多维关联规则在图书馆借阅数据中应用分析
2021-12-19李华群






摘要:该文旨在分析出不同属性的读者与借阅的图书类别之间多维关联规则,将读者所在学院和年级属性进行细分,与借阅图书类别三级类目属性生成多维属性事务表,利用维间编码自连接的方式将多维属性整合成单维属性的模式,对不同学院不同年级2020年下半年借阅数据进行多维维间和混合维关联规则分析,根据读者细分程度,得出不同读者的个性化需求特征,为图书馆优质的服务提供有力的理论依据。
关键词:多维关联规则;图书馆;数据挖掘;关联规则;借阅数据
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2021)32-0018-04
图书馆随着智能现代化技术发展,服务器里存储了大量的读者借阅行为历史数据,这些宝贵的数据不应仅备份起来保持“有”,还应该“活用”起来,使这些数据能够“说话”。发挥他最大的作用。数据挖掘技术是可以让数据活用起来的技术,是可以从大量的、不完全的、有噪声的、模糊的数据中提取隐含在其中的人们事先不知道的、但又是潜在有用的信息和知识。数据挖掘技术常用的有关联规则、贝叶斯分类算法、决策树算法、神经网络算法、支持向量机、聚类分析、模糊集方法等。其中关联规则技术常被用于图书馆借阅数据挖掘中,寻找出其中的借阅规律,为图书馆资源建设和提供个性化服务提供理论依据[1]。
但目前的研究大多仅在图书类别之间寻找读者借阅书籍的关联规则。侯贺[2]将关联规则应用到图书馆流通数据挖掘中,是通过馆藏量依照中图法分类分成T类和其他类进行图书类别间的关联分析;聂飞霞[3]是运用Apriori算法在图书馆典藏规划中的应用,通过建模运算得出图书各类别之间的关联规则;陈淑英[4]也将关联规则应用到高校图书馆图书推荐服务中,通过一次抽取不同专业不同年级的记录进行多维属性的关联规则分析,但仅研究的是读者属性与书籍类别之间维间关联规则,如关联规则{法学类专业,大一}==> H31,表示该读者是法学类专业一年级的学生,同时借阅了图书H31,是维间关联规则,缺少混合维规则的挖掘。王蕾[5]的借阅行为大数据应用于高校图书馆服务创新的路径分析文中使用weka将年级、专业和图书分类三个字段进行关联分析,分析出的也是维间规则。本文将读者的属性所在学院、年级信息和图书类别三级目录属性多维属性通过编码自连接的方式整合成单维属性,运用weka3.8.0数据挖掘工具Apriori算法不仅挖掘出维间规则,同时挖掘出混合维关联规则,分析出更多潜在的信息,为图书馆更好地发展提供丰富的理论依据。
1关联规则
1.1 关联规则基本概念
关联规则就是发现描述数据库中数据项之间潜在的关联,找出大量数据之间未知的、有用的依赖关系。一个关联规则是[X⇒Y]的形式,即[A1⋀A2⋀…⋀Am⇒B1⋀B2⋀…⋀Bn]规则样式,其中[Ai和Bj均为属性值],[X⇒Y]表明满足X中条件的数据库元组多半也满足Y中的条件,X为规则的前项,Y称为结果的后项。
定义1:数据项和事务
设[I=i1,i2,...,im]是m个不同项目的一个集合,每个[ikk=1,2,...,m]称为数据项(Item),数据项的集合I称为数据项集。
事务T(Transaction)是数据项集I上的一个子集,即[T⊆I]。每个事务均有一个唯一的标识符TID与之相联,不同事务的全体构成了全体事务集D(即事务数据库)[6]。
