基于空间感知的多级损失目标跟踪对抗攻击方法
2021-12-08程旭王莹莹张年杰付章杰陈北京赵国英
程旭,王莹莹,张年杰,付章杰,陈北京,赵国英
(1.南京信息工程大学计算机学院、软件学院、网络空间安全学院,江苏 南京 210044;2.南京信息工程大学数字取证教育部工程研究中心,江苏 南京 210044;3.奥卢大学机器视觉与信号分析研究中心,奥卢 FI-90014)
1 引言
视觉目标跟踪是计算机视觉的关键任务之一,在公共安全领域扮演着十分重要的角色,如视频监控、自动驾驶、无人机追踪、图像目标分割、目标行为识别等。近年来,得益于深度学习(DL,deep learning)技术的蓬勃发展,目标跟踪算法取得了重大突破,特别是孪生网络这一类目标跟踪算法在精度和速度上均取得了优异表现,并在OTB 视频跟踪数据集上达到了91%的精确度,速度也达到了实时。然而,从安全的角度考虑,深度学习跟踪器存在严重的安全隐患,极易受到对抗样本的干扰。
对抗攻击是通过对原始图像添加人眼不可见的微小扰动,以欺骗深度网络模型,导致分类预测错误。近年来,对抗攻击已经由图像分类延伸到目标跟踪、语义分割等领域,成功地破坏了深度学习任务的有效性。此外,深度学习算法无法有效地处理对抗样本。伪造的样本会使深度学习模型输出意想不到的结果。因此,研究基于深度学习的目标跟踪对抗攻击方法对确保算法的安全性和稳健性是至关重要的,可为设计更加稳健的算法提供思路。
基于以上动机,本文以孪生网络跟踪器SiamRPN++为主要攻击对象,研究了视觉目标跟踪的对抗攻击方法,主要贡献包括以下3 个方面。
1) 针对现有对抗扰动技术难以有效地干扰跟踪器使运动轨迹发生快速偏移的问题,提出了一种基于空间感知的多级损失目标跟踪对抗攻击方法,利用生成器生成对抗样本来实现对目标跟踪器的干扰,降低了跟踪精度,具有较好的攻击效果。
2) 提出了一种高效的空间感知快速漂移攻击框架,在此框架下设计了欺骗损失、漂移损失和双重注意力机制的特征损失和感知损失来联合训练生成器,生成人眼难以察觉的对抗扰动,用于欺骗目标跟踪器。
3) 将所提方法在OTB100、VOT2018 和LaSOT这3 个主流的目标跟踪数据集上进行验证,实验结果表明,所提方法可使跟踪器的判别能力失灵,预测边框逐渐收缩,导致目标轨迹发生偏移,比原始跟踪器在OTB 数据集上实现了70%的精确度下降。
2 相关工作
目标跟踪技术是高层视觉任务分析与处理的基础,已在视频监控、视觉导航、行为识别、自动驾驶等领域得到了广泛应用。视觉目标跟踪任务是在给定某视频序列初始帧的目标大小与位置的情况下,预测该目标在后续帧的大小与位置。然而,即使基于深度学习的目标跟踪技术已经能够成功地处理复杂问题,但最近研究表明它们对输入中的轻微扰动很敏感,会导致跟踪性能下降。对抗攻击对深度学习在实践中取得成功构成了一系列威胁。本节将分别从目标跟踪、对抗攻击2 个方面介绍相关的研究工作。
1) 目标跟踪
近年来,以相关滤波(CF,correlation filter)和深度学习为代表的判别式方法取得了令人满意的效果,已成为目标跟踪的主流方法。
相关滤波源于信号处理领域,基于相关滤波目标跟踪的基本思想就是寻找一个滤波模板,让下一帧图像与滤波模板进行卷积操作,响应最大的区域则是预测目标。基于此,国内外学者先后提出了大量方法,如MOSSE(minimum output sum of squared error filter)[1]、KCF(kernelized correlation filter)[2]等。此外,在KCF 的基础上又发展了一系列跟踪方法用于处理各种复杂场景下的挑战,如处理尺度变化的DSST(discriminative scale space tracker)[3]、基于分块的相关滤波RPT(reliable patch tracker)[4]等。但是上述方法会受到边界效应的影响。为了克服这一问题,Danelljan 等[5]提出一种高效的SRDCF(spatially regularized discriminative correlation filter)方法,利用空间正则化惩罚相关滤波系数,取得了和同时期基于深度学习跟踪方法相当的效果。进一步地,Danelljan 等[6]利用卷积神经网络(CNN,convolutional neural network)提取目标特征,并结合相关滤波提出了连续卷积算子的目标跟踪(C-COT,continuous convolution operator for visual tracking)方法。
