基于机器学习与光谱技术的油菜叶片含水率估测研究
2021-12-14蔡振江张东方范晓飞王林柏
张 君,蔡振江,张东方,范晓飞,王林柏,王 菁
(1.河北农业大学 机电工程学院,河北 保定 071001;2.河北农业大学 园艺学院,河北 保定 071001)
水分是影响作物光合作用和产量的重要因素之一[1],水分匮乏轻则影响作物的生理特征使得其光合速率降低,重则直接影响作物的生长。快速有效地诊断作物水分状况,对高效利用水资源提高作物品质以及产量具有重要意义。
目前国内外已有研究表明作物缺水导致叶片的颜色、厚度以及形态结构等发生一系列变化,作物叶片的含水量与其光谱波段所对应反射率有较显著的关系。白铁成等[2]利用多元散射校正(Multiplicative Scatter Correction, MSC)和连续投影算法(Successive Projections Algorithm,SPA)提高回归模型的预测精度,证明利用光谱技术无损检测对作物叶片水分检测具有借鉴意义。李珺等[3]通过对光谱反射特征的草莓含水率模型进行研究,验证了预测模型的稳定性和敏感性。张海威等[4]通过光谱技术监测植被水分状况,基于聚类分析中的欧式距离方法将叶片含水量划分为3 个等级,通过对比不同植被水分指数对植被水分指数进行了预测能力的评判,表明利用光谱技术可以为植被生长和干旱环境提供研究手段。孙红等[5]利用高光谱成像对马铃薯叶片含水率进行检测和可视化研究,为监测马铃薯生长状况及叶片含水量分析提供了理论依据。李梦竹等[6]研究不同水分胁迫下,采用光谱仪技术进行不同水分胁迫下的不同植株的光谱反射特征和作物含水率变化规律的研究,通过筛选最佳敏感波段进行模型构建,通过建立的数学模型进行烤烟旱情指导。孙旭东[7-8]利用近红外光谱结合最小二乘支持向量机的快速检测方法检测赣南脐橙果树叶片含水率,并利用建立的相关的数学模型进行预测,模型预测相关系数R2提高到0.94,预测值的平方根(Root-Mean-Square Error of Prediction, RMSEP)降低为0.002 7。GamalEIMasry 等[9]利用高光谱技术对草莓水分含量情况进行研究,结果表明利用全波段建立的偏最小二乘(Partial Least Squares,PLS)预测模型相关系数R²高至0.90,为光谱技术监测作物含水量状况提供了理论依据。曹晓兰等[10]采用多种预处理方法建立并比较了各种预处理方法的偏最小二乘回归(Partial Least Squares Regression,PLSR)模型效果,得出经正交信号校正(Orthogonal Signal Correction, OSC)预处理方法效果最佳。宋镇等[11]研究杏鲍菇含水率的快速无损检测以及含水率的分布可视化,利用偏最小二乘和最小二乘支持向量机分别建立了光谱特征、纹理特征以及光谱与纹理特征融合的含水率预测模型,结果表明光谱特征模型预测效果较好,很好地实现了对杏鲍菇的含水率分布可视化研究。徐庆[12]用水稻叶片和冠层高光谱数据以及无人机多光谱数据建立了水稻叶片含水量和植株含水量估计模型。孙俊等[13]通过高光谱成像系统获取高光谱图像并利用干燥法测量叶片含水率,建立了油麦菜叶片的全光谱数据、特征光谱数据与干基含水率的关系模型,结果表明经过人工蜂群算法优化后的模型预测集决定系数R²和均方根误差(Root-Mean-Square Error, RMSE) 分别为0.92 和2.95%,故利用光谱技术结合模型预测油麦菜叶片含水量情况是可行的。