时序影像在冬小麦种植区提取中的应用分析
2021-12-12明艳芳刘春秀隋淞蔓
石 娴,明艳芳,刘春秀,瞿 渝,隋淞蔓
(山东科技大学 测绘与空间信息学院,山东 青岛 266590)
0 引言
冬小麦为头年秋季播种次年初夏收获的一种农作物[1],在全世界范围内都有着广阔的种植面积[2]。它的种植面积对经济和社会发展有重要的影响[3-4]。精确、高效的冬小麦空间分布监测具有十分重要的意义[5]。遥感技术能够快速实现大面积作物种植区域的连续监测,可以在冬小麦监测中发挥重要作用[6]。
农作物的遥感识别方法主要包括2大类:单时相遥感影像识别和多时相遥感变化检测。然而由于不同植被之间具有较为相似的光谱特征,单一的光谱信息难以达到较高的识别精度,而物候期的差异通常被作为农作物识别的重要信息。此外,区域灌溉不均匀、土壤盐渍化、病虫害、植被密度差异甚至植物的含水量不同等因素都会导致相同作物在生长过程中产生不同程度的差异[7],因此很难利用单一时相的遥感影像进行区分。多时相遥感影像能够充分反映不同作物的物候特性及变化规律,增大光谱特征相似作物之间的可分离性,可以很好地解决“异物同谱”和“同物异谱”问题,大大提高识别精度[8]。随着高时空分辨率遥感的快速发展,基于时间序列的农作物遥感识别已广泛应用于作物种植面积提取、农业遥感监测等方面。
时间序列遥感作物识别方法主要利用作物整个生育期固定时间间隔的时序数据获取农作物特定的时序曲线,然后分析其物候或数学特征并进行农作物识别。杨小唤等[9]绘制并分析了作物的归一化植被指数(NDVI)时序曲线,制定了不同作物的提取依据,获取了北京市的冬小麦、玉米和大豆的种植空间分布图;陈健等[10]以整个作物生育期内35个时相的合成地表反射率数据生成MODIS数据的增强植被指数(EVI)时序数据,结合作物物候历和种植结构,构建分类模型,最终达到了95.7%的整体分类精度。近年来随着遥感卫星研发技术的不断进步,云平台计算能力和计算机图像处理技术的不断提高,作物识别逐渐向大空间尺度、长时间序列方向发展,分类算法也在不断改进。周珂等[11]根据每旬NDVI最大值合成Landsat8影像,提取了河南省的冬小麦,其平均分类精度达到了95.3%,且有效降低了与统计数据的相对误差;You等[12]将3个波段、7个光谱指数作为特征,使用10 d中值合成Sentinel-2时间序列影像,利用随机森林分类器进行分类,首次在10 m分辨率下制作了中国年度区域作物图。
然而,目前大多数识别方法都是使用某一种时间序列数据,很少有专门的研究通过试验比较分析不同间隔的时序影像用来做冬小麦提取的适宜性和准确性。根据Blaes等[13]的研究,时间序列影像中过长的时间间隔或关键期一景影像的缺失都会对分类精度造成影响。Wardlow等[14]表示,每种作物有其独特的时序光谱曲线,不同的构造方法会造成时序数据的变化,使得作物的提取效果产生差异。由此,时序数据的构造方法对于时序影像的遥感识别分类和基于物候特征的遥感监测产生着至关重要的影响,此类研究也十分有必要开展。
