基于K近邻分类算法的网络敏感信息自动过滤
2021-12-28石小兵
石 小 兵
(安徽工业经济职业技术学院,安徽 合肥 230001)
0 引 言
在当今网络时代,网络的开放性越来越强,特别是在网络中,受到网络环境和网络自身结构因素的影响,导致网络敏感信息越来越多,需要对网络敏感信息实现有效检测和过滤处理,净化网络环境,确保网络的安全性。研究网络敏感信息自动过滤方法,对网络的开放式发展和网络安全管理具有重要意义,相关的网络敏感信息自动过滤方法研究受到人们的极大关注。
网络敏感信息的自动过滤方法是建立在对网络敏感信息的特征提取和大数据融合基础上,结合对网络敏感信息特征分布式表达和信息识别,提取网络敏感信息的关联规则特征量,通过分布式的节点融合和特征检测,采用模式识别方法,实现对网络敏感信息过滤。当前,网络敏感信息过滤方法主要有网络虚拟社区文本内容敏感词过滤系统[1]以及一种面向网络安全的图像文字敏感词过滤方法[2],构建网络敏感信息的特征编码和大数据融合模型,通过模糊度特征分布式重构,实现网络敏感信息过滤检测,通过底层数据库开发设计,建立网络敏感信息的可视化重构模型,提高信息过滤能力。但传统方法进行网络敏感信息过滤的计算开销较大,抗干扰能力不好[3]。
针对上述问题,本文提出基于K近邻分类算法的网络敏感信息自动过滤方法。最后进行仿真测试分析,展示了本文方法在提高网络敏感信息自动过滤能力方面的优越性能。
1 网络敏感信息的云存储结构模型和特征分析
1.1 云存储结构模型
为了实现基于K近邻分类算法的网络敏感信息自动过滤,采用混合云构架技术实现对网络敏感信息的云存储结构分析,根据对敏感信息的数据结构特征,采用自动化的特征匹配和模板信息聚类分析方法,构建网络敏感信息的特征检测和信息融合滤波分析模型[4-5],根据信息滤波结果,结合嵌入式的融合过滤和自动化控制方法,实现对网络敏感信息的过滤分析,得到网络敏感信息自动过滤结构框架(图1)。

图1 系统的总体结构框架
在图1所示的网络敏感信息自动过滤模型中,采用嵌入式融合控制的方法,构建网络敏感信息的云存储结构构架模型,基于实体排序和联合特征分析的方法[6-7],得到网络敏感信息的云存储结构构架(图2)。
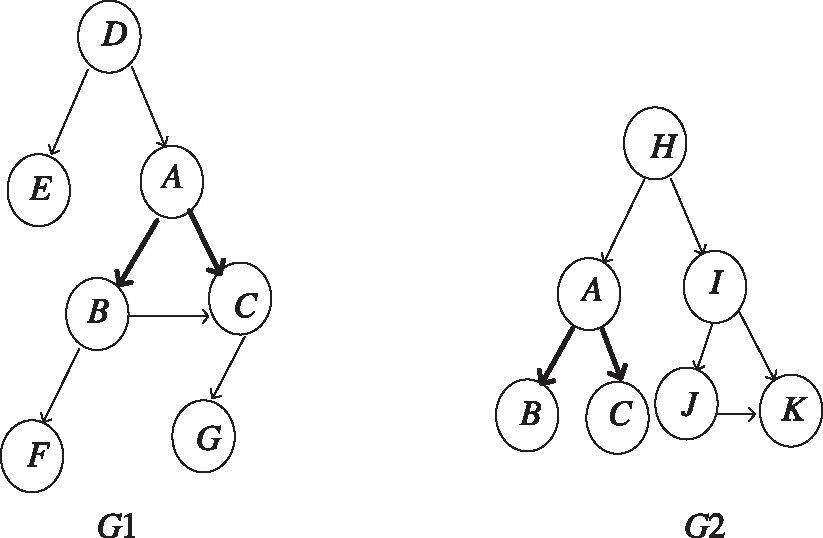
图2 网络敏感信息云存储结构构架
在图2所示的网络敏感信息云存储结构构架体系中,采用G1和G2有向图分析方法得到网络敏感信息云存储的模板参数e,通过联合关联规则挖掘,得到网络敏感信息云存储实体分布模型为
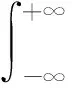
(1)
