一种基于多重信息的不完全数据的模糊C均值聚类算法
2021-12-08朱峥瑜
朱峥瑜,宋 燕
(上海理工大学 光电信息与计算机工程学院,上海 200093) E-mail:sonya@usst.edu.cn
1 引 言
随着数据信息时代的来临,数据种类和数量不断增加,使得数据挖掘技术成为研究者们的热门话题.聚类是一种比较流行的数据处理方法,广泛应用于模式识别、机器学习、计算机视觉、图像处理等领域[1,2].聚类根据目标函数将一组样本进行同构划分,从而提高同一簇内的相似性,降低不同簇间的相似性[3].根据此种划分原理可定量地确定样本的相似性关系,从而获得研究对象合理划分.
在众多的聚类算法中,K均值算法[4]由于其简单、易于理解,是应用最广泛的聚类算法之一.在K均值算法中,每个样本属于某一确定的簇,并通过“簇内距离平方和最小化”准则来实现对样本的划分.K均值算法对数据的归属是一种硬性的划分(即:反映样本隶属于某个簇的程度的值只能取0或1)[5].然而,现实中的数据往往具有簇的不确定性,因而导致簇之间存在模糊边界.基于此,在聚类分析中引入模糊划分的概念十分必要.Bezdek[6]提出的模糊C均值(FCM,Fuzzy C Means)算法是一种典型的模糊聚类算法.FCM算法中隶属度可以取0~1之间的任何数,并且通过“簇内距离平方和最小化”准则来实现对隶属度的模糊化.
尽管FCM算法的提出解决了不确定性数据集的聚类问题,但其本身还具有一些固有的缺点[7],比如模糊指标m的选择,对噪声数据和初始聚类中心敏感,迭代容易陷入局部极值点等[8].迄今为止,有很多学者对传统FCM算法的改进研究做出了巨大贡献,例如文献[9]中用闵可夫斯基距离代替欧式距离,使聚类算法能适用于复杂几何形状的数据;文献[10]提出结合硬划分和软划分的半模糊C均值算法,提高聚类的紧致性;文献[11]利用稀疏表示方法得到样本与样本间的相似性,并将此作为判别特征加入目标函数,有效提高了聚类精度;文献[12]利用粒子群算法(PSO,Particle Swarm Optimization)的全局搜索能力,解决FCM算法对初始值敏感,以及容易陷入局部极值的缺点;文献[13-15]针对每一特征的不同重要性,提出了特征加权的FCM算法;文献[7]引入模糊熵作为FCM算法的约束条件,从而提高了聚类的准确性和抗噪性;在图像分割领域的研究中,文献[16]融合空间信息引入的模糊聚类,提高了图像分割精度.
在对FCM算法改进的过程中,考虑信息特征是非常重要的.因为不同的特征表示不同的意义.特征加权方案是一种增强重要特征而减少琐碎特征影响的有效方法.由于其有显著作用,在机器学习是许多学者的研究重点,例如文献[17]自动计算个体特征的权重,同时减少不相关的特征成分;文献[18]提出基于信息熵特征加权核函数的SVM分类方法,以避免核函数设计的盲目性;文献[19]提出基于全局冗余最小化(AGRM)的特征选择框架,从全局的角度可以大大减少特征之间的冗余;文献[20]在基于图的半监督学习中引入特征选择和自动加权,提取出有效的、鲁棒的特征;文献[21]在图像分类中提出基于特征融合和加权的少样本学习多尺度决策网络,计算支持集和查询集特征之间的余弦相似度作为权重,引入了关注机制,使关系网络更加关注同一类图像.
此外,传统的FCM算法通常需要满足信息完全的假设前提.但是,由于数据采集环境的复杂多变和仪器测量能力的限制等因素,很难获取研究对象的全部信息.据研究发现,机器学习领域的基准数据库—UCI数据集中,有高达40%的数据集包含缺失信息[22].在面对这样的数据集时,目前的大多聚类算法是无效的.因此,研究不完全数据集的聚类分析方法是非常必要的.