另外,由于中等分辨率卫星自身的局限性以及小规模农业种植区域的分类易受到背景因素的干扰,像素尺度下的冬小麦提取效果可能难以满足要求。面向地块的分类方法在以往的研究中被证明可以很好地克服上述问题,尤其是在小规模农业盛行的地区要优于面向像素的分类方法[15-16]。但是目前还未有在不同时间序列数据下关于地块和像素提取方法的对比,也未有关于提取效率方面的评价。
综上所述,冬小麦种植区提取目前主要存在时间序列单一的问题,另外没有考虑到面向地块、像素方法与不同时序数据结合的适用性。因此本文利用GEE平台和Sentinel-2A/B数据评估了不同时间间隔(10、15和30 d)合成的时序数据对冬小麦提取精度的影响,明确了更适合提取冬小麦种植区的Sentinel-2A/B时序数据。同时对比了使用不同间隔的时序数据时面向地块和面向像素分类方法的优劣性,为扩大Sentinel-2A/B数据在作物分类中的应用提供了依据。
1 研究区和数据预处理
1.1 研究区概况
本文研究区胶州市(36°00′N~36°30′N,119°37′E~120°12′E)位于山东省青岛市,占地面积为1 324 km2,总耕地面积82万亩,地貌类型有丘陵、平原、洼地和滨海低地4类。胶州市年无霜期210 d,平均气温12 ℃,有效积温4 599.2 ℃,日照时数2 170.5 h,降水量724.8 mm,为典型的暖温带半湿润季风区大陆性气候,四季分明,雨热同期,非常适宜小麦、马铃薯和花生等农作物的种植。
1.2 作物物候期
通过实地调查了解到研究区内农作物多种多样,主要种植的农作物有冬小麦、马铃薯、花生和玉米等。该地玉米年耕种2次,冬小麦、马铃薯和花生则耕种一次,典型地表类型包括冬小麦-夏玉米双熟制耕地、马铃薯-夏玉米双熟制耕地、蔬菜-春玉米双熟制耕地和花生单熟制耕地。冬小麦一般在10月初播种,12月下旬进入越冬期,翌年3月开始返青生长,4月进入生长旺期,6月中旬以前基本收割完毕,生长期大概8个月。本研究将2020年10月—2021年6月(共270 d)作为研究期,使用DOW(Day of Wheat)表示研究期内的时间,表1为研究期内胶州市主要农作物的关键物候期。
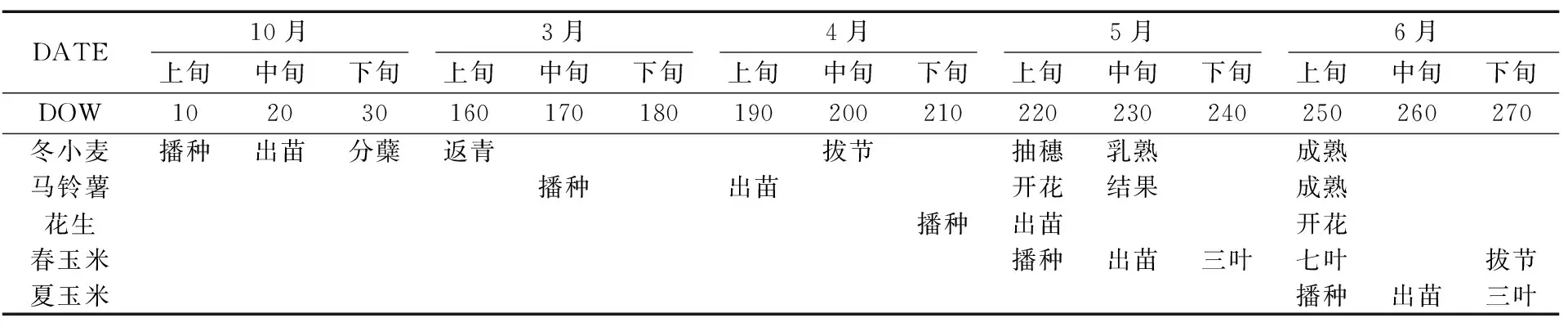
表1 胶州市主要农作物物候期
1.3 卫星数据及预处理
