面向无人驾驶时空同步约束制导的安全强化学习
2021-12-14王金永黄志球杨德艳XiaoweiHuang华高洋
王金永 黄志球 杨德艳 Xiaowei Huang 祝 义 华高洋
1(南京航空航天大学计算机科学与技术学院 南京 211106) 2(高安全系统的软件开发与验证技术工信部重点实验室(南京航空航天大学) 南京 211106) 3(江苏师范大学计算机科学与技术学院 江苏徐州 221116) 4(利物浦大学计算机科学系 英国利物浦 L69 3BX)
无人驾驶系统可以看作是自车车辆和环境在时间空间上的转移,其安全性一直是阻碍无人驾驶普及的首要问题.系统安全性(safety)可定义为坏的事情永远不要发生,无人驾驶安全指的是车辆之间和车辆与周围的环境之间不要发生碰撞.无人驾驶决策模块需要根据动态的时钟和空间信息做出正确安全的决策,提供安全的时空道路通行权(right-of-way),避免在某一时刻自车车辆与周围环境车辆的空间重叠.安全攸关的无人驾驶车辆处在复杂的时空运动轨迹中,在面对没有训练过的未知不确定场景时,系统设计者不仅需要采用强化学习(reinforce-ment learning, RL)的方法来训练车辆,使得车辆获得最优的策略和累计奖励,而且更加需要特定领域的形式化规约方法,为强化学习提供安全约束和保障.
无人驾驶决策的方法可以分为2类:1)基于规则(rule-based)的方法,比如有限状态机(finite state machine);2)数据驱动(data-driven)的方法,比如机器学习(machine learning)的方法.基于规则的决策系统可以根据事先定义好的规则输出事先规定好的动作,从而实现系统的安全与可解释性[1-4].尽管基于规则的方法可以为安全的系统操作提供保障,但是只有复杂的现实环境与待验证的模型相匹配才可以满足系统设计的需要[5].对于复杂的无人驾驶交通场景,系统状态转换较多,决策系统不能理解周围复杂的交通环境,而且对于未识别的系统状态无法给出较好的决策行为[6].基于数据驱动的方法,通过与环境交互大量的学习训练,可以理解学习周围的环境.对于深度强化学习来说,学习的过程受奖励函数的指导,产生从观测输入到动作输出的策略.但是基于学习的决策方法,较多依赖数据和黑盒训练,缺少学习过程的安全约束和决策结果的可解释性[7-12].因此本文主要关注无人驾驶系统设计与运行部署阶段的安全性与奖励函数设置的可解释性,具体研究无人驾驶车辆在时间空间同步约束系统中不发生时空重叠(no spatio-clock overlaps)以及形式化规约制导的安全强化学习方法(formal specification guided safeRL).
近期的研究工作显示无人驾驶系统已经广泛采用时间空间约束的形式化规约和强化学习相关技术.在无人驾驶领域空间建模方面,协同无人驾驶系统安全性需要采用专用的领域特定的空间逻辑来描述车辆的物理空间位置和逻辑空间关系[13-14].无人驾驶系统包含连续状态变化和离散状态迁移,无人车变道控制器可以用来保证空间位置不发生重叠[15-16].在无人驾驶领域时间建模方面,时间自动机被用来建模通信无人驾驶车辆之间的行为[17],时钟约束规约语言(clock constraint specification language, CCSL)被用来建模系统的安全约束[18-19].时空同步约束系统中的事件触发不仅受严格的时序和物理时间的约束,同时还要逻辑和物理空间关系的约束[20-21].无人驾驶决策系统的核心问题是如何安全高效地分配路权来解决可能的时空重叠.无人驾驶行为需要在满足时间约束的同时满足空间关系的约束,反之亦然,这种方法可以保证在某一时刻和空间位置,只允许最多一辆车存在.时空安全攸关的事件包括安全卫士和不变式规约,需要满足逻辑时序和物理时钟关系,同时需要满足逻辑空间关系和物理空间位置.然而在无人驾驶领域,现有的时空同步约束规约方法和验证技术是不充分的.
无人驾驶系统是一类典型的信息物理系统(cyber-physical systems, CPS),高保真的物理模型开发成本很高并且难以验证.随着计算能力的提高和可用交通数据的增加,越来越多的数据驱动的机器学习技术可以用来解决无人系统的智能决策.基于强化学习的无人驾驶基本思想是智能体(agent)直接与环境(environment)之间不断试错,通过不断的交互,从环境中寻求最优策略(optimal policy),智能体会接收到环境发来的奖励(reward),强化学习的目标就是通过改进策略以期获得最大化累计奖励(maximize cumulative future rewards)[22-23].安全强化学习(safeRL)是指在学习训练和执行过程中,学习最优策略的过程需要满足严格的形式化安全约束[24-25].目前强化学习多数应用在模拟环境中,没有大规模被应用在实车训练和实践中,主要是用于2个原因:1)由于强化学习的状态空间和动作空间输入来自黑盒的卷积神经网络和全连接神经网络,缺乏可解释性成为深度强化学习部署到现实系统的主要障碍之一;2)由于面对新的没有训练过的交通场景,强化学习不能为安全攸关的无人驾驶系统提供严格的安全约束和负责任的规则约束.
针对上述面向无人驾驶安全的智能决策方法研究现状和存在的研究问题,本文主要关注无人驾驶领域专用的时空同步约束规约语言和时空同步行为描述自动机,并将形式化时空同步安全约束的强化学习用于无人驾驶决策模块,结合时空安全约束的强化学习来增强系统的安全性.主要研究贡献有5个方面:
1)给出了时空同步约束系统的架构,并给出了无人驾驶领域相关的时空同步约束安全域和交通快照的定义;
2)提出了面向无人驾驶领域的时空同步约束规约语言(spatio-clock synchronous constraint speci-fication language, SCSL),该高层抽象规约语言可以处理时空同步约束的安全卫士条件和不变式,并且提出了强化学习奖励函数设置可解释性的方法;
3)设计了无人驾驶领域的时空同步约束自动机(domain-specific spatio-clock synchronous constraint automata),系统设计者可以用该自动机描述无人驾驶行为和状态-动作空间迁移系统,这种方法为无人驾驶系统与环境之间的正确交互提供了安全保障和逻辑基础,为强化学习状态行为策略的生成提供了安全保障;
4)提出了安全强化学习的方法框架,定义了时空同步约束奖励状态机,描述了非Markov性质的奖励函数结构,提供了任务目标和奖励函数之间的映射关系,指导非Markov性质奖励函数的设置;
5)设计了无人驾驶汽车在高速公路变道超车的案例,在无人驾驶仿真环境SUMO中模拟实验展示本文所提方法的有效性.
1 研究基础
1.1 面向无人驾驶系统的强化学习架构
无人驾驶系统(autonomous driving systems)相当于强化学习系统中的智能体,集成了感知模块(perception module)、决策模块(decision-making module)、控制模块(control module)等智能功能,其中决策模块综合环境感知信息和自车(ego vehicle)信息,经过多次训练,利用强化学习可以实现模仿人类考驾照的类似人类驾驶行为,如图1所示.环境感知模块的主要功能是通过感知器和车辆通信获取强化学习的状态空间和动作空间输入信息,感知器主要包括传感器、激光、雷达和摄像机等,车辆通信主要包括车与车(vehicle to vehicle, V2V)、车辆与道路基础设施(vehicle to infrastructure, V2I)以及全球定位系统(global position system, GPS)等.决策模块是无人驾驶系统的软件模块,该模块提取出软件模块的输入信息,也就是高层抽象的场景理解信息,智能体通过形式化约束制导的安全强化学习,输出符合任务要求的最优策略;智能体软件模块经过学习与函数映射关系,输出可执行的行为决策信息给智能体执行模块,动作控制信息包括纵向运动的加速和减速等规划动作,以变道、超车、转向等横向运动规划信息.智能体的决策能力是实现车辆全自动化的基本要素,目前大量的研究采用强化学习来实施无人自主决策[26-29],综合周围交通环境和自车信息,产生安全通明安全的驾驶行为.在无人驾驶应用中,无人车做动作或者做决策,强化学习中的智能体就是无人车;而环境是与无人车交互的对象,无人车所处的真实交通物理世界就是环境,包括交互过程中的道路信息、交通标志、交通规则、驾驶经验等规则和推理机制.动作空间是决策模块输出给执行模块的行为决策信息,奖励表示交通环境对智能体基于当前状态产生动作的打分,需要系统设计人员设计奖励函数,本文主要针对如何获得非Markov性质的安全可解释奖励函数的设置展开研究.
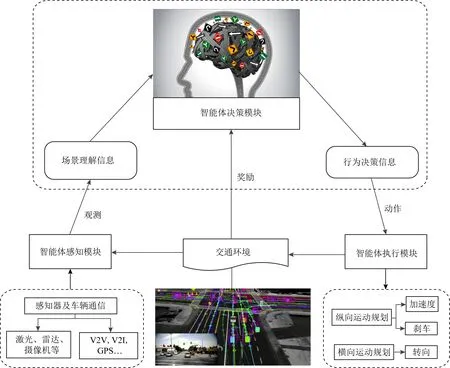
Fig.1 The RL architecture for autonomous driving systems
1.2 双重深度Q学习网络
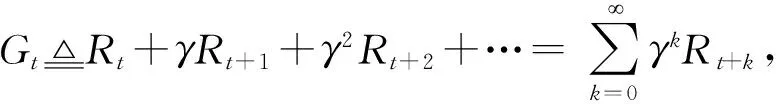
贝尔曼方程式(1)和式(2)表示状态价值函数和动作价值函数之间的关系,也称为贝尔曼期望方程(Bellman expectation equations):
(1)
Qπ(st,at)=R(st,at)+
(2)
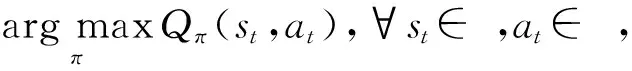
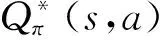

