钻蛀性害虫取食声音的人工智能早期识别*
2021-12-15刘璇昕陈志泊骆有庆
刘璇昕 孙 钰 崔 剑 蒋 琦 陈志泊 骆有庆
(1.北京林业大学信息学院 北京 100083; 2.北京航空航天大学网络空间安全学院 北京 100191; 3.北京林业大学林学院 北京 100083; 4.国家林业和草原局林业智能信息处理工程技术研究中心 北京 100083)
林业有害生物导致的林业生物灾害是威胁我国林业的重大自然灾害之一,其对森林资源和生态系统的破坏,每年均造成大量的直接或间接经济损失(李娟等, 2019)。在林业有害生物中,林木蛀干害虫生活隐蔽、防治困难,是生态安全的重大隐患。蛀干害虫大部分龄期均生活在寄主林木的木质部或韧皮部,蛀食树干,破坏树木的分生组织和输导组织,严重时危害树势甚至导致树木死亡(黄志平等, 2013; 吕飞等, 2015)。蛀干害虫高隐蔽性的生活习性导致其在危害早期难以发现,人工样地观察(Floweretal., 2013)、成虫诱集技术(Mcculloughetal., 2011)、遥感监测(Zhangetal., 2014)等常用的监测手段难以实现早期预警。随着声音监测技术在害虫识别领域的应用,林木蛀干害虫的早期预警有了新的研究方向(韦雪青等, 2010)。
声学技术在害虫监测领域的应用始于20世纪20年代,但由于技术的局限性,未能取得有效成果,随着计算机技术和微电子技术的进步,害虫声音监测技术有了新的发展(韦雪青等, 2010)。害虫声音监测技术的研究对象主要包括仓储害虫(李玥等, 2018)、木材检疫害虫(娄定风等, 2013)、土壤害虫(Mankinetal., 2007)、林木钻蛀害虫(Mankinetal., 2018)等。在害虫声音监测中,对于有发声器官的成虫或隔音环境下的幼虫,可采用麦克风作为传感器,侦听传导至空气中的振动(罗茜等, 2011)。但麦克风仅能接收空气中的振动,且易受环境噪声干扰,难以采集蛀干害虫在树木内部的活动信号。对于土壤害虫和蛀干害虫的活动信号,通常利用压电传感器采集害虫在土壤或树干内爬行或蛀食时产生的振动信号,以提高监测灵敏度并减少环境噪声对信号的干扰(Mankinetal., 2003)。
害虫活动信号识别的研究大致可分为2种。其一是对害虫活动信号的时频特性进行人工分析,如统计脉冲信号数量和强度(赵源吉等, 2009; Dosunmuetal., 2014)、分析脉冲时域图和功率谱密度(卜宇飞等, 2017; Jalinasetal., 2019)等。其二是利用算法对采集到的害虫声信号进行自动识别。美国农业部Mankin课题组利用Raven筛选出包含害虫声音的音频后利用DAVIS软件进行最小二乘匹配以区分虫声和噪声或不同虫声(Inyangetal., 2019; Mankinetal., 2016); 国内的研究学者大都借助语音识别的原理实现害虫声信号的识别,首先提取信号的梅尔倒谱系数,然后利用LBG(Linde, Buzo, Gray)矢量量化算法(竺乐庆等, 2010)、高斯混合模型(Gaussian mixture model,GMM)(竺乐庆等, 2012)或BP(Back propagation)神经网络(罗茜等, 2011)进一步提取特征,最后通过最邻近搜索(竺乐庆等, 2010)、概率统计(罗茜等, 2011; 竺乐庆等, 2012)等实现分类。近年来,也有研究学者利用卷积神经网络实现端到端的害虫识别(孙钰等, 2020)。
