基于大数据分析的负载平衡数据分级存储方法
2021-12-28黄永生
黄 永 生
(合肥职业技术学院 现代教育技术中心,安徽 巢湖 238000)
0 引 言
随着互联网技术和计算机技术的发展,各种应用业务不断产生新的数据信息,造成数据信息量呈现几何式增长。这些数据信息是企业各种业务运行的基础,对于企业发展至关重要,因此企业每年都会投入大量的资金对数据信息进行存储和管理[1]。然而,数据的增长是无限的,单靠企业的本地存储远远无法满足需要,造成企业的数据信息存储压力增大,且随着时间推移,应用业务产生新的数据信息经常出现不可储存或者已经存储的数据不可访问的问题。在此背景下,分布式存储方式出现,即将数据存储到由许多独立、廉价的机器组成的存储介质当中,如磁盘、磁带、光盘、固态盘等[2]。然而,分布式存储存在一个大的问题,即数据信息不能均衡地存储在设备上,造成了局部或部分存储设备存储量过大,而有的存储设备存储量过小,导致存储设备空间利用率较低,增加了数据存储成本、降低了数据存储效率。
面对上述问题,很多专家和学者都进行了研究和分析[3-5]。如,余芸等人提出基于一致性Hash的电力企业MDS集群高质量元数据管理模型[4],通过一致性Hash算法设计元数据框架,构建一致性Hash集群数据管理模型,备份结点策略保留MDS失效数据信息,利用数据延迟处理方式促使集群变化数据迁移量减少,能够有效实现数据进行分布均匀;龙赛琴等人提出一种基于CloudSim的分级云存储仿真模型[5],通过云存储集群进行数据存储分级设计,利用数据I/O业务处理方法进行稠密数据特征优化,选择适合的行存储或列存储格式;D.M.Banks等人研究了一种固态存储装置,以此来应对越来越多的数据存储问题,缓解了企业数据存储压力。
