基于BERT与图像自注意力机制的文本匹配模型
2021-12-09陆鑫达
宋 爽,陆鑫达
(西安邮电大学计算机学院,陕西 西安 710121)
0 引 言
根据第47次《中国互联网络发展状况统计报告》[1],截至2020年12月,我国网民规模达9.89亿,较2020年3月增长8540万,互联网普及率达70.4%。大量网友每天频繁使用的搜索引擎、即时通讯、网络新闻等软件会产生数量巨大的电子文本信息,而这些电子文本信息包含着海量的数据信息,并具有巨大的经济价值。如何有效地利用和高效地管理这些电子文本信息,已经是自然语言处理任务[2]中急需解决的关键问题,而文本匹配则在电子文本信息的利用与管理中占据着核心的地位。文本匹配已经在众多的领域中得到了广泛的应用,例如智能问答[3]、信息检索[4]、机器翻译[5]、释义识别[6]、答案选择[7]等任务。随着人工智能与神经网络[8]的快速发展,深度学习在文本匹配任务中得到了众多学者的广泛研究,涌现出了许多优秀的基于深度学习的文本匹配模型。
文本表示的深度学习模型:陈珂等人[9]提出的MCCNN模型使用多个卷积神经网络从不同的角度来获取文本特征的表示。Hu等人[10]提出的ARC-I模型,通过一维卷积获取2段文本特征的表示来计算2段文本的相似度。Pang等人[11]提出的MatchPyramid模型,以计算机视觉中[12-13]图像识别[14-15]的方式,通过卷积神经网络来捕捉2段文本的匹配特征。
预训练的深度学习模型:Google提出的BERT[16]模型将11项自然语言处理任务的记录大幅提升,该模型在文本匹配任务中将表示2个文本匹配信息的[CLS]标志向量输入softmax函数来计算2个文本的相似度分数。随着BERT模型中Transformer层数的增多,模型的体积也愈加庞大,Lan等人[17]提出的ALBERT模型通过层参数共享和factorized embedding的方式减少了大量参数,大幅提升了模型的训练速度。Zhang等人[18]提出的SemBERT模型通过融合BERT和语义角色标注的知识进一步提升了BERT模型的表现效果。
