基于OpenCL的3DES算法FPGA加速器
2021-12-20吴健凤郑博文柴志雷
吴健凤,郑博文,聂 一,柴志雷,3
(1.江南大学 人工智能与计算机学院,江苏 无锡 214122;2.江南大学 物联网工程学院,江苏 无锡 214122;3.数学工程与先进计算国家重点实验室,江苏 无锡 214215)
0 概述
将加解密算法用于数字货币、区块链、云端数据加密等领域时[1-2],算法应具备高强度计算能力。因此,当前服务器端允许包含异构计算平台以增强特定工作负载的性能,同时改善整个系统的维护成本。OpenCL 是异构平台的开放框架,其中内核(Kernel)程序可以在多核CPU 上,同时也可以在GPU、现场可编程门阵列(Field Programmable Gate Array,FPGA)、DSP 上编译执行[3]。当前服务器端除了采用ASIC 或GPU 处理大批量数据外,考虑到能效等因素也会大规模部署FPGA。
目前,已有许多基于OpenCL 的加解密算法加速器的研究。文献[4]设计一种基于OpenCL 的MD5算法加速器架构,提出结合优化CPU 端内存分配、复制内核计算单元的方法,其较未经优化方法性能提高了6.1 倍。文献[5]提出基于OpenCL 内核的Kuznyechik算法流水线架构设计,结合轮密钥按位模2 加消除依赖、查找表、分解线性变换为布尔函数等方法,在Intel Arria 10 系列实现了41 Gb/s 的吞吐率,同时占用不超过10%的FPGA 资源。文献[6]评估了可扩展的多FPGA 架构上AES 加密内核的性能,在带有Stratix A3 FPGA 的单个M506 模块上,通过使用OpenCL SIMD4 达到了较高的吞吐率。文献[7]结合OpenCL 工具设计SHA1 哈希算法,与基于硬件的描述语言相比,使用Intel FPGA SDK 工具进行少量的内核代码更改即可实现电路的改变,有效节省了系统开发时间,其结合循环展开、循环流水等策略,在Altera Stratix V 系列器件上达到3 033 Mb/s 的吞吐率,相比于CPU 性能提升了14 倍。
DES 算法是1972 年美国IBM 公司设计的对称密码体制加密算法。随着软硬件的快速发展,DES算法已被证实不够安全。为了克服DES 算法的缺陷,1999 年美国NIST 发布了新版本的DES 标准[8],指出DES 仅能用于遗留的系统,同时3DES 将取代DES 成为新的标准。在国内,中国人民银行的智能卡技术规范已支持3DES[9],电子支付系统将3DES方案用于数据的加解密[2]。目前3DES 算法在国内外有着广泛的应用,因此,更高效地实现3DES 加密具有重要意义。
现有针对3DES算法的优化方法以使用硬件描述语言(Hardware Description Language,HDL)居多[10-11]。虽然HDL 仍是在FPGA 上开发时序关键型设计的合适选择,但在HDL 中开发应用程序需要付出较大代价并且容易出错。高层次综合工具(High-Level Synthesis,HLS)是高性能计算界针对FPGA 编程的替代解决方案[12]。使用HLS 可以让几乎没有FPGA开发经验的用户充分利用FPGA 的优势。目前,有2 种支持利用FPGA 开发OpenCL 应用的商业编译器,一个是用于OpenCL 的Intel FPGA 软件开发套件(Software Development Kit,SDK),支持Cyclone、Stratix 和Arria 系列的FPGA平台[13-15],另一个是Xilinx,为基于OpenCL 的Kintex 系列和Virtex-7 FPGA 产品提供了完整的SDAccel 开发环境[16]。
