基于属性关联的人事档案数据智能分类方法
2021-12-21周毛

摘要:为了提高数据分类的精准度,提升人事档案数据管理的综合水平,提出了基于属性关联的人事档案数据智能分类方法。通过计算人事档案数据属性条件的发生概率,确定数据集合分割点,根据分割点对应属性,将相同类别的数值使用一个指定的数值代替,实现人事档案数据的离散化处理。同时,根据不同条目数据的属性重要性,确定数据分类最佳标准与度量依据,构建离散数据智能分类规则,并参照FastTxet模型,构建文本分类模型,实现人事档案数据的智能分类。通过对比实验证明,提出的方法分类精准度更高,可高精度分类不同人事档案数据。
关键词:属性关联;人事档案;数据分类;离散化处理;
中图分类号:TP391文献标识码:A
0引言
在互联网技术在各大企业内全覆盖后,企业人事档案信息与各类存储在计算机中的信息流呈现一种倍数增长趋势,尽管在此过程中人事档案管理人员已掌握了基本的计算机操作能力,使用现代化技术管理档案信息的效率也同比例提升。但在此过程中,人事档案管理人员也不得不面临大批量信息中,冗余信息的排查问题[1]。目前,企业人事档案信息大多存储在数据库内,但并不是所有的数据均可以直接入库,导入数据需要相关技术人员排查信息数据,即通过某种专用的工具,一次处理前端导入的数据,并整理其中的无效数据、重复数据,按照数据的所属类别及不同类型数据之间的关联性,对其进行归类,只有确保数据的秩序化导入,才能实现人事档案信息管理的高效率与高水平[2]。为了实现与此方面相关的工作,在早期的研究中,技术人员提出了基于概念学习(Concept Learning System,CLS)算法的数据分类方法,此种方法的原理是将所有数据打乱在一个指定区域,在此基础上设定一个分类标准,采用依次排查数据的方式重整与处理大批量数据。尽管此种方法可满足基础数据分类处理需求,但由于此种处理方式需要消耗的时长较高,难以满足人事档案处理的高效率要求。因此,在本文的研究中,提出一种基于属性关联的智能分类方法,通过提取人事档案数据属性的方式,完成数据的批量处理。
1基于属性关联的人事档案数据智能分类方法
1.1人事档案数据离散化处理
为了实现对人事档案数据的智能化分类,在本章的研究中,将采用离散化处理人事档案数据的方式,对其完成预处理[3]。这一过程最关键的步骤是计算属性条件的发生概率,并根据不同属性的发生条件获取数据属性特征,以此为依据,掌握属性数据在人事档案数据集合中的占比,比重表示为 ,其中P表示为属性数据在人事档案数据集合中的比重, 表示为数据i的属性特征, 表示为人事档案数据集合。
倘若在归类数据时,人事档案数据集合中特征属性为离散化数据,此时,只需要统计前端训练样本集合中不同类别数据出现的频率即可,即计算类别的发生概率,但倘若在分类过程中,人事档案数据呈现连续性特征,则可以认为其属性也是连续的,针对连续性数据的分类不仅需要大量计算,还需要调度辅助分类器对其进行参照处理。因此,有必要在分类数据前,对其进行离散化处理。