由于深度特征对目标拥有强大的表征能力,深度学习在计算机视觉各领域展现出巨大的潜力。Wang 等[7]首次将深度学习引入目标跟踪领域,其将在分类数据集上训练的卷积神经网络迁移到目标跟踪任务中,与传统方法相比,性能得到了提升。Hong 等[8]提出的 CNN-SVM 算法首先利用在ImageNet 上训练的卷积神经网络提取目标特征,再利用SVM 跟踪目标。Wang 等[9]提出基于全卷积模型的目标跟踪方法,利用目标的2 个卷积层特征构造可以选择特征图的网络,跟踪性能比CNN-SVM有了小幅提升。其他代表性方法还有HCF[10]、VITAL[11]等。然而,目标跟踪任务与图像分类任务有本质区别,图像分类任务关注类间差异,忽视了类内区别;目标跟踪任务则关注区分特定目标与背景,抑制同类目标。因此,在分类数据集上预训练的网络可能不完全适用于目标跟踪任务。
针对这一问题,文献[12]提出一种专门在跟踪视频序列上训练的多域卷积神经网络模型MDNet,获得了VOT2015 竞赛冠军。然而,该方法不能满足实时要求。针对这一问题,基于孪生网络的目标跟踪算法在跟踪精度和速度上取得了很好的平衡,在大量数据集上取得了优异的性能,代表性方法包括 SiamFC[13]、SiamRPN[14]、SiamRPN++[15]、DaSiamRPN[16]、Siam R-CNN[17]等。
2) 对抗攻击
研究表明,CNN 极易受到攻击。即使最先进的分类器也很容易被添加到原始图像中的噪声所蒙蔽。因此,深度学习下的对抗攻击研究具有重要意义。
根据威胁模型,可将现有攻击分为白盒攻击和黑盒攻击,它们之间的差异在于攻击者了解的信息不同。白盒攻击假定攻击者具有关于目标模型的完整知识,可通过任何方式直接在目标模型上生成对抗样本。黑盒攻击只能依赖查询访问的返回结果来生成对抗样本。在上述3 种攻击模型的框架中,研究者提出了许多用于对抗样本生成的攻击算法。这些方法大致可分为基于梯度迭代的攻击、基于生成式对抗网络(GAN,generative adversarial network)的攻击和基于优化的攻击三类。
基于梯度迭代的攻击方式的代表性方法包括FGSM[18]、Deepfool[19]、DAG[20]、PGD[21]、BIM[22],它们通过优化对抗目标函数以愚弄深度神经网络。Wang 等[19]利用迭代计算生成最小规范对抗扰动,将位于分类边界内的图像逐步推到边界外,直到出现错误分类。然而,FGSM 和PGD 生成的对抗样本比较模糊,跟踪时不但容易被发现,而且攻击效果较差。司念文等[23]提出一种基于对抗补丁的Grad-CAM 攻击方法,设计了分类结果不变而解释结果偏向对抗补丁的目标函数,使Grad-CAM 方法无法定位图像中的显著区域。Su 等[24]提出一种基于差分进化的单像素对抗扰动生成方法,通过修改图像中的一个像素,使数据集中多种类别的图像至少有一类目标被攻击。该方法仅修改单个像素无法适应视频的多帧任务。Zhong 等[25]首次研究了迁移对抗攻击在人脸识别中的特性,提出了一种基于丢弃的方法DFANet 来提高现有攻击方法的迁移性,生成的人脸图像对有效地欺骗了人脸识别系统。Chen等[26]提出对目标模板的单次攻击方法,通过优化批置信度损失和特征损失来寻找模板的对抗样本。该方法产生的对抗样本易被人眼察觉,无法攻击正常运行的跟踪器。Jia 等[27]利用构造的伪分类标签和伪回归标签来寻找真实损失和伪损失差异的梯度方向,进而产生对抗样本。然而,该方法攻击过程耗时,难以满足实时性要求。
