视觉与激光结合的室内移动机器人重定位方法
2021-12-13包加桐杨圣奥朱润辰唐鸿儒宋爱国
包加桐,杨圣奥,朱润辰,唐鸿儒,宋爱国
(1.扬州大学电气与能源动力工程学院,江苏 扬州 225300; 2.东南大学仪器科学与工程学院,江苏 南京 210096)
0 引 言
移动机器人重定位[1]一般指在没有先验信息的前提下,机器人仅依靠自身传感器估计其在已知全局地图中的位姿。重定位发生于同步定位与建图(SLAM)结束后的自主导航过程中,是自主导航的重要前提[2]。在初始位姿未知或发生“绑架”时,机器人均需要进行重定位。其中在机器人初始上电工作时或突发状况下被强制重启后,需要估计机器人的初始位姿;机器人“绑架”指在导航时由于某种外部因素(如人为搬离、外部碰撞等)机器人位姿发生突变,从而导致原有依赖位姿连续变化的定位算法[3]失效。
由于室内环境下激光雷达测距较精确且不易受环境光照影响,同时在考虑激光雷达成本情况下,许多研究工作致力于利用单线激光雷达实现机器人重定位。其中主要涉及两个关键问题:如何表征和匹配局部感知信息与全局地图信息以及如何确定全局地图中待搜索区域。传统的方法多采用占用栅格来描述激光雷达测得的局部环境信息以及全局地图信息,再基于概率运算完成候选搜索区域内的重定位。例如在经典的自适应蒙特卡罗定位(AMCL)算法[4]中,在重定位时随机分布粒子表示机器人所有可能位姿,根据栅格占用情况基于似然域模型计算每个粒子的权重,利用重要性采样更新粒子以及KL散度采样调整粒子数等,最终加权平均各粒子得到估计位姿。然而该方法由于在全局地图范围分布粒子,粒子收敛时间较长且在环境特征相似的场景中易出现错误定位。在Google的Cartographer算法[5]中同样使用占用栅格来表示环境信息,通过匹配栅格化后的激光雷达数据与地图数据并基于极大似然估计来求解最有可能的位姿。由于重定位时该算法也需在全局地图上搜索,定位时间较长且在单一结构环境中易定位失败。
为了简化激光雷达与地图数据匹配及全局搜索过程,许多研究尝试将深度学习应用于机器人重定位。例如文献[6]将连续多帧的激光雷达数据形成多通道图像,送入卷积神经网络提取图像特征,经全连接网络预测机器人位姿。文献[7]采用了堆栈自动编码器自动学习激光雷达数据特征,根据相似性度量对SLAM过程中的激光雷达数据帧进行分割并生成训练数据集。在堆栈自动编码器网络后加上Softmax层,使用数据集训练得到分类器,在重定位时用于预测激光雷达数据帧的类别并关联到SLAM时的地图区域,从而缩小全局地图搜索区域。
此外由于视觉感知可以获取丰富的场景信息,随着无人驾驶技术的兴起[8],视觉SLAM也一直是研究热点,出现了许多基于单目、双目、RGB-D相机的视觉SLAM算法。例如ORB-SLAM2算法[9]提取和匹配当前图像帧与关键帧的ORB特征,通过估计相机运动实现局部位姿跟踪,其凭借完善易用等优势成为主流的特征点SLAM算法。然而视觉SLAM主要关注的是如何从连续图像帧中估计出相机位姿变化并通过后端优化生成视觉地图,视觉地图一般无法直接用于机器人导航和避障。文献[10]则在视觉物体识别的基础上构建语义地图,实现了基于语义似然估计的粒子滤波重定位,是将视觉信息与激光信息结合的一种有效尝试。