Sentinel-2是一种高分辨率多光谱成像卫星,携带有一枚多光谱成像仪(MSI),包括Sentinel-2A和Sentinel-2B两颗卫星,一起提供5 d间隔的影像。GEE平台提供了2种级别的Sentinel-2A/B数据:Level-1C和Level-2A。Level-1C级产品是指经过了辐射定标、几何校正(主要包括正射校正、空间配准操作)的大气表层(Top-of-Atmosphere,TOA)反射率数据,Level-2A级产品则是在Level-1C级产品的基础上又经过了大气校正的地表反射率(Surface Reflectance,SR)数据[17]。本次研究使用Sentinel-2 SR数据集,已经消除了大气吸收以及各项散射作用造成的误差,能够反演地物真实的表面反射率,使得作物分类更加准确。数据共含有12个光谱波段,分别具有不同的空间分辨率(10,20,60 m),具体的数据介绍如表2所示。
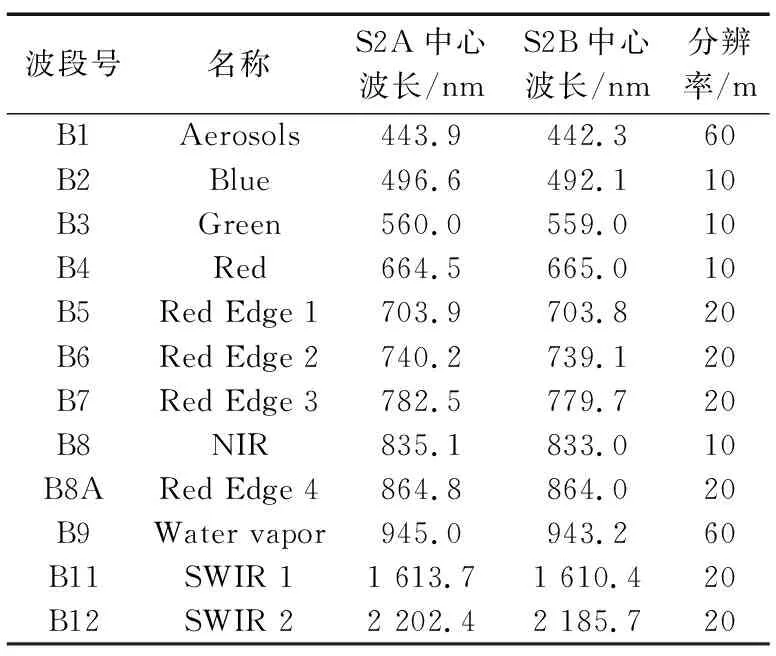
表2 Sentinel-2A/B Level-2A数据介绍
研究期内共218景影像,由于原始数据是按10 000倍缩放的SR数据,将每景影像除以10 000获得真实单位的地表反射率数据。另外,数据还有3个QA(Quality Assessment)波段,其中的QA60波段存储有云掩膜信息,利用它消除Sentinel-2A/B数据中被云和阴影污染的观测,又使用线性插值的方法填补去云留下的缺失,以实现整个时间、空间域的完全覆盖。
1.4 地面调查数据
样本数据来源于2021年3月和5月胶州市野外实地调查数据,共获得436个样本点,其中冬小麦212个,非冬小麦224个。采样时记录样本的经纬度及作物类别,并拍摄照片方便后续核查。
2 材料和方法
本研究主要包括以下2个部分。首先,利用图像分割技术从高分辨率影像中提取胶州市的地块,为了避免非农作物区域的干扰,将非耕地地块剔除。然后,在GEE平台中使用实地调查得到的样本结合构造的作物时序特征作为输入,训练基于RF算法的冬小麦分类器,将分类器分别应用于耕地地块或像素,以实现胶州市冬小麦的提取。研究的技术路线如图1所示。

图1 技术路线Fig.1 Technical route
2.1 耕地地块获取
在面向地块的分类方法中地块的获取过程至关重要,地块与真实地物的符合程度直接影响信息提取的正确与否。图像分割的过程其实是相邻同质像素的结合和异质像素的分离过程,在尽量减少图像信息损失的基础上将图像分割成有意义的多边形对象[18]。每个多边形代表一个实地地物,内部具有相同光谱、纹理等信息。
本文使用易康(eCognition)软件的多尺度分割方法获得耕地地块,影像为下载得到的2021年4月胶州市GF2 PMS数据,经过正射校正、波段融合后,空间分辨率达到了1 m。为了使分割结果与影像更加吻合,经过多次试验达到了最佳效果,分割尺度设置为50,形状因子为 0.3,紧致度为0.4。采用目视解译的方法将非耕地地块(主要包括建筑物、道路等)删除,只在耕地范围内作图,人工修正和细化边界后得到了99 733个农作物地块,局部效果如图2所示。近年来国家耕地保护政策十分严格,获得的耕地块矢量具有较长期的稳定性,可以重复利用。