(3)
训练双重深度Q学习网络(double deep Q-learning network, DDQN)常用的算法是时序差分算法(tem-poral difference, TD).假设有一个模型Q(s,a;w),w是模型训练的参数,给定一个四元组(st,at,rt,st+1),可推导出折扣回报为Gt=Rt+γGt+1,根据式(3),当智能体执行动作at后,环境通过状态转移概率pr(st+1|st,at)可以计算出下一时刻的新状态st+1,而第t时刻的奖励最多只依赖于随机变量St,At,St+1,现在已经观测到了st,at,st+1,则可得变量Rt的观测值,记作rt,接着可以对期望做蒙特卡洛近似,可得:
(4)
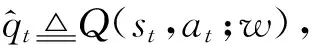
损失函数关于参数w的梯度为

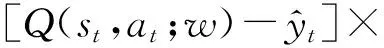
(5)

算法1.DDQN求解最优动作价值算法.
① 初始化动作价值函数Qi(s,a;wi),
i∈{0,1};
② for eachepisode
/*每个回合时序差分学习*/
③ 状态st和动作at采样,进行时序差分
更新;
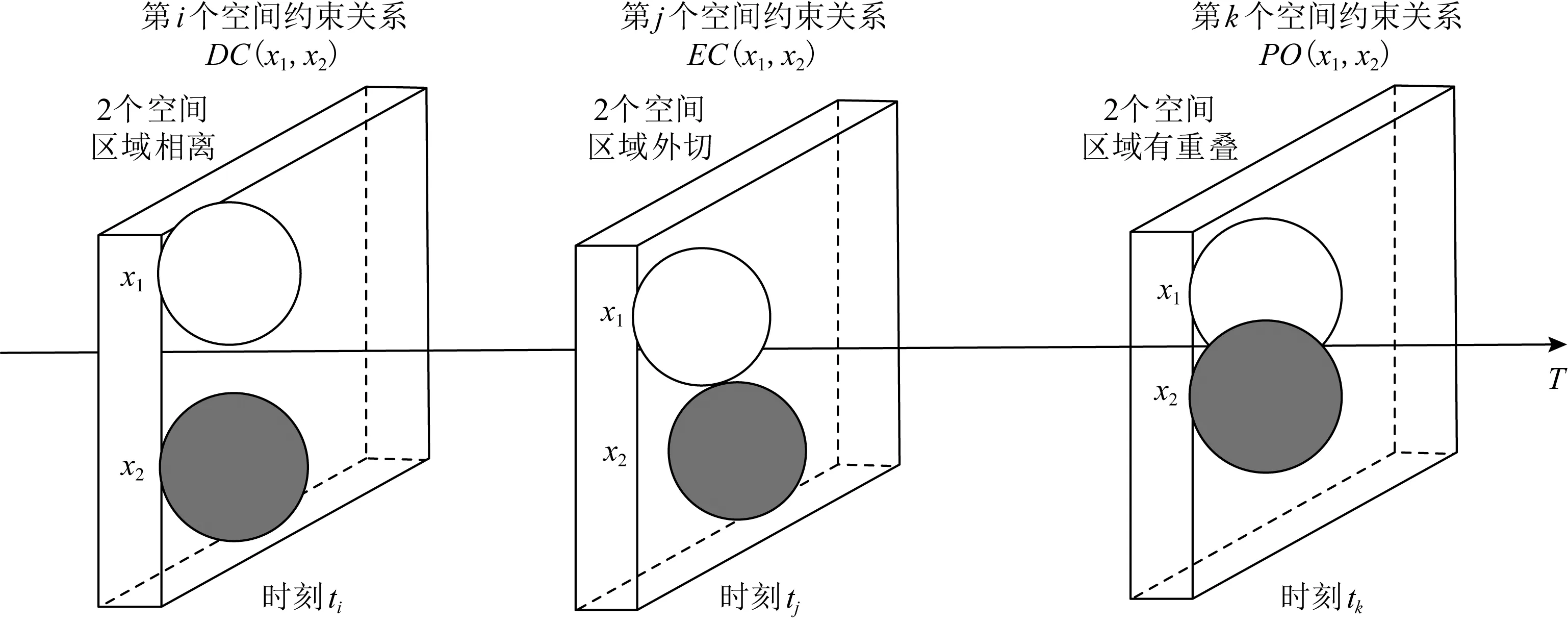
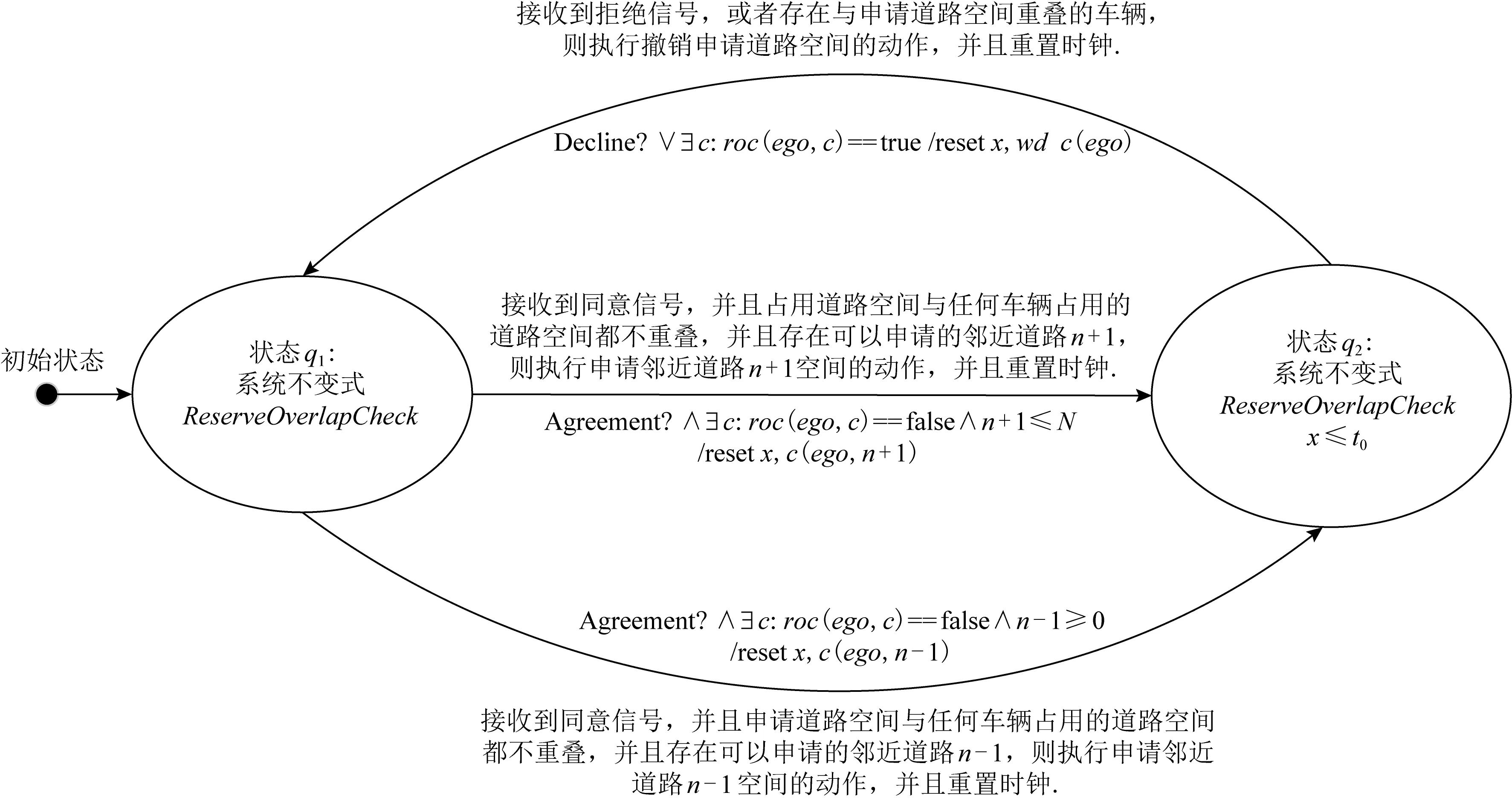
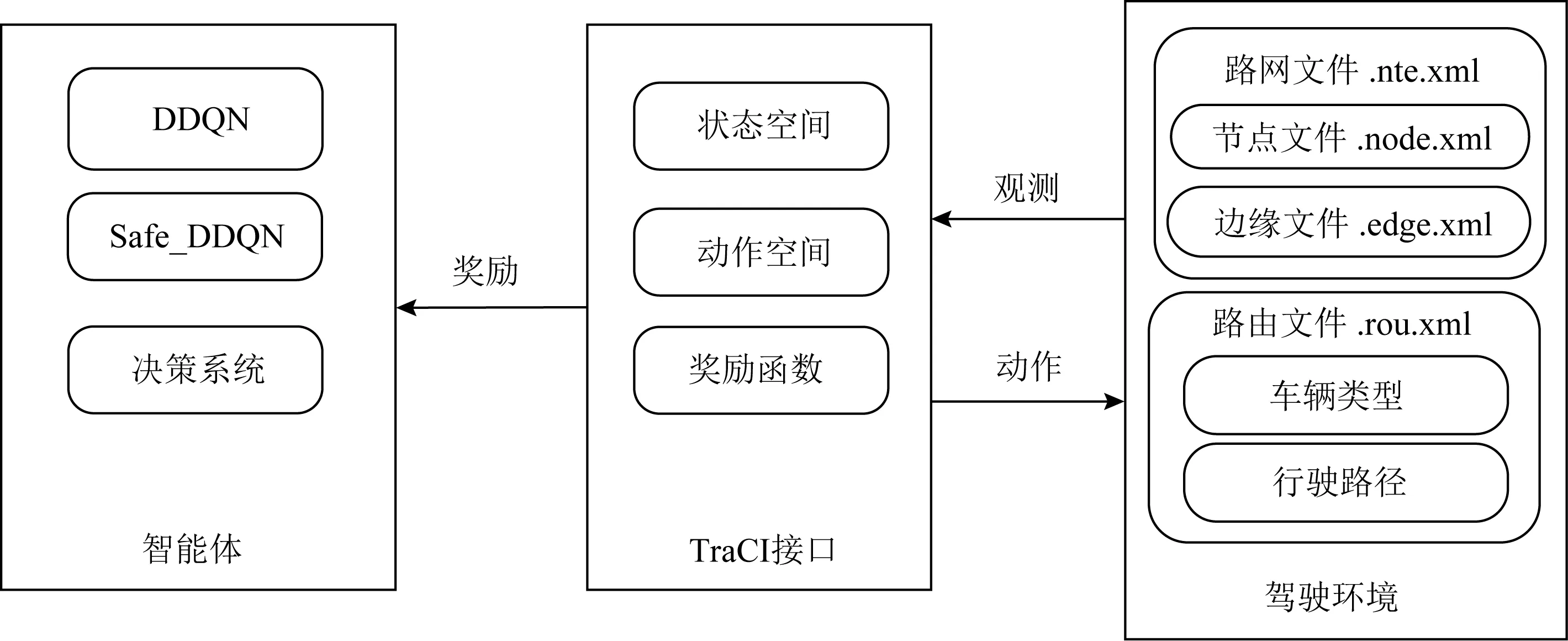
④ while(episode ⑤ 选择最优动作a*,a*= ⑥ 进入到下一个状态st+1并且返回奖励rt; a*;w1); ⑧ 计算TD-error,δt=Q0(st,at;w0)- (rt+γQ1(st+1,a*;w1)); ⑨ 更新DDQN参数w0和w1; 时钟约束规约语言是基于时钟和时钟约束的形式化规约语言,时钟表示一个信号在每个离散时间点的触发状态;时钟约束描述信号时钟之间的逻辑关系.下面给出逻辑时钟、时钟调度和时钟历史的相关定义[30]. 定义2.时钟调度.一个时钟调度σ反映了所有时钟在离散时间每个时刻的触发状态,是一个有限或者无限的序列σ(0)σ(1)…σ(i)…,i∈,为0和正整数的集合.σ(i)∈2c表示在时刻i触发的时钟集合,形式化定义为 定义3.时钟历史.对于给定的时钟调度σ,时钟历史记录了在σ中每一个时钟截止到当前时刻的触发次数,形式化定义为 Hσ(c,i)=|{j|j∈+,j≤i,c∈σ(j)}|= 基于上述定义,下面展示6种最基本的时钟关系的语法和语义,分别是优先关系(precedence)、互斥关系(exclusion)、子时钟关系(subclock)、同时关系(coincidence)、因果关系(causality)和交替关系(alternation).时钟关系包括逻辑时钟和二元连接操作符.时钟关系的语法定义如下,Rel∷=c1c2|c1#c2|c1⊆c2|c1≡c2|c1~c2|c1≼c2,时钟关系的形式化语义见表1. Table 1 The Formal Semantics of Clock Relations 优先关系c1c2表示时钟c1的触发快于时钟c2的触发.互斥关系c1#c2表示若时钟c1触发,则时钟c2不触发,反之亦然.子时种关系c1⊆c2表示在任意时刻,若时钟c1触发.则时钟c2必然触发.同时关系c1≡c2表示时钟c1和时钟c2同时触发.因果关系c1≼c2表示时钟c1的触发不慢于时钟c2的触发.交替关系c1~c2表示时钟c1和时钟c2交替触发. 时空状态迁移表示空间关系随着时刻变化的而不断演化.区域连接演算(region connection calculus, RCC)主要用来描述空间区域间拓扑关系,该空间描述逻辑是Randell等人[31]在Clarke[32]的空间演算逻辑公理的基础上提出的,将区域连接逻辑应用在无人驾驶系统时空同步规约中,可以用来描述无人驾驶车辆间的空间逻辑关系. 无人驾驶车辆之间可以通信并且决定什么时间怎样做出决策,并且安全的无人驾驶系统需要具备可以解释的决策行为.这些决策可以帮助选择适合的行为并且能预测危险行为,无人系统决策涉及到安全攸关的时间和空间关系建模.系统行为可以描述为时钟关系随着空间变化而不断同步演化,文章给出了时空同步约束系统的抽象架构,如图2所示.假设在时刻ti处,对于2种空间区域x1和x2,存在一种2个空间区域相离的空间关系DC(x1,x2);在另外时刻tj处,存在另外一种空间区域外部相切的空间关系EC(x1,x2);而在时刻tk处,存在空间区域部分重叠的空间关系PO(x1,x2),两车占用的时空区域可能存在部分重叠的空间关系.对于无人驾驶车辆来说,空间区域相切和空间区域部分重叠是危险的空间位置关系,需要在决策模块提前避免发生碰撞的时空关系出现.无人驾驶系统状态和动作迁移不仅伴随着空间关系的变化,还伴随着严格的时钟关系的迁移. Fig.2 An abstract architecture of spatio-clock synchronous constraint systems 为了安全决策和实时时空逻辑推理,本文给出无人驾驶交通快照、无人驾驶时空包络、和特定领域专用的时空同步约束规约语言的定义. 定义5.无人驾驶交通快照(traffic snapshot).无人驾驶交通快照可以描述为七元组TS=(res,clm,posx,posy,spd,acc,td),其中每一个元素分别代表无人驾驶系统相关的函数. 