以上方法均有效解决了企业数据存储压力,但是未考虑存储成本及数据的利用率。为此,本研究结合前人研究经验,在分级思想的引导下,结合大数据分析技术,实现大数据负载平衡存储的目的。该研究首先对分级存储方式及其对应的存储设备进行分析,然后对数据信息价值进行评估,最后根据评估结果将数据信息迁移到不同的存储设备中,实现数据存储。通过本研究以期为数据存储提供参考和借鉴,解决企业数据存储压力。
1 负载平衡数据分级存储方法
随着数据量的增多,企业面临的数据存储压力越来越大,因此对数据存储提出了更高的要求。面对这种情况,企业一开始选择扩大存储空间来解决,但是业务数据每时每刻都在产生,因此扩大存储空间仅能暂时解决问题,而要长远解决问题,只能选择将数据存储到异地存储设备中[3]。在此背景下,本文研究一种分级存储方法,将海量数据均衡地分布存储到不同等级的异地设备中。数据分级存储方法逻辑结构如图1所示。
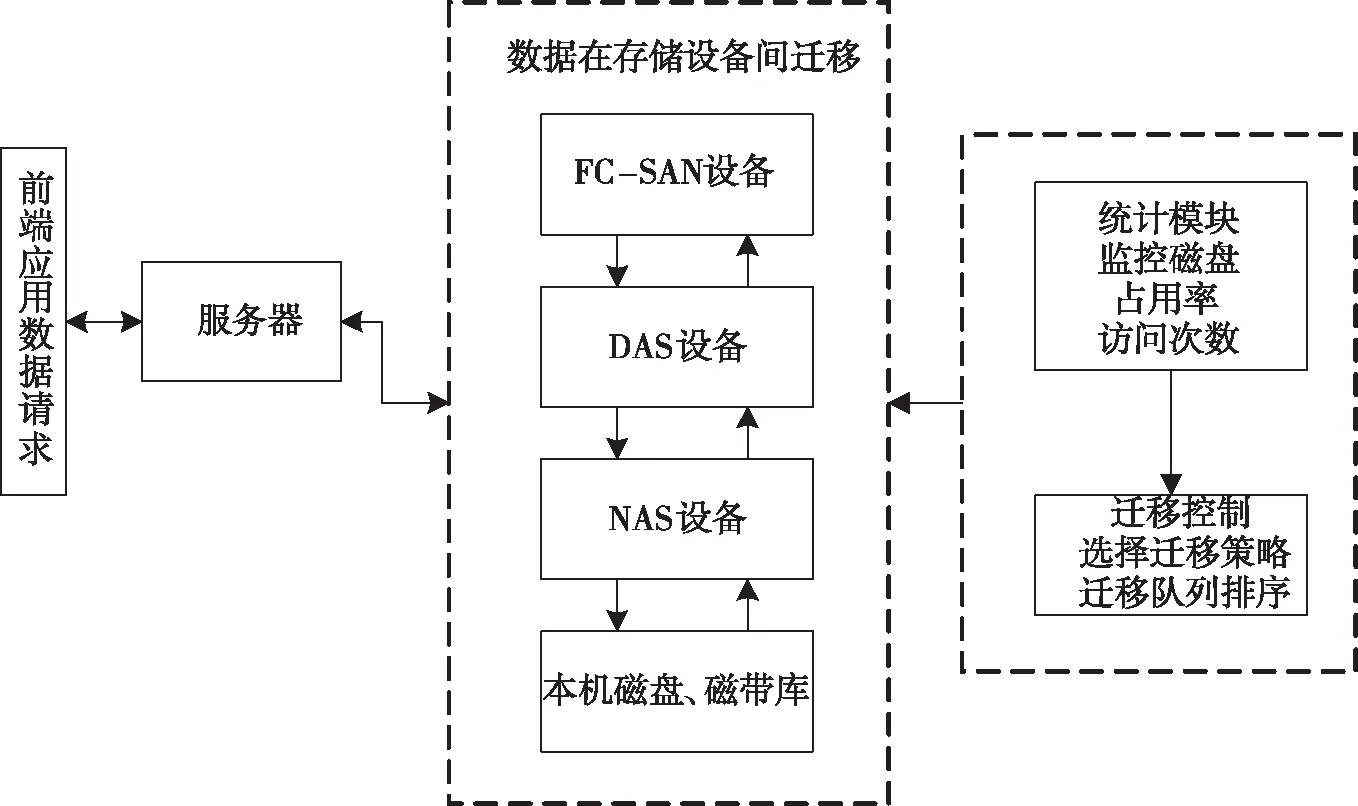
图1 数据分级存储方法逻辑结构
1.1 数据分级存储方式及其存储设备分析
分级存储,顾名思义,就是将数据分为不同的等级,分别转移到对应的不同设备中[4]。海量的数据中并不是所有的数据都是重要的,因此对应的存储方式和存储设备也是不同的。在本文当中,数据存储可以划分4个等级方式,即一到四级(图2)。

