DDPG优化算法的机械臂轨迹规划*
2021-12-29张浩博仲志丹乔栋豪杨遨宇
张浩博,仲志丹,乔栋豪,赵 耀,杨遨宇
(河南科技大学机电工程学院,河南 洛阳 471003)
0 引言
机械臂的轨迹规划是指在满足一定的约束条件下,计算出一条连接起点和终点的轨迹[1-2]。传统的机械臂轨迹规划主要包括人工势场法[3]、蚁群算法[4]、快速随机树法[5]等,这些方法都需要在已知的环境中进行训练,且动态规划较差,智能性较低。随着深度强化学习(Deep Reinforcement Learning,DRL)的发展,具备了让智能体在未知的环境中进行自主学习的能力,深度学习(Deep Learning,DL)使用多层神经网络学习,在特征提取和事物感知方面具有独特的优势,强化学习(Reinforcement Learning,RL)是一个顺序决策问题,在马尔科夫决策过程中,通过获得最大的奖励来找到最优的策略。DRL结合了DL和RL的优势,可以很好地完成在复杂的环境下对机械臂的控制[6]。
Mnih V等[7]提出了DQN算法,将神经网络与Q-learning相结合,并且在Atari 2600游戏中进行了训练,最终训练的水平远高于人类。Lillicrap T P等[8]用DDPG算法,将其应用到高维连续动作空间。Rusu A A等[9]将仿真环境下训练的结果迁移到实体机械臂上,只需要进行简单的训练之后就能达到与仿真相似的效果。柯丰恺等[10]基于DDPG算法,提出根据TD-error变化的优化采样算法,并将其应用到机械臂。陈建平等[11]提出的E-DDPG算法,增加了多样性和高误差样本池,收敛速度更快。Li Z等[12]通过添加成功经验池和碰撞经验池改进传统的经验池,与传统的DDPG算法相比,改进后的DDPG算法效果更好。Luck K S等[13]将DDPG算法与基于模型的轨迹优化方法相结合,利用已学习到的深度动力学模型来计算策略梯度,以价值函数作为评判标准,从而提高了训练的效率。综上所述,以上方法并未改变样本的提取方式,仍然是均匀地从经验池中采集样本进行训练,智能体不能高效地学习到成功的样本,从而导致训练时间较长。
针对上述问题,本文以深度确定性策略梯度(DDPG)算法为基础,采用以SumTree[14]数据结构的加权采样方法来代替均匀采样的方法,使成功的样本有更大的几率被智能体学习,并对Q-learning动作价值函数进行优化,在训练起始阶段引入OU随机噪声模型,最后将其应用到机械臂上,经实验仿真表明,优化后的DDPG算法能够使机械臂更加快速地完成任务。
1 深度强化学习算法
1.1 强化学习模型
强化学习是机器学习的重要分支之一,它是一种自监督的学习方式。在智能体与环境交互过程中,假设环境是完全可观测的,包括状态S,执行动作A,奖励函数R,初始状态p(s0),状态转移概率p(st+1|st,at)以及折扣因子γ,这些成分构成了一个元组{S,A,R,P,γ},表示为马尔科夫决策过程。