对于不完全数据的聚类分析,通常可以分为两步:先对缺失值进行填补[23];然后再对填补后的完整数据集进行聚类.需要说明的是,这样分两步的实施策略往往比较耗时.针对这一问题,文献[24]提出了4种改进的FCM策略:完全数据策略(WDS,Whole Data Strategy),部分距离策略(PDS,Partial Distance Strategy),最优完成策略(OCS,Optimal Completion Strategy)和最近原型策略(NPS,Nearest Prototype Strategy),这4种策略能有效避免增加额外的计算负担.具体来说,WDS是在缺失量占比很小的时候直接删除缺少属性值的样本,依此策略提出了WDSFCM算法;PDS定义了一种距离函数,通过所使用的部分信息的占比的倒数将仅依赖于已知属性的结果缩放到与完整目标数据集相同的范围,依此策略提出了PDSFCM算法;OCS把缺失的元素视为附加变量,通过对其进行迭代优化,找到目标函数的最优解,依此策略提出了OCSFCM算法;在OCS的基础上,NPS直接用最接近缺失元素的集群原型替换缺失值,依此策略提出了NPSFCM算法.
尽管FCM算法在完全数据聚类的研究中已有相当的研究成果,但不完全数据的FCM聚类分析尚处于起步阶段,更不要说能综合解决不完全数据的FCM算法中如对初始值敏感性、易于陷入局部极值、未充分考虑簇间与簇内的样本差异等问题,这也是我们研究的主要动机.本文研究不完全数据集的聚类问题,综合考虑不同特征权重、簇内间距的最小化和簇间距离的最大化以及避免对初始值的敏感和局部极值问题,提出一种基于多重信息的不完全数据的FCM聚类算法.该算法的主要优点在于:
1)由于不同特征信息常常表示不同的物理意义,本文使用局部赋权方法充分考虑各个特征的重要性,以获得更好的性能表现;
2)在聚类分析的代价函数中不仅考虑了传统FCM算法中“簇内距离平方和最小化”,还合理增加了“簇间距离平方和最大化”;
3)此外,本文采用粒子群优化算法(PSO)搜索全局最优值,有效地克服FCM算法对初始值敏感、易于陷入局部最小值的缺点.
最后,通过对比实验证明了本文提出的聚类算法不仅能处理不完全数据的聚类问题,还能有效地提高模糊聚类效果.
2 FCM算法、PDS策略及PSO算法
2.1 FCM算法
FCM算法是通过最小化如下所示目标函数,将一个由有限的数据组成的集合X={x1,…,xN}划分为C个模糊聚类[6]:
(1)
其中,xi∈表示原始数据集X的第i列;N和C表示样本数和聚类个数;pj表示第j个聚类中心;U≜{uij},i=1,…,N,j=1,…,C是一个隶属度矩阵;m是模糊因子,通常取m≥1.
通过运用拉格朗日乘子法,可以得出隶属度和聚类中心的迭代公式如下:
(2)
(3)
FCM算法执行流程:
1)设定最大迭代步数Steps,模糊指数m,终止阈值ε;
2)初始化隶属度矩阵U=[uij],聚类中心P=[pj];
3)利用式(2)计算隶属度U=[uij];
4)利用式(3)计算新的聚类中心P=[pj];
5)若‖U(r+1)-U(r)‖<ε或迭代次数iter>Steps,结束算法,否则返回步骤3).
2.2 部分距离策略(PDS)及PDSFCM算法
参照文献[24],PDS相关概念描述如下.
首先通过示例说明PDS的计算形式:
(4)
由式(4)可推出,部分距离公式的一般形式:
(5)
其中,XM表示所有缺失元素的集合,XP表示所有已知元素的集合;S表示数据集维数;xis和pjs分别表示第i个样本的第s维特征和第j个聚类中心的第s维特征.
PDSFCM算法是FCM算法的PDS版本,经过对传统FCM算法进行修改可以得到:
1)根据式(5)完成不完全数据在式(2)中的计算,得到的uij更新公式为:
(6)
2)将式(3)的pj替换为:
(7)
由于算法使用交替优化,所以有模糊聚类的标准收敛性[25].
