基于信息融合的典型工况感知算法研究
2021-12-11王梦园甘海云袁志宏
王梦园,甘海云*,袁志宏
基于信息融合的典型工况感知算法研究
王梦园1,2,甘海云1,2*,袁志宏3
(1.天津职业技术师范大学汽车与交通学院,天津 300222;2.智能车路协同与安全技术国家地方联合工程研究中心,天津 300084;3.山东大学能源与动力工程学院,山东 济南 250061)
针对自动驾驶频发交通事故的问题,结合中国道路的典型工况,文章基于信息融合的理念,将毫米波雷达与摄像头融合的目标检测的结果进行融合来解决盲区中行人横向穿越道路的小目标检测问题。首先将毫米波雷达和摄像头环境感知的信息进行融合;然后通过yolov2目标检测算法对相邻车道前方车辆进行检测;最后,对车辆前方划定ROI(Region of Interest),并通过yolov3-bt对ROI进行检测。实验对比结果表明,对车辆前方出现行人这一现象,毫米波雷达与摄像头信息融合的方法比单视觉算法检测提前135帧,即检测时间提前4.5 s,提升了17.8%。表明文章提出的毫米波雷达与摄像头信息融合的方法可以进一步提高自动驾驶车辆行驶的安全性。
自动驾驶;环境感知;信息融合;目标检测
前言
智能网联汽车的快速发展在带来许多便利的同时也引发了许多安全问题。就自动驾驶频频发生的事故而言,2016年5月,美国佛罗里达州一辆开启自动驾驶模式的特斯拉与白色卡车相撞,导致特斯拉车主身亡[1]。2019年11月7日,Uber的一辆自动驾驶SUV与一位横穿马路的女士相撞,造成该女士的死亡[2]。2021年3月11日下午,美国底特律市一辆特斯拉Model Y撞上了一辆白色半挂卡车,从车祸现场来看,地面并没有刹车的迹象,推测该车的自动驾驶系统可能把白色卡车货箱识别成天空。当前随着人工智能技术的发展,自动驾驶的技术路线方案也各不相同,但结合自动驾驶车辆事故的数据来看,当前自动驾驶车辆在某些危险场景中,如视线盲区、夜间、雨雪天气等,自动驾驶车辆的感知效果的性能仍然有很多不足。
根据国家汽车安全统计数据,94%的交通事故是由人为因素造成的,而在所有人为因素里,94%的人为事故中80%是由于驾驶员在交通事故的前3秒的时间内未注意到路况。实际上,驾驶员在驾驶时,其视线很容易被道路两旁的障碍物遮挡,司机没有及时发现目标并且做出相应的制动,从而造成事故的发生。而当前的汽车自动驾驶系统在面对驾驶视觉盲区时,往往不能提前对车辆前方障碍物进行识别。为了提高自动驾驶环境感知系统识别的准确性,以防交通事故的发生,本文基于信息融合的理念,将毫米波雷达与摄像头融合的目标检测方法来解决盲区中行人横向穿越道路的小目标检测问题。
1 典型工况场景分析
众所周知,在驾驶员开车的过程中,除正常视野之外,还存在一定的视觉盲区,若盲区检测问题不能有效解决,那么自动驾驶车辆中环境感知就会存在一定的缺陷,这些盲区场景往往是由于其他物体的遮挡,若突然出现行人或车辆时,驾驶员毫无防备,将会导致事故的发生。随着智能车辆的发展,这类车辆配有环境感知系统,像人类的眼睛一样感知周围的环境,为后续车辆的控制系统提供相应的信息,从而进行本车的决策。本文主要是针对交通道路环境下,突然出现在前车侧边前方的行人目标检测,现有的视觉感知算法往往是在行人基本全部出现在视野中才能被准确地检测到,而当面对前方车辆侧边突然横穿的行人时,由于车辆的遮挡,往往是先出现人的头部或者手脚等,其检测的泛化能力和准确性差。基于此,本文根据出现在视线中的人体的部分特征来判断前方是否存在行人,这将有效解决自动驾驶盲区检测的问题,提升驾驶安全性。
2 方案场景设计
本文在对自动驾驶车辆毫米波雷达以及摄像头进行信息融合时,由于决策层融合是信息融合中的最后一级,其偏向于应用层面;另外特征层融合在毫米波雷达数据处理上存在一定的困难[3-5]。鉴于此,考虑到毫米波雷达和摄像头在不同场景下的精度,本文在数据层融合方面进行研究。
2.1 数据融合平台搭建
本文为了解决盲区中行人横向穿越的中国典型道路场景的前方障碍物检测问题,以我国某自主品牌乘用车为平台,并搭建LEOPARD IMAGING摄像头和大陆ARS408毫米波雷达的融合平台。
2.1.1基于感兴趣区域的空间融合方案
由于毫米波雷达ARS408和摄像头单独获取物体信息时采取的参考系不同,因此需要将毫米波雷达与摄像头采集到的信息在空间上进行统一,分别将两者获取的信息转换到同一坐标系下,转换过程如下:
(1)雷达投影坐标系转换成摄像头投影坐标系。
坐标系转换示意图如图1,将摄像头与雷达坐标系投影到地面上,得到对应的投影坐标系。
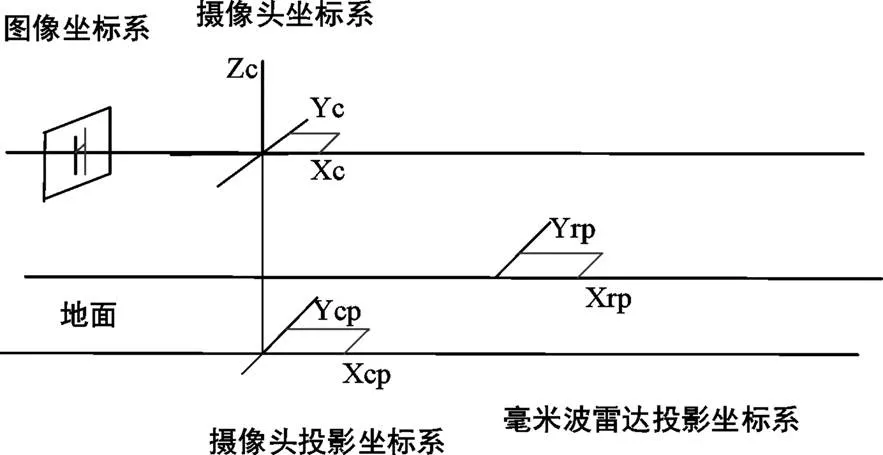
图1 雷达投影与摄像头投影坐标系转换示意图
假设车辆前方物体在雷达投影坐标系下的坐标为(X,Y),而其在摄像头投影坐标系下坐标为(X,Y),由公式(1)可以将两者进行空间转换。其中0,0分别为两投影坐标系、轴方向的距离。

