面向英、汉跨语言研究的自动依存句法分析工具信度研究*
2021-12-06刘鼎甲张子嬿
刘鼎甲 张子嬿
(北京外国语大学中国外语与教育研究中心/国家语言能力发展研究中心, 北京 100089)
提 要:近年来,句法分析被广泛应用于语言研究,尤其是随着语料数据的成倍增长,自动分析方法和工具的运用更显重要。 然而,原本用于自然语言处理研究的自动句法分析方法和工具的适用性、准确性学界尚不了解,尤其在跨语言、跨文体研究中的适用性和特征的显著性未加检验,使得研究者不敢贸然使用,因而自动句法分析在实证语言研究中的信度是问题的关键。 为此,本文考察和比较当前3 种主流的句法分析工具Stanford Parser,Mate Parser 和Malt Parser 用于英、汉语言自动句法分析的准确性,并在此基础上以科技、新闻、社会科学和文学文体为例,在依存句法框架下对英语源语、翻译汉语与原创汉语的差异性进行考察,借以讨论依存句法分析方法在跨语言、跨文体研究中的适用性和特征的显著性。
1 引言
句法是语言研究的核心问题之一(Valin 2001:1),但长久以来缺乏实证研究的传统(Biber et al. 1998:55)。 近年来,上述限制正逐渐被打破。 首先,句法在语言本体的研究已在语料库短语学研究和配价的框架下进行。 前者主张词汇与语法的统一,通过共选产生意义,体现出词语互选的倾向性(甄凤超2019:36,许家金2020:1 -10),具体的考察对象包括搭配、语义韵、语义倾向和类连接(Sinclair 2004)。 后者以词汇为切入点,通过“局部描写”方法来描述词汇间的潜在结合能力,且这种潜在能力只有在语言使用时被激活(刘海涛2009:23),弥补传统次范畴化的成分语法割裂句法和语义的不足。 其次,复杂性(complexity)是句法研究重要应用领域。 当前,复杂性分析已成为历史(历时)句法学、语言习得和语言演变3 个主要发展领域的重要问题(Givón 2009:7),研究的焦点在句法复杂度的特征、复杂度计量以及句法复杂度和语言类型、文体学、语言发展、语言习得和跨语言对比等领域(Gibson 1998;Dahl 2004; Crossley, McNamara 2014; Mancilla et al. 2015;雷蕾2017;朱周晔王金铨2020;胡韧奋2021)。 目前,已有研究利用自动句法分析方法,通过语句长度、从属结构数量、并列结构数量和短语复杂度等多个维度的计算,对多达几十个句法复杂度测量指标进行自动化分析,如Biber Tagger(Biber 1988)、Coh-Metrix 3.0(Graesser et al. 2004)和L2SCA(Lu 2010), TAASSC(Kyle 2016)。
然而,准确的句法分析需要经专业人员手工进行,耗时费力,效率和准确率都不高(雷蕾2017:2)。 此外,人工标注主观因素影响大,标注结果一致性差。 相比而言,采用计算机程序自动标注具有快速、客观的优势。 尤其是基于语料库的研究,势必要对语料库进行自动词性赋码和句法标注(梁茂成等2010:201),但标注的准确性需要细致的实验和考证。 有学者对词性赋码的信度进行过考察(梁茂成2006),指出词性赋码工具在二语习得研究中具有较高的可靠性,为语料库研制和语言研究中语法关系的考察扫清障碍,但也同时指出当前句法分析的困境。 近年来,自动句法分析方法和技术已取得进展(刘鼎甲王克非2018),对语料库实施句法标注的障碍正在逐渐被打破,但自动句法分析方法用于语言研究的信度考察仍是一个亟待解决的问题,使得研究者不敢贸然对基于自动句法分析的语料进行深入的阐释(Hunston, Francis 2000)。 有鉴于此,本文旨在对数据分析的准确性进行实证考察,并以翻译汉语句法特征为例,考察依存句法分析方法在跨语言、跨文体研究中的适用性和特征的显著性,以期对自动句法分析方法在实证语言研究中的信度做初步探索。
2 研究方法
2.1 研究问题
本研究拟回答以下问题:(1)使用自动依存分析工具对英汉语言的自动句法分析,分析的准确率如何,自动句法分析的准确率与句子形式和文体存在何种关联;(2)自动句法分析主要呈现何种错误类型,是否存在显著的差异性;(3)句法分析方法及其自动分析工具用于跨语言实证研究的适用性和特征显著性如何?
