XGBoost模型在新冠疫情预测中的研究应用
2021-12-08李少亭王雪瑞
李少亭,王雪瑞
1(东北财经大学 统计学院,辽宁 大连 116025) 2(北京交通大学 理学院,北京 100044) E-mail:20121642@bjtu.edu.cn
1 引 言
2019新型冠状病毒(COVID-19)是新中国成立以来发生的最严重的一次重大突发公共卫生事件,具有传播速度快、感染范围广、持续时间长以及防控难度大等特点.此次新冠疫情持续时间较长,直到2021年仍然零星爆发,对我国经济造成巨大冲击,也对我国医疗卫生体系提出重大挑战.因此准确地预测疫情发展趋势,可以为疫情防控提供有效的参考信息,为打赢疫情防控阻击战提供数据支撑.
国内外学者针对新冠疫情构建了各种模型预测和分析其传播和发展趋势,主要集中在传播动力学模型和传统统计学模型.传播动力学模型主要根据各要素之间的关系构建微分方程从而模拟其发展趋势,因此被广泛地运用于传染病的传播与分析中.盛华雄等[1]在疫情控制阶段采用SIR模型分析和预测武汉市疫情,比较准确地刻画出各类人群在控制阶段随时间变化的规律.Zareie 等[2]构建SIR 模型,对伊朗新冠疫情传播进行有效预测.范如国[3]等基于复杂网络理论建立了SEIR模型,对3种情形下疫情拐点进行了预测,结果表明与真实情况基本吻合.Rajagopal等[4]采用分数阶SEIR模型对意大利新冠疫情进行预测,结果表明分数阶SEIR模型更接近真实数据.唐三一等[5]利用常系数的SEIHR模型较好地预测2020年1月24日凌晨以前累计报告确诊病例数.Manotosh等[6]建立SEIQR模型发现减少接触是控制疫情最有效的途径,并对印度马哈拉施特拉邦、泰米尔纳德邦和德里的疫情进行短期预测,建议增强对马哈拉施特拉邦和泰米尔纳德邦的防控力度.
也有部分学者运用传统统计模型对我国新冠疫情进行预测和分析.林德双等[7]运用ARIMA模型对中国疫情发展情况进行了预测.白璐等[8]利用ARIMA(1,1,1)模型对湖北省新冠肺炎确诊人数进行短期预测,并对相关防疫政策提供建议.王旭艳等[9]采用平滑指数模型对累计确诊人数、累计治愈人数以及累计死亡人数等进行拟合和预测.
此外,一些学者考虑了机器学习模型,但大多数是运用机器学习模型对新冠疫情进行诊断.高瞻等[10]利用XGBoost模型构建了新冠肺炎智能检测系统,能够准确地诊断新冠肺炎.Li等[11]提出了一个基于XGBoost的分类模型来区分流感患者和新冠肺炎患者.少部分学者运用机器学习模型对新冠疫情的趋势进行预测,如季伟东等[12]提出ADVPSO优化的神经网络模型预测新冠疫情传播趋势,具有较好的实用性.
尽管上述模型在一定程度上刻画了新冠疫情的趋势,但是仍然存在一些不足:1)多数学者预测分析之前未对数据进行预处理,大多数预测模型的预测精度和准确度有待提高;2)多数学者多采用传统的传染病模型以及统计模型,并未考虑机器学习模型以及深度学习模型;3)大多数模型仅仅采用短期数据进行短期预测,对实际的疫情防控帮助有限;4)采用的数据多为传统统计数据,传统统计数据存在获取周期长、容量较小以及时效性较差等缺点,必然会影响预测的准确度与时效性.