(2)图像坐标系转换到摄像头坐标系。
图像坐标系是三维坐标,因此根据图像坐标系下的坐标能够计算出车辆前方物体的高度。图像坐标系与摄像头坐标系之间得相互转换如图2所示。
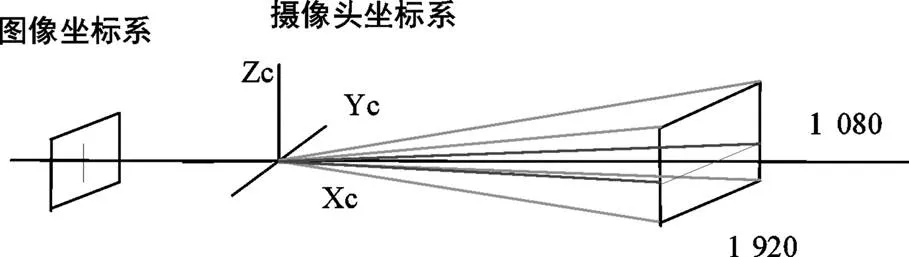
图2 图像坐标系与摄像头坐标系相互转换示意图
摄像头技术参数如表1。利用水平视场角和垂直方向分辨率的比例关系完成坐标系转换,可求出障碍物高度。
表1 摄像头技术参数
技术参数垂直视场角/°水平视场角/°水平方向分辨率垂直方向分辨率 数值31581 9201 080
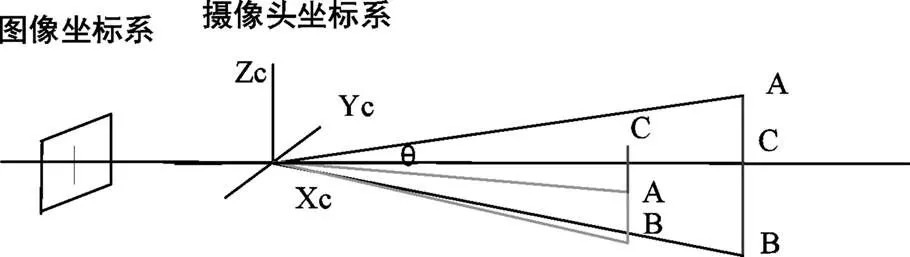
图3 图像坐标系转换成摄像头坐标系
如图3所示,摄像头能实现障碍物检测,由检测结果得、点的像素坐标,参考目标上侧的点,得到障碍物在摄像头坐标系下的信息,进而求得的像素值P。从而根据式(2)求出值。