在训练开始时,从分布p(s0)中采样初始状态s0,在每个时间步长t下,智能体在当前状态st下执行一个动作,该动作遵循策略at=π(st),策略π表示从状态空间到动作空间的映射。之后,环境反馈一个奖励rt=r(st,at),并从状态转移概率p中采样下一个状态st+1。在每个时间步长t,智能体获得的奖励会减少γ倍,即:
(1)
γt随着训练时长的增加而变小,即后期的奖励对当前决策影响较小。
强化学习的目标是选出最优的一系列动作,使得机械臂在任意步数获得期望的奖励值为:
(2)
定义策略函数π:S→A,从状态到动作的映射a=π(s),即为机械臂中的决策策略,优化策略函数的过程即根据机械臂在不同的状态下执行不同的动作,并使期望奖励值最大化。通过构造状态动作价值函数和动作对总奖励的影响,策略π在某状态st下执行动作at所获得的总奖励期望定义如下:
Qπ(st,at)=Est+1~psa[r(st,at)+γEat+1~πQπ(st+1,at+1)]
(3)
其中,r(st,at)为机械臂获得的奖励,γEat+1~πQπ(st+1,at+1)是策略π在未来累积奖励的期望。机械臂在初始状态s下获得的期望奖励值为:
(4)

1.2 深度确定性策略梯度算法
机械臂执行的任务是连续状态空间,因此本文选择适用于连续状态空间的DDPG算法,该算法采用深度性行为策略,通过相应的函数得到确定的动作值,使用参数为θμ的actor网络表示确定性策略μ(s|θμ),参数为θQ的critic网络表示状态动作价值函数Q(s,a|θQ),采用确定性策略可以充分地利用机械臂与环境进行交互并产生训练数据。确定性策略用μ表示,其动作价值函数表示为:
Qπ(st,at)=Est+1~psa[r(st,at)+γQμ(st+1,μ(st+1))]
(5)
确定性策略梯度法到目标函数的梯度为:
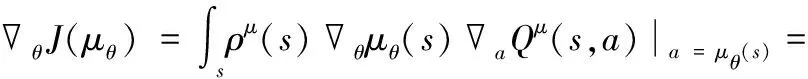
(6)
其中,控制策略μ为机械臂的动作,Q网络为动作价值函数。训练这些深层神经网络要求输入数据是独立且均匀分布的,而强化学习模型是马尔可夫决策过程,数据是顺序采集的,并不满足要求。因此引入DQN(Deep Q-learning Network)的经验重播来打破数据相关性。
当经验池储存的训练数据达到一定数量之后,按照均匀采样的方式,从经验池中采集数据进行训练Q网络。
2 动作价值函数和OU随机噪声模型的设计与优化
2.1 动作价值函数的设计与优化
动作价值函数是判断机械臂行驶当前策略好坏的重要依据,Q网络的输入包含了机械臂当前的状态和动作,采用神经网络对Q函数进行拟合。
本文采用Q-learning算法对Q网络进行优化,同时也用到了策略网络,优化的目标函数为:
δt=rt+γQ(st+1,μ(st+1))-Q(st,at)
(7)
同时设置了Q网络和策略网络的目标网络Q′、μ′,计算如式(8)所示:
δt=rt+γQ′(st+1,|μ′(st+1|θt))-Q(st,at)
(8)
对于Q网络在训练过程中,对参数的更新会产生延时误差,本文采用如下公式进行更新:
ω′←τω+(1-τ)ω′
