一种基于多粒度循环神经网络与词注意力的多轮对话回答选择方法
2021-12-08陈羽中刘漳辉
谢 琪,陈羽中,刘漳辉
(福州大学 数学与计算机科学学院,福州 350116)(福建省网络计算与智能信息处理重点实验室,福州 350116)E-mail:lzh@fzu.edu.cn
1 引 言
根据不同的应用场景,对话系统可以大致分为两类:一类是任务型对话系统[1-3],另一类是开放领域对话系统[4-6].面向任务的对话系统专注于特定的垂直领域,目标是帮助用户完成特定的任务,例如预订机票、旅馆等.由于缺乏特定领域的对话数据,大多数任务型对话系统必须依靠人工设计的模板或启发式规则来处理用户对话.因此,实现任务型对话系统需要大量的人工投入.此外,人工设计的模板或启发式规则无法涵盖所有可能的对话情景,从而限制了任务型对话系统适应其它垂直领域的能力.开放领域对话系统则专注于开放领域[7],并要求其响应多样化和个性化,因此需要大规模的对话知识库来对模型进行训练.随着社交网络的爆炸式增长,Twitter、微博等社交媒体积累了大量的对话数据,使得从网络中获取开放领域对话数据集并构建数据驱动的开放领域对话系统成为可能.构建开放领域对话系统,可以进一步提高对话系统的实用性.随着科技的发展,人们不仅仅满足于单轮对话的需求,多轮对话回答选择顺势而生.多轮对话回答选择是构建开放领域对话系统的关键问题之一.
近年来,深度神经网络已逐渐成为构建开放领域对话系统的主流方法.通常来说,多轮对话答案选择方法可以大致分为两类,一类是基于生成模型的多轮对话答案选择方法,另一种是基于信息检索的多轮对话答案选择方法.基于生成模型的多轮对话答案选择方法[8-10]通常采用Seq2Seq模型[11],Seq2Seq由一个编码器和一个解码器组成.编码器从输入句子中提取语义和上下文信息,并将其映射为中间表示,解码器则依次从中间表示生成响应.然而,基于生成模型的多轮对话答案选择方法在生成的回答中经常出现语法错误.相比之下,基于信息检索的多轮对话答案选择方法[12,13]旨在使用匹配算法从语料库中选择与给定的对话上下文最相关的语料作为答案.与基于生成模型的多轮对话答案选择方法相比,基于信息检索的多轮对话答案选择方法可以提供更有意义和更流畅的响应,且不存在语义歧义,具有更好的实用性.网络数据的多样性也使得基于信息检索的多轮对话答案选择方法能够有效地处理低覆盖率的问题.因此,本文主要研究基于信息检索的多轮对话回答选择方法.
针对多轮对话回答选择问题,虽然深度神经网络在理解用户意图和检索最佳匹配答案等方面取得了显著的进展,但是仍然存在着重大挑战.较早的研究工作多把对话上下文连接形成一个长文本,然后输入到卷积神经网络或循环神经网络中进行匹配,但是这种基于连接成长文本的语义匹配方式忽略了对话上下文中语句之间的依赖关系.近期的研究工作主要使用对话上下文分别和回答进行匹配的方式,分别形成词语的相似度矩阵和句子的相似度矩阵,再输入到特征提取层中对特征信息进行提取.使用这种方式进行匹配由于只存在句子粒度和词语粒度的信息,这两种粒度信息不能充分表示对话上下文和回答的语义信息,从而会产生语义的缺失.并且,这种方式无法使对话上下文和回答之前的关键信息进行契合的匹配,从而导致对话上下文和回答语义匹配度低.
针对上述问题,本文提出了一种结合词注意力机制的多粒度循环神经网络模型MRNA,主要贡献如下:
1)为了解决粒度信息不够丰富的问题,MRNA采用AHRE[14]机制对每个句子进行层级的编码并将其分割为不同的粒度,通过融合词语粒度、前向句子粒度、后向句子粒度,增强句子的语义表示,防止句子出现语义缺失.
