基于视觉显著模型和局部线性嵌入的图像哈希算法
2021-12-07齐保峰王先传陈秀明刘争艳
凌 曼,齐保峰,王先传,陈秀明,刘争艳
(阜阳师范大学 计算机与信息工程学院,安徽 阜阳 236037)
0 引言
图像哈希算法是多媒体内容安全领域研究的一项热门课题,现如今已经应用到了很多方面,比如图像篡改检测、图像拷贝检测、数字水印、图像取证等[1]。它可以将任意一幅图像映射成一串短小的字符序列或者数字。在实际的应用过程中,可以用哈希序列去表示图像信息,从而实现高效处理。图像哈希的一个重要特性是对于视觉内容相似的图像,哈希函数生成的哈希值相同或相似,又叫做鲁棒性。而对于视觉内容不同的图像,哈希函数生成的哈希值将完全不同,这一特性又叫做唯一性。
近年来,研究人员也提出了许多图像哈希的算法。例如,Tang 等人[2]提出了利用颜色向量角(Color Vector Angle,CVA)和局部线性嵌入(Local Linear Embedding,LLE)来提取图像哈希,该算法对大角度旋转稳健性仍然有待提高;Qin 等人[3]提出使用混合特征来提取图像哈希,该算法具有较好的稳健性,但是唯一性有待提高;Huang 等人[4]设计了一种新的基于随机游走的图像哈希算法,在针对云端存储的医学密文图像安全检索问题上,该算法的运算速度很快,但唯一性提升的空间;张等人[5]提出了利用离散小波变换(Discrete Wavelet Transform,DWT)的感知哈希检索算法;Tang 等人[6]利用随机Gabor 滤波器和DWT 提取图像特征的鲁棒哈希算法,该算法的分类性能和运算速度均优于常见的基于DWT 的哈希算法;Ghouti[7]设计了一种基于四元数奇异值分解(Quatemion-Singular Value Decomposition,Q-SVD)的彩色图像哈希算法,该算法对旋转的稳健性有待提高;Shen 和Zhao 等[8]提出了一种基于局部特征和全局特征的图像哈希算法;Hamid 等人[9]设计了一种拉普拉斯金字塔R 的鲁棒图像哈希算法,该算法的分类性能较好;Tang 等人[10]还提出了一种具有低秩表示(Low-Rank Representation,LRR)和环分区的新颖图像哈希算法,该算法对大角度旋转具有较好的稳健性。