1)res:→P(),车辆标识符I∈,res(I)⊆表示车辆I占用的道路编号集合; 2)clm:→P(),车辆标识符I∈,clm(I)⊆表示车辆I申请占用的道路编号集合; 3)posx:→,车辆标识符I∈,posx(I)表示车辆在占用道路或者申请道路上的纵向位置信息; 4)posy:→,车辆标识符I∈,posy(I)表示车辆在占用道路或者申请道路上的横向位置信息; 5)spd:→,车辆标识符I∈,spd(I)表示车辆的纵向速度信息; 6)acc:→,车辆标识符I∈,acc(I)表示车辆的纵向加速度信息; 7)td∈{-1,0,1}表示车辆的驾驶方向,分别表示车辆右转、直行和左转. 定义6.无人驾驶时空包络(spatio-clock envelope).对于任意车辆I∈和交通快照TS,无人驾驶时空包络可定义为SCE=(pid,bd,L,I,Vx,Vy)clk,其中pid∈是提前规定的最小距离(prescribed interval distance),包含了车辆的长度和规定的最小安全距离;bd∈表示刹车距离(braking distance),描述了车辆从开始刹车到最终停止的距离,对于自车车辆ego和刹车时间t,定义刹车距离为 加速度acc:→,安全距离(safety distance)是刹车距离加规定间隔距离sd=bd+pid.L=[l,n]⊆表示时空安全包络包含的车道编号集合. Vx=[pos(I)-h,pos(I)+h]⊆和Vy=[0,w]⊆分别表示在时刻clk和位置(posx,posy)处,车辆所能观测到的纵向区域和横向区域. 定义7.时空同步约束规约语言.时空同步约束规约语言(spatio-clock synchronous constraint specification language, SCSL)的语法定义: φSCSL∷=true|φ|φ1∧φ2|∃v:φ1|u(l,t)= v(l′,t)|re(A)(l,t)|cl(A)(l,t)|e(l,t)(l′,δ)| 基于第2节提出的领域特定的时空规约语言,本节给出系统行为建模语言,即时空同步自动机(spatio-clock synchronous automata, SCSA),然后给出无人驾驶行为的转换条件,以及时空安全攸关转换系统的卫士条件和不变式. 定义8.时间空间同步约束自动机.该模型语法定义为七元组SCSA=(Q,q0,Σ,Varb,E,Grd,Inv),其中: 1)Q是系统状态的集合,每一个状态可以看作是系统控制图中的一个顶点; 2)q0是系统的初始状态; 3)Σ是无人驾驶控制动作的集合; 4)Varb是系统变量的集合,有4类变量,分别是离散变量dVar,连续变量ctVar,时钟变量ckVar,和空间位置变量sVar; 5)E⊆Q×Grd×Σ×2Varb×Q是控制图中连接状态之间边的集合,E代表迁移关系; 6)Grd代表迁移卫士条件,Σ代表迁移动作,2Varb需要重置的变量; 7)Inv:Q→ψ(Varb)表示关于变量的不变式. 时空同步约束自动机中的状态Q=(n,v,clk,sp)包括状态名称n,变量名称v,时钟以及时钟关系clk,和空间位置及其关系sp.对于迁移关系中的环境标签λ,触发事件evt(λ),卫士条件grd(λ),和迁移动作act(λ), 表示当观测到触发事件evt(λ),迁移卫士条件grd(λ)满足,那么迁移动作act(λ)将会被执行. Fig.3 An example of spatio-clock synchronous controller 定义9.无人驾驶控制器动作.无人驾驶控制器动作(autonomous controller action,ACA)可以定义为ACA∷=c(A,ψL)|wdc(A)|r(A)|wdr(A,ψL)|τ,其中ψL∷=n|l1|l1+l2|l1-l2,n∈,l1,l2∈LVar,c(A,l)表示车辆A申请道路l.动作wdc(A)表示车辆A撤销申请的道路.动作r(A)表示车辆A占用之前申请的道路.动作wdr(A,l)表示车辆A撤销占用除了道路编号l以外的道路.τ表示空动作,允许没有任何动作的交通迁移. 结合定义8和定义9,给出时空同步自动机操作语义和控制器动作的例子,如图3所示.初始状态Initial,状态q1是碰撞检测状态ReserveOverlap-Check,当接收到前方车辆同意超车Agreement信号,并且所有相关车辆和当前车辆都不存在可能碰撞时,即∀c,roc(ego,c)==false,并且申请道路在道路线标号范围内n+1≤N,状态迁移触发事件满足,卫士条件也满足,需要执行迁移动作,重置时钟变量x,并且执行申请临近道路动作c(ego,n+1),接下来状态从q1迁移到潜在碰撞检测状态q2,即申请道路空间重叠检测ClaimOverlapCheck.在状态q2,如果车辆接收到拒绝信号Decline,或者存在潜在碰撞的车辆,即满足∃c,coc(ego,c)==true,则需要重置时钟变量x,并且执行撤销申请道路的动作wdc(ego). 下面给出时空同步迁移的定义. 定义10.时空同步迁移(spatio-clock synchronous transitions).对于任何车辆I∈,经过时间t后,速度和纵向位置的演化迁移可以根据: spd′,acc,td)∧∀I∈:spd′= (6) 对于任何车辆I∈和道路编号n∈,车辆可以申请邻近道路n+1或者n-1,并且为了保证无人驾驶的安全性和负责任,车辆必须服从交通规则,例如在右侧行驶的国家(比如美国、中国和除了英国、澳大利亚以及其他英国殖民地国家以外的大部分国家),大部分国家只允许右侧行驶,但是在超车时需要申请左侧道路超车行驶,可以根据式(7)执行申请道路迁移和式(8)执行撤销申请道路的迁移: spd,acc,td′)∧(|clm(I)|=0)∧(|res(I)|=1)∧ (td′=1)∧({n+1,n-1}∩res(I)≠∅)∧ (clm′=clm⊕{I{n}}), (7) posy,spd,acc,td′)∧(td′=0)∧ (clm′=clm⊕{I∅}). (8) 重载算子⊕含义如下,ξ⊕{vα}可得{vα}中所有的关系,并且加上除去第一个元素在关系{vα}中,同时也在关系ξ中的关系后的所有剩余ξ中的关系. 