基于生成式对抗网络的攻击方式使用大量数据来训练生成器以产生扰动噪声,代表性方法有AdvGAN[28]、UEA[29]、AdvGAN++[30]。Deb 等[31]提出一种高质量的对抗人脸生成法,运用GAN 来改变人脸的潜在区域使对原图扰动最小,在不改变视觉质量的情况下,大幅降低了人脸识别的成功率。Baluja 等[32]提出一种全新的对抗样本生成方法,针对目标网络或一系列需要攻击的网络,通过自监督学习方式训练对抗转化网络(ATN,adversarial transformation network)来生成对抗样本,提高了对抗样本生成速度且丰富了样本的多样性。以上基于GAN 的方法需同时优化生成器与判别器以产生对抗样本。Yan 等[33]提出一种冷却收缩对抗损失以冷却目标区域及收缩预测边框,该方法虽能快速产生人眼无法察觉的对抗样本,但是攻击能力欠佳且对黑盒跟踪器的迁移性有限。Sharif 等[34]提出一种对抗生成网络(AGN,adversarial generative network),训练生成器网络产生满足期望目标的对抗样本,在数字空间和现实世界中均成功迷惑了人脸识别系统。
基于优化的攻击方式主要是CW 攻击(carlini and wagner attack)[35]。该攻击生成的扰动可以从未经防御的网络迁移到经过防御的网络上,以实现黑盒攻击。Moosavi-Dezfooli 等[36]提出一种计算普适性扰动的算法,在数据分布中采样样本集进行训练,使每个样本都能以一定概率被错误分类,在新样本预测时欺骗分类器,证明高维决策边界具有几何相关性。Din 等[37]提出基于隐写技术的对抗扰动生成方法,通过在变换域中将单个秘密图像嵌入任意目标图像来产生扰动,使流行分类模型以高概率错误分类目标。
3 基于孪生网络的目标跟踪器及其可攻击性
近年来,孪生网络在目标跟踪领域取得了很高的性能,其将目标跟踪问题转化为Patch 块的匹配问题,通过比较图像搜索区域与目标模板的相似度,得到新的目标位置。在众多孪生网络跟踪方法中,SiamRPN++[15]跟踪器在跟踪数据库上刷新了纪录,不仅精度高,运行速度也满足实时性要求。
然而,跟踪算法本身存在被攻击的潜在风险。即使是SiamRPN++跟踪器也会遭受噪声干扰,导致目标跟踪失败。
现有目标跟踪系统的对抗攻击存在以下难点。
1) 目标跟踪的对抗攻击不同于简单的分类任务,它既包括分类,也有精准的边框回归,仅通过迁移图像分类任务中的对抗攻击达不到预期效果。
2) 由于目标跟踪的特殊性,目标只在第一帧中给出,无法预知其类别,因而不能为每个类别单独训练对抗补丁。
为此,本文从视觉目标跟踪任务本身出发,在设计攻击损失函数时融合了基于分数与特征干扰分类任务和基于回归偏移量破坏回归任务,导致跟踪器无法准确判别目标存在区域,回归边框逐渐缩小并快速沿着与真实目标最远的方向移动,造成跟踪失败。此外,本文摒弃为每个类别单独训练对抗补丁的思路,从低级特征和高层语义角度出发,设计了欺骗损失、漂移损失、基于双重注意力机制的特征损失和感知损失,通过联合训练生成器,使生成器在不同场景下能对目标产生肉眼难以察觉的扰动,以达到欺骗目标跟踪器的目的。
4 空间感知的多级损失跟踪对抗攻击方法描述
本文提出一种基于空间感知的多级损失漂移攻击框架来欺骗性能较好的SiamRPN++跟踪器,对原始图像添加微小扰动,使跟踪器识别不到目标的正确位置及姿态估计。为了实现这一目标,本文设计了欺骗损失、漂移损失、基于注意力机制的特征损失和感知损失来联合训练基于GAN 的生成器,以产生强对抗样本,用于攻击跟踪器。下面将详细介绍本文所提出的攻击方法。
4.1 对抗样本生成
本文提出的攻击框架包括两部分,分别是扰动生成器ξg和跟踪器SiamRPN++。扰动生成器训练结构框架如图1 所示。生成器训练过程中,保持模板不变,将干净搜索区域送入生成器产生噪声,再与干净搜索区域相加,形成对抗搜索区域。同时,将每一帧对抗搜索区域分别与干净模板一起送入跟踪器进行模板匹配,输出特征提取网络Conv3-3的特征图,得到对抗样本响应图和回归图。