定义2:支持度和置信度
关联规则的支持度就是事务集中同时包含X和Y出现的概率,即:
[SupportX⇒Y=P(X⋂Y)]
关联规则的置信度就是在数据集X出现的前提下Y出现的概率,即:
[ConfidenceX⇒Y=P(Y|X)]
定义3:提升度
由于支持度和置信度不足以过滤掉一些无用的关联规则,再引入提升度作为度量参数,提升度是含有X的条件下同时含有Y的概率与Y总体发生的概率之比,即:
[LiftX⇒Y=PY|X/P(Y)]
用来描述X对Y的影响力大小,若值小于1,意味着一个出现可能导致另一个不出现,只有值大于1时的关联规则才有意义[7]。
1.2多维关联规则
关联规则依照数据的维数可分为单维关联规则和多维关联规则。如规则[BookTP3⇒BookH2],其中TP3和H2是讀者借阅书籍的分类号,是属于同一个属性范围,只有一个谓词,这是单维关联规则。涉及两个属性或两个以上谓词的关联规则就是多维关联规则。比如[Dept(X,计算机专业)⋀Grade(X,"2")]
[⇒Book(X,"TP312")],这里就有三个谓词(Dept、Grade和Book)。规则中的谓词只出现一次称为无重复谓词,这样的关联规则称为维间关联规则(不允许维重复出现),另外一种允许维在规则的左右同时出现的,称为混合维关联规则,比如[Dept(X,计算机专业")⋀Book(X,"TP311")⇒Book(X,"I247")],规则前后项都出现了Book谓词[8]。
2多维关联规则在图书馆中数据挖掘
2.1数据采集
考虑2020年疫情原因,上半年没有可用的借阅数据,仅拉取2020年下半年的借阅流通数据作为数据源。因本次数据挖掘需要考虑读者所在学院和年级,还选取了读者库和馆藏清单用来提取读者对应的学院和年级属性、所借阅书籍分类号。在智慧借阅系统里选择2020年9月份~2021年1月份的2017级~2020级大学四个年级4685名本科生36485笔借阅数据和对应的读者库和2000年以来的馆藏清单数据。
2.2 数据的预处理
数据预处理是在分析之前对原始数据进行必要的清理、集成、转换、归约等一系列处理工作,本文重点在于对多维数据的处理,将多维数据形式通过编码自连接的方式转换为单维数据形式。
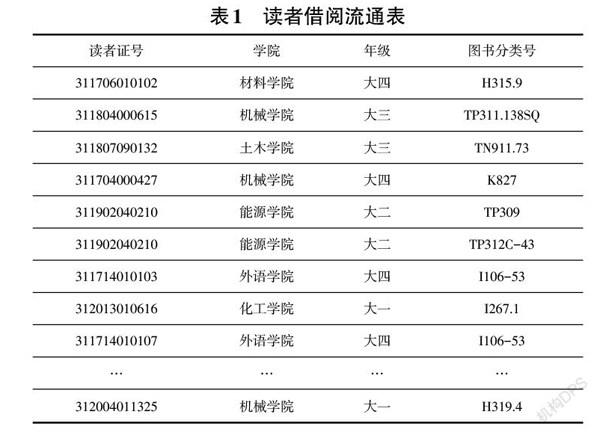
先对借阅流通数据做简单清洗,删除空白项、缺失项、无效项等数据行,再删除其他无用的属性列,包括图书财产号列、借书还书时间列、操作人员列。通过读者库和馆藏清单,将读者的学院、年级和图书分类号信息对应到读者ID上,经处理得到3660名本科生23326笔有效的借阅数据。构成一个新的读者借阅流通表,如表1所示。
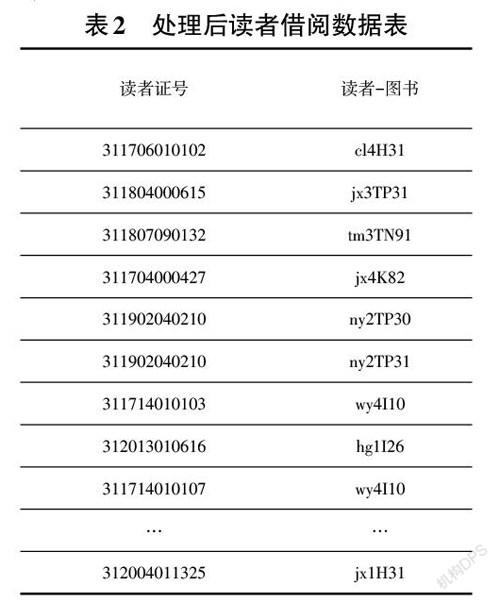
因直接对图书分类号进行关联分析,得到的数据是稀疏的,分析不出实际意义,需要对图书分类号依照中图法进行三级分类数据合并,对学院和年级进行简化编码,学院名称统一简化为首字母缩写,年级统一用1、2、3、4来表示,如机械学院大四学生简化为jx4。再通过属性间逻辑与自连接的方式将读者属性与所借阅图书分类号进行融合,将多维属性转换为单维属性的形式,最终处理如表2所示。
