Dr.Deep:基于医疗特征上下文学习的患者健康状态可解释评估
2021-12-14马连韬张超贺焦贤锋王亚沙赵俊峰
马连韬 张超贺 焦贤锋 王亚沙 唐 雯 赵俊峰
1(高可信软件技术教育部重点实验室(北京大学) 北京 100871) 2(北京大学信息科学技术学院 北京 100871) 3(北京大学软件工程国家工程中心 北京 100871) 4(北京大学第三医院肾内科 北京 100191)
我国医疗服务领域存在明显供需矛盾.一方面,随人口老龄化加速、慢病增多、健康意识增强,人民对健康医疗服务的需求快速增长;另一方面,医疗服务供给总量不足,医疗资源分布不均.以重症监护预后为例,随着疾病的进展,患者病情会发生变化,死亡风险也会随之变化,在变化的不同阶段都需要医护人员及时的跟进治疗.现如今,由于缺乏这类有经验的医护人员,很多临床死亡风险高的患者在早期未被及时识别并处理.
近年来,现代卫生系统推进了医疗病历记录信息化的建设,在医疗机构中存储了大量的医疗电子病历(electronic medical record, EMR)[1].其中结构化多变量时间序列数据是一种重要且在医疗领域广泛记录的数据类型,蕴含巨大价值有待分析[2-5].对医疗多变量时序数据进行分析挖掘,可以辅助医生对患者进行疾病快速诊断筛查,降低误诊率,提升医疗效率,为提前医疗干预带来机会,发现人类医学专家尚未意识到的医学知识.
随着计算机硬件设备算力的提升,深度学习模型逐渐成为多变量时间序列数据分析的主流技术,并被广泛应用于解决以下问题:死亡预测[6]、患病预测[7]、再入院预测[8]、患者相似性分析[9]、治疗方案分析[10]、临床路径分析[7]、疾病进展建模[11]、ICU患者死亡预测[12]等.虽然在这些研究中处理的任务各不相同,但它们的本质均为学习患者的健康状况表示,将患者复杂的健康数据压缩至低维空间中,从而进行健康预测.
然而,在医疗等领域中,多变量时间序列数据存在特征构成复杂、患者个性化差异大、可解释性要求高等诸多挑战有待解决.在构建预测模型时,应综合考虑3个医疗多变量时序数据特性以及医疗领域预测可解释性需求:
1)分析特征关联关系,个性化抽取患者健康上下文.医疗特征之间有高度的相关性,应综合考虑以进行患者状况表示学习.如血浆中肌酐和尿素浓度开始双曲线上升时,它们和肾小球滤过率值通常与慢性肾病患者的全身表现相关.此外,静态特征与动态特征之间亦有高度相关性,如临床特征(如血糖)的值可能对具有不同静态基线(记录了是否患有糖尿病)的患者具有不同的意义.建模患者健康状态时应综合分析患者不同医学指标之间的关联关系.
2)为处于不同健康状态的患者差异化分析特征重要性.对于健康状况不同的患者,其重要的生理指标也不同;即使对于同一患者,其每个生理指标的重要性也应随着时间的推移进行自适应地调整.例如既往病情稳定的尿毒症患者突然出现血红蛋白大幅降低可能预示着消化道出血可能,模型应立刻给予关注.模型在评估每个指标的取值给患者身体状况带来的影响时,需综合考虑各项特征,判定每个指标对健康的指示意义.
3)医疗领域预测可解释性需求.虽然深度学习在许多领域取得了巨大的成功,但由于其黑匣子的性质,在医疗领域尚未得到广泛信任[13].如果模型可以从多角度输出其判断逻辑,医生可以在信任该结果的基础上为患者制定精准的治疗方案.
本文针对医疗领域数据特点所带来的挑战和医疗应用对多视角可解释性的独特需求,开展了针对医疗多变量医疗时间序列数据表示学习的研究.提出了一种基于医疗特征上下文学习的患者健康状态可解释评估方法Dr.Deep,并开发了基于医疗多变量时序数据分析的医生临床辅助系统,为临床诊疗提供辅助决策支持.本文的创新点总结为3个大方面.
1)面向多变量时序电子病历数据,提出基于特征上下文表示学习的患者健康状态个性化表示学习方法与可解释评估方法.技术贡献具体包括:
① 提出了一种多通道健康上下文表示学习方法,有效编码医疗记录以构成患者的健康表示.在多特征通道结构的基础上,采用了基于去相关自注意力机制的特征上下文关联分析,显式抽取多个动态特征之间、以及动态特征与静态基线信息之间的关联信息,解决需求1.
② 提出了基于压缩激励机制的特征重要性重标定方法,自适应地选择重要特征信息作为代表性的指标来构建健康状态表示,抑制无用特征以提升表示学习鲁棒性.最终将指标重要性显示输出,为模型提供可解释性,解决需求2与需求3.
2)在2个开放重症监护患者医疗数据集上进行脓毒症预测、出院时间预测实验.实验证明本文方法有效性显著高于同期其他方法:
① 重症监护开放数据集(PhysioNet Challenge)的脓毒症预测实验中,与医疗时序分析领域经典最佳基准模型T-LSTM(SIGKDD)[9]相比,Dr.Deep在精准召回率曲线下面积(area under precision recall curve, AUPRC)指标实现了10.7%的相对性能提升,min(Se,P+)指标实现了6.4% 的相对提升.
② 同济医院开放的新冠肺炎重症监护患者数据集出院时间预测实验中,此方法相比最佳基准模型在均方误差(mean square error, MSE)和平均绝对误差(mean absolute error, MAE)指标上,分别实现了18.2% 和5.4%的性能相对提升.
3)设计并实现了一种基于医疗多变量时序数据分析的人工智能医生在线临床辅助系统:该系统可以展示每一位患者的健康状态动态评估结果、预测依据等.经由医学专家试用系统并查阅医疗文献验证,本文方法抽取的可解释性符合临床经验,解决需求3.