2)MRNA运用词注意力机制通过动态学习注意力矩阵的权值,赋予对话上下文和回答中契合的关键词和次要词不同的注意权重,从而有效提取对话上下文和回答中匹配的重要信息.
3)本文在Ubuntu数据集[15]和Douban数据集[16]上进行了试验,实验结果表明MRNA在这两个公开的数据集上都取得了领先的效果.
2 相关工作
近年来,对话系统受到了人们的广泛关注,对对话系统的研究可以追溯到20世纪60年代.Eliza[17]是最早依靠手工模板或启发式规则来生成响应的对话系统,这需要大量的人力物力资源,但取得的效果有限.随着研究的不断深入,一种基于数据驱动的方法被提出来了,让对话系统从庞大的对话数据集中学习如何与人交谈.目前,非任务型对话系统主要有两种实现方式,即基于信息检索的方法和基于生成的方法.
基于生成的方法主要使用机器翻译技术来生成响应.Li等[18]认为传统的Seq2Seq模型过于保守,倾向于生成安全通用的回答,因此使最大互信息代替最大似然估计作为新的目标函数.MMI可以产生多样化的响应,并且生成的语句更契合主题.Xing等[19]提出了一种基于Seq2Seq的模型,通过联合注意机制和偏差生成的概率权衡主题信息,从而生成丰富的响应.基于生成的方法实用性较差,需要大量的时间进行训练,并且生成的回答很容易产生语法错误.
基于信息检索的方法通过搜索和排序从现有数据集中进行筛选,选择匹配度最高的回答作为响应.早期基于信息检索的方法主要用于短文本和单轮对话.Hao等[20]基于实际的样例构建了一个短文本对话数据集,为后面的研究提供了丰富的示例.Hu等[21]提出了一种卷积神经网络模型来匹配两个语句.该模型不仅可以表示句子的层级结构,而且在不同层级上捕捉丰富的匹配模式.Wang等[22]提出了一种被称为深度匹配树的模型.深度匹配树利用深度神经网络挖掘句法信息的模式,从而更高效、直观地计算两个短句之间的相似度.一般来说,上述算法仅适用于短文本或单轮对话,它们没有考虑多轮对话中对话上下文和各个话语之间的序列依赖关系.
近年来,研究人员研究的重心转向了多轮对话的研究.多轮对话需要考虑对话语境的长期依赖关系,这比研究单轮对话要困难得多.Lowe等[15]构建了世界上最大的多轮对话语料库Ubuntu数据集,它的出现促进了多轮对话的发展.Kadlec等[23]研究了CNN[24]、LSTM[25]、Bi-LSTM等不同深度网络在Ubuntu数据集上的性能表现.Zhou等[26]提出了Multi-view模型(Multi-view Response Selection Model),该模型结合了话语序列视图和单词序列视图两种不同视图的信息.并且它把对话上下文中的话语都看做单独的语句,并没有把对话上下文看做一个长语句,这样可以有效地捕捉话语之间的依赖关系.Yan等[27]经过研究提出了DL2R(Deep Learning-to-respond),该网络结合多种信息,使用CNN提取连续词之间的局部邻接特征,从而生成话语的复合表示.Wu等[16]提出了SMN模型(Sequential Matching Network),SMN在多个粒度级别上将对话上下文中的每个话语和回答进行匹配,并通过卷积和池化操作从话语回答对中提取重要的匹配信息.SMN充分考虑了之前的话语与回答之间的交互信息,因此它可以承载丰富的语义信息和长期依赖关系.An等[28]使用交叉卷积运算来扩展编码器,通过从数据集中学习不同向量的表示从而改进了稀有词的表示,解决了稀有词的信息缺失的问题.Dong和Huang[29]将预训练的词向量与在任务特定训练集上生成的向量相结合,从而解决大量未登录词的问题.Zhang等[30]使用GRU[31]对话语进行编码,并且每个话语和最后一句话语进行融合,从而提高最后一句话语在对话上下文中的权重.然后采用门控自注意机制直接将融合后的表示与自身进行匹配,从而获得更有区别性的语义特征.Zhou等[32]结合Transformer[33]提出了自注意力机制和交叉注意力机制,其中自注意力机制用于构建具有不同粒度的文本片段表示,交叉注意力机制用于捕获潜在匹配片段对之间的依赖关系.从而增强不同粒度的语义信息,为多轮对话答案选择的语义匹配提供丰富的语义特征信息.