根据Weka可以识别的数据形式,将此表建立事务数据库,每个读者借阅数据为一个事务项目,把每个读者-图书值列为一个数据项属性,并保存为.csv格式。
2.3模型建立与分析
2.3.1模型建立
依照中图法的22大类,将借阅图书分类号的第一级大类分解出来,进行统计分析,借阅范围大致分布如图1。
从图1可知,文学I类借阅量占整体的46%,借阅量比较大,将所借图书类别一起进行关联分析,其结果会出现关联关系集中在文学类书籍上,不能深入挖掘出其他类别书籍关联结果,为此我们把读者借阅的模式分为2种类型:一种是借阅了I文学类书籍的读者;另一种是借阅了非文学类书籍的读者。
2.3.2 文学类读者与图书类别间关联分析
应用Weka3.8.0数据挖掘工具[9],使用preprocess模块打开需要分析的csv文件,选择Associate关联规则模块,运用Apriori算法对参数进行设置,经多次试验选用lowerBoundMinSupport为0.5%,MetricType为Confidence,MinMetric为0.1,运行结果如表3和表4。
从表3关联结果可以看出:
(1)文学类书籍属于通识类书籍,大一、大二年级学生主要课程以基础课为主,极少涉及到专业类课程,他们大多借阅书籍以文学类为主,各学院大一、大二年级的读者有2%以上都借阅了文学类书籍,而大三、大四年级的读者相对较少,不到1%,说明随着专业课的开展和学习,读者的偏好有所转移,涉猎了更广泛类别的书籍。
(2)其中文学类书籍最受欢迎的是I24中国文学小说和I56外国文学小说,70%以上读者借阅了I24类书籍,25%以上读者借阅了I56类书籍,而且各学院各年级都有借阅比例,尤其借阅比例高的是文法学院和机械学院读者,且I56外国文学类书籍集中借阅在文法学院各年级。
(3)这些规则提升度都大于1,说明规则前项和后项是正相关关系,前项的出现都会有后项同时出现,如{文法学院,大三}==>I56,提升度是2.97,意味着文法学院大一年级的读者借阅I56类书籍是所有读者随机借阅I56类书籍的2.97倍。
从表4混合维关联规则可知:
(1)财经学院、机械学院、文法学院、物电学院大一新生借阅了I24中国小说类书籍的读者有60%以上都同时借阅了I26中国散文集书籍,文法学院和财经学院文科类学院学生涉及的类别相对较多些,财经学院大一新生有88%读者还同时借阅了I71外国文学类书籍,文法学院大一、大二学生有71%都借阅了I21中国作品集。
(2)这些规则提升度都在27.45以上,表明前项后项关联性很强,如规则1,读者是财经学院大一新生借阅了I24类书籍,同时也借阅了I71类书籍的概率是读者随机借阅I71类书籍的45.79倍。
2.3.3 非文学类读者与图书类别间关联分析
运用Weka3.8.0挖掘工具,选择非文学类读者借阅数据表进行分析,使用associate关联规则模块,对Apriori算法的参数进行设置,设置参数lowerBoundMinSupport为0.5%,MetricType为Confidence,MinMetric为0.1,挖掘结果如下表5和表6。
从表5关联规则结果可知:
(1)非文学类书籍大多是偏专业性强的书籍,大多借阅集中在大三大四年级,借阅比例较高的有物电学院大三学生借阅了H31英语类书籍,数信学院大四学生借阅了O17数学分析类书籍,建艺学院大三学生借阅了TU98区域规划类书籍,计算机学院大三学生借阅了TP31计算机软件类书籍,机械学院大四学生借阅了TH12机械设计类书籍,但也有建艺学院和计算机学院大一大二学生也开始阅读TU20建筑学一般性问题类书籍和TP31计算机软件类书籍。