图2 地块分割Fig.2 Parcel segmentation picture
2.2 随机森林分类
随机森林(RF)算法是Breiman在2001年提出的一种强大的机器学习算法[19],已经在不同领域有了广泛的应用,例如风险评估及预测、医学检验和金融投资等[20-22]。它是基于决策树弱分类器的集成学习算法,在利用集成算法优势的同时规避了单个分类器的缺点,比许多传统的分类器(如单层神经网络、最大似然法等)更具有准确性和鲁棒性[23]。RF的随机主要有2个方面:首先是对原始数据集采用bootstrap方法(随机且有放回的抽样方法)抽取多个训练集和其对应的测试集;其次是在生成决策树时随机抽取一部分特征用于树节点的分裂。最后每个决策树进行投票来确定最终分类结果。
RF算法的模型表示为:
(1)
式中,I表示示性函数;Y表示预测结果;hi(Si)表示单颗决策树。
RF分类步骤如下:
① 从原始数据集N中随机且有放回地抽取n个样本,重复n次,而未抽中的样本组成袋外数据集(OOB),作为测试数据;
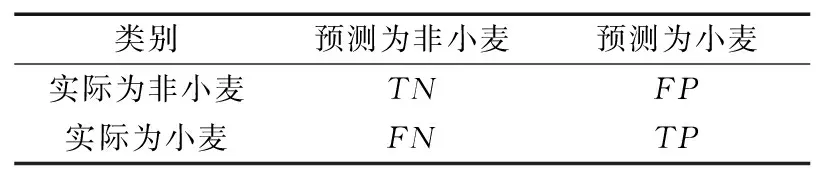
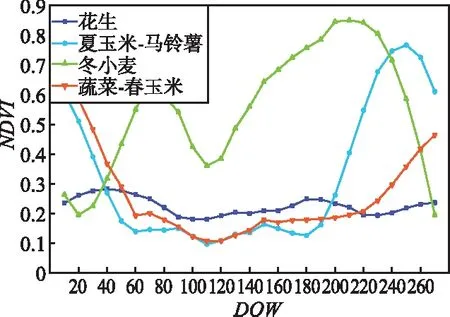
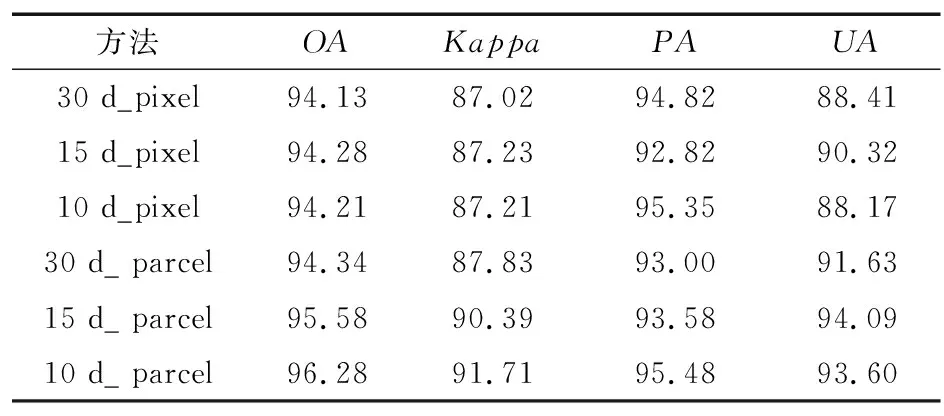
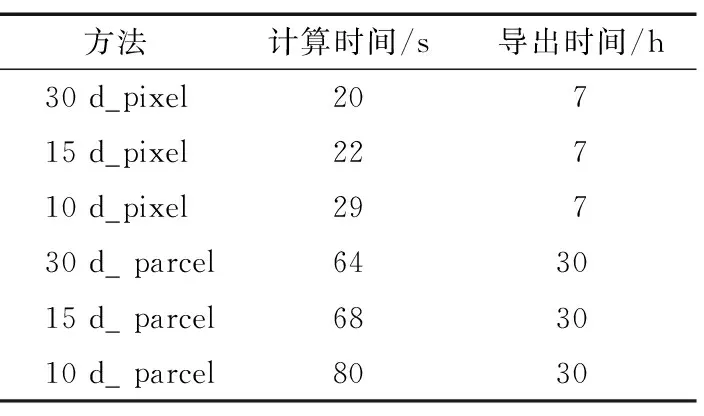
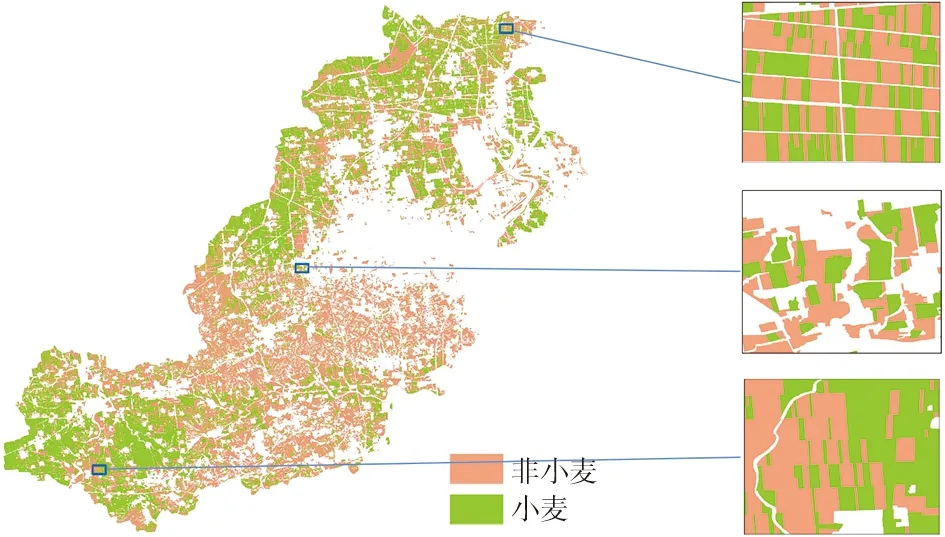
② 从特征集合M中随机抽取m个作为特征子集,且m ③ 基尼指数能够选出数据集的最佳分界点,找出使每棵决策树的基尼指数最小的特征作为最优特征,其对应的切分点作为最优切分点,然后将剩余训练数据应用到下面的2个子节点中; ④ 在每个子节点上重复进行步骤③,直到分割完所有节点; ⑤ 重复进行步骤②~步骤④,得到需要数量的决策树; ⑥ 每一颗决策树都会对测试数据集中的每一条数据进行投票,统计得票最多的类别即为该样本的最终类别。 RF算法有着较高的准确性,GEE平台中的RF算法已成功用于检测土地利用变化和作物分类等研究中,本研究将它运用在冬小麦提取中。 2.2.1 光谱特征计算 NDVI是监测作物生长状态的最佳指示因子,还能反映出植物冠层的背景(如土壤、潮湿地面、雪和枯叶等)影响,当土地还未耕作时裸露地表的NDVI指数值接近0。NDVI计算公式为: (2) 式中,ρNIR为近红外波段的反射率;ρR为红波段的反射率。 