基于时间卷积网络的业务流程预测监控
2021-12-31宫子优方贤文
宫子优,方贤文
(1.安徽理工大学计算机科学与工程学院,安徽 淮南 232001;2.安徽理工大学数学与大数据学院,安徽 淮南 232001)
过程挖掘是指从现代信息系统和业务流程的事件日志中获取过程知识,发现、监测和改进实际系统行为模式。在业务流程运行中可能需要提前知道业务流程的下一个事件,以便对业务流程进行调整。流程预测监控是过程挖掘和业务流程管理领域的一个重要的研究方向,通过预测业务流程运行中将要发生的事件或是后续可能发生的一系列事件以及它们可能持续的时间或是下一个事件的时间戳,旨在为业务流程提前进行人工干预提供决策支持。过程挖掘和业务流程管理领域都是使用事件日志作为记录和分析的工具,类似于自然语言处理中所研究的文本和语音数据,事件日志是一种时间序列数据。深度学习的发展在诸多领域都有着不俗的表现,如计算机视觉、自然语言处理等,使用自然语言处理中的深度学习方法来研究和分析事件日志是很自然的想法。文献[2]指出应用自然语言处理方法进行过程预测的可行性,并给出一个实验评估来证明其有效性。已经有多个工作使用深度学习方法来进行业务流程预测,其中包括循环神经网络(Recurrent Neural Networks,RNN)中的长短期时间记忆(Long Short-Term Memory,LSTM)网络和卷积神经网络(Convolutional neural networks,CNN)。
时间卷积网络(Temporal Convolutional Networks ,TCN)作为卷积神经网络的一种变体,相比于循环神经网络和卷积神经网络,克服了各自的缺陷,在建模和预测序列数据有着很好的效果。本文提出一种新的方法,使用基于时间卷积网络的预测模型作为过程行为预测的一种手段,并在3个真实生活事件日志数据集上进行实验,结果表明相比于使用LSTM和传统CNN预测过程事件有部分提升,说明时间卷积网络用于业务流程预测的可行性和有效性。
1 相关工作
流程预测最早的工作由文献[4]提出,通过从事件日志中构建带注释的变迁系统预测流程剩余时间。使用RNN预测序列数据是在自然语言处理中常用的方法,事件日志中的迹也是一种事件序列数据。文献[5]首先将深度学习中的RNN引入过程预测,提出用两层LSTM神经网络预测下一事件。文献[6]采用层数更多的LSTM预测包括下一事件以及其时间戳和事件序列后缀三种任务,其中下一事件和下一事件时间戳由共享的多任务层分别预测输出,事件序列后缀是由预测的下一事件作为输入迭代形成,并且效果均优于带注释的变迁系统和两层LSTM单一任务预测。卷积神经网络CNN也可以用于序列预测和分类,效果上和RNN类的方法相当,但是CNN的并行度优于RNN,所以训练和推断速度均优于RNN。文献[7]提出CNN的方法,将事件序列(迹)转化成类似图像数据的矩阵用作CNN的输入,预测下一事件,相比采用LSTM的方法,在训练和预测的速度上有很大提升,在准确率上也有一定提升。
相比之前的工作只利用事件日志中的活动和时间属性预测下一事件和时间戳,事件对应属性同样可以作为输入数据利用起来。文献[8]从事件、时间戳和角色属性中训练共享的LSTM模型预测多任务,包括预测下一事件、剩余时间以及生成事件序列后缀。文献[9]在使用LSTM的基础上提出一种调制器(Modulator)的模块,通过调制器对齐隐藏层信息,学习每个属性的重要性,最终预测下一事件,以及生成事件序列后缀。除了深度学习的方法,文献[10]提出使用贝叶斯网络预测预测下一事件,以及生成事件序列后缀,在运行速度上优于深度学习的方法。
2 基本概念
定义1
事件 事件ε
是活动域A
中的活动act
,并且具有对应属性如发生时间的时间戳ts
,角色属性role
等一些其他属性。活动域A
是h
个不同活动的集合,根据对应的业务流程的模型,这些活动可能出现在事件中。定义2
迹迹σ
=<ε
,ε
,…,ε
>是业务流程实例的执行。它是l
个不同事件的有限序列,在时间上是非递减的,即ts
≤ts
,1≤i
≤j
≤l
。迹中每个事件隐含对应的属性,后面的定义都是如此。定义3
事件日志 事件日志L
是事件的集合,其中每个事件都被连接成为一个迹。