本文采用数据存储调整、数据位宽改进、指令流优化、内核矢量化、计算单元复制等策略,设计并实现一种基于OpenCL 的加解密算法FPGA 加速器架构,以应用广泛的3DES 算法为例,介绍内核程序的设计过程。
1 3DES 算法原理
3DES 算法以DES 算法为基础,其通过进行3 次DES 加密增强算法复杂性,从而保障安全性[17]。DES 算法包含16 轮迭代,使用56 bit 密钥,而3DES算法包含48 轮迭代,使用168 bit 密钥。
1.1 DES 算法
DES 算法将明文按64 bit 进行分组,参与计算的密钥长度固定为64 bit(有效位数56 bit)。加密流程主要包括初始置换、16 轮循环迭代、逆初始置换3 个部分。其中,16 轮迭代过程中参与计算的子密钥由56 bit 密钥扩展而来[8]。
DES 算法流程如图1 所示,其中,64 bit 的输入明文经初始置换分为L0和R0两部分,然后进行16 轮相同的迭代运算,最后经过逆初始置换得到64 bit 的输出密文。在每一轮迭代中,包含一次异或运算和f 函数运算。
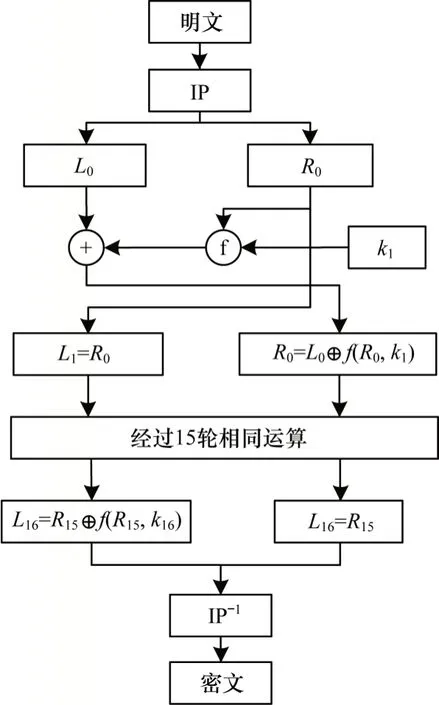
图1 DES 算法流程Fig.1 Procedure of DES algorithm
f 函数原理如图2 所示,其中,输入为该轮的Ri-1和该轮对应的子密钥ki,Ri-1经E 盒扩展后的结果与48 bit 的子密钥ki进行异或运算,之后经S 盒变换、P 盒置换得到32 bit 的输出。S 盒将6 bit 的输入转换为4 bit 的输出,这也是算法中唯一的非线性变换,极大地提高了算法的安全性。S 盒的置换部分使用查找表实现,其将8 个S 盒的内容存储于片上ROM,有效提高了算法的计算效率。DES 算法的子密钥生成模块输入为56 bit 的密钥,经16 轮迭代生成16 个子密钥ki,分别用于DES 算法的16 轮迭代计算模块。在子密钥生成模块中,每轮迭代包含循环左移和密钥置换操作。
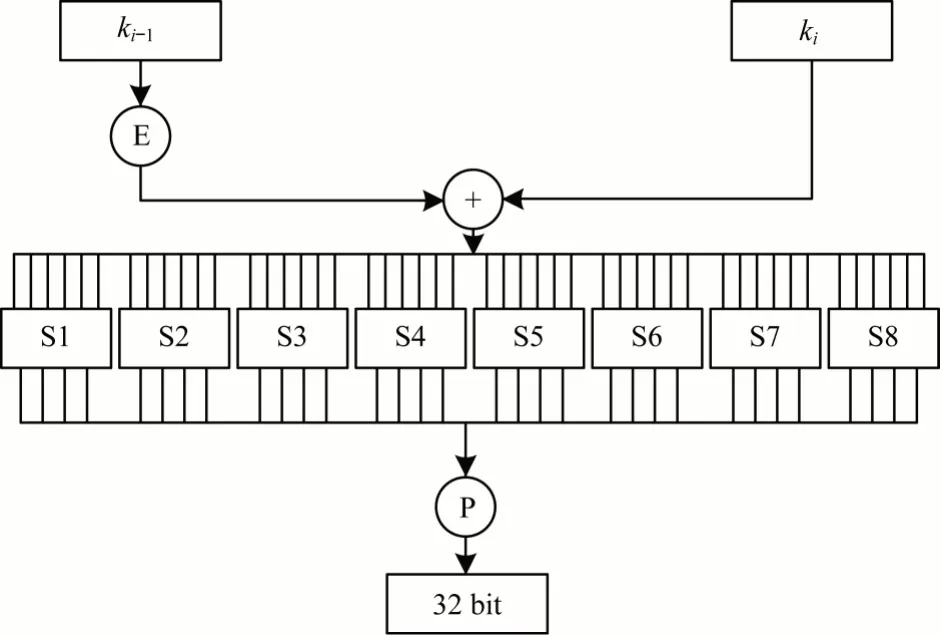
图2 f 函数原理示意图Fig.2 Schematic diagram of f function principle
1.2 3DES 算法
3DES 算法在DES 算法的基础上发展而来,其输入为64 bit 的明文,输出为64 bit 的密文。与DES 算法不同,3DES 算法包含192 bit(有效长度168 bit)的密钥。令Eki(I)和Dki(I)分别表示使用DES 密钥ki对数据块I的DES 加密和解密运算。3DES 的加密操作如式(1)所示,其将64 bit 的输入块I转换成64 bit的输出块O1。3DES 的解密操作如式(2)所示,其将64 bit 的输入块I转换成64 bit 的输出块O2。

2 基于OpenCL的FPGA设计
OpenCL 为开发人员提供了抽象的内存层次结构以生成有效代码,适合目标设备的内存层次结构。OpenCL 内存结构由全局内存(Global Memory)、常量内存(Constant Memory)、局部内存(Local Memory)、私有内存(Private Memroy)4 种类型构成[18]。工作项在处理单元(Processing Element,PE)上运行,可以访问对应的私有内存,工作组在一个计算单元(Compute Unit,CU)上运行。同一工作组中的工作项拥有共同的局部内存。