1 电子病历数据分析相关工作
现在已有较多工作将通用时序数据分析方法(以循环神经网络为代表)应用至医疗多变量时间序列数据分析任务,并取得了相较传统模型的较大提升[14].但医疗领域,多变量时间序列数据分析存在特征记录不规则、变化模式复杂、样本少、可解释性要求高等特点,传统模型往往应用效果不佳、决策支持效果差,以至于深度学习模型落地困难,难以切实在实际应用场景发挥模型原本价值.
现有医疗多变量时序数据分析工作中所输出的可解释性主要集中在使用注意力机制输出时间步层面的重要性.例如,Lee等人[11]提出了一种基于医学上下文注意力机制(medical context attention, MCA)的循环神经网络,捕捉时序重要性;Ma等人[14]使用双向循环网络结构和注意机制来捕捉不同访问之间的关系以进行预测;Song等人[15]借鉴了自然语言处理领域中的自注意力机制(self-attention),取代了传统的时间序列处理常用的如长短时记忆网络、门控循环网络等方法,抓取各个时间步下就诊信息的相互关联.此类方法忽略了对特征重要性的分析,而针对不同患者个性化判别的特征重要性才是医生了解模型判断依据并制定精准治疗方案的关键信息.
一些研究因此进一步探讨了医学特征层面的可解释性.如Bai等人[16]提出不同医疗特征对隐层表示应该有不同程度的影响,因此利自注意力机制,学习单次就诊下不同输入特征对应的注意力权重,此类方法能识别疾病编码的重要性,但无法分析实验室检验检查特征重要性.考虑到复杂的深度学习模型拟合数据的能力、表示学习的能力强、性能好,但可能可解释性差,部分研究工作为提升模型可解释性,降低深度学习模型复杂度或与决策树等高可解释性模型结合;Yan等人[17]使用决策树方法对新冠肺炎重症患者进行死亡预测;Choi等人[18]提出了双层注意力模型RETAIN,利用2个循环神经网络分别学习各次就诊的重要性和单次就诊下每个特征的重要性.其用特征注意力加权来刻画每次就诊的隐层表示,再将每次就诊的隐层表示用时间注意力加权求和记得到一个患者的隐层表示,最终对学得的患者表示使用全连接层进行相应的预测.亦有其他工作[19-20]指出,此类简化方法往往仅使用决策树或线性层学习的隐层表示,难以抽取复杂时序变化模式,特征提取不够充分,表示学习能力降低而性能受损,可能陷入“性能/可解释性的选择困局”,难以在保证高性能的同时辅助医生有针对性地制定个性化治疗方案.
此外,较少研究从医疗特征关联关系方面分析模型的可解释性.Bai等人[16]引入自注意力机制学习不同疾病编码之间的关联,但其仅适用于疾病编码特征,不适用于实验室检验检查特征,且仅学习单次就诊下的关联,未捕捉到全局视角.现有工作仍然不能捕捉特征记录之间的相互依赖关系.
因此,尽管当前深度学习方案相关工作在医疗多变量时序数据分析、健康状态预测任务上已达到较高准确率,但距离满足临床需求落地应用仍需要针对患者情况学习其特征健康上下文关系、个性化利用特征编码构成患者最终健康表示,并输出可解释性供医生参考.
2 重症监护患者预后问题定义
医疗多变量时序数据中涉及病人健康相关的多个因素,包括生理指标因素(如血糖、血压、体重等)、治疗措施因素(如服用某种药品、采取某种处置等)和疾病诊断因素(如被诊断患有某种疾病等).在数据分析中,这些因素被抽象为一组“变量”.由于病人通常在医院接受多次多种检查或治疗,因此上述变量在不同时间的取值形成了多变量时间序列数据,本文称其为“医疗多变量时间序列数据”.在这里,时间是一个抽象的概念,通常表示为就诊检查时步(timestep).在一个以就诊为单位的医疗数据序列中,序列中第1次就诊所得到的检验检查结果就是第1个时步.
假设病人的动态临床记录由T次就诊记录组成.因此,这样的临床序列可以被表述为一个纵向的病人矩阵R,其中一个维度代表医疗特征,另一个维度表示访问时间戳:
多个患者的不同就诊、不同特征数据共同构成一个稀疏的张量.在真实临床应用中,电子病历数据除时序数据R之外,一般还需要一并分析静态基线信息,包含人口统计信息(如性别、年龄等)和原发疾病(如慢性肾小球肾炎、慢性间质性肾炎等),记为base.
医疗预测的目标是使用EMR数据(即R和base)来预测病人在治疗过程中是否会出现目标临床结果,表示为y.问题被表述为分类或回归任务,即:
3 健康状态可解释评估方法
在绝大多数基于深度学习的多变量医疗时序数据分析工作中,患者的健康状态表示学习主要基于循环神经网络来进行.健康变化过程被类比为自然语言中的句子,患者疾病发展路径建模类比于学习自然语言模型.患者随着就诊逐渐产生多次医疗记录,如同自然语言中的一句话中的每个单词;而患者的多项生理检查指标特征变量,则视作一个单词的编码中的多个隐层单元的取值.学习患者的健康状态并做出健康预测,类比于学习一句话的表示并预测这句话的含义.
文献[6]假设,相比自然语言处理任务中提取时序关系,在综合患者的医疗多变量时序数据以学习患者健康编码并评估病情发展时,更重要的应是提取特征关系,即对特征进行全局编码随后对特征关联进行学习.因此其未采用绝大多数已有相关工作的时序压缩编码方案,而是提出了多特征通道编码框架.多特征通道结构适合从患者健康完整序列的全局视角显式捕捉特征之间的关联,并筛选最重要的特征.在多通道编码部分使用循环神经网络编码动态特征序列的同时,使用多层感知机隐层神经网络将静态信息base做映射,得到一个更加稠密中间的表示输入到网络之中.该表示为后续网络使用自注意力机制学习静态信息与动态特征关联做准备,与其他动态特征序列编码结果即将按位叠加,因此亦属于同一隐层特征空间.