害虫的取食声经传感器处理后通常转化为音频格式,与语音识别的数据格式及频率范围较为一致,因此,可借助语音识别领域的关键词检测技术实现取食声音的识别。关键词检测用于语音信号中关键单词或短语的识别(Warden, 2018)。早期的关键词检测通常采用隐马尔科夫模型(hidden Markov model,HMM)(Wilponetal., 1991),随着人工智能技术的发展,基于深度学习的关键词检测模型取得新的进展(LeCunetal., 2015)。近年来的研究中,在关键词检测中应用的深度学习模型主要有深度神经网络(deep neural network,DNN)模型(Chenetal., 2014)、卷积神经网络(convolutional neural network,CNN)模型(Tangetal., 2018)、循环神经网络(recurrent neural network,RNN)模型(Heetal., 2017)、卷积循环神经网络(convolutional recurrent neural network,CRNN)模型、时延神经网络(time delay neural network, TDNN)模型(Sunetal., 2017)等,为了强化模型的学习能力,部分模型中还引入了注意力机制(Shanetal., 2018)。
相较人工监测、诱捕器监测、遥感监测等监测技术,声音监测技术具有在虫害发生早期及时预警的能力,近年来,受到越来越多研究人员的关注。但是,国外的研究学者大都借助Raven和DAVIS软件进行半自动的特征提取及虫害声音匹配,识别结果依赖主观分析,没有数值化的精度评价。国内的研究学者借助语音识别技术针对害虫活动或取食声设计模型,实现自动化的害虫声音识别,但研究所采用的数据均为隔音箱或室内环境中采集的纯净虫声数据,缺乏对含噪虫声数据的研究,难以实现钻蛀性害虫声音监测的实际应用。因此,本研究在校园、马路边等户外开放环境下采集噪声音频,一方面作为钻蛀性害虫取食声的负样本,另一方面也作为噪声数据,通过和钻蛀性害虫取食声进行混音,进行噪声强度可控的含噪取食声识别研究。
本研究以双条杉天牛(Semanotusbifasciatus)为研究对象。双条杉天牛是危害柏科(Cupressaceae)树木的蛀干害虫,属我国林业有害生物检疫对象(耿涌鑫等, 2018)。本文利用压电传感器采集其咬食木段的声音,同时采集噪声数据作为干扰,参考基于深度学习的人工智能语音识别技术,设计基于卷积神经网络的识别模型识别双条杉天牛的取食声,同时对识别模型的抗噪性能进行测试,验证模型在野外嘈杂环境下的可用性,为隐蔽蛀干害虫的早期预警提供抗噪技术支撑。