EVI设置了更窄的红边波段,可以减少水汽的影响,加强了对植被稀疏地区的监测能力。另外,它引入的蓝光波段能够降低土壤背景和大气噪声的干扰,可稳定地反映地表植被特征。EVI计算公式为: (3) 式中,ρNIR为近红外波段的反射率;ρR为红波段的反射率;ρB为蓝波段的反射率。 2.2.2 时序数据分析及合成 为了对比不同时间间隔的合成对时序曲线的影响,本文结合Sentinel-2A/B NDVI,EVI时间序列数据和实地调查的样本数据,绘制不同作物原始的NDVI,EVI时间序列曲线。由于受到云、水汽、气溶胶和传感器等因素的干扰,时间序列数据容易出现异常值,时间序列曲线出现不规则波动现象,对波谱分析和特征构造造成不可忽略的影响[24]。平滑和去噪操作可以更加真实地反映各种作物的生长曲线,本文采用S-G(Savitzky-Golay)滤波方法重构Sentinel-2A/B的时间序列数据,设置移动窗口大小为7(70 d观测值),多项式次数为3。图3为经过平滑后的作物NDVI,EVI时间序列曲线,横坐标表示日期,纵轴表示NDVI,EVI的值。 (a) NDVI时序曲线 由NDVI时间序列曲线可以看出,冬小麦曲线整体呈现“两峰一谷”的趋势。夏玉米在9月下旬—10月上旬收获,然后冬小麦开始播种,7 d左右出苗,NDVI逐渐增大;12月份出现一个小的波峰,然后开始冬眠,光合作用衰减,NDVI逐渐减小;波谷在1月份出现;在2—3月份开始返青、起身,NDVI迅速升高;4月中下旬—5月上旬进入抽穗期,达到第2个波峰;6月成熟后收获,植被指数值明显下降。花生、春玉米和马铃薯都是春季作物,一般去年的夏季作物收获之后都会为其保留耕地,NDVI值较低,在11月中旬—次年4月都与冬小麦曲线有着明显差异。EVI曲线与NDVI较为类似,冬小麦曲线也有着“两峰一谷”的形态,在11月中旬—次年4月都是区分冬小麦的关键时期。 由于影像众多,且直接使用单景影像易受到异常值的干扰,虽然进行了滤波处理但是作物曲线依然出现了振荡现象。本文分别取DOW 1~270中的每10,15,30 d的均值合成一景新的影像,得到NDVI,EVI的不同时间间隔合成的时序影像。面向地块的分类方法最后还要计算每个地块内的均值作为地块的特征。 2.2.3 特征选择 经过以上计算,得到了不同时间间隔合成的时序特征,如表3所示。 表3 时序特征 多光谱时序数据在提供更多光谱信息的同时,也带来了高维输入和输出的新挑战。由于大量光谱特征可能会携带高度相关的信息,增加模型的计算负担,出现过拟合现象。因此特征选择显得十分重要,它在很大程度上决定机器学习算法的效率。RF允许使用基尼指数在分类时对特征重要性进行评价。因此使用GEE中的评价方法对特征波段进行排序,最后分别保留14~24个最佳特征进行冬小麦的提取。 