3 业务流程预测方法
3.1 时间卷积网络
时间卷积网络(TCN),是近年来提出一种卷积神经网络(CNN)的变体,对时间序列数据有很好的处理能力。往常对序列数据(如自然语言处理,股市预测等)的处理一直是循环神经网络(RNN)的强项,使用CNN处理序列数据相比RNN并行处理能力更强,准确率也可以和RNN相媲美。但是传统的CNN有着不能捕获远距离特征和无法保留原始输入的相对位置信息的问题,所以针对这些问题,TCN在一定程度上有所解决。
TCN采用了一维全卷积网络(fully-convolutional network)架构来处理序列数据,每一个隐藏层的长度与输入层都相同,通过补0来保证下一层长度和上一层相同。TCN通过因果卷积(causal convolution)来保证时间t
的输出仅与前一层中的时间t
的输出和更早时间输出有关;膨胀卷积(dilated convolution)来增加感受野实现更长序列的捕获;残差模块(residual block)的结构加深网络层数而不会导致梯度消失,致使训练困难,相当于进一步增加感受野。TCN的接受域依赖于网络深度n
、滤波器尺寸k
和膨胀因子系数[Dilation],例如在预测需要大小为2的历史输入的情况下,可能需要最多12层的网络(见图1)。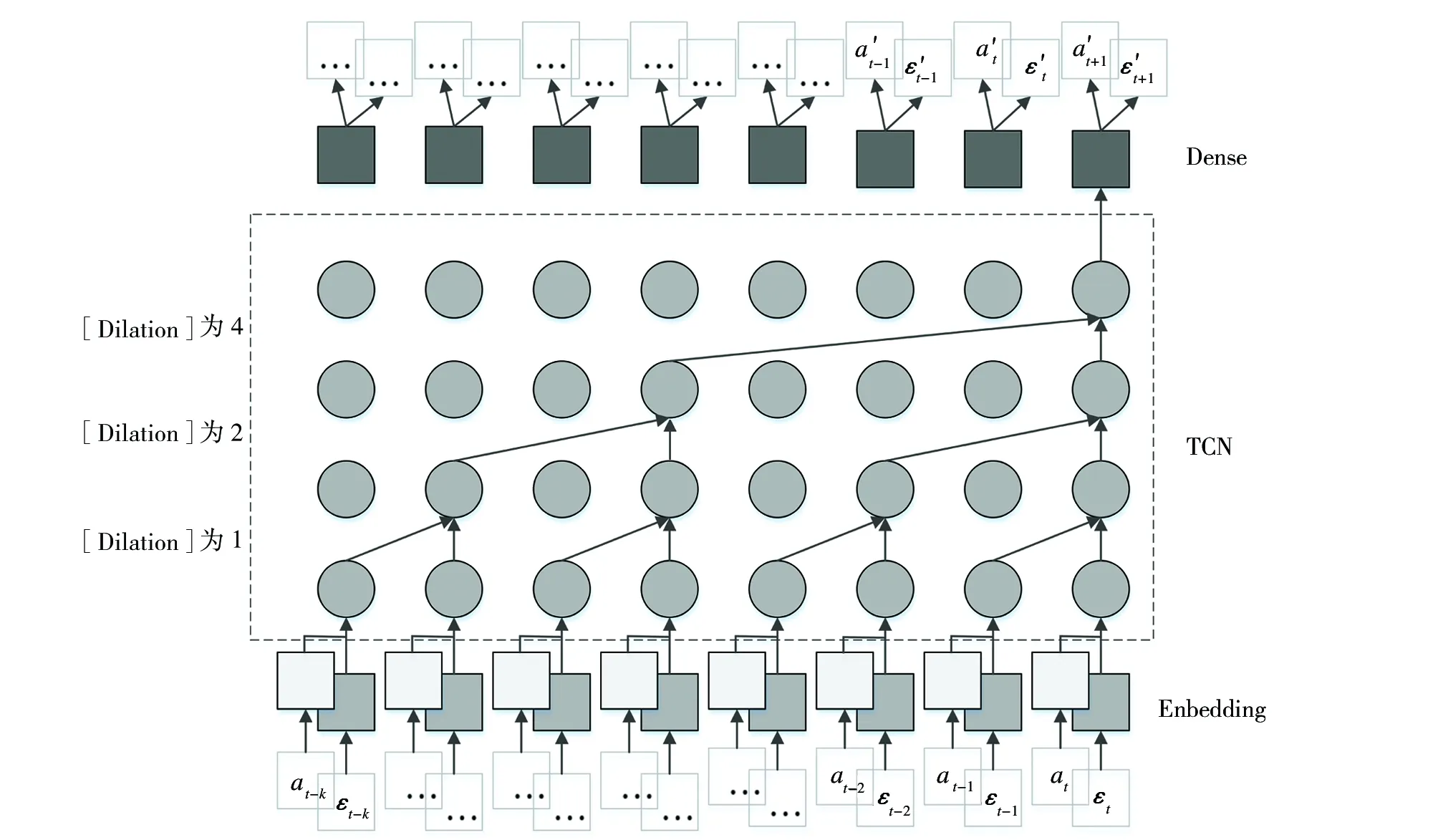
图1 TCN模型结构
由图1可知,TCN结构由因果卷积和膨胀卷积组成。t
时刻输出y
是由t
时刻输入x
、膨胀系数[Dilation]为[1、2、4]和更早的x
-1至x
-的输入(滤波器尺寸k
=2)得来,膨胀系数越大,所能获取的历史输入信息越多。残差模块的结构如图2所示,残差模块通过将输入加到网络的输出可以有效地允许各层学习对恒等映射的修改,而不是整个转换,已被证明可以有效地训练深层网络。
图2 残差模块
