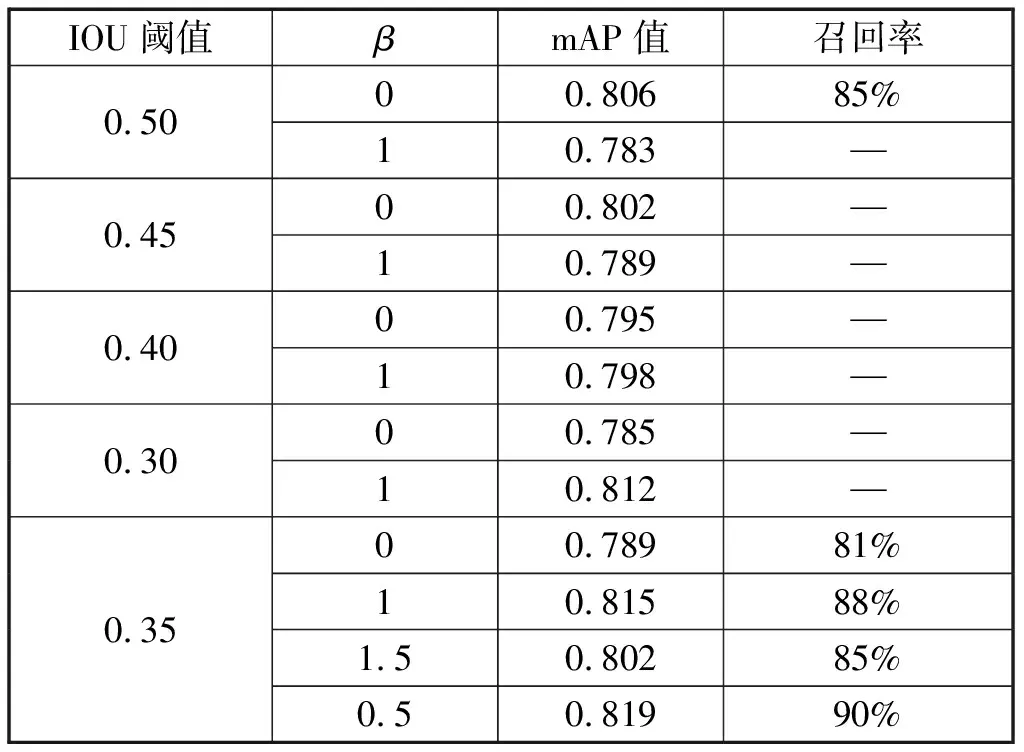
表1 不同IOU阈值与β值对比
基于对目标分类损失和目标定位损失改进后,得到的ILF-YOLOv3模型的总损失函数如公式15所示。
(15)
2.3 尺度特征模块的改进
YOLOv3网络中的多尺度特征提取是通过对底层的特征上采样后获得,存在特征信息单一、不完整的问题。因此,本文通过采用卷积与反卷积操作来增加多尺度特征间的融合密度,保证提取特征信息包含更多的上下文特征信息。改进后的多尺度特征提取网络的结构如图6所示。
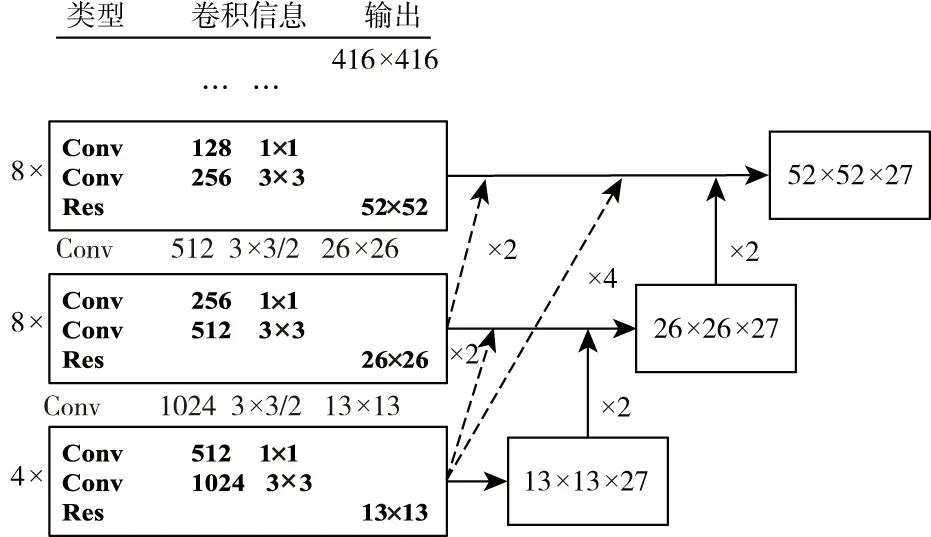
图6 改进后的多尺度检测网络Fig.6 The improved multi-scale detection network
图6中,实线表示原多尺度检测网络的结构联接,虚线表示本文添加的多尺度间融合。
如图7所示,该模块为本文提出的用来融合不同尺度间特征的卷积操作。该模块包含3项卷积操作:

图7 不同尺度特征间融合的卷积操作Fig.7 Convolution operation of fusion among features of different scales
2)通过设定Stride参数,利用反卷积技术来实现特征图像的上采样。尺度1313到2626和尺度2626到5252设定Stride参数为2,利用22的卷积核反卷积来实现上采样;尺度1313到5252,设定Stride参数为4,利用44的卷积核反卷积实现上采样。
3)对拼接后获得的新特征图像进行一系列Stride步长为1的卷积操作,减少拼接特征图像融合后出现的混叠效应,同时也减少了不必要的特征偏移。该系列卷积操作中包括1个11的卷积模块和1个33的卷积模块。
通过改进后的多尺度检测模块,最终提取的特征图像将会融合更多层级的特征信息,相比原网络模型包含了更加完整的特征信息,更值得信任。
通过实验验证,改进后模型在睡岗和打手机状态的检测精度分别提高了2.9%和5.7%,平均精度提升了2.3%.如表2所示。

表2 增加多尺度目标融合后的精度对比
3 实验结果与分析
3.1 StaffSData-Strong数据集的制作