结合摄像头坐标系中的X,求的高度H,即障碍物Z的坐标。

通过不同坐标系的转换,使得摄像头与毫米波雷达的信息能够互相补充,信息共享,确保了毫米波雷达与摄像头探测到的是同一目标,能够准确描述前方障碍物的距离和高度信息,为智能车辆提供更加精准的环境信息。
2.1.2时间数据融合
在摄像头和雷达在空间坐标达到统一的条件下,还需要毫米波雷达与摄像头采集的数据在同一时刻,实现时间上的对应统一。
本文数据融合平台所使用的雷达为德国大陆ARS408毫米波雷达,具有每秒能够采集79帧数据的能力,每帧数据间隔为13 ms;而LEOPARD IMAGING摄像头的拍摄频率是30 fps,即每帧图像数据间隔为33.3 ms。鉴于摄像头的采集周期比毫米波雷达长,为了更好地将其进行时间维度上的融合,以摄像机采样速率为基准,摄像机每采一帧图像,选取毫米波雷达上一帧缓存的数据,即完成共同采样一帧雷达与视觉融合的数据,从而保证了毫米波雷达数据和摄像机数据时间上的同步。
2.2 基于融合识别方案
本文在毫米波雷达和摄像头采集到的数据融合时,主要包括两部分,如图4所示。将毫米波雷达经过采集和滤波处理得到的有效目标数据,投影到摄像头采集到的图像上,从而形成ROI;然后利用摄像头传感器对ROI进行检测,判断出车辆前方障碍物的种类。

图4 融合思路
而对于盲区中行人横向穿越场景这一特殊检测情形,其产生驾驶员视觉盲区的主要原因是相邻车道的车辆。为了提高检测的泛化能力与准确性,本文利用摄像头传感器对相邻车道前方车辆进行检测,若相邻车道前方出现车辆,对其前方划定ROI,并对ROI利用yolov3-bt[6-7]进行目标检测,详细的检测方案如图5所示。

图5 小目标检测方案
3 实验验证与结果分析
为了对比视觉检测准确率与本文融合算法准确率的差距,体现融合算法的优势,需要采集相应的目标数据集,在深度学习的Darknet框架下,训练网络模型,之后进行测试验证,而融合方面需要建立一个毫米波雷达与摄像头两者融合的软硬件系统,最后将该系统应用到实车检测。
3.1 试验平台介绍
本文融合实验的环境感知系统是基于现有的实验车设备,在数据采集的车辆上,安装毫米波雷达与摄像头,位置如图6所示。该车配有一台开发信息采集系统的工控机,能够对采集的信息进行保存,录制视频,同时具有回放的功能。该系统可分别通过USB线和周立功CAN卡接收毫米波雷达与摄像头的信息。

图6 环境感知采集系统
3.2 数据集的采集与制作
深度学习网络模型的性能往往取决于数据集是否合适,若是训练车辆检测模型,就需要提前在数据集上标注车辆的信息,同样,若是小目标针对人头的检测,就需要相应的数据集,然而,目前常用的开源数据集有VOC与COCO,虽然这两大数据集包括大量的行人、车辆等其他目标,但是对于突然出现的小目标的数据少之又少。因此本文针对小目标进行数据集的制作。
3.2.1数据采集
首先在学校内选取经常有学生走动的道路进行所需的数据集,视频采集的过程按照车辆视角,采集突然出现在小轿车与模拟公交车前的行人目标特征,摄像机采集图片的高度和车辆安装摄像头的高度保持一致。具体采集过程如下:
(1)模拟公交车前出现行人。因为公交车高于行人,所以若突然出现行人时,其特征为:胳膊、腿,半身、头部等。
(2)模拟轿车前出现行人。一般人的身高比家用轿车高,所以若从侧边突然出现行人时,首先视觉系统下出现的特征是头部,然后是胳膊,腿等。

图7 数据集整理
本文通过录制视频进行数据集的采集,采集完成后通过视频解析算法将视频分为一帧帧图片,为了提升数据集的质量,要对重复性大的图片进行筛选与剔除。得到有效的数据集如图7所示。
3.2.2数据集制作
通过上文的介绍,本文的典型场景为突然在车辆前方的行人头部位置。所以,首先需要训练识别大量行人的头部。根据解析之后的图片可知,人体的头部在整个场景中的占比很小,并且距离越远,行人头部信息越少,如果不找出头部出现的区域,直接训练,会造成训练时间长,检测结果差。由此本文提出对小目标出现的感兴趣区域进行检测。
首先,根据训练好的车辆检测模型,对图片进行检测,选取距离本车比较近的目标车辆,截取车辆周围环境。根据车辆检测框的中心位置,感兴趣区域宽度和高度的像素分别为320、224。如图8所示。