2.2 研究数据与句法标注工具
本研究的语料取自“中国英汉平行语料库”(CECPC),总库容103,766,292 形符,包括非文学和文学两个子类。 其中非文学部分包含科技、社科和新闻,文学部分包含传记、散文、小说、戏剧和儿童文学等主题。 首先,在自动分析工具的准确性分析部分,为最大程度的验证自动句法分析在真实语料中的准确度,控制手工分析的难度,本文采用随机抽样的方法使用R4.0.3 的sample 函数分别从文学和非文学两个文类中抽取原创英语和汉语各100 句,共计400 句。
其次,在翻译汉语句法特征分析中,本文从CECPC 中进行采样,抽取科技、社科、新闻和文学4 种文体英译汉语料各20 万字/词,并抽取兰卡斯特现代汉语语料库(LCMC)中的科学、自传和议论文与官方文档、媒体和普通小说作为原创汉语文本与上述各文体中翻译汉语进行对比分析,具体数据如表1所示。

表1 数据统计
根据刘鼎甲和王克非(2018),本文选取可以免费获取、使用广泛且其报告的分析准确率最高的3 种决策式自动句法分析工具,包括:基于机器学习的Malt Parser(Nivre et al. 2006)、Mate Parser(Bohnet, Nivre 2012)和基于神经网络的Stanford Parser(Chen, Manning 2014)进行对比考察。 为最大可能降低训练集对句法分析精度的影响,提高准确性,实现对汉语的支持,本研究使用Penn2Malt 分别将完整的宾州树库和宾州汉语树库等价转换为依存树库,并统一使用Universal Dependency 进行依存关系标注,然后对3 个分析器进行完整训练,分别获得英语和汉语分析模型。
2.3 语法结构类型分类框架与研究步骤
观察自动标注工具的错误类型和理解导致错误的成因,有助于通过预处理提高自动标注的准确性,并在实际研究中有目标地减少自动标注错误对研究结果的影响。 根据Nivre 等(2006)与Chang 等(2009),分别将英汉主要依存关系按照其语法结构类型划分为短语结构和句子结构,其中短语结构的中心成分为名词节点,句子结构的中心成分为动词节点。 短语结构的依存关系按照名词中心成分所支配成分间关系,可划分为修饰关系和功能关系。 前者表现为支配词要求在语义上受其支配的从属词与之共现,是典型的词汇配价表现(周国光2011:49)。 后者主要受中心节点的语法范畴限定,完成短语结构在句子中的语法关系。 根据依存关系在句子结构中的类型来看,可划分为描述句子内部成分关系和小句关系两类,前者表示句中成分之间的关系,后者描绘节点词及其从属结构与句子内其它节点词及从属结构共同构成的句法关系。
本研究分3 步进行:首先,考察自动句法分析工具的准确性。 (1)使用3 种工具分别对虚构和非虚构类英汉语句进行自动句法分析,所得结果经PyGraphViz 可视化后,由研究者和经过充分培训的4 名硕士生进行独立的错误分析,错误分析结束后,由研究者组织参与错误标记的人员进行一致性校订,对于有争议的句法结构,研究者咨询该方向的同事,直到达成一致。 (2)对句法分析的准确性进行统计,考察对象包括:支配节点、依存关系和整句分析。 (3)对所得结果进行统计,使用R 通过多元回归对影响句法标注准确性的因素及其影响的程度进行分析。
其次,考察自动句法分析工具的误例类型和成因。 分别对英、汉语依存关系标注错误及其错误的类型进行分类统计,考察的依存关系类别包括短语结构类依存关系和句子结构类依存关系,考察的错误类型包括词性标注错误和依存关系的标注错误,后者包括支配节点及支配关系的错误。