对于任何车辆I∈和道路编号n∈,根据式(9)车辆占用之前申请或者占用的道路编号,根据式(10)车辆也可以撤销占用除了道路编号n以外的道路: spd,acc,td)∧(clm′=clm⊕{I∅})∧ (res′=res⊕{Ires(I)∪clm(I)}), (9) posy,spd,acc,td)∧(res′=res⊕{I{n}})∧ (n∈res(I)∧|res(I)|=2). (10) 对于任何车辆I∈和加速度acc∈,加速度可以根据式(11)进行演化: spd,acc′,td)∧(acc′=acc⊕{Ia}). (11) 根据第3节介绍的时空同步自动机和迁移条件,本节主要介绍无人驾驶安全卫士条件和结合形式化时空同步约束的强化学习方法.提出满足系统安全需求的奖励函数设置方法,重点关注时间空间同步约束的卫士条件和不变式. 定义 11.无人驾驶安全卫士(autonomous driving safety guards).根据定义4,时空安全卫士条件(即不发生碰撞)表示为申请和占用时空区域不发生重叠,可以检验安全性条件来确保没有交通事故发生(前提是车辆之间的通信不会发生延迟,车辆的感知器和其他硬件不会发生故障等). safetyOverlap(c1,c2)=(c1.posx≤c2.posx≤ c1.posx+c1.sd)∨(c1.posy≤c2.posy≤ c1.posy+c1.sdy)∨(c2.posx≤c1.posx≤ c2.posx+c2.sd)∨(c2.posy≤c1.posy≤ c2.posy+c2.sdy). (12) safetyOverlap(c1,c2)为真说明车辆c1和c2占用道路空间存在相交的区域.这时安全卫士条件意味着任何两辆车辆之间不存在相交的时空区域,可表示为 safe=∀c1,c2:((c1=c2)∨(res(c1)∩ res(c2)=∅)∨safetyOverlap(c1,c2)). (13) 或者根据时空同步约束语言SCSL,可以形式化规约为 safe=∀c1,c2:((c1=c2)∨(res(c1)∩res(c2)= ∅)∨(re(c1)(l,t)∧re(c2)(l,t))). (14) 占用时空重叠检测(reservation overlap check)roc(c1,c2)用来阻止任意两辆车占用重叠的时空区域,表示为 roc(c1,c2)=∃c1,c2:((c1≠c2)∧(res(c1)∩ res(c2)≠∅)∧safetyOverlap(c1,c2)). (15) 根据时空同步约束语言SCSL,安全卫士约束可以形式化规约为 roc(c1,c2)=∃c1,c2:(re(c1)(l,t)∧ re(c2)(l,t)). (16) 申请时空重叠检测(claiming overlap check)coc(c1,c2)阻止任意两辆车辆占用或者申请时空区域重叠.如果车辆c1想把申请信息转换为占用道路信息并且安全地进行换道,车辆c1需要检查自身申请的时空区域与另外一辆车c2申请或者占用的道路空间是否有重叠,参照: coc(c1,c2)=∃c1,c2:((c1≠c2)∧((clm(c1)∩ res(c2)≠∅)∨(clm(c1)∩clm(c2)≠∅)∧ safeOverlap(c1,c2)). (17) 根据时空同步约束语言SCSL,安全卫士约束可以形式化规约为 coc(c1,c2)=∃c1,c2:(cl(c1)(l,t)∧ (re(c2)(l,t)∨cl(c2)(l,t))). (18) 强化学习无法从环境交互的经验中学习到奖励函数,奖励函数必须由人工编写,而编写奖励函数具有2个挑战:1)感知数据不能直接用于奖励函数的输入参数(比如像素等),系统需要对数据进行抽象来获得强化学习中的状态空间和动作空间;2)复杂的学习任务需要分解为多个子学习任务(sub-goal task),子任务奖励不仅与当前的状态和动作有关系,还与历史状态的状态和动作有关,本文称为非Markov性质的奖励,所以系统设计人员需要对子学习任务的时序关系进行严格的形式化约束,否则不能达到安全累计回报的最优值.为了解决上述问题,需要构建一个面向特定领域的状态-动作空间词汇表,本文给出将智能体学习经验(s,a,s′)与状态-动作空间词汇联系起来的命题标签函数的定义. 该标签函数标注了强化学习中状态和动作的系统迁移,首先本文给出无人驾驶系统相关的状态空间和动作空间的抽象描述.状态空间可以描述为 S=(numlane,numveh,idveh,rlid,clid,vr,ar,vid, 其中,numlane是道路的数量,numveh是安全区域内车辆的数量,idveh表示车辆的标识符,rlid表示车辆占用的道路编号集合,clid表示车辆申请的道路编号集合,vr表示车辆的速度区间[vmin,vmax],ar表示车辆的加速度区间[amin,amax],vid表示车辆id的速度,aid表示车辆的加速度,posx表示车辆的纵向位置,posy表示车辆的横向位置,ddid表示车辆的驾驶方向,llid表示道路的长度,wlid表示道路的宽度,pdx表示两车纵向最小间隔,pdy表示横向最小间隔.