基于主动学习的遥感图像地块目标分类
2021-12-09屈晓渊张永恒
屈晓渊,张永恒
(榆林学院信息工程学院,陕西 榆林 719000)
0 引 言
机器学习(Machine Learning, ML)是一个多领域的交叉学科,主要研究内容是使计算机可以高度模拟人类的思维方式和学习能力[1],通过获取知识更新、重组知识结构等方式以达到不断完善的目的,其核心是从海量数据中进行自动分析,获取数据分布规律,并从发现的规律中对未知数据进行预测[2]。机器学习目前在数据挖掘[3]、人工智能[4]、计算机视觉[5]、医学图像分析[6]、金融证券预测[7]等众多场景和领域中取得重大突破。机器学习的主要研究内容有监督学习[8]、无监督学习[9]、半监督学习[10]和主动学习等方面。主动学习作为机器学习中一个重要的领域,其主要特点是通过一定方法的检索,在未标记的数据集中检索出最有意义的数据进行标记,以期提高模型的性能[11]。主动学习主要实现2个目标:一是通过已标注的数据集,使模型获得最佳性能;二是使用较小的标注数据集对模型的性能进行进一步优化[12]。在遥感图像分类研究中,机器学习的目标是选出最具有标记意义的数据进行标记,以最大限度地提高设计好的模型的性能。主动学习可以帮助实现2个目标:
1)通过对一定量未标记数据标记后以达到模型的最优性能[13]。假设遥感数据集中有50000份未标记的数据,如何选择性地标记5000份未标记数据,以实现模型性能的最优化。
2)用最小的数据标记代价获得模型的最优性能[14]。假设需要模型的判别准确率达到75.8%,如何通过标记最少的未标记数据来实现模型的准确率要求。
在遥感图像分类中,标记工作具有难度大、任务重和耗时长的特点,所以在为遥感图像数据创建标签之前,通常必须在非常大的遥感图像数据集中找到最有标注意义的遥感图像进行标注。因此,通过主动学习可以让标注人员只关注最相关的图像或图像中的信息[15],提高标记工作的整体效率,最大限度地降低标注成本。
1 主动学习在遥感图像分类方面的工作流程
遥感图像分类处理主要是通过深度学习模型来实现的,本文使用的是深度学习中的卷积神经网络[16](Convolutional Neural Network,CNN)。因为模型训练通常需要大量标注后的图像才能正常工作,通过主动学习可以很好地改善训练中缺少标注数据集的问题[17],提高模型的准确率。具体方法归纳为:周期性地在未标记数据集中选取部分原始遥感图像,通过检索算法找出未标记图像集的一个子集,通过对该子集进行标注来改善模型的性能。
主动学习的一般方法可描述为:对某一确定的计算方式和所有图像的数据集D,其中,已标注的图像数据集为A,未标记的图像数据集为B,和一个以CNN作为分类模型的M,那么将B中的某一图像Xi作为模型的输入,则输出的概率为:
p(Xi∈B)=M(Xi)
(1)
设未标记的图像数据集B中的N个遥感图像需由标记专家进行标记,通过选择和标记B中的N个后得到的已标记图像数据集B*,则有B*⊂B。本文研究的主要内容是在未标记的遥感图像数据集B中找到最优子集B*,使得通过B*对模型进行训练时,可得到最优的模型M。
在上述问题的描述中,主动学习的过程往往是迭代进行的,首先通过已标注数据集A对模型M进行初始训练,得到一个具有一定分类能力、但性能仍有待提高的模型。然后通过主动学习技术在图像数据集B中选择一个Xi,通过标记专家对Xi进行标记后用于模型的微调或者加入已标记数据集A中进行重新训练。当标记数量达到N个,或者在标记过程中模型性能达到预期阈值,或者查找的未标记图像始终在某一类数据分布中,在遥感图像上数据分布[18]可能表现为新地块、新地形、新区域等,则终止迭代。具体迭代流程如图1所示。

图1 主动学习的迭代流程图
2 主要方法
在遥感图像地块分类任务中,主动学习技术的主要目标是在未标记图像数据集B中筛选出合适的Xi,这是依照对Xi的信息化评估进行的,即在遥感图像Xi对模型M进行训练时能为模型M带来的信息量多少。信息量是用信息熵来表示的,根据信息论之父克劳德·香农对信息熵[19]的解释:信息熵是消除不确定性所需信息量的度量,也即未知事件可能含有的信息量[20]。对任意一个随机变量X,信息熵的定义如下:
(2)
信息熵具有以下3个特性:
1)单调性[21],发生概率越高的事件,其携带的信息量越低;
2)非负性,信息熵可以看作为一种广度量,非负性是一种合理的必然[22];
3)累加性,即多随机事件同时发生存在的总不确定性的量度是可以表示为各事件不确定性的量度的和,这也是广度量的一种体现[23]。
根据遥感图像地块分类所使用的CNN模型,主动学习按照不同方法在信息定义上也有所不同,下面讨论以下3种策略:基于不确定性的主动学习[24],基于代表性的主动学习[25],度量学习。
2.1 基于不确定性的主动学习
基于不确定性的主动学习可以选择出遥感图像地块分类的CNN模型无法区分的遥感地块信息。如图2所示,遥感图像中的某个地块,通过目前的模型无法准确进行分类,从模型的预测值可以看出,各个情况可能的概率大体相似,也就是模型预测出来的结果无法区分地块属性。