预测效果优秀与否不仅仅取决于预测模型的好坏,选取有效的预测数据也至关重要.在大数据背景下,网络搜索数据(Web Search Data,WSD)克服了传统统计数据的缺点,具有较强的便利性、时效性以及对用户的敏感性.实际上,Ginsberg 等[13]利用 Google 搜索数据准确地预测了美国各地区流感疫情每周的变化状况,该研究方法引起国内外专家学者的广泛关注.李秀婷等[14]发现网络搜索信息与流感趋势的历史信息互补,历史信息能够较好地预测流感趋势,而网络搜索信息能够保证对新变化的即时预测的精确度.王若佳等[15]指出历史数据以及网络搜索数据的综合使用具有良好的监测效果.Kurian等[16]发现谷歌趋势上的搜索关键词与美国部分地区新冠疫情的爆发具有强烈的相关性.
针对上述不足,本文将与我国新冠肺炎相关的网络搜索数据(Web Search Data,WSD)、自适应噪声的完整集合经验模态分解(Complete Ensemble Empirical Mode Decomposition with Adaptive Noise,CEEMDAN)和极端梯度提升树(eXtreme Gradient Boosting,XGB)结合起来构建我国新冠每日新增确诊人数预测模型,所构建的组合模型(CEEMDAN-XGB&WSD)具备良好的时效性、稳定性和精确度.同时引入CEEMDAN-XGB(未加入网络搜索数据)、CEEMDAN-LSTM&WSD(长短期记忆网络模型)、CEEMDAN-LSTM(未加入网络搜索数据)、CEEMDAN-BP&WSD(神经网络模型)、CEEMDAN-SVR&WSD(支持向量回归模型)、CEEMDAN-RFR&WSD(随机森林模型)、CEEMDAN-LGB&WSD(轻量提升树模型)作为基准模型进行相应的对比分析.因此本文将从以下4个方面展开研究:1)基于相关参考文献,分别从疫病名称、病理征状、传染防控、政策举措、器具名称以及机构、职业群体和场所名称6个方面构建与我国新冠疫情每日确诊人数相关的网络搜索关键词词库,并采用互相关系数和逐步回归的思想筛选出最终预测变量;2)对最终确定的预测变量与被预测变量采用数据预处理方式CEEMDAN去除高频噪声并重构数据;3)将重构后的数据集引入XGB模型,并运用网格搜索的方法寻找最优超参数,构建CEEMDAN-XGB&WSD模型,进而对我国新冠疫情每日新增确诊人数的变化情况进行探究和分析;4)引入多个基准模型和性能评价指标对组合模型进行较为科学、全面的评价.图1展示本文的工作流程与提出的组合模型.
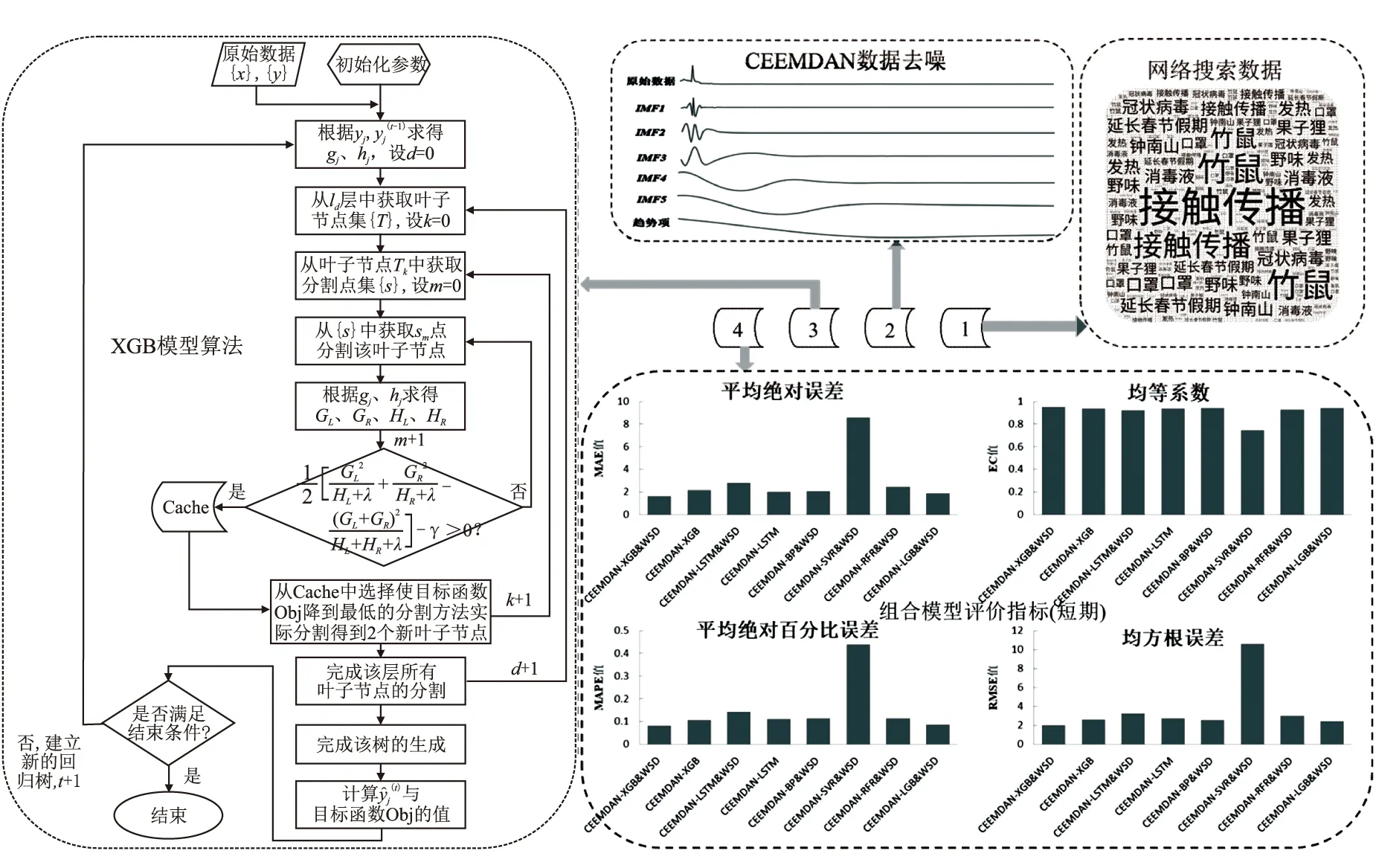
图1 组合模型流程图Fig.1 Flow chart of combined model
2 数据来源及预处理
2.1 数据来源
本文采用的中国新冠每日新增确诊人数为被预测变量,来自中华人民共和国国家卫生健康委员会官方网站,时间区间为2020年1月10日-2020年12月31日.预测变量为与我国新冠肺炎相关的网络搜索关键词,数据来源于百度指数,时间区间为2020年1月10日-2020年12月31日.
随着计算机技术的发展,人类社会不断产生具有更强时效性的新数据.在流行病爆发时,人们会通过百度、谷歌等搜索引擎查询该病的爆发情况以及相应的预防措施等.因此,利用开源的网络搜索数据监测我国新冠疫情是对传统监测手段的有效补充,能够起到早期预警、指导医疗救治以及完善防控策略等作用.由于与我国新冠疫情相关的网络搜索词较多,选取有效的、预测能力好的网络搜索关键词至关重要.本次研究对网络搜索关键词的选取和确定步骤如下:
2.1.1 初始网络搜索关键词的确定
查阅相关文献,分别从疫病名称、病理征状、传染防控、政策举措、器具名称以及机构、职业群体和场所名称6个方面选取与我国新冠每日新增确诊人数相关的96个初始关键词,如表1所示.