要想达到攻击的目的,需要更多地关注搜索区域中最有可能是目标的区域。因此,同时把干净模板和相应干净搜索区域输入跟踪器,找出感兴趣区域。接着,利用所提出的欺骗损失Lcheat、漂移损失Ldrift、基于双重注意力的特征损失Lfeature和感知损失Lquality联合训练生成器。算法流程如算法1 所示。
算法1本文扰动生成器训练框架
输入干净的目标模板ZC,干净的搜索区域SC,自定义噪声图像Nt,训练视频数目T,随机初始化生成器ξg
输出基于搜索区域的扰动生成器
1) 初始化生成器ξg和跟踪器并固定参数
2) fori=1:T
3) 获取干净的模板ZC和N张干净搜索区域SC;
4) 将ZC和N张干净的搜索区域SC输入孪生网络跟踪器中,得到干净的响应图GC;
5) 将SC送入生成器中产生噪声 Noise=ξg(SC);
6) 得到对抗搜索区域图像Sadv=SC+Noise;
7) 使用Sadv得到对抗响应图Gadv、回归图Madv和对抗搜索区域Sadv的特征E(Sadv);
8) 基于特征E(Sadv),通过通道注意力和空间注意力协同机制得到特征权重分布;
9) 基于Gadv、Madv、Sadv、E(Sadv)和Nt,根据式(1)、式(3)、式(7)分别计算欺骗损失、漂移损失和基于注意力机制的特征损失;
10) 利用式(9)计算Lqualtity损失函数;
11) 利用式(10)计算总损失函数;
12) 利用Adam 优化器更新生成器ξg的参数;
13) 直到模型收敛;
14) end for
4.2 损失函数的设计
给定一段视频,对干净视频帧添加微量扰动,生成对抗样本,使跟踪器偏离原始运动轨迹。本节从欺骗损失攻击、漂移损失攻击、基于双重注意力机制的特征损失攻击和感知损失4 个方面详细介绍本文算法的损失函数。
4.2.1 欺骗损失攻击
在单目标跟踪中,跟踪器需要在视频的每一帧中精确定位目标。对于攻击而言,需求与之相反,希望跟踪器在每一帧中都尽量偏离正确的目标位置。由于目标跟踪是集粗定位和细定位于一体的任务,因此本文设计了粗定位和细定位的欺骗损失函数用于迷惑目标跟踪器。
对于粗定位,跟踪的目标是粗略确定目标有可能存在的区域,反之,攻击是使粗定位任务失灵。粗定位确定目标的主要依据来源于正样本,让正样本的置信度分数尽量小就能达到辨认不出目标的目的。对于细定位,跟踪的指引就是基于粗定位的结果结合修正量精准回归边框,在攻击时让回归边框尽量收缩,就能使定位的目标位置不准确,从而降低重叠率,细定位任务也就失去了效果。具体的函数表达式为
在图1 中,A 模块利用干净模板和干净搜索区域产生m个候选框,再依据每个候选框的置信度s寻找感兴趣区域。本文将置信度大于0.7 的候选框作为正样本,在干净响应图中计算对应索引,作为注意力掩码Ã,定义为
进一步,利用式(2)寻找Gadv和Madv中相应候选框,再计算,得到Lcoarse与Lscale。
4.2.2 漂移损失攻击
欺骗损失攻击旨在冷却干净搜索区域中可能是目标的区域,使跟踪器难以辨认目标,同时,尽可能减小修正量的宽和高,收缩目标边界框,降低重叠率。然而,该攻击还不够强大,跟踪器仍然可以在搜索区域内定位出物体。针对这一问题,本节提出了漂移损失函数,通过赋予中心坐标修正量很大的漂移值,目标预测边框中心会与原始中心相差甚远,导致跟踪器快速丢失目标。漂移损失函数表达式为
欺骗漂移攻击框架如图2 所示,进一步细化了欺骗损失攻击和漂移损失攻击。为方便计算,先将Gadv和Madv调整为二维矩阵,再利用式(2)选择的候选框产生粗定位结果和细定位结果。
4.2.3 基于双重注意力机制的特征损失攻击
欺骗损失攻击和漂移损失攻击都着眼于对高级类别信息进行攻击,这依赖于特定白盒模型产生的分类概率和回归预测,迁移能力受到了限制。考虑任何跟踪器都需利用图像底层特征作为网络输入,对图像底层特征攻击有助于提高白盒模型产生的对抗样本在黑盒模型跟踪器上的迁移能力。因此,提出了特征损失攻击函数,定义为