3 模 型
3.1 问题定义

3.2 模型框架
本文所提出的MRNA模型的总体架构如图1所示,包括词语表示层、多粒度语义信息融合层、词注意力层、语义匹配层以及预测层5个模块.词语表示层采用双通道的方式更准确的表示语义表征向量.多粒度语义信息融合层将对话上下文和回答使用AHRE进行编码,并且对编码后的序列进行分割获得前向序列相似度矩阵和后向序列相似度矩阵.词注意力层通过动态地学习注意力矩阵的权重,从而提取与对话上下文和回答最契合的关键信息.语义匹配层将词矩阵、前向序列矩阵、后向序列矩阵通过卷积和最大池化操作提取每个话语和回答对的特征信息,并通过GRU按时间顺序累积向量.预测层则通过Softmax生成一个类标签上的概率分布.

图1 MRNA模型架构Fig.1 Framework of the MRNA model
3.3 词语表示层
在深度神经网络中,如果要表示一个单词就需要将单词转化为词向量的形式.MRNA通过一个预先训练好的词向量矩阵E∈R|D|×dv,将(C,R)对中的每一个词都需要转化为低维的词向量,其中|D|表示词典中的词语数,dv表示词向量的维度.
多轮对话语料库中存在的未登录词是一个非常棘手的问题,句子中的未登录词无法映射为词向量,导致句子语义信息的缺失,影响模型的有效性.MRNA使用卷积神经网络进行字符级编码,并与词向量进行连接,从而缓解未登录词对模型的影响.
假设有一个单词w=(x1,…,xi,…,xlw),xi代表单词w中的第i个字符,lw代表w的字符数.通过查询预训练的字符向量表的方式将字符映射为一个向量wc∈Rdc,wc代表字符映射之后的向量,dc代表字符向量的维度.将单词中的每个字符进行映射就可以得到单词w的表征矩阵.之后将矩阵输入到CNN中,并使用不同的过滤器来进行特征提取.经过卷积和池化操作,再将所有的特征都连接起来.其中de表示CNN中过滤器的数量,第j个过滤器的大小使用sj来表示,卷积运算后第k个元素的输出为oj,k.卷积和最大池化操作的公式如下:
(1)
(2)
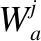
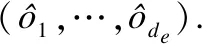
最后,将对话上下文和回答中的每个单词的词向量与该单词的字符级表示连接起来,从而得到Ut=[et,1,…,et,i,…,et,lt]和R=[er,1,…,er,i,…,er,lr].Ut和R分别代表对话上下文第t句话语和回答的最终表示,et,i,er,i∈Rdw,dw代表最终词向量的维度.
3.4 多粒度语义信息融合层
现在大多数对话系统的模型仅使用LSTM或GRU对话语进行编码,这种方式无法充分捕获到序列中的时序关系,导致上下文语义特征匮乏无法充分用于预测.为了增强所获得的语义特征,我们采用了AHRE对话语进行编码.AHRE采用层级BiLSTM,将l-1层的输出作为第l层的输入,并结合每个输入词向量进行堆叠,学习话语的线性变化.AHRE与只使用单层的RNN相比,性能得到了提高.AHRE计算公式如下:
(3)
(4)


(5)
(6)
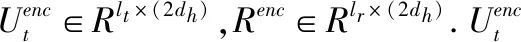
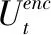
(7)
(8)

3.5 词注意力层
为了防止在计算词矩阵的过程中语句中的每个词权重都相同,从而导致对话上下文和回答中语义相关信息得不到突出,引入词注意力层.词注意力层采用词注意力机制.通过动态学习注意力矩阵的权重,词注意力机制将单词权重集中在对话上下文和回答中最匹配的关键词上,以防止无关的单词获得更多注意力.首先将句子语义表征s输入到MLP中,从而获得hs作为s的隐藏层表示,s代表3.3节中对话上下文和回答中任意一句话的语义表征.之后使用Ws∈Ratt×1来动态计算注意力权重的分布,通过一个softmax函数得到归一化的注意力权重a.最后,将句子和归一化的权重进行元素逐位相乘,从而获得词注意力层的输出.词注意机制的公式如下:
hs=tanh(sWw+bw)
(9)
a=softmax(hsWs)
(10)
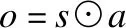
(11)
其中s代表输入的句子,o为词注意力机制的输出.Ww∈Rdw×att,bw∈R1×att代表参数,att代表注意力机制的大小.⊙代表元素之间按照对应位置相乘.