本文针对预训练的BERT模型在文本匹配任务中只使用[CLS]标志向量,忽略了其他位置上的编码信息的问题,以及文本表示的MatchPyramid模型中,卷积核无法提取匹配矩阵中长距离依赖特征的问题,提出一种基于BERT与图像自注意力机制的文本匹配模型B-SAI(BERT and Self-Attention Mechanism of Image based Text Matching Model)。该模型利用MatchPyramid模型扩展了BERT模型在文本匹配任务中只使用表示文本相似信息的[CLS]标志向量和softmax函数的方式,有效地利用了BERT模型输出的其他位置上的编码向量,避免了语义信息的损失,并针对MatchPyramid模型中只能利用匹配矩阵局部信息的问题,进一步引入了图像自注意力机制来捕获全局的依赖特征。最后在WikiQA数据集上,通过与MatchPyramid模型、BERT模型和其他优秀的文本匹配模型进行实验对比,验证了该模型的有效性。
1 相关模型
1.1 BERT模型
BERT模型是Google在2018年提出的一种基于Transformer编码器的语言表征模型,其结构如图1所示。
图1中符号Trm表示Transformer中的一个编码层,由于BERT模型是基于Transformer模型的双向编码器,会根据当前词上下文的语义进行表征,可以更全面地捕捉语句中词语的依赖关系。
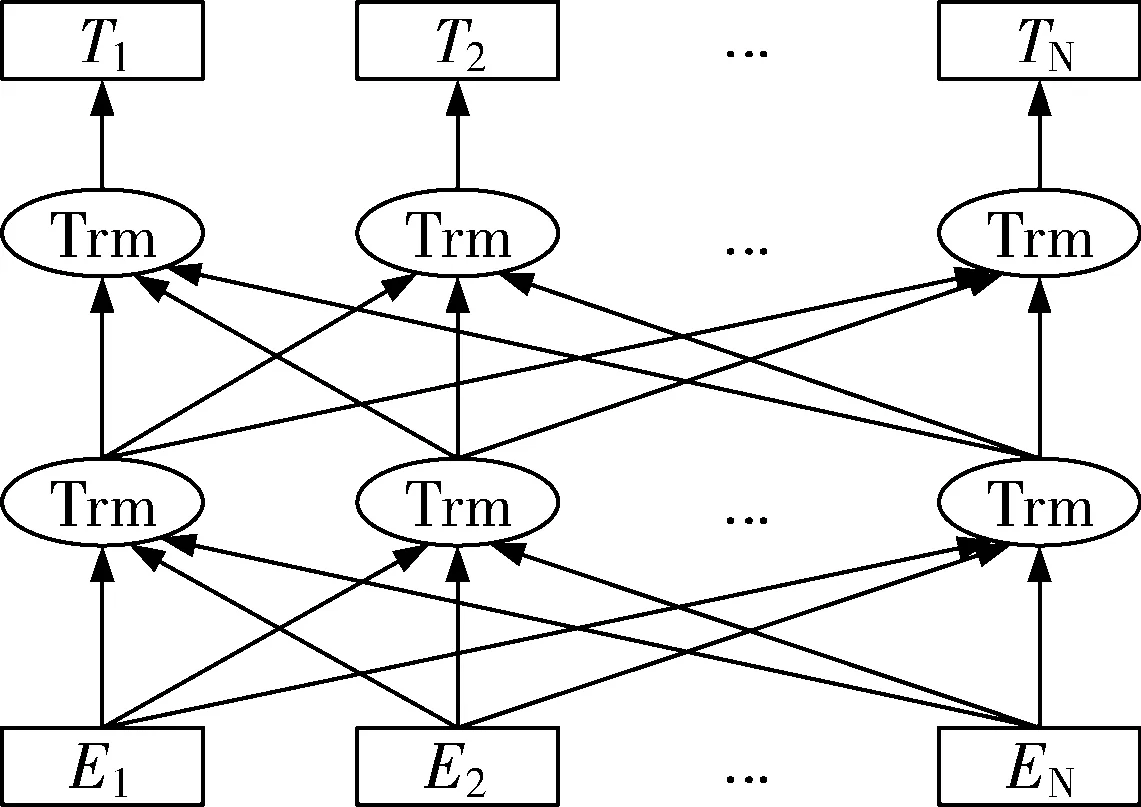
图1 BERT模型结构图
BERT模型的训练分为2个阶段,包括模型预训练和针对下游任务的微调。在模型预训练时,BERT模型通过遮挡语言模型和下句预测2个目标训练网络中的参数,在微调阶段根据下游任务训练目标对网络预训练部分参数进行微调。对于不同的自然语言处理任务,BERT模型在经过微调后,均表现出了良好的实际效果。BERT模型面对下游任务中的文本匹配任务的微调模型结构如图2所示。
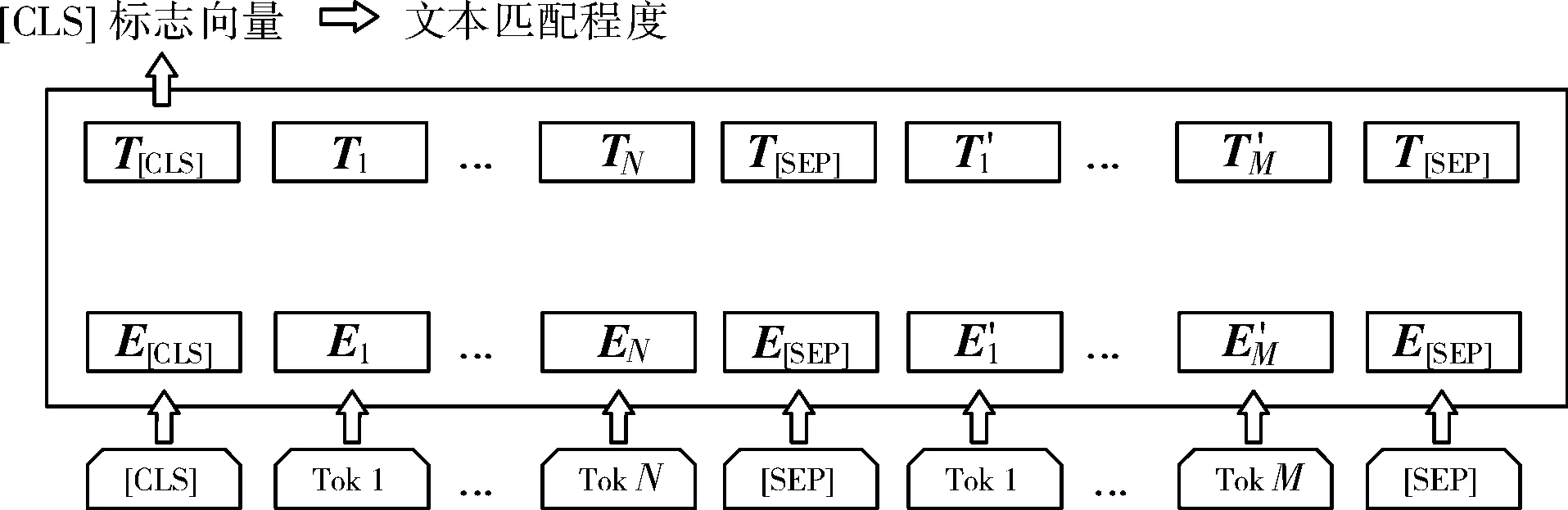
图2 BERT模型在文本匹配任务中的结构
在图2中,E表示BERT模型的输入向量,由词向量、段向量和位置向量逐元素相加得到,T表示BERT模型输出的标志向量与单词向量,其中[CLS]标志包含2段文本的匹配程度,[SEP]表示将2个句子分隔的特殊标记。通过将[CLS]标志向量输入softmax函数便可以得到2段文本的匹配程度,但是在文本匹配任务中,BERT模型忽略了其他位置上的编码向量,导致了一定语义信息的损失。