针对学习特征关联关系的预测需求,提出去相关自注意力机制.每个特征的隐层表示通过关注所有其他特征的隐层状态来计算注意力权重,让每个特征都和其他所有特征产生线性组合的交互,即每个特征都能“全局”地观察其他特征和自身的关系,并通过加权方式结合不同特征信息,重新学习结合医疗上下文的个性化编码.这样不受采样频率、记录稀疏度的限制,建立任意2个特征序列之间直接关联,关联信息丢失更少.例如当模型重编码“舒张压”这一生理指标的隐层表示时,会和舒张压更相关的生理指标(如收缩压)产生更多关联,从而将“收缩压”这一指标的信息也纳入到“舒张压”中来.此外,本文额外结合静态基线信息捕捉动态特征之间的相互依赖关系.例如,当模型处理特征“血糖”时,自注意机制可能会使其与静态基线信息中的“糖尿病诊断”相关联.
在前期工作多特征通道表示学习基础上,本文指出,根据传统多头自注意力机制工作(multi-head self-attention)[21]在实践中的经验,多个注意力头之间很可能会学到近似的相关知识,造成编码冗余,泛用性下降.具体来说,由于多头自注意机制往往倾向于捕捉最有判别力的特征,学习到的医疗上下文信息将是有限的.基于相关工作在防止过拟合方面的研究[22-24],本文认为在数据量少且缺乏额外约束的情况下,特征编码器被训练为在训练数据上协同工作,即特征编码器仅在几个其他特定编码器的协同环境中才能发挥作用,存在可能导致过拟合的协同适应效应,更容易发生过拟合现象.因此本文针对性提出了多头去相关自注意力提升策略,抑制部分注意头对重要特征的关注,迫使网络去寻找其他上下文关联信息.以迫使各个注意头广泛差异化关注特征.
同时,文献[6]仅依赖静态信息在最终预测层发起查询(query),因此在缺少静态信息或其所包含信息对待预测任务目标意义不足时可能面临无法合理分配特征重要性的问题.本文进一步引入了压缩激励机制以学习用于发起查询的隐层编码,并通过针对不同患者学习每个特征的重要性权重,提供特征级别的预测可解释性.
如图1所示,本文方法Dr.Deep具体分为3个模块:
1)多通道时序特征抽取表示学习(multi-channel time series feature extraction);
2)基于自注意力的健康上下文关联学习方法(self-attention-based health context learning)与去相关增强策略(boosted strategy);
3)基于压缩激励机制的特征重要性重标定(SEBlock-based adaptive feature recalibration).
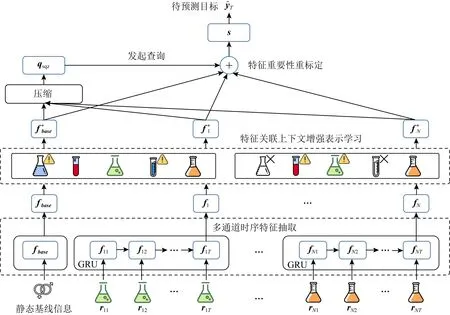
Fig.1 Dr.Deep framework
3.1 多通道时序特征抽取表示学习
Dr.Deep使用了多通道的门控循环单元(gated recurrent unit, GRU)分别压缩表示不同特征的时序信息,读入数据并将每个特征时序各自编码为同一特征空间的等长隐层向量.将模型的特征序列输入统一记为r.GRU会依次重复接收就诊时步t下的原始特征rt,并结合历史就诊数据编码ht-1,将数据映射为抽象的隐层空间编码结果ht.循环神经网络通过“更新”(zt)和“重置”(et)操作来控制历史编码结果对最新就诊时步的影响.
et=σ(Ue·rt+We·ht-1+be),
zt=σ(Uz·rt+Wz·ht-1+bz),

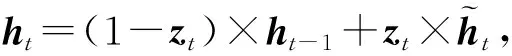
其中,σ和tanh分别指sigmoid和tanh非线性激活函数,×和+分别指矩阵的元素乘法和矩阵加法.随后通过多通道GRU分别嵌入每个特征的时间序列:
hn,1,hn,2,…,hn,T=GRUn(rn,1,rn,2,…,rn,T),
其中,特征n的时间序列表示为rn,:=(rn,1,rn,2,…,rn,T)∈T.至此,已经针对不同特征序列分别学习获得其时序编码结果,暂不考虑其时序不规则性,取最后一个时间步的表示作为该特征的最终表示,则:
fn=hn,T,n=1,2,…,N.
此外,将基线数据线性映射至与特征序列编码同样的隐层维度,为后续综合学习静态特征动态特征之间的关联并获得最终健康表示做好准备:
fbase=Wbase·base,
其中,Wbase是待学习参数矩阵.为了便于记述,在本文的公式中忽略了偏置项.至此,患者的所有变长时序特征数据与静态信息均已被编码至矩阵:
F=(f1,f2,…,fN,fbase).
3.2 基于自注意力的健康上下文关联学习
Dr.Deep通过自注意力机制的方式捕捉特征间相互关联,从而全局捕捉患者的健康上下文语义信息,并以此获得每个特征新的表示.该模块结合上下文信息重新编码语义后的特征向量,输入前馈神经网络中得到最终患者健康表示.具体而言,自注意力机制[21]中原始输入或前一层编码器的输出,经过线性变化,将特征矩阵F映射到3个不同的子空间中,分别形成3个新的编码矩阵Q,K,V.当处理某个特征时,将当前特征作为查询发起(query),去和病历中所有特征(包含该特征本身)的相应向量(key)去匹配,即Q与K之间进行点乘计算得到不同特征之间相关度的度量,随后使用softmax函数将上述计算结果进行归一化,每个值(value)项都获得相对应的权重以进行后续加权求和.注意力权重矩阵A计算:
Q=F·WQ,
K=F·WK,
V=F·WV,
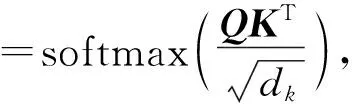

F*=AVWO,
其中,WO为待训练的参数矩阵.
