条件GAN去模糊算法在人脸识别中的应用
2021-12-08曾凡智邱腾达
曾凡智,邹 磊,周 燕,邱腾达
(佛山科学技术学院 计算机系,广东 佛山528000) E-mail:coolhead@126.com
1 引 言
近年来,计算机成像领域已经取得了巨大的进步,但对于捕获的模糊内容的处理仍然是一个挑战.图像模糊[1]的一种起因是由传感器曝光期间,场景中的物体或照相机运动所造成.除了明显降低图像的视觉质量外,模糊造成的失真会导致诸多计算机视觉任务的性能大幅下降.商业上有一些可用的相机,它们可以以高帧频捕获帧,从而减少模糊现象,但是这会使图像拥有更多噪声.
由于图像模糊本身的不确定性,它依然是计算机视觉中一个具有挑战性的问题.目前运用相对广泛的图像去模糊方法主要有以下两类:盲去模糊和非盲去模糊.非盲去模糊是当模糊核[2]已知时,采取有针对性的反卷积操作获取清晰图像,因此模糊核估计的准确性就成了图像去模糊的关键.目前主流的模糊核估计方法大部分建立在概率先验模型之上.韩阳[3]提出两阶段图像恢复方法,首先利用图像的稀疏性,在多尺度情况下估计模糊核,再结合非盲反卷积获取清晰图像.黄英豪[4]提出一种基于经典L0梯度先验的人脸图像去模糊算法,通过随机森林模型进行人脸轮廓检测,然后利用人脸的结构化特征进行非盲去模糊.徐弦秋[5]等提出利用模糊核对各个通道彩色分量图造成的差异性,对图像的RGB通道分别进行模糊核估计,此方法取得了不错的去模糊效果.
随着人工智能的不断兴起,新兴的深度学习技术推动了图像修复任务的突破.在图像去模糊任务中,通过模型的先验知识,不提前进行模糊核估计的方法(即盲去模糊)越来越受到研究者的青睐.Nah[6]等通过使用多尺度残差网络,通过从粗糙到精细的方式聚合特征,直接对图像去模糊,避免了对模糊核进行估计;Ramakrishnan[7]等结合使用pix2pix框架和稠密连接网络DenseNet[8]执行图像无核盲去模糊;陈阳[9]等提出一种基于自编码深度神经网络的方法,对输入图像中的模糊区域进行准确标记,并对这些区域进行去模糊处理,这能在保证图像不发生失真的同时有效去除局部模糊;Kupyn[10]等针对运动模糊提出一种基于生成对抗网络的图像盲去模糊方法,将梯度惩罚和感知损失引入生成对抗神经网络,这不仅使图像保留了更多的纹理细节,运行效率也有大幅提高;Li[11]等采用数据驱动的先验鉴别并设计了基于半二次分裂法的图像盲去模糊算法;Shen[12]等人结合人脸的深度语义信息进行盲去模糊,通过合并全局语义先验输出,并且在多尺度神经网络中加入局部结构损失来正则化输出,获得了较好的人脸图像去模糊效果.
现有大部分基于深度神经网络的图像去模糊算法存在参数量众多,对人脸识别准确率提升不明显等问题.本文基于生成对抗网络[13]框架,提出一种条件GAN图像去模糊算法,致力于解决图像去模糊技术运用在人脸识别相关场景中准确率提升不明显等问题.
本文的主要贡献如下:
1)提出Group-SE模块,将分组卷积和注意力机制结合,在降低模型参数量的同时提高模型的性能;
2)改进了原SE模块,将全局深度卷积引入其中,代替全局平均池化层提取全局性的通道特征;
3)将全局性稠密连接引入DenseNet,强化了模型的特征重用能力;
4)提出了一种新的可用于人脸识别的去模糊算法.