本文提出了一种基于Itti 视觉显著模型和局部线性嵌入(LLE)的图像哈希算法。首先利用Itti模型在图像空域上进行计算,可以识别图像的显著区域,并提取该图像的视觉显著图。然后用提取的视觉显著图构造二次图像,接着对二次图像使用LLE 算法,LLE 算法可以紧凑的表示数据之间的关系,最后对降维后的数据,求取方差作为哈希值。用L2 范数来作为哈希相似度的衡量标准。利用公开的数据集去验证该算法的性能,实验表明该算法可以抵抗常见的数据操作,并且具有较好的唯一性,分类性能也优于某些文献算法。
1 相关工作
1.1 Itti 视觉显著模型
Itti 视觉显著模型[11,12]是一种用于检测图像视觉显著区域的计算模型,是根据灵长类动物的视觉神经系统所设计的视觉注意模型。该模型是用高斯采样方法构建图像的亮度金字塔、颜色金字塔和方向金字塔,然后用中央-周边差算子分解这三类金字塔,得到亮度、颜色和方向的特征图,最后通过多尺度融合归一化技术可获得亮度、颜色和方向的显著图,再将这些显著图相加得到最终的视觉显著图。下面将详细介绍Itti 视觉显著模型的关键步骤。
1.2 高斯金字塔分解
高斯金字塔分解的第一步是对图像进行高斯低通滤波处理,然后再隔行隔列进行采样操作。高斯金字塔分解图像具体公式如下。

其中,σ∈{0,1,…,8}表示金字塔的层数(尺度)。
1.3 亮度显著图
Itti 视觉显著模型中,图像亮度主要通过计算图像的红、绿和蓝这三个分量的平均值得到的,具体公式如下:

其中,R、G 和B 代表了红、绿、蓝三种颜色分量,亮度显著图可以通过中央-周边差(C-S)运算得到。该运算公式如下:
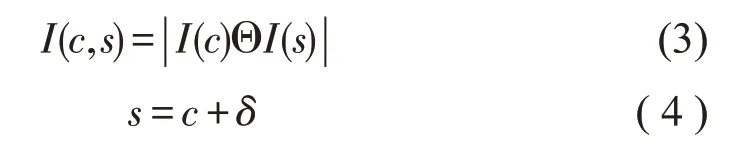
其中,I(c)和I(s)分别代表细尺度图像和粗尺度图像,Θ 代表中央-周边差运算,表示将两个图像调节至相同尺寸后,对其做矩阵减法操作,s 表示周边,c∈{2,3,4}表示中央部分,δ∈{3,4}。通过上述计算可产生6 幅亮度特征图,融合这6 幅亮度特征图,形成亮度显著图,具体公式如下:
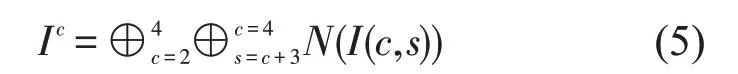