可以看出,如何缩小候选地图搜索区域是解决重定位问题的关键。本文提出了一种视觉与激光结合的重定位方法。在SLAM阶段,同时进行视觉SLAM与激光SLAM,记录视觉系统中相机位姿和激光系统中机器人位姿并生成位姿映射表。在重定位时利用当前图像与视觉SLAM系统中的关键图像帧进行特征匹配,由于关键图像帧对应的相机位姿已知,可以根据EPnP[9]算法解算出当前的相机位姿。根据最近邻匹配从位姿映射表检索出激光SLAM系统中的最佳的可能位姿,从而缩小了候选地图搜索区域。该位姿进一步作为AMCL算法的先验信息,在该位姿周围分布粒子,更新粒子直至收敛,完成全局重定位。
1 重定位方法框架
视觉与激光结合的重定位方法框架如图1所示。由于重定位发生在已知全局地图的导航过程中,因此预先开展SLAM过程,生成全局地图。在使用单线激光雷达测量环境的基础上,增加RGB-D相机通过视觉感知来记录和区分机器人所在环境,同时开展激光SLAM和视觉SLAM。在SLAM过程中,当机器人位姿发生显著变化时(根据设定阈值来判定),同步记录激光系统中的机器人位姿和视觉系统中的相机位姿,建立位姿关系映射表并存储。激光SLAM结束后,生成二维占用栅格地图。视觉SLAM结束后,生成稀疏特征点地图,记录关键图像帧序列以及对应相机位姿等。
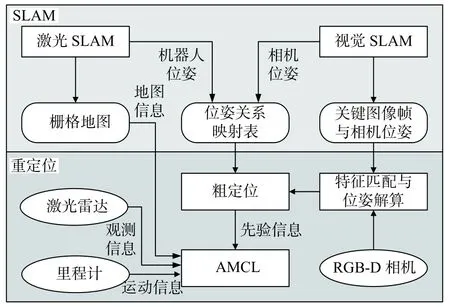
图1 重定位方法框架
重定位时,利用视觉特征匹配寻找关键图像帧及参考相机位姿,基于EPnP算法解算出当前相机在视觉地图中的全局位姿。基于最近邻匹配从上述位姿关系映射表中检索出最佳的栅格地图中的机器人位姿,完成粗定位。将粗定位结果作为自适应蒙特卡洛定位(AMCL)算法中粒子滤波的先验信息,经粒子收敛后实现对机器人精确位姿的估计,最终完成整个重定位过程。
2 基于视觉特征点匹配的粗定位
2.1 图像特征点提取与帧间匹配
图像特征点一般用关键点和描述子来表示,用于表征图像的本质特征,具有不变性和可区分性。本文采用ORB[11]特征点来表示图像,其利用具备尺度不变性和旋转不变性的改进FAST算法来检测各个角点,再使用速度极快的二进制描述子BRIEF来表示角点特征。
在视觉SLAM中图像特征点也被视为路标,由于相机运动的连续性或出现回环时,路标会重复出现在多个图像帧中。为了从多图像帧中估计相机位姿变换,需要获得多图像帧上匹配的特征点对。由于图像特征点采用了二进制描述子,因此采用汉明距离来度量不同角点特征之间的距离,当汉明距离小于设定的阈值即判定匹配成功。
2.2 重定位模式下相机的位姿估计
使用RGB-D相机基于ORB-SLAM2[9]算法完成视觉SLAM过程,生成稀疏特征点地图,记录关键图像帧序列以及对应相机位姿。在重定位模式下,当相机采集的当前图像帧与视觉SLAM过程中的关键图像帧匹配成功后,选取组匹配特征点对,获取关键图像帧中每个匹配特征点的全局3D坐标以及其在当前图像帧中的2D投影,使用EPnP算法求解该3D-2D位姿估计问题。