2.3 粒子群优化算法(PSO)
粒子的位置代表优化问题在搜索空间中的潜在解,粒子的飞行的方向和距离由它们的速度决定,所有粒子都有一个被适应度函数f决定的适应值[26,27].假设在一个S维的目标搜索空间中,有N个粒子组成一个群落.第i个粒子的位置表示为矢量(xi1,xi2,…,xiS),飞行速度表示为(vi1,vi2,…,viS).每个粒子通过跟踪两个“最好的位置”来更新自己,一个是粒子本身目前所找到的最好位置(pbest),另一个是目前整个群体中所有粒子发现的最好位置(gbest),gbest是在pbest中的最好值.对于第k次迭代,每个粒子按下式进行更新:
(8)
(9)
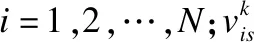
3 基于多重信息的不完全数据的FCM聚类算法
文献[24]通过PDS直接利用FCM算法对不完全数据集进行聚类分析.其中采用的还是传统的FCM算法聚类准则,并没有进行改进,无法避免FCM算法本身缺点对聚类结果造成的影响.而本文引言部分中提及的改进文献都只能针对完全的数据集,并且也不能同时解决对初始聚类中心敏感、易于陷入局部最优、簇间距离及特征权重的问题.因此,开发一种新的聚类准则来同时解决上述缺点是非常重要的.根据上述缺陷和已有相关工作,本文提出一种基于多重信息的不完全数据的FCM聚类算法,使得提出的算法能够解决缺失数据聚类问题的同时克服传统FCM算法的易于陷入局部极值、对初始聚类中心敏感及未充分考虑类间距离因素以及数据集信息的缺点,有效提高聚类的性能表现.
3.1 改进的算法推导
基于上述考虑,本文将局部特征动态加权、PSO、簇间距离引入FCM算法,提出了用于不完全数据集的改进算法.详细的目标函数如下:
(10)
其中xis和pis表示第i个样本的第s维特征以及第j个聚类中心的第s维特征;ωjs表示第j类的第s维特征的权重,β≥0是一个平衡权重影响的参数.
隶属度uij和权重ωjs被定义为:
(11)
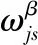
聚类分析的准则是寻找最优的隶属度矩阵和聚类中心使得目标函数Jm2在约束条件下达到极小值.通过本文设计的目标函数,可以在数据不完全情况下,对数据集进行聚类分析,并且能够动态地根据特征重要性赋予不同的权重,以及在考虑“簇内距离”的同时考虑“簇间距离”(即:当目标函数Jm2达到最小时,“簇间距离”就达到最大,而“簇内距离”就达到最小).
为了求解带约束条件式(11)的最小化问题式(10),利用拉格朗日乘子法可构造如下目标函数:
(12)
在给定KKT条件下,uij、wjs、pjs更新规则如下:
(13)
(14)
(15)
基于以上讨论,本文提出了一种基于多重信息的不完全数据FCM聚类算法.与现有的PDSFCM算法相比,通过隶属度公式(6)与公式(13),以及聚类中心公式(7)与公式(15)的对比可以发现,本文提出的算法有以下显著优势:1)在求某个样本属于某个类的隶属度的时候,考虑了在此类别中每一特征的不同权重;2)在求隶属度时,不仅考虑“簇内距离”,还额外考虑“簇间距离”最大化.所以通过以上改进,本文的改进算法增加考虑多方面信息比PDSFCM算法更合理和全面,能有效克服原算法不足.
基于以上的改进并不能帮助算法解决对初始值敏感和易于陷入局部极值的不足,所以基于上述改进的算法,本文再利用具有强大全局搜索能力的PSO算法与之结合,来解决对初始值敏感和易于陷入局部极值的问题.