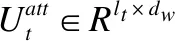
(12)
其中M3,t代表词语的相似度矩阵.
3.6 语义匹配层
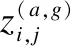
(13)
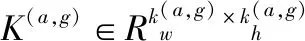
(14)
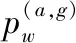
将池化层的输出输入到全连接层进行降维操作,从而获得Ut和R语义融合的向量表示.将全连接层的输出的所有向量进行连接操作可以得到[Z1,…,Zlt]∈Rlt×df,df表示经过全连接层之后的维度.由于对话上下文中的每个话语还包含时序关系,MRNA使用GRU对话语之前的潜在语义关系进行建模.将[Z1,…,Zlt]作为一个序列输入到GRU当中,获取最后的隐藏状态Hm=[h1,…,hlt].GRU的计算公式如下:
(15)
(16)
(17)
(18)
其中zi和ri分别代表更新门和重置门,σ(.)代表sigmoid函数,Wz,Wr,Wh,Vz,Vr,Vh代表训练的参数,⊙代表元素之间按照对应位置相乘.
3.7 预测层
预测层以语义匹配层的输出作为输入通过一个全连接的层,并使用softmax函数来生成一个类标签上的概率分布g(C,R).g(C,R)的定义如下:
(19)
其中Wd和bd代表参数.MRNA使用交叉熵作为损失函数计算损失值,通过Adam优化算法进行学习率的更新,利用反向传播迭代更新模型参数,以最小化损失函数来训练模型.其中,最小化损失函数Loss的计算公式如下:
(20)
4 实验和结果
4.1 数据集
本文选择使用Ubuntu和Douban两个数据集对MRNA模型进行评估.Ubuntu数据集是目前最大的英文多轮对话语料库,内容主要是从Ubuntu聊天内容中提取出来,作为对话问题的公共语料库.Ubuntu数据集中积极的回答来自于人的对话,而消极的回答是从数据库中随机选择的.训练集包含100万个对话上下文-回答-标签组,其中积极和消极的回答比例是相同的.在验证和测试集上,积极的回答和消极的回答的比例是1:9.豆瓣数据集是开放域的中文数据集,从豆瓣网爬取得到,候选回答通过一个检索系统获得.表1显示了两个数据集的统计信息.

表1 数据集统计信息Table 1 Statistics of datasets
4.2 对比算法
实验中对比算法的如下:
TF-IDF[23]:TF-IDF一般用于获取给定单词对某个文档的重要程度.
RNN[23]:该模型使用两个RNN分别对对话上下文和回答进行时序建模,使用隐藏层计算出最后的分数.
LSTM[23]:该模型使用LSTM通过遗忘门移除上一层的隐藏层状态,对对话上下文和回答的长期依赖性进行建模.
MV-LSTM[34]:该模型将对话上下文视为一个句子构造捕获词语信息的矩阵,然后使用RNN提取局部句子的相互信息,其重要性由四种类型的门决定.
Match-LSTM[35]:该模型将对话上下文连接成一个长语句,两个语句在每个位置上的交互是由其前缀之间的交互以及在词语层面上的交互组成.
Multi-View[26]:该模型从话语序列视图和单词序列视图两种不同视图的信息计算上下文和候选回答之间的匹配程度.它把对话上下文中的话语都看做单独的语句,并没有把对话上下文看做一个长语句.