其中,Ic是方向显著图,⊕是将多个图像调整到同一尺寸后相加的操作,N()则是一种标准化操作,具体在文献[11,12]中有详细讨论。
1.4 颜色显著图
Itti 模型中,颜色显著图是将不同尺度差下的颜色特征图进行融合得到的。因此需要计算出原图像的颜色信息,公式如下:
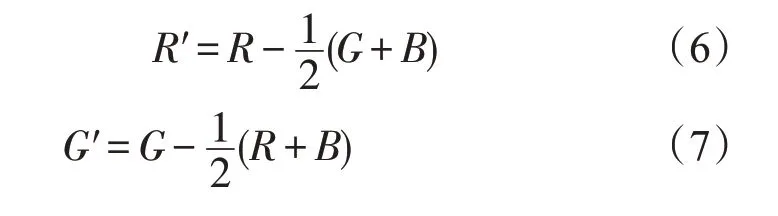
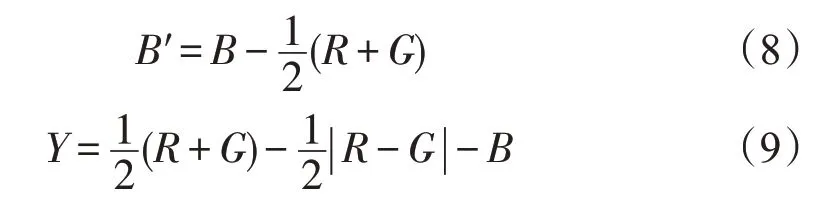
其中,R、G 和B 分别代表红、绿、蓝三种颜色分量,R'、G'、B'、Y 分别代表红、绿、蓝、黄的颜色高斯金字塔。接着在上式基础上,分别计算出不同尺度差下的红-绿颜色显著图和蓝-黄颜色显著图,具体公式如下:
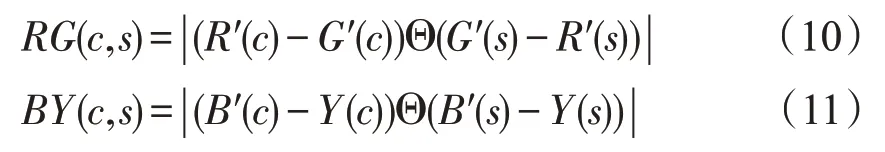
其中,s=c+δ,c∈{2,3,4},δ∈{3,4}。R'(s) 和R'(c)分别是红色分量的周边尺度和中央的特征图,G'(s)和G'(c)分别是绿色分量的周边尺度和中央的特征图,B'(s)和B'(c)分别是蓝色分量的周边尺度和中央的特征图,RG(c,s)是红-绿颜色特征图,蓝-黄颜色特征图。
通过上述计算可得到12 幅颜色特征图,融合12 幅特征图,形成颜色显著图,公式如下:

其中,Cc是颜色显著图。
1.5 方向显著图
在Itti 模型中,利用不同方向的Gabor 金字塔来确定图像方向。由于Gabor 核具有方向性,选取00、450、900和1350四个方向的Gabor 核。对每个方向的Gabor 核,处理公式(2)中的图像I,可产生一个Gabor 金字塔,4 个方向就产生4 个Gabor金字塔。用O(σ,θ) 表示Gabor 金字塔的图像,σ∈{0,1,…,8},具体计算公式如下:
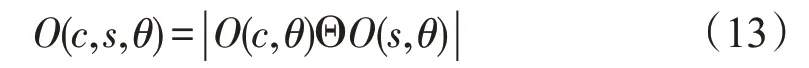
其中,θ表示方向,θ∈{0°,45°,90°,135°},c、s和θ为参数,其中s=c+δ,c∈{2,3,4},δ∈{3,4}。通过操作算子Θ 的作用,得到方向特征图。因为有4 个Gabor 金字塔,所以可以产生24 个方向特征图,对它们进行线性融合,可得到最终的方向显著图,公式如下:
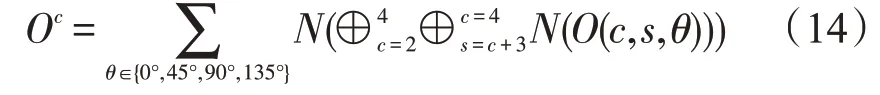
其中,Oc是方向显著图。
1.6 Itti 视觉显著图
得到亮度、颜色和方向的显著图以后,将这三个显著图叠加可得到最终的Itti 视觉显著图,计算公式如下:

其中,Ic、Cc和Oc分别代表亮度显著图、颜色显著图和方向显著图,S 为最终的视觉显著图。
2 本文哈希算法
本文哈希算法主要可分为三个步骤,如图1所示。首先对输入的图像进行预处理,利用Itti 视觉显著模型提取该图像的视觉显著图,然后对提取的显著图构造二次图像,最后对二次图像使用LLE 算法,求取方差作为哈希值。下面将分别介绍每个部分的详细过程。

图1 本文哈希算法示意图
2.1 提取视觉显著图
为了保证不同尺寸图像所提取的哈希长度相同,得到规范化图像,需对图像进行预处理。首先对输入图像使用双三次插值法将图像调整为大小是M×M 的图像。然后对调整后的图像进行高斯低通滤波,以减轻噪声干扰等对哈希带来影响。高斯低通滤波可以用卷积模板实现。设是模板的第i 行第j 列,具体计算公式如下:
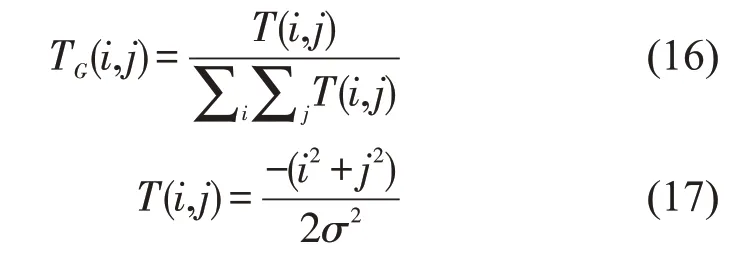
其中,σ是所有模板元素的标准差。接着对预处理后的图像运用上文中所提及的Itti 视觉显著模型去计算图像的视觉显著区域,并将提取出的视觉显著图记为L。
2.2 构造二次图像
为了构造适合数据降维的图像,首先对提取的视觉显著图L 进行非重叠分块,分块的大小为m×m,因此一共有n=(L/m)2个图像块,接着对每个图像块进行Z 字形扫描[13],每一个图像块扫描后将得到的高维向量m2×1,假设是第i 个图像块的高维向量,其中1 ≤i≤n,逐一排列每个高维向量,最终得到二次图像X。图2 是构造二次图像示意图。
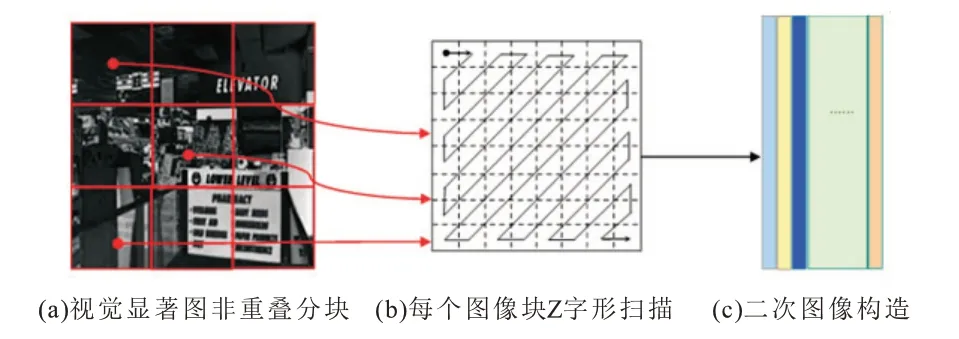
图2 构造二次图像示意图
2.3 局部线性嵌入