1.2 MatchPyramid模型
MatchPyramid模型的核心思想是以图像识别的方式来处理文本匹配任务,其结构如图3所示。
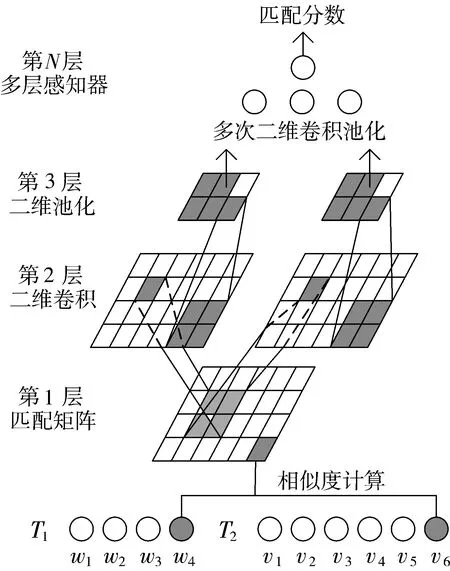
图3 MatchPyramid模型结构图
MatchPyramid模型结构可分为输入层、匹配层、卷积层、输出层4个部分。输入层对文本预处理,进行分词以及去停用词,使用unit ball随机初始化词向量,不依赖额外资源。匹配层通过余弦函数构建2个句子中单词与单词相似性的匹配矩阵,将其视为单通道的图像表示。卷积层通过捕捉图像中的边缘信号并进行组合来获取文本匹配特征。输出层将捕获到的文本匹配特征输入全连接层得到2段文本的相似度。
由于卷积神经网络中卷积核的大小存在一定的限制,只能利用局部信息计算图片中的像素,无法捕捉全局信息,计算的像素可能存在一定的偏差。因此在文本匹配任务中,MatchPyramid模型无法捕获匹配矩阵中的长距离依赖关系,会丢失一些文本匹配特征的细节信息。
2 B-SAI模型
本文提出的B-SAI模型有2个改进之处。一是有效利用了BERT模型输出的编码向量,避免了额外的语义信息损失。二是在MatchPyramid模型中引入了图像自注意力机制,可以捕获匹配矩阵中的全局依赖。
B-SAI模型架构如图4所示,分为输入层、匹配层、图像自注意力层和输出层4个部分。
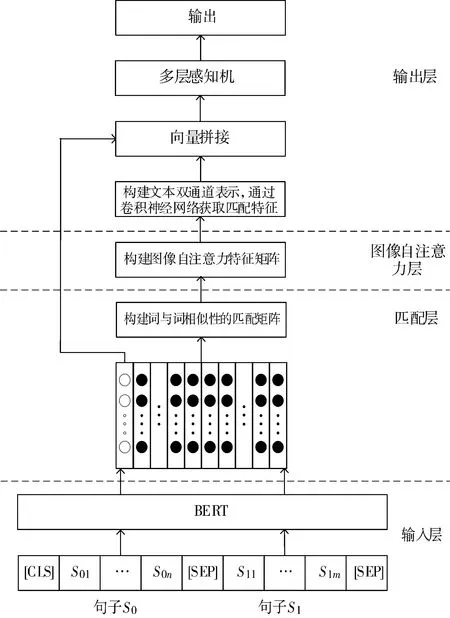
图4 B-SAI模型架构图
2.1 输入层
在输入层中对2段文本进行预处理,首先对其进行分词以及去停用词操作,其次按照BERT模型的输入格式将2个句子拼接为S={[CLS],S01,…,S0n,[SEP],S11,…,S1m,[SEP]}形式的字符串,其中S0n表示句子S0中的第n个单词,S1m表示句子S1中的第m个单词。然后将字符串S输入到微调后的BERT模型得到2个句子的上下文矩阵,并将其调整成维度为d×s的特征映射,其中s是设置的文本规定长度,如果句子Si(i∈{0,1})的长度si大于s,则进行截断,如果句子Si(i∈{0,1})的长度si小于s,则使用值为0的向量进行填充。
2.2 匹配层