在序列建模任务中输入序列一般会表示成one-hot编码,one-hot方式编码的向量维度很高也很稀疏,可以通过使用嵌入技术(Embedding)将稀疏高维的向量转变成低维非稀疏的矩阵,每一个序列中事件不是被一个向量来表示,而是被替换为用于查找嵌入矩阵(Embedding Matrix)中向量的索引。本文使用的模型先分别对输入的事件序列和属性组成的序列输入Embedding层,再合并两个输出输入TCN中,TCN的输出再输入全连接层,最后分别通过两个softmax作为激活函数的全连接层输出下一事件及其属性。除了图1中网络结构,也可以将事件序列和属性组成的序列的Embedding层输出分别输入两个的TCN中,然后合并两个TCN的输出再输入全连接层,该结构准确率和前一种结构接近,但训练和推断时间较前一种长。
3.2 业务流程预测
1)下一事件预测 在预测模型运行时,将新来的迹看作事件序列流,对于给定前缀迹输入,TCN模型预测输出该前缀迹下一个事件,这里的事件仅为事件日志中出现的事件。
设定一个输入序列窗口window,即有效输入序列的最大长度为输入序列窗口长度。事件流中的迹按时间顺序进入输入序列窗口,先对事件序列和资源序列进行编码得到其下标序列,再对下标序列进行Embedding后输入到TCN预测模型中,模型输出前缀迹的概率最大的下一个事件。例如window为5时模型输入事件序列和属性序列
input=[<0,0,0,0,ε
>,<0,0,0,ε
,ε
>,<0,0,ε
,ε
,ε
>,<0,ε
,ε
,ε
,ε
>,<ε
,ε
,ε
,ε
,ε
>,<ε
,ε
,ε
,ε
,ε
>,…]input=[<0,0,0,0,a
>,<0,0,0,a
,a
>,<0,0,a
,a
,a
>,<0,a
,a
,a
,a
>,<a
,a
,a
,a
,a
>,<a
,a
,a
,a
,a
>,…]预测模型输出
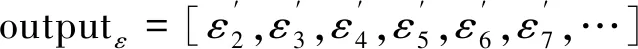