最后,以英译汉平行库科技、社科、新闻和文学4 类文体为例,通过语际对比和语内类比,对英语源语和汉语翻译、汉语翻译语言和汉语原创语言的依存句法特征和以依存距离作为指标的句法复杂度展开对比分析,借此验证依存句法分析方法在跨语言、跨文体研究中的适用性和特征的显著性。
3 数据分析
3.1 英、汉句法标注准确性分析
语言研究中信度的最基本保证取决于标注的准确性。 本研究分别对经Mate Parser,Stanford Parser 和Malt Parser 句法标注的依存句法结构准确性进行对比考察,结果如表2显示。

表2 句法分析工具标注的准确性统计
句法标注工具的准确性较之词性赋码工具存在较大差距(梁茂成2006)。 无论是支配节点还是依存关系的标注,句法分析器的平均精度在78%~93%之间,而整句的完全正确率最高仅36%。此外,数据显示,语种和文体也影响句法分析的精度。 其中,无论是局部的支配节点与依存关系,还是整句准确性,英语的句法标注精度均显著高于汉语,可能是由于汉语没有丰富的形态标记系统(石毓智2010:13),而基于形态分析的词性赋码是句法分析器的重要参考指标之一。 从文体上看,非文学文本语句的局部支配节点和依存关系的分析准确率高于文学文本,而文学文本整句准确率高于非文学语料。 本文认为,非文学文本的句子普遍偏短,因此所有依存关系同时标注正确的几率也越高。 相反,非虚构文体的语言较为正式,句法和语义结构相对完整,但句中依存关系数量较多,因此句法分析所得正确的节点较多,但整句所有节点得到正确分析的几率不高。
本文选择依存节点分析的准确率(百分比*100)作为因变量,分别将句长、分析器、语种和文体作为解释变量,采用多元线性回归进行分析(残差F=13. 5,df=1192,p<0. 001,R2=0.0536),考察句长、文体和语种对依存关系分析准确性影响的程度。 由于句法分析的复杂性,本研究不考虑在回归模型中对解释变量的全面性和模型对因变量的预测性,即不考察拟合优度(R2),也不考虑各解释变量间的交互效应。 结果表明,句长、句法分析工具、语种和文体与句法分析结果的精度均存在不同程度的关系,且上述关系均具有显著性。 其中,句长与依存关系的精度存在负相关的关系(p<0.05),表明句子越长,句法分析的精度越低。 Stanford Parser 分析器与依存关系的精度存在显著的正相关关系(p<0.001),且显著性高于Mate(p<0.001)。 英语较之汉语更容易获得较高的精度(p<0.001),而非文学文体在依存关系分析上具有较高的准确性,但文体对分析准确性影响的显著性低于前两者。
3.2 英、汉语句法标注的错误分析
本文对英语和汉语的自动句法分析错误进行对比分析,结果分别如表3和表4所示。

表3 英语依存关系标注错误分析

表4 汉语依存关系标注错误分析
由表3和表4可知,各分析器的误码呈现出一定的共性:句子结构的分析较之短语结构的分析错误更多;Stanford Parser 的错误数最少,且显著低于Mate Parser 和Malt Parser. 较之英语,汉语的句法分析错误明显增多,但错误的类型与英语分析结果具有一定的一致性。