匹配层的结构如图5所示,通过BERT模型生成的词向量构建2段文本中单词与单词的相似性匹配矩阵,并将其视为单通道的图像表示。

图5 B-SAI模型匹配层
为了清楚地说明B-SAI模型的工作原理,在图5中展示了2段长度不同的文本表示矩阵,其中αi和βj分别表示句子S0和句子S1中第i个和第j个单词,将2段文本的匹配矩阵使用I来表示,其中元素Iij由以下公式获得:
(1)
其中c是一个极小的常量,避免除0错误。
2.3 图像自注意力层
图像自注意力层的结构如图6所示。

图6 B-SAI模型图像自注意力层
在图6中,首先将匹配层得到的词与词相似性的匹配矩阵I作为自注意力层的输入,通过卷积核大小为1×1、激活函数为ReLU的卷积层,分别得到3个新的特征图f(I)、g(I)和h(I),然后转置特征图f(I)并与特征图g(I)矩阵相乘,并通过softmax函数计算注意力特征S(I),如公式(2)所示。
(2)
其中,Sj,i表示第i个区域对第j个区域的影响程度,N表示整个空间位置。最后将注意力特征Sj,i进行转置并与特征图h(I)执行矩阵乘法操作,并再次通过卷积核大小为1×1,激活函数为ReLU的卷积层,得到自注意力特征矩阵L∈RH×W×1。L自注意力特征矩阵包含全局信息,可以更有效地捕捉到全局特征中的长距离依赖关系,更加有利于提升文本匹配的准确率。
2.4 输出层
输出层将2段文本的匹配矩阵和自注意力特征矩阵连接为双通道,并且通过卷积神经网络提取双通道图像中包含的文本匹配信号,然后将提取到的文本匹配信号与BERT模型输出的代表2段文本相似度信息的[CLS]特征向量进行拼接,输入全连接层,并将全连接层的输出作为softmax函数的输入,从而得到2段文本的相似度。
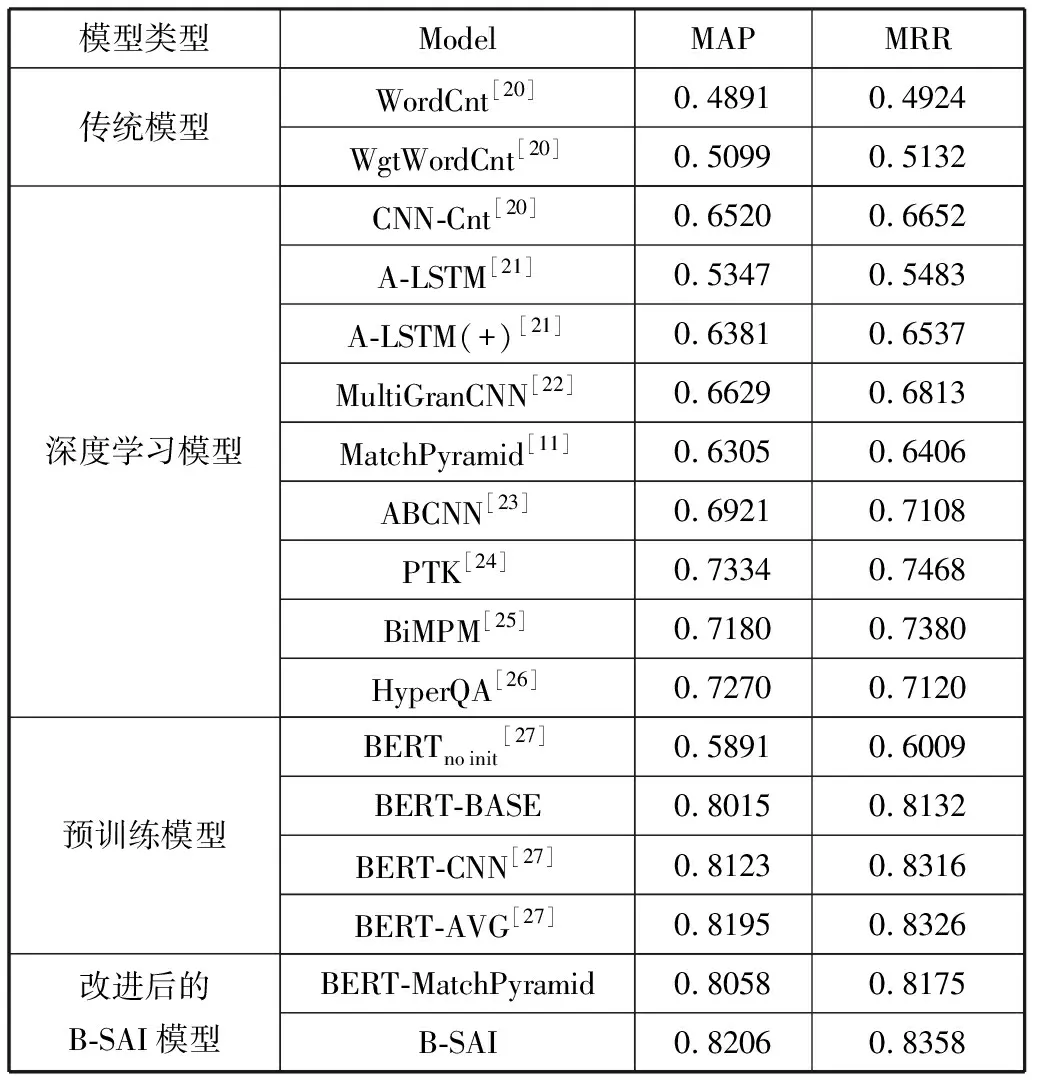
表2 模型在WikiQA数据集上的结果对比
3 实验分析
3.1 实验参数
实验采用Google已经预训练完成的BERT-base模型,其中Transformer编码器的堆叠子层的层数为12,隐藏层维度为768。在本文的实验任务中,BERT模型的微调参数如表1所示。B-SAI模型的输出层中包含2层卷积层和池化层,第1层的卷积层中卷积核为(3,3,8),池化层为最大池化,尺寸为(2,2),第2层的卷积层中卷积核为(3,3,16),池化层为最大池化,尺寸为(2,2)。B-SAI模型的学习率为0.01,L2正则化参数为0.0004,训练轮数为15轮,使用Adagrad随机梯度下降法优化B-SAI模型。

