基于多块卷积变分信息瓶颈的多变量动态过程故障诊断
2021-12-30何雨旻侍洪波
何雨旻, 侍洪波
(华东理工大学化工过程先进控制和优化技术教育部重点实验室,上海 200237)
随着化工行业的快速发展,化工生产过程的复杂性也随之增加。然而,如此复杂的工业过程一旦发生故障,可能导致严重的财产损失和人员伤亡,因此,高效的故障检测和诊断(Fault Detection and Diagnosis,FDD)方法对于维护化工过程的安全稳定生产是十分重要的[1-4]。在故障诊断方法中,按照建模原理的不同可以分为基于模型的方法以及基于数据的方法两大类。基于模型的方法需要对化工过程进行机理建模,但由于现代化工过程的复杂性,很难直接应用基于模型的故障诊断方法。与此同时,由于集散控制系统(Distributed Control System,DCS)技术的广泛运用,系统可以收集大量的工业数据,这有利于开发基于数据的故障诊断方法。目前,基于数据的故障诊断方法主要根据变量之间的相关性来提取特征。传统的基于数据的故障诊断算法主要有:主成分分析(Principal Component Analysis,PCA)、费舍尔判别分析(Fisher Discriminant Analysis,FDA)、支持向量机(Support Vector Machine,SVM)等[5-9],其中,PCA、FDA 通过线性方法提取特征,不适用于实际的化工过程。而SVM 将故障诊断视为分类任务,建立判别函数对故障进行分类,但这类方法需要手动设计特征,导致实用性有限。此外,上述方法均未考虑过程数据间的时序关联性。因此,为了提高故障诊断方法的性能,应开发一种直接、有效的非线性动态特征提取方法。
深度学习技术能有效地学习复杂、抽象的特征,因此,深度学习在过去几年中引起了FDD 领域研究者的关注[10-13]。其中,变分自编码器利用变分推断能够提取服从标准高斯分布的潜变量,Zhang 等[14]提出了一种基于变分自编码器(Variational AutoEncoder,VAE)的非线性故障检测方法。此外,变分推断不仅可以利用其构建生成模型,还可以结合信息论来提高模型的特征提取能力[15]。Alemi 等[16]结合变分推断与信息论提出了变分信息瓶颈(Variational Information Bottleneck, VIB),从而将与任务目标最相关的信息保留在潜层。另外,在故障诊断任务中,卷积神经网络(Convolutional Neural Network,CNN)被用来提取动态特征,二维卷积神经网络(Two-Dimensional Convolutional Neural Network,2-D CNN)是最常见的卷积神经网络类型。一般来说,2-D CNN 首先将数据进行二维分块,然后与2-D CNN 中的卷积核矩阵进行卷积生成特征。