同时,自注意力机制可进一步拓展为多头(multi-head)注意力机制[21],即多个自注意结构的组合,同时学习不同的Q,K,V表示每个注意头学习到在不同特征空间中的语义,因此它们学习到的注意力侧重点可能均有不同,进而可以使模型丰富学得特征的表示空间、捕捉更丰富信息.首先对于每个自注意头i:
其展开式为
dk为Ki的尺寸.矩阵Ai表示头i所学到的对特征间的相关程度.headi为该自注意头所学习到的融合特征相关信息的后的编码,其接收上文原始特征线性映射后得到的Vi作为输入:
headi=AiVi,
其展开式为
随后结合全部注意头的计算结果:
U=(u1,u2,…,uN)T=
(head0⊕head1⊕…⊕headm)WO,
其中,⊕是按行连接算子,WO为待训练的参数矩阵,U为数据F通过学习信息关联得到的重构编码.利用单层映射层对ui进行编码,形成结合健康上下文后学得的特征表示矩阵:
3.3 特征关联表示学习去相关增强策略
在表示学习模块基础上,本节进一步提出多头去相关自注意力提升策略,在训练过程中控制网络中神经元之间的关联减少冗余表示,即训练自注意头对拥有不同特征记录情况的样本可以有效工作,不能依赖于其他特征的存在,防止对训练数据进行复杂的协同适应,鼓励头之间的多样性,并全面地提取患者健康状况.Dr.Deep抑制多头机制中特别具有判别性特征的注意力,自我注意模块被迫寻找其他的信息特征,每个自注意头的不同神经元被控制于有倾向性的学习不同信息、捕捉不同的特征相关性规律,实现隐层单元级别的表示学习控制.使得不同的头形成不同的隐藏空间,从不同的角度捕捉病人的信息,全面抽取患者健康上下文.
具体来说,在执行多头自我注意机制时,鼓励后一个头去关注与前一个头不同的特征.头i中丢弃第j个特征的概率计算为
pi,j=γ×softmax(xi,j×ξ),
其中,γ是超参,表示特征j在headi的丢弃率.ξ是一个放缩变量,控制了当前头的注意力应该被压制的程度.xi,j为在headi前的所有注意力权重的标准化累积和,对于j,它被计算为
其中:
其中,k代表着第k个注意力头.前面的头对特定的特征给予的注意力权重越多,当前的头对这个特征就会倾向于分配较少的注意力权重.网络被迫寻找病人的其他相关特征.最后生成压制向量压制headi里的特征:
M(i,j)=1-rc,
其中,rc~Bernoulli(pi,j).
压制向量M(i,j)与headi中的注意力权重相乘,来压制先前注意力头中过多关注的具有判别性的特征.在通过以上多头注意力机制得到每一时间步的表示之后,使用全连接网络子层:
FeedForward(rn)=
max(0,un·W1+b1)·W2+b2.
在其中每两个子层之间使用残差连接[25]和层标准化[26],得到的输出被表示为
3.4 特征重要性重标定与患者健康编码整合
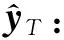
4 真实世界重症监护数据集实验
本文在美国医疗机构重症监护患者数据集(PhysioNet)、中国同济医院新冠肺炎重症患者数据集(COVID-19)上分别进行了院内死亡预测脓毒症预测、出院时间预测实验,患者信息统计如表1所示.所进行实验的源代码、数据集的统计数据和案例研究均已上传GitHub代码库(1)https://github.com/Accountable-Machine-Intelligence/Dr.Deep.
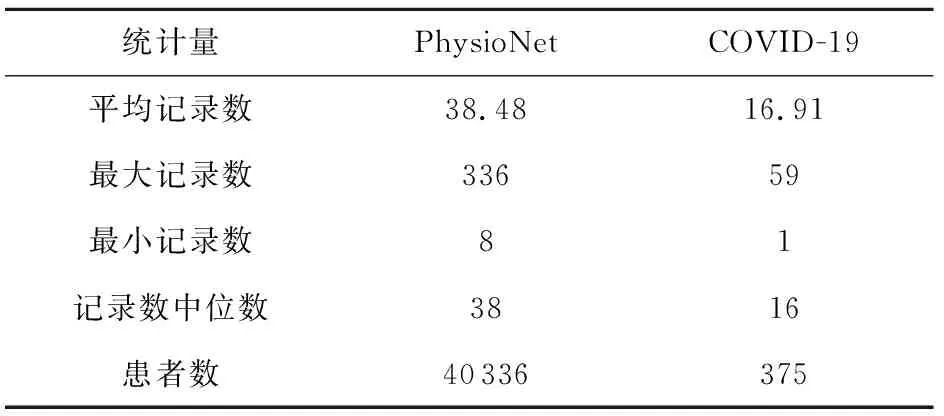
Table 1 Basic Statistics of Patient Visits in Datasets
4.1 数据集介绍
4.1.1 重症监护患者-美国PhysioNet ICU
美国PhysioNet ICU预测赛数据集是一个公开的医疗数据集,其患者收集自2家美国的医疗机构:Beth Israel Deaconess Medical Center和Emory University Hospital.数据集中累计40 336名患者,每个患者拥有33个动态医疗特征,总计1 552 210条动态医疗记录.该数据集的预测目标为在一定时间窗口内诊断为脓毒症疾病的概率.在这40 336名患者中,共有2 932名患者最终患上了脓毒症,剩余的37 404名患者则为负样本.详细统计数据见数据集发布方原文[27].在该数据集中预测患者最终是否会被诊断为脓毒症.
