基于强化学习的无人机全自主电力巡检
2021-12-27王瑞群欧阳权段朝伟王志胜
王瑞群,欧阳权,段朝伟,王志胜
(南京航空航天大学自动化学院,江苏 南京 211100)
0 引言
目前,电力行业的巡检任务基本由无人机辅助电力巡检人员进行,这种模式使得电力巡检更加的高效和安全,并且节约了很大的人力成本。严波等[1]提出的电力巡检系统需要巡检人员通过遥控控制无人机操控旋翼机,对电线电塔等待巡检设备进行拍照传回地面站进行分析。但是,由于电量限制,电量不足时需要中断巡检任务,人工操作控制无人机飞回地面进行充电,且无人机的操控难度高。无人机飞手需要时刻集中注意力控制无人机飞行,整个巡检任务的执行过程相对比较烦琐。因此,本文设计一套全自主电力巡检系统,由无人机、无线充电桩和待巡检目标3部分构成,无需人工的任何介入即可全自主完成巡检任务。
邢志伟等[2]提出使用深度优先搜索算法来进行电力巡检路径规划;Patle等[3]使用基于矩阵编码得遗传算法进行路径规划;Mavrovouniotis等[4]使用蚁群算法来进行局部搜索解决旅行商问题。这些文献仅解决了路径规划或者巡检点选择这2个子问题,并未解决全自主电力巡检的综合问题。本文提出一套电力巡检系统通过智能联调无人机和充电桩,应用强化学习技术,无人机可以进行自主决策是否充电或继续巡检。利用深度学习视觉技术,无人机可以精准降落到充电桩上;利用无线充电技术,无人机可以自主充电。充好电后,无人机自主决策继续执行任务。
1 系统模型
在全自主电力巡检系统中,无人机在执行巡检任务时,共有3个决策点:在什么情况下执行回充命令、目标的选择和飞往目标路径规划的决策。基于这些的决策点,设计强化学习训练环境,使智能体的决策能达到全局最优,并考虑泛化性问题以应用在实际系统中。
基于无线充电和深度强化学习无人机智能体全自主电力巡检系统如图1所示。整个系统可以分为巡检无人机智能体、分布在适当位置的无线充电桩和待巡检目标(电力塔和电力线)3个部分。

图1 巡检环境示意图及拓扑图
这里将巡检系统转化为一个网络拓扑模型,电网拓扑可以看作是一个无向图。设κ={0,…,k,…,K}为图的节点集,其中的元素为检查的目标点,如电塔、发电机等;lk,k′为目标点k和目标点k′之间的电缆,且k,k′∈κ,k≠k′,该段电缆lk,k′的长度为dk,k′,当结点k′和结点k没有连接时可表示为2个结点之间距离为无穷,即dk,k′=∞。