动作空间为 A=(cl_left,cl_right,wd_cl,res,wd_res, keep_lane,brake,hard_brake,acc, 其中,cl_left表示申请左转,cl_right表示申请右转,wd_cl表示不满足申请条件时撤销申请,res表示占用道路(r(I)),wd_res表示撤销道路占用(wdr(I,n)),keep_lane表示保持当前道路,brake表示刹车减速,hard_brake表示遇到紧急情况时紧急刹车,acc表示加速行驶,maintain表示保持当前速度行驶,roc表示占用道路时空重叠检测(roc(c1,c2)),coc表示申请道路时空重叠检测(coc(c1,c2)),overtake表示超车. Fig.4 The research framework ofsafeRL approach 为了保证安全累计回报的最大化,需要规定智能体获得奖励函数的时空同步约束条件,对于复杂的强化学习任务,各个子学习任务之间存在条件、循环和否定等时空约束关系,系统奖励不仅仅依赖Markov奖励决策过程,还受时空同步公式的约束,只有满足时空同步约束的动作才可以获得相应的奖励,记为rt:(s1,a1)(s2,a2)…(st,at)φ,也就是系统的历史经验满足逻辑公式φ(φ是关于命题集合的时空同步约束公式)时,系统才能获得奖励.也可以理解为状态-动作空间迁移系统满足公式φ.下面给出时空同步约束的奖励函数状态机的定义,该状态机对应着完成相应任务时的形式化时空同步逻辑规约公式,从而解决了非Markov决策过程的奖励函数设置问题. 定义13.时空同步约束奖励状态机(spatio-clock synchronous constraint reward machine, SCSRM)[11].时空同步约束奖励状态机可以定义为九元组SCSRM给定非Markov决策过程中的元素命题符号集合系统状态集合以及动作集合状态-动作空间迁移系统是该状态机中的状态集合;u0是该状态机的初始状态;表示系统可以接收的输入状态和动作信息;状态机的状态转移函数表示在状态ut∈U时,满足标签迁移命题逻辑公式时,系统状态发生迁移,即状态机的奖励函数δr:U×U→[(S×A)+×S→]表示在迁移关系中,时空同步约束状态机为非Markov奖励函数,即根据定义,该奖励是从奖励状态机的初始状态到当前状态的满足逻辑公式φ的奖励之和. 算法2.safe_DDQN求解最优动作价值算法. 输出:形式化约束制导的动作价值估计. ② fort=0 toTdo /*回合数内迭代寻找最优价值*/ ③ 选择子学习任务i←subtask(SCSRM,t); ⑤ while(episode ⑥ 进入到下一个状态st+1并且返回奖励rt; ⑧ 更新时空同步约束奖励状态机状态; ⑨ 更新时空同步约束奖励状态机奖励; ⑩ ifst+1是终止状态 then /*当前价值为奖励*/ /*更新价值,执行新的动作*/ /*策略梯度下降更新w*/ at←at+1;/*状态机、状态和动作的 更新*/ 算法2在提高安全性的同时,比算法1多了一层for循环,算法嵌套的循环迭代次数增加了,因此算法复杂度提高为O(n3),而算法1的算法复杂度是O(n2),原因是为了满足非Markov性质的奖励,需要构建时空同步约束的奖励状态机,然后在形式化约束制导的奖励状态机里面选择子学习任务,用来在回合数规定内获得子学习任务满足形式化时空同步规约的最优动作价值,导致了算法复杂度的增加.同时,形式化时空同步约束制导的强化学习融合了安全规则和先验经验等安全约束,智能体将不会去探索或者试错不正确的动作策略,在相对较少的训练次数内获得较好的奖励,所以加快了深度强化学习的效率,提高了算法的收敛速度. 对于无人驾驶系统,系统设计者希望车辆能够安全高效地行驶,同时车辆还需要遵守交通规则,所以考虑回报奖励函数时,需要综合考虑以下3个方面:1)车辆发生碰撞或者违反交通规则,假如奖励为-2;2)如果车辆速度太慢,导致通行效率太低,假如速度小于2 m/s,则奖励为0;3)计算安全距离(safety distance),并设计奖励函数.同时需要限制训练回合的时间,因为在训练过程中,可能会出现车辆在某一个范围内转圈,需要限制回合时间,使得车辆进入后续回合的训练.基于回报奖励函数,可以设置回合时间,例如发生时空重叠或者违反交通规则;汽车速度小于最低速度;碰撞时间小于设定值等. 根据无人驾驶安全卫士条件的形式化描述,文章提出了基于时空同步约束的安全强化学习方法.该方法的主要思想是是指在强化学习训练和执行过程中,学习最优策略的过程需要满足形式化时空同步安全约束.系统很难及时预测前车的动作策略,车辆碰撞可能发生在自车与前车的距离小于安全距离时.基于这个原因,需要制定形式化安全距离约束来惩罚那些与前车距离小于安全距离的车辆.在定义6的基础上,再增加一个反应时间内行驶的距离dre,跟驰车辆(following vehicle)的刹车距离[33]dstop_f表示跟驰车辆在反应时间内以最大加速度和最小刹车加速度行驶的距离,计算为 (19) 其中,vf表示跟驰车辆的速度,tre是车辆的反应时间,amax,brake是车辆紧急刹车(hard brake)的最大刹车加速度,amax,acc是后面跟驰车辆在反应时间内的最大加速度,amin,brake是反应时间过后前面车辆从开始刹车到车辆停止且前后两辆车没有发生碰撞的最小刹车加速度. 前面车辆(preceding vehicle)的刹车距离dstop_p表示车辆以初始速度vp行驶,最大制动加速度amax,brake刹车时车辆行驶的距离,计算为 (20) 车辆之间的最小距离dmin是后车刹车距离dstop_f与规定间隔dpid之和,减去前车刹车距离dstop_p和两车间隔dgap距离的和,车辆之间的距离必须满足式(21),才保证车辆不发生碰撞. dmin=(dstop_f+dpid)-(dstop_p+dgap)>0, (21) 其中,dpid是规定的车辆之间的安全间隔距离,dgap是两车停止后的实际间隔距离. 违反安全距离的规定促使无人驾驶车辆在强化学习的过程中保持安全距离行驶.