为了实现对人事档案数据的有效处理,可先将连续性数据以高斯分布的方式进行排列,并将其建立在一个连续变量上,确保数据在排序后是基于某种概率分布的。在排列数据集合后,采用高斯分布切割数据集合。高斯处理数据的核心在于确定数据集合分割点,因此,本文选择的分割点可以是基于一个相同属性下的两个邻近数据,将此数据进行竖向交叉,得到一个属性类 ,每个 對应的属性 在指定条件下的发生概率表示为式(1):
公式(1)中: 表示为指定条件下,数据属性条件的发生概率; 与 表示为对应数据 与 在竖直与水平方向上的训练集合; 表示为训练样本记录;i表示为数据排序对应的序列;j表示为邻近数据交叉点。
以属性表示为A的数据集合为例,离散化处理A集合的步骤为:按照数据训练处理方式,将A划分为A1~A3;在确保数据集合符合高斯分布的条件后,计算A1~A3的均值 与A对应的方差值 ;根据计算结果,得到一个针对A的概率密度计算公式;使用此公式计算 、 的交叉点数值,将交叉计算结果作为分割点,并根据分割点对应的特征属性分类元素,相同类别的数值使用一个指定的数值代替。以此种方式,便可以实现对人事档案样本数据的离散化处理。
1.2基于属性关联构建离散数据智能分类规则
在完成人事档案样本数据的离散化处理后,需要找出与所有数据精准对照的可能规则集合,将此集合定义为PR,即为数据智能分类规则。在此过程中,应明确不同数据之间的属性关联性是构成粗糙理论集合的主要内容之一,因此,在构建智能分类规则时,也应将相关内容建立在属性之上,考察人事档案数据是否具有该属性的方法为删除数据集合中的此条数据,判断此时的信息系统的分类依据是否受到影响[4]。假定删除此条数据后,数据集合的分类依据没有发生变化,证明此条数据与数据集合不发生关联,反之,当删除此条数据后数据集合的分类依据发生了改变,可认为此条数据与数据集合之间存在属性关联。
按照上述提出的内容,对事物集合项集进行确定,此时可得到一个精度为1.0的项集。在此基础上,根据不同条目数据的属性重要性,确定最佳标准与度量依据。确定数据度量标准后,利用Apriori算法将选择的属性生成一个候选数据集合,将此候选集合作为依据,进行关联规则的生成,步骤如下:
在数据前端生成一个人事档案数据集合T,定义数据可信度阈值表示为minsup,使用rule指令,生成一个关联规则集合。此时,在算法中按照精度为1.0的项集,计算不同条目数据属性的重要性。计算公式如式(2)。
公式(2)中: 表示为不同条目数据属性的重要性; 表示为前端生成的rule指令; 表示为生成的分类规则近似集合。按照上述计算公式,不断扫描计算机中人事档案数据库,直到掌握所有数据的关联性达成一致,以此为依据,便可以得到针对人事档案数据分类的标准规则。
1.3基于FastTxet的文本分类模型
考虑到人事档案部门数据库内现已存储了大量的档案数据,并且部分数字档案尚未被开发利用,因此,可通过开发FastTxet模型的方式,构建一个针对文本信息的分类模型,此模型是一种基于深度学习理论的模型,可以在管理文本数据时,根据数据情境归类文本信息。其结构如图1所示。
参照图1提出的三层架构模式,将文本分类模型划分成输入层、矢量特征层、输出层。其中输入层中含有大量的隐藏信息,需要根据优化器与梯度下降算法,得到不同数据的权重参数,在此基础上,根据损失的函数划分数据类别[5]。当数据从输入层流经矢量特征层时,深度学习理论将根据损失函数的预测结果,细分档案数据的类别,并设置学习率,按照训练标准分类训练数据。完成训练后,使用soft分类器分类预测人事档案数据,并输出预测结果,以此为依据,划分文本信息的批量。至此完成人事档案数据的智能分类。