其中,E(·)表示图像经过骨干网络输出的特征图;Sadv表示搜索区域的对抗样本;C表示通道数量;Nt表示自定义的噪声图像。通过优化对抗样本特征和自定义噪声图像特征之间的欧氏距离,使对抗样本特征与噪声图像特征相似,以改变特征空间中对抗样本的内部结构。
进一步地,为了增强对目标的攻击强度,该特征损失攻击融合了空间和通道注意力,构成双重注意力模块,以聚焦图像中感兴趣的区域,如图3 所示。
1) 空间注意力模块。卷积神经网络的输出特征图存在空间内的依赖关系,本文利用这种关系产生空间注意力图,以关注目标具体位置。在单目标跟踪中,仅有一个感兴趣目标,关注图像中前景区域尤为重要,这有利于捕获关键信息,增强对目标攻击的强度。针对每一个感兴趣区域,空间注意力机制表达式为
其中,ROI 表示感兴趣区域;i表示第i个ROI;s表示置信度;h()和w()分别表示ROI 的高度和宽度。对于每幅干净图像,首先依据s寻找前40 个感兴趣区域,获取其坐标和相应置信度,然后将这些区域映射到E(Sadv)中,通过叠加E(Sadv)中每个响应值所包含ROI 的所有置信度来确定最终空间注意力图SA,最后得到细化后的对抗样本特征图,具体表达式为
其中,E(Sadv)'表示细化后的特征图;⊗表示像素相乘。
2) 通道注意力模块。孪生网络输出特征图的各通道之间存在依赖性,不同通道对于每个类别的响应强度差异很大,每个通道所蕴含的信息量也有所不同。对目标攻击而言,与目标关联度越大,对应特征通道应赋予更多扰动,以关注信息量更丰富的通道,抑制信息量小的通道。为了更关注目标,本文融合了双重注意力机制来攻击图像中重要区域的特征,得到各通道的特征权重分布,实现对目标的攻击。因此,融合通道和空间注意力协同机制的式(4)可进一步表示为
其中,◦表示哈达玛积,Ak表示各通道特征权重分布,计算式为
其中,vk(i,j)表示第k个通道特征图中的响应值;H和W分别表示特征图的高和宽。先将各个通道全局平均池化后获得每个通道特征图的相对重要程度,再将其送入Softmax 激活函数,得到每个通道的特征权重分布。注意力特征权重的计算提高了对抗样本关键通道的特征图与自定义噪声图像特征图之间的相似程度,同时也抑制了贡献小的通道对扰动的影响,增强了对目标攻击的强度。
4.2.4 感知损失
为了使生成图像更接近于原始图像,防止图像失真,本文引入了感知损失函数Lquality,定义为
其中,SC表示干净搜索区域;Sadv表示对抗搜索区域;N表示搜索区域的数量。利用2-范数对噪声幅度进行约束,使原始图像转化为能够欺骗目标模型的对抗图像。
最后,将欺骗损失Lcheat、漂移损失Ldrift、特征损失Lfeature和感知损失函数Lquality损失组合成总的损失函数L
其中,λ1、λ2和λ3表示权重系数,以平衡不同的损失函数。本文中,这些权重系数值是依据大量实验设置的参数,通过扰动生成器产生的扰动图像既不被发现,又能有效地欺骗跟踪器。
4.3 损失函数作用
攻击目标的场景包括遮挡、尺度变化、光照变化、背景干扰等。本文的4 种损失函数针对不同任务场景设计,所起的作用有主次之分。特征损失函数旨在破坏图像特征结构,使模型具有更好的迁移性,让白盒模型训练的扰动生成器以更高的成功率和精度迁移到其他黑盒跟踪器中,产生好的攻击效果,增强攻击泛化性。欺骗损失同时干扰目标的分类和回归任务,通过干扰分类响应图使跟踪器误把背景当作目标,并使回归边框收缩,降低与原目标的重合率,涵盖RPN 中的分类与回归阶段。漂移损失集中攻击回归任务,主要解决欺骗损失带来的攻击偏移度差问题,进一步增强攻击强度,使目标大幅偏离原始预测位置。此外,由于数字空间中的对抗攻击遵循扰动不可见原则,因此本文设计了感知损失,它能使产生的扰动图像尽可能与原图像相似,使人眼不可察觉。
5 实验与结果分析
本节将本文提出的方法在Pytorch 深度学习架构下开展验证,硬件平台的配置环境为Intel-i9 CPU(64 GB 内存)和一块RTX-2080Ti GPU(11 GB 内存),并且在3 个数据集(OTB100、VOT2018 和LaSOT)上测试了本文方法的有效性。