局部线性嵌入(LLE)是一种非线性的降维方法,在降维时保持了样本的局部线性特征,通过相互重叠的局部邻域来提供整体的信息,从而保持整体的几何性质。与传统的主成分分析(PCA)等方法相比,LLE 表现出更好的性能,已经广泛应用到高维数据可视化、图像识别[14]、影音认证[15]等领域。图3 为LLE 算法降维的一个实例图。其中(a)是高维空间的数据,(b)是从(a)中提取的样本点,(c)为低维空间数据表示。从图3 可以看出,在LLE 降维过程中,能够保持高维的结构特征不变。

图3 LLE 算法降维示例图
LLE 的算法[16]思想主要分为三个步骤。首先是对邻接点进行选择,接着构造权重矩阵,最后计算低维嵌入向量。详细计算步骤如下。
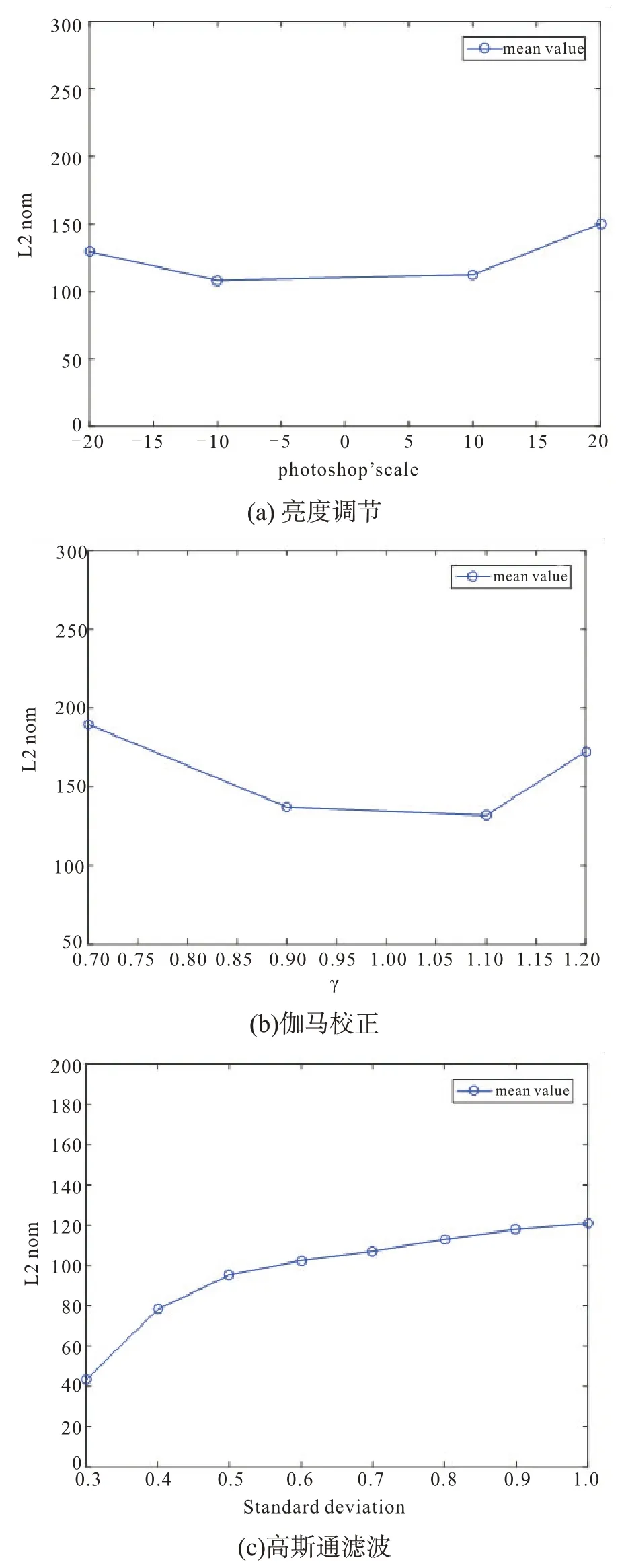
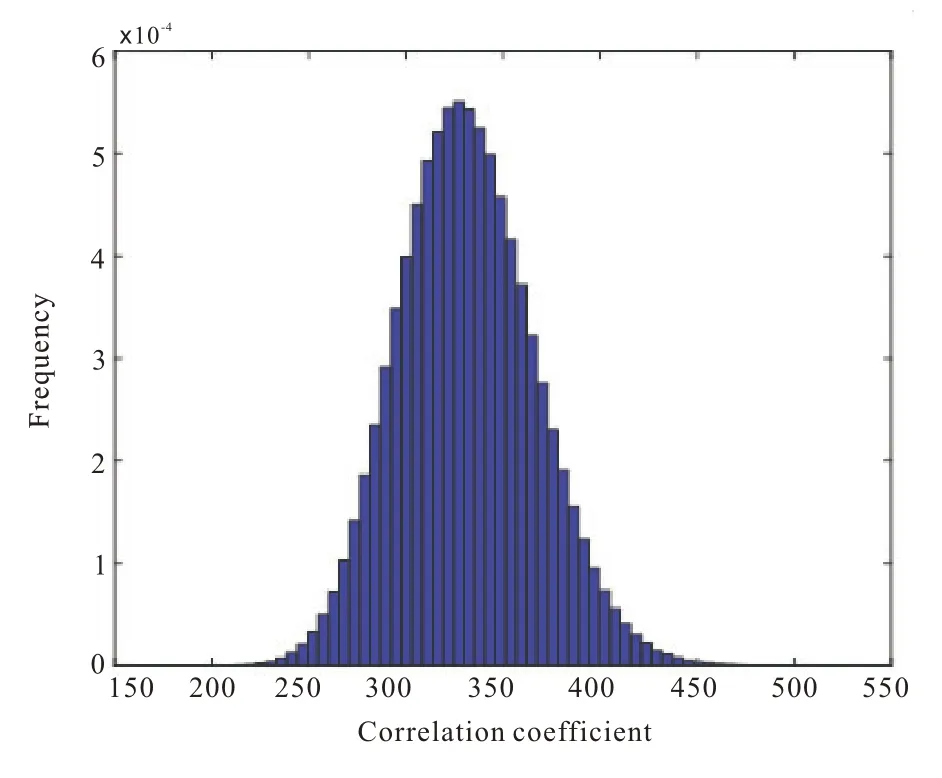
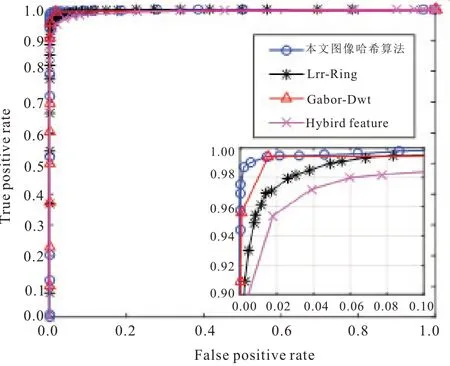
第一步,对邻接点进行选择。假设给定的数据集X=(x1,x2,…,xN),xi∈RD,找到和xi临近的k(k 第二步,构造权重矩阵。计算权重矩阵W=(Wi,j)N×K权重矩阵是xi的k 个最邻近点重构得到的,其公式如下。 其中,Wi,j是xi与xj之间的权重。为了更好研究,在计算W 时,所有xi邻近点之和为1,=1,保证了重构与坐标的平移、缩放和旋转等无关。 第三步,计算低维嵌入向量。通过得到的权值矩阵,每个高维向量xi都会被映射成低维向量yi,具体公式如下。 其中,Φ(Y)是损失函数值,Y=[y1,y2,…,yN]是低维向量所形成的矩阵,yj(j=1,2,…k)为yi的k个邻近点,并且满足以下公式。 其中,I 是一个m×m的单位矩阵。 运用上述LLE 算法对二次图像X 进行数据降维处理得到矩阵Y=[y1,y2,…,yn],并且计算yi的统计特征,用来构造图像哈希序列。本文算法选取方差作为LLL 向量的统计特征[17],具体定义如下: 其中,yi(l)是yi的第l个元素,ui是均值。 最后将方差化为整数记为H,具体公式如下: 其中,Round()表示取整操作,1≤i ≤n。 设H1和H2是两幅图像的哈希,它们的第i 个元素记为H1(i)和H2(i),为了判断相似性,选用L2范数作为衡量标准,其中D(H1,H2)是两幅图像的L2 范数,定义如下: 一般来说,L2 范数越小,哈希序列越相似,相应的图像越相似。