4.1.2 新冠肺炎重症患者—中国同济医院
中国同济医院新冠肺炎重症患者数据集[17]为在2020-01-10—2020-02-18期间收集的同济医院新冠肺炎重症患者数据.患者平均年龄58.8岁,其中男性59.7岁.375例患者中,201例从COVID-19中康复出院,174例不幸死亡.相关记录天数分布统计等如图2、表2所示.
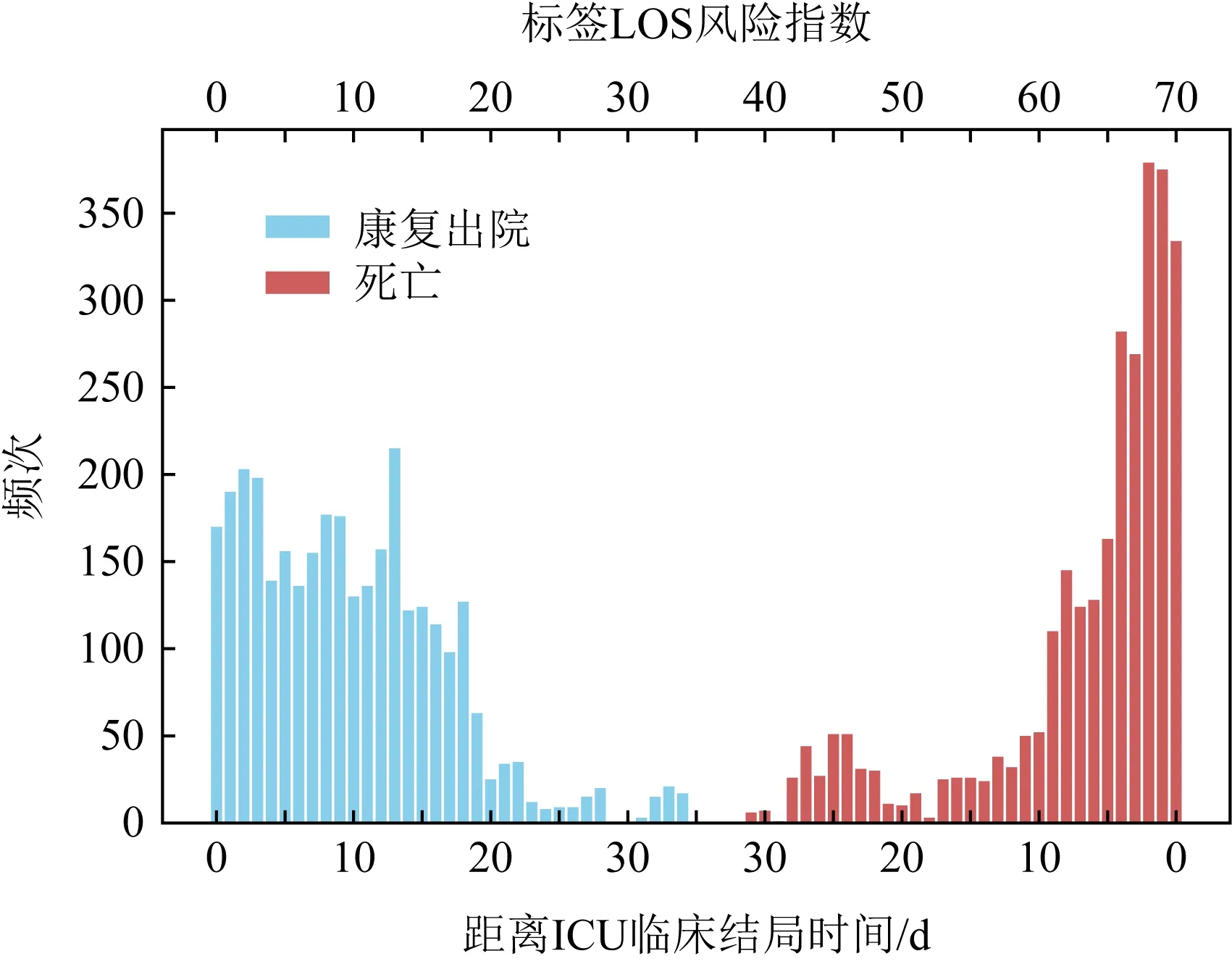
Fig.2 Days to outcome of patients’ records in COVID-19 dataset
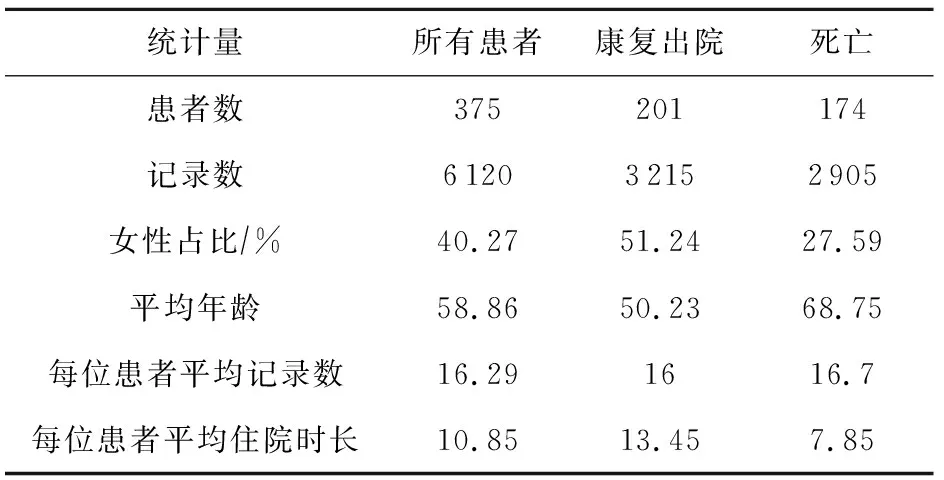
Table 2 Statistics of the COVID-19 Dataset
在疫情爆发期,大量新冠肺炎患者挤兑医疗资源,尤其是重症监护病房(ICU)不堪重负,医疗资源运转效率降低.而其中部分重症患者亟待抢救,部分轻症患者已好转.如能有效预测不同患者的出院时间,将有助于提高医疗资源利用效率.如图3所示,住院时间相同但结局不同(最终从ICU中康复出院或死亡)的患者在健康状况上存在显著差异.对于几天内出院的患者,他们的健康状况应该比其他患者更为健康,尤其是即将死亡的患者.则以剩余住院天数t作为存活患者记录的出院时间标签,以LIMIT-t作为死亡患者的标签.如根据新冠肺炎重症监护患者数据集统计[17],COVID-19重症患者大多在35 d内出院.因此将LIMIT的值设置为2×35=70.