系统首先给出关于最小安全距离dmin的奖励反馈函数: (22) 利用安全强化学习训练车辆的过程中,车辆的速度不要超过允许的最大速度,同时希望车辆能够快速的到达目的地,所以系统设计人员需要设置关于训练车辆速度的奖励函数: (23) 为了避免车辆偏离行驶车道撞向路边基础设施发生交通事故,本文设置车辆安全驾驶行为的正强化学习奖励函数,系统设计人员应鼓励车辆靠近路中间的道路行驶,用dispy_mid表示车辆的横向位置与道路中间横向位置的距离,为此设置车道保持的奖励函数: Rlane=exp(-1.2×dispy_mid). (24) 本文主要关注无人驾驶车辆强化学习智能体的安全性和通行效率,为此给出在时刻t的奖励函数: (25) 系统的需求描述如图5所示,当前道路上的自车车辆有超车意图时,首先需要打开转向灯,提示在时空安全包络内的周围车辆超车意图,此时有3件安全关键的事情需要确认:1)需要确认与同车道的车辆是否在安全距离内,也就是确认是否存在占用空间重叠;2)安全包络内的周围车辆观测到变道信号后,后面车辆不能加速;3)向前面车辆发送变道超车请求信息.前方车辆preceding-vehicle在接收到超车请求信号后,需要在一定时间(反应时间假设2 s)内回复同意或者拒绝,如果自车车辆在反应时间内接收不到回复信息或者接收到拒绝信息,自车车辆不能实施变道超车,需要保持原来的状态前进;如果与周围的申请道路车辆不满足安全距离约束,也就是存在申请道路的空间重叠,同样不能实施变道超车.需要同时满足在约定的反应时间内接收到同意信息和满足安全距离的情况下,才可以实施变道超车.超车动作可以分解成2次变道,首先是第1次变道到申请的道路,变道之后需要加速前进,在这个过程中,之前回复同意的车辆不能加速,当自车车辆的相对空间位置超过自车车辆前方车辆时,并且它们之间满足变道的安全距离时,自车车辆实施第2次变道,2次变道超车的时间间隔不能超过超车规定时间. Fig.5 An example of autonomous lane-change and overtaking in highway scenario Fig.6 Combine RL and SUMO simulation platform 建立时间空间同步自动机理论模型包含3个步骤:1)车辆左转信号Turn_left必须优先变道申请Claiming_req,变道申请优先于互斥的时钟事件同意申请Change_claim_agr和不同意申请信号No_change_claim_agr,该需求形式化规约为CTurn_leftCClaiming_req(CChange_claim_agr#CNo_change_claim_agr).其次,当前面车辆回复同意超车信号后,占用道路碰撞检测roc(ego,c)严格优先于占用道路动作Reserving,而且占用道路动作又严格优先于前方车辆不能左转信号No_turn_left,该需求可以形式化规约为roc(ego,c)CReservingCNo_turn_left.2)申请邻近道路信号c(I,n)与撤销申请信号交替发生wdc(I),该需求形式化规约为c(I,n)~wdc(I),同样地,占用道路事件r(I)与撤销占用道路事件wdr(I,n)交替发生,该需求形式化规约为r(I)~wdr(I,n).3)碰撞检测时钟roc(ego,c)的发生不慢于申请变道的时钟Claiming_req,2个时钟满足因果关系,即roc(ego,c)≼CClaiming_req,同样地,潜在碰撞检测coc(ego,c)触发互斥时钟占用之前申请的道路Reserving和存在潜在碰撞Potentialcol,该需求可以形式化规约为coc(ego,c)≼(CReserving#CPotentialcol). 结合强化学习的SUMO仿真平台是一个开源、微观和连续的交通仿真软件包,支持动态路由的生成和输入,拥有可视化的图形界面,可以对时间和空间进行良好的定义和模拟,利用TraCI接口(traffic control interface)实现用Python语言进行模型开发与仿真,所以本文选择了SUMO作为仿真验证工具,如图6所示系统由3个部分组成:1)驾驶环境,该模块路网文件(.net.xml)和路由文件(.rou.xml),路网文件描述了交通道路信息,包括节点文件(.node.xml)和连接边文件(.edge.xml);路由文件定义车辆行为、行驶路径和车流信息.2)TraCI接口,它作为仿真平台和强化学习算法之间的接口,将仿真网络里的观测状态信息传递给算法,而后又将算法输出的高层动作传回给目标车辆智能体.3)智能体模块,借助TensorFlow库开发的DDQN算法和改进的safe_DDQN算法,实现智能体的智能安全决策.这里需要注意,DDQN和safe_DDQN算法只输出高层控制动作,而对目标车辆的底层控制由SUMO模拟器实现.对于道路信息,SUMO还可以通过netconvert程序将很多的第三方的路网文件转化为SUMO可读的文件,例如可以选定真实物理世界的osm格式的地图文件,直接生成一个可以运行仿真的SUMO路网文件;车辆的行为主要靠无人驾驶的感知模块获得,所以只要实际无人车系统的车辆感知系统满足道路运行测试条件的话,就可以将文中的方法部署在实际的无人驾驶车辆. 在SUMO中生成案例中的交通仿真场景如图7所示,交通场景中包含3条道路,车辆信息由路由文件生成,图7中的红色车辆是需要强化学习训练的自车车辆,黄色车辆是交通驾驶环境视窗中的其他周围车辆. Fig.7 Overtaking scenario screenshot in SUMO platform Fig.8 Experimental results and analyses 本文对2个算法分别进行了500回合的深度强化学习训练,其中每一回合表示自车车辆完成了一次在规定道路上的驾驶行为,并对仿真结果进行了比较.