表1 网络搜索关键词词库Table 1 Thesaurus of web search keywords
2.1.2 潜在预测变量筛选
首先去除百度指数中没有的42个初始网络搜索关键词;其次,由于部分关键词与被预测变量相关性不高,对模型的预测效果贡献度较低,因此需要筛选出可能具有良好预测性能的关键词.互相关系数可以计算两个时间序列在做任意两个不同时刻的相关程度,从而寻找与被预测变量相关性较高的预测变量.取阈值为±0.7,采用互相关分析选取16个潜在预测能力较好的预测变量.被预测变量自相关系数为0.621,滞后阶数为1,由于历史信息对预测至关重要,故放入潜在预测变量中,与网络搜索数据综合使用.
2.1.3 最终预测变量的确定
不同的网络搜索关键词对预测效果的贡献不同,有些词汇对预测贡献较小,反而增加模型复杂度,应当剔除.本次研究采用逐步回归的思想,建立回归模型,根据AIC准则剔除贡献度低的预测变量,最终保留7个具有良好预测性能的预测变量,结果如表2所示.

表2 被预测变量与预测变量相关分析Table 2 Correlation analysis between predicted variables and predictors
2.2 数据预处理
本次数据具有非平稳、非线性、信噪比低以及局部噪声大等特点,直接带入模型进行预测效果较差,因此在建模之前需要对数据进行预处理.Huang等[17]提出一种适用于非线性非平稳信号的自适应信号时频处理方法—经验模态分解(EMD).为了克服EMD的模态混叠现象,Wu等[18]又提出了一种噪声辅助信号分析方法—集合经验模态分解(EEMD),但仍然存在计算成本大、重构误差大等缺点.Yeh等[19]提出了互补集合经验模态分解(CEEMD),在原始信号中加入成对正负辅助白噪声,在集合平均时相抵消,提高分解效率并降低重构误差.Torres等[20]对CEEMD进行了改进,提出了自适应噪声的完整集合经验模态分解(CEEMDAN),解决了集合平均时IMF分量无法对齐的问题.此方法已在一些工程应用方面取得了较好的效果,如心电信号去噪等[21].
本文采用自适应噪声的完整集合经验模态分解(CEEMDAN)将原始数据分解成几个从高频到低频的IMF分量,去除频率较高的噪声,保留低频分量进行数据重构.定义待分解数据为X(t),定义算子Ek(·)表示数据经过EMD分解后得到的第k个固有模态分量,设数据分解后共有K个固有模态分量,则CEEMDAN算法分为如下几个步骤.
步骤1.在原始数据中添加不同幅度的高斯白噪声,进行EMD分解:
(1)