在故障诊断任务中,2-D CNN的输入矩阵通常由一个时间窗内的采样点组成,矩阵维度分别代表采样时间和过程变量。Wu 等[17]采用2-D CNN 提取动态特征的方式进行故障诊断。然而,2-D CNN 同时对输入矩阵的两个维度进行拆分,这将导致每个二维分块内只包含部分变量,这部分变量与初始变量的排序方式有关。变量的不同排序可能导致不同的结果,会引入一定的随机性。此外,不同于2-D CNN,一维卷积神经网络(One-Dimensional Convolutional Neural Network,1-D CNN)将输入数据沿单一维度划分。Chen 等[18]利用1-D CNN 将输入数据沿变量维度划分,以降低变量的维度,用于多变量过程的故障诊断。
受上述研究启发,本文提出了一种多块卷积变分信息瓶颈(Multi-Block Convolutional Variational Information Bottleneck, MBCVIB)模型用于故障诊断,该模型利用1-D CNN 沿时间域维度划分输入数据,提取相邻样本之间的动态特征。1-D CNN 在每次滑动中都会考虑所有变量,因此变量的排序不会引入随机性。同时,1-D CNN 通过并行计算提取动态特征,降低了计算复杂度并且使得梯度能够有效传播。不同的卷积核在1-D CNN 中能够学习到不同的时序相关特性,使得1-D CNN 能够更全面地考虑样本的时序信息。但是由于化工过程中变量数目愈来愈多,1-D CNN 每次考虑所有变量导致模型参数过多,无法有效学习过程的动态特征。因此本文采用变量分块的方式,将属于同一操作单元的变量划分到同一个子块中,在每个子块中使用含有多个卷积层的深度1-D CNN 来学习每个操作单元的局部动态特征表示。其次,为了整合网络学习到的所有局部动态特征,利用特征拼接方法得到全局特征。然后,希望网络能够从提取到的全局特征中保留与故障类别信息最相关的特征,利用信息瓶颈思想从全局特征中进一步提取与故障最相关的特征表示。最后,基于连续搅拌釜反应器(Continuous Stirred Tank Reactor, CSTR)和田纳西-伊士曼过程(Tennessee Eastman Process, TEP)验证了该模型的有效性。
1 基础算法
1.1 1-D CNN
1-D CNN 由卷积层、池化层、全连接层和输出层4 个单元组成。图1 示出了一个输入为多变量时滞数据的1-D CNN 架构,图中T表示输入数据的时间窗长度,V是每一个采样点的变量个数。卷积核f在时域对应的维度上滑动,提取动态特征,它提取每一个卷积层的高层次的抽象特征表示。特征RCl×1可以表示为
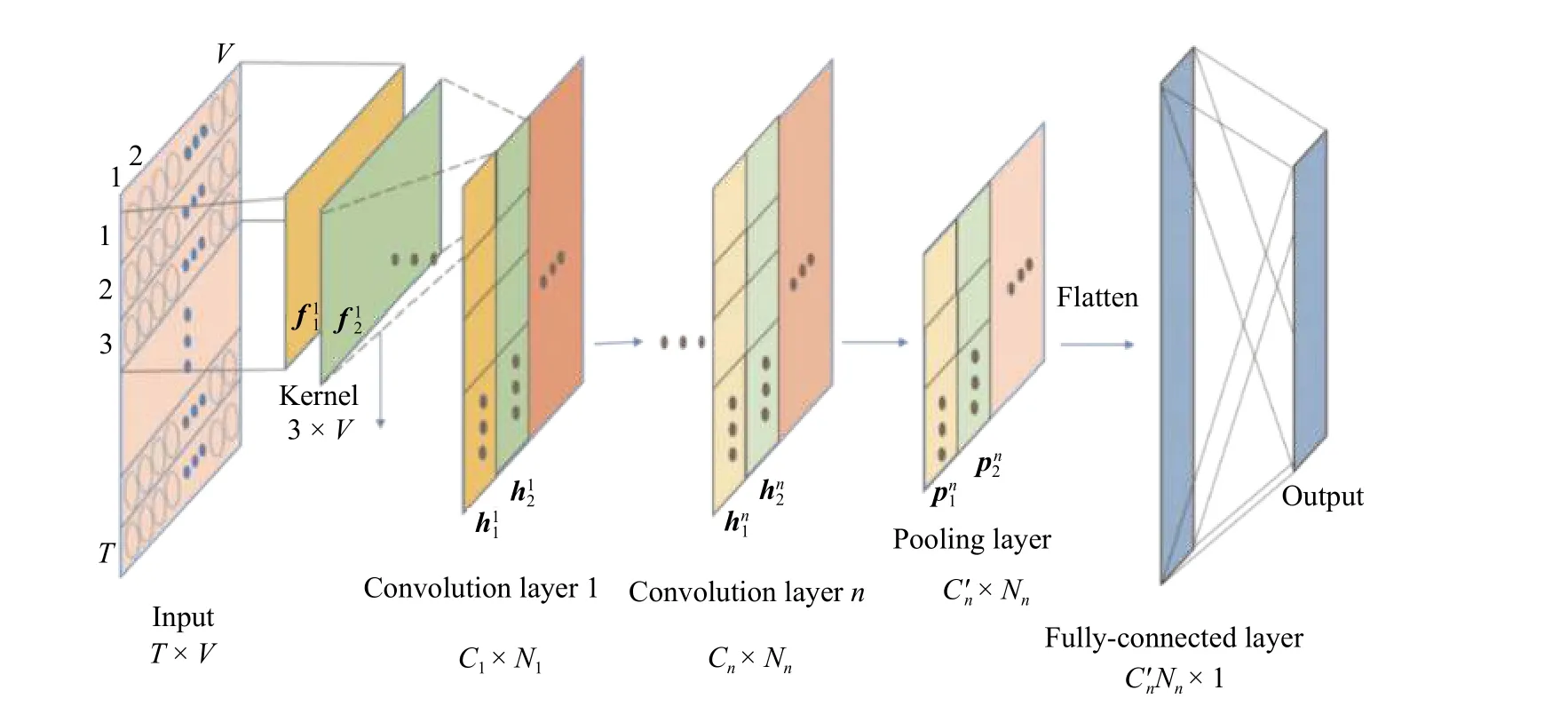
