基于CSOT-BiLSTM-CRF 的中文事件要素识别
2021-12-07张顺香
杨 彬,廖 涛,张顺香
(安徽理工大学,计算机科学与工程学院,安徽 淮南 232001)
事件抽取是信息抽取的重要子任务,旨在从非结构化的信息中抽取出用户感兴趣的信息,并以结构化的形式向用户展示。事件抽取可以分成事件识别和事件要素识别两个部分,事件识别是找到事件的触发词并确定事件所属类别;事件要素识别是对确定事件中所包含的事件要素进行识别。
定义1 事件(Event)指的是在某个特定时间和环境下发生的、由若干角色参与、表现出若干动作特征的一件事情[1]。
定义2 事件要素(Event Argument)指的是参与某个事件的角色,例如时间、地点、参与者、动作等[1]。
本文的研究内容是事件要素识别,事件要素识别的目的是找到事件中表示要素的词语所在的位置。例如,在交通事故类事件中需要准确识别出事故发生的时间、地点、救援措施等;在恐怖袭击类事件中需要识别出袭击地点、策划人、袭击方式等。对于例1,在事件要素识别任务中,“5 月12日14 时28 分”应被识别为时间要素;“四川汶川县”应被识别为地点要素;“地震”应被识别为标识词要素。
例1,5 月12 日14 时28 分 在四川汶川县 发生7.8 级地震
早先的事件要素识别多采用模式识别和传统机器学习的方法,通常依赖于一系列复杂的自然语言处理工具来提取词汇级特征(如词性特征,邻近词)和句子级特征(如依存关系),虽然取得了一定效果,但模型的泛化能力通常较差。
近年来,神经网络迅速发展,并成功应用于自然语言处理领域。例如,Zhang 等[2]提出了一种结合BERT 和双向长短期记忆网络的事件抽取模型,在中文事件触发词识别和事件分类实验中取得了不错效果。Zhang 等人[3]提出了一种结合Skip-Windows 的卷积神经网络模型,并在ACE 语料集上也取得较好的效果。与此同时,条件随机场能自动学习标注序列的约束条件,被广泛应用于自然语言处理各项任务中。
受此启发,为了更好地学习标注序列中隐藏的约束条件,本文提出了一种基于CSOT-BiLSTM-CRF 的事件要素识别模型,将BiLSTM 与CRF 结合。在保留BiLSTM 网络获取文本的上下文特征的基础上,加入CRF 自动学习标注序列中隐藏的约束条件。同时针对当前事件要素识别中存在的类别不平衡问题,在预处理阶段提出了一种CSOT 算法,有效提高少数类的识别效果。
1 相关工作