孙红等[14]为了指导精确灌溉,对马铃薯作物叶片含水量的无损检测进行了研究,结果得出基于特征波段提取的数据结合PLSR建模精度为0.98,验证精度为0.94,为田间检测马铃薯植株含水量提供了理论依据。康丽等[15]研究表明主成分分析(Principal Component Analysis, PCA)保留非线性信息多 ,相对于非线性建模方式更优。
本研究采取了正交信号校正的预处理方法结合非线性回归建立了油菜的含水率估测模型,采取了主成分分析的方法进行数据降维处理,可以有效避免因特征波段提取的不稳定性带来的模型误差,按照本研究所采用的实验方法,能够为实时监测油菜作物含水率情况且实现精确灌溉提供理论依据与技术支撑。
1 材料及方法
1.1 材料与仪器
1.1.1 试验环境、材料 油菜样本从河北农业大学机电工程学院智能温室种植箱中采集,且其植株生长状况良好。
1.1.2 试验数据采集系统 光谱仪为便携式地物光谱仪PSR-1 100,其光谱范围为320 ~1 100 nm(紫外-可见-近红外)。PSR-1 100 测量系统由光谱仪和光纤组成,是被动式测量反射率的光谱仪,包含512 线阵探测器,由固定全息光栅作为色散元件,配有25°的前视场镜。叶片含水率的测量所用设备为具有PID 温度控制的DHG 系列电热鼓风干燥箱,具有高精度与高灵敏度的英衡牌电子秤。如图1 所示为由PSR-1 100 和卤素灯组成的实验环境。

图1 实验环境Fig.1 Experimental environment
1.2 光谱数据的采集
试验以油菜叶片含水量为研究对象,对所采集的样本立即进行相关测量。在使用光谱仪对每一片叶片进行光谱反射率测定之后,立即对其进行含水率的测定。由于光谱反射率的采集范围是镜头25°广角之下,确保叶片充满被测范围,调整被测样品到镜头的位置为10 cm。采集光谱反射率数据之前,首先对仪器进行白板校正。通过多组对比实验,仪器的理想平均次数为12 次,仪器根据光线条件自动设置积分时间为最佳范围。将所测叶片放在反射率极低的黑色底板上,测量得到的光谱反射率图显示在光谱仪所配套软件DARWinSP 上。
为减小测试误差,采集被测样品3 个位置以获得平均光谱。本实验采用将油菜叶片放入烘干箱,60 ℃下进行烘干,直至得到干重。其含水量计算公式为:
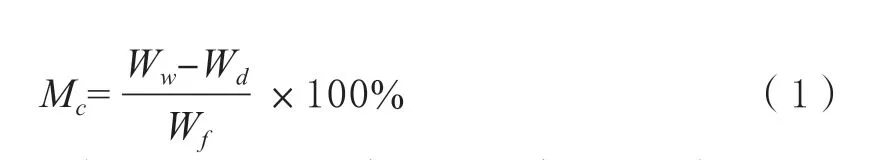
注:其中式子中Mc代表含水率,WW代表叶片的每一烘干阶段的质量,Wd代表叶片的干重质量,Wf代表叶片的鲜重质量。
1.3 光谱数据的预处理
在暗室环境下进行实验数据的提取,首先需要对取得的原始光谱反射数据进行预处理,从而提高估测模型的精度。常用的预处理方法有卷积平滑法、多元散射校正法、归一化等[16]。本试验采用标准正态变量(Standard normal variable,SNV)、均值归一化、多元散射校正、SG卷积平滑(Savitzky-Golay,SG)、正交信号校正预处理方法对原始数据进行预处理,数据分析程序在Unscrambler X 10.4 和SPSS
25.0 中完成,原始光谱数据以及经过不同预处理后的光谱图如图2 所示。