5.1 数据集
训练数据集:为了涵盖更丰富的目标类别,本文采用GOT-10K 作为训练数据集。该数据集的视频序列超过10 000 个,覆盖500 多个目标类别,呈现出跟踪目标的多样性。具体地,对于每个视频序列,在视频的第一帧裁剪目标模板,在后续的帧中每10 帧均匀采样一次,并裁剪搜索区域,其中模板区域大小裁剪为127×127,搜索区域大小裁剪为255×255。
测试数据集:本文将在OTB100、VOT2018 和LaSOT 这3 个数据集上测试本文方法的有效性。下面,从数据集大小和数据特点等方面分别介绍这3 个数据集。
OTB100 数据集:该数据集中共有98 个视频,涉及目标跟踪的11 个属性,包括光照变化、尺度变化、遮挡、形变、运动模糊、快速运动等。每个序列都对应2 个或多个属性。
VOT2018 数据集:该数据集中包括60 个视频,与OTB 数据集相比,更具挑战性。在目标丢失时,该数据集有重新初始化机制。
LaSOT 数据集:包含1 400 个视频;目标类别有70 个,每个类别包含20 个序列。其中测试集由每个类别中精心挑选的4 个视频序列组成,共计280 个视频序列。
5.2 评价标准
OTB100 数据集采用精确度(P,precision)和成功率(S,success)作为评价标准。P 反映跟踪算法估计的目标位置中心点(bounding box)与人工标注目标中心点(ground-truth)的中心误差。S 代表跟踪算法得到的预测状态与目标原始重合率大于0.5 的百分比。VOT2018 数据集同时衡量算法的精确度(A,accuracy)和稳健性(R,robustness),并以平均重叠期望(EAO,expected average overlap)给出算法性能的排序。LaSOT 数据集选择S 和标准化精度(Norm P,norm precision)来衡量算法性能。
5.3 实验细节
本文使用Adam 优化算法优化生成器,学习率设置为2×10−4。将欺骗损失中的γ设置为−5,并将ρ1和ρ2分别设为0.1 和1,以平衡粗定位与细定位损失。将漂移损失中的Δδ设为500,使边框大幅偏移目标中心。式(10)中的漂移损失系数λ1和特征损失权重λ2分别设置为2 和20,感知损失系数λ3设置为620。
对于攻击生成的施加条件,本文攻击方法需要2 个部件,分别为U-net 结构的生成器以及ResNet50结构的SiamRPN++跟踪器。U-net 结构在像素级任务中展现优异的性能,因此适合为数字空间中的攻击任务产生噪声。整个攻击生成的施加条件作用于白盒设置模式下,能获取SiamRPN++跟踪器的全部参数,以产生高级语义层面与低级特征层面的多级损失函数用于扰动生成器的训练,从而确保训练的扰动生成器能够成功攻击图像中的目标。
5.4 实验结果与分析
表1 和表2 给出了本文方法在OTB100[38]、VOT2018 和LaSOT[39]这3 个数据集上的攻击结果。表1 中,Original 表示SiamRPN++原始的跟踪结果,Attack S 表示仅攻击搜索区域,Drop 表示性能下降;表2 中,Attack SZ 表示同时攻击搜索区域和目标模板。攻击策略为仅攻击搜索区域以及同时攻击搜索区域和目标模板。

表1 本文方法对仅攻击搜索区域的实验结果
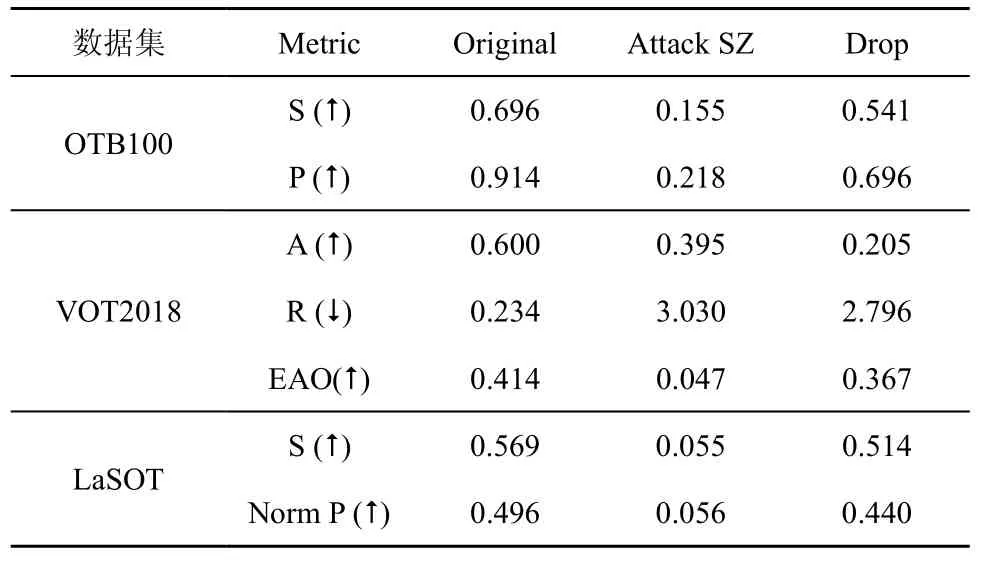
表2 本文方法同时攻击搜索区域和目标模板的实验结果
攻击生成的具体过程如下。