1.1 基于模式识别的方法
基于模式识别的方法指的是在一定模式的指导下,将待抽取的句子与已经抽出的模板进行匹配,从而完成识别任务。例如,Vanitha 等[4]提出了一种基于通用规则的事件抽取算法,通过映射框架规则从自然语言文本中识别事件,对MUC(Message Understanding Conference)语料库进行事件抽取实验,取得较好的效果。梁晗等[5]利用句型模板和Bootstrapping 技术,提出了一种基于框架的信息抽取模式,并建立一整套事件框架,在灾害事件信息抽取实验中有良好的实验效果。
总体来说,基于模式匹配的方法在特定的领域能取得较高的准确率,但在制定模板时往往需要具有丰富领域知识的专家进行指导,制作过程容易产生错误且费时费力。除此之外,抽取出的模板只适用于某一特定领域,可移植性较差。
1.2 基于传统机器学习的方法
与基于模式识别的方法相比,传统的机器学习方法通常将事件要素识别看作分类问题,这种方法与领域无关,系统的可移植性较好。但常会受到语料库规模和数据稀疏问题的影响,并且依赖于复杂的自然语言处理工具,识别的准确率通常低于基于模式识别的方法。
赵妍妍等[6]提出了一种扩充触发词的方法,其合并了不同类别的相同事件元素,以构建用于事件要素识别模型。在ACE(Automatic Content Extraction)语料库上进行实验,事件要素识别效果有所提升。付剑锋等[7]提出了一种基于特征加权的事件要素识别方法。该方法对ReliefF 算法进行了改进,并根据每个特征的贡献不同以分配不同的权重,最后利用聚类算法对事件元素进行识别。Liao 等[8]对K-means 算法实现了改进,通过引入Canopy 算法有效解决了K 值问题,并对突发事件中的时间和地点要素进行识别。
1.3 基于深度神经网络的方法
近年来,深度神经网络逐渐应用于自然语言处理任务上,大量基于深度神经网络的事件抽取模型不断涌现。
Nguyen 等[9]提出了一种基于卷积神经网络(Convolutional Neural Network,CNN)的事件识别模型,避免了传统机器学习中预处理阶段的错误传播,并且不需要复杂的特征提取工程,在ACE语料集中取得了较好的事件识别效果。之后,Nguyen 等[10]又将BiLSTM 应用于事件抽取任务中,通过BiLSTM 提取文本的上下文特征,在ACE 语料集中取得较好的效果。