OpenCL 程序包含主机端程序和内核程序两部分。如图3 所示,内核程序运行时系统会创建一个整数索引空间,工作项对应执行索引空间的一个实例,工作组是工作项的集合,同一工作组中的工作项共享内存并可以实现组内同步。工作项在全局索引空间中的坐标为该工作项的全局ID,工作项在工作组中的坐标为该工作项的局部ID。
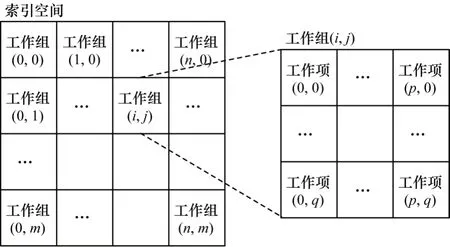
图3 OpenCL 索引空间示意图Fig.3 Schematic diagram of OpenCL index space
本文采用IntelFPGA SDK 实现3DES 算法加速器设计。在FPGA 上构建系统之前,SDK 支持在CPU 上仿真OpenCL 应用程序。软件仿真利用CPU模拟FPGA 硬件特性,通常用于功能验证。目前,Intel 的工具链不支持硬件仿真[16]。Intel FPGA SDK包含一个编译OpenCL 内核以创建优化硬件镜像的离线编译器,该编译器将内核代码转换成为中间Verilog 形式,然后通过Quartus II 软件将其编译为二进制镜像,该镜像可在程序运行时加载至FPGA端。由于编译过程需要数小时来应用适当的优化并设计出硬件镜像,因此编译过程是离线的,主机程序仅在运行时才加载硬件镜像。构建完成后,将创建主机可执行文件和二进制文件,以在FPGA 上运行目标程序[19]。
3 基于OpenCL 的3DES 算法FPGA 加速器
本文基于OpenCL 实现3DES 算法FPGA 加速器的设计,包含主机端(HOST)程序设计与设备端程序设计两部分:主机端程序结合3DES 算法加密的原理,完成主机端程序对明文数据的读取、初始化、存储、OpenCL 运行时环境的创建以及对Kernel 的调度与管理;设备端程序设计针对3DES 算法内核计算模块进行优化并形成流水线并行架构。同时,采用数据存储调整、数据位宽改进策略有效提升实际带宽利用率,采用指令流优化技术针对算法中的循坏迭代进行改进,提高计算的并行度,采用内核矢量化、计算单元复制进一步提升内核性能。
3.1 主机端程序设计
主机端完成明文数据的读取、初始化、存储、内核调度、管理等工作。Intel FPGA SDK提供了OpenCL平台API 及运行时API:平台API 定义了主机端程序发现OpenCL 设备所用的函数以及这些函数的功能;运行时API 用于管理上下文来创建命令队列以及运行时发生的其他操作。通过调用OpenCL API 可实现主机端对内核的调度与管理[17],CPU 端程序流程如图4 所示。
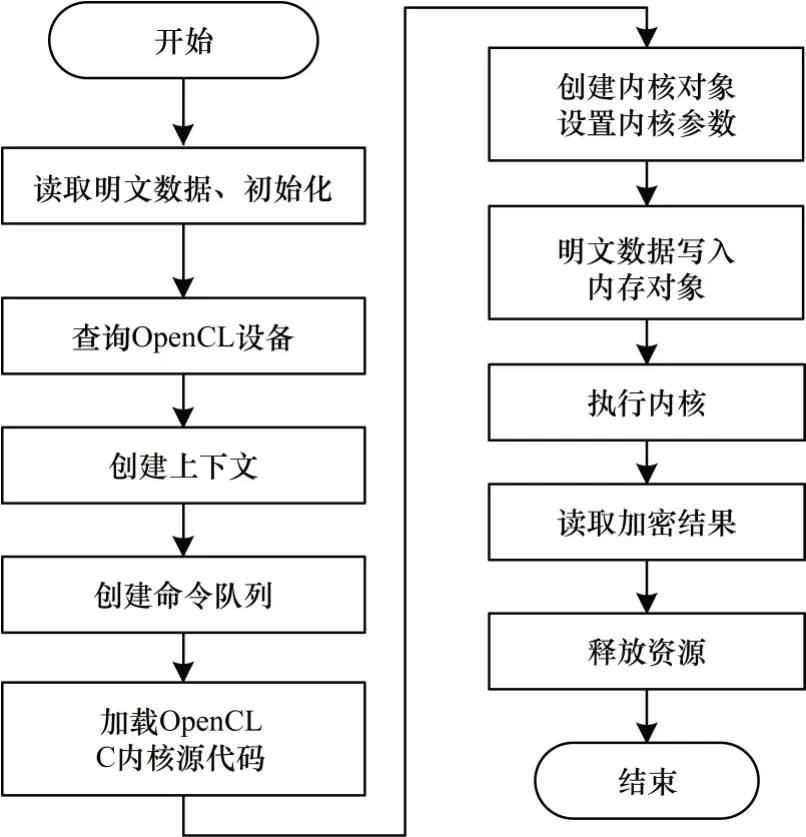
图4 主机端程序流程Fig.4 Procedure of HOST program
3.2 优化策略
3DES 算法内核模块包括明文数据输入缓存、算法加密模块和密文数据输出缓存3 个模块,如图5 所示。明文数据输入缓存完成从全局内存读取明文数据,通过使用数据存储调整、数据位宽改进提高实际带宽利用率;算法加密模块基于FPGA 完成3DES 算法的加密计算,通过数据循环展开、循环流水形成流水线并行计算架构;密文数据输出缓存模块将数据从FPGA 片上传输至外部DDR 中。
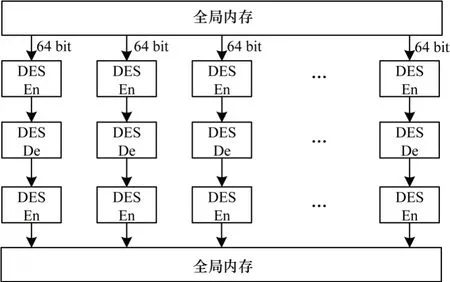
图5 内核模块示意图Fig.5 Schematic diagram of Kernel module
3.2.1 数据存储调整
由主机端传输的数据存储于片外DDR 中,对应的数据类型为__global;常量内存位于片上缓存单元,对应的数据类型为__constant;局部内存的物理地址为片上RAM 资源,对应的数据类型为__local;私有内存的物理地址为片上寄存器资源,对应的数据类型为__private。由于片上不同资源的大小、延迟、吞吐率存在差异,因此合理分配数据存储位置对于算法性能提升有较大的影响[19]。