(2)因专业内容范围的不同,有的学院学生借阅书籍类别比较单一,有些则涉及类别比较多样,如数信学院大二、大三、大四学生有30%以上都借阅了O17数学分析类书籍,计算机学院大一、大二、大三、大四学生有34%以上都借阅了TP31类书籍,而且随着年级提高借阅比例也提高,计算机学院大四学生有88%比例都借阅了TP31类书籍。物电学院大三学生都分别有31%借阅了H31英语类书籍,27%借阅了O44电磁学类书籍,20%借阅了TP31计算机类书籍,机械学院大四学生都分别有35%借阅了TG50机床加工类书籍,68%借阅了TH12机械设计类书籍,25%借阅了TP31计算机软件类书籍。
(3)从提升度来看,有相当一部分关联规则的提升度很高,表明因前项出现导致后项出现概率比后项随机出现概率高许多,前后项有很强的关联性,比如关联规则{数信学院,大四}==>O17的提升度为49.13,数信学院,大四的学生借阅O17类书籍是任意学生借阅O17书籍的49.13倍。
从表6生成的关联规则可知:
(1)因专业类知识学习也是逐渐递增的过程,从基础类专业到某方向类专业,大多学生借阅了某类别的书籍后同时也会借阅同类别其他书籍,如机械学院大四学生借阅了TG50机床一般性问题,有60%借阅了TH12機械设计类和80%借阅了TH16机械制造工艺类书籍,计算机学院大三学生借阅了TP30计算机一般性问题,有100%借阅了TP3-0计算机理论类书籍和50%借阅了TP31计算机软件类书籍,建艺学院大四学生借阅了TU-0建筑理论类书籍,有67%借阅了TU20建筑设计一般性问题和67%借阅了TU98区域规划类书籍。
(2)有的学院专业知识比较集中,借阅书籍类别相对较少,如化工学院大四学生借阅了O65分析化学类书籍100%都会借阅O62有机化学类书籍,数信学院大四学生借阅了O15代数类书籍78%会借阅O17数学分析类书籍。
(3)因有的专业界限清晰,不会涉及跨专业类学科,分析出的关联规则提升度超过100,如化工学院借阅的书籍是有关化学方面的,建艺学院借阅的书籍都是建筑设计类书籍,与其他学院专业知识基本无交叉,意味着只有化工学院的学生才会借阅O62、O65类书籍,只有建艺学院学生才会借阅TU建筑设计类书籍,这些关联规则极强。
3 多维关联规则在图书馆的应用分析
3.1 优化馆藏资源建设
通过对2020年下半年本科四个年级的图书借阅数据分析,可以看出大概有近一半的学生都偏爱文学类书籍,尤其是低年级的大一和大二学生,本校目前只有一个文学库,借此图书馆扩建时机,可以考虑增加书籍馆藏量并增设文学库,来满足读者对文学类书籍的需求。
依照读者借阅书籍的关联关系,还可以适当调整馆藏布局,将借阅关联度大的书籍就近放置,方便读者寻找和阅读。如I24、I56中外文小说类书籍深受读者喜爱,可以适当优化馆藏布局,为读者快速找到自己偏爱的书籍提供便利。
3.2 提供个性化服务