本文的样本数据是对员工在岗状态监控视频加工处理后获得。首先运用图像工具对采集的视频生成7 800张有效的特征图像,然后用labelImg工具标注出所需目标特征的区域,最后将标注过后的图像按6∶4比例生成对应的训练集和交叉验证集,其中交叉验证集又根据3∶2划分测试集和验证集,最终构建了StaffSData数据集,包含4 680张的训练集、1 872张的测试集和1 248张验证集。
采用ILF-YOLOv3模型训练自制的样本数据集,取得理想的效果,但在实际检测场景出现了错、漏检的现象,通过分析发现,特征图像中的复杂环境的噪点(光照强度 、视频角度等)对实际检测结果影响较大,因此本文采用了DCGAN[17](Deep Convolutional GAN)来定向增强样本数据集,最终得到针对在岗异常状态检测的样本数据集StaffSData-Strong.数据集包含12 300张图像,其中训练集7 376张、测试集2 959张,验证集1 965张。
3.2 实验结果
本文实验的硬件环境配置如表3所示。
表3 实验硬件配置表
本文分别对YOLOv3模型和改进后的ILF-YOLOv3模型从mAP值和召回率上进行实验对比,总计迭代10 000epoch.
图8表示对比两次改进损失函数模型与原YOLOv3模型的损失值变化曲线。(YOLOv3-L1表示改进目标定位损失函数;YOLOv3-L2表示同时改进目标定位及置信度损失函数;YOLOv3表示原损失函数)。

图8 损失函数对比曲线图Fig.8 The comparison curves of loss functions
由图8分析可知,改进后的YOLOv3-L1模型相比原模型的损失值有更快的下降速度,且最终收敛效果明显比原模型效果好;而改进后的YOLOv3-L2由于均衡了易分类与难分类的样本权重,导致收敛速度变慢,但是最终的收敛值较YOLOv3-L1又有提升。
图9是ILF-YOLOv3在增强后数据集StaffSData-Strong上测试的mAP值曲线图。
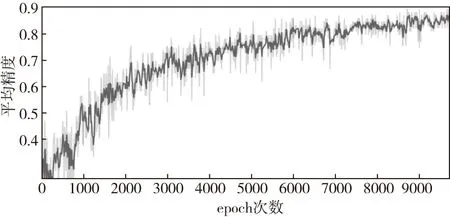
图9 ILF-YOLOv3的mAP曲线图Fig.9 The mAP graph of ILF-YOLOv3
为更好地验证新模型和增强数据集在人员在岗检测领域的性能,本文将新模型与多种不同的目标检测模型进行对比实验。其中新模型分别在数据集StaffSData和增强数据集StaffSData-Strong上进行实验,其余检测模型在数据集StaffSData进行实验。