1 数据材料
1.1 数据采集
本研究主要采集了2类数据,一类是双条杉天牛取食声,另一类是在开放环境下采集的噪声音频。
从林场采集直径约为10 cm长度约为30 cm的侧柏(Platycladusorientalis)木段,并在木段中部钻孔(孔深3 cm左右),于3月中下旬向木段中接入双条杉天牛成虫,等待成虫在木段中进行交配、产卵。5月上旬开始,每隔3~5 天使用SP-1 L探头连接NI 9215电压采集卡采集木段中双条杉天牛幼虫的取食声(图 1),采集到的取食声中基本无环境噪声。同时,利用相同的数据采集设备,在校园、马路边等户外开放环境下使用相同仪器录制的噪声音频,其中包含行人脚步声、人与人交谈声、鸟鸣声、风声、汽车行驶声、鸣笛声等明显环境噪声,但不含双条杉天牛的取食声。

图1 数据采集设备
选取130段双条杉天牛取食声和83段噪声音频用于后续试验,单段音频时长为5 min,采样率为44.1 kHz。利用SoX(Sound eXchange)音频处理工具将音频的采样位数转换为16 bit,同时将音频的采样率统一为16.0 kHz。
1.2 数据划分
为了对模型的抗噪性能进行测试,从采集到的83段噪声音频中随机选择加噪音频,其中8段加入训练集和简单测试集,5段加入抗噪测试集,剩余70段作为噪声类用于识别模型的训练及简单测试; 同时,从采集到的130段双条杉天牛取食声中随机选取60段加入抗噪测试集,剩余70段加入训练集和简单测试集。数据集划分情况如表 1所示。

表1 数据集划分情况
1.3 音频加噪
为了训练识别模型,对数据进行切分,切分方式如图 2所示,切片长度为1 s,每段音频可得到300段切片。为了测试模型的训练效果,训练集/简单测试集中的音频切分得到的各类切片按7∶3的比例划分为训练集和简单测试集。

图2 数据切片方式
为了使模型适应噪声环境,从而增加模型的抗噪能力,训练阶段,在保留一定量不混音的双条杉天牛取食声切片的基础上,对双条杉天牛取食声切片和加噪音频切片进行混音(Ephratetal., 2018),混音前后的时域波形图和频域声谱图如图 3所示。混音时的噪声强度通过信噪比(signal-noise ratio,SNR)(Barkeretal., 2013)衡量,信噪比的计算公式为:

图3 不同信噪比下的波形和声谱
(1)
式中,LS表示取食声音频,NS表示加噪音频,P表示音频能量,Ai表示音频在第i个采样点处的振幅,n表示音频采样点数。
在对训练集和简单测试集混音时为每段加噪音频切片设置7种信噪比(-3~3 dB,间隔1 dB),将7种信噪比下的加噪音频切片和不同双条杉天牛取食声切片混合,得到用于训练和测试的双条杉天牛取食声数据。训练集中共有取食声切片14 700段,其中,7种信噪比的取食声切片各有1 680段,不加噪的取食声切片有2 940段; 简单测试集中共有取食声切片6 300段,其中,7种信噪比的取食声切片各有720段,不加噪的取食声切片有1 260段。同时,在训练集和简单测试集中加入与双条杉天牛取食声切片数量一致的噪声切片作为负样本。