其中K为相机内参矩阵。基于式(1)可以得到两个线性方程:
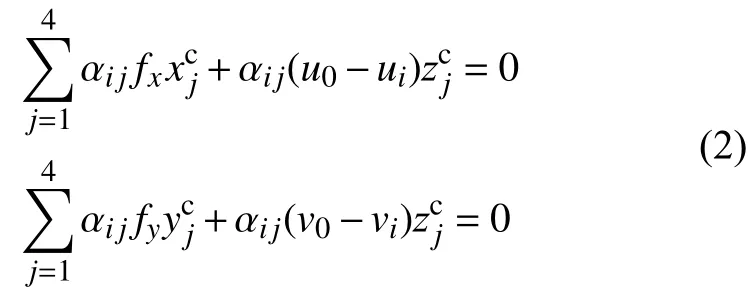

式中:M——2n×12的矩阵;
x——12个未知量构成的列向量。
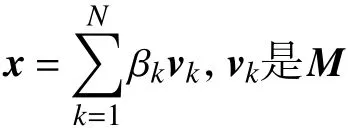

2.3 基于最近邻匹配的粗定位
在视觉SLAM的过程中同时开展基于单线激光雷达的SLAM,本文采用了机器人操作系统(ROS)中常用的GMapping[12]算法来定位机器人和生成栅格地图。以建图起始点为地图坐标系(世界坐标系)原点,当机器人移动距离超过设定阈值(实验中设定为0.25 m)时,同时记录视觉系统中的相机位姿和激光系统中的机器人位姿。设生成的相机位姿与机器人位姿的变化轨迹表示为:


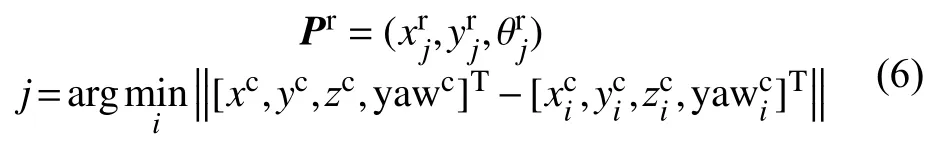
3 基于AMCL的精定位

4 实验结果与分析
为了验证本文提出的视觉与激光结合的重定位方法的有效性,与基于AMCL全局分布粒子的重定位方法、基于Cartographer算法的重定位方法进行了比较实验。
采用 TurtleBot2机器人,搭载 Nvidia Jetson TX2微型计算机,配备RPLIDAR A3单线激光雷达和 Microsoft Kinect RGB-D相机。实验环境为长约14.2 m、宽约6.8 m,面积约97 m2的实验室,靠墙的四周均放置有办公桌、书柜等,中间有两排工作台,整体环境布局呈“回”字型。在重定位前预先同时开展激光SLAM和视觉SLAM,生成的栅格地图和稀疏特征点地图如图2所示。为了评价重定位的准确性、成功率和实时性,在室内环境中人工标定出机器人出发位姿O点,以及A点至E点共5个观测位姿点。重定位实验中,将移动机器人从O点“绑架”至 A点O→A,接着A→B,B→C,C→D,D→E,每组共5次绑架。将机器人重定位结果与人工标定结果进行比对,若在60 s时间内,两者平面距离小于移动机器人的底盘半径0.18 m且航向偏差小于0.25 rad时,判定该点重定位成功;否则判定重定位失败。

图2 室内环境的栅格地图和稀疏特征点地图
图3显示了SLAM过程中绑定的相机位姿与机器人位姿在同一坐标系下的二维轨迹图。由于视觉SLAM和激光SLAM系统相互独立,虽然运动轨迹之间存在误差,但整体运动轨迹变化趋势基本一致。

图3 相机与机器人运动轨迹图
4.1 基于AMCL全局分布粒子的重定位实验
该实验是在没有先验信息的情况下,希望通过全局分布粒子的方式经机器人的运动模型和观测模型实现粒子收敛完成重定位过程。图4显示了将机器人从某一位姿绑架至B点的重定位情况。图4(a)中绿色的箭头代表全局分布的带有权重的粒子,黑色圆圈为机器人模型,红色点为激光雷达测距障碍物点。当机器人开始移动,粒子快速收敛,但最终收敛到了错误的位姿如图4(b)所示,重定位失败。为了定量评价该方法的重定位效果,进行了4组O→E共计20次机器人绑架实验,其中只有第2组D点处重定位成功,耗时约5.4 s,其余重定位实验均以失败告终。据此断定在全局进行撒粒子一般难以解决重定位问题。

图4 机器人绑架到B点的重定位结果
4.2 基于Cartographer算法的重定位实验
Cartographer算法是基于图优化理论的经典SLAM算法,源码中提供的pure_localization接口可实现全局重定位。其基本原理是利用激光雷达生成的局部地图与SLAM过程中的子图依次进行匹配完成全局定位。图5显示了将机器人从O点绑架到A点的重定位情况。如图5(a)所示,机器人被绑架后栅格地图上机器人模型的位置未发生改变,但是激光数据已发生变化。经过一段时间后,机器人模型出现在地图的A点处,重定位完成,如图5(b)所示。