2.2.4 模型训练和分类 在进行地块级别的分类时,由于胶州市面积较大,地块数量较多,将它分为3个区分别计算和导出结果。面向地块的分类方法将冬小麦样本所属的地块标记为1,非冬小麦地块标记为0;面向像素的分类方法将冬小麦样本点标记为1,非冬小麦点标记为0。最后将样本分别按照7∶3的比例随机分为训练样本和验证样本。将样本和特征都导入RF分类器中进行分类,设置RF的参数如下:① numberOfTrees,树数代表建立RF模型的决策树的数量,在一定范围内随着树数的增多,精度可能会略有提高,设置为500;② seed,随机种子设置为999;③ 其他几个参数,maxNodes(每棵树中叶节点的最大数目)、minLeafPopulation(叶节点所需的最小样本数)、bagFraction(每棵树输入到bag的分数)、variablesPerSplit(每次分割的变量数)保持默认设置。 为了方便与面向像素的分类方法进行对比,基于像素的冬小麦提取也使用多尺度分割得到的耕地地块进行掩膜,时序特征及样本也与面向地块的分类方法保持一致。 评价指标用来定量的衡量一个算法性能的优劣水平。混淆矩阵是最常用的方式,能一目了然地展示出分类结果和地表真实信息的差异,如表4所示。 表4 混淆矩阵 将真实类别为非小麦的样本称为负类,真实类别为小麦的样本称为正类,TN(True Negative)代表负类的正确预测,FN(False Negative)代表正类的错误预测,FP(False Positive)代表负类的错误预测,TP(True Positive)代表正类的正确预测。样本总和为N,则: N=TN+FN+FP+TP。 (4) 常用的几种精度评价方式:总体分类精度(OA)、Kappa系数、生产者精度(PA)和用户精度(UA)都是基于混淆矩阵计算的。OA表示正确分类的像元(地块)总和除以总像元(地块)数,计算公式如下: (5) 但是OA只考虑分类正确的比例,不能对模型性能的好坏做出评价。Kappa系数不仅考虑了被正确分类的像素(地块),又综合了各种错分和漏分误差,是更为全面的评价指标。Kappa系数计算公式为: (6) 式中, (7) (8) 生产者精度是指分类器将所有像素(地块)正确分为某类和某类真实总数的比例,例如冬小麦类别的生产者精度计算公式为: (9) 用户精度是指正确分到某类的像素(地块)数与分类器分为某类的总数的比例,例如冬小麦类别的用户精度计算公式为: 1.2.2 培训方法 我院临床技能培训中心采用儿童仿真模型模拟临床环境对学员进行培训,内容包括理论及技能操作培训,形式为教师讲解、视频演示、边看边做、实战演练等。 (10) 图4为冬小麦生长期内(DOW 0~270)不同时间间隔合成的作物生长曲线图,横轴表示时间,纵轴表示NDVI,EVI的值。 (a) 10 d_NDVI 经过时间合成以后,曲线变得更加平滑也消除了一些异常波动,并且合成的时间间隔越长,作物曲线越平滑,但同时也失去了更多的细节,比如30 d合成的冬小麦NDVI,EVI时序曲线均不再呈现“两峰一谷”的形态。时间间隔为10 d和15 d的曲线既抵消了一些干扰也保留了作物生长的细节变化,在不同特征的曲线中冬小麦与其他作物的差异都比较明显。 为了检验本文方法的有效性,对比不同时序数据以及地块和像素级别分类的优劣性,分别使用定性和定量的方式评价最终分类结果。定量方法即使用第2节中的评价指标进行对比分析,定性方法主要将提取结果与遥感影像进行对比,目视评判冬小麦提取效果,主要包括下面几个方面:① 判断冬小麦提取区域是否全面;② 判断是否存在误提现象;③ 基于像素的提取方法孤立像素现象是否严重。 本文使用多尺度分割时利用的GF2 1m分辨率影像与各种方法得到的提取结果进行局部对比,图5为典型区域的原始影像,冬小麦表现为深绿色,图6、图7和图8分别为这些区域对应的提取结果。 (a) 规整区域 (a) 30 d_像元 (a) 30 d_像元 (a) 30 d_像元 在图6中,30 d和15 d合成的地块、像素级别的提取均存在一定程度的误提现象;10 d合成的像素级别的提取有少部分的漏提;10 d合成的地块级别的提取结果符合影像显示的冬小麦区域。在图7中,地块的不规整增大了提取的难度,基于像素的提取结果漏提现象严重;30 d和15 d合成的地块级提取也出现了漏提现象;10 d合成的地块级提取结果较为全面准确。图8中,在复杂种植区域,基于像素的提取结果漏提和孤立像素现象都比较严重,提取效果不佳;30 d合成的地块级提取有小面积的漏提,15 d和10 d合成的地块级别的提取结果一致,在复杂种植区域的提取结果也较为理想。整体来看,地块和像素级别的提取效果都会随着合成时间序列数据时间间隔的缩小变得更好;当时间间隔相同时,地块级别的提取并不全都优于像素级别的提取,但随着时间间隔的缩小地块级别的提取进步明显,10 d合成的面向地块的提取方法总是最优的,几乎没有出现错提、漏提现象。 表5为最终得到的一系列量化结果,包括不同提取方法得到的OA、Kappa系数、冬小麦的PA和UA。 表5 冬小麦提取精度 以上方法均得到了较高的精度,证明了利用规律时间间隔合成的时间序列影像进行分类的有效性。整体而言,与基于像素的分类结果相比,面向地块的分类方法都得到了更高的OA和Kappa系数,但PA和UA并不全都高于基于像素的分类。并且总体趋势显示,当合成Sentinel-2A/B影像的时间间隔越短时,冬小麦提取的精度越高。15 d和10 d合成时间间隔相差不大,提取精度相差不大。 