在PSO算法中,将本文提出的基于多重信息的不完全数据FCM聚类算法的聚类准则函数式(10)作为适应度函数:
(16)
粒子通过改变每一维不同的取值即簇中心的取值从而产生多种聚类结果,直到找到可接受的簇中心即适应度函数达到终止条件或整个循环达到最大循环次数.
3.2 改进算法的算法流程
基于多重信息的不完全数据FCM聚类算法的基本流程如下:
输入:聚类个数C,数据集样本数N,学习因子c1、c2,惯性权重δ,最大迭代次数T,模糊因子m
输出:每个样本的类别标签
1.初始化N个聚类中心P,形成初代粒子.每个粒子的pbest为其当前位置,gbest为当前种群中所有粒子中的最好位置;
2.使用式(13)计算隶属度矩阵U;
3.使用式(14)计算特征W权重;
4.使用式(16)计算每个粒子的适应度值,如果优于该粒子当前的最好位置的适应度,则更新该粒子个体最好位置.如果所有粒子中的最好位置的适应度优于当前全局最好位置的适应度值,则更新全局最好位置;
5.使用式(8)和式(9)对每个粒子的速度和位置进行更新,产生下一代粒子群;
6.如果迭代次数达到设定的最大值,则输出全局最好位置的粒子,即簇中心的集合,并根据式(13)得出样本集的隶属度矩阵,从而得到聚类标签;如果没有达到最大迭代次数,则重复返回步骤2).
4 实验结果与分析
4.1 实验数据与评估指标
实验环境:操作系统为Ubuntu16.04,配置为2.10GZ,24Inter(R)Xeon(R),2块TITAN,在Python3平台开发.实验采用的数据集选自UCI数据库中的Iris、ParkinsonSpeech、Abalone、Blood、Wine、Ionosphere、Letter Recognition(A,B,C)、Balance-Scale、Vowel数据集,具体的信息,如表1所示.
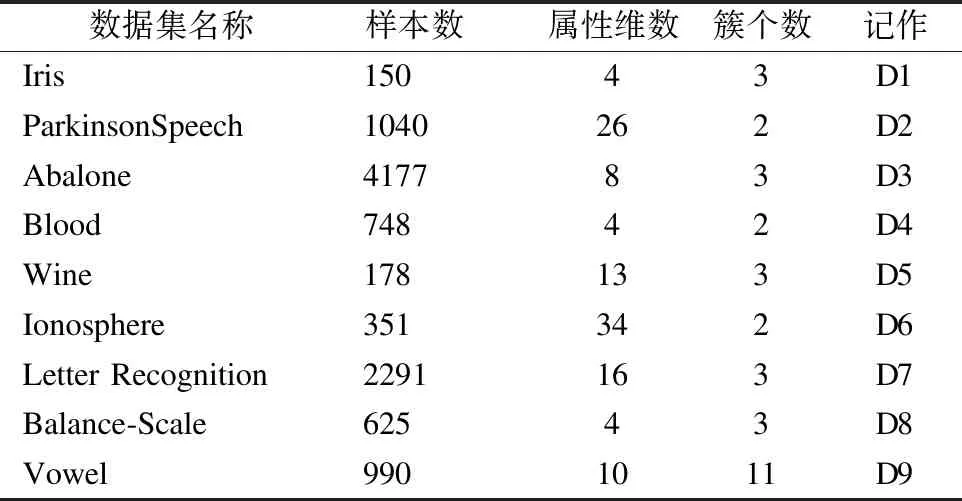
表1 实验数据集信息Table 1 Details of datasets
此外,在所有数据集上,我们使用5折交叉验证寻找最优超参数β.总体实验设计,1)数据集被随机分成5个互斥的子集,每个子集都包含数据集20%的数据;2)选择4个子集训练模型,其余子集进行验证;3)重复步骤2)5次根据不同超参数下模型的表现,选择最优超参数;4)根据选择的超参数运行10次算法,最后结果为取10次结果的均值±标准差形式.