θ′←τθ+(1-τ)θ′
(9)
其中,ω、ω′是Q网络参数和目标网络参数,θ、θ′是机械臂策略网络参数和目标网络参数。
2.2 OU随机噪声模型的设计
深度强化学习在训练之初,机械臂会在相同的状态下执行相同的动作,不具备探索能力。本文在训练起始阶段对控制策略的生成动作中加入Ornstein-Uhlenbeck(OU)噪声,此时噪声的方差较大,使机械臂能够搜索较多的空间,可以尝试更多的动作,并通过当前状态信息和奖励大小进行学习。在训练中后期控制策略产生的动作大体上可以完成规定的任务,此时机械臂只需要小范围的搜索并微调控制策略,产生更多成功的训练样本,优化控制策略,此刻的噪声方差应尽可能的小。
OU噪声是一种随机变量,应用于和时间相关联的噪声数据,其产生方式如下式所示:
dxt=θ(α-xt)+σWt
(10)
其中,xt是需要产生的数据,设置的随机变量期望用α表示,随机变量用W表示。
3 基于SumTree加权采样的DDPG算法的研究与设计
机械臂每次与环境交互所获得的数据(st,at,st+1,rt)被储存在经验池(Replay Buffer)中,传统的DDPG算法视经验池中所有样本对网络训练的价值是相同的,以均匀随机采样的方法提取训练样本。但实际上经验池中的样本对于网络训练有较大的不同。在机械臂轨迹规划的实际训练中,成功的案例较少,失败的案例居多,如果采取均匀随机采样的方法会导致成功的样本难以被提取出来进行训练。
SumTree作为二叉树结构存取数据,本文将它运用到DDPG算法的经验回放中。在DDPG算法中运用目标Q值和现实Q值差值的期望进行更新策略网络和价值网络中的参数,差值越大代表参数的选取并不准确,即样本更需要被机械臂训练。因此本文将目标Q值与现实Q值所产生的损失值作为优先权的标准,表达式为:
(11)
其中,P(i)为训练样本的第i个元组被采样的概率,β为常数,β越大则优先权的比重就越大,k为经验池的样本总数。
经验池中储存的元组,相对于之前的(st,at,st+1,rt),优化之后为(st,at,st+1,rt,δt),其中δt的计算如式(7)所示。SumTree的结构如图1所示。
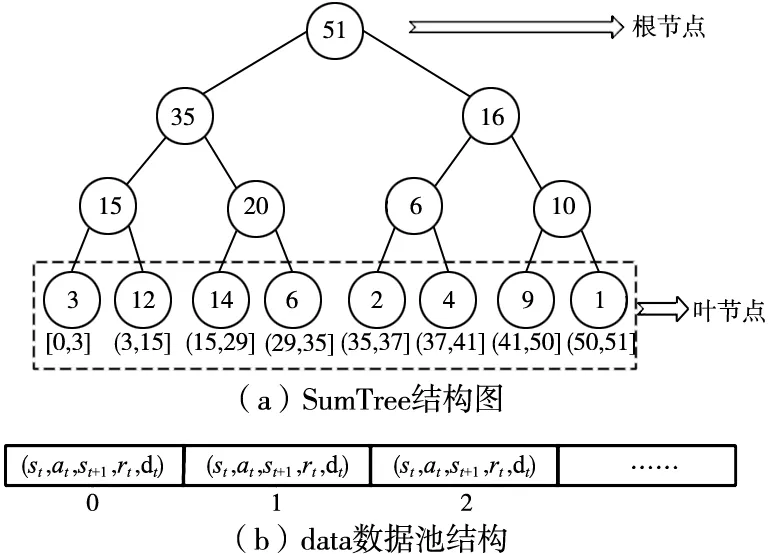
图1 结构图
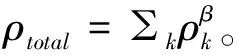
在建立好SumTree的结构后,对经验池中的数据用以下方式进行采样:首先,从[0,ρtotal]采样出一个权值ρ1,接着从根节点开始比较,采取从左往右从上到下的顺序,若选取的权值ρ1小于等于左节点权值,则走左边子节点这条,若选取的权值ρ1大于左节点权值,则用ρ1减去左节点的权值,并将所得到的新的权值赋值给ρ1,接着以右节点作为新的节点继续向下进行采集,直到当前的节点为叶节点的时候,提取其中的数据,搜索结束。
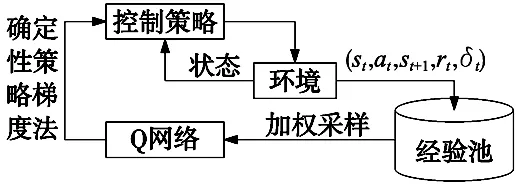
图2 加权采样的DDPG算法