2实验
为了验证本文上述提出的基于属性关联的人事档案数据智能分类方法在实际应用中的有效性,本文采用基于属性关联的分类方法和文献[1]基于FastText的分类方法进行对比实验的方式,完成如下对比实验。
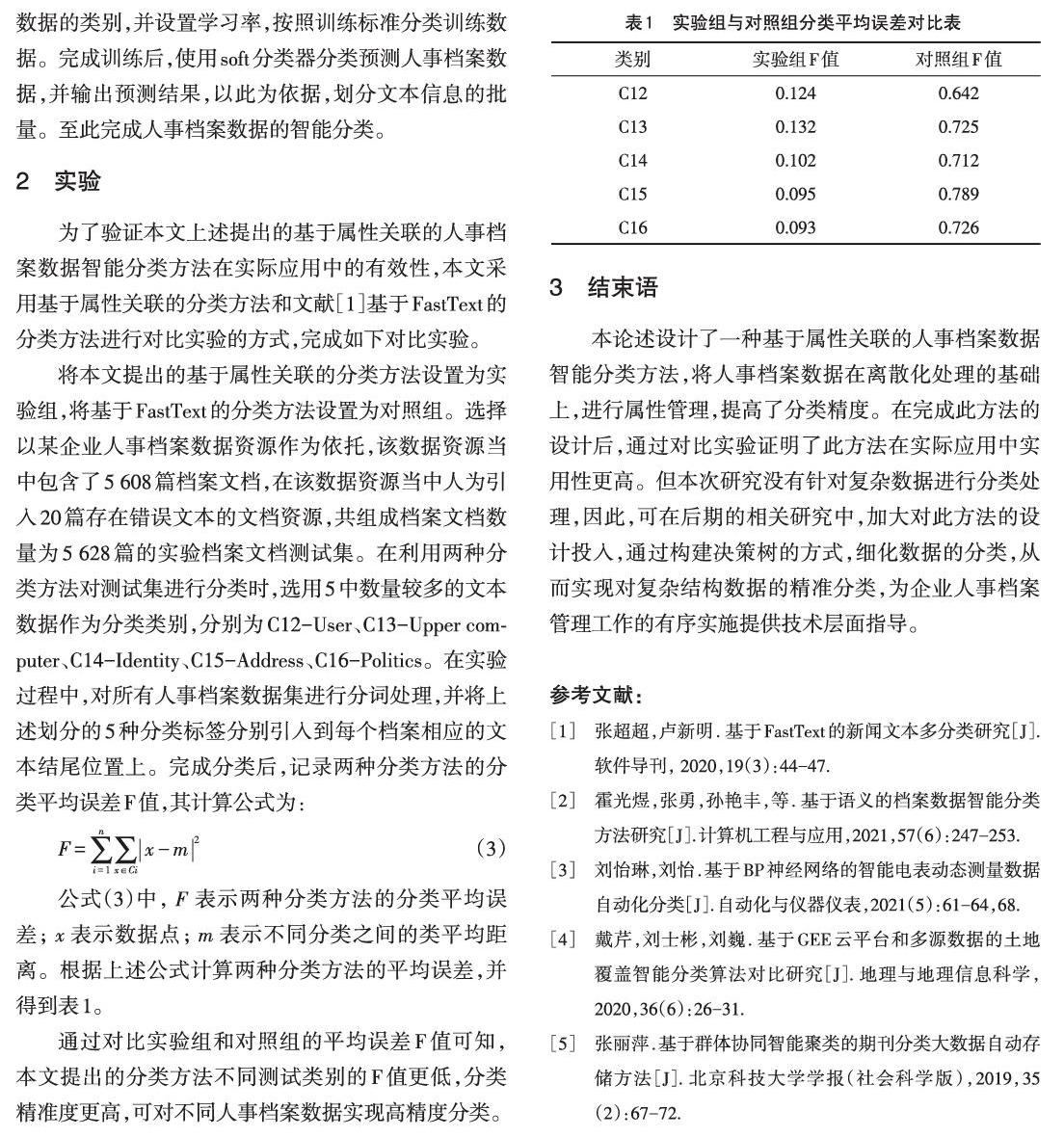
将本文提出的基于属性关联的分类方法设置为实验组,将基于FastText的分类方法设置为对照组。选择以某企业人事档案数据资源作为依托,该数据资源当中包含了5608篇档案文档,在该数据资源当中人为引入20篇存在错误文本的文档资源,共组成档案文档数量为5628篇的实验档案文档测试集。在利用两种分类方法对测试集进行分类时,选用5中数量较多的文本数据作为分类类别,分别为C12-User、C13-Upper computer、C14-Identity、C15-Address、C16-Politics。在实验过程中,对所有人事档案数据集进行分词处理,并将上述划分的5种分类标签分别引入到每个档案相应的文本结尾位置上。完成分类后,记录两种分类方法的分类平均误差F值,其计算公式为:
公式(3)中, 表示为两种分类方法的分类平均误差; 表示为数据点; 表示为不同分类之间的类平均距离。根据上述公式计算两种分类方法的平均误差,并得到表1.
通过对比实验组和对照组的平均误差F值可知,本文提出的分类方法不同测试类别的F值更低,分类精准度更高,可对不同人事檔案数据实现高精度分类。
3结束语
本文设计了一种基于属性关联的人事档案数据智能分类方法,将人事档案数据在离散化处理的基础上,进行属性管理,提高了分类精度。在完成此方法的设计后,通过对比实验证明了此方法在实际应用中实用性更高。但本次研究没有针对复杂数据进行分类处理,因此,可在后期的相关研究中,加大对此方法的设计投入,通过构建决策树的方式,细化数据的分类,从而实现对复杂结构数据的精准分类,为企业人事档案管理工作的有序实施提供技术层面指导。
参考文献
[1] 张超超, 卢新明. 基于FastText的新闻文本多分类研究[J]. 软件导刊, 2020, 19(03):44-47.
[2] 霍光煜,张勇,孙艳丰,等. 基于语义的档案数据智能分类方法研究[J]. 计算机工程与应用,2021,57(06):247-253.
[3] 刘怡琳,刘怡. 基于BP神经网络的智能电表动态测量数据自动化分类[J]. 自动化与仪器仪表,2021(05):61-64+68.
[4] 戴芹,刘士彬,刘巍. 基于GEE云平台和多源数据的土地覆盖智能分类算法对比研究[J]. 地理与地理信息科学,2020,36(06):26-31.
[5] 张丽萍. 基于群体协同智能聚类的期刊分类大数据自动存储方法[J]. 北京科技大学学报(社会科学版),2019,35(02):67-72.
作者信息:
周毛,女,藏族,1976.10,青海西宁,本科,馆员,青海民族大学:810007,现从事档案管理工作