图1 1-D CNN 网络结构图Fig. 1 Network structure of ordinary 1-D CNN
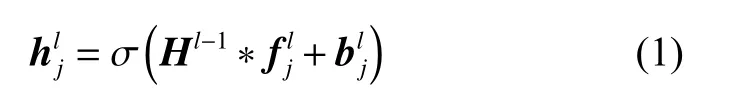
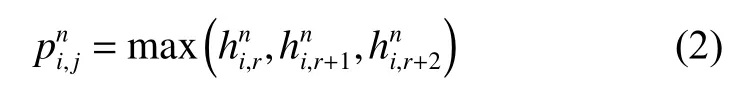
其中:i∈(1,Nn) ,并且j≤Cn−2 。将所有矩形特征张成向量后,得到一个代表输入数据的潜变量。之后应用全连接神经网络从特征中提取目标相关信息,并使用反向传播训练方法来更新该网络的参数。
1.2 互信息
互信息(Mutual Information,MI)利用熵来描述变量之间的非线性相关性。MI 的值可以反映变量之间的相关性强弱,MI 值越大,说明相关性越强。两个变量Xi、Xj之间的MI 值可以定义为[19]
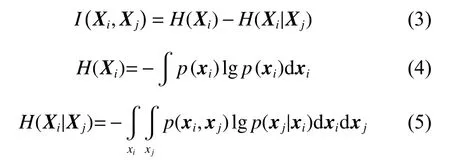
其中:H(Xi) 表示Xi的熵;H(Xi|Xj) 表示给定Xj的条件下,Xi和Xj的条件信息熵。
2 MBCVIB 模型
为了使卷积核能够在相邻时间步上滑动卷积来提取动态特征,1-D CNN 进行卷积时需要考虑所有变量。但对于多变量过程故障诊断,由于变量数量多,并且变量之间的相关性不同,使得网络可能难以提取有效的动态特征,因此,本文提出以局部提取、全局整合的方式提取过程的动态特征。此外,为了提取与故障更相关的特征表示,减少特征中存在的冗余信息,利用VIB 进一步提取表征故障信息的特征。
2.1 基于过程机理的变量分块方法
大型工业过程普遍由多个操作单元构成,其中各操作单元都具有其独特的功能和对应的变量,并且操作单元间存在相互联系。因此,根据工艺流程的机理结构,本文提出对各操作单元对应的变量建立1-D CNN 模型,在属于同一操作单元的相关关系强的变量中提取局部动态特征,然后,整合模型提取的局部特征得到反映整个流程运行情况的全局特征。
假设Xt表示在t时刻的时滞输入数据,包括t时刻以及前T−1 个时刻的数据,T是Xt的时间窗口大小,每个时刻数据有V个变量,Xt可以表示为
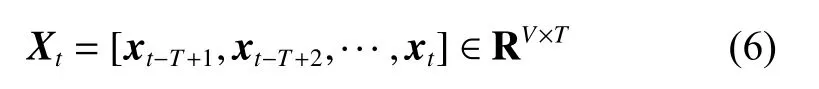
若一个流程包括p个操作单元,并且每个操作单元中的变量形成一个独立的子块,得到p个子块,那么输入数据可以根据式(7)和式(8)来构建:
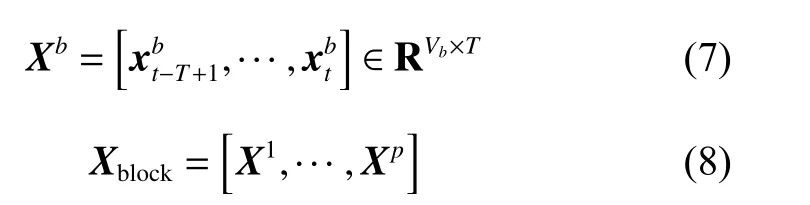
其中:Xb∈RVb×T为一个子块,b∈(1,p) ;Vb为第b个子块中的变量数;Xblock∈RV×T为分块后的输入数据。
2.2 并行多块1-D CNN 建模策略
整个并行建模的网络结构如图2 所示。在按照过程机理将变量分块之后,对每个子块(即每个操作单元中包含的变量)建立1-D CNN 模型以提取每个操作单元的的局部动态特征,然后利用特征拼接法整合局部动态特征,得到全局动态特征,且使得网络能够并行训练。