Chen 等[11]在卷积神经网络的基础上加入动态多池化,提出了一种动态多池化卷积神经网络(Dynamic Multi-Pooling Convolutional Neural Network,DMCNN)模型,该模型能自动提取词汇级和句子级特征,并在ACE 语料集上也取得了不错的效果。Zeng 等[12]在2016 年提出一种混合模型,将BiLSTM 和CNN 相结合提取句子级和词汇级特征,利用词语义表示,摆脱手工制作的困难,易于适应多种语言。实验分别在中文、英语和西班牙语语料集上进行事件识别实验。除此之外,还要很多学者将神经网络[13-15]应用于自然语言处理任务中,但没有探索事件要素的抽取方法。
相比于传统机器学习方法,神经网络能自动从原始数据中学习有用的特征,避免了对自然语言处理工具的依赖,减少特征提取的工作量。并且不需要分析句子间的语义特征,避免了因人工干预带来的错误传播。其中BiLSTM 作为RNN(Recurrent Neural Network)的一种变体,能够从前向和后向获取文本的上下文特征,更符合中文的遣词造句思想。
在此基础上,本文提出了基于CSOT-BiLSTM-CRF 事件要素识别模型,其中CSOT 算法能有效解决类别不平衡问题,提高了少数类的识别准确率;BiLSTM 能很好的提取文本的上下文特征;条件随机场能自动学习标注序列中隐藏的约束条件。
2 基于CSOT-BiLSTM-CRF 的事件要素识别
通常情况下,传统的机器学习方法将事件要素识别划分为两个步骤:要素特征提取和要素分类。本文将事件要素识别看成序列标注问题,这样可以有效减少线性模型带来的误差传播。
在介绍本文模型之前,首先阐述一下事件要素识别中存在的类别不平衡问题。
2.1 类别不平衡问题
对于数据集D,如果不同类别的样本数量相差很大,即Ni>>Nj,那么称D 为类别不平衡数据集。其中样本数量较少的类别称为少数类,样本数量较多的类别称为多数类。对于不平衡数据集,如果不加处理的进行实验,所得出的实验结果往往较差。例如,对于多数类数量达到980,而少数类数量只有20 的类别不平衡数据集。即便实验将所有的样本都预测为多数类,实验的准确率也能达到98%,但此时所有的少数类都会被错分。
经过学者的不断研究,目前类别不平衡问题的解决方法主要有两种:欠采样和过采样。欠采样指的是通过去除多数类中的一些样本,使样本数量达到相对平衡;过采样指的是通过增加一些少数类的样本,使样本数量达到相对平衡。基于欠采样和过采样,研究者提出了EasyEnsemble[16]、BalanceCascade[16]、SMOTE[17]等算法。