(2)


(3)
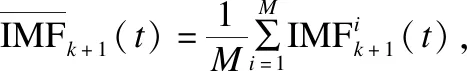
步骤4.重复上述步骤直到提取出所有固有模态分量及最终残差(趋势项)r(t),则原数据可以表示为:
(4)

步骤5.去除频率较高的噪声(前a个IMF分量,a∈{1,2,…,K},a一般由经验确定),保留低频分量及趋势项进行数据重构,则重构数据为:
(5)
被预测变量yt的去噪过程以及去噪后数据对比如图2所示.从图2可以看出原始数据经过CEEMDAN分解后,得到5个固有模态分量和趋势项.在剔除频率较高的噪声(IFM1)并进行重构后得到重构数据.重构数据保留了数据的主要特征,变得更加平滑.根据重构数据分析原始数据的本质特征,可以得到更加合理准确的评估和预测.

图2 数据去噪过程及对比Fig.2 Data denoising and comparison
3 模型建立与分析
3.1 极端梯度提升树
极端提升树是Chen等[22]提出的基于集成思想的机器学习算法.与传统的集成学习不同,传统的集成学习如随机森林(RF)是通过减少模型方差提高性能,极端提升树(XGBoost)通过减少模型的偏差提高性能.作为机器学习方法的一种,XGBoost在网络入侵检测[23]、卫星网络协调态势预测[24]等工程应用方面取得了良好的效果.极端提升树的主要思想就是基于当前的模型加入另一个模型,使得组合模型的效果优于当前模型,以下是推导过程.
(6)

(7)
(8)
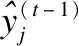
对式(7)进行泰勒展开
(9)
(10)

(11)
对目标函数进行变形:
(12)