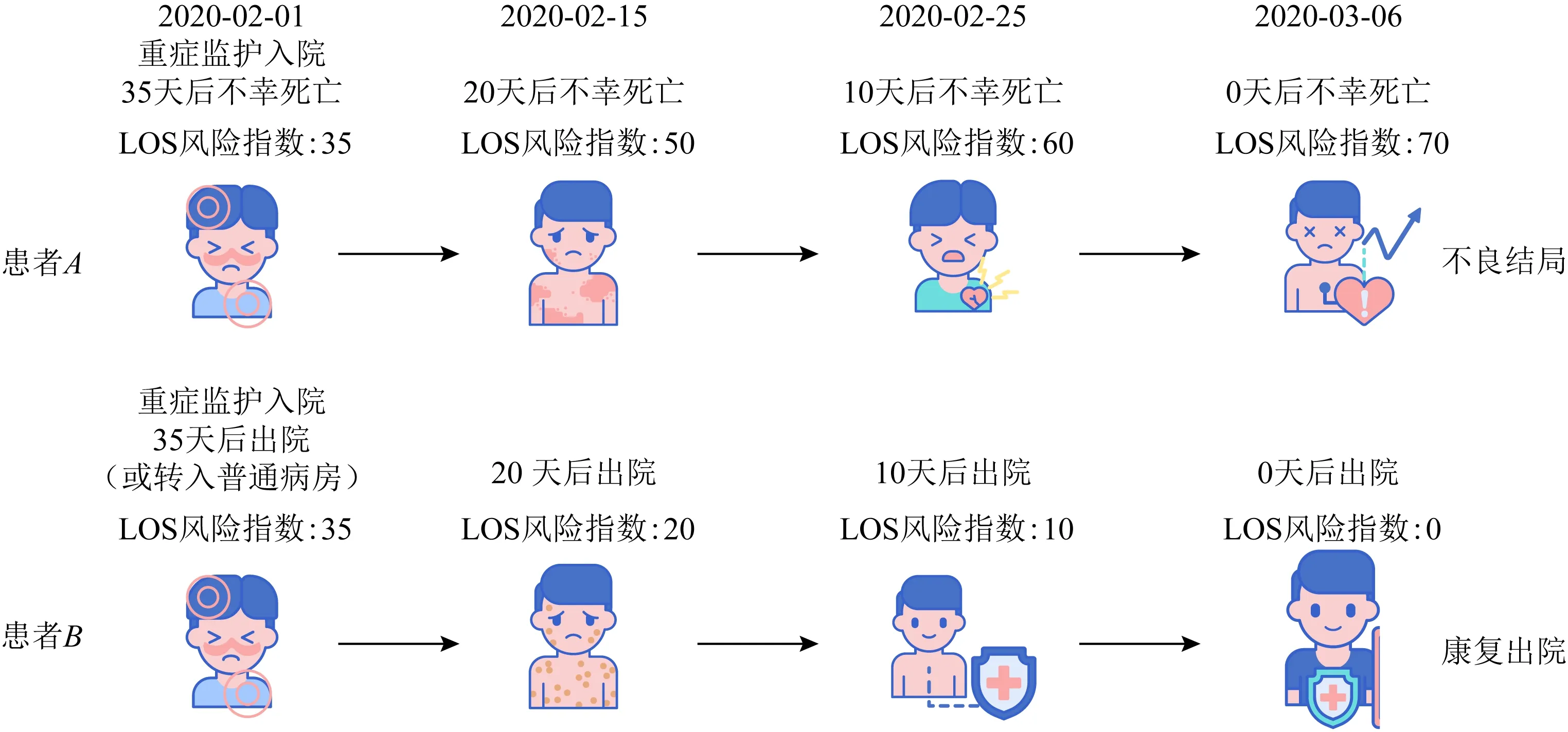
Fig.3 ICU Length-of-stay problem definition
高风险评分的患者面临着很高的不良结局风险,需要紧急治疗.相反,低风险分数的人健康状况相对稳定.
4.2 实验设置
4.2.1 数据集划分
本文按照2种方式来划分实验数据集:
1)在数据量较大(约40 000位患者)的PhysioNet ICU数据集上,按照8∶1∶1的比例将数据划分为训练集、验证集和测试集,在验证集上损失函数最小的模型将被保存用于测试.
2)在数据量较小的COVID-19(约300位患者)数据集上,使用十折交叉验证进行实验.
4.2.2 评估指标
本文使用以下分类与回归经典评估指标进行实验结果分析:
对于二分类任务,本文使用受试者工作特征(receiver operation characteristic, ROC)曲线下面积(area under the ROC curve, AUROC),精确召回曲线(area under the precision-recall curve, AUPRC)下的面积以及精度和灵敏度最小值min(Se,P+)评估对患者健康风险的预测性能.尤其当处理高度不平衡和偏斜的数据集时,AUPRC是提供最多信息和最主要的评估指标[28-29].
对于回归任务,本文使用平均平方误差(mean square error, MSE)、平均绝对值误差(mean absolute error, MAE)作为评估指标.