图8 形成的感兴趣区域图
其次,只保留所需的感兴趣区域,其他区域删除,得到宽度和高度的像素分别为320、224的图片集。如图9所示,与图8相比,感兴趣区域内的目标较少,干扰信号大大降低,缩短了训练周期。
本文采用数据标注软件LebelImg完成标注,框出图片中所存在行人头部进行标注,保存yolo格式得标签文件,得到图片与该图片相对应得标签文件夹。最终的数据集如图10所示。

图9 最终的感兴趣区域图

图10 数据集汇总图
3.3 实车验证
将已完成的数据集进行训练,并把模型加载到工控机中,然后选择某一检测场景,分别利用单一摄像头以及本文的融合检测方案进行目标检测。
3.3.1普通交通场景检测结果与分析
选取包含相邻车道与对向车道的普通交通道路,如图11所示,视觉检测结果如图12所示,该场景下的车辆目标基本都会被检测并标记出来。毫米波与摄像头融合的检测结果如图13所示,首先是融合的第一步,假设产生,雷达对前方目标进行检测,在图上以绿点表示雷达的检测结果。其次是将雷达的检测结果通过坐标系之间的转换投影到图像上形成一个ROI[7-8],融合的第二步是假设验证过程,视觉系统的检测只需在此感兴趣区域内进行,相对于原图片,缩小了视觉检测的范围,周围的干扰信号也大大减少,检测性能有所提升。在相同的硬件与软件环境下,确保被检测的图片有相同的分辨率,单一摄像头的检测时间与融合的检测时间对比如表2所示。最终加上雷达的检测时间为24.53 ms,明显高于单一视觉的检测结果29.89 ms。在检测时间方面提高17.8%。

图11 交通场景图

图12 摄像头检测结果

图13 融合方案检测结果
表2 两种方案检测时间对比
方案算法检测时间/ms 摄像头方案Yolov3-bt-41629.89 融合方案Radar+Yolov3-bt-41624.53
由于校园环境条件有限,只能根据现有的条件模拟普通交通场景图14,分别用单一视觉与融合方案检测本车前方没有任何遮挡的车辆与行人,将视觉检测与融合检测结果与目标的实际尺寸进行对比,实验检测结果如图15、16所示。目标的尺寸大小对比如表3所示。由表可知,本文融合方案的检测效果更加贴近目标的真实尺寸。

图14 模拟交通场景图

图15 Yolov3-bt目标检测算法结果

图16 Radar+Yolov3-bt目标检测算法结果
表3 实验结果
类别车辆行人单位 目标宽目标高目标宽目标高 真实尺寸120903073像素 Yolov3-bt1501104589 Radar+Yolov3-bt1311023680
3.3.2典型交通场景检测结果与分析
在校园内模拟搭建典型的十字交通路口,如图17所示,存在从侧边突然出现小目标的典型危险场景如图17里框所示,即为视觉检测的感兴趣区域。常用的视觉检测算法往往是对该场景下的所有目标进行检测,存在两处不足,一是无法及时检测“鬼探头”式的小目标(本文为行人头部),二是针对场景下的所有目标进行检测,干扰信号多,检测性能差,检测速度慢[9]。通过本文的融合算法,首先以车辆为基准划定感兴趣区域,如图17的绿色框所示,针对感兴趣区域进行探测,大大减少了计算量,提升了检测速率;其次本文毫米波雷达与视觉融合方案,提升了小目标的检测准确率;有效解决了这两处不足。同时,若大量训练行人的特征,也能在交通场景中及时准确的识别出行人目标。

图17 典型道路交通场景

图18 yolov3-bt检测效果

图19 改进后的检测效果
此外,针对车辆前方出现行人这一典型工况,本文改进后的融合算法优于单一视觉的检测结果。本文以典型的行人突然从侧边出现在车辆前方为场景,如图19所示。普通视觉检测算法只能在行人基本完全出现在视野中才能检测到,如图21所示,然而本文改进后的算法在人体的头部刚刚出现在视野中时即可被探测到,如图22所示。此外,选取校园内多种典型场景,大量实验对比结果如表4所示,本文的方案比普通视觉检测方法平均提前了135帧,根据摄像头每秒30帧图片得出,检测时间提前4.5 s。根据实验发现,摄像头在该典型场景下,平均最远能够在21.7米的距离处检测到行人的人头。若自动驾驶车辆在这种典型的复杂场景下以20 km/h的速度行驶时,从发现行人到汽车制动大约有3.95 s的反应与制动时间,符合智能驾驶汽车实时性的要求。