表6为各种冬小麦提取方法所需要的计算时间和结果导出的时间。 表6 冬小麦提取时间对比 无论是计算时间还是导出时间,不同时间序列下地块级别的提取之间或者像素级别的提取之间都相差不大,真正对提取时间产生影响的不是不同时间序列的合成方法,而是面向不同元素的分类方法。地块与像素级别的提取在计算时间上最多相差3倍,但都在1 min之内,因此对计算效率的对比评价意义不大;然而在结果的导出上,二者相差了23 h,将近一天的时间,由于面向像素的分类方法精度也在比较高的水平,当在时间紧急的情况下,面向地块的分类方法优势不大。 通常在种植结构单一、农田连片区域的冬小麦更容易识别,但在地块破碎区域由于内部的光谱变异和边界的光谱混合导致识别较为困难。本文的研究区为整个胶州市,地块数量众多、类型多样,方法具有普适性。由以上对比结果得知,10 d合成的面向地块的分类方法精度更高,提取效果更好,因此利用此方法做出2021年的胶州市冬小麦种植分布图,如图9所示,可以明显看出,冬小麦种植区主要分布在胶州市的北部和西南部。 图9 2021年胶州市冬小麦空间分布Fig.9 Spatial distribution map of winter wheat in Jiaozhou in 2021 本文使用不同时间间隔合成的Sentinel-2A/B时间序列数据,提取了胶州市的冬小麦种植区,主要为了探索更适合提取冬小麦的时序数据与方法。为了对比在不同时序数据下面向像素和面向地块的分类结果,2种方法在完全相同的条件下进行。结果表明:① 当Sentinel-2A/B合成影像的时间间隔缩短时,可以为冬小麦与其他作物的区分提供更多信息,地块和像素级别的提取准确度都会更高;② 在相同的时序数据下,面向地块的分类方法并不总是优于面向地块的分类方法,但可以明显改善面向像素分类结果中常见的“椒盐现象”,且随着合成时间序列数据时间间隔的缩小进步更明显。同时,更短时间间隔(10 d)合成的Sentinel-2时序数据结合面向地块的分类方法,对冬小麦的提取帮助更大,在一些不规整、复杂种植区域也获得了很好的提取效果;③ 由于地块级别的结果导出时间较长,当对精度和提取效果要求较高而时间比较充裕时,选择地块级别的分类更加合适;当对时间的要求较高而对精度的需求较低时,面向像素的分类更加符合条件。分类是不断优化的过程,随着遥感卫星研发技术、计算机和云平台计算能力的不断提高,现有的分类算法也在逐渐改进,未来更高级的图像分割技术与更强大的云平台计算能力的结合将获得更加准确的冬小麦种植区提取结果。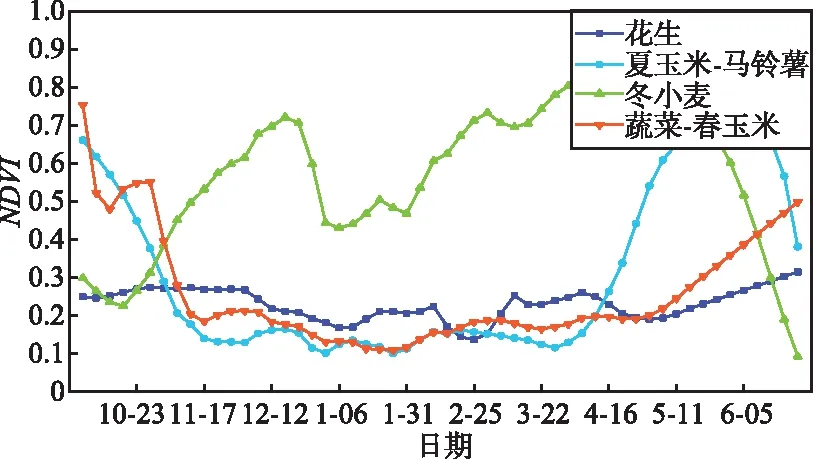

2.3 结果评价指标
3 结果与评价
3.1 时序曲线对比
3.2 定性评价




3.3 定量评价
3.4 效率评价
4 冬小麦分布
5 结束语