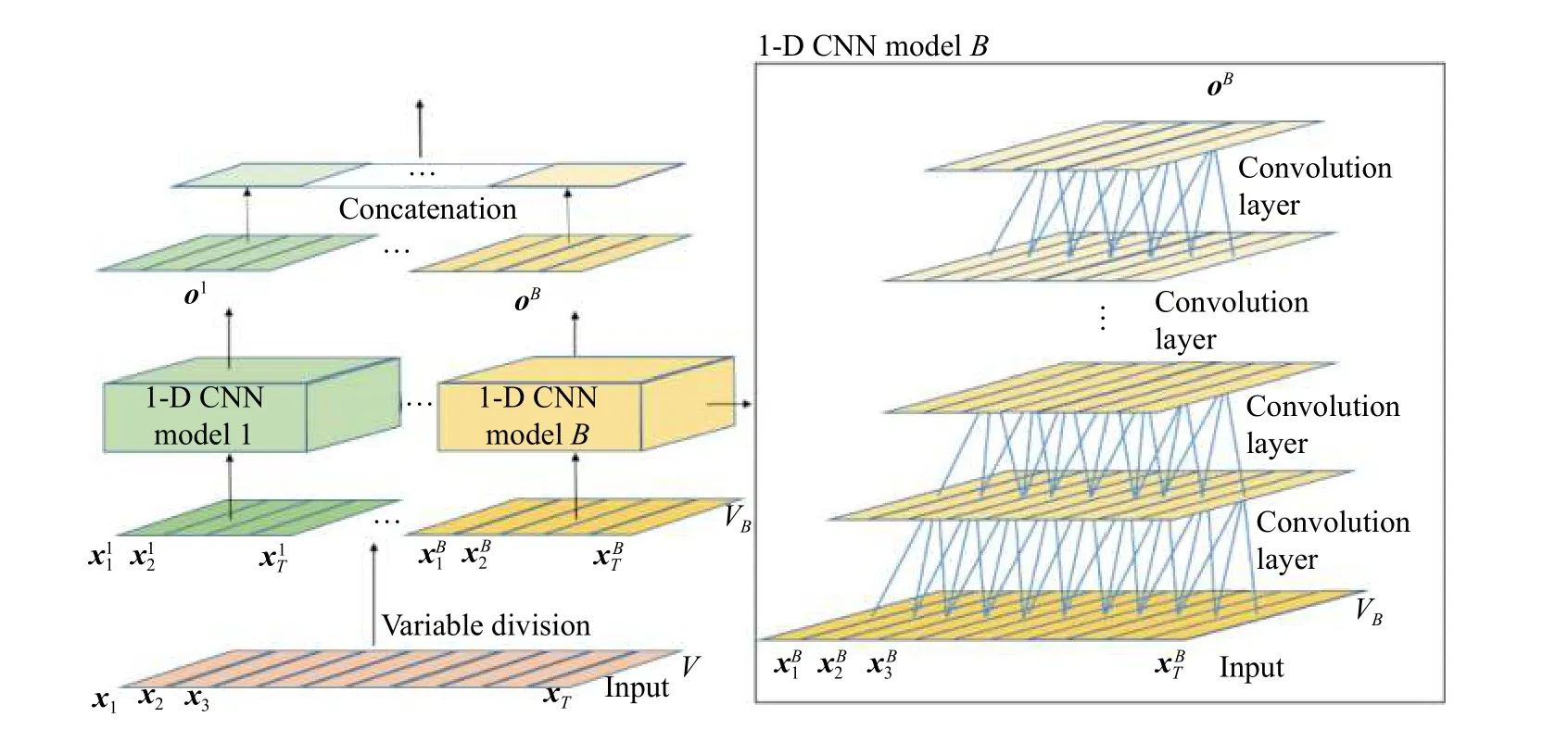
图2 并行多块1-D CNNFig. 2 Parallel multiblock 1-D CNN
本文采用的1-D CNN 不同于1.1 节的传统1-D CNN,模型中未对最后一层卷积层进行池化操作。因为池化对网络所提取的特征进行下采样,这可能会导致部分与故障诊断有关的特征丢失。因此,每个1-D CNN 模型的最后一层卷积层的输出即为局部动态特征。为了整合所有的局部动态特征以获得全局动态特征,采用特征拼接方法对所有子块的局部动态特征进行串接,得到能表征整个输入过程数据的全局特征表示,并且所有1-D CNN 模型都可以通过这种特征整合方式进行并行训练。该特征拼接法可表示为
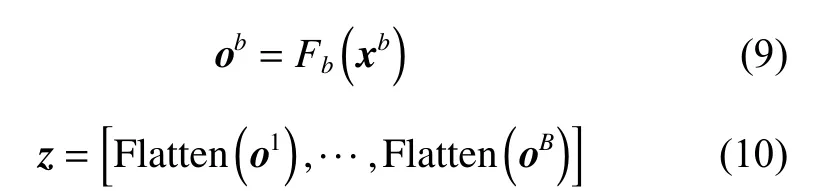
其中:xb∈RT×Vb;ob∈R(T−L·(K−1))×N;z∈R1×B·(T−L·(K−1))·N),表示所得到的全局特征表示;Fb表示子块b中的1-D CNN 网络;B表示子块数;L表示网络层数;N表示卷积核个数;K表示卷积核尺寸;Flatten 表示将矩阵形式的特征展开为向量形式。通过这种方式,可以把从所有子块中提取的局部特征矩阵整合成一个全局特征向量。
2.3 变分信息瓶颈模型
在特征提取阶段,通过整合所有局部特征得到了全局特征,这可能带来与故障诊断任务无关的冗余信息,因此,希望利用信息瓶颈思想过滤这部分信息,从而提取最精炼的特征表示。信息瓶颈理论[20]定义了一个最优的特征表示,即网络所学习到的特征应该与输入X之间的互信息最小,同时与理想输出Y的互信息最大。因此,信息瓶颈中的学习目标可以写为极大化式(11):

其中:Z表示网络所学习到的输入数据的特征表示;I(Z,X;θ) 表示Z和X之间的互信息;I(Z,Y;θ) 表示Z 和Y之间的互信息; β 表示权重; θ 表示网络参数。在故障诊断任务中,理想输出Y是故障类别信息。我们希望利用实现了特征瓶颈思想的深度学习方法(VIB)来保留与输入数据X对应的全局特征Z中和故障类别信息Y最相关的部分,同时过滤噪声,故引入瓶颈信息表征Z′,构建Z-Z′-Y的信息瓶颈,使得模型能够在瓶颈信息表征Z′中保留与故障信息Y最相关的信息,忽略与Y无关的信息。因此,将Z、Z′代入式(11),并结合式(4),可得:

其中,q(z′|z)=N(z′|fµ(z),fσ(z)) ,fµ、fσ分别是两个输出为K维的全连接神经网络,用来表示高斯变分后验分布q(z′|z) 的均值和方差。最后,结合样本标签和交叉熵损失函数,利用重参数方法[14],可使式(14)能够通过反向传播算法寻找最优值。MBCVIB 网络结构如图3 所示。