在本文实验中,5种聚类算法的结果通过以下精度(ACC%±STD),记作M1和归一化互信息(NMI%±STD),记作M2来评估:
(17)
(18)
其中,N是样本数,C是聚类数目,ei是正确分配到第i个类的样本数;Y是一个混淆矩阵,Yij表示在A划分中属于簇i的样本个数,在B划分中属于簇j的样本个数;YA(YB)是在A(B)划分中的簇的样本数;Yi·(Y·j)表示矩阵Y中第i行(第j列)的元素个数.NMI越大,A和B划分的相似性就越大.显然,NMI属于[0,1],特别是当NMI为1时,意味着A和B是相同划分.
4.2 实验结果分析
为了测试本文提出算法的性能,采用表1所示的数据集,在数据集具有不同缺失率(缺失比例为:10%、30%、50%)的情况下,本文采用5种算法进行对比,算法1-算法5分别记作A1-A5.
A1:PDSFCM算法[24],应用传统FCM算法进行聚类;
A2:PDS+文献[15],应用文献[15]中的MWFCM,结合特征权值信息和簇间距离信息;
A3:PDS+文献[27],将PSO算法与传统的FCM算法相结合;
A4:PDS+文献[3],利用大密度区域以及样本的密度值变化方法,选取初始聚类中心以及候选初始聚类中心;
A5:本文提出的基于多重信息的不完全数据模糊C均值聚类算法.