(13)
对wo求偏导进行求解后带入目标函数得到:
(14)
极端提升树利用贪心算法遍历树模型的所有分裂叶子节点,选择分裂后目标函数增益最大的叶子节点进行分裂,判定条件如下所示:
(15)
3.2 模型输入集构造
从表2可知,我国新冠每日新增确诊人数与本身滞后1阶变量存在显著相关关系,并且是重要的历史信息,故选取其1阶滞后作为预测变量;接触传播滞后15阶与每日新增确诊人数存在较高的正相关,高达0.841,接触传播是新冠肺炎的主要传播方式,表明人民群众对传染防控的关注,传染防控的落实程度将会影响每日新增确诊人数;竹鼠、野味和果子狸的21阶滞后均与我国新冠每日新增确诊人数存在较高的正相关,竹鼠、野味和果子狸也是新冠肺炎疑似携带者;延长春节假期的17阶滞后也与被预测变量存在较高的正相关性,确保疫情防控各项政策措施落地落实才能够精准科学防控疫情;消毒液的6阶滞后与预测变量存在较高的正相关,合理使用疫情防控器具才能够打赢疫情防控战.
综上所述,本次研究的输入变量为{yt-1,x2,t-15,x5,t-21,x8,t-17,x9,t-21,x10,t-6,x12,t-21},yt为输出变量,实验数据集为{yt-1,x2,t-15,x5,t-21,x8,t-17,x9,t-21,x10,t-6,x12,t-21:yt},共335个样本.为增强模型的预测性能,采用式(16)对数据集进行归一化.
(16)
式(16)中,zs表示第s个样本点取值,zmin、zmax分别表示样本区间的最小值和最大值.归一化后数值落入[0,1]区间,这种数据处理方式一定程度上能够提升模型的预测能力[25].模型训练完成后,再将预测结果进行反归一化N-1(zs)得到预测值.考虑到模型的泛化能力,将归一化后的数据集分为训练集和测试集;同时为了进一步检验预测模型的稳健性,本次研究分别检验模型12期短期、36期中期以及72期长期的预测性能.
3.3 模型预测性能评价指标
为了对组合模型进行较为科学、全面的评价,本文引入多种模型预测性能评价指标对组合模型的预测性能进行评测,分别有平均绝对误差MAE,均等系数EC,平均绝对百分比误差MAPE,均方根误差RMSE,绝对百分比误差REP,其公式如下所示.
(17)
(18)
(19)
(20)
(21)

3.4 组合模型结果分析
本次研究运用Python语言环境,主要基于scikit-learn库建立组合模型CEEMDAN-XGB&WSD.根据预测算法流程,将经过预处理的数据集导入XGB模型,基于网格搜索的思想寻找最优超参数后,运用最优超参数结合训练集构建模型,获得最优参数,最后将最优参数的模型保留并分别在12期短期、36期中期以及72期长期测试集上检验所构建模型的预测性能以及模型的稳健性.
预测结果显示组合模型CEEMDAN-XGB&WSD在短期、中期以及长期预测中均有良好的性能.根据图3所展示的短期、中期、长期每日新增确诊人数REP箱线图,可以看出在不同时期与其他基准模型相比,组合模型CEEMDAN-XGB&WSD的绝对百分比误差REP整体值较小并且相对更加集中,表明本次研究提出的模型具有更好的精确度和稳定性.

图3 每日新增确诊人数REP箱线图Fig.3 Box-plot of REP of daily new coronavirus cases
为了进一步评价组合模型CEEMDAN-XGB&WSD,本文以MAE、EC、MAPE以及RMSE为评价指标,以短期(12期)、中期(36期)以及长期(72期)为时间区间,分别测评CEEMDAN-XGB &WSD、CEEMDAN-XGB、CEEMDAN-LSTM &WSD、CEEMDAN-LSTM、CEEMDAN-BP &WSD、CEEMDAN-SVR &WSD、CEEMDAN-RFR&WSD以及CEEMDAN-LGB &WSD这8个预测模型的预测性能,结果如表3所示.