图2 分级存储划分
一级存储方式:负责存储企业业务应用运行中新产生的数据以及一段时间内被访问最多的数据;
二级存储方式:负责存储两种类型的数据,即共享型和文件型;
三级存储方式:负责存储用户访问频率较低的数据;
四级存储方式:负责存储从未被用户访问过的数据,只用于数据备份[5]。
在图2中,各个等级存储方式中所用到的各级存储设备特点见表1。

表1 各级存储设备特点对比
1.2 数据价值评估
数据分级的关键在于确定数据价值。根据数据价值才能确定其对应的存储方式和存储设备。在这里采用一种基模糊综合评价方法进行数据机制评估[6]。模糊综合评价法是指利用隶属度理论对难以通过具体数据描述的评价对象进行量化,具体过程如下。
步骤1:确定数据价值评估指标。在这里主要包括访问频率、数据完整性、数据规模、数据时效性等[7]。
步骤2:确定数据价值评语集,见表2。
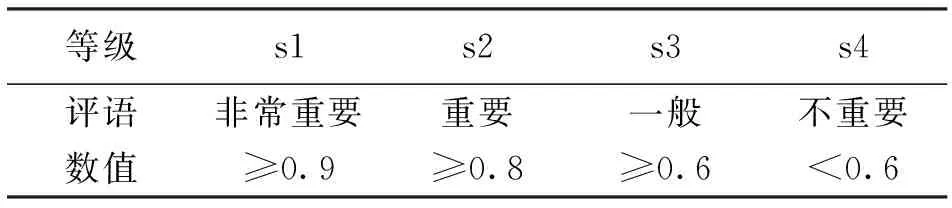
表2 评语集
步骤3:计算评价指标的权重向量,在这里采用熵权法进行。熵权法是一种根据指标携带信息量的多少来确定指标权重的一种方法,携带的信息量越大,指标权重就越大[8]。
step1:将数据价值评估指标进行标准化处理,标准化处理方法主要有3种
1)Min-Max标准化
(1)
2)正规化方法
(2)
3)log函数转换法
(3)
其中,x′为规范化后的大数据,x为原始数据,max为大数据集中最大值,min为大数据集中的最小值,a为对应特征均值,b为标准差;
step2:计算第j项数据的信息熵;
step3:计算第j项数据的信息熵冗余度;
step4:计算第j项数据的权重。
步骤4:进行单因素模糊评价,确立模糊关系矩阵R。
步骤5:根据隶属度矩阵,构建评价矩阵。
步骤6:利用合适的合成算子将评价矩阵与模糊关系矩阵合成,得到各被评价数据的模糊综合评价结果向量。
步骤7:将综合评价结果转换为综合分值,并进行从大到小排序,挑选出最优者。
步骤8:对比表2评语集,得到数据价值的评语。
1.3 数据分级存储
基于上述数据价值评估结果,进行数据分级存储,这也是本文研究的重点。数据分级存储是指根据数据价值存储到不同等级的存储设备当中。目前数据分级存储方法主要有两种,即固定阈值法和高低水位法[9]。
1)固定阈值法
固定阈值法关键在于将用户对数据的访问频率作为分级存储的衡量指标[10]。该方法有两种迁移存储方向,即由高级存储向低级存储或者由低级存储向高级存储,其具体过程如图3所示。
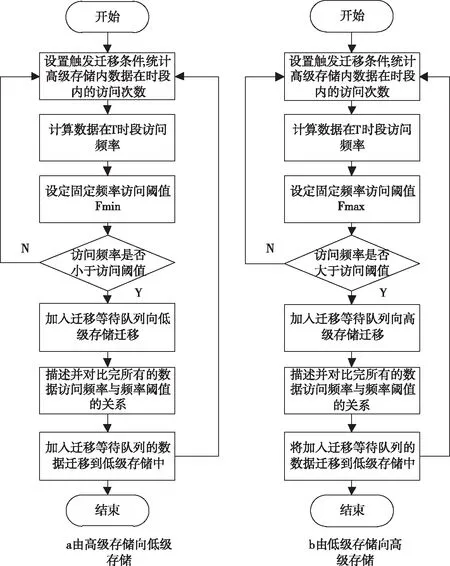
图3 固定阈值法基本流程
2)高低水位法
高低水位法就是利用水往低处流的原理来进行数据分级迁移与存储。在该种算法中,数据占据存储空间的最高值作为数据迁移存储的开始,然后以数据访问频率作为数据分级迁移标准,并且以数据占据存储空间的最低值作为数据停止迁移的条件[11]。该方法具体流程如下。
步骤1:设置参数,包括数据存储空间占有率最大值M、数据存储空间占有率最小值N、数据访问频率F、数据存储空间尺寸S、数据实际占有存储空间率X、迁移存储的数据队列长度Y,最长队列数Z[12];
步骤2:根据数据存储空间占有率最大值M和最小值N、数据存储空间尺寸S,计算最长队列数Z,计算公式为Z=(M-N)·S