图2 具有不确定性的遥感图像地块分类
为了量化不确定性,对模型的后验分布用不确定度来衡量,其衡量准则如下:

(3)
(4)
其中,p(yi|xi)表示xi属于yi的概率。在得到xi的后验概率最大类别后将此类别的概率作为置信度,依次计算出每个类别的置信度,将置信度最低的交由标注专家进行标记。
2.2 基于代表性的主动学习
基于不确定性的主动学习方法有一个非常严重的缺点就是它们往往选出的图像非常相似。为了解决这一问题,本文提出一种基于代表性的主动学习方法,其目标是从未标记图像数据集B中选择出一个子集B*,使子集B*中的图像尽可能具有整个未标注数据集B中所有图像的代表性。求出最具有代表性图像子集B*的方法分为以下2步:
1)通过聚类的方式对已标注图像数据集A进行聚类分析,从而找到具有代表性的类别,在此步骤中不进行最后预测结果的分类。本文通过堆栈自动编码机结合K-means算法实现遥感图像的聚类模型建立。通过聚类模型整合后,假设在图像数据集A中有n个图像数据,分别为(x1,x2,…,xn),聚类结果有K类,即分析得出有K种代表性类别,分别用(c1,c2,…,cK)表示,可通过公式(5)计算已标注样本集A和聚类模型获取的代表性样本之间的最小距离。
(5)
2)在未标注数据集B中使用上述聚类模型进行聚类,得到在B中每一个图像数据样本的先验概率αk,通过对每一个αk计算后依次得到先验分布概率p(xi),用σ2表示已标注的样本集中的样本方差,基于代表性策略模型建立公式如下:
(6)
对公式(6)进行分析可知,p(xi)的值越大,表示该样本xi对该类越具有代表性。所以应选择p(xi)较大的值所对应的xi进行专家标注。
2.3 度量学习
上述2种方法在做分类研究的时候各有优缺点。在此情况下,本文采用度量学习(Metric Learning)的方式进行样本标注。度量学习的核心思想是通过学习,在特征空间内减少同类样本的距离,增加不同类样本之间的距离。主要工作包括2个方面的内容:
1)通过网络模型将遥感图像数据转换为特征向量,本文通过2个孪生的网络结构来实现。
2)对特征向量进行相似度比较。
在上述过程中,关键问题在于2个方面:一是网络的设计,即如何设计2个孪生的神经网络,如图3所示;二是loss函数的改进,如何使网络更加优化,样本之间可以有更好的区分度。传统的分类使用softmax loss函数来实现,本文在此基础上,使用三元组损失来计算,三元组损失需要3个遥感图像样本共同计算:一对同类样本和一个不同类样本,固定图片(Anchor)表示为a、同类样本图片(Positive)表示为p和不同类样本图片(Negative)表示为n,公式可表达为:

图3 孪生网络结构
(7)