表3 不同模型评价指标对比Table 3 Comparison of evaluation indexes of different models
从短期和中期来看,组合模型CEEMDAN-XGB&WSD的预测性能的各项评价指标均优于其他7个预测模型,从长期看,组合模型CEEMDAN-XGB&WSD的预测性能的评价指标中仅MAPE略微高于CEEMDAN-XGB模型,其余评价指标均优于其他7个模型.
从稳健性上看,组合模型CEEMDAN-XGB&WSD从短期到长期的预测性能波动幅度不大,其预测误差和拟合度不随预测时间的增加而发生剧烈波动,稳健性明显优于其他7个模型,这充分表明在本次研究中组合模型CEEMDAN-XGB&WSD具有较好的稳健性.因此,从整体上看,组合模型CEEMDAN-XGB&WSD具有良好的预测性能和稳健性,优于其他7个预测模型.
在拟合度方面,相对于不加入网络搜索数据的CEEMDAN-XGB模型,组合模型CEEMDAN-XGB&WSD的拟合度在短期、中期和长期分别提升了1.41%、0.68%和0.38%;相对于不加入网络搜索数据的CEEMDAN-LSTM模型,拟合度在短期、中期和长期分别提升了1.67%、2.59%和4.80%;而相对于CEEMDAN-LSTM&WSD、CEEMDAN-BP&WSD、CEEMDAN-SVR&WSD、CEEMDAN-RFR&WSD以及CEEMDAN-LGB&WSD模型,其拟合度在短期分别提升了3.27%、1.04%、27.59%、2.57%和0.90%,在中期分别提升了4.54%、8.19%、54.62%、0.77%和1.99%,在长期分别提升了9.28%、8.64%、14.11%、0.83%和0.64%.
在误差方面以MAE为评价指标,可以看出组合模型CEEMDAN-XGB&WSD具有强大的学习能力和泛化能力,可以将误差控制在合理范围内,并且在不同时期与其他模型相比与预测性能均有不同程度的提高.相对于不加入网络搜索数据的CEEMDAN-XGB模型,组合模型CEEMDAN-XGB&WSD的平均绝对误差在短期、中期和长期分别降低了24.72%、6.88%和0.83%;相对于不加入网络搜索数据的CEEMDAN-LSTM模型,平均绝对误差在短期、中期和长期分别降低了19.11%、25.43%和30.16%;而相对于CEEMDAN-LSTM&WSD、CEEMDAN-BP&WSD、CEEMDAN-SVR&WSD、CEEMDAN-RFR&WSD以及CEEMDAN-LGB&WSD模型,其平均绝对误差在短期分别降低了42.02%、22.02%、81.02%、33.87%和13.36%,在中期分别降低了36.33%、49.47%、85.03%、8.89%和17.66%,在长期分别降低了52.10%、48.80%、82.69%、4.22%和5.76%.
综上所述,在我国新冠每日新增确诊人数的预测研究中,组合模型CEEMDAN-XGB&WSD具有卓越的记忆功能、强大的学习能力、优秀的泛化能力以及良好的稳健性,可以进行较为准确并且稳定的短期、中期和长期预测;同时也证明加入了网络搜索数据的CEEMDAN-XGB&WSD模型性能明显优于不加入网络搜索数据的CEEMDAN-XGB模型以及CEEMDAN-LSTM模型,网络搜索数据能够对历史数据进行补充,进一步提高模型预测的准确性.
4 结 论
本次研究结合网络搜索数据,运用CEEMDAN进行去噪后引入XGBoost模型,构建了组合模型CEEMDAN-XGB&WSD,经过对比分析得出如下结论.
1)网络搜索数据具有时效性强、数据容量大以及易于获取等优点,可以对传统统计数据进行有效地补充.
2)将CEEMDAN和XGBoost引入组合模型使得其具有强大的学习能力以及稳健性,可以将误差控制在合理范围内并且不随预测时期的增加而剧烈波动.
3)从预测性能上看,组合模型CEEMDAN-XGB&WSD在短期、中期以及长期都具有较高的精确度,预测性能明显优于其他7个模型,说明本次研究构造的组合模型CEEMDAN-XGB&WSD在我国新冠每日新增确诊人数的预测上具有良好的性能,是一个合理有效的模型.
综上所述,本次研究构造的组合模型CEEMDAN-XGB&WSD能够准确地预测每日新增确诊人数,为我国制定合理有效的防疫政策提供有力的数据支撑.同时本次研究所构建的模型也可以为与疫情相关的其他指标的预测提供思路,将模型推广到其他疫情相关指标的预测中.