步骤4:对所有带存储数据的访问频率按照从小到大的顺序排列;
步骤5:然后按排序表进行分级,分别选择一级、二级、三级和四级存储设备;
步骤6:以数据的访问频率最小值开始,逐一加入到迁移存储队列中;
步骤7:判断迁移存储的数据队列长度Y是否大于等于最长队列数Z?若大于,则数据迁移存储完成,否则,将队列中的数据逐一迁移存储到对应的等级的存储设备中;
步骤8:重复上述步骤2到步骤7,直至所有数据遍历完成;
步骤9:数据分级存储完成。
3)负载平衡法
上述两种数据分级存储方法各有不足,前者单纯将数据访问频率作为分级存储的评定标准,分级精度不足,而后者通过更适用处理数据量较小的情况,一旦数据量过大会过多占用服务器资源[13]。为此,针对上述情况,本次将数据价值评估结果作为分级阈值,并结合上述两种方法进行数据分级存储。
具体过程如下。
步骤1:确定常量,包括数据存储空间占有率最大值M、数据存储空间占有率最小值N、数据价值数值F1、数据存储空间尺寸S、数据实际占有存储空间率X、迁移存储的数据队列长度Y,最长队列数Z;
步骤2:根据数据存储空间占有率最大值M和最小值N、数据存储空间尺寸S,计算最长队列数Z;
步骤3:当第一次出现数据实际占有存储空间率X大于数据存储空间占有率最大值M时,利用高低水位法对数据进行初次迁移,并将这次迁移数据中价值数值作为数据下一次迁移的阈值,记为F2[14];
步骤4:当第二次出现数据实际占有存储空间率X大于数据存储空间占有率最大值M时,将F1 步骤5:判断迁移存储的数据队列长度Y是否大于等于最长队列数Z。当大于时,根据F1值将迁移队列中的数据进行排序,从F1数值最大开始移出迁移队列,否则,迁移队列完成; 步骤6:如果F1 步骤7:将队列中的数据逐一迁移存储到对应的等级的存储设备中; 步骤8:记录最后一个迁移队列中数据的最小价值数值F3与F2的平均值,作为下次迁移的阈值F4; 步骤9:重复上述过程,直至所有数据遍历完成; 步骤10:数据分级存储完成。 为测试所研究的基于大数据分析的负载平衡数据分级存储方法,以与一般存储方法进行对比,仿真实验平台为MATLAB。 本次仿真实验环境见表3。 表3 仿真实验环境 基于大数据分析的负载平衡数据分级存储方法拓扑结构如图4所示。 图4 分级存储方法拓扑结构 根据存储方式等级,实验中需要四种等级的存储设备,即FC-SAN设备、DAS设备、NAS设备、本机磁盘,具体选型如下。 1)FC-SAN设备。海数存16盘位视频监控FC-SAN存储设备HSC-I16,单台可提供1 000 MB/S的读写带宽,容量可扩展至1 PB以上的裸存储容量,满足从区域分布式到次级中心到主控中心的多级监控系统的数据读写性能和存储容量需求。 2)DAS设备:Drobo(德宝)5C DAS。Drobo5C拥有5个磁盘槽,可支持64 TB数据存储,并且提供了断电保护功能,避免磁盘驱动器因断电消失而意外损毁的状况。拥有先进的自我保护功能,通过建立第二组备援空间专门备份启动扇区以及其内容,能保护操作系统、应用软件等数据。 3)NAS设备:铁威马F4-220。内置双硬盘插槽,最大支持10 TB存储空间。外接存储(个人云伴侣或磁盘阵列等)可轻松扩展至128 TB空间,海量存储,取之无尽。 4)本机磁盘。WD西部数据固态硬盘1T。无可移动部件,能防止硬盘意外碰撞或掉落时发生数据丢失。其MTTF(平均无故障时间)达175万h,持久率高达500 TBW(写入的兆字节数),使用寿命更长,哪怕在高负荷的工作环境下,也能轻松应对。 仿真实验中所用到的数据包价值分布情况见表4。 表4 数据价值分布表 从表5可以看出,将表4中不同价值的数据分别分级存储到不同等级的存储设备中,准确性均在90%以上,证明了所研究存储方法性能的优点。 表5 数据分级准确性 数据存储的目的是方便用户,更快、更准确地查询数据。因此,为了与一般存储方法进行对比,用户输入同一指令到不同的存储系统当中,进行数据查询,并统计数据查询响应时间和准确性,结果见表6。 表6 数据查询响应时间和准确性 从表6可以看出,按所研究存储方法存储后,数据查询响应时间更短,查询准确性更高,证明了该种存储方法能够更好地服务用户,帮助用户更高效地完成数据查询工作。 3 结 论 文章研究一种基于大数据分析的负载平衡数据分级存储方法,该方法利用大数据分析对负载数据进行分级,将数据存储到的不同设备当中,以缓解企业存储压力,同时也提高数据查询效率。经测试,数据查询准确性可达95.8%,本文方法有效提升了数据准确性。数据查询响应时间仅为1.15 s,提升了负载平衡数据分级存储响应效率。本研究中,检验存储方法所用数据数量较少,需要扩大试验数据,进一步检验分级存储方法。2 仿真实验分析
2.1 仿真实验环境

2.2 分级存储方法拓扑结构

2.3 存储设备
2.4 数据价值分布

2.5 数据分级准确性

2.6 数据查询响应时间和准确性对比分析