不同内存类型的性能参数如表1 所示。全局内存类型具有最大的吞吐率及容量,但同时也存在较大的访存延迟,主机端传输的数据存储于全局内存中,因此提高内存带宽的实际利用率对于系统性能的提升是有效的。局部内存对工作组中的所有工作项可见,与私有内存相比,在访存延迟相当的情况下,其具有更高的吞吐率及更大的容量,但同一工作组中的工作项执行后需要通过使用屏障保证数据一致性,这在一定程度上增加了延迟。因此,将参与3DES 计算的变量存储于私有内存中,工作项访问位于私有内存中相应的明文数据块并完成3DES 算法加密。针对f 函数计算模块的S 盒和E 盒变换,由于是频繁访问的数据且其值在计算过程中保持不变,因此将其存储于常量内存,对应的物理地址为片上ROM,从而在加快访问速度的同时避免访存冲突。

表1 不同内存类型的性能参数Table 1 Performance parameters of different memory types
3.2.2 数据位宽改进
工作项执行内核程序的一个实例,如果工作项处理的数据位宽不固定,则编译器会使用更多的资源以满足可能的数据位宽,但同时也会对程序的优化编译有所限制。
基于3DES 算法输入数据长度为64 bit 且输出数据长度为64 bit 的前提,将单工作项处理的数据长度调整为8 Byte。若将数据长度调整为4 Byte,则需要2 个工作项来完成一个明文块的加密操作,此时工作项间的数据需要同步以保证数据一致性,这会增加额外的时间开销;若将数据长度调整为16 Byte,此时单工作项的处理数据量为原来的1 倍,理论上内核执行时间增加1 倍,则将单工作项的行为定义为从全局内存中搬运8 Byte 的数据至私有内存,针对8 Byte 数据进行3DES 加密计算,再将计算的结果从私有内存搬运至全局内存中。通过获得工作项的全局ID 可实现工作项与明文数据的一一对应,从而避免工作项间的同步操作。
3.2.3 指令流优化
指令流优化主要使用循环展开和循环流水来提高程序的并行度。循环展开可指导离线编译器将OpenCL Kernel 转换为硬件镜像的方式。通过使用循环展开可形成有效的流水,而流水线架构能够缩短整体的执行时间。如图6 所示,假设每步操作需要1 个时钟周期,未形成流水线型设计时,内核在下次计算时延迟了3 个时钟周期,而在使用流水线型设计后,只延迟了1 个时钟周期。
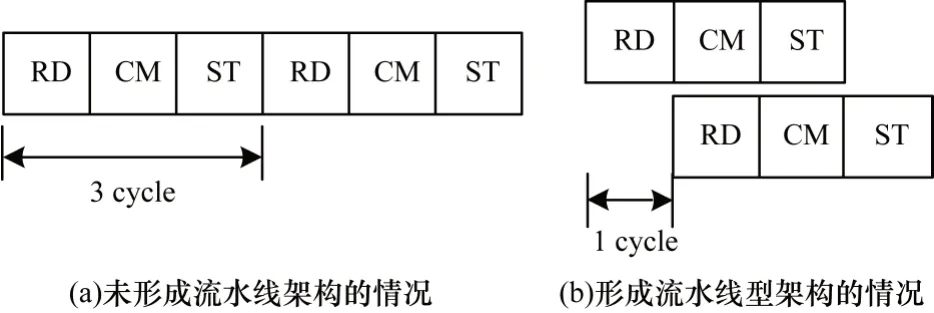
图6 内核计算架构Fig.6 Architecture of Kernel computing
循环展开在消耗一定硬件资源的前提下可降低数据读取与存储的次数,节省计算所需的时间,形成流水线型架构,从而提高并行度。如表2 所示,在内存数据Load 模块,针对8 Byte的明文数据与3 个8 Byte的子密钥数据读取进行循环展开形成内存合并,将对内存数据的32 次Load 操作降低为4 次更宽的Load 操作;在内存数据Store 模块,针对8 Byte 的密文数据存储进行循环展开形成内存合并,将使内存的8 次Store 操作减少为1 次更宽的Store 操作;在迭代计算模块,针对子密钥生成模块的16 次循环左移和密钥置换、DES 计算模块的16 轮轮换计算模块进行循环展开,指导编译器生成多套单次迭代所需的硬件结构,节省了迭代计算所需的时间。表2 数据显示,未进行循环展开时,内核的执行时间为1 110.096 ms,使用循环展开后,内核的执行时间降低为46.620 ms,可见通过循环展开取得了较好的优化效果。