CEC(Chinese Emergency Corpus,中文突发事件语料库)语料集中共定义了6 种要素,本文主要关注其中的标识词、时间、地点和工具4 种要素。其中标识词要素有5909 个,而工具要素只有174个,不平衡比例达到34:1。图1 所示为各要素所占比重。

图1 识别各要素所占比重
受SMOTE 算法[17]的启发,同时考虑到多数中文词语具有同义词的特性,本文结合同义词词林扩展版提出了一种CSOT 算法以解决类别不平衡问题。词林中包括一定数量的词语以及这些词语的同义或同类词,本文使用的是由哈工大扩充后的扩展版。算法具体步骤如下:第一步,对数据集进行预处理,计算各类别要素的数量,确定其中的多数类和少数类。第二步,对于少数类S={x1,x2,x3...,xn},通过同义词词林扩展版获取每个样本xi 的同义词。第三步,使用同义词生成新的样本集E,并将样本集E 添加到S 中来扩大数据集,从而形成新的少数类Snew。表1 所示为具体算法描述流程:
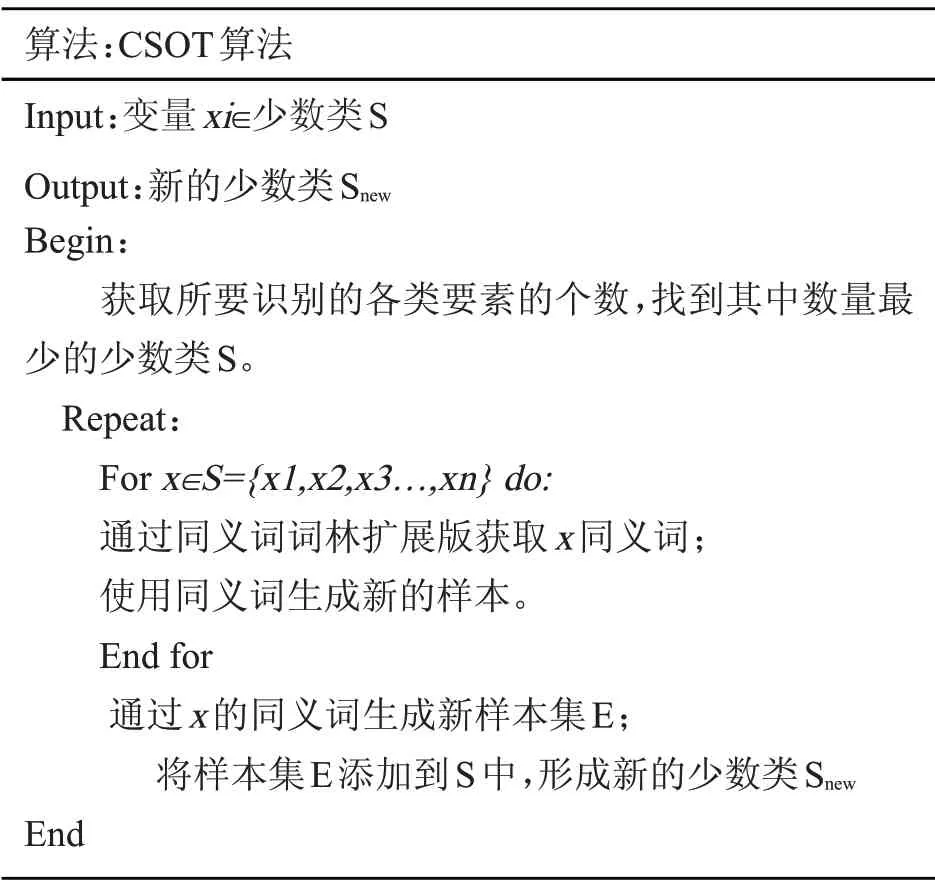
表1 CSOT 算法流程
2.2 CSOT-BiLSTM-CRF 网络总体结构
本文将事件要素识别看做序列标注问题,即对句子中的每一个字预测它所对应的标签。由此,提出了一种基于CSOT-BiLSTM-CRF 的事件要素识别模型,图2 所示为网络总体结构。

图2 CSOT-BiLSTM-CRF 网络总体结构
首先,通过CSOT 算法处理,使数据集中各要素数量达到相对平衡,并对句子中的每个字进行BIO 标注;然后,将每个字映射成向量形式,并把向量化的句子输入到BiLSTM 中提取上下文特征信息;最后,将提取的特征信息输入到CRF 层中自动学习标注序列隐藏约束条件,并解码得到最终的标注序列。下面对模型中的每一部分进行详细说明。
2.3 BiLSTM 层
长短期记忆(Long Short-Term Memory,LSTM)神经网络是一种时间循环神经网络,是为了解决RNN 中存在的长短期依赖问题而设计的,善于处理时间序列中间隔比较长的事件。与RNN 不同,LSTM 在隐藏层加入记忆单元,用来保存长期状态,使得LSTM 有能力向状态单元中添加或丢弃一些信息。图3 所示为LSTM 的一个存储单元。
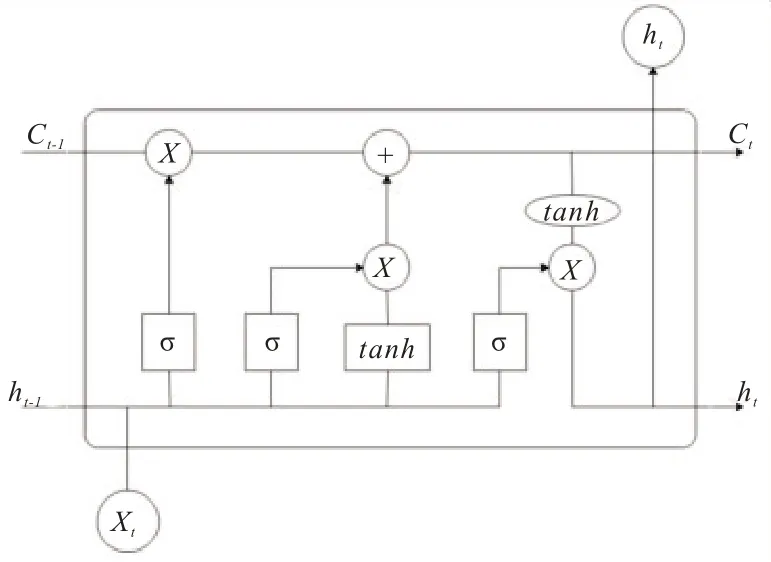