4.2.3 实施细节
本文在一台配置了CPU:Intel Xeon E5-2630、256 GB RAM和GPU:Nvidia Titan V的计算机上使用Pytorch 1.5.0进行模型的训练.为了防止过拟合,本文在所有RNN层中使用了dropout(dropout率为0.3).对于本文模型中的特征维度的注意力机制和SEBlock模块,局部和历史特征的压缩比r=4.本文对模型中所有权重使用了l1和l2正则化,正则化系数为0.001.本文使用了Adam优化方法[30]以及256名患者的批量,并将学习率设置为1E-3.本文使用网格搜索(grid search)对本文模型和所有基线模型进行超参选择.我们将Dr.Deep与以下6种基线方法进行了对比评估,这些先进的基线方法均解决同本文相似的医疗预测问题或使用了相似的机制:
1)GRUα是具有注意力机制的GRU.
2)RETAIN(NeurIPS)[18]利用两级注意机制来检测有影响的就诊和重要变量.
3)T-LSTM(SIGKDD)[9]通过启用时间衰减来处理不规则的时间间隔.本文将其修改为监督学习模型.
4)MCA-RNN(ICDM)[11]利用从条件变量自编码器生成的个体患者信息来构建基于医学上下文关注的RNN.
5)Transformere(NeurIPS)[21]使用了Trans-former的编码器,在最后一步中,本文将高阶特征扁平化并使用前馈神经网络进行预测.
6)Dr.Deepbasic(AAAI)为拓展前会议版本ConCare模型[6],其使用时间感知机制与注意力机制学习患者时序编码.
4.3 量化结果
4.3.1 真实世界数据集预测实验结果
表3与表4分别为同济医院新冠肺炎重症患者出院时间预测实验结果和PhysioNet重症监护数据集脓毒症预测实验结果,其中括号()内的数字表示Physionet脓毒症预测数据集上进行自助法(bootstrap)测试100次的标准差,以及COVID-19数据集上十折交叉验证的标准差.
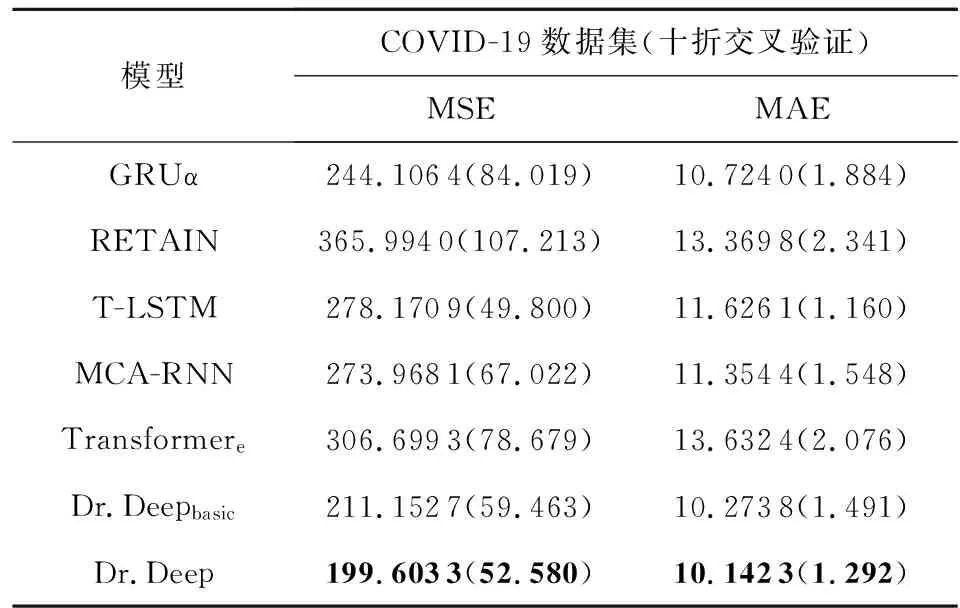
Table 3 Results of the Length-of-Stay Prediction on COVID-19 Dataset
如表3所示,与最佳基准模型相比,Dr.Deep在MSE和MAE方面分别实现了18.2%和5.4%的性能相对提升.COVID-19数据集仅包含400位患者的时间序列数据,表明Dr.Deep在较小的数据集上表现依然良好.本文所提出的模型可以有效地预测住院时间,这将有助于医生合理分配医疗资源,并在许多不堪重负的医疗机构中提高临床效率.
如表4所示,与医疗时序分析领域经典最佳基准模型T-LSTM(SIGKDD)[9]相比,Dr.Deep在AUPRC中指标实现了10.7%的相对性能提升,min(Se,P+)指标实现了6.4% 的相对提升.特征关联表示学习去相关增强策略可以使得AUPRC,AUROC同时进一步提升.
Dr.Deep优于顺序表示学习方法(即GRU,T-LSTM等方法),表明在全局视图中分别学习每个特征编码优于直接顺序学习整个就诊序列的信息.Dr.Deep的性能优于Dr.Deepbasic(本文模型在会议上的ConCare模型),从而验证了特征关联表示学习去相关压制策略的功效,其鼓励多头注意力机制的多样性并提高性能.

Table 4 Results of the Sepsis Prediction on PhysioNet Dataset
尽管RETAIN可以提供可解释性,但在这4个数据集上,其性能都比GRU模型差,与[31]中报告的结果一致.
4.4 重症监护患者健康评估可解释性主观分析
为了确定Dr.Deep的合理性并提取有用的医学知识,本文对PhysioNet数据集上不同患者群组(即有/无败血症)的模型行为进行了实验观察,并计算具有不同结局的患者对每个生物标记物的平均注意权重,在图4中生成特征重要性热力图.
如图4所示,红细胞压积(Hct)和肌酐(Creatinine)等特征在败血症和非败血症队列中均具有很高的关注权重,与患者败血症的发展密切相关.有一些医学文献支持本文的发现.严重败血症和败血性休克处理的国际准则[32]在2012年提到了Hct的重要性.他们建议在出现血流灌注不足的前6 h内保持血细胞比容超过30%[32-33].提示血压可以反映疾病状态,因为败血症发生时患者经常会出现血管舒张和血容量不足,从而导致血压降低.