DL2R[27]:该模型首先使用不同方法,用先前对话上下文的话语来重构对话上下文最后话语.然后用RNN和CNN的组合表示候选的回答和先前重构的话语.最后,通过连接这些表示来计算匹配分数.
SMN[16]:该模型分别在词语级和句子级分别对对话上下文的每个话语和回答进行匹配并通过卷积和池化操作从话语回答对中提取重要的匹配信息.最后输入到GRU中,对序列信息进行建模.
DUA[30]:该模型首先使用GRU对话语进行编码,并且每个话语和最后一句话语进行融合,提高最后一句话语在对话上下文中的权重.然后采用门控自注意机制直接将融合后的表示与自身进行匹配,从而获得更有区别性的语义特征.
上述对比模型中,TF-IDF是基于传统统计的方法.RNN、LSTM是基于单一循环神经网络的单轮对话模型,MV-LSTM、Match-LSTM也是单轮对话模型,Multi-View、DL2R、SMN、DUA则为多轮对话模型.MRNA、SMN、DUA均采用CNN对词矩阵和句子矩阵进行特征提取,但MRNA获取的是层级的序列信息,并且使用词注意力机制获取关键词,而SMN、DUA则仅获取单层的序列信息,词矩阵的生成也仅仅是简单的将对话上下文和回答相乘.
4.3 实验设置和评估指标
在这两个数据集上,词向量的训练根据Gu等[14]的操作进行.在Ubuntu数据集上,我们将300维Glove词向量和100维Word2vec词向量进行连接操作,从而得到最终的词向量.在中文Douban数据集上,我们将Song等[36]提出的200维词向量和200维Word2vec词向量进行连接操作,从而得到最终的词向量.因为中文字符量太大,我们只在Ubuntu数据集上使用字符级编码,字符级表示使用的是150维的向量.对于字符级编码,在卷积操作中使用3,4,5分别作为窗口大小进行运算.在多粒度语义信息融合层中,BiLSTM的隐藏层大小为200,层数为3.在单词注意力模块中,注意机制的大小为25.在匹配层中,GRU的隐藏层大小为200.我们的学习使用Adam作为优化器,初始学习率是0.001.
本文采用与参考文献[16]相同的评价指标.Rn@k表示在n个候选回答中,选择了k个最匹配的回答,并且正确的回答在这k个回答之中.在Ubuntu数据集上,我们选择R2@1,R10@1,R10@2,R10@5作为评价指标.在Douban数据集上,除了使用R10@1,R10@2,R10@5作为评价指标,我们还加入了MAP[37]、MRR[38]、P@1作为评价指标.
4.4 实验结果分析
表2展示了MRNA和基准算法在Ubuntu和Douban数据集上的实验结果.除MRNA模型外,其他模型的相关数据均来自其他文献.从表2的实验结果可以发现,MRNA模型在两个数据集的表现均优于所有基准算法.与LSTM、MV-LSTM等单轮对话算法相比,MRNA在各个评价指标上都有明显的提升.与效果最佳的单轮对话模型MV-LSTM相比,在Ubuntu数据集上,MRNA的R2@1、R10@1、R10@2、R10@5分别提升了3%、10.4%、6.4%、2.1%.在Douban数据集上,MRNA的R10@1、R10@2、R10@5分别提升了6.2%、8%、8.7%.从实验结果可以发现,MRNA模型相比于MV-LSTM模型有较大的性能提升.MRNA模型中,对话上下文中的每一个句子都和回答进行匹配,并使用GRU对上下文特征信息进行提取,从而保留了对话中的上下文信息.而MV-LSTM模型将对话上下文连接成一个长句,忽略了对话间的上下文依赖.这也是单轮对话模型性能普遍低于多轮对话模型的主要原因.与SMN、DUA等多轮对话模型相比,MRNA也获得了较优的性能.和DUA相比,在Ubuntu数据集上,R10@1和R10@5分别提升了0.5%,R10@2的效果持平.在Douban数据集上,MRNA的所有评价指标都提升了1%左右.这是因为在MRNA模型分别使用AHRE和词注意力机制提取层级信息和句子中的关键信息.DUA模型尽管将对话上下文的每句话和最后一句话进行融合,并且使用门控自注意力机制提取语义信息.但DUA没有考虑序列的层级信息,并且词矩阵未使用注意力机制提取其中的关键词,这样容易导致上下文语义信息的缺失.