图3 LSTM 的一个存储单元
相较于原始RNN,原始RNN 只考虑最近时刻的状态,只是简单地将上一时刻的输出与这一时刻的输入相级联,使得RNN 对长期的输入不敏感,导致梯度消失问题。而LSTM 引入细胞结构,通过遗忘门、输入门和输出门来控制哪些细胞状态应该被遗忘、哪些应该被添加以及输出应该是什么,这就使得LSTM 能很好的解决长期依赖问题。LSTM 的状态更新可由下列公式得到。
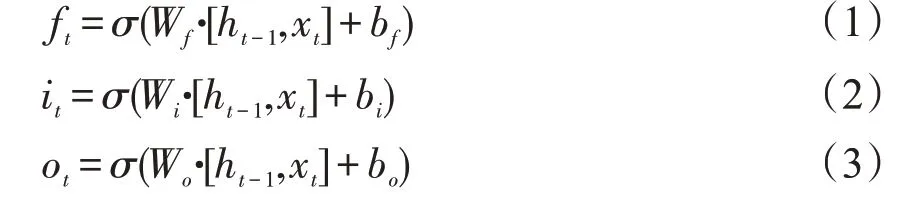
式(1),(2),(3)中ft,it和ot分别表示LSTM的遗忘门、输入门和输出门。式(4),(5)表示通过输入,遗忘和输出门确定的单元状态和隐藏状态。其中σ是一个激活函数,该激活函数具有非线性,并且类似地将其输入压缩到[-1,1]范围。W表示每个门单元的权重矩阵,b是偏置。ht-1为上一隐藏层状态值,xt为当前输入。ht为当前隐藏层状态值。
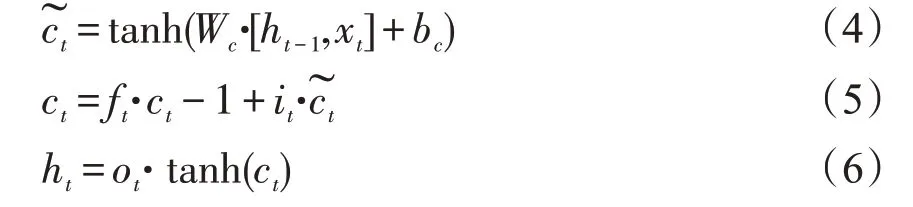
本文采用的是BiLSTM,相较于LSTM 只能从一个方向提取文本特征,BiLSTM 将前向LSTM 和后向LSTM 相结合。前向LSTM 抽取出上文的特征信息,后向LSTM 抽取出下文的特征信息,最终融合获取全局的上下文特征,能够很好地解决LSTM 无法提取下文特征信息的问题。
2.4 CRF 层
CRF 指的是若X 与Y 是随机变量,随机变量Y 构成一个由无向图G=(V,E)表示的马尔可夫随机场,则称条件概率分布P(Y|X)为条件随机场。条件随机场是一种序列化标注算法,用于解决在给定一组输入随机序列的情况下,预测另一组输出随机序列的概率分布,式(7)所示为条件随机场定义公式。
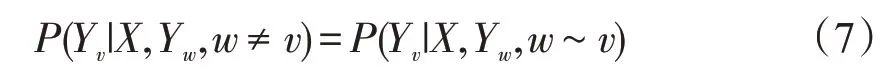
其中w∼v表示在图G=(V,E)中与顶点v有边连接的所有顶点w;w≠v表示顶点v以外的所有顶点;Yv和Yw为顶点v与w对应的随机变量。
线性条件随机场是目前解决序列标注问题的经典算法,它指的是若X={x1,x2,x3,...xn}为一组输入序列,Y={y1,y2,y3,...yn}是一组输出序列,线性条件随机场所要计算的就是两者之间的条件概率P(Y|X),式(8)所示为线性条件随机场定义公式。
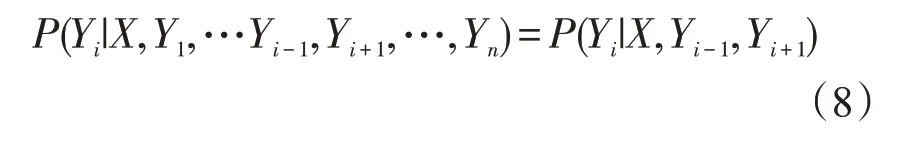
其中i=1,2,3,…,n,在i=1 和n时只考虑单边。