表1 BERT模型微调参数
3.2 数据集与评价指标
本文在实验中选择的是答案选择任务中经典的WikiQA[19]数据集,其中训练集包括2118个问题、20360个句子,其中没有答案的问题个数为1245;测试集包括633个问题、6165个句子,其中没有答案的问题个数为390。实验采用的评价指标为MAP(Mean Average Precision)与MRR(Mean Reciprocal Rank)。
3.3 实验结果分析
表2展示了B-SAI模型和BERT模型、MatchPyramid模型以及其他优秀文本匹配模型在WikiQA数据集上的对比结果。首先对其中的经典模型介绍如下:
1)WordCnt。该模型通过统计问题和答案中共同出现的非停用词的数量来计算2段文本的匹配程度。
2)WgtWordCnt。该模型在WordCnt的基础上调整问题中单词的权重来计算2段文本的匹配程度。
3)A-LSTM。该模型通过注意力机制调整LSTM中各个节点的权重,并使用加权池化获得文本的向量表示来计算2段文本的匹配程度。
4)ABCNN。该模型首先让2段文本的词向量直接交互来构建注意力矩阵,然后获取2段文本各自的注意力特征表示,其次将文本上下文表示和注意力特征表示连接为双通道,通过宽卷积得到高层语义粒度的文本表示,并再次交互构建注意力矩阵,最后通过池化与全连接层得到2段文本的匹配程度。
5)PTK。该模型首先通过语法树的形式组织2段文本的上下文表示,节点的排列位置包含了句子对内部的相似度信息,然后选取问题中的关键词语,最后通过标记答案中是否有实体对应问题中的关键词语来获取2段文本的匹配程度。
6)BiMPM。该模型首先通过双向LSTM学习上下文表示,然后从2个方向进行语义匹配,其次使用双向LSTM对匹配结果进行聚合得到一个长度固定的匹配向量,最后通过全连接层得到2段文本的匹配程度。
7)BERT-CNN。该模型首先将BERT模型输出的词向量通过一维卷积的方式进行聚合,然后拼接[CLS]标志向量,最后输入全连接层得到2段文本的匹配程度。