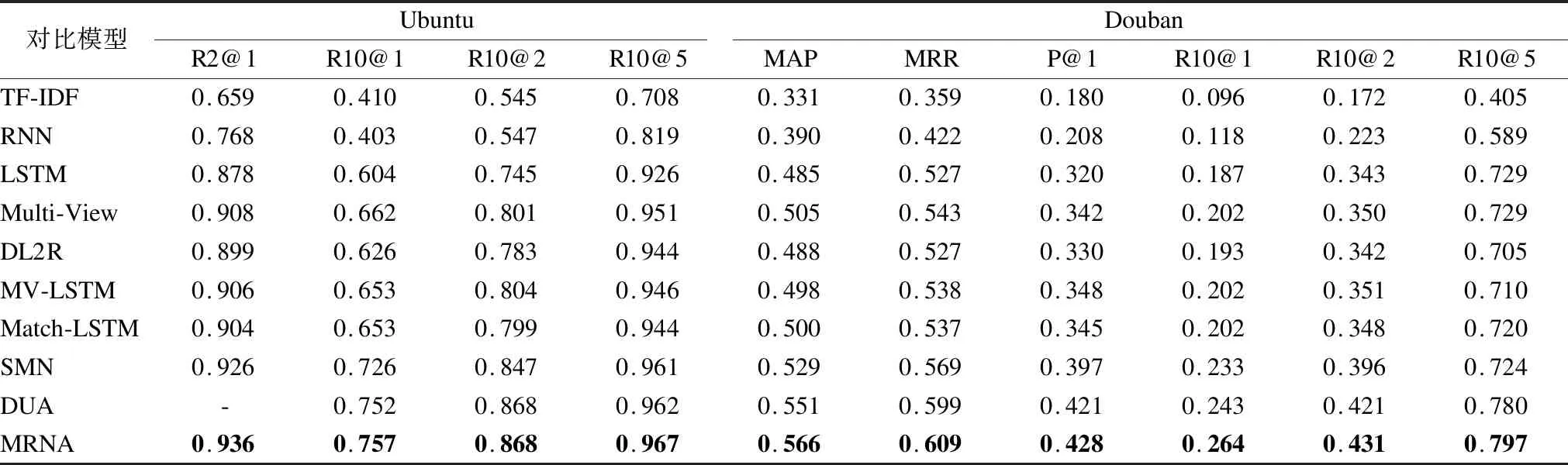
表2 MRNA与基准模型的性能对比Table 2 Overall performance of MRNA and the baseline models
4.5 模型分析
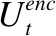

表3 消融实验结果Table 3 Ablation experiment results
实验结果如表3所示,可以看出各模块对MRNA模型的总体性均有积极的影响.MRNA w/o CHAR在Ubuntu数据集R2@1、R10@1、R10@2、R10@5分别下降了0.6%、1.7%、1.2%、0.3%.上述结果表明字符级编码的有效性.字符级编码主要是用来解决未登录词的问题,避免由于某些不在词汇表中的词造成语义缺失的情况.MRNA w/o AHRE在Ubuntu数据集R2@1、R10@1、R10@2、R10@5分别下降了0.7%、1.7%、1.1%、0.4%,在Douban数据集上MAP和MRR分别下降了1%、1%.AHRE模块使用多层BiLSTM提取序列信息,层数的选择非常重要,并且会影响模型的效果.上述结果显示,仅使用BiLSTM的效果并不理想,因为它无法捕获足够的时序信息.MRNA w/o Word Attention在Ubuntu数据集R2@1、R10@1、R10@2、R10@5分别下降了1.3%、2.7%、2.2%、0.9%,在Douban数据集上MAP和MRR分别下降了0.9%、0.6%.词注意力机制模块的主要功能是将对话上下文和回答中最匹配的单词赋予较大的权重,将一些无用的单词赋予较小的权重,从而达到提取关键词的效果.上述结果也验证了词注意力机制的有效性.MRNA w/o Split在Ubuntu数据集R2@1、R10@1、R10@2分别下降了0.2%、0.6%、0.3%,R10@5持平,在Douban数据集上MAP和MRR分别下降了0.8%、1.1%.将编码后的句子进行切分操作,这样可以形成多粒度信息,从而有效地捕获话语的潜在语义信息,克服话语之间的语义鸿沟.上述实验结果也证明了分割句子操作的有效性.