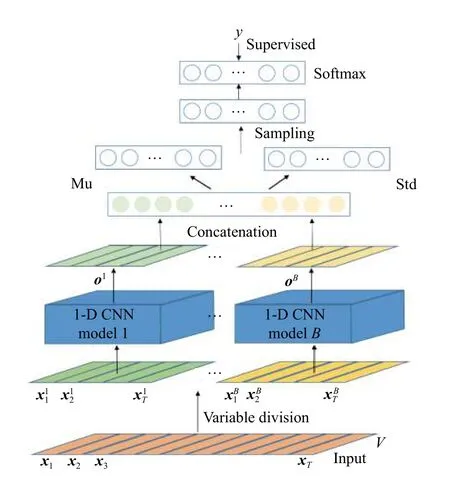
图3 MBCVIB 网络结构Fig. 3 Network structure of MBCVIB
2.4 基于MBCVIB 的故障诊断
MBCVIB 利用1-D CNN 网络在过程中对每个操作单元提取局部动态特征,使用特征拼接法整合局部动态特征来获得全局动态特征,并结合变分信息瓶颈进一步提取全局动态特征中与故障类别信息最相关的部分进行故障诊断。基于MBCVIB 的故障诊断的具体实现流程如图4 所示,分为离线训练和在线诊断两个阶段。
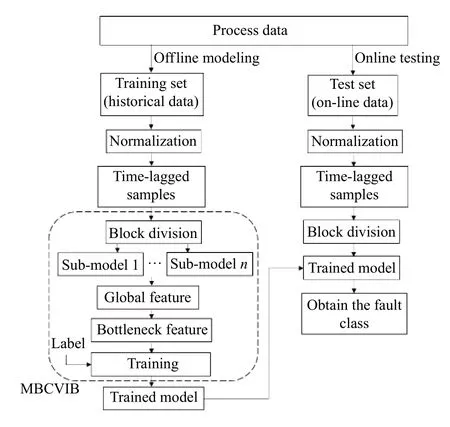
图4 基于MBCVIB 的故障诊断方法流程Fig. 4 Procedure of fault diagnosis method based on MBCVIB
离线训练:
(1)获得训练数据集X∈RU×V以及相应的故障类别标签Y∈R1×U,其中U为采样点总数,V为变量个数;
(2)对训练数据集X进行标准化处理,得到标准化后的训练数据集X′;
(3)利用时间步长为T的时间窗将X′转化为时延数据集XT∈R(U−T+1)×(T×V),并获得对应的标签YT∈R1×(U−T+1);

(5)对每个子块建立1-D CNN 模型,获得局部动态特征zb,通过特征连接法,整合所有局部特征,获得全局动态特征z;
(6)根据高斯后验分布q(z′|z)=N(z′|fµ(z),fσ(z)) ,可以得到瓶颈特征z′;
(7)结合类别标签Y,通过Adam 算法最小化式(14)训练模型。
在线诊断:
(1)获得新的时延样本xtest∈RT×V;
(2)利用离线建模中步骤(2)中得到的均值和方差对数据xtest进行标准化;
(5)得到测试样本xtest所对应的故障类别。
3 仿真实验
3.1 连续搅拌釜反应器
CSTR 过程是一个评估故障诊断方法性能的基准过程,其仿真设置与Alcala 等[21]的实验类似,选取9 个变量作为故障诊断的监控变量,包括冷却水温度TC、入口温度T0、入口浓度CAA和CAS、溶剂流量FS、冷却水流量FC、出口浓度CA、温度T和反应物流量FA。本文设置了9 个故障进行故障诊断,具体故障描述如表1 所示,其中E/n和Uac为仿真参数[21]。每类故障数据采集1000 个样本,采样间隔为0.2 min,设置的时间窗口大小为10 个样本,滑动步长为0.2 min,每类数据的维度为90×991。将转化后的时延数据的一半随机分离作为训练数据,另一半数据作为测试数据。为了说明MBCVIB 的故障诊断性能,以支持向量机(SVM)、堆栈自编码器(Stacked AutoEncoder,Stacked AE)、二维卷积神经网络(2-D CNN)、长短期记忆循环神经网络(Long Short-Term Memory,LSTM)作为对比算法。