实验结果如表4、表5所示。
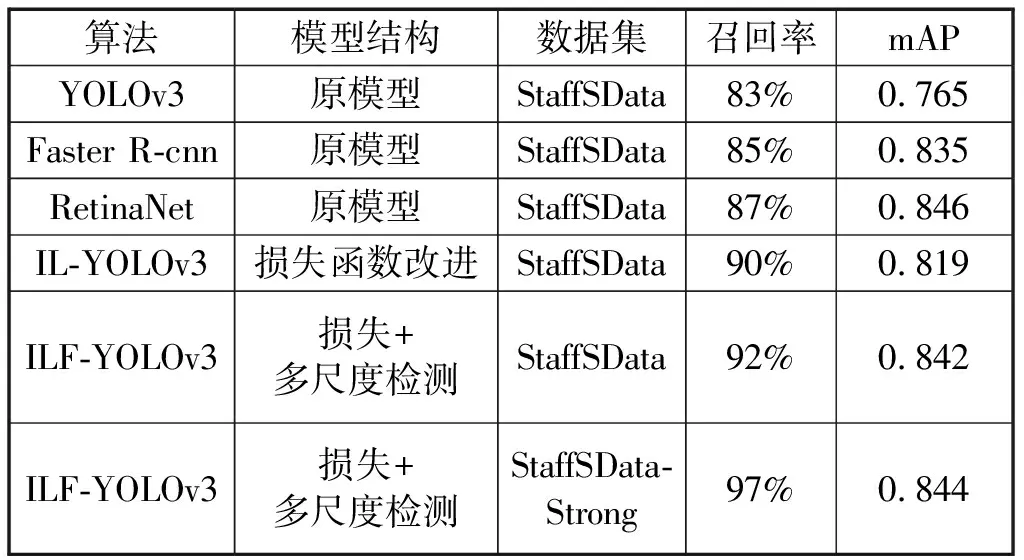
表4 实验结果对比
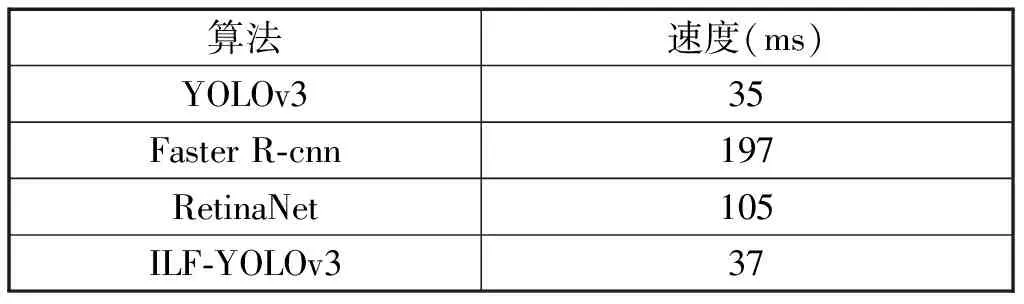
表5 各模型检测速度对比
分析表4得,(1)改进损失函数的IL-YOLOv3模型在未增强的数据集上测试比YOLOv3,在召回率提高了7%,精度提高了5.4%.(2)改进损失函数和多尺度融合的ILF-YOLOv3在未增强的数据集上测试对比YOLOv3模型,召回率提高了9%,精度提高了7.7%.(3)ILF-YOLOv3在增强后的数据集上StaffSData-Strong测试比YOLOv3网络,召回率提高了14%,精度提高了7.9%.
综合表4、表5可知,ILF-YOLOv3模型在增强后的数据集上与RetinaNet、Faster R-cnn在未增强数据集上的检测精度相近的情况下,不仅检测速度分别提高了68 ms和160 ms;召回率也分别提升了10%和12%.综合来看,本文提出的ILF-YOLOv3模型不仅同时兼顾精度与速度,且对人员在岗检测环境有较高的鲁棒性,能满足人员在岗状态实时检测的需求。
最终的检测效果如图10所示,其中包含人员的在岗、脱岗、睡觉、打手机的状态检测。

图10 人员在岗状态检测效果展示(在岗、脱岗、睡岗、打手机)Fig.10 Display of on-duty status detection effect(on-duty,off-duty,sleeping,cell phone)
4 结束语
本文基于对YOLOv3两项损失函数和多尺度检测模块的改进,提出了一种对员工在岗状态的实时检测算法ILF-YOLOv3,并且采用深度卷积对抗网络(DCGAN)对真实视频数据集进行处理,构造了一套员工在岗状态实时检测的样本数据集StaffSData-Strong.实验结果表明,本文提出的ILF- YOLOv3模型在检测速度与原YOLOv3模型检测速度相近的条件下,mAP值提高了7.9%,召回率也达到了97%.已具备员工在岗状态的实时检测与监督管理。
在之后的工作中,作者会继续加强样本数据集的多样性,提取更多有效影响因子(客户的行为状态、表情等);对模型结构作优化,通过合理的压缩参数量来进一步提升检测性能。