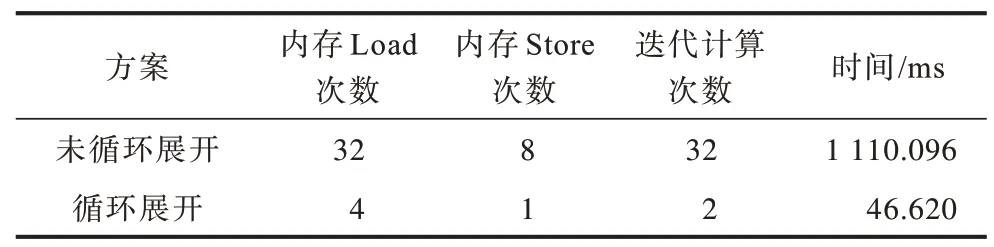
表2 循环展开的优化效果Table 2 Optimization effect of loop unrolling
3.2.4 内核矢量化
内核矢量化允许多个工作项以SIMD 的方式执行内核程序的实例。矢量化指导编译器生成多个矢量通道,使得工作项可以同时存取并处理多个数据[20]。如图7 所示,内核矢量化参数设定为2 后编译器会合并内存访问。与未经矢量化相比,矢量化后的内核单次Load 和Store 的数据量为原先的2 倍。使用内核矢量化时,需要同时指定工作组大小,且内核矢量化的参数能被工作组大小整除。内核矢量化的参数只能是2 的指数,由于硬件资源的限制,因此实验中可设定的最大矢量化参数为16。
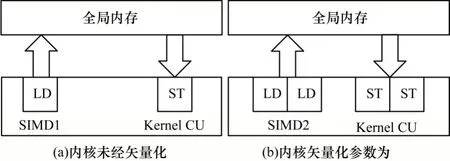
图7 内核矢量化示意图Fig.7 Schematic diagram of kernel vectorization
以加密128 MB 数据量为例描述不同内核矢量化参数下系统内存带宽及吞吐率的变化情况。在SIMD2方案中,设置矢量化参数为2 后工作组中的工作项平均分布在2 个SIMD 通道中,此时单工作项执行的工作量为原来的2 倍,同时编译器会合并内存访问,单工作项一次可从内存中加载2 个明文数据块进行加密并一次将2 个数据块的加密结果存储到全局内存中[19]。如表3 所示,随着矢量化参数的增加,内核的执行时间得到降低,内存带宽及系统的吞吐率得到提升。
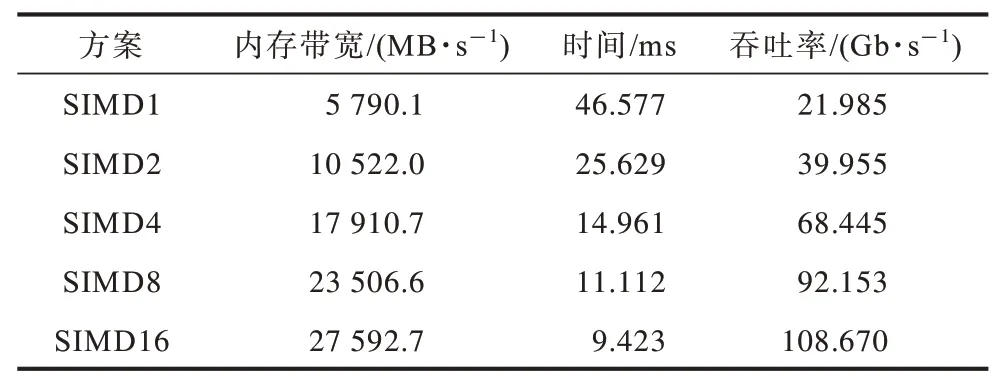
表3 内核矢量化的优化效果Table 3 Optimization effect of Kernel vectorization
在本文设计中,工作组大小为512,内核矢量化参数为16,每个工作组中的工作项分布在16 个SIMD 通道中。编译器实现16 个SIMD 通道后,每一个工作项的计算工作量为原先的16 倍,相应的全局工作组大小减少为原来的1/16。
3.2.5 计算单元复制
通过计算单元复制策略可提高具有常规内存访问模式的内核性能。Intel FPGA SDK 编译器支持为内核生成多个计算单元,通常每个计算单元可以同时执行多个工作组,从而提高内核的吞吐率。使用计算单元复制后,FPGA 中的硬件调度器将工作组分派到其他可用的计算单元。只要计算单元尚未达到其最大容量,就可以将其用于工作组分配[19]。
如图8 所示,本结合参数为16 的内核矢量化策略,利用FPGA 硬件调度器将工作组分配至2 个计算单元中执行,理论上可使内核的运行时间缩短为原来的一半。然而,虽然通过使用多个计算单元可提高系统的吞吐率,但也会增加对于全局内存带宽的竞争以及硬件资源的使用。
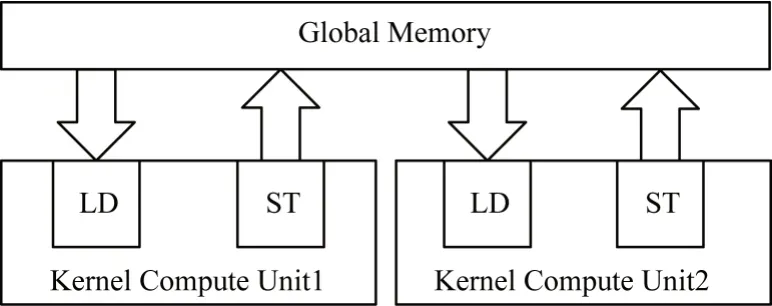
图8 计算单元复制策略示意图Fig.8 Schematic diagram of compute unit replication strategy
3.3 加速器总体架构设计
如图9 所示,基于OpenCL 的3DES 算法加速器架构由主机(HOST)端和设备端2个部分组成,其中,HOST端负责与OpenCL 程序外部环境的数据交互、与设备端的数据交互及Kernel的调度与管理,设备端负责3DES算法的计算任务。
设备端包含明文数据输入缓存、3DES 算法加密计算、密文数据输出缓存3 个模块。其中,明文数据输入缓存、密文数据输出缓存位于设备端的全局内存区域,3DES 算法加密的中间数据存储于设备端的私有内存区域。