对于SVM、Stacked AE,输入时滞数据的维度为1×90。对于2-D CNN、LSTM、MBCVIB,时滞数据的维度为9×10。SVM 算法加入了径向基核函数从而考虑过程非线性因素。其他基于神经网络方法的详细结构和参数列在表2 和表3 中,其中MBCVIB 的 β 参数参考Tishby 等[20]的实验设置为0.001。对于MBCVIB,根据2.1 节介绍的基于过程机理的子块划分策略,变量划分结果如表4 所示。

表1 CSTR 故障描述Table 1 Faults description in CSTR

表2 CSTR 故障诊断模型结构Table 2 Detailed fault diagnosis model structures in CSTR

表3 CSTR 故障诊断模型参数Table 3 Fault diagnosis model parameters in CSTR

表4 CSTR 分块结果Table 4 Block division result in CSTR
表5 列出了MBCVIB 和其他模型的故障诊断精度。从表5 可以看出,MBCVIB 对所有故障的总体准确率都超过了0.87,平均准确率最高,达到了0.983。而其他模型不能对所有故障保持类似的精度水平,它们对一些故障的准确度较差。结果表明,基于MBCVIB 的故障诊断优于其他模型。
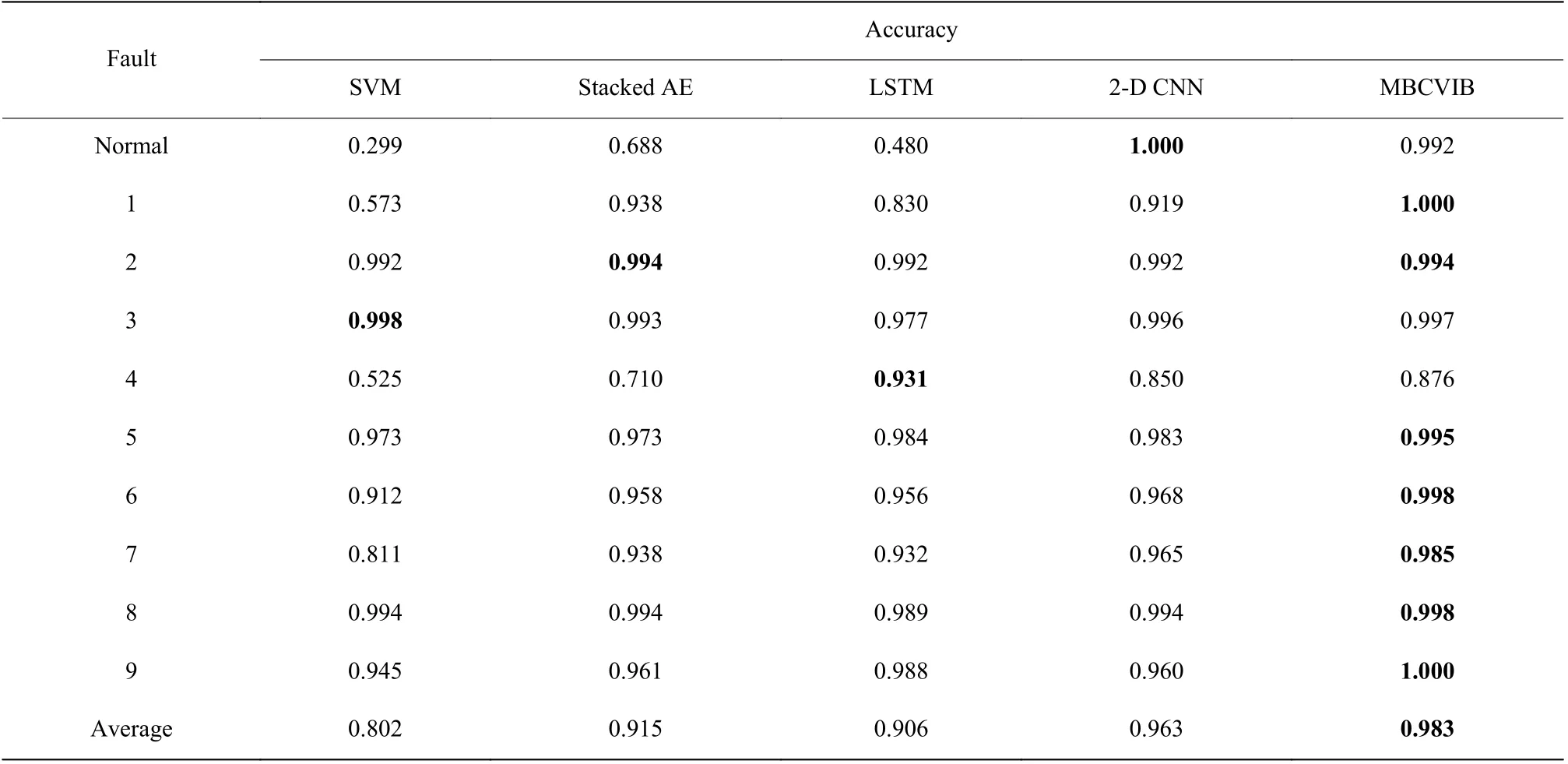
表5 不同模型在CSTR 上的故障诊断准确率Table 5 Fault diagnosis accuracy of different models on CSTR
3.2 田纳西-伊士曼过程
TEP 是一个被广泛运用于故障检测与诊断的基准过程[22-23],有5 个操作单元:反应器、冷凝器、压缩机、分离器和汽提器。整个过程包含52 个变量、41 个连续过程变量(XMEAS 1-41)和11 个操纵变量(XMV 1-11)。TEP 数据集设置了20 个故障类型,包括15 个已知故障和5 个未知故障。其中,故障3、9、15 由于均值、方差和高阶统计特征和正常数据无明显变化[24],因此在实验中不对故障3、9、15 进行研究,对剩余的17 个不同故障类型以及正常工况下的数据进行了详细的对比。实验中的训练数据集由500 个正常样本以及每类故障的480 个样本组成,测试数据集由960 个正常样本和每类故障的800 个样本组成。数据的采样时间间隔为3 min。由于故障6 在故障开始7 h 后系统直接停机,因此故障6 的测试样本和训练样本只包含140 个故障样本点[17]。采用3.1 节中的对比算法,验证MBCVIB 在TEP 中的故障诊断性能。时间窗长度参考了Wu 等[17]的实验,设置为20 个样本,滑动步长设置为3 min。TEP 实验数据如表6 所示。对于SVM、Stacked AE,输入时滞数据的维度为1×(52×20)。对于2-D CNN、LSTM、MBCVIB,时滞数据的维度为52×20。基于神经网络方法的详细结构和参数见表7 和表8。SVM 的核函数选择与CSTR 实验相同。其中MBCVIB 的参数 β设置与CSTR 实验相同。