为了测试模型的抗噪性能,利用抗噪测试集中的双条杉天牛取食声切片和加噪音频切片生成独立的双条杉天牛取食声混音数据作为抗噪测试集,抗噪测试集中不包含噪声切片,但相较训练集和简单测试集,设置了更大的信噪比区间(-7~3 dB,间隔1 dB),在低信噪比上,扩展了4 dB,每种信噪比的取食声切片各有1 500段,同时包含相同数量的不加噪的取食声切片。利用公式(1)可推知:
(2)
式中,NS表示加噪音频,LS表示取食声音频,SNR表示信噪比。
将信噪比代入公式(2)可知,信噪比为-3 dB时,噪声音频的音频能量约为取食声的音频能量的2倍,信噪比为-7 dB时,噪声音频的音频能量约为取食声的音频能量的5倍。已有研究人员的测试表明,信噪比为9 dB时,人的听觉对字母的识别准确率约为97%,当信噪比下降至-6 dB时,人的听觉对字母的识别准确率仅有83%左右(Barkeretal., 2013),可以看出,音频的信噪比强度会对声音识别的准确率造成明显影响。
2 模型设计
2.1 频谱特征提取
提取平均对数谱(average log spectrum)作为音频的特征用于取食声识别。平均对数频谱的计算主要包括短时傅里叶变换(short-time Fourier transform,STFT)、对数计算、平均池化(average pooling)3步。
为了增加音频的复杂度,避免训练中的过拟合现象,在计算频谱之前对音频进行-5 ms至5 ms的随机平移,平移后用0填充至1 s时长。对于平移后的音频,以30 ms的窗长及20 ms的重叠率进行逐段的傅里叶变换,傅里叶变换的点数设置为512。通过短时傅里叶变换,每个1 s长的音频均可得到98×257的声谱图(图4a)。为了放大频谱特征的波动,增加区分度,对频谱特征进行对数计算(图4b)。为了综合频谱特征,将对数计算后的频谱特征进行平均池化,平均池化的窗大小为1×6,2个方向的步长分别为1和6。经过平均池化,每个1 s长的音频可得到98×43的平均对数谱用于后续的卷积计算(图4c)。
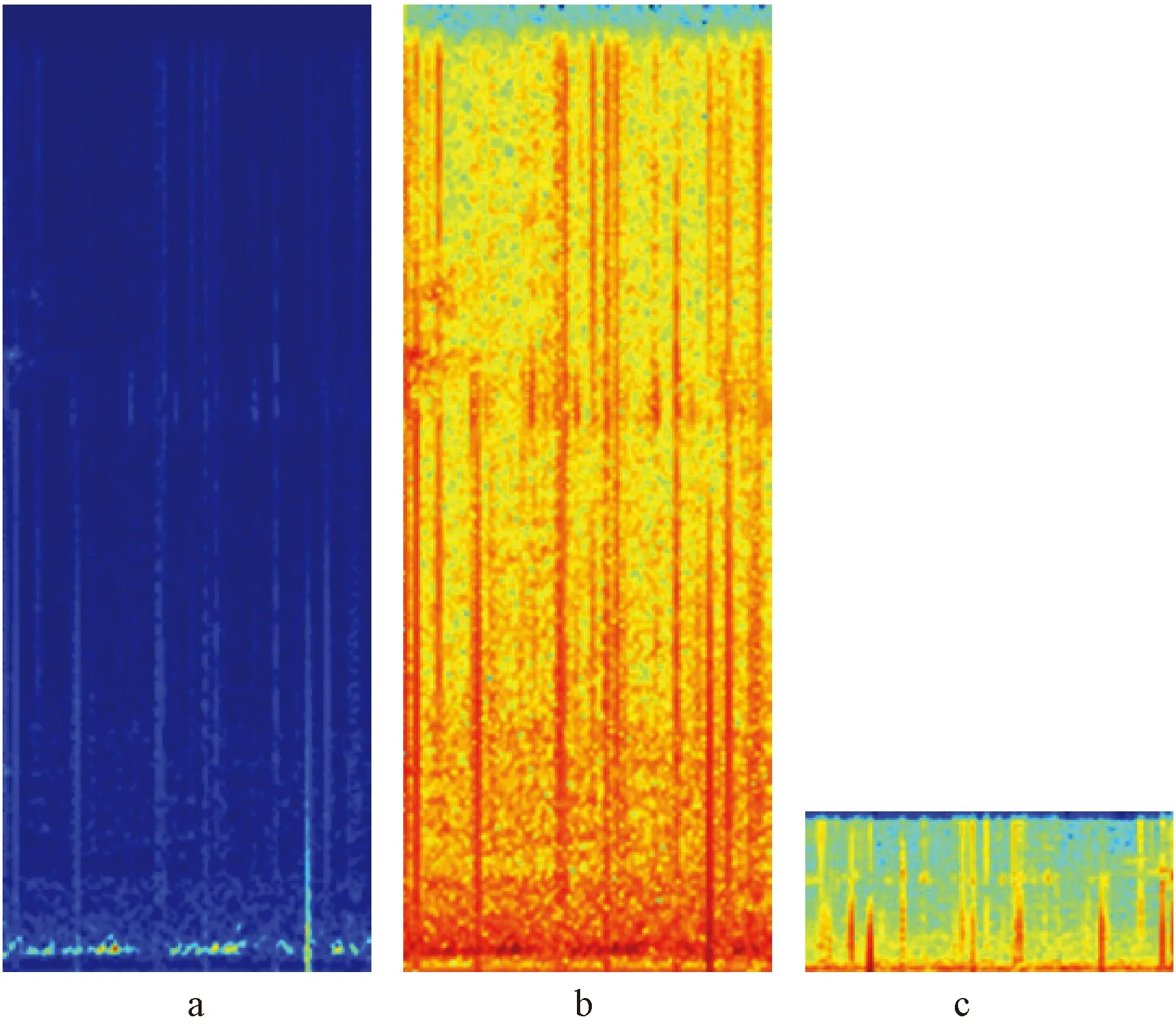
图4 频谱特征提取逐步结果
2.2 网络结构设计
设计基于卷积神经网络的识别模型进行取食声的识别,网络结构如图5所示。

图5 卷积神经网络结构
卷积神经网络主要由2层二维卷积、一层最大池化和一层全连接构成。卷积层包括权重和偏置2组参数,其中权重通过标准差为0.01的截段正态分布随机初始化,偏置初始化为0。为保证卷积操作前后特征图大小的一致性,卷积操作前对特征图进行补0操作,2层卷积的卷积核个数均为64,卷积步长均为1,卷积核大小分别为20×8和10×4,卷积操作后网络利用ReLU(Rectified Linear Unit)激活函数提高模型的非线性映射能力,同时为了避免网络过拟合,在激活函数后利用dropout层随机忽略网络层中50%的神经元。在第1次卷积操作之后,网络通过步长为2的最大池化操作,在实现特征降维的同时,更好地保留特征中的纹理信息。在第2次卷积操作之后,网络通过特征展开得到68 992维特征,然后利用全连接层综合特征信息,并借助softmax函数实现各类识别概率的计算。