1) 仅攻击搜索区域。当仅攻击搜索区域时,预先处理训练数据集,每10 帧均匀采样GOT-10K 数据集中视频帧,裁剪目标模板和搜索区域,共获得9 350 段视频。对于每段视频,第一帧为干净目标模板,后续帧为干净搜索区域。训练阶段,首先获取目标模板和搜索区域,保持目标模板不变,随机初始化扰动生成器,将每一帧干净目标搜索区域送入扰动生成器产生噪声后,再与干净目标搜索区域相加,形成对抗搜索区域。然后分别将干净搜索区域,对抗搜索区域与干净目标模板送入SiamRPN++跟踪模型,输出网络Conv3-3 的特征图,分别得到干净样本的响应图GC、对抗样本的响应图Gadv和回归图Madv。最后构造Lcheat、Ldrift、Lfeature和Lquality这4 种损失函数以联合训练生成器,得到基于搜索区域的扰动生成器。在推理阶段,保持干净目标模板不变,将干净搜索区域通过扰动生成器生成对抗搜索区域,再把对抗搜索区域和干净目标模板同时送入SiamRPN++中,得到两者匹配的相似度,记为SiamRPNP+++S(仅攻击搜索区域)。从表1 可以看出,本文提出的攻击方法使跟踪器的性能在3 个数据集上大幅度下降。
2) 同时攻击搜索区域和目标模板。当同时攻击搜索区域和目标模板时,扰动生成器的训练方法和仅攻击目标搜索区域时的训练方法相同。在推理阶段,使用训练的扰动生成器同时攻击目标模板和目标搜索区域,并将对抗模板和对抗搜索区域送入跟踪器 SiamRPN++中,记为SiamRPN+++SZ(同时攻击搜索区域和目标模板),实验结果如表2 所示。从表2 中可以看出,同时攻击模板和搜索区域比仅攻击搜索区域性能下降更多。在OTB100 数据集上,同时攻击模板和搜索区域时,SiamRPN++跟踪器定位的成功率由未攻击时的69.6%下降为15.5%,降低了约54%;精确度由91.4%下降到21.8%,降低了约70%。
另外,将SiamRPN++以及2 种攻击策略下的SiamRPN+++S、SiamRPN+++SZ 在OTB 数据集上与其他主流跟踪器(MDNet[12]、SiamFC[13]、SiamRPN[14]、SiamRPN++[15]、DaSiamRPN[16]、GradNet[40]等)进行对比,性能表现如图4 所示。
从图4 中可知,本文方法大大降低了SiamRPN++的性能。表3 给出了本文方法与现有攻击方法在SiamRPN++上的攻击性能比较。在OTB100 数据集上,本文方法在S和P上都超越了CSA[33]、SPARK[41]与FAN 方法[42],使SiamRPN++的定位能力显著下降,在OTB100 数据集上仅有15.5%的成功率和21.8%的精确度。

表3 不同攻击方法在SiamRPN++跟踪器上的攻击性能比较
5.5 消融实验
5.5.1 损失项消融实验
为了验证并分析模型各损失项的作用,将损失项分为4 个部分,分别是粗定位损失Lcoarse、细定位损失Lscale、漂移损失Ldrift和特征损失Lfeature。Lcoarse用于冷却目标位置;Lscale用于收缩目标边界框,降低重叠率;Ldrift用来漂移目标;Lfeature用来改变图像在特征空间中的结构。本节分析了这4 个损失项及其组合对于SiamRPN++跟踪器性能的影响。实验在OTB100 和VOT2018 数据集上进行了测试,结果如表4 和表5 所示。其中,“-”表示未使用,“√”表示使用。从表4 和表5 中可以看出,无论是使用单独损失项还是组合项,同时攻击搜索区域和目标模板都取得了比仅攻击搜索区域更强的攻击效果。
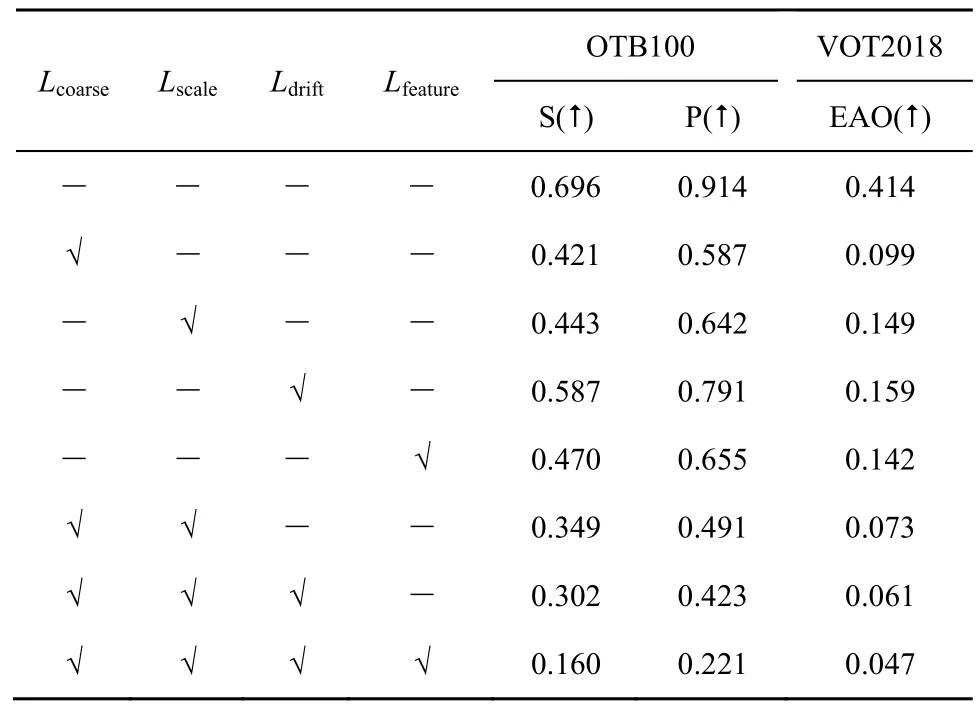
表4 仅攻击搜索区域时各损失项对于性能的影响

表5 同时攻击搜索区域和目标模板时各损失项对于性能的影响
首先,针对4 个单独损失项,其对迷惑跟踪器均有积极影响,Lcoarse取得了最佳的攻击效果,证明了粗定位任务在跟踪中的重要性。Lscale和Ldrift的攻击效果次于Lcoarse,这是因为两者都是基于粗定位结果进行收缩或漂移,去掉粗定位损失Lcoarse,跟踪器便能粗略确定目标位置,此基础上进行单独收缩或漂移,效果自然欠佳。
其次,对于损失项的组合,在Lcoarse的基础上添加Lscale,跟踪器的预测边框逐渐收缩,无法精确估计目标尺度,如图5(a)所示。此外,在欺骗损失Lcoarse和Lscale的基础上再叠加漂移损失Ldrift,跟踪器对目标位置信息极度不敏感,并很快沿着与目标距离最远的位置漂移,如图 5(b)所示。
最后,同时联合4 项损失能最大幅度地愚弄跟踪器,且生成的对抗样本不易被人眼所察觉。