图5 机器人绑架到A点的重定位结果
为了定量评价该方法的重定位效果,进行了10组O→E共计50次机器人绑架实验,记录各位姿点处的重定位结果,重定位位置与航向误差如图6所示。可以看出,该方法在各位置点处x轴方向和y轴方向的位置偏差均在18 cm以内,有一定的误差波动,航向角的偏差大部分处于0.1 rad以内。
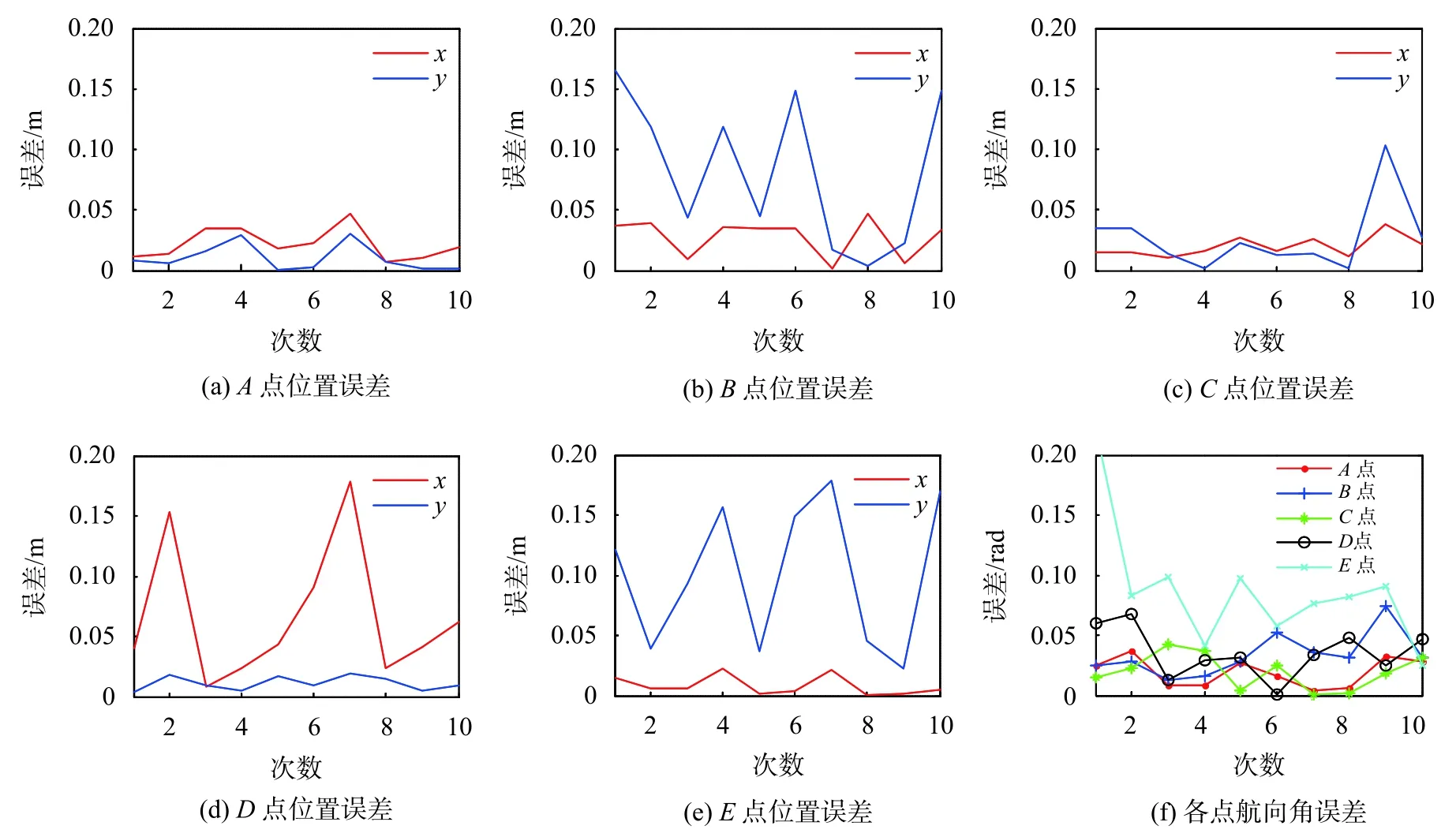
图6 重定位位置和航向误差
再分别 10 s、15 s和20 s为时间限制,计算重定位成功率如表1所示。可以看出该方法在20 s内完成重定位的成功率最高为80%。