在图9 中,PE 单元为一个工作项的处理单元,每个PE 单元拥有相应的私有内存用于存储运算的中间数据,一个PE 单元完成一个明文块的3DES 加密计算。针对全局内存与私有内存的数据传输模块,结合OpenCL 内存模型及全局内存、私有内存存在访存差异的特点,采用改进数据存储位置、调整数据位宽策略提高内核实际带宽利用率;针对算法加密计算模块,结合3DES 算法加密的原理,采用循环展开、循环流水策略形成流水线并行架构,同时结合使用内核矢量化策略形成更宽的矢量计算通道从而有效提升算法的性能,采用计算单元复制策略进一步提高FPGA 端计算的吞吐率。
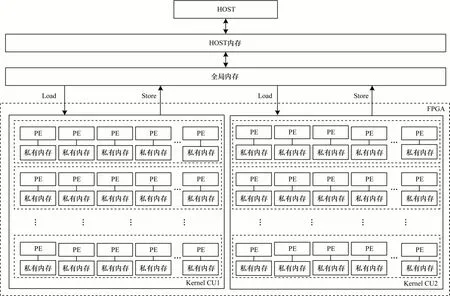
图9 3DES 算法FPGA 加速器总体架构Fig.9 The overall architecture of FPGA accelerator for 3DES algorithm
4 实验
4.1 实验环境
对本文设计的加速器进行实验验证,软件环境为CentOS Linux release 7.7.1908+GCC V4.8.5,OpenCL 版本为Intel FPGA SDK for OpenCL 19.3,硬件组合为Intel Xeon E5-2650 V2 的CPU+Intel Stratix 10 GX2800 的FPGA,该款FPGA 包含1 866 240 个ALUT,内存带宽为34 GB/s,资源情况如表4 所示[14]。

表4 FPGA 端资源情况Table 4 FPGA resources
4.2 实验结果
在不同优化策略下,以加密128 MB 数据、单工作项处理8 Byte 明文块为例,结合FPGA 端内存带宽、工作频率、内核执行时间及资源消耗情况描述内核的性能变化。内存带宽及时钟频率通过在编译器编译时加入性能计数器(-profile)获得,通过aocl report 指令调用Intel FPGA Dynamic Profiler for OpenCL 工具获得内存带宽及工作频率的信息,通过clGetEventProfilingInfo 函数获得内核的执行时间,通过aoc -rtl 指令生成内核的分析报告,获得资源消耗的详细信息。实验中记录的时间是算法的绝对执行时间,不包含主机与设备之间的数据传输时间,时间的统计结果通过多次测试取平均值获得。
4.3 实验结果分析
表5 展示了不同优化策略下FPGA 端内存带宽、时钟、内核执行时间及资源占用变化情况。,其中,未优化的内核其内存带宽为1 916.9 MB/s 且FPGA板卡的工作频率为306.2 MHz,内核运行时间为1 349.181 ms。下文对不同方案下的实验数据进行分析。
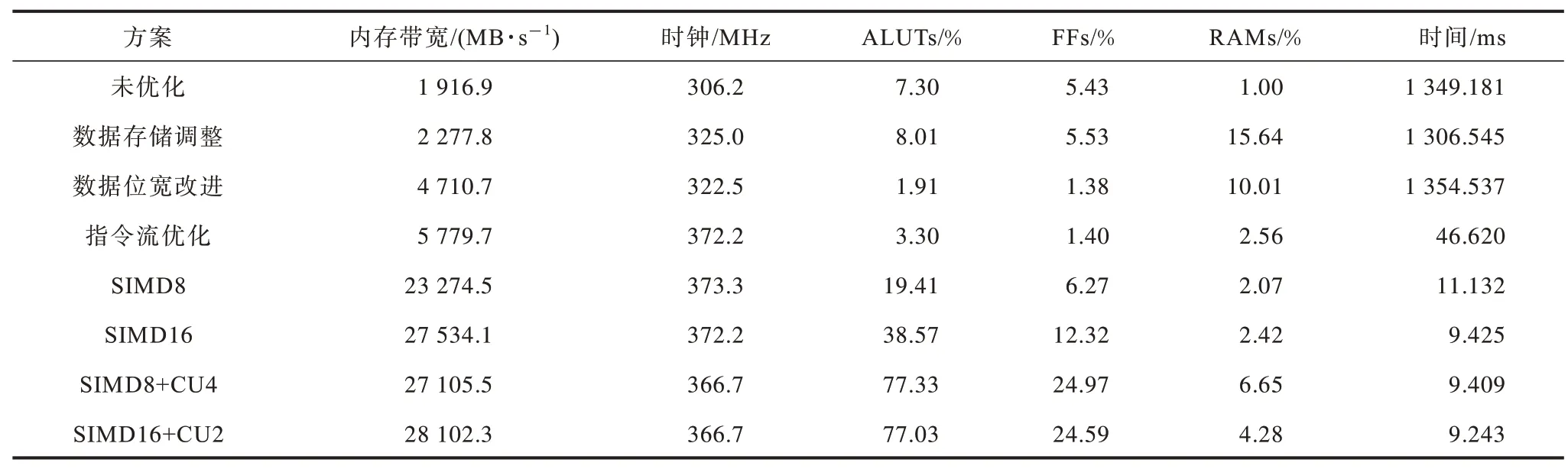
表5 不同优化方案下FPGA 端性能及资源情况Table 5 FPGA performance and resources under different optimization schemes
数据存储调整结合OpenCL 内存模型及FPGA 板卡不同硬件资源存在访存延迟及吞吐率差异的特点,将HOST端传输的数据存储类型由常量类型(__constant)更改为全局变量类型(__global),将内存的实际带宽利用率、板卡的工作频率提升至325 MHz。这是因为全局类型的变量其存储位置为FPGA 的片外DDR,且理论带宽可达到34 GB/s,而常量类型变量在内核运行时会自动由DDR 转存至FPGA 片上缓存,这在一定程度上增加了额外的数据移动。