通过读者大量的历史借阅数据,不仅分析出读者与图书的维间关联性,还分析出读者不同学院不同年级借阅图书的混合维关联关系,细化了读者属性,明确了读者需求分布特征,可以更加精准地指导图书馆进行个性化推薦服务、个性化检索和推送服务。如读者是大一学生,都可以给读者推荐I24、I56文学类书籍;计算机学院的学生,可以给读者推荐TP31计算机软件类书籍;机械学院大四的学生,都可以推荐TH12机械设计类书籍和TP31计算机类书籍,如果读者借阅过TG50机床类书籍,且是机械学院大四的学生,可以给读者推荐TH12机械设计类书籍。建立图书推荐系统,将被动服务变为主动服务,主动根据数据分析结果预测读者可能喜爱的书籍,不仅可以缩短读者借阅图书的时间,还可以快速找到读者偏爱的书籍,节约了读者的时间,同时也提高了书籍流通率和借阅率,将图书馆的价值充分发挥出来。
3.3 学科服务
通过读者不同学院不同年级对借阅书籍的关联规则,可以找出不同读者对借阅的图书类别的分布特征,可以与所在学院和年级进行合作,开展一些文献信息咨询服务和文献资源分布指南培训等活动,并嵌入到学院、教学第一线的信息素养教育中,使读者更深入地了解图书馆资源信息分布,使资源被充分利用起来。也从中挖掘出学科间隐藏的关联,可以引导读者拓宽阅读范围,为跨学科建设指明方向。
4 结论
本文以读者属性所在学院、年级、所借阅图书来建立挖掘的体系架构,不仅细化了读者属性,也将图书的类别依照中图法划分成三级类目,将多维属性通过编码自连接的方式转换成单维属性,运用Weka3.8.0数据挖掘工具进行多维关联规则数据挖掘,分析出维间规则和混合维规则丰富的潜在信息,其结果不仅可以指导图书馆优化馆藏资源建设,还可以为读者提供更精准的个性化服务和学科服务。但本文仅使用了关联规则一种数据挖掘技术,在以后的研究中应加入更多的数据挖掘技术如聚类分析、分类分析、神经网络、随机森林等算法,挖掘出更多潜在和可用的信息,以此来进一步指导高校图书馆发挥更大的服务职能。
参考文献:
[1] 冯磊.大数据挖掘在高校图书馆个性化服务中应用研究[J].图书馆学刊,2019,41(1):109-112.
[2] 侯贺.基于关联规则的图书馆流通数据挖掘——以深圳大学城图书馆为例[J].图书馆学刊,2017,39(2):107-111.
[3] 聂飞霞,陈长明.Apriori算法在图书馆典藏规划中的应用[J].情报探索,2018(7):30-35.
[4] 陈淑英, 徐剑英.关联规则应用下的高校图书馆图书推荐服务[J].图书馆论坛,2018 (2):97-102.
[5] 王蕾, 高翔.借阅行为大数据应用于高校图书馆服务创新的路径分析[J].大学图书馆情报学刊, 2020(11):107-120.
[6] 郑继刚. 数据挖掘及其应用研究[M].昆明:云南大学出版社,2014.
[7] 李珺, 刘鹤. 基于改进的K-means算法的关联规则数据挖掘研究[J].小型微型计算机系统,2021(1):15-19.
[8] 温海波.多维关联规则在图书馆中的应用研究[D].合肥:合肥工业大学,2013: 9-11.
[9] 周捷, 章增安.基于大数据的高校图书馆个性化推荐书目生成研究[J].晋图学刊,2017(5):29-33.
【通联编辑:王力】
收稿日期:2021-04-10
基金项目:河南理工大学人文社科基金资助,年度项目“改进Apriori算法在图书馆信息知识发现中应用分析”(项目编号:722618/172)
作者简介:李华群(1985—),女,河南省焦作市人,河南理工大学图书馆助理馆员,硕士研究生,主要研究方向:图书情报、数据挖掘。