设计的巡检系统工作流程为:无人机从充电桩出发,飞向巡检目标,完成所有巡检任务后飞回充电桩,中间如何进行决策是本文要考虑的重点。整个流程如图2所示。
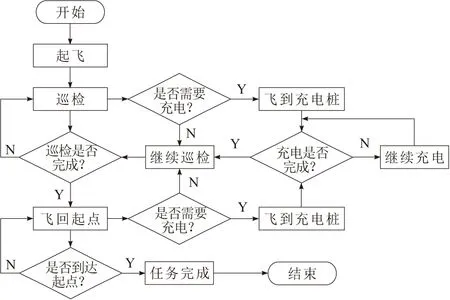
图2 巡检无人机工作流程
以下面的标准来评判该巡检系统是否是全自主的,即当无人机面临以下情景时有自主决策能力:无人机巡检过程中应拥有自主选择最优目标和规划最优路径的能力,并且巡检中无人机会根据自身的电量决定是否飞向充电桩进行充电;在充电状态下,无人机能够根据已充电量和剩余任务选择是否继续执行任务。总之,整个电力巡检系统要满足无需人的任何干预即可完成自主电力巡检。
(1)
N为电塔的总对数;N+1为电塔个数;n为已巡检的电塔个数;L为电缆的总长度;l为已检测的电缆长度。
接下来,建立能耗模型和充电模型,进一步评估巡检系统在完成巡检任务前提下的能耗水平。
1.1 能耗模型
能耗包括无人机的推进能耗和通信能耗2个部分。由于在实际情况中,通信能耗相较于推进能耗要小得多[5],因此,在本文中对通信能耗忽略不计。
为了获取无人机的推进能耗,这里假设无人机始终为稳定直线水平飞行,即无人机的飞行受以下2个方面约束:无人机向恒定的方向以固定的速度进行飞行,没有水平加速度和突然的转向。由于升力和重力的平衡,这里考虑无人机没有垂直加速度,在固定的高度飞行。
定义无人机在电缆lk,k′的飞行速度为vk,k′,因此飞过电缆lk,k′所需要的能耗为
(2)

(3)
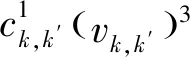
(4)
(5)
1.2 充电桩充电模型
无线充电是在没有导线的情况下通过气隙进行电能传输的一种技术。无线充电系统主要由能量发射电路和接收电路2个谐振电路组成,能量通过磁场在这2个谐振电路之间传输[6]。本文中所讨论的无线充电系统可以用简化电路表示,如图3所示。
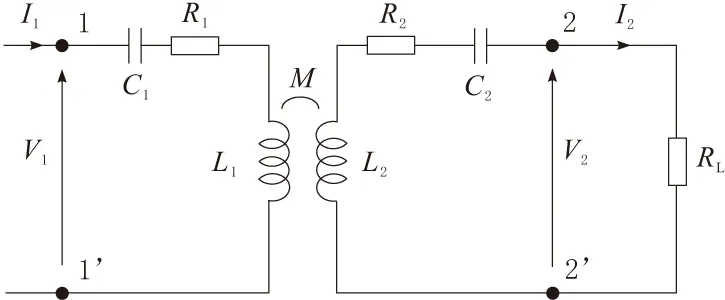
图3 无线充电系统简要电路
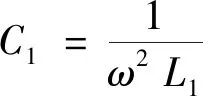
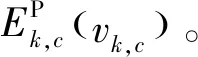
(6)
1.3 优化目标
全自主电力巡检中,在满足巡检任务无差错完成的前提下,应尽量减小无人机在完成一个回合巡检任务中所耗费的能量。因此,根据前面建立的2个模型,可以设目标函数为:
(7)

接下来将针对本节建立的模型来设计一种算法能使得无人机的能量消耗最小。
2 算法分析
本节首先对问题进行分析转换,而后设计了智能体神经网络的模型和基于动作屏蔽的PPO算法。
2.1 问题描述与转换
在本文设计的全自主电力巡检系统中,无人机的决策通常被看作是在度量空间中进行搜索的一个过程[7],根据任务的不同多旋翼无人机的决策可以被分为以下2个子问题:
a.最短路径问题。
b.旅行商问题。
本文中所探讨的问题中,无人机飞向目标点(可以是待巡检目标或者充电桩)时可以通过寻找最短路径来找到该子问题的最优解。无人机要完成所有巡检任务,可以看作是一个寻找旅行商问题最优解的过程。
这里用深度强化学习方法来解决以上2个子问题。首先构建强化学习训练环境,定义相应的奖励函数和参数优化算法;然后对无人机智能体进行训练,优化神经网络参数;最终使得无人机智能体能在能耗最少的情况下完成所有巡检任务。
2.2 算法设计
2.2.1 算法模型设计
本文设计的智能体采用演员-评论家网络。首先,对当前地图画面的帧进行预处理,将原始帧由RGB模式转化为灰度图模式;然后,将灰度图下采样至256×256大小。演员网络模型分为地图界面信息处理部分和决策部分。信息提取部分负责实时地将当前帧的地图信息提供给决策网络,决策网络根据地图信息产生响应的动作概率分布。
信息提取部分由2个卷积层组成[8],第1个卷积层使用16个8×8的卷积核,第2个卷积层使用32个4×4的卷积核。决策部分由1个flatten层和1个LSTM(长短期记忆网络)层组成,网络输出层为4个神经元。除输出层使用softmax激活函数外,其余层均使用ReLU激活函数。
评论家网络和演员网络结构类似,只是评论家网络的输出层为单个神经元,使用ReLU激活函数。
2.2.2 基于动作屏蔽的PPO算法(PPOAM)
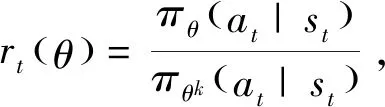
(8)
C(rt(θ))指对rt(θ)进行剪切,可表示为
C(rt(θ))=clip(rt(θ),1-ε,1+ε)
(9)
ε为超参数。可以通过调节该参数控制θ和θk的分布相似度,也即KL散度。
本文中引入的动作屏蔽机制将演员网络输出层的输出结果进行了过滤,即将不合理动作对应概率进行了置0,然后对输出重新进行了归一化。例如,在无人机飞到左边界时,在算法中对不合理动作向左飞行(对应action=1),原地停止(对应action=0)的发生概率进行置0。因此动作k发生的概率变为