因为大部分算法无法直接分析不完全数据,本文采用组合形式,将PDS应用于文献[3,15,27],使其能应用于不完全数据集从而进行性能比较.实验结果见表2-表4.此外,本文对聚类结果进行了显著性验证.原假设H0为聚类算法结果与原标签结果之间不存在显著性差异,在显著性水平α=0.05的情况下,p>0.05接受原假设,p≤0.05则拒绝原假设.实验结果见表5.
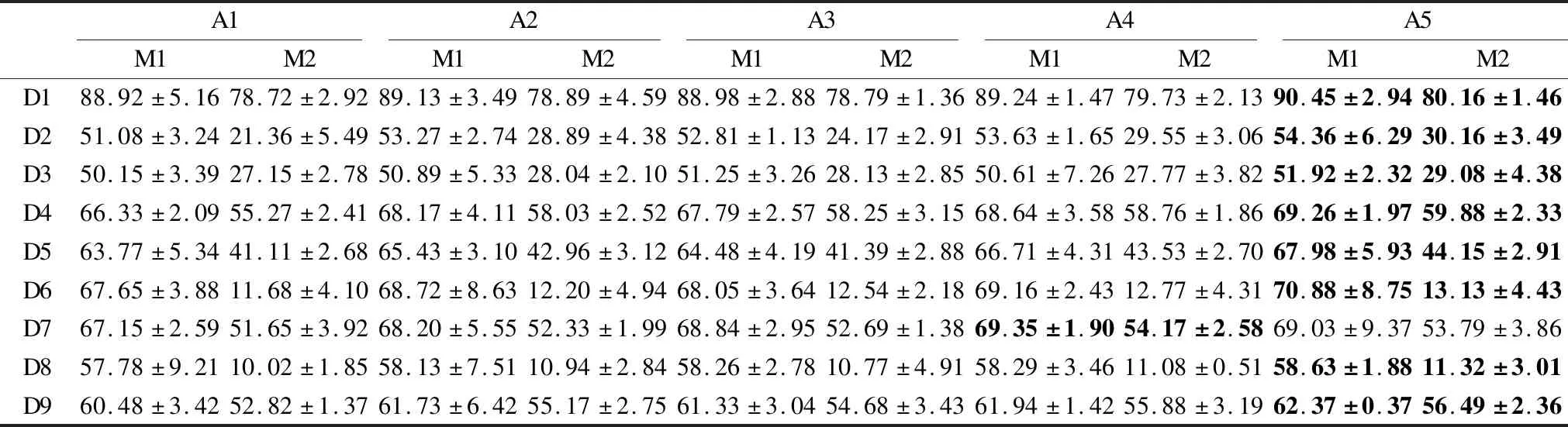
表2 聚类算法性能比较(缺失率10%)Table 2 Performance of different algorithms with 10% missing

表3 聚类算法性能比较(缺失率30%)Table 3 Performance of different algorithms with 30% missing
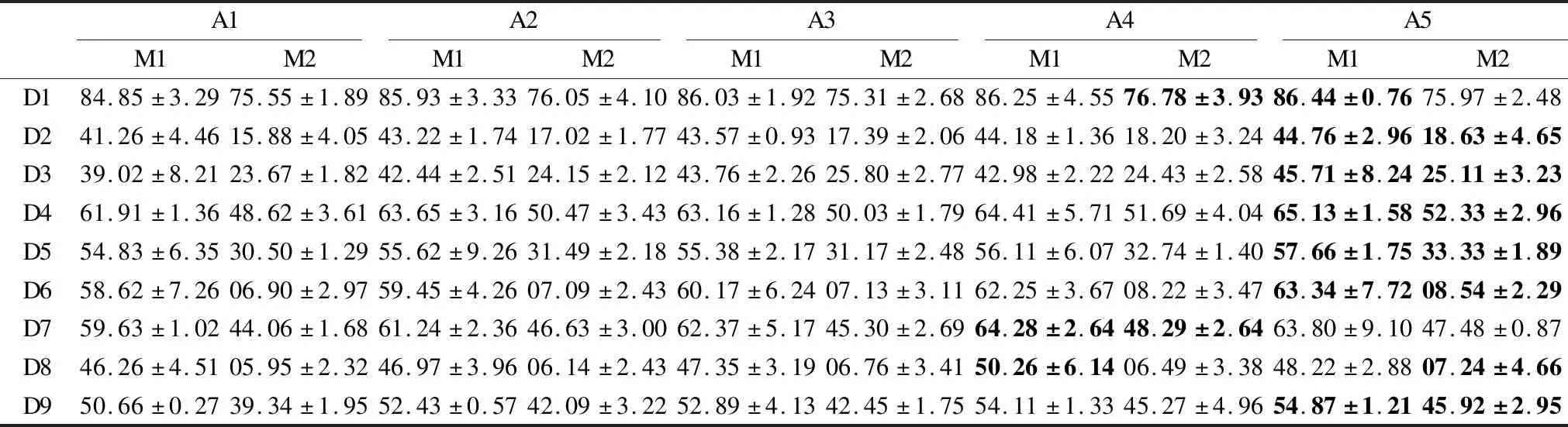
表4 聚类算法性能比较(缺失率50%)Table 4 Performance of different algorithms with 50% missing
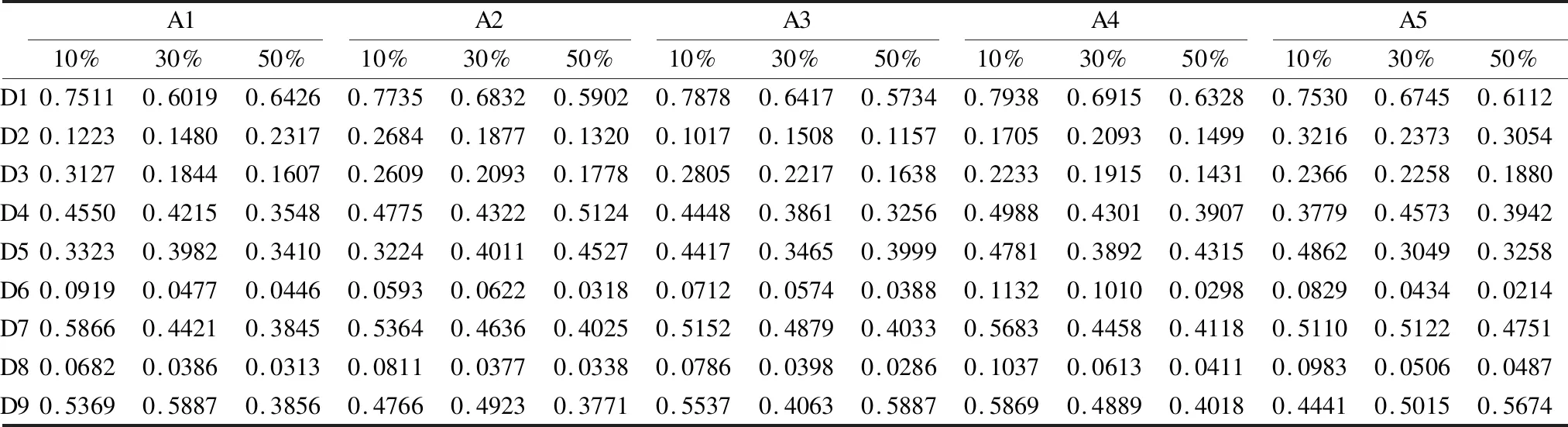
表5 不同缺失率下聚类算法显著性检验结果Table 5 Significance test results of clustering algorithmswith different missing rates
表2-表4实验结果,均是算法运行10次取平均值.此外,参数设置为m=2,c1=c2=2,β为在[-10,10]以2为步长,进行灵敏度测试的最佳值,具体见表7.