图8(a)显示了算法在每一回合训练中获得的平均奖励,首先可以看到随着训练回合数的增加,2个算法的平均奖励都在上升,但是safe_DDQN的平均奖励相比于普通的DDQN更高而且在较短的时间内趋于稳定,这也意味着本文提出的算法safe_DDQN更容易收敛.图8(b)显示了算法指导的智能车在每一回合训练中发生的总碰撞次数,在2个算法中,智能车的碰撞次数随着训练回合数的增加而不断减少,说明智能车通过探索强化学习学得了正确的驾驶动作,减少了碰撞次数的发生,但是普通的DDQN算法不够稳定,在400回合后,仍有较高频率的碰撞发生,而safe_DDNQ此时已经几乎不会发生碰撞.在实验中设置每一个回合进行1 000时间步(timesteps)的状态-动作空间采样,对应算法1行③和算法2行④,根据算法描述,有时候遇到终止状态仿真会提前终止回合的迭代,500回合仿真大约有40万时间步,为了方便观察,每20个时间步选取一个数据,并绘制了如图8(c)所示的智能体车辆的速度变化图.从图8中可以看到,safe_DDQN算法指导的智能车,在20万时间步后,速度就趋于平稳,且始终维持在目标车速附近,而普通的DDQN算法指导的小车,速度波动始终很大,这不仅会影响乘车舒适度,还会带来安全隐患.由此可见,本文提出的safe_DDQN算法相比于普通的DDQN算法,在算法收敛速度、算法稳定性,以及其指导的智能车所带来的驾驶安全性、乘车舒适性方面都有较大的提高. 首先介绍关于时间和空间形式化约束规约的相关工作.Chouhan等人[34]利用形式化时间自动机模型和统计模型检测方法,为启发式无人驾驶交叉路口管理提供了相关的建模和验证技术.Cuer等人[35]提出了从自然语言到形式化状态机的建模架构,并且不断删掉潜在的自然语言模糊性和不一致性.Briola等人[36]用本体来描述空间关系,并且用Prolog来规约可解释的规则信息,方便系统设计者重复使用形式化的领域空间知识.多道路空间逻辑(multi-lane spatial logic)被用来建模无人驾驶领域的道路知识,包括乡村道路的应用[37]、城市道路的应用[13]和高速场景的应用[38].无人驾驶时间行为建模方面,文章[39]设计了随机混合时空规约语言和自动机,并提出了无人驾驶车辆发生碰撞时刻和位置的预测方法.Tan等人[40]展示了空间时序事件建模的方法,该方法规约事件的触发不仅根据严格的时序和物理时间,而且还受空间关系的制约.上述研究关注了空间或者时间的建模,但是对于时空同步约束的自动驾驶系统来说,仍然缺乏领域相关的形式化规约语言,增强系统需求和任务的严格描述,减少自然语言的二义性,同时用来增强系统决策的安全性. 然后介绍结合安全约束的强化学习方法.对于安全攸关的无人驾驶系统,为了增强系统决策的安全性,结合形式化安全约束的强化学习技术得到越来越多的关注和研究.文献[6,41]结合可解释的基于规则的策略和黑盒的强化学习来实现系统的安全性和鲁棒性.纪守领等人[42]回顾了机器学习中的可解释性问题,分析了可解释性机器学习的安全性面临的挑战和研究方向.Krasowski等人[43]通过扩展强化学习安全层来限制动作空间,利用基于集合的方法来增强强化学习的安全保障.Wachi等人[44]提出了一种带约束Markov决策过程的强化学习方法,该方法通过扩展安全区域来不断学习安全约束.Gao等人[45]设计了一个结合形式化线性时序规约(linear temporal logic, LTL)的奖励回报函数,可以更准确地估计损失函数的梯度和改善训练过程的稳定性.Wolf等人[46]指出仅仅对专家知识进行建模是比较困难的,提出结合语义状态和交通规则来增强强化学习的安全性.Wang等人[47]在无人驾驶任务决策方法中结合基于规则约束和强化学习的方法,实现了安全高效的变道行为.Chen等人[48]提出了一种基于经验指导的深度学习多行动者-评论家算法,从优秀经验中学习指导网络,并对动作价值函数进行更新指导.Garca和Fernández[49]给出了安全强化学习的定义,并给出在系统学习和部署的过程中增加安全约束的相关文献综述. 针对基于强化学习的无人驾驶系统决策安全性问题,本文首先给出了时空同步轨迹的介绍,指出无人驾驶系统是时间空间安全攸关的系统,并给出了无人驾驶特定领域的时空同步约束规约语言.其次,无人驾驶的安全性主要是关心系统的时空是否重叠,本文基于时空同步约束语言和自动机的定义,展示了无人驾驶控制器和占用/申请(撤销占用/申请)空间的动作,规约了安全状态迁移的条件,给出了如何检测占用时空重叠和申请时空重叠的检测标准.然后,针对学习任务非Markov性质的奖励函数,本文给出系统状态-动作空间迁移系统的安全迁移条件,提出形式化时空同步约束奖励状态机,来提高获得强化学习非Markov性质奖励函数的安全性,进而来提高形式化约束制导的奖励函数设置的可解释性.最后通过无人驾驶高速场景下变道超车的案例,在SUMO仿真平台上验证所提方法的有效性. 在将来的研究工作中,首先需要优化强化学习安全约束的设计与训练,考虑交通规则对无人驾驶系统的影响,建立遵守交通规则的负责任的和安全的无人驾驶决策系统.其次,需要改进强化学习奖励回报函数的设计与训练,提升学习的效率和学习策略的可解释性.最后,目前实验验证是在模拟的环境下进行,而且驾驶场景比较简单,在今后的工作中,需要在其他交通场景比如交叉路口和环岛等加强仿真实验,同时还需要在实际无人驾驶系统中部署结合安全约束的强化学习研究与应用,逐步推进安全强化学习在无人驾驶系统中的推广与实际应用. 作者贡献声明:王金永负责阅读文献和初稿写作,黄志球提供研究基金和科学问题,杨德艳提出算法思路和文献整理,Xiaowei Huang提供实验方案和safeAI论文思路,祝义负责形式化理论与论文审查,华高洋负责实验设计与结果分析.
1.3 时钟约束规约语言和空间逻辑