其中,f(x)表示关联规则挖掘函数,随机选择k个网络敏感信息的存储节点,采用分段线性融合的方法,构建网络敏感信息的可视化分析模型,结合三维特征融合,提高网络敏感信息的模式特征抽取能力[8],采用三维线性规划,得到网络敏感信息的特征分辨率表示为
pk=p3DkΦN-k+1,k=0,1,2,…,N
(2)
其中,p3D表示网络敏感信息的三维特征分辨率,采用高斯Copula函数R进行网络敏感信息的模糊信息聚类[9],结合二元语义特征分析A得到网络敏感信息的相空间融合输出
(3)
采用大数据挖掘和识别,得到网络敏感信息的特征提取和优化存储结构模型。
1.2 网络敏感信息的大数据结构分析
采用混合云构架技术实现对网络敏感信息的云存储结构分析,根据对敏感信息的数据结构特征,建立网络敏感信息的特征融合模型[10],得到网络敏感信息可视化分析关联综合特征量X符合稳定分布。采用有向图分岔节点的特征匹配方法,计算有向图分岔节点与数据存储Source节点j之间的条件转移概率,得到网络敏感信息联合关联特征量Xij,表示为
(4)
其中,aij表示节点特征融合模型,从i=1开始进行网络敏感信息特征重组,建立网络敏感信息的特征融合和空间特征压缩模型[11],采用自相关特征匹配方法实现对网络敏感信息B=diag(b1,b2,…,bn),得到网络敏感信息可视化过滤和信息重组的节点的测度定义为
li=∑bnaij
(5)
采用模糊聚类方法,对网络敏感信息的语义概念集融合,得到网络敏感信息的数据关联结构分布为
(6)

2 网络敏感信息过滤优化
2.1 网络敏感信息特征提取
结合数字标签识别技术,分析网络敏感信息的模糊统计特征量α,通过模糊度检测和云融合技术,得到网络敏感信息特征转移矩阵为
P=f(t)Tα
(7)
此时结合统计特征分析进行网络敏感信息的语义相似度融合,根据特征聚类分析结果,计算网络敏感信息的输出稳态特征量,得到模糊度参数分布的指标向量匹配集为S,选择第K个关联节点进行网络敏感信息的匹配滤波检测,得到网络敏感信息的K近邻聚类中心表示为
(8)
式中,r为网络敏感信息聚类中心的覆盖半径。
采用关联规则融合方法进行网络敏感信息的模糊信息聚类处理,得到模糊度特征参量为
ε=q∑f(t)×x(t-1)
(9)
其中,x(t-1)为网络敏感信息的语义相似特征量。选择语义相近程度最高特征量作为训练集,设S为行网络敏感信息的特征分布概率密度集,采用最大熵模型D(t),构建网络敏感信息的联合关联规则挖掘模型,得到联合关联规则分布特征量表示为
(10)
由此构建网络敏感信息特征提取模型Fz(·),得到量化特征解为
(11)
采用自适应的K均值聚类方法,得到K近邻分布集,根据K近邻分布融合结果,实现敏感信息的融合聚类和滤波处理[12]。
2.2 网络敏感信息自动过滤