数据位宽改进将单工作项处理的数据位宽确定为8 Byte,此时内存带宽提升了一倍多,这是因为在数据位宽确定的情况下,编译器能够结合长度信息做更好的优化,且使用8 Byte 长度的位宽可最大化单工作项处理数据的效率,同时减少不必要资源的使用。结合数据位宽改进后,设备端占用的逻辑资源大幅减少,由最初的8.01%降至1.91%。
指令流优化包含循环展开和循环流水两部分。使用指令流优化后,系统整体性能的提升较为明显。由表5 可知,使用指令流优化后内存带宽提升至5 779.7 MB/s,时钟频率达到372.2 MHz,同时内核的运行时间由最初的1 349.181 ms 缩短至46.620 ms。这是因为在结合数据存储调整、数据位宽改进的前提下,采用循环展开和循环流水策略可以达到较好的并行度。实验结果表明,在未结合数据位宽改进的情况下,采用循环展开循环流水策略后内核的运行时间为437.053 ms。这是因为如果未结合数据位宽改进,编译器无法针对循环做有效的展开,且会尽量使用更多的资源和更粗粒度的优化来满足可能的数据长度,这在一定程度上限制了编译器的优化能力。由表5 可知,使用循环展开、循环流水策略后,消耗的逻辑资源由原先的1.91%增加至3.3%,这与循环展开增加逻辑资源的消耗相符合。
内核矢量化实现内核中多个工作项以单指令多数据(SIMD)的方式参与运算。结合工作组大小为512,将内核矢量化的参数指定为8,此时全局工作组的大小减少为原来的8 倍。内核矢量化后内存带宽由5 779.7 MB/s 提升至23 274.5 MB/s。这是因为矢量化内核会指导编译器合并内存访问,将对全局内存的8 次Load操作合并为1 次更宽的矢量Load 操作且内核函数计算模块包含较少的分支语句,有利于形成较合适的SIMD通道。内核矢量化后FPGA端的工作频率为373.3 MHz,内核的执行时间由原先的46.620 ms缩短至11.132 ms,可见内核矢量化在性能上产生明显的提升。内核矢量化会增加FPGA 端资源的消耗,由表5 可知,其占用的逻辑资源由3.3%上升至19.41%。
将矢量化的参数由8提升至16,此时可形成更宽的内存访问操作。由表5 可知,内存带宽进一步提高至27 534.1 MB/s,内核的执行时间缩短至9.425 ms,系统资源的消耗由19.41%增加至38.57%。
结合内核矢量化与计算单元复制的组合可进一步提高内核的性能。内核矢量化参数为8 时,可复制的最大计算单元数为4;内核矢量化参数为16 时,可复制的最大计算单元数为2。
结合矢量化参数为8、4 个计算单元复制后内存带宽为27 105.5 MB/s,相比于SIMD16 有一定程度的下降,这是因为计算单元的增加导致对带宽的竞争,内核的执行时间缩短至9.409 ms,逻辑资源的消耗为77.33%。使用参数为16 的内核矢量化与2 个计算单元复制的组合,其内存带宽为28 102.3 MB/s,工作频率为366.7 MHz,内核的计算时间缩短至最低的9.243 ms,逻辑资源的占用达到77.03%。在有限的资源下,内核矢量化参数为16、计算单元复制数为2时获得了最佳的内核性能。下文将结合不同大小的明文数据量,进一步描述结合内核矢量化参数为16、计算单元复制数为2 的内核性能变化。
4.4 不同数据量下系统吞吐率变化
为直观描述内核的性能,以64 KB、1 MB、8 MB、64 MB、128 MB、256 MB、512 MB、1 024 MB的数据为例,描述内核在不同数据量下的吞吐率变化情况。内核吞吐率的计算公式[21]如式(3)所示:

其 中:T为吞吐率;N为3DES 加密的次数;B为单次3DES 加密的明文块大小;E为内核的执行时间。不同数据量下内核的执行时间及吞吐率的变化情况如表6 所示。可以看出:在数据量较小的情况下,内核的吞吐率不能很好地反映算法的真实性能;随着数据量的增加,内核的吞吐率在增加后趋于稳定;在计算的数据量大于128 MB 后,内核的吞吐率保持在111.801 Gb/s 左右。