表7 不同数据集的参数设置 Table 7 Parameters settings of different datasets
从表2-表4可以看出,在相同缺失率的情况下,本文提出的基于多重信息的不完全数据FCM算法在绝大多数数据集上的聚类准确性最高,具有较好的NMI指标.并且通过对聚类结果的显著性检验,绝大多数都能接受原假设,除了数据集D6和D8.主要因为在算法迭代过程中,本文提出的算法不但考虑了特征权重,而且是动态地更新权重,而非固定权重.此外,本文提出的算法的目标函数值要小于对比算法,主要是因为引入了PSO算法,通过其全局寻优能力克服FCM算法易于陷入局部极值的缺点.因此,本文提出的改进算法聚类性能是优于文献[3]、文献[15]以及文献[27]的.
为了进一步比较3种算法在聚类结果在“簇间距离最大化”和“簇内距离最小化”上的表现,使用Xie-Beni(XB)指标[28]作为评价指标,具体公式如下:
(19)
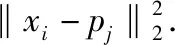
在图1(a)-图1(c)中,每个数据集的5个柱状从左至右分别是算法1-算法5的XB指标值.从图中可看出,在不同的缺失比率下,本文提出的算法在XB指标上的性能表现对比于其他算法几乎都有一定的提升.依据XB指标的结构来看,本文算法也充分体现了簇内距离需要最小化而对应的簇间距离需要最大化的聚类准则,所以能够有效地提升算法性能.
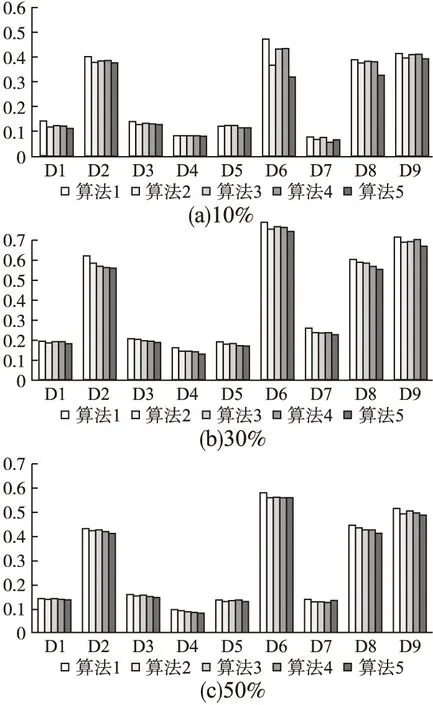
图1 不同缺失率下5种算法XB指标Fig.1 Values of XB indexes three algorithms with different missing ratio
4.3 计算复杂度
在这一节中将对上一节中的实验算法进行计算复杂度分析,假设迭代次数为t,每一个样本的特征维数为S,数据集样本数为N,聚类簇个数为C.由于实验算法为了能处理缺失值,都应用了PDS公式,所以不考虑此部分的计算复杂度.传统的FCM算法(A1)的时间复杂度为O(NC2St);文献[15](A2)的时间复杂度为O(C3S3Nt);文献[27](A3)的时间复杂度为L*O(NC2S)+O(NC2St),其中L为PSO算法的迭代次数;文献[3](A4)的时间复杂度由于t,N,C,S未知,所以为O(CSNt)或O(N2S);本文算法(A5)的时间复杂度为O(C3SNt).具体的平均时间耗时见表6.通过对每个算法的时间复杂度分析及平均耗时可以看出本文提出算法计算复杂度略高于部分算法,这是因为在其迭代过程中需要计算的信息量的增加,但是,在计算复杂度未爆炸式增长的情况下,本文提出算法的聚类质量是优于对比算法的.