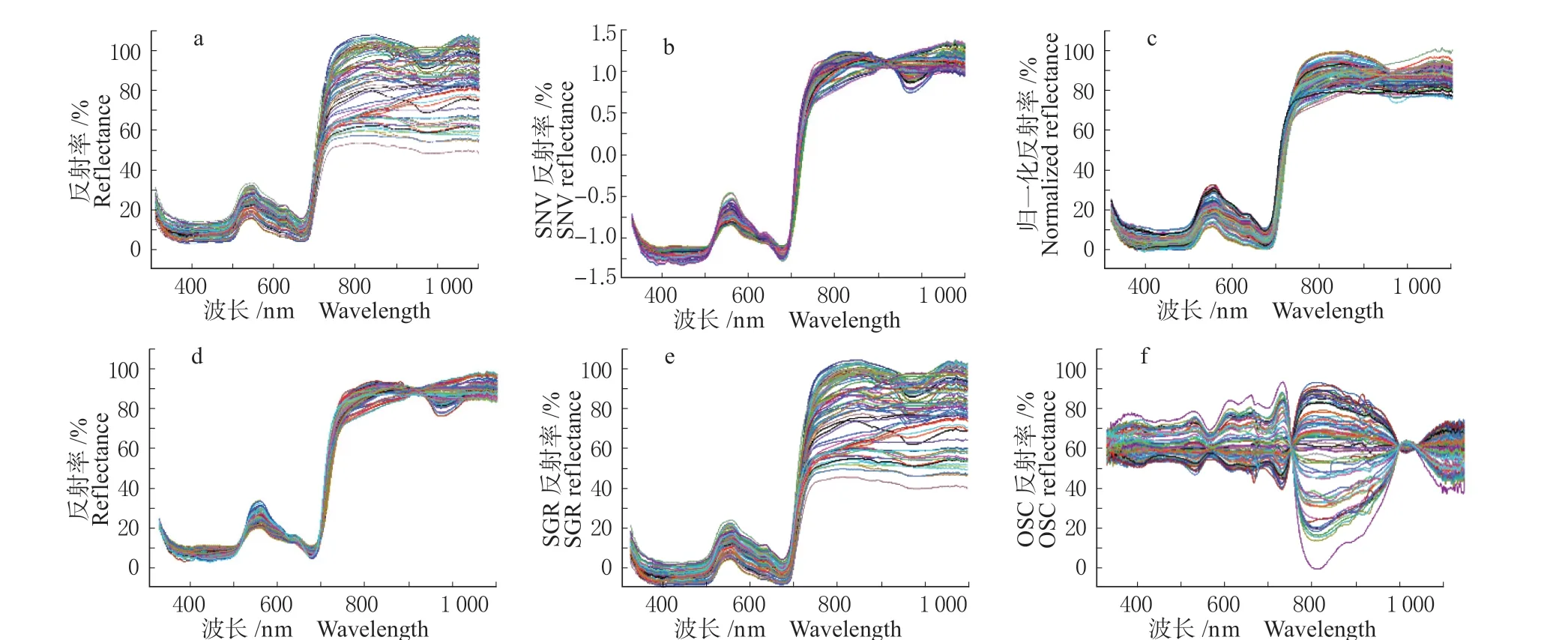
图2 光谱数据:(a) 原始光谱数据 (b) SNV 预处理后的光谱数据 (c) 均值归一化预处理后的光谱数据 (d) MSC 预处理后的光谱数据 (e) SG 预处理后的光谱数据 (f) OSC 预处理后的光谱数据Fig.2 Spectral data: (a) Original spectral data (b) SNV pre-treated spectral data (c) mean normalized pre-treated spectral data (d) MSC pre-treated spectral data (e) SG pre-treated spectral data (f) OSC pre-treated spectral data
利用SG 卷积平滑滤波法[17]可以降低光谱数据中的噪声,同时保留光谱中有效的信息,消除原始数据中的非必要信息,使得原始数据更为平滑,SNV[18]与MSC[19]均可以消除光谱中的散射现象,消除必要的误差,OSC[20]可以滤掉光谱数据与实际数据(含水率)之间无关的信号,经过不同预处理的光谱数据结合原始数据均可以提高模型的预测能力。
2 光谱数据的降维分析
主成分分析是1 种数据降维的数学方法。采用PCA 算法进行数据变量降维,提高建模准确度,其中主成分分析根据各变量之间的相互关系,在不损失原有变量信息的同时以维数较少的、信息不重叠的综合指标来反映原始变量的大部分信息。主成分分析通过使用较少的新变量来解决问题,这些新变量彼此不相关以表示原始变量提供的大量信息[21]。本试验采集叶片的781 个光谱波段数据,利用主成分分析法,选取了8 个基于原始数据的综合变量,这8 个主成分能代表原始数据的98%及以上的信息。如表1 所示列出了利用PCA 提取的8 个主成分的累计贡献率,利用此方法以原始变量的1.02%的数据代替原始数据,可以大大降低模型的复杂度。
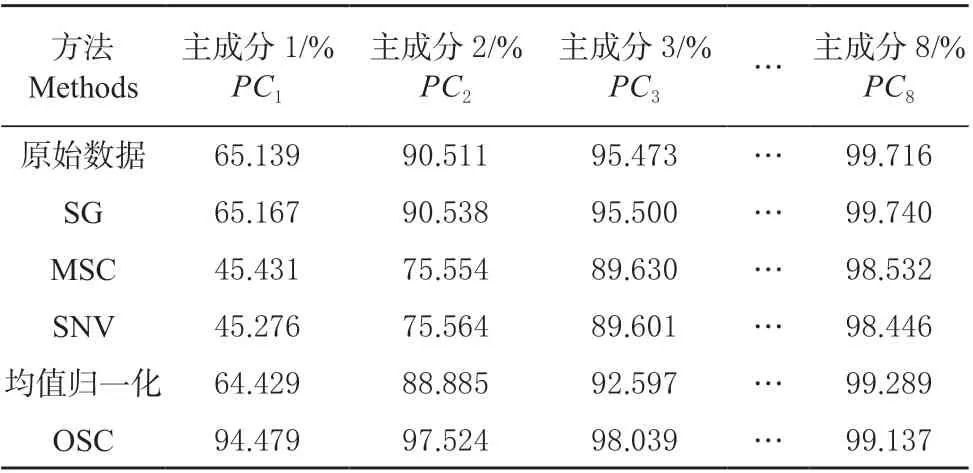
表 1 基于主成分分析的各主成分的累计贡献率Table 1 The cumulative contribution rate of components from principal component analysis
3 数学模型的建立
对所采集样本进行估测模型的建立,采用多元线性回归(Multiple linear regression,MLR)、偏最小二乘回归、支持向量机回归(Support vector regression, SVR)结合主成分分析法对原始光谱数据与5 种预处理后的数据进行处理。并利用模型评判参数决定系数R²、均方根误差RMSE与相对分析误差(Relative percent deviation, RPD) 对所得模型进行评判。3 个判别参数计算公式为:

MLR:其用来描述自变量(y)与因变量(xi)之间的关系,即含水量与8 个主成分(PC)之间的线性关系。
它可以用数学形式表示为:
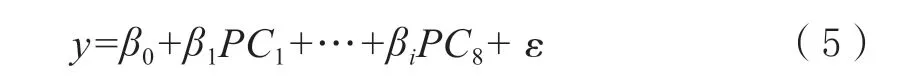
在公式中,PCi是第i个主成分,β0,β1, …,βi是回归系数,ε是随机误差.