优化后的DDPG算法如表1所示,其中训练步数用episode表示,每个步数下策略的时长序列用T表示。

表1 基于SumTree的DDPG优化算法
4 实验仿真
4.1 仿真实验的准备

图3 机械臂仿真环境
ROS(Robot Operating System)是一款机器人仿真开源平台,使用ROS平台仿真主要应用到了它独特的通讯机制(话题的发布和订阅,可以通过修改话题内容和订阅者对机械臂模型进行修改。Gazebo是ROS平台中的仿真工具,在Gazebo中建立一个UR5机械臂作为实验主体,在工作平台上放置障碍物,获取Gazebo发布机械臂的状态作为Q网略的输入,算法输出的动作发布到action话题,实验主体订阅action话题,即可在仿真环境中做出相应的动作。图3为UR5仿真环境的搭建。
UR5机械臂经过训练之后,可以有效地避开环境中的障碍物,并沿着能够获得最大奖励值的方向进行轨迹规划,最终可以到达指定的目标点,如图4所示。
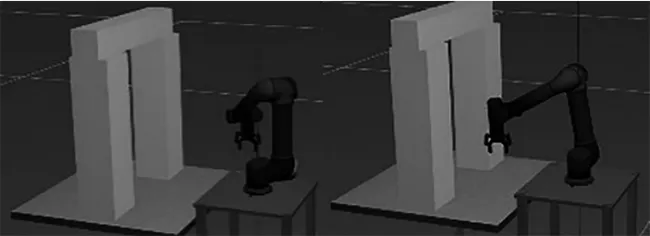
(a) 起始姿态 (b) 第2步

(c) 第3步 (d) 最终姿态图4 机械臂轨迹规划避障过程
将传统DDPG算法和优化后的DDPG算法进行比较,除了对数据采样的方式不同之外,其他参数均相同,具体参数设定如表2所示。
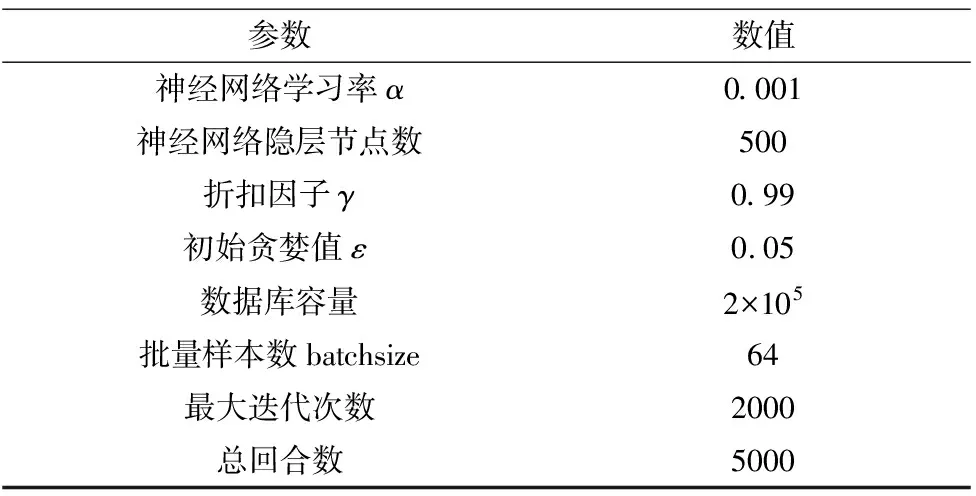
表2 算法的相关参数
4.2 实验仿真数据分析
机械臂在学习训练过程中,获得的累积奖励越高,说明机械臂完成任务所选择的动作越优,对比两种算法在每一百回合中获取的平均累积奖励,奖励越高表明机械臂规划的轨迹越优。从图5可以看出,加权采样的DDPG算法在3000回合趋于稳定,即达到了最大累积奖励,经典的DDPG算法在6500回合趋于稳定,相比之下学习效率提高了53.8%。
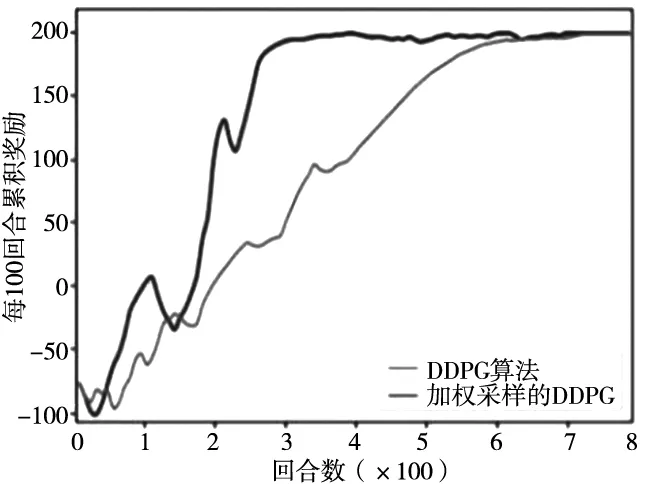
图5 训练过程中的奖励
在仿真8000回合之后,得到最终训练结果的成功率,如图6所示。实验结果表明,基于加权采样的DDPG算法在训练3000回合后成功率可以保持在90%以上,而传统的DDPG算法在6000回合后达到90%以上。通过该仿真实验可以验证在轨迹规划任务中,加权采样的DDPG算法与传统的方法相比较,学习速率提高了一倍以上,能够快速地实现机械臂的学习训练,效果较为明显。
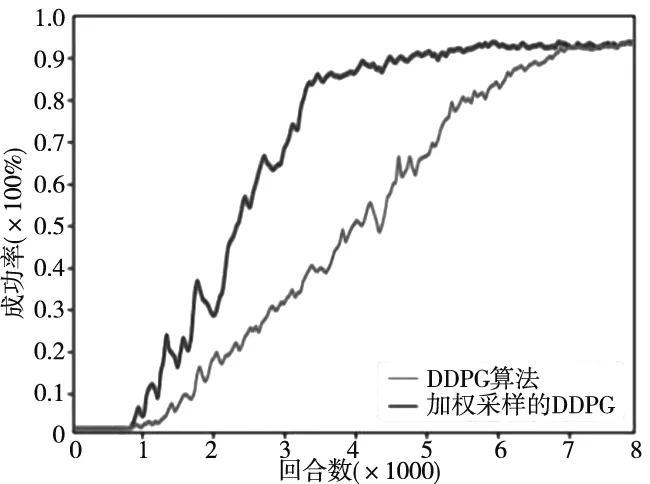
图6 机械臂完成任务的成功率
5 结束语
本文首先通过对现存的基于深度强化学习的DDPG算法进行改进,对Q-learning的动作价值函数进行优化,并在训练起始阶段引入了OU噪声模型,增强了智能体的探索能力,从而得到更好的控制策略,其次,对传统DDPG算法的均匀采样进行改进,采用SumTree数据结构的加权采样方法,对经验池中的每个样本添加优先权,提高了机械臂的学习速度,大大减少了训练的时间。实验表明,经过加权采样的DDPG算法,训练六自由度的机械臂效果明显提高,收敛速度更快。