Fig.4 Importance of biomarkers differentiated by Dr.Deep for sepsis prediction on the PhysioNet dataset
4.5 人工智能医生在线可解释交互系统
本文设计并实现临床辅助系统:小雅医生系统(2)随系统更新迭代,特征重要性分布与案例可视化结果可能会有变动..如图5所示,其输入数据为住院患者或门诊随访患者随时间多次记录的多变量时序数据,以及初次就诊时记录的静态基线数据.该系统综合利用前文表示学习模型,评估患者健康状况,提示不同患者应当重点关注的高危生理指标,对健康状况不佳患者的疾病发展状况进行时刻监视.
以PhysioNet重症监护数据集脓毒症预测任务中11 498患者为例(3)http://47.93.42.104/challenge/11498,本文模型Dr.Deep判断该患者经历了3个不同的脓毒症高风险阶段.针对该患者,模型重点关注体温的变化.尤其是在患者被诊断脓毒症前的最后3次检验检查中,患者的体温从37.33℃升至39.67℃,模型预估的脓毒症风险从12.52%升至67.66%.该案例过程表明Dr.Deep捕捉到了患者体温的上升过程,并将其作为一种预示着脓毒症的不良状态予以高度关注,并建议医生对重症监护患者、潜在脓毒症高危人群进行及时、密集的体温监测管理.研究[34-35]表明体温是严重发炎或感染的标准,并且严重脓毒症患者经常出现体温异常.
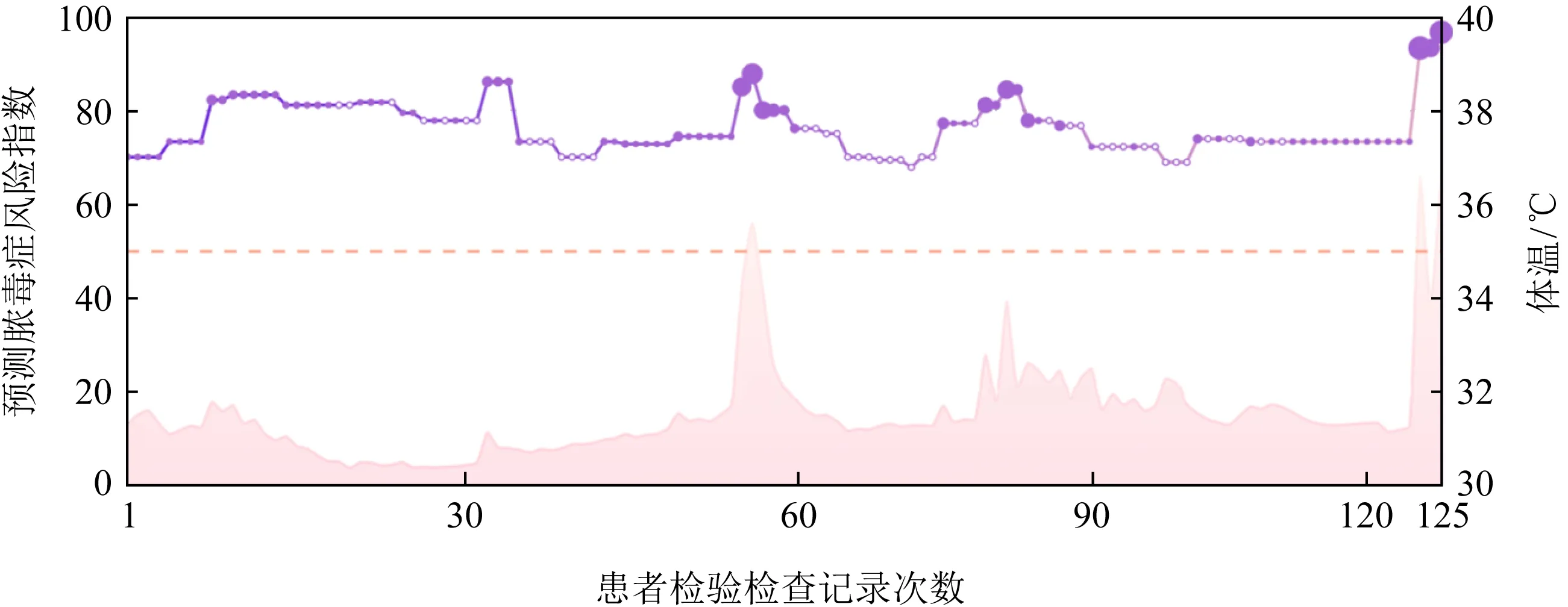
Fig.5 Sepsis case study
5 结 论
针对结构化多变量时序电子病历数据分析工作当中个性化表示学习不足、可解释性缺乏的问题,本文提出了基于特征上下文表示学习的患者健康状态可解释评估方法Dr.Deep.该方法针对不同患者情况自适应捕捉患者医疗特征上下文并利用去相关策略增强表示学习效果,同时基于压缩激励机制进行特征重要性重标定以输出可解释性因素.在公开数据集PhysioNet重症监护患者脓毒症预测与同济医院COVID-19重症患者出院时间预测任务中,Dr.Deep性能均显著超越最佳基准方法.本文最终设计并实现了人工智能医生在线交互系统,可视化患者的疾病发展路径及模型所动态分析的特征重要性供医学专家参考.
作者贡献声明:马连韬提出算法、撰写文章、设计可视化系统;张超贺进行算法设计实现和实验验证;焦贤锋对数据预处理、实现部署可视化系统、进行实验验证;王亚沙修改了深度学习模型;唐雯负责医学知识引入模型设计、医学知识挖掘、案例分析;赵俊峰对文章进行修改、提供了实验室计算资源.其中,马连韬和张超贺为共同第一作者,王亚沙和唐雯为共同通信作者.