本文用CRF 预测最终的标注序列,图4 是线性条件随机场模型,在预测标签时不仅可以充分考虑上下文关联,还会对预测的标签添加一些约束来保证结果是有效的,具体约束如下所示:
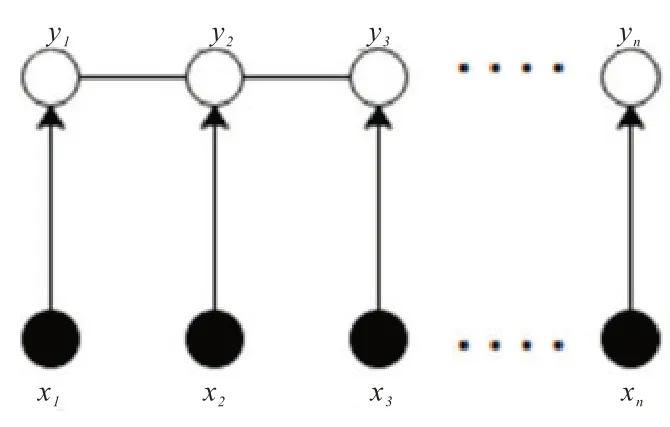
图4 线性条件随机场模型
(1)当要素仅由一个字构成时,例如“伤”、“亡”等,标注应该是“B-”或“O”,而不存在“I-”的标注形式;
(2)当要素由两个或两个以上字构成时,例如“碰撞”、“森林火灾”等,第一个标注应该是“B-”,而不是“O”或“I-”;
(3)在“B-lable1,I-label2,I-label3...”标注中,label1、label2、label3 应属于同一类别。例如“Btime,I-time”是合法的,而“B-time,I-denoter”是无效的。
通过这些约束条件,可以充分考虑上下文之间的联系,预测结果的无效序列会大幅减少,有效提高事件要素的识别效果。
3 实验结果与分析
3.1 数据来源和评价
本文使用的语料库是CEC2.0 版本。其中包括地震(62 篇)、火灾(75 篇)、恐怖袭击(49 篇)、食物中毒(61 篇)和交通事故(85 篇)五大类共计332 篇新闻文本。CEC 语料库中共定义了6 种事件要素,本文主要关注其中4 种:标识词、时间、地点、工具,表2 所示为CEC 对于相关要素的描述。

表2 CEC 中相关要素描述
本文使用准确率(Precision)、召回率(Recall)、F1 值(F-Measure)来评价事件要素识别的效果,Precision、Recall、F1 定义如式(9)~式(11)所示。
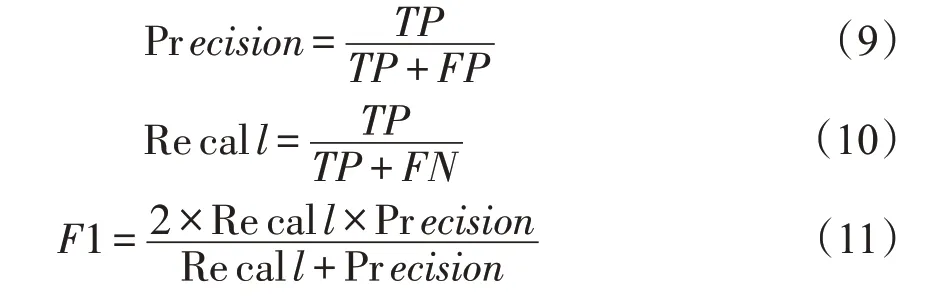
3.2 数据准备
对于语料库中的XML 文档,首先需要提取文本信息,获取完整的新闻;然后,考虑到新闻文本的特殊性,需要对数据进行清洗,去除新闻中如出版日期、记者名称、出版社等与新闻事件无关的信息;最后,对标识词、时间、地点和工具要素进行BIO 标注,并按7:2:1 将语料库划分为训练集、测试集和验证集。表3 所示为划分后数据集各要素数量分布。
由表3 得出标识词、时间和地点要素数量相对均衡,其中标识词要素数量最多,工具要素数量最少。因此本文中标识词要素为多数类,工具要素为少数类,多数类与少数类的比例达到34:1。
3.3 实验环境与参数设置