2 生成对抗网络与条件生成对抗网络
生成对抗网络GAN作为一种新兴的深度学习模型,在图像超分辨率重构[14]等任务上取得了不错的成绩.它由一个生成器网络和一个判别器网络组成.判别器的训练目的是能够区分生成器的输出样本与来自真实数据的样本,生成器的训练目的是欺骗判别器.GAN的一个显著优势是可以不用计算复杂的马尔科夫链,只需要凭借反向传播算法就可以获得梯度[15].GAN的训练是两个角色之间“动态”博弈的过程,是以价值函数V(D,G)最小化最大值为目标的对抗过程,价值函数V(D,G)见式(1):

(1)
其中D,G分别代表判别器和生成器,x为真实数据,z为噪点数据,pdata(x)为真实数据分布,pz(z)为噪点分布,Ex~pdata(x)为真实数据x的数学期望,Ez~pz(z)为噪点数据z的数学期望,D(x)为x来自真实数据的概率,D(G(z))为噪点z经生成器产生的样本被判定为来自真实数据的概率.
在原始非条件的生成模型中,模型无法有效控制生成样本的类型,但是如果通过给模型增加额外信息(即加入约束条件),则可以引导模型生成的方向.条件生成对抗网络[15]的价值函数V(D,G)见式(2):
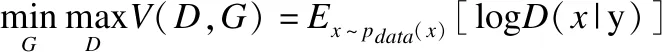
(2)
其中y为模型引入的额外信息,y可以是类别标签或者是来自其他模型的数据(本文中y为原始清晰图像),D(x|y)为x在y的条件下被判定来自真实数据的概率,G(z|y)为在y的条件下噪点z生成的样本.
3 整体算法结构
本文基于生成对抗网络框架进行图像去模糊算法设计,整体算法结构由生成器和判别器组成,其结构如图1所示.模糊图像从生成器网络输入层输入,首先经过一个7×7标准卷积层,并将输出用非线性激活函数和特征归一化(Activation and Normalization,AN)进行处理,以增强模型的非线性表达能力和加速模型收敛,再将结果依次送入32个Group-SE块中提取特征,其中Group-SE块包含1×1卷积层、3×3分组卷积层(Group Convolution,GConv)、非线性激活层、归一化层、SE块(Squeeze and Excitation,SE)、1×1卷积层及特征融合层(Add),SE块又由特征筛选层(Feature Selection,FS)和特征重标定层(Scale)组成,最后将结果送入反卷积层(ConvTranspose),用于将低分辨率图像上采样为高分辨率清晰图像;同时将生成器网络得到的模拟图像作为负样本送入判别器中,而正样本是原始清晰图像,本文使用的判别器是具有全局性稠密连接的改进DenseNet网络,网络通过Softmax分类器输出判别清晰图像的真假结果.

图1 本文算法整体结构图Fig.1 Overall structure of the algorithm in this paper
3.1 生成器网络
受到ResNeXt[16]和SENet[17]设计思想的启发,本文提出一种结合了分组卷积和注意力机制的模块,称为Group-SE模块.Group-SE模块主要由轻量级的分组卷积和具有注意力机制的SE模块组成,具体结构如图1生成器部分所示,目的是使生成器在大幅降低参数量和计算量的情况下仍然可以保持较好的性能.
3.1.1 分组卷积
分组卷积是ILSVRC(ImageNet Large Scale Visual Recognition Challenge)2016分类任务亚军模型ResNeXt中大力推广的一种新兴卷积方法,它主要先对输入的特征图进行分组,再对每组分别进行卷积操作,其运算方式如图2所示.它常用在轻量级的高效神经网络中,因为它可以用较少的运算量和参数量产生大量的特征图,而大量的特征图就意味着网络能够编码更多有用信息.

图2 标准卷积与分组卷积Fig.2 Standard convolution and group convolution
假设某一层的输入特征图尺寸为C·H·W(分别为输入特征图数量、特征图高和宽),输出特征图数量为N,卷积核边长为K,分成G组.
标准卷积:卷积核参数量为C·K·K·N;
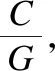
3.1.2 改进SE(Squeeze-and-Excitation)模块
SE模块是ImageNet 2017竞赛分类任务冠军模型SENet中所提出的一种方法,其组成如图3(a)所示.它首先对输入特征图使用全局平均池化层(Global Average Pooling,GAP)进行压缩(Squeeze)操作,得到通道级的全局特征,然后对全局特征进行激励(Excitation)操作,学习各个通道之间的关系.第1个全连接层(Fully Connected,FC)主要的目的是降维,这可以极大地减少参数量和计算量,并将输出用非线性激活函数和特征归一化(Activation and Normalization,AN)进行处理,以增强模型的非线性表达能力、加速模型收敛以及更好地拟合通道间复杂的相关性.第2层的全连接层属于扩张层,它的输出通道又回到了原来的输入的数量,为后面的权重归一化预先做准备.Sigmoid函数对上一步的通道进行最后的筛选,获得0~1之间归一化的权重,即越是重要的通道,它的权重就越大.最后的Scale为特征重标定,即将归一化后的权重加权到原先输入的每个通道的特征上,最终完成SE模块对图像特征的筛选工作.