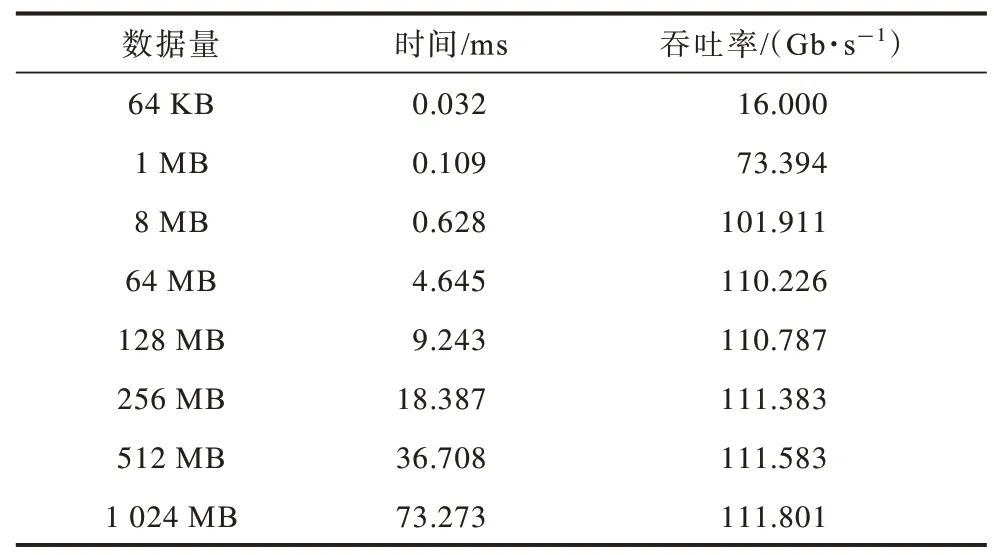
表6 不同数据量下的吞吐率Table 6 Throughput rates under different data volumes
4.5 与不同方案的对比
为了验证本文方案的有效性,与其他文献方案进行比较,并与CPU、GPU 平台实现结果进行比较。
4.5.1 与其他文献方案的比较
文献[11,22-25]皆采用基于Verilog/VHDL 的设计方案。本文基于OpenCL 实现FPGA 的设计,采用数据存储调整、数据位宽改进、指令流优化、内核矢量化等策略实现3DES 算法加速器的设计。如表7 所示,与基于Verilog/VHDL 实现的方案相比,本文方案有效解决了开发周期长、维护升级困难等问题,同时频率达到了366.7 MHz,吞吐率达到111.801 Gb/s,取得了较明显的性能提升。
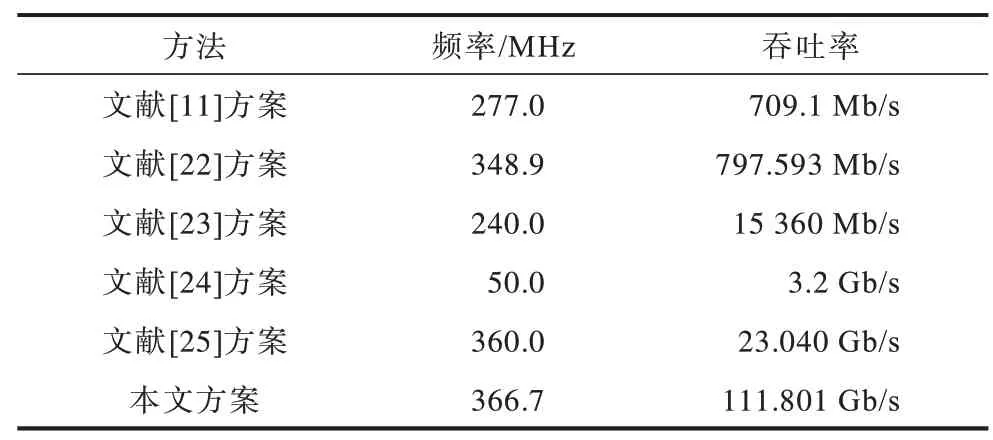
表7 不同方案的加速性能Table 7 Acceleration performance of different schemes
4.5.2 与CPU、GPU 实现结果的比较
结合CPU、GPU 平台验证本文方案的性能。OpenSSL 是基于密码学的开发工具包,包含丰富的密码算法库。Hashcat 是一种快速密码恢复工具,支持OpenCL 框架。本文的对比对象为CPU 端的OpenSSL 库,其版本为1.0.2,CPU 型号为Intel Core i7-9700;GPU 端 的Hashcat,其版本为5.0.0,GPU 型号为NvidiaGeForce GTX 1080Ti。
由图10 可知,本文实现方案相比于CPU 性能提升372 倍,相比于GPU 性能提升20%。由图11 可知,本文实现方案相比于CPU 能效比提升644 倍,相比于GPU 能效比提升9 倍。
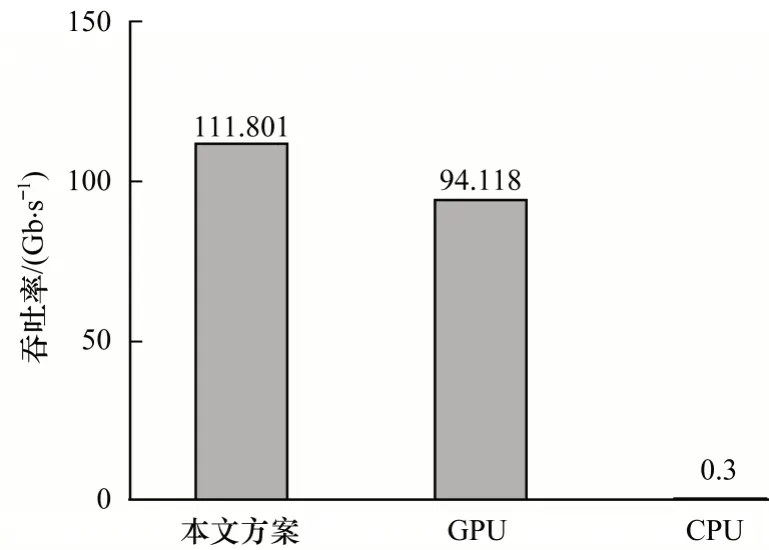
图10 不同平台下的吞吐率Fig.10 Throughput rate under different platforms
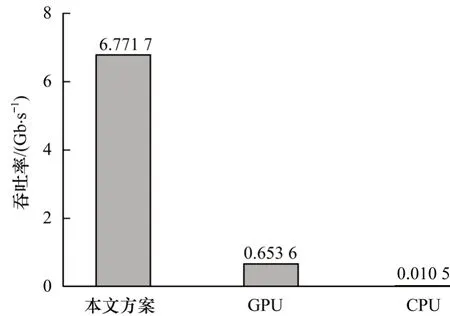
图11 不同平台下的能效比Fig.11 Energy efficiency ratio under different platforms
5 结束语
本文针对传统数据加解密计算速度慢、功耗高、占用主机资源的问题,以及Verilog/VHDL 方式实现的FPGA 加解密系统开发周期长、维护升级困难的问题,提出一种基于OpenCL 的3DES 算法FPGA 加速器架构设计方案。结合OpenCL 内存模型与FPGA 端硬件资源的对应关系优化数据存储模块,同时对私有内存与全局内存的数据传输模块,采用循环展开、数据位宽改进策略提高内存带宽的实际利用率,对3DES 算法计算模块,采用指令流优化提高计算的并行度,形成流水线型架构。在此基础上,结合内核矢量化、计算单元复制策略进一步提高内核的吞吐率。实验结果表明,本文设计的加速器能够有效提升3DES 算法的速度与能效方面,满足数字货币、区块链、云端数据加密等高强度计算领域的计算要求。为进一步提高该加速器的通用性和性能,后续将针对非对称加密算法和哈希算法进行设计,同时优化主机端与FPGA 端数据的传输性能,开发实现支持算法类别更多的加解密算法计算平台。