图20 小目标检测场景

图21 普通算法行人检测结果

图22 改进后的算法行人检测结果
表4 测试数据记录
场景搭建yolov3-btYolov3-bt-head相差帧数 第一组18652134 第二组20560145 第三组15732125 第四组18848140 第五组17242130 第六组17236136 平均值135
4 结论
本文提出了一种毫米波雷达与摄像头信息融合的方法来解决中国典型工况的问题。实验对比结果表明,对车辆前方出现行人这一现象,毫米波雷达与摄像头信息融合的方法比单视觉算法检测提前135帧,即检测时间提前4.5 s,提升了17.8%。表明本文提出的毫米波雷达与摄像头信息融合的方法可以进一步提高自动驾驶车辆行驶的安全性。
[1] 刘葳漪.无人驾驶技术不会因特斯拉停摆[N].北京商报,2016-7-5.
[2] Self-Driving Uber Car Kills Pedestrian in Arizona, Where Robots Roam[EB/OL].(2018-03-19)[2018-03-30].https://www.nytimes.com/2018/03/19/technology/uber-driverless-fatality.html.
[3] 谭力凡.机器视觉与毫米波雷达融合的前方车辆检测方法研究[D].长沙:湖南大学,2018.
[4] 梁翼.基于毫米波雷达及深度学习视觉信息融合的前方车辆检测方法研究[D].广州:华南理工大学,2019.
[5] 陈晓伟.汽车前方车辆识别的雷达和视觉信息融合算法开发[D].长春:吉林大学,2016.
[6] N Long,Wang K,Cheng R, et al.Unifying obstacle detection, recogni- tion, and fusion based on millimeter wave radar and RGB-depth sensors for the visually impaired[J].Review of Scientific Instrumen- ts,2019,90(4):044102.
[7] Chen X, Ma H, Wan J, et al. Multi-View 3D Object Detection Netw- ork for Autonomous Driving[C].2017 IEEE Conference on Compu- ter Vision and Pattern Recognition (CVPR). IEEE, 2017. Redmon J, Farhadi A.YOLOv3:an incremental improvement[J].arXiv,1804. 02767v1,2018.
[8] 宋伟杰.基于毫米波雷达与机器视觉融合的车辆检测技术研究[D].合肥:合肥工业大学,2020.
[9] He K,Zhang X,Ren S,et al.Deep residual learning for image recogni- tion[C].Proceedings of the IEEE conference on computer vision and pattern recognition.2016:770-778.
Research on Typical Working Condition Perception Algorithm Based on Information Fusion
WANG Mengyuan1,2, GAN Haiyun1,2*, YUAN Zhihong3
(1.School of Automotive and Transportation, Tianjin University of Technology and Education,Tianjin 300222;2.National and Local Joint Engineering Center for Smart Vehicle-Road Collaboration and Safely Technology, Tianjin 300084;3.College of Energy and Power Engineering, Shandong University, Shandong Jinan 250061)
Aiming at the frequent traffic accidents of autonomous driving, combined with the typical working conditions of Chinese roads, an information fusion scheme is proposed in this paper. Firstly, the millimeter-wave radar and camera are used to perceive the front environment, and the collected information is fused. Secondly, the front right vehicle is detected based on the yolov2 target detection algorithm, which forms the trigger condition for the appearance of a specific scene. Finally, the area of interest in front of the vehicle is divided, and the yolov3-bt algorithm is used for target detection in the area of interest to solve the problem of small target detection under typical working conditions. Through experimental comparison, it is found that the fusion algorithm improves the detection time by 17.8% compared with the ordinary vision detection algorithm. Aiming at the phenomenon of pedestrians in front of the vehicle, compared with ordinary visual detection algorithms, the improved algorithm is advanced by 135 frames on average, and the corresponding detection time is advanced by 4.5s, thereby further improving the safety of intelligent driving vehicles.
Autonomous vehicles; Environment perception; Information fusion; Target detection
B
1671-7988(2021)22-17-07
U495
B
1671-7988(2021)22-17-07
CLC NO.:U495
王梦园,硕士研究生,就读于天津职业技术师范大学,研究方向:智能驾驶环境感知融合。
甘海云,博士、教授,就职于天津职业技术师范大学,研究方向:智能网联汽车。
基于封闭园区及开放道路的L4级智能网联汽车研发及示范运行(编号18ZXZNGX00230)。
10.16638/j.cnki.1671-7988.2021.022.005