5.5.2 注意力机制消融实验
本节讨论了特征损失中空间和通道注意力协同机制对目标攻击效果的影响。为了探索2 种注意力机制及其组合对于性能下降的影响,设计了仅攻击搜索区域和同时攻击搜索区域及目标模板2 种攻击策略下的对比实验。实验结果如图6 所示。
仅攻击搜索区域时,设计的实验有G-S-noA-Feature(G 表示生成器,S 表示搜索区域,noA 表示无注意力机制)、G-S-Spatial-Feature(Spatial 表示执行空间注意力)、G-S-Channel-Feature(Channel 表示执行通道注意力)和G-S-Spatial-Channel-Feature(Spatial-Channel 表示空间和通道注意力协同机制)。
同时攻击搜索区域和目标模板时,设计的实验有G-SZ-Channel-Spatial-Feature(SZ 表示搜索区域和目标模板)、G-SZ-Channel-Feature、G-SZ-Spatial-Channel-Feature、G-SZ-Spatial-Feature 和 G-SZnoA-Feature。
从图6 中可以看出,在2 种攻击策略下,空间和通道注意力机制对攻击跟踪器都有积极作用,仅有单个注意力时,通道注意力比空间注意力有更好的攻击效果。将二者串联协同工作,跟踪器跟踪目标的性能会大幅下降,达到了最好的攻击效果。
5.5.3 各损失项迁移性消融实验
为了验证各损失项在黑盒攻击设置下的迁移性能,本文选取3 种最先进的跟踪器进行攻击,将由基于ResNet-50 的SiamRPN++训练的生成器迁移到其他3 种最先进的跟踪器上,分别是基于在线更新策略的 DiMP-50、基于MobileNet 的SiamRPN++和基于ResNet 的SiamMask。各损失项对于攻击3 种最先进的黑盒跟踪器时迁移性的表现如表6~表8 所示。从表6~表8 可以看出,仅用单一损失训练时,4 种损失项训练的模型都能一定程度上降低跟踪器的性能,使目标偏移原本的运动轨迹。较之其余3 项,Lfeature损失项训练的模型在3 种黑盒跟踪器上都展现出最好的攻击效果,体现出良好的迁移性。
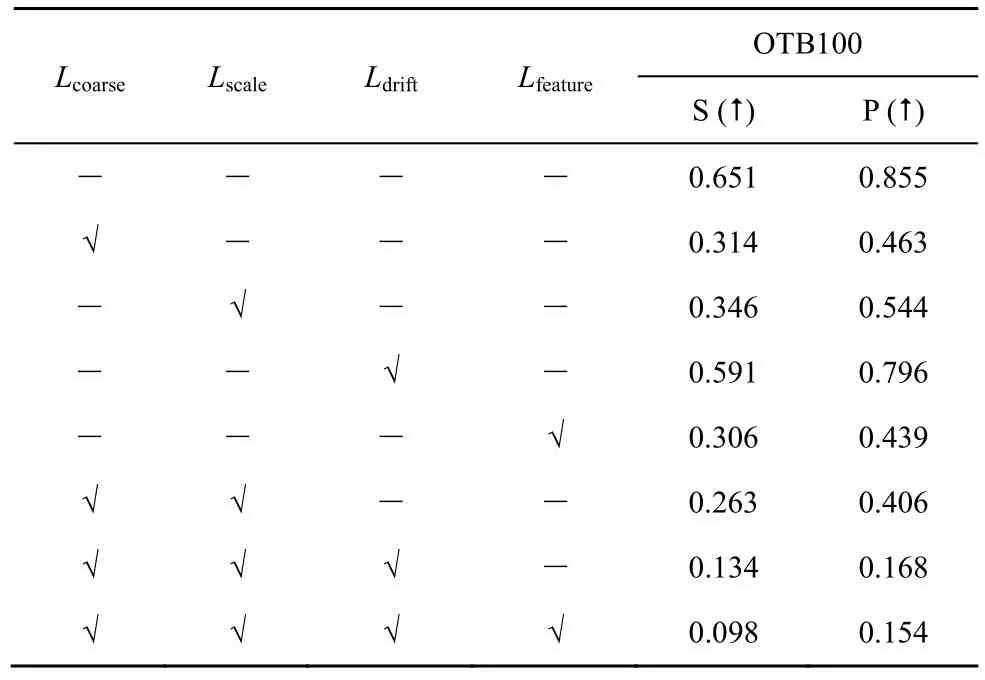
表6 SiamRPN++(MobileNet)跟踪器各损失项迁移性对比
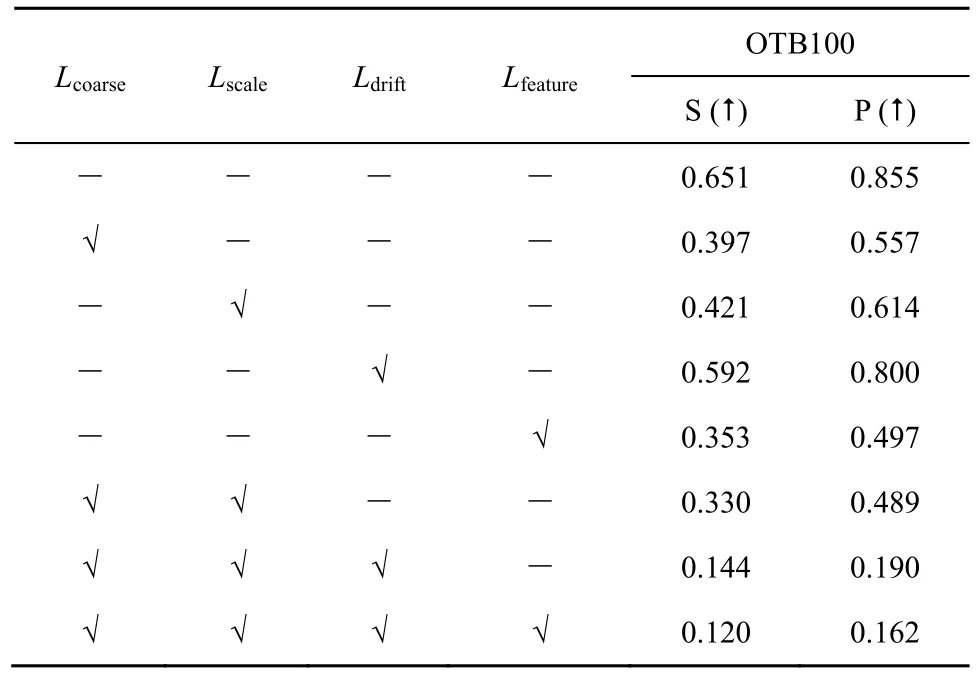
表7 SiamMask 跟踪器各损失项迁移性对比

表8 DiMP-50 跟踪器各损失项迁移性对比
5.5.4 攻击生成所付出代价分析
本文所提出的攻击方法包括欺骗损失、漂移损失、特征损失和感知损失。在生成器训练过程中,当无特征损失时,仅需要2 h 就能完成对所有视频的训练,得到扰动生成器。添加特征损失时,需要8 h 才能完成整个训练过程。这是由于特征损失涉及对特征图间的逐像素操作,且利用空间和通道注意力机制探索空间通道的依赖关系,寻找感兴趣区域,从而造成计算成本提高。尽管如此,本文方法对SiamRPN++及其他最先进跟踪器都能取得良好的攻击效果。如表4 所示,对于SiamRPN++跟踪器,添加特征损失比不添加时攻击成功率高出14.2%,精确度高20.2%,故虽付出了一定计算代价,却能有效欺骗跟踪器,使跟踪器偏离原始运动轨迹。所付出的计算代价是可容忍的。
6 结束语
针对现有对抗扰动技术难以有效地降低跟踪器的判别能力使运动轨迹发生快速偏移的问题,本文提出一种高效的攻击目标跟踪器的方法。首先,所提方法从高层类别和底层特征考虑设计了欺骗损失、漂移损失和基于注意力机制的特征损失来联合训练生成器,使其拥有对抗扰动的能力;然后,在对一段视频序列攻击时,将每帧干净图像送入该生成器中,生成对抗样本,以干扰SiamRPN 目标跟踪器,使其运动轨迹发生偏移,导致跟踪失败。所提方法在OTB100、VOT2018 和LaSOT 这3 个主流的目标跟踪数据集进行了验证,相较于对比方法,本文方法达到了较好的攻击效果。