4.6 参数分析
本节将通过实验分析MRNA模型中的参数对MRNA的性能影响.在MRNA模型中,利用了GRU按时间顺序累积特征向量,从而对对话上下文和回答的特征按时序关系进行建模.GRU隐藏层的设置成为了影响MRNA模型效果的重要超参.图2中给出了不同超参数配置下GRU隐藏层大小对MRNA模型的影响.从Ubuntu数据集和Douban数据集的实验结果来看,当GRU隐藏层大小为200时,模型效果最佳.当GRU为100时,隐藏层大小不足以按照时间顺序累积特征,使向量的特征信息收到损失.当GRU为300时,隐藏层大小又过大了一些,导致引入了一些无关信息.从实验可以验证GRU为200时效果最佳.
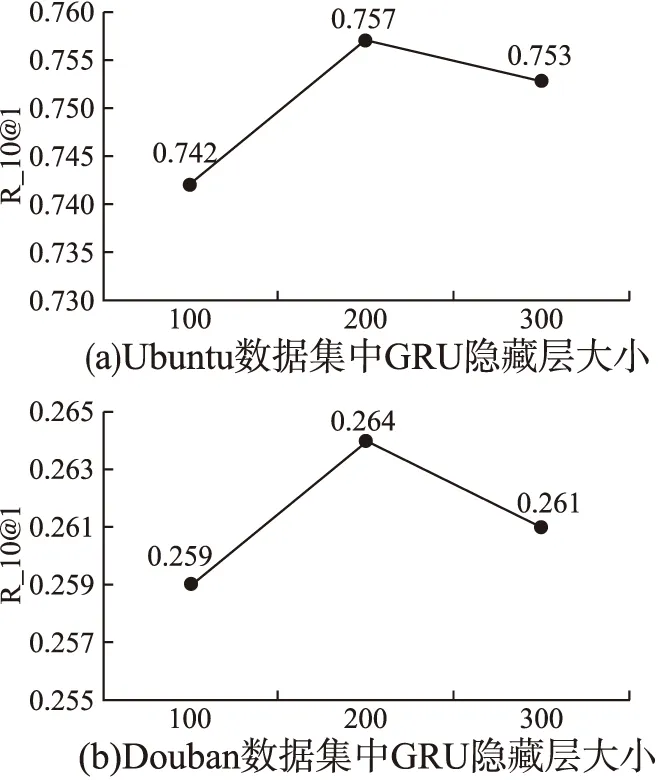
图2 GRU隐藏层大小对MRNA的影响Fig.2 Effect of GRU hidden layer size on MRNA
在MRNA模型中,使用AHRE对对话上下文和回答进行编码,从而提取对话上下和回答中丰富的时序信息.AHRE模块的层数是影响MRNA模型效果的重要超参.实验结果如图3所示,在两个数据集上,当AHRE模块的层数为3时,提取层级序列信息的效果最好,层数如果持续增加,可能会出现过拟合现象反而使模型效果下降.