如果D>T(预先定义的阈值),则输入图像被认为是视觉上不相同的图像。否则,它们是相同的图像。 本文实验的参数设置如下:图像尺寸调整为256×256,高斯低通滤波卷积模板为3×3,标准差为1,非重叠分块大小为32×32。LLE 算法中,每个向量选取15 个邻近点,维度为40。即M=256,m=32,k=15,n=40。因此哈希长度H=64。下面分别讨论鲁棒性、唯一性和哈希算法的性能比较。 本文采用柯达彩色图像集[18]来验证算法的鲁棒性。该数据集包含了24 幅彩色图像,为了得到用于鲁棒性测试的视觉相似图像,利用StirMark、MATLAB 和Photoshop 工具来对24 幅图像进行常见的数据操作,如亮度调节、伽马校正、…、图像旋转等,每幅测试图像可得到64 幅视觉相似图像。分别提取每一幅图像和它的视觉相似图像的哈希值,然后计算L2 范数,具体结果如图4 所示。从图中可以看出,L2 范数均值都不超过200,因此如果选择阈值T=200,本文哈希算法可以抵抗大多数鲁棒性攻击。 图4 不同鲁棒性攻击的测试结果 为了测试本文哈希算法的唯一性,选用UCID[19]包含1338 幅真彩色图像。应用本文算法提取数据库中1338 幅彩色图像的哈希值,接着用L2 范数去计算每对哈希之间的相似度,这些范数分布的结果如图5 所示,中x 轴是L2 范数,y轴是其频率。最大L2 范数是512.38,最小L2 范数是190.39。所有的L2 范数平均值是331.27,标准差是34.85。如果选择阈值T=200,此时只有0.00559%的不同图像被误判成相同图像。 图5 不同图像之间的哈希距离分布 将本文算法与基于混合特征的哈希算法[3]、基于随机Gabor 滤波和DWT 的图像哈希算法[6]和基于视觉模型的低秩图像哈希算法[10]进行实验比较。实验数据集采用3.1 节和3.2 节的测试图像库,为确保公平,所有图像大小均调整为256×256,再进行哈希计算。同时,仍然采用文献算法的相似性度量来计算它们的哈希距离,即基于混合特征的哈希算法[3(]Hybrid feature)、基于随机Gabor滤波和DWT的图像哈希算法[6(]Gabor-Dwt)和基于低秩表示和环分区图像哈希算法[10](Lrr-Ring)都是使用L2 范数。