图3 SE模块与GDC-SE模块Fig.3 SE module and GDC-SE module
全局平均池化层的使用会在一定程度上降低模型的表达能力[18],具体分析如图4所示,虽然中心点感受野RF2大小与边角点的感受野RF1大小相同,但是中心点的感受野包括了完整的图片,边角点的感受野却只有部分图片,因此特征图中每个点的权重应该不一样,但是全局平均池化层却把它们当做一样的权重去考虑,这使得网络的表达能力下降.
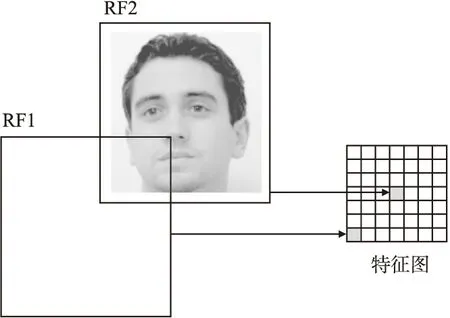
图4 特征图像素点的不同感受野分析Fig.4 Analysis of different receptive fields of feature map pixels
针对这一问题,可以使用全局深度卷积[18](Global Depthwise Convolution,GDC)代替全局平均池化层进行通道性特征提取.全局深度卷积对特征图的每个像素点赋予了不同的权重,使得图像不同位置的感受野具有不同的重要性,进一步增强模型的表达能力,全局深度卷积的计算公式如式(3)所示:
Gm=∑i,jKi,j,m·Fi,j,m
(3)
其中Gm为第m个通道输出特征,尺寸为1×1×M;K为深度卷积核,尺寸为W×H×M;F为第m个通道特征图,尺寸为W×H×M;i和j为像素的横纵坐标.W,H,M分别为特征图的宽,高,输入通道数,全局深度卷积的尺寸与输入特征图大小一样,输出通道数与输入通道数相同.
本文将全局深度卷积引入SE模块,代替全局平均池化层提取全局性通道特征,同时依据文献[19]对通道压缩的思考.本文去除了原SE模块的压缩层,减少通道信息在压缩层的损失.最后,本文将改进后的模块称为GDC-SE模块,具体结构如图3(b)所示.
本质上GDC-SE模块是一种带有注意机制的模块,这种注意机制可以让模型更加关注信息量大的通道特征,而抑制那些并不重要的通道特征,起到对特征重标定的作用.本文将GDC-SE模块加入到生成器网络中,推动网络快速地寻找到模糊图像存在的潜在有效特征,帮助生成器网络模拟出欺骗判别器网络的“真”样本.
3.2 判别器网络
判别器网络借鉴了2017 CVPR最佳论文所提出的DenseNet[8]模型,DenseNet通过稠密连接改善了网络中信息和梯度的流动问题,进而使网络易于训练;通过密集的特征重用方法,使DenseNet可以在计算量和参数量更少的情形下实现比前辈ResNet[20]更优的性能.本文为进一步增强DenseNet特征重用的能力,在原DenseNet网络结构的基础上引入全局性稠密连接,将特征重用的对象由DenseBlock内部扩展到DenseBlock之间,具体如图5所示.

图5 具有全局稠密连接的网络组成结构Fig.5 Network composition structure with globally dense connections
针对不同DenseBlock的特征图之间因为尺度不一致而无法拼接(Concatenate)问题,本文分别采用2×2池化和4×4池化的下采样方案,对于相同尺度的特征图则采用恒等映射方案.最后,配合全局深度卷积(GDC)输出全局性的通道特征,完成判别器部分的深度特征提取.
4 损失函数
本文将内容损失(Content loss)与对抗损失(Adversarial loss)的总和作为训练整个生成对抗网络的总体损失,具体表达式如式(4)所示:
Ltotal=Lcont+λLadv
(4)
其中Ltotal为总体损失,Lcont为内容损失,Ladv为对抗损失,λ为权重系数,本文λ=1×10-4.