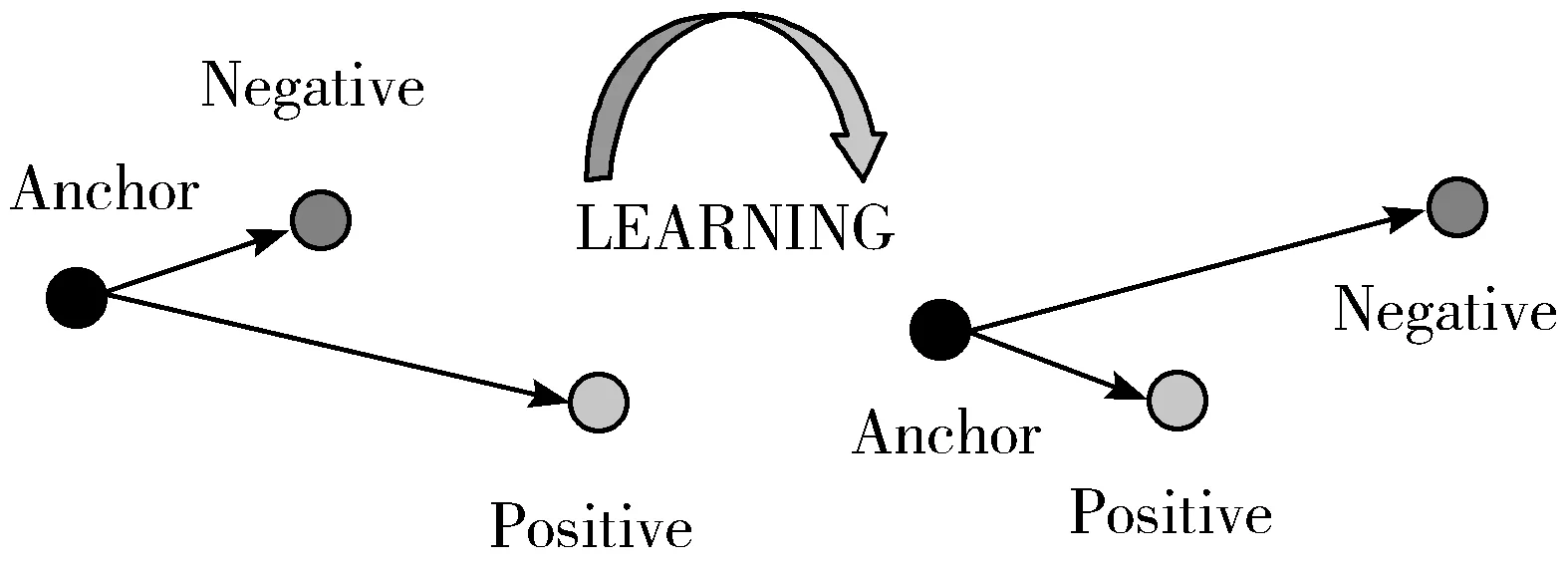
图4 三元组损失函数学习过程
3 实验与结果
3.1 模型与数据集
本文在遥感图像处理中,首先使用图像分割模型对遥感图像按照地块进行分割。本文选用的是具有U-Net结构[26]的CNN模型,模型结构如图5所示。

图5 U-Net网络结构图
上述模型由34538563个参数组成,该模型的输入和输出的宽度和高度相同,但数据维度不同。数据集是包含140000张分辨率为2 m/pixel的图像,大小为2560×2560×3,如图6所示,对应的数据标签是2560×2560×1的数据。地块类型分为建筑、耕地、林地、水体、道路、草地以及其他共7类,见图7。

图6 原始遥感图片
3.2 模型测试
因为已标注的图像比较少,所以3种方案经过训练的模型均不完善,准确率远远不能达到预期的指标。通过具有U-Net结构的CNN对遥感图像进行处理后,将各类地块进行划分,划分结果如图8所示。

图8 U-Net网络对遥感图像的地块分类
在使用度量学习技术之前,首先需要使用已标注数据集对模型进行训练。本文把14000张图片及相对应的图像标签分3种方案进行测试:第1种方案用2000张已经标注的图像数据集和12000张没有标注的数据集;第2种方案用3000张已经标注的图像数据集和11000张没有标注的数据集;第3种方案用4000张已经标注的图像数据集和10000张没有标注的数据集。表1为数据集划分方案。

表1 数据集划分方案
在对模型进行初步训练后,采用度量学习的策略对筛选出的图片进行学习,设定类别数K=7,规定准确度为75.8%或直至未标记数据集中的图片全部遍历完毕终止迭代。图9为使用度量学习前后的学习曲线和准确率。
图9(a)是未通过度量学习,训练了所有的14000张图像得到的结果,图9(b)是由表1的方案1通过度量学习后的学习曲线,图9(c)是由表1的方案2通过度量学习后的学习曲线,图9(d)是由表1的方案3通过度量学习后的学习曲线。

图9 数据学习曲线和准确率
为了验证模型的优越性,本文同时设计了基于生成对抗神经网络(GAN)的模型,并对遥感图像进行验证,生成对抗模型的效果见图10。

图10 原图像与GAN生成图像
通过4000个样本对2种模型进行测试,可以看出,在较少标记量样本的情况下,U-Net网络比GAN的准确率更高,在1600张遥感图片内,U-Net的准确率明显高于GAN,在4000张图片时,GAN的准确率才与U-Net相接近,分别为47.6%和48.3%。测试结果如图11所示。

图11 U-Net和GAN准确率曲线
4 结束语
本文通过使用度量学习策略对遥感图像进行地块目标分类。首先分析了主动学习中基于不确定性和基于代表性的主动学习,提出了针对本项目的度量学习方式。然后对模型和数据进行了介绍,并使用由U-Net结构的CNN模型训练对图像进行分割,根据训练集和测试集不同的方案,得到初始训练程度不同的CNN模型。最后采用度量学习策略筛选未标注数据集并进行标注,标注后加入已标注数据集,对模型进行迭代训练。并通过生成对抗神经网络和U-Net进行比较。由实验可以得出,通过度量学习,可以用较少的样本数,得到比较高的准确率。度量学习对数据进行筛选前,如果初始的模型越好,则达到某一准确率指标所需要的样本数也越少。在同样的已标记样本数的条件下,U-Net比GAN更具有小样本时的训练优势。基于度量学习策略可以有效地减少数据的需求量,降低专家对无标签数据的标注成本。