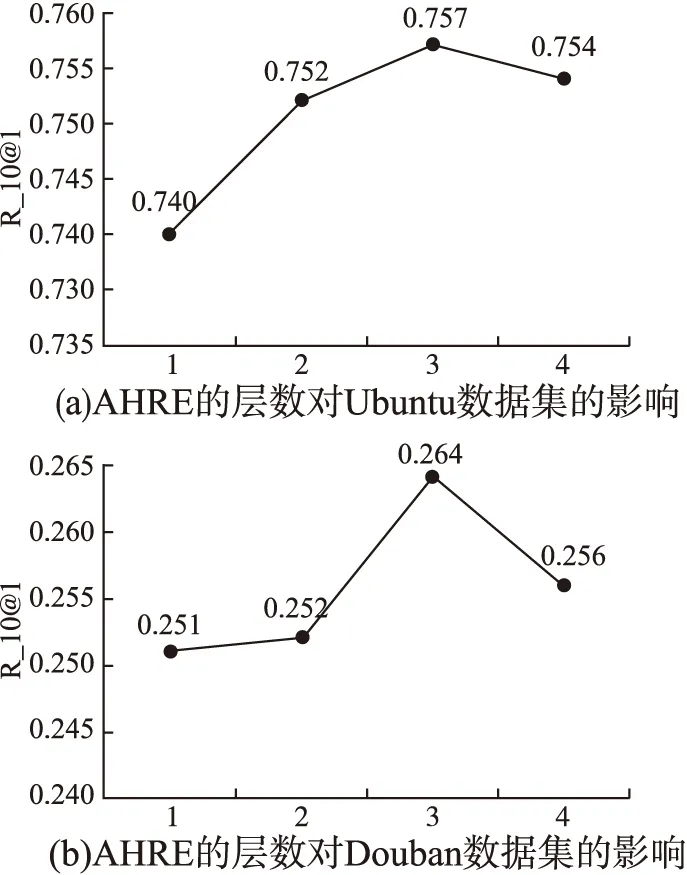
图3 AHRE层数对MRNA的影响Fig.3 Effect of AHRE layers on MRNA
4.7 案例可视化分析
本节通过可视化的方式研究展示词注意力机制给语句中每个词语所分配的注意力权重大小.MRNA的词注意力模块输出的注意力权重分布根据每个单词所赋予的注意力权重大小,显示单词的颜色.颜色越深,所赋予的权重越高.
本文在Douban数据集中选择了一个案例进行注意力权重可视化.例子如下{u1:什么星座是一个人在战斗;u2:我一个人在战斗白羊;u3:我也是一个人奋斗的白羊;R:请睡感谢在这个冷清的夜陪伴我的你祝明天考好;}.图4显示了Douban例子中u2和R的注意力权重分配.在u2中“战斗”和“白羊”这两个词是这一句话的关键词.因为在u1中正在询问的主体是“什么星座”,并且后面跟随的动词也正好是“战斗”.在图4中,我们可以很明显的看出u2中“战斗”和“白羊”这两个词颜色较深,说明分配了比较多的注意权重,“白羊”可以作为“什么星座”的回答,而u1和u2都出现了战斗,上下呼应.在R当中注意力权重主要集中在“冷清”、“陪伴”、“考”这几个词上面.“陪伴”和“考”是动词代表了这句话主要的动作,而“冷清”形容了当时的环境,这3个在句子中占有突出的意义.在图4中还可以看出分配给“我”、“你”、“的”这样的代词和助词比较少的注意力权重,说明注意力机制可以减少无关词在整个句子中的作用,从而证明注意力机制的有效性.

图4 u2和R的注意力分布Fig.4 Attention distribution of u2 and R
5 总 结
本文中提出了一个结合词注意力机制和多粒度的深度学习模型来解决多轮对话问题.MRNA融合词向量和字符级向量,从而获得更加准确的表征向量.为了更好的提取句子中的重要信息,MRNA提出了一种词注意机制来更有效地提取对话上下文和回答匹配的关键词信息.在句子信息的提取上,MRNA使用了分割句子的思想,扩展了句子级别的粒度,从而进一步增强了句子的语义信息.在两个公共数据集上进行实验,实验表明MRNA模型可以产生最优秀的效果.在未来的工作中,我们将会研究如何改善对于对话上下文的语义建模,如何更有效提取对话上下文中的时序信息.并且针对不同的对话主题和对话场景,从对话上下文中抽象出能代表对话主题的核心信息.