8)BERT-AVG。该模型首先将BERT模型输出的所有编码向量进行相加,最后将相加后得到的编码向量输入到全连接神经网络得到2段文本的匹配程度。
表2可分为4个部分,分别为传统模型、深度学习模型、预训练模型以及改进后的B-SAI模型。由表2可知,通过统计词频信息的传统模型在实验结果上劣于深度学习模型和预训练模型。在深度学习模型中,PTK相较于其他深度学习模型,实验表现最好,其中MatchPyramid模型的MAP和MRR实验指标分别为0.6305和0.6406,改进后的B-SAI模型分别提升了19.01百分点和19.52百分点。在预训练模型中,经过微调后的BERT-BASE模型在MAP与MRR实验指标上优于随机初始化的BERTnoinit模型,但利用MatchPyramid扩展后的BERT-MatchPyramid模型相比于BERT-BASE模型,在MAP和MRR实验指标上有小幅提升,表明MatchPyramid模型有效地利用了BERT模型所有位置上输出的编码向量,避免了语义信息的损失。BERT-CNN模型和BERT-AVG模型的实验结果优于BERT-BASE模型,其中BERT-AVG模型表现最好。改进后的B-SAI模型相比于BERT-MatchPyramid模型,分别在MAP和MRR实验评价指标上提升了1.48百分点和1.83百分点,表明B-SAI模型中的图像自注意力机制有效地捕获到了匹配矩阵中的长距离依赖,获取到了更多的文本匹配细节信息。
4 结束语
为了提升文本的匹配准确率,本文提出了一种基于BERT与图像自注意力机制的文本匹配模型B-SAI。B-SAI模型的整体思路是先利用BERT预训练模型生成表示2段文本相似度的[CLS]特征向量和单词嵌入向量,其次构建2个句子之间词与词相似性的匹配矩阵,然后通过图像的自注意力机制捕获全局特征依赖关系,生成自注意力特征矩阵,最后通过卷积神经网络提取文本匹配特征,并与[CLS]特征向量融合,输入全连接层得到2段文本的匹配程度。实验结果表明,B-SAI模型有效地提升了文本匹配的准确率。
针对本模型,有待改进的部分如下:一个句子的语义可以拆解为单词、短语、长短语和句子等多个粒度,本文提出的B-SAI模型只考虑了句子中的单词语义粒度,忽略了其他粒度上的语义信息。在后续的研究工作中,将尝试多语义粒度的B-SAI模型的探索。