PLSR:偏最小二乘集成了主成分分析、典型相关分析、线性回归分析的优点,很好地解决了自变量间多重共线性问题[22]。PLSR 分析是因子分析和回归分析的结合。其输入因变量(光谱矩阵)与自变量(含水率值)进行模型的建立,最终实现向模型输入光谱矩阵以直接得到含水率的值。
SVR: 支持向量机(Support vector machine,SVM)不仅可以用于分类模型,也可以用于回归模型。SVR 就是找到1 个回归平面,让1 个集合的所有数据到此平面的距离最近,让训练集的每个点(xi,yi)尽量拟合到1 个线性模型yi=w·φ(xi)+b。SVM 算法有大量的的核函数可以用于使用,故可以很灵活地解决各种非线性回归问题。支持向量回归即先对样本数据进行模型的训练,后利用此模型进行估测,输入样本为光谱反射率数据,输出数据为油菜叶片含水量的估测值。
对于原始光谱数据以及经过预处理后的光谱数据结合主成分分析得到的8 个综合变量,结合MLR,PLSR, SVR,本文建立了18 个估测模型,其评判参数如表2 所示;基于3 种回归建模方法,得出基于OSC 的预处理方法具有最优的预处理效果,图3 为该方法的拟合效果图。通过利用R²越大接近于1,RMSE越小接近于0,RPD越大,此模型的估测效果最优,选取了OSC+PCA+SVR 方法。

图3 基于OSC方法的拟合效果图:(a)OSC+PCA+MLR; (b)OSC+PCA+PLSR; (c)OSC+PCA+SVRFig.3 The fitting effect diagram of OSC method:(a) OSC+PCA+ MLR; (b) OSC+PCA+PLSR; (c)OSC+PCA+SVR

表2 模型的评判参数Table 2 The evaluation parameters of the model
4 讨论与结论
本试验利用机器学习算法结合光谱数据实现对油菜叶片含水率的快速估测,及时、精准对叶片在没有任何损伤的情况下获得其含水率,为油菜生长监测提供一定的技术支持和理论支撑。
由于光谱数据的采集受环境,温度等外界因素的影响,故本试验在暗室内进行,以最大程度地减小试验误差。同时为了降低由于外界因素的影响,故本文利用5 种不同的预处理方法对所采集的光谱数据进行了数据预处理,最终发现基于正交信号校正预处理方法具有最优效果。此方法有效地增强了光谱数据与成分含量之间相关的信息量,由于原始数据具有781 个光谱波段,本试验选用主成分分析对原始781 个光谱波进行了降维处理,得到了8 个主成分。利用仅占原始数据1.02%的综合变量信息,极大地简化了数学模型且加快了模型的运算速度。最后经过数据处理与降维处理后的6 种数据结合了3种建模算法,建立了18 种估测模型。综合3 个模型评判参数最终选用OSC+PCA+SVR 的估测模型,其Rc²=0.901,Rv²=0.857,RMSE=9.874%,RPD=2.929。本试验结果显示非线性模型效果优于线性模型。SVR 是把线性的回归转化为非线性,将内机核函数转化为了高维空间的非线性映射,不受样本空间维数的影响,且支持向量机可以解决神经网络中无法避免的局部最优的问题,这也验证了相关研究得出的机器学习算法模型优于传统线性模型[22]。
基于光谱分析技术的叶片水含量的估测模型,采用光谱仪对不同含水量状态下的油菜叶片进行监测,通过实际含水率与所得光谱反射率值进行模型的建立,结果验证可知基于光谱技术检测油菜叶片含水量具有极佳的效能,未来利用光谱检测方法可以大大避免水资源的浪费,提高作物的生产效率,为精确灌溉提供极大的帮助。