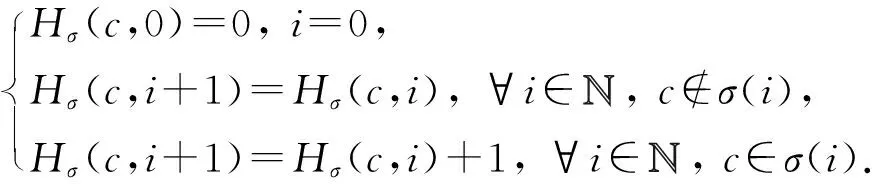

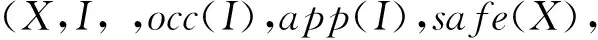
2 时空同步约束规约语言


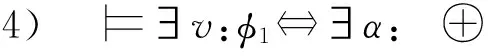

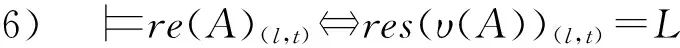

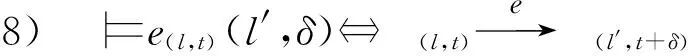
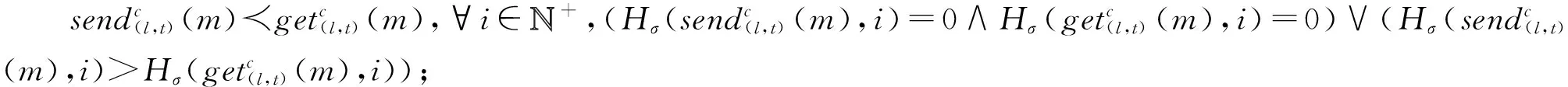
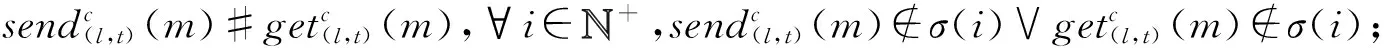
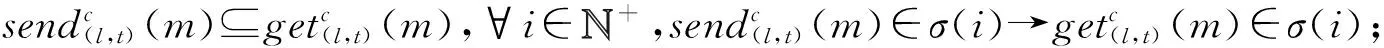

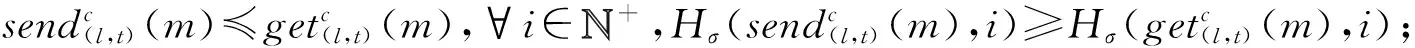

3 时空同步约束自动机和时空迁移条件
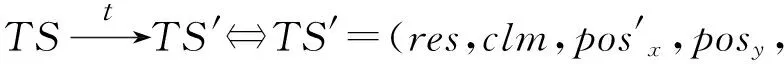
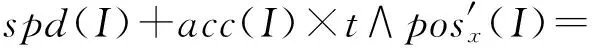
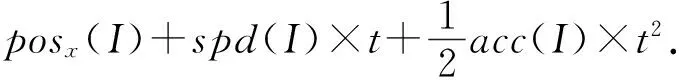
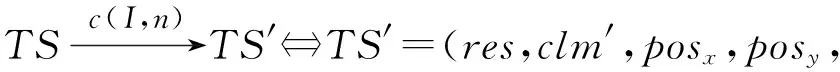
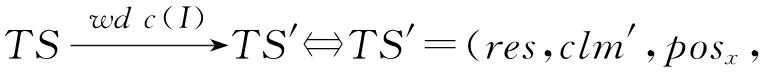

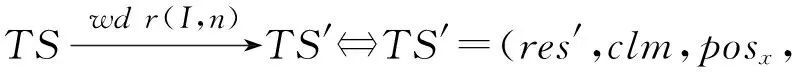
4 时空同步约束制导的强化学习方法
4.1 时空同步约束系统的安全迁移条件
4.2 形式化约束制导的安全强化学习框架

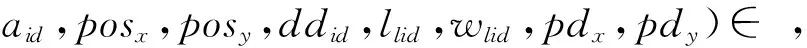
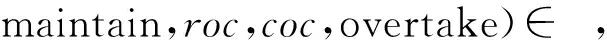
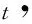

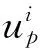
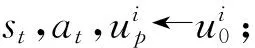
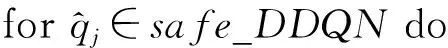

5 案例分析
5.1 案例需求分析

5.2 SUMO仿真平台及实验设计分析


6 相关工作
7 总结与展望