本文采用Pytorch 搭建模型,采用Python3.6作为实验工具。
实验参数设置为:迭代次数epoch 为20,训练集和测试集的batch_size 为64,BiLSTM 的前后隐向量的维数为128,学习率为0.001,使用Adam优化器最小化模型损失,使用梯度截断技术防止BiLSTM 梯度爆炸,实验通过观察验证集上的误差确定最终模型使用的参数。
3.4 CSOT 算法泛化实验
为了证明CSOT 算法能有效地解决类别不平衡问题,并且验证算法的泛化能力,本文将算法分别应用于K-means、HMM、BiLSTM 以及BiLSTM-CRF 模型中进行实验。考虑到不平衡比为34:1,实验将少数类的倍数设置为5~30 倍,并计算少数类的识别准确率。图5 所示为CSOT 泛化实验结果。
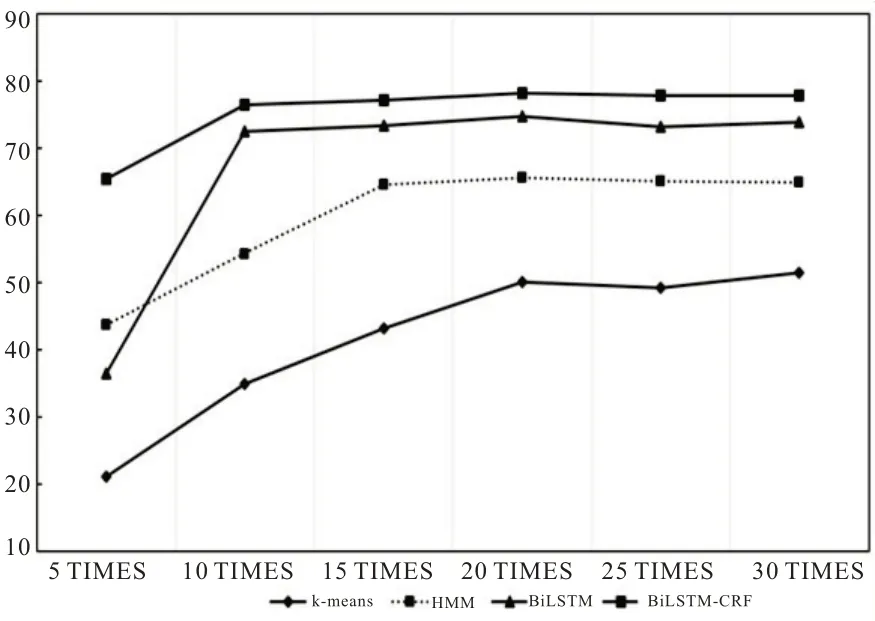
图5 CSOT 算法泛化实验
由图5 可以看出:本文提出的CSOT 算法泛化能力较好。随着少数类的成倍增加,K-means、HMM、BiLSTM、BiLSTM-CRF 模型对于少数类的识别精确度都能增加,并最终趋于定值。这说明CSOT 算法能很好地解决类别不平衡问题,提高少数类的识别准确率。
3.5 事件要素识别实验
为了证明本文的模型具有更好的事件要素识别效果,实验将本文模型与K-means、HMM、BiLSTM 以及BiLSTM-CRF 模型进行比较。其中Kmeans、HMM 采用的是基于传统机器学习的方法,BiLSTM 和BiLSTM-CRF 采用的是基于深度神经网络方法。由泛化实验可知,当少数类的倍数为20 时,其准确率达到最高,故本文模型的倍数为20。实验分别对各模型要素识别的准确率、召回率和F1 值进行比较,结果如表4~表6 所示。
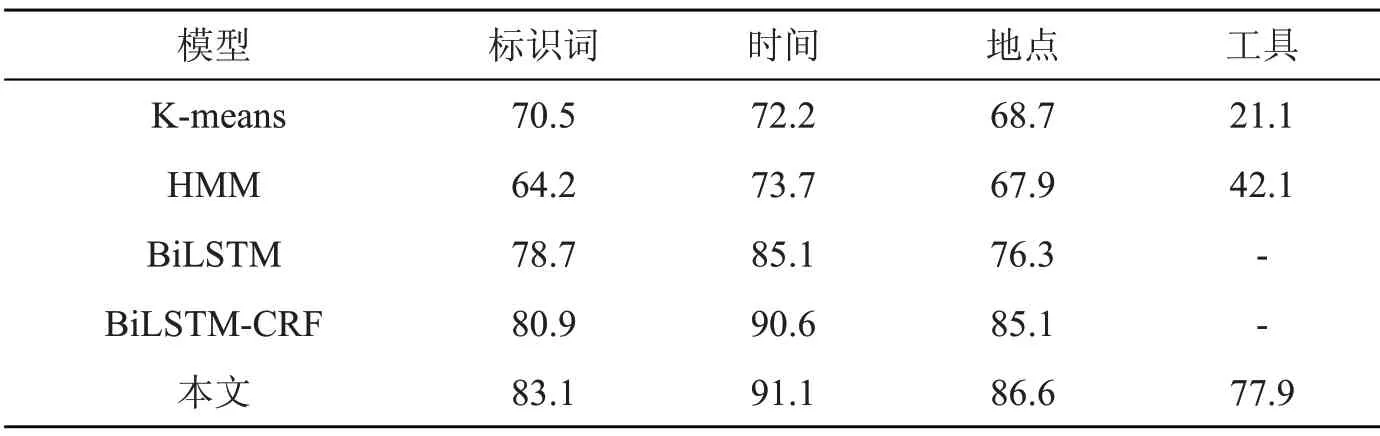
表4 各模型的要素识别准确率(P)对比
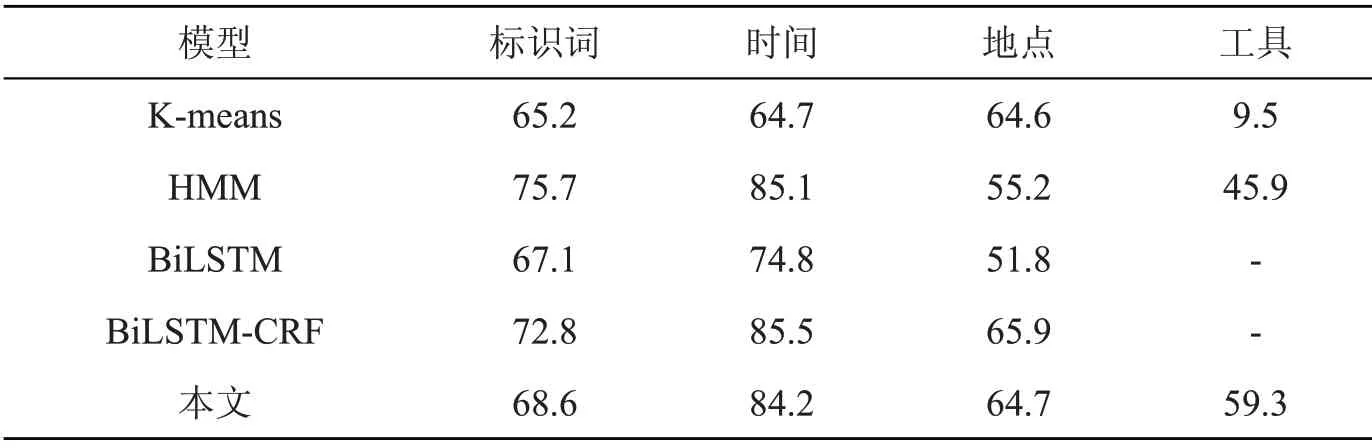
表5 各模型的要素识别召回率(R)对比
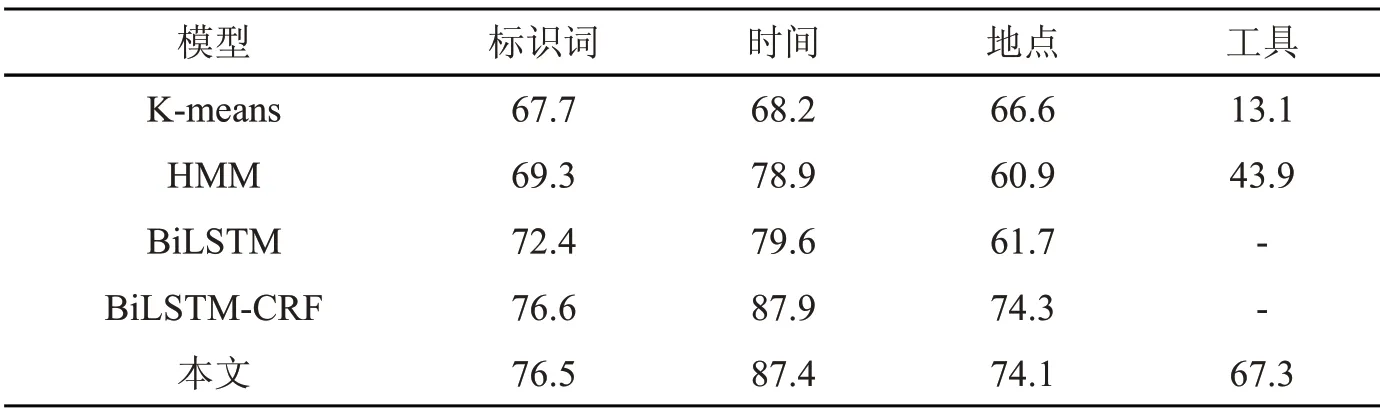
表6 各模型的要素识别F1 值对比
由表4~表6 可以看出:
(1)对于标识词要素。相较于传统机器学习方法中的K-means 和HMM 模型,本文模型的F1值分别提升了8.8%、7.2%;相较于单一的BiLSTM 模型,本文的F1 值提升了4.1%;相较于BiLSTM-CRF 模型,本文的F 值下降了0.1%,但识别准确率P 值提升2.2%。