3 结果与分析
3.1 试验环境
基于卷积网络的识别模型的实现基于TensorFlow深度学习框架,硬件平台采用Intel Core i7-6700 CPU(64 GB内存)和NVIDIA TITAN RTX GPU(24 GB显存)。
模型训练阶段批处理大小为128,损失函数为多分类交叉熵损失。模型利用梯度下降算法(Gradient Descent Optimizer)进行参数更新,一共迭代6 000次,前3 000次学习率为0.005,后3 000次学习率为0.001。
3.2 简单测试集
以音频切片的识别准确率作为模型性能的评价指标,试验的简单测试集包括双条杉天牛取食声、噪声2类,各类的切片数为6 300。基于卷积神经网络的识别模型在简单测试集上的整体准确率为98.80%。其中,双条杉天牛取食声切片的准确率为98.95%,噪声切片的识别准确率为98.63%,简单测试集识别结果的混淆矩阵如图 6a所示。为了对比基于卷积神经网络的识别模型的识别效果,利用相同的训练集训练了昆虫声音识别中常用的高斯混合模型(郭敏等, 2012; 竺乐庆等, 2012)并在简单测试集上进行测试,高斯混合模型在简单测试集上的整体准确率为99.68%,其中,双条杉天牛取食声切片的准确率为99.49%,噪声切片的识别准确率为99.87%,识别结果的混淆矩阵如图 6(b)所示。

图6 基于卷积神经网络的识别模型(a)高斯混合模型(b)在简单测试集的混淆矩阵
3.3 抗噪测试集
为了验证模型的抗噪性能,利用抗噪测试集测试2种模型在更多信噪比下对双条杉天牛取食声切片的识别效果,识别准确率如图 7所示。在测试集上,基于卷积神经网络的识别模型的平均准确率为97.37%,高斯混合模型的平均准确率为90.61%; 在信噪比为-6 dB时,基于卷积神经网络的识别模型的识别准确率为92.1%,而高斯混合模型的识别准确率只有86.5%。

图7 抗噪测试集不同信噪比下双条杉天牛取食声的识别准确率
3.4 综合分析
对比基于卷积神经网络的识别模型和高斯混合模型在简单测试集上的结果,基于卷积神经网络的识别模型的识别准确率为98.80%,高斯混合模型的识别准确率为99.68%,2种模型均能有效识别无噪及低噪双条杉天牛取食声,准确率差距不足1%。对比基于卷积神经网络的识别模型和高斯混合模型在抗噪测试集上的结果,对于不加噪的双条杉天牛取食声,2个模型的识别准确率均为100%; 除此之外,在各信噪比下,高斯混合模型的识别准确率均低于基于卷积神经网络的识别模型。信噪比为-3 dB时,高斯混合模型的识别准确率已经低于90%,基于卷积神经网络的识别模型的准确率仍能达到98.1%; 信噪比为-4、-5 dB时,高斯混合模型的识别准确率已低于88%,基于卷积神经网络的识别模型的准确率仍高于95%; 信噪比-6 dB时,高斯混合模型的识别准确率为86.5%,而基于卷积神经网络的识别模型仍有92.1%的准确率; 信噪比为-7 dB时,2种模型的识别准确率均低于90%,但基于卷积神经网络的识别模型的准确率仍比高斯混合模型高4.8%。