表1 基于Cartographer算法的重定位成功率
4.3 视觉与激光结合的重定位方法实验
重定位时首先进行视觉粗定位,再进行基于AMCL的精定位。图7显示了机器人从某一位姿被绑架到A点的重定位情况。机器人首先通过视觉特征的提取与匹配,快速估计出相机位姿,如图7(a)所示,其中蓝色的框图为关键帧,稀疏的点为特征点,黑色代表已观测过的特征点,红色代表当前图像帧中的特征点。将粗定位结果作为AMCL先验信息,在先验位姿周围分布带有权重值的粒子群,如图7(b)所示,其中绿色箭头代表不同的粒子。移动机器人经旋转、移动等可使得粒子群更新直至收敛,如图7(c)和(d)所示。
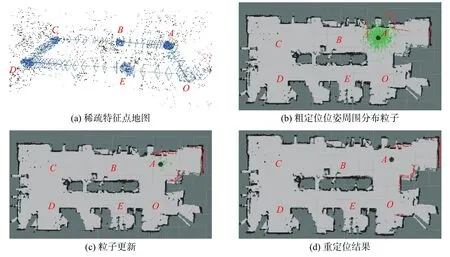
图7 机器人绑架到A点的重定位结果
为了定量评价该方法的重定位效果,同样进行了10组O→E共计50次机器人绑架实验,记录各位姿点处的重定位结果,重定位位置与航向误差如图8所示。可以看出,该方法在各位置点处x轴方向和y轴方向的位置偏差均在10 cm以内,且误差波动幅度较小,航向角的偏差也基本在0.2 rad以内。
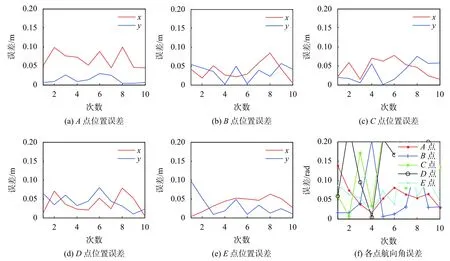
图8 重定位位置和航向误差
同样分别以10 s、15 s和20 s为时间限制计算重定位成功率如表2所示。可以看出该方法在20 s内均能完成重定位,且大部分重定位过程都能在15 s内完成。

表2 本文方法的重定位成功率
进一步统计各点处的重定位误差、时间及成功率的平均值,对本文方法与基于Cartographer算法的重定位方法进行对比,见表3。由于基于AMCL全局分布粒子的重定位方法成功率较低,不参与对比分析。在本文方法中,同时还统计了视觉粗定位的平均定位误差与定位时长。
从表3中可以看出,本文方法的重定位平均误差略高于对比方法,但整体平均位置误差小于5 cm,平均航向误差小于0.1 rad,满足一般系统实际的定位需求。本文方法的平均重定位时间为11.4 s,对比方法需要19.9 s,且以不同时长为限制的情况下统计的成功率明显优于对比方法。

表3 与两种重定位方法实验结果对比
5 结束语
解决初始位姿估计与机器人绑架问题是机器人自主导航的前提。为了综合利用相机与激光雷达分别在视觉感知方面的丰富性以及距离测量方面的精确性,提出了一种结合视觉与激光的重定位方法。将视觉粗定位结果作为先验信息,基于自适应蒙特卡洛方法再进行精定位。与基于AMCL全局分布粒子的重定位方法和基于Cartographer算法的重定位方法进行了比较实验,实验结果表明提出的方法定位时间短、成功率高且定位准确,能够满足一般室内环境下移动机器人自主导航需求。然而本文方法在重定位的实时性方面仍有较大的提升空间。