采用K近邻分类算法,构建网络敏感信息的聚类和网格分块重组模型λ,实现对网络敏感特征表达,得到网络敏感信息的统计特征量,表示为
(12)
结合实体集标签分析方法,得到网络敏感信息的语义相关性实体模型表示为
(13)
综上分析,通过Logistics模型训练的方法,得到网络敏感信息自动过滤的可视化数学模型表示如下
J(x)=H(f1(t),f2(t),…,fm(t))T
(14)
信息过滤输出的图节点模型属性集V,V={Ii,j(t),Ui,j(t)},其中Ii,j(t)表示网络敏感信息分布的本体对象,Ui,j(t)表示网络敏感信息过滤的语义概念集,表示为
(15)
此时,采用标签索引技术,得到敏感信息的K近邻分类输出为vij,设η为网络敏感信息的关联分析度量值,计算公式为
(16)
其中,gij(t)表示为网络敏感信息过滤调度节点分布权系数。综上分析,构建网络敏感信息的聚类和网格分块重组模型,实现对网络敏感信息自动过滤。算法的改进实现流程如图3所示。

图3 网络敏感信息自动过滤算法改进流程
3 仿真测试分析
对本文所设计的基于K近邻分类算法的网络敏感信息自动过滤方法进行仿真测试,在测试过程中信息的采样条数为1 200万条,统计间隔周期为1 h,每200万作为一组测试集进行敏感信息过滤的分组检测,得到敏感信息分布的时域波形检测结果(图4)。
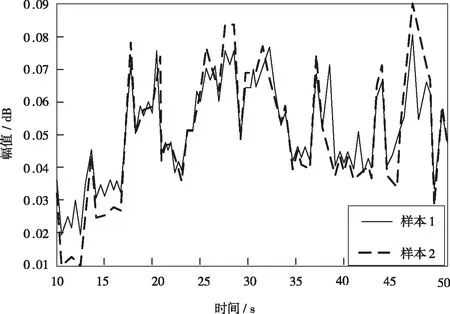
图4 网络敏感信息分布的时域波形
根据图4的网络敏感信息分布检测结果,利用本文方法与文献[1]方法和文献[2]方法分别进行网络敏感信息的自动过滤处理,得到网络敏感信息检测精度比较结果(图5)。
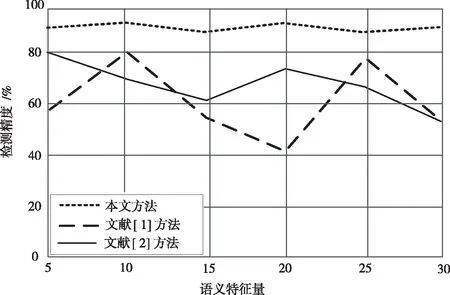
图5 网络敏感信息检测精度比较结果
分析图5得知,本文方法的网络敏感信息检测精度始终保持在90%以上,远高于文献方法,说明该方法的网络敏感信息检测精度更高,可以为后续的网络敏感信息过滤提供有效支持。
在上述基础上,测试网络敏感信息过滤的吞吐量,得到结果(图6)。
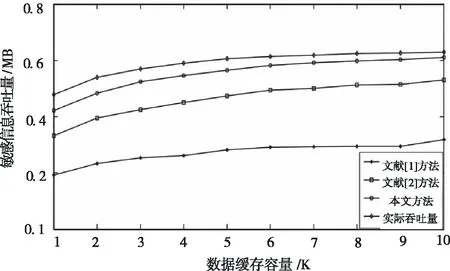
图6 吞吐量测试
分析图6得知,本文方法进行网络敏感信息过滤的吞吐量较高,提高了检测性能。
4 结 论
对网络敏感信息实现有效的检测和过滤处理,可以净化网络环境,确保网络的安全性。本文提出基于K近邻分类算法的网络敏感信息自动过滤方法。构建网络敏感信息的特征检测和信息融合滤波分析模型,采用高斯Copula函数进行网络敏感信息的模糊信息聚类,结合二元语义特征分析,建立网络敏感信息的特征融合和空间特征压缩模型,根据K近邻分布融合结果,实现敏感信息的融合聚类和滤波处理。研究得知,本文方法进行网络敏感信息分布检测的精度较高,自动过滤性能较好。