4 讨论
当前国内外对昆虫声音识别的研究对象中,缺乏含噪虫声数据。因此,本研究设计基于卷积神经网络的识别模型,同时选择昆虫声音识别中常用的高斯混合模型作为对比模型,对含噪双条杉天牛取食声进行识别并利用含较强噪声干扰的双条杉天牛取食声对2种模型的抗噪能力进行了测试。
高斯混合模型通过期望最大化实现对各类数据的拟合。由试验结果可知,在与训练集数据相似度较高的简单测试集上,高斯混合模型的识别准确率接近100%,但对于与训练集区别较大的抗噪测试集,随着噪声强度的增加,高斯混合模型的识别准确率下降较为明显。对比训练集和简单测试集,二者的双条杉天牛取食声和噪声音频的相似度较高且含噪双条杉天牛取食声的噪声强度一致,高斯混合模型通过对训练集的迭代,有效提取训练集的数据特征,在简单测试集上的表现较好; 对比训练集和抗噪测试集,二者的双条杉天牛取食声和噪声音频是不同时间录制的音频段,数据存在较大差异,且抗噪测试集中的含噪双条杉天牛取食声具有更高的噪声强度,高斯混合模型在数据差异较大的抗噪测试集上的识别结果下降明显,表明模型的泛化能力较差,难以满足应用需求。
基于卷积神经网络的识别模型通过卷积操作提取特征,池化操作放大局部特征,激活函数映射非线性特征,经过训练,简单测试集识别准确率接近100%。同时,在与训练集区别较大的抗噪测试集上,基于卷积神经网络的识别模型仍能取得较好的识别准确率,表明卷积神经网络具有更好的泛化能力。根据公式(2),信噪比为-6 dB时,噪声能量约为双条杉天牛取食声频能量的4倍,在此噪声干扰下,基于卷积神经网络的识别模型的识别准确率为92.1%,表明卷积神经网络具有良好的抗噪性能,更能有效应对实际应用时可能出现的噪声干扰。
5 结论
本研究使用压电传感器采集双条杉天牛咬食木段的取食声,同时采集典型户外环境下的噪声音频,设计基于卷积神经网络的识别模型进行双条杉天牛取食声的识别,对比研究卷积神经网络和高斯混合模型的抗噪识别能力。通过提取音频的平均对数谱,设计卷积神经网络进行特征提取及分类,实现双条杉天牛的取食声识别。为了验证模型的抗噪性能,向双条杉天牛取食声中混入更广信噪比的噪声,测试模型对含噪双条杉天牛取食声的识别准确率。研究结果表明,基于卷积神经网络的识别模型能有效综合频谱特征,准确识别无噪及低噪的双条杉天牛取食声; 同时,基于卷积神经网络的识别模型还具有良好的泛化能力,在-6 dB信噪比下仍能保证双条杉天牛取食声92.1%的识别准确率。因此,基于卷积神经网络的识别模型能够适应林木蛀干害虫的野外监测环境,为林木蛀干害虫的自动化监测和早期预警提供技术支撑。未来将从林区活立木上采集双条杉天牛取食声,进一步验证人工智能识别模型的抗噪性和可行性。