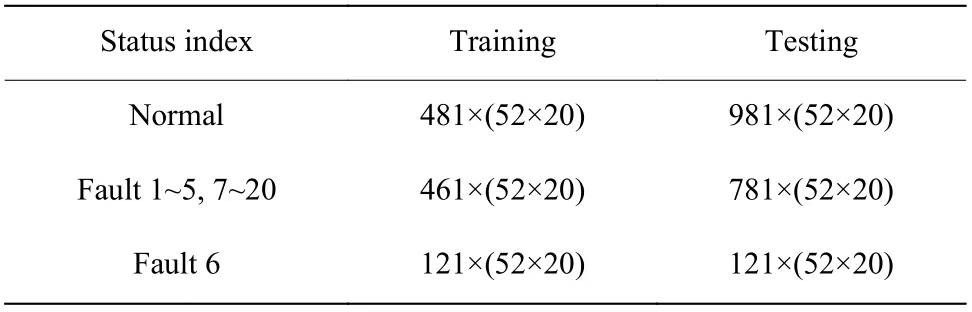
表6 TEP 实验时延数据维度Table 6 Time-delay data dimension of TEP

表7 TEP 故障诊断模型结构Table 7 Detailed fault diagnosis model structures in TEP

表8 TEP 故障诊断模型参数Table 8 Detailed fault diagnosis model parameters in TEP
对于MBCVIB,首先根据基于过程机理的变量划分方法将变量分成几个子块。TEP 中属于各操作单元的变量列于表9,其中XMEAS 表示连续过程变量,XMV 表示操纵变量。冷凝器和回收压缩机的变量对于其他运行单元来说相对较少,因此,为了简化模型,将这两个运行单元的变量合并为一个子块。表10 示出了TEP 的区块划分结果。

表9 TEP 中每个操作单元的变量Table 9 Variables of each operation unit in TEP

表10 TEP 分块结果Table 10 Block division result of TEP
表11 比较了了MBCVIB 和其他模型在TEP 基准上的故障诊断准确度。与其他模型相比,MBCVIB在正常类以及故障8、故障10、故障11、故障16 上的精度提升明显。此外,MBCVIB 的总体平均精度最高,达到0.955。以上结果均说明了MBCVIB 相比于其他模型在TEP 过程上具有更好的故障诊断性能。
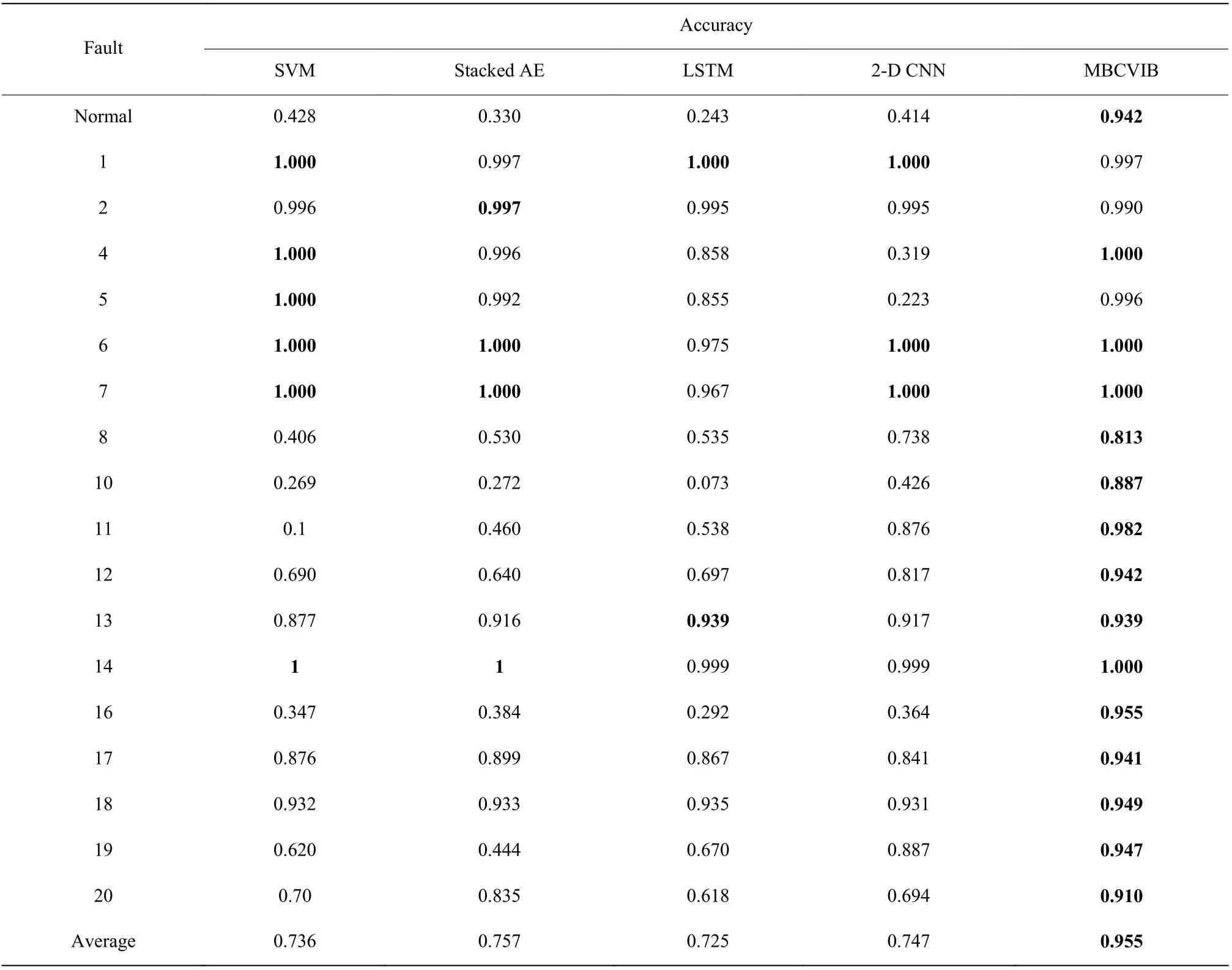
表11 不同模型在TEP 中的故障诊断准确率Table 11 Fault diagnosis accuracy of different models on TEP
为了探究VIB 对特征的提取能力以及对故障诊断效果的影响,本文利用t 分布随机领域嵌入(tdistributed Stochastic Neighbor Embedding,t-SNE)方法[25]对所提出的模型以及不含VIB 层的同一模型进行特征可视化实验,即可视化展示这两个模型在测试集中提取到的特征。通过t-SNE 将测试数据中得到的特征缩减至二维后,特征可视化的结果如图5 所示,其中x1,x2表示将特征在压缩后的两个维度。