在应用到业务流程运行中时,对已发生的部分流程即前缀迹预测下一个最可能发生的事件,然后可以对当流程进行监控分析和改进。
2)后缀预测 在后缀预测中需要在迹的末尾添加结束标识符“[EOS]”,用于判定预测终止。对于给定前缀迹,模型迭代地将TCN预测模型输出的下一个事件连接到输入前缀迹末尾作为下一步的输入的迹,直到预测输出序列结束标识,将所有输出的事件按时间顺序连接在一起生成的事件序列即迹的后缀。 例如对于给定输入的前缀迹<0,0,0,ε
,ε
>,TCN预测输出的后缀为<ε
,ε
,ε
,ε
,ε
,[EOS]>。后缀迹生成的伪代码如下,<>为空序列,max_trace_length为事件日志中最大迹长度,model_predict为预测模型,+为序列拼接操作。算法 后缀迹生成

i
←k
to max_trace_length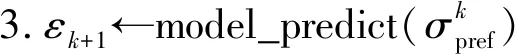


ε
+1为序列结束符 then break
在应用到业务流程运行中时,由未完成流程预测后续完整的流程,直到该流程结束,可以事先对业务流程进行评估,判断需要经过哪些流程,需要占用哪些资源,或是最终到达什么结果。
4 实验与结果分析
4.1 实验数据
实验采用3个在4TU.ResearchData (https://data.4tu.nl/)下载的来自不同领域的现实生活事件日志数据集,分别为Helpdesk、BPIC12和BPIC12 W,其中Helpdesk是某公司的帮助台的票务管理后台记录的日志,BPIC12是2012a业务流程智能竞赛(Business Process Intelligence Challenge 2012)中提供的一荷兰财政机构贷款申请过程日志,包括BPIC2012 A、BPIC2012 O和BPIC2012 W,本文只选用BPIC12和BPIC12 W,本文中使用BPIC12 W为BPIC12 W只包含完成事件的部分日志,因为这也是对比方法中所用的事件日志。这些事件日志数据集的统计数据如表1所示。

表1 事件日志数据集统计信息
4.2 实验设置与评价标准
本文实验环境在Windows10系统中使用Python3.7语言,并使用Tensorflow2和Kares深度学习库。使用的TCN的超参数主要是滤波器尺寸k
和膨胀系数[Dilation],对于不同事件日志数据集,选择的参数有所不同,在Helpdesk数据集上k
=2、[Dilation]=[1,2,4,8],在BPIC12 W数据集上k
=5、[Dilation]=[1,2,4,8,16,32],在BPIC12数据集上k
=2、[Dilation]=[1,2,4,8]。事件日志数据集采用7∶3的比例划分为训练集和测试集,训练集中包括20%验证集,并在每个数据集上重复实验3次取平均值。在预测迹前缀下一事件任务中,对于同一事件日志数据集,训练时设置不同长度输入序列窗口进行实验,当迹前缀长度小于输入序列窗口长度时,在迹前缀之前补0。在预测迹后缀任务中输入序列窗口长度设成一个恒定值。本文采用文献[10]的实验结果作为基准进行比较。与相关工作相同的是,在下一事件预测任务中,使用的指标是下一个事件预测的准确率(Accuracy)。为了评估后缀生成的质量,使用基于Damerau-Levenstein距离(DL distance)的相似度来比较生成的后缀和真实迹后缀之间的相似度,Damerau-Levenstein距离定义为将一个序列转换为另一个序列所需的插入、删除和替换操作的最小数目,以及两个相邻字符的转换。比较两个序列之间的相似度(S
)定义如下
len
(s
)是序列s
长度,相似度=0为完全不同,相似度=1为完全相同。4.3 实验结果
针对不同事件日志数据集设置不同输入序列窗口长度,预测下一事件准确率结果如图3所示。可以看到预测模型在三个事件日志数据集上的测试准确率均在输入序列窗口大于2之后稳定在一个很小的范围,说明对于本文中的方法,输入序列长度大于2即达到比较好的结果。

图3 不同数据集不同输入序列窗口长度准确率对比
本文中选择几个有代表性的基于RNN和基于传统CNN的方法以及基于非深度学习的机器学习方法作比较,预测下一事件准确率不同方法对比如表2所示。在所有事件日志数据集上,本文用到的预测模型相比其他方法综合效果接近,在BPIC12W上高于其他方法。

表2 预测下一事件准确率
在后缀迹预测任务中,设置输入序列窗口长度大于2即可,本文选择5,预测后缀迹生成结果不同方法对比如表3所示。可以看出本文的方法预测生成的后缀迹在Helpdesk数据集上高于其他方法。造成这个现象的一个原因是BPIC12W事件日志在迹的末尾添加结束标识会导致预测准确率下降,且BPIC12W中的迹存在大量连续重复事件,在业务流程模型中对应循环结构,对预测循环之后的事件准确率有所影响。另一个原因是BPIC12W和BPIC12事件日志中迹的最大长度过大,而平均迹长度远小于迹的最大长度。

表3 生成的后缀与真实后缀平均相似度
5 结语
本文提出一种基于时间卷积网络TCN的业务流程预测方法,使用事件及其对应属性作为输入,预测业务流程的下一个事件和剩余事件,并在3个现实生活事件日志数据集上实验。实验结果表明,在BPIC12W数据集上预测部分事件序列的下一个事件准确率相比于之前的基于RNN类神经网络和基于传统CNN的方法有一定的提升,在另外两个数据集上的结果接近。对于预测部分事件序列的剩余部分,在短流程数据集Helpdesk上要优于之前的方法。后续可以改进的方面包括对TCN结构的改进,使用更先进的序列预测方法以及结合过程挖掘领域的方法。