(10)
该机制避免了不合理动作的发生,可以有效加快收敛的速度。整个算法的过程如图 4所示。
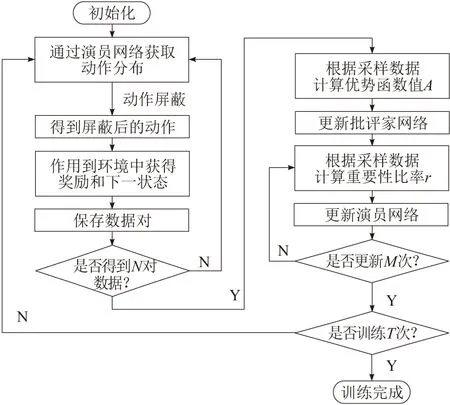
图4 PPOAM算法流程
3 实验环节
首先,对实验环境进行了搭建,深度强化学习的应用首先需要构建智能体的训练环境,只能通过与环境互动来获得训练数据,优化自身的参数;然后,配置了软硬件环境和相关的超参数;最后,对实验的结果进行了分析。
3.1 环境模型搭建
本实验的训练环境基于gym进行搭建,无人机采取规定的动作来进行移动,每次移动的步长固定。
状态空间设置:状态表示须将完整的描述环境的信息提供给智能体。这里使用图像的形式来提供[10],图像使用当前的仿真地图界面,此仿真地图可以表示无人机的位置和电量信息,充电桩的位置以及电塔和电线的位置。
动作空间设置:本文主要研究全自主电力巡检环境中无人机如何进行决策,并没有考虑无人机动力学特性的影响,因此仅定义了东、西、南、北4个方向以恒定速度飞行或停止5个离散动作。
在全自主电力巡检任务中,最终的目标是要在最短时间内以最小的耗能巡检完成所有的电塔和电力线。因此,奖励函数也可以根据耗能和巡检任务完成情况来进行设计。
首先,设计能量相关奖励函数。在无人机执行任务时,应尽量减小无人机的能耗,因此相应的能量消耗惩罚函数为
Re1=-ξe1
(11)
其中,ξe1为超参数,表示单位能耗(焦耳)的惩罚大小。
然后,设计充电决策相关的奖励函数。关于充电奖励,这里考虑当前电量和当前无人机与最近充电桩的距离2个影响因素,设计三者的关系式为
(12)
其中,ξe2为超参数,表示充电相关的奖励系数;Er为无人机能量剩余百分比;dt为当前时刻无人机与充电桩的距离;dmax为巡检场景的最大距离,在此设为巡检地图的对角线长度。
根据上述分析,能量相关的奖励函数可表示为
Re=Re1+Re2
(13)
接下来,设计电力巡检相关奖励函数。在巡检过程中对单个目标点巡检完成后给予奖励,该部分奖励为
Rp1=ξp1
(14)
其中,ξp1为超参数,表示每巡检完成1个目标的奖励大小。由于稀疏奖励的问题,这里设置额外的巡检惩罚即距离惩罚项
Rp2=-ξp2dt
(15)
其中,ξp2为超参数,表示距离惩罚系数;dt为无人机与最近巡检目标的距离。因此巡检奖励可以表示为