4.1 内容误差损失
本文采用带有L2正则项的像素均方误差(Mean Square Error,MSE)作为本部分的损失函数,具体表达式如式(5)所示:
(5)
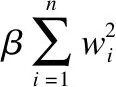
4.1.1 均方误差损失(Mean Square Error,MSE)
在算法中采用MSE作为内容损失的一部分,用于计算由生成器模拟的图像与目标图像对应像素间的欧几里得距离.通过使用MSE训练得到的模型,其模拟的图像在细节上更加接近真实图像[11].目前,MSE被广泛运用在图像去模糊、超分辨率图像重构等模型的训练中.MSE具体表达式如式(6)所示:
(6)

4.1.2 L2正则化

min(Loss(Data|Model))
(7)
转变为以最小化损失和复杂度为目标:
min(Loss(Data|Model)+Complexity(Model))
(8)
其中min为最小化操作,Data为模型需拟合的数据,Model为需训练的模型,Loss(Data|Model)为损失项,用来衡量模型与数据的拟合度;Complexity(Model)为正则化项,用于衡量模型的复杂度.
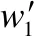
1)求Lcont(w1)的梯度:
(9)
2)参数w1更新:
(10)
(11)
(12)
由式(12)可知,每一次迭代,w1都要先乘以一个小于1的因子,从而使权重|w1|不断衰减使模型复杂度逐渐减小,降低了模型出现过拟合的风险.
4.2 对抗损失
基于生成对抗网络互相对抗的原理,本文将结合了轻量级分组卷积与改进SE注意力机制的Group-SE模块作为生成器的主体部件,将引入了全局性稠密连接的改进Den-seNet作为判别器核心,整个网络在无监督学习下通过约束对抗损失迫使生成器模拟出更加清晰、高质量的图像,具体对抗损失表达式如式(13)所示,在训练过程中,生成器G尝试去最小化对抗损失Ladv,而判别器D则竭尽所能最大化Ladv.
Ladv=EIs~psharp(s)[logD(Is)]+
EIb~pblur(b)[log(1-D(G(Ib)))]
(13)
其中EIs~psharp(s)为原清晰图像数据分布的数学期望,EIb~pblur(b)为模糊图像数据分布的数学期望,Is和Ib分别为清晰图像和模糊图像,D(Is)为Is被判定是清晰图像的概率,D(G(Ib))为模糊图像Ib经生成器模拟后的图像被判定是清晰图像的概率,G(Ib)为经过清晰图像y(见公式(2))引导得到的模拟图像.
5 实验与结果分析
本文使用CASIA WebFace人脸数据集对本文算法进行实验验证,CASIA WebFace人脸数据集是由中国科学院发布的一个大规模人脸数据集,目前广泛运用于人脸识别和身份验证等任务.本文将CASIA WebFace以7:3的拆分比,拆分成训练集和验证集,验证集不参与训练.同时,本文额外加入LFW(Labeled Faces in the Wild)人脸数据集,以进一步验证本文算法在人脸识别上的性能.LFW数据集由马萨诸塞大学建立,用于评测非约束条件下的人脸识别算法性能,是人脸识别领域使用最广泛的评测集合.
由于CASIA WebFace和LFW全为高清图像,本文通过DeBlurGAN[10]提供的方法将数据集全部转化为具有不同模糊程度的人脸图像用于本文实验,部分图像如图6所示.

图6 CASIA WebFace部分原图与模糊化后的图像Fig.6 Part of the original and blurred images of CASIA WebFace
5.1 参数设置
本文实验均在Window8.1操作系统上进行,使用Anaconda下基于Python语言的PyCharm解释器,深度学习框架为MXNet,计算机CPU为AMD Ryzen7 2700X,GPU使用的是NVIDIA RTX 2080.本文网络总共训练600个周期,学习率为0.001,采用带有动量的SGD算法优化器.
5.2 测试与对比
为验证本文提出的算法在图像去模糊上的性能,实验通过CASIA WebFace验证集和LFW进行测试,采用结构相似性(Structural SIMilarity,SSIM)和峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)作为图像质量客观评估主要指标,SSIM和PSNR数值越高,表明去模糊后的图像质量越好.