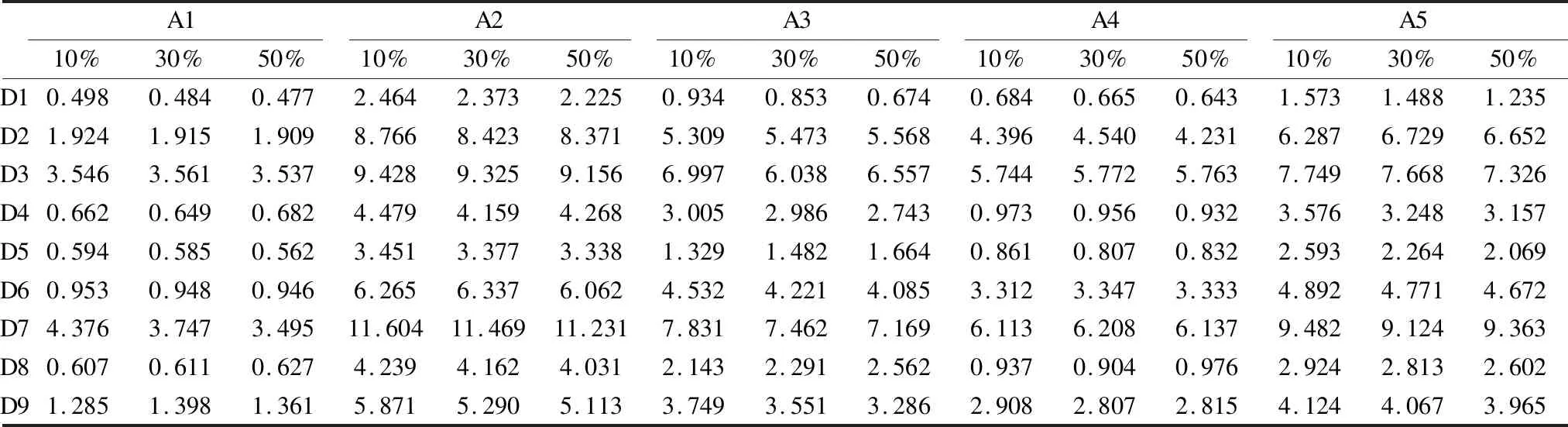
表6 不同缺失率下聚类算法平均时间(s)Table 6 Average time(s)of clustering algorithmswith different missing rates
5 结束语
针对已有的不完全数据集聚类,往往忽略了数据特征的不同重要性、簇间距离以及算法对初始值敏感和易于陷入局部极值,本文通过特征加权、簇间距离最大化和PSO算法,提出了针对于不完全数据集的模糊聚类新方法.该方法首先在FCM算法中引入局部特征动态加权、簇间距离,充分考虑不同特征重要性和簇间距离最大化因素,形成同时考虑上述因素的目标函数.然后把新的目标函数作为适应度函数结合PSO算法进行迭代更新.通过测试多个数据集不同缺失率的实验结果表明,本文提出的基于多重信息的不完全数据FCM算法具有较高的聚类准确性和较好的聚类效果.当然,本文还存在一定的缺陷,如计算复杂度略高等,这也将是我们未来工作的努力方向.