Rp=Rp1+Rp2
(16)
最后,可以利用加权和来表示最终的奖励函数为
R=αRe+(1-α)Rp
(17)
其中,α为超参数,可以调节无人机的执行任务风格。在合理的范围内,α越小,无人机的巡检时任务执行风格越为激进。
3.2 实验设计
实验的硬件环境使用64位Windows10操作系统,处理器为3.2 GHz AMD Ryzen 7 5800H,运行内存为16 GB,显卡型号为NVIDIA GeForce RTX 3060,显存容量为6 GB。
软件配置为Python 3.7、TensorFlow 2.4.1、gym 0.18.0和NumPy 1.19.5。
在该软硬件环境中,设置好表中的超参数,分别使用PPO算法和PPOAM算法,在本文设计的电力巡检环境中对无人机智能体进行训练,最终得到2组实验数据。下一节分别对2个算法在训练过程的奖励变化和能耗变化进行分析,然后设置本文实验的各个超参数,具体参数设置如表1所示。
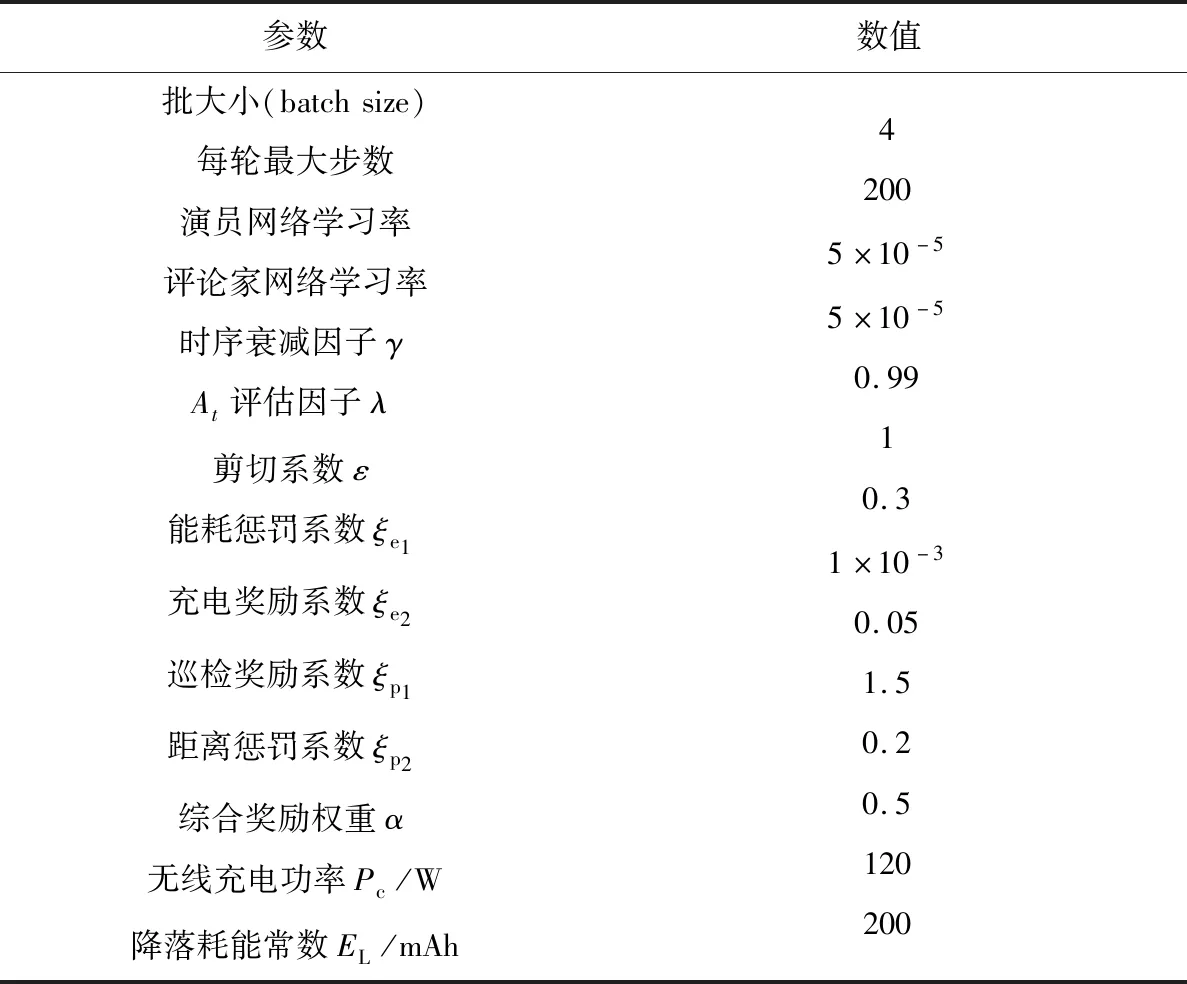
表1 超参数表
3.3 仿真结果分析
对常规PPO算法和本文提出的PPOAM算法进行比较。图5和图6是2种算法的训练结果,深色实线表示含动作掩码的结果,浅色实线表示无动作掩码的结果。
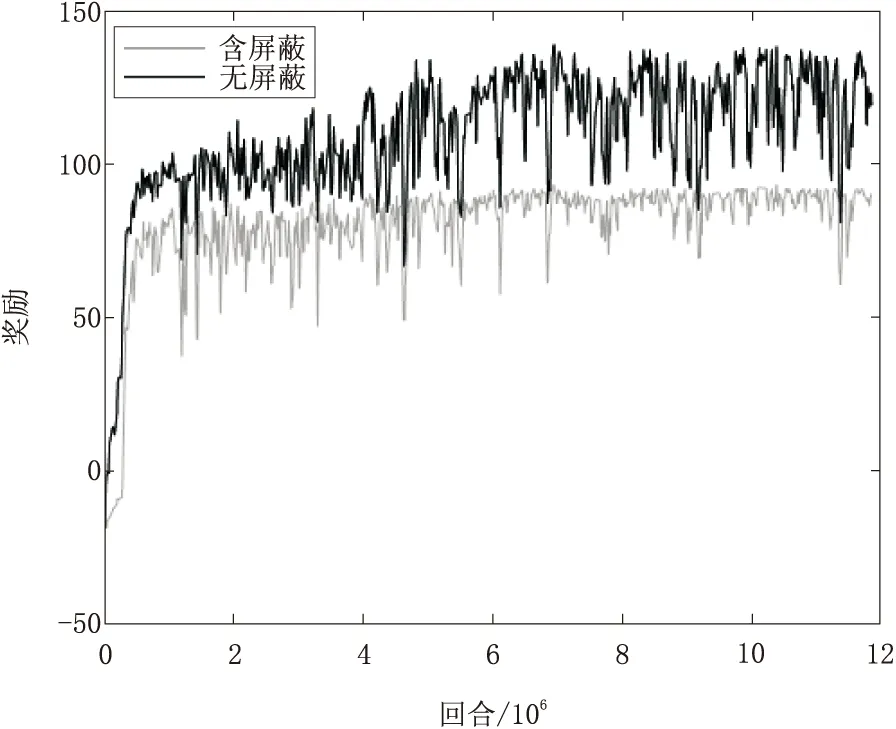
图5 2种算法训练过程奖励变化对比

图6 2种算法训练过程能量消耗对比
如表2所示,在引入动作掩码机制后智能体收敛奖励比PPO算法高39%,能耗值降低15.34%。仿真结果表明,无动作掩码时智能体的训练结果的方差相对于有动作掩码要更小,而PPOAM算法的奖励和能耗大小,都比PPO算法要好,由此说明了在适用的情况下,针对实际训练场景滤除无效操作的有效性。

表2 2种算法结果对比
4 结束语
在本文中,提出了基于动作屏蔽的PPO算法,该算法联系实际场景删除无效的动作,缩小了智能体的探索空间,大大提高了PPO算法的训练效率。另外,还提出了一种全自主电力巡检系统,无人机借助无线充电桩和强化学习算法决策,使无人机能够持续且自主地执行任务,并通过仿真实验证明了该范式的可行性和高效性,该方法也可适用于无人外卖餐车、无人出租车等行业。以后的研究将着手于引入无人机的飞行动力学模型进行进一步的实验,并且考虑将该算法部署到真正的电力巡检系统中。