本文测试主要包含以下4部分:
1)测试对比Group-SE模块中,使用全局平局池化层和全局深度卷积之间,在图像去模糊效果上的差异;
2)测试对比生成器网络中使用Group-SE模块与仅使用分组卷积、经典ResNet残差块、新兴DenseNet稠密连接块之间的性能差异,测试对比判别器部分使用原DenseNet网络与引入了全局性稠密连接的改进DenseNet网络的性能差异;
3)测试对比本文算法与DeepDeblur[6]、DeblurGAN[10]流行算法在去模糊后图像质量、参数数量和测试时间上的差异;
4)测试对比在开源人脸识别算法SphereFace[21]、CosFace[22]和ArcFace[23]的基础上各自分别加入基于DeblurGAN、DeepDeblur和本文算法的预处理模块后,在人脸识别准确率上的差异.
5.2.1 对比实验1
本部分实验将对本文提出的GDC-SE模块与原始SE模块进行对比,对比实验在CASIA WebFace验证集上和LFW上进行.
由表1可知,在CASIA WebFace和LFW数据集上,使用GDC-SE模块的方法相比使用了原始SE模块的方法,在评价标准PSNR和 SSIM上都有小幅的分数提高,这主要是因为全局深度卷积为特征图上的每个像素点都赋予了不同的权重,使得不同的感受野具有不同的重要性,相比直接使用全局平均池化层的方法,使用具有全局深度卷积的注意力机制模块更能提升模型的表达能力.

表1 实验1对比结果Table 1 Experiment 1 comparison result
5.2.2 对比实验2
本部分实验将对本文所使用的Group-SE模块和引入了全局性稠密连接的改进DenseNet网络,与其他深度学习经典的模块和网络进行对比.为保证对比结果的准确性和公平性,当实验在生成器网络部分对比时,判别器网络部分均使用本文改进的DenseNet网络;当实验在判别器网络部分对比时,生成器网络部分均使用Group-SE模块.
本部分实验在CASIA WebFace测试集上进行,具体各部分对比情况如表2所示,使用了Group-SE模块和改进DenseNet网络的模型,与使用其他深度学习经典模块和网络的模型相比,去模糊后的图像在客观评估指标SSIM和PSNR上均有不同程度的提高,这说明本文提出的Group-SE模块和引入了全局性稠密连接的改进DenseNet网络作为模型关键部分,可以起到提高去模糊后图像质量的作用,这是因为分组卷积可以在保持原有性能的基础上,大幅减少了网络诸多冗余连接,使得信息可以更好地传递,并且GDC-SE模块对特征进行了精心筛选,使得模型有针对性地去挖掘对当前输出有益的特征,进一步增强了模型的表达能力.

表2 实验2对比结果Table 2 Experiment 2 comparison result
5.2.3 对比实验3
本部分实验对本文提出的算法与DeepDeblur、Deblur-GAN 在PSNR、SSIM、参数量和测试时间上进行对比.
由表3可知,本文算法在CASIA WebFace验证集和LFW数据集上,相比先进的开源图像去模糊模型DeepDeblur和DeblurGAN,在PSNR和SSIM上获得了更高的得分,说明由本文算法得到的清晰图像失真程度更低并且由本文算法模拟出的清晰图像,它在图像结构恢复上效果更加明显.在参数数量方面,本算法形成的模型参数量较DeblurGAN和DeepDeblur都有一定程度的减小,因为使用了本文提出的Group-SE模块,分组卷积可以在保持原有效果的基础上大大减少模型参数数量.而在对同一张图像测试时间方面,本文算法的速度要慢于DeepDeblur,原因是模型在对特征重标定过程中,增加了推理的计算量,使得耗时相对增加.