实验用接收机操作特性(ROC)曲线[20]来分析上述对比算法的分类性能,即分别计算它们的正确率PTPR和误判率PFPR。 其中,nT是相似图像的正确判断数,N1是相似图像的总数,nF是不同图像的误判数,N2是不同图像的总数。PTPR和PFPR分别描述鲁棒性和唯一性,在ROC 图中,x 轴是PFPR,y 轴是PTPR,越靠近左上角的ROC 曲线,对应的哈希算法分类性能就越好。图6 列出了本文和其他三种哈希算法的ROC 曲线,可以发现本文算法的ROC 曲线更靠近左上角,说明本文的哈希算法的鲁棒性和唯一性之间的分类性能优于Hybrid feature 算法[3]、Gabor-Dwt 算法[6]和Lrr-Ring 算法[10]。 图6 不同的哈希算法的ROC 曲线 本文设计了一种基于Itti 视觉显著模型和LLE 的图像哈希算法。首先利用Itti 视觉显著模型提取图像的视觉显著图,提高了算法的鲁棒性,然后用提取的显著图构造二次图像,接着用LLE算法进行降维处理,最后取方差作为哈希值,可确保本文算法在拥有唯一性的同时将哈希长度缩短。利用公开的数据集去验证该算法的性能,实验表明该算法在鲁棒性和唯一性之间达到良好的平衡,其分类性能也优于某些文献算法。接下来的工作中,将计划扩大数据集设计基于深度学习的哈希算法。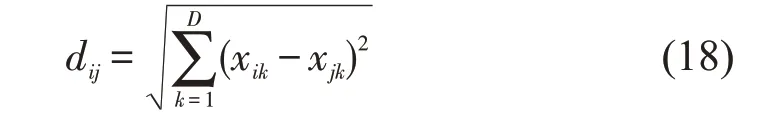
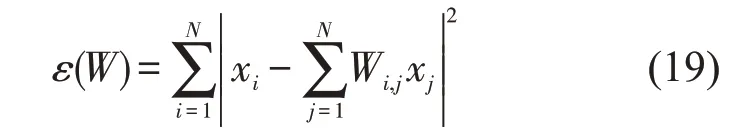
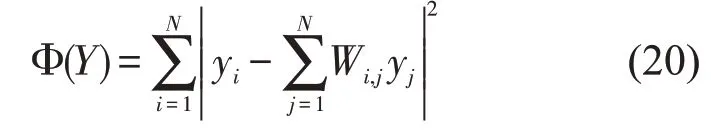
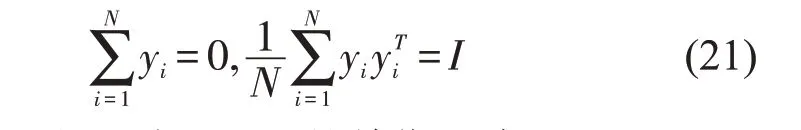
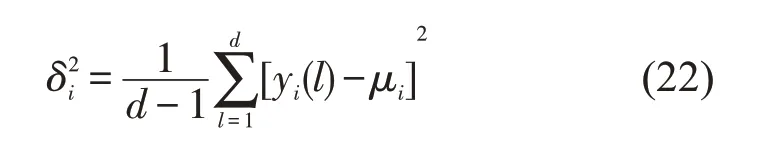
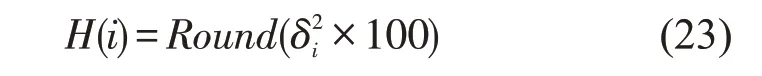
2.4 哈希相似度计算

3 实验结果及分析
3.1 鲁棒性

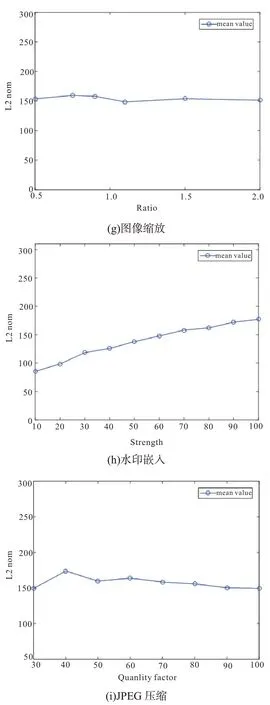
3.2 唯一性
3.3 算法性能比较

4 结语