(2)对于时间要素。从结果来看,无论哪个模型对于时间要素识别的F1 值都是最高的。相较于K-means、HMM,本文模型的F1 值分别提升了19.2%、8.5%,提升幅度较大;相较于BiLSTM 模型,本文的F1 值提升了7.8%;相较于BiLSTMCRF 模型,本文的F1 值下降了0.5%,但识别准确率提升了0.5%。
(3)对于地点要素。从结果来看,各个模型对于地点要素识别的F1 值都是最低的。这是由于事件发生的地点各不相同、长短不一、没有规律可循,导致模型对于地点要素的特征学习性能不高。相较于K-means 和HMM 模型,本文模型的F1 值分别提升了7.5%、13.2%;相较于BiLSTM模型,本文的F1 值提升了12.4%;相较于BiLSTM-CRF 模型,本文的F1 值下降了0.2%,但识别准确率P 值提升了1.5%。
(4)对于工具要素。相较于K-means 和HMM 模型,本文模型的F1 值分别提升了54.2%、23.4%;而BiLSTM 和BiLSTM-CRF 模型未能识别出工具要素,本文将F1 值提升到67.3%,识别准确率P 值提升到77.9%。
总的来说,本文提出的模型在事件要素识别任务上能取得较好的效果。与基于传统机器学习的模型相比,本文提出的模型在F1 值上有很大提升,原因是深度神经网络能更好的抽取文本特征,避免误差传播;与BiLSTM 模型相比,本文提出的模型在F1 值上有所提升,这是由于CRF 能自动学习标注序列中的约束条件,使预测结果中的错误序列大幅减少;与BiLSTM-CRF 模型相比,本文提出的模型在F1 值上有所下降,这是由于少数类数量的增加,导致其他要素的学习效果有所下降,但本文模型能提高要素识别的准确率,其中工具要素P 值显著提升。
4 总结与展望
本文提出了一种CSOT-BiLSTM-CRF 模型,将事件要素识别看成一种序列标注问题。提出CSOT 算法以解决类别不平衡问题,利用BiLSTM抽取文本的上下文特征,同时使用CRF 自动学习标注序列的隐藏约束条件。实验结果表明:与已有的事件要素识别模型相比,本文的模型能自动学习标注序列中的隐藏约束条件,有效解决类别不平衡问题,提升事件要素识别性能。
下一步将扩充实验语料库,继续对事件要素识别的研究,尝试将该模型运用到其他要素的识别。另外,今后可将注意力机制加入到模型中来进一步改善事件要素识别的效果。