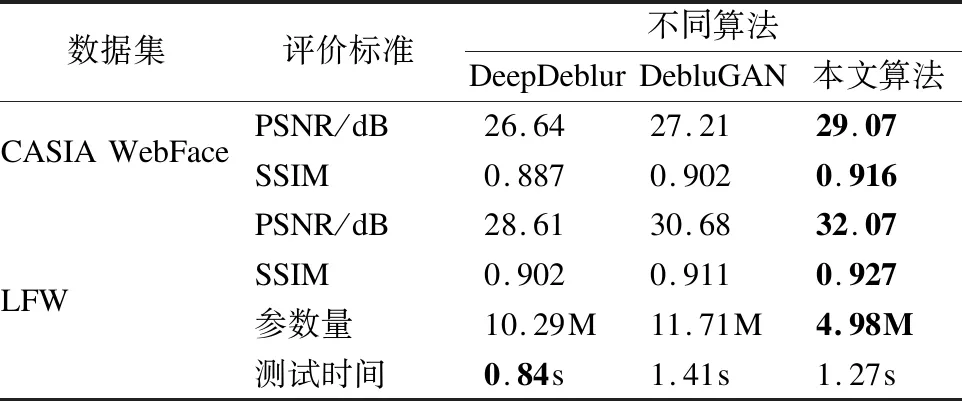
表3 实验3对比结果Table 3 Experiment 3 comparison result
5.2.4 对比实验4
为验证将本文算法作为图像预处理的人脸识别算法在识别准确率上的表现,本实验在开源人脸识别算法SphereFace、CosFace和ArcFace的基础上各自分别加入基于DeblurGAN、DeepDeblur和本文算法的预处理模块进行对比,本部分实验在LFW数据集上进行,具体对比如表4所示.
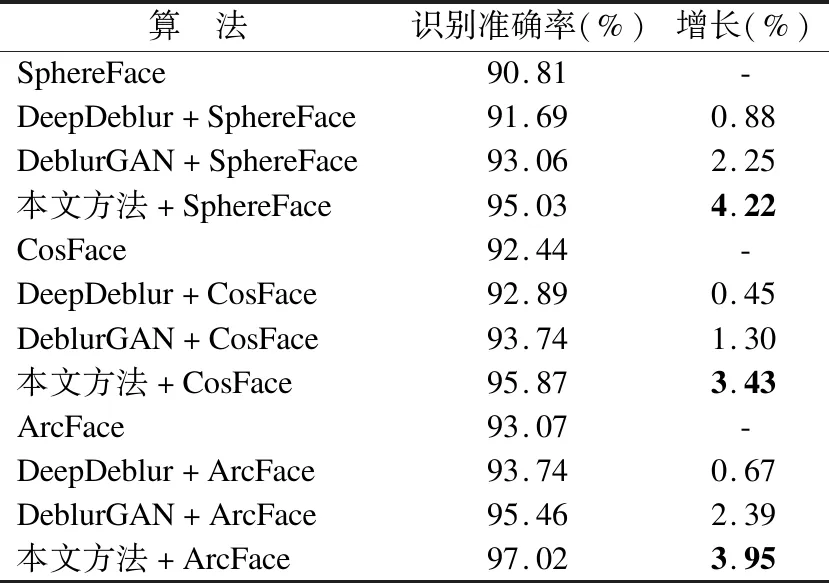
表4 实验4对比结果Table 4 Experiment 4 comparison result
由表4可知,将本文算法作为图像预处理的人脸识别算法比原生的SphereFace、CosFace 和ArcFace的识别准确率均有较大的提高,同时相比流行算法DeepDeblur和DebluGAN也有不同程度的提高.因为通过本文模型去除模糊后的人脸图像保留了更多人脸原有的细节特征,使得特征提取算法提取出更加精确完整的人脸特征,进而提高识别准确率.
6 结 论
本文提出一种基于条件生成对抗网络的图像去模糊算法.该算法将结合了轻量级分组卷积与改进SE注意力机制的Group-SE模块作为生成器的主体部件,将引入了全局性稠密连接的改进DenseNet作为判别器核心,以解决去模糊技术应用在人脸识别算法中的低效率等问题.在CASIA WebFace和LFW数据集上的实验结果表明,相较于现有几种流行算法,本文算法在PSNR和SSIM的得分上表现良好.同时将本文方法作为图像预处理步骤的人脸识别算法在识别率上有较大的提升.目前人脸识别技术已应用于众多行业,本文算法作为人脸识别中的一项预处理方法,对人脸识别的性能有一定的提升,因此本文算法具有广阔的市场价值.下一步工作,将考虑解决加入了图像去模糊模块后,人脸识别算法延迟严重等问题.