从图5(a)可以看出,缺少VIB 层的模型所提取的特征分离度较差,并不能很好地区分属于故障0、故障10、故障16 的特征。然而,含有VIB 层的模型提取的特征能够很好地区分属于不同故障类型的特征,如图5(b)所示。这也说明了根据信息瓶颈思想所提取的特征能够过滤掉全局特征中可能对故障诊断带来影响的冗余信息,只保留了和故障最相关的特征表示。因此,基于MBCVIB 的故障诊断方法能提取到可视化分离度更高的特征。
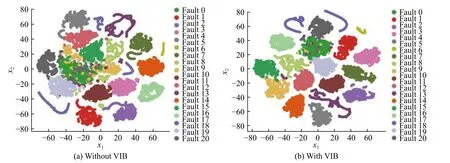
图5 特征可视化结果Fig. 5 Consequences of feature visualization
TEP 和CSTR 实验均表明,MBCVIB 与其他模型相比具有优越的故障诊断性能,可以提取有效的特征。这些结果说明了MBCVIB 中对于动态特征提取的 “局部提取、全局整合”策略的有效性,以及利用信息瓶颈进一步提取故障相关信息的可行性。在MBCVIB 中,局部动态特征是从不同操作单元中提取的,这样可以在密切相关的变量中提取详细的动态特征。局部特征拼接法整合局部特征以获得全局特征,使得子模型可以并行训练。其他模型则是同时考虑所有变量和动态特征之间的相关性,而不是从不同的操作单元中提取局部动态特征,这使得在特征提取过程中,过程数据的相关性更加复杂。因此,其他模型的特征不能像MBCVIB 中的全局特征那样有效地反映过程的动态性质。另外,由于全局特征中整合了所有子块所提取到的特征,为了过滤冗余信息,只提取与故障特征最相关的信息,故引入信息瓶颈思想从全局特征中进一步提取与故障类别信息最相关的瓶颈特征,使得瓶颈特征与故障类别分布间的互信息最大,同时与全局特征互信息最小,过滤掉全局特征中存在的与故障诊断无关的信息,让所提出的模型能够更有效地对故障进行诊断。
4 结束语
本文提出了一种基于MBCVIB 的多变量动态过程故障诊断方法。在多变量动态过程中,动态特征往往伴随着变量之间复杂的相关性,这给特征提取带来了困难。因此,在MBCVIB 中采用了一种新颖的动态特征提取思想,即“局部提取、全局整合”。MBCVIB 利用过程机理将属于同一操作单元的变量分配到相同子块中。利用1-D CNN 从子块中提取局部动态特征,再利用局部特征拼接法整合所有的局部动态特征,得到全局动态特征,同时,这些1-D CNN 子模型可以并行训练,再利用VIB 从全局动态特征中过滤与故障诊断任务无关的冗余信息,进一步提取与故障类别信息最相关的瓶颈特征用于故障诊断。本文在TEP 和CSTR 数据集上验证了基于MBCVIB 的故障诊断方法的性能。所提出的方法在TEP 上实现了0.955 的平均故障诊断准确率,在CSTR上实现了0.983 的平均准确率。这些结果说明了所提出的方法的有效性,证明了所提出的方法在化工过程故障诊断中的潜力。