首先,就短语结构的分析而言,英、汉语既有共性,也有差异。 对于修饰关系,名词性修饰关系(nmod)是两种语言中短语结构修饰关系分析错误最多的类型,其次是形容词修饰关系(amod)。其中,英语中导致大量名词性修饰关系分析错误的原因是分析器对“复合型”名词关系和“修饰性”名词关系的误判。 根据Quirk 等(1985:313,971),名词性的复合关系(compound)通常包含两个以上的基础成分,且二者具有同位性和并列性,而各类分析器对名词语义识解的困难造成同位性无法识别的问题。 汉语也存在类似情况,但多数误码是数量词词性赋码错误所致。 此外,汉语这类词汇组成方式与近年来汉语因“双音化”(王力1988:1 -3)所引起的典型“复合化”(compounding)现象有关,如两个语素“食”和“材”因削弱或丧失其间的词汇边界,成为一个语言单位,是汉语语法化和词汇化的典型现象(石毓智2002:1 -2)。 第二,对于功能型依存关系,各分析器对于名词短语“格”(case)关系存在一定程度的误判,且这类关系通常是无法判定介词的支配节点所致。 此外,汉语中还存在限定性修饰语和量词修饰关系的误判,多因分析工具无法准确识别指示型限定词与其所指名词或量词与其所指名词。
其次,在句子结构类关系中,英、汉语也呈现出一定的共性和差异。 就成分语法关系而言,句子的中心动词(root)、名词性主谓关系(nsubj)和状语修饰关系(advmod)依次是两种语言中出现错误较多的3 类依存关系,且错误数量远高于其它语法关系。 此外,汉语中直接宾语(dobj)的误码也呈现一定的显著性。 本文发现,绝大多数中心动词识解错误是句子中心动词词性赋码错误引起;名词性主谓关系的分析错误一般出现在复合句(compound sentence)或复杂句(complex sentence)中,这类错误通常也会导致中心动词的误判。 此外,中心动词的误判也会造成状语修饰关系的支配节点的误判。 在汉语中,直接宾语的误码一般在谓语动词与直接宾语跨小句时出现。 对于小句关系,英语中描写连接成分间(conj)和连接成分与连接词(cc)的依存关系误判情况最多,其次为状语从句(advcl) 和补语从句关系(comp),一定程度上是长句中状语从句中心动词的词性标注错误所致。 汉语中只有描写并列关系的错误居多,这是由于汉语倾向于使用流水句式,既出于修辞需要,也是一种表达习惯,用于叙述事件在时间或空间维度上的连续性,但小句间通常不存在显式的连接词,部分语句通过“,”分割各子句,因而句法分析过程中缺乏形式上的标记。
3.3 句法分析在跨语言实证研究中的适用性分析
已有研究对比考察汉语和英语在句子扩展手段上的差异(秦洪武周霞2019),从深层次解释英、汉语言语句长度和句子扩展手段背后的语法成因。 不同于原创汉语,在英汉翻译中,有可能受英语源语的影响,通过多种手段使得翻译汉语过多的接纳源语的语法资源,体现出区别于原创汉语和英语源语的语言特点(夏云秦洪武2017,秦洪武孔蕾2018, 蒋跃等2021)。 有鉴于此,本文对英汉翻译中英语源语与翻译汉语、翻译汉语和原创汉语的句法关系资源的运用进行对比分析,以此考察依存句法分析方法在跨语言、跨文体研究中的适用性和特征的显著性。 结果如表5所示。本文采取的对比框架均来自Stanford Universal Dependency,研究结论较上述研究更为可靠。
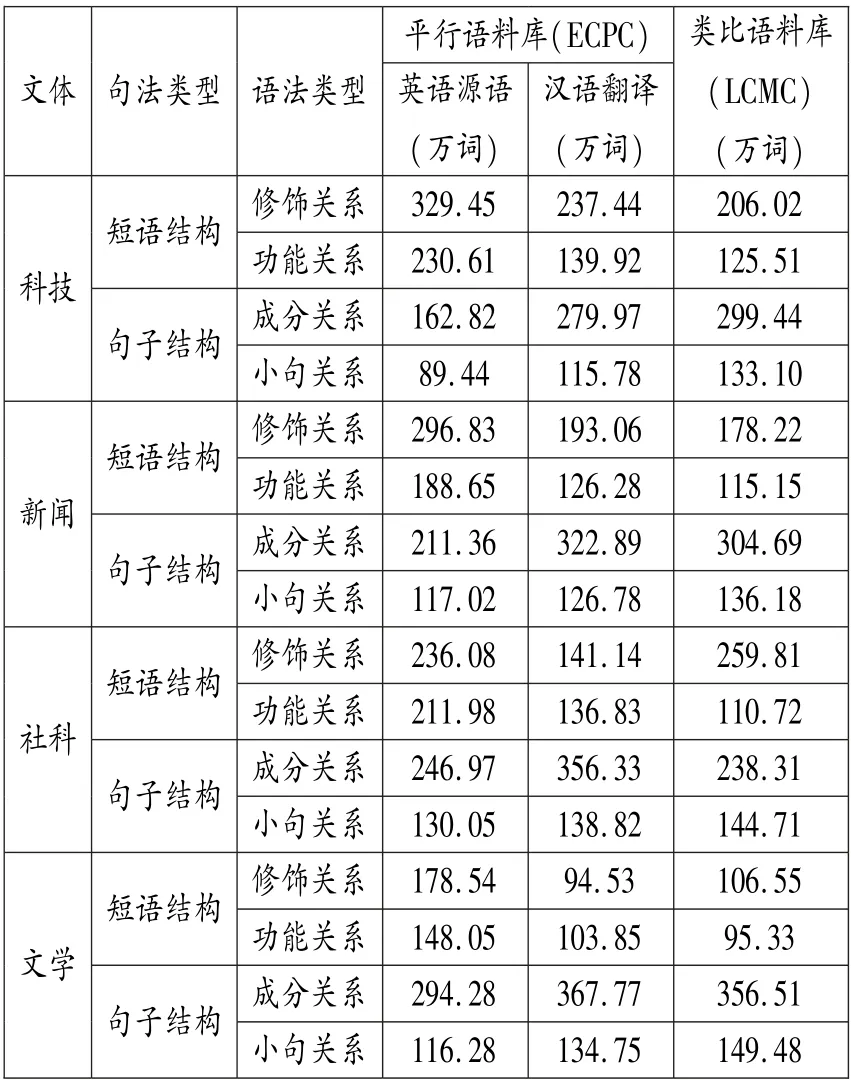
表5 英—汉翻译和汉语原创文本中依存关系的分布情况
表5 统计Stanford Core NLP 自动句法分析后的文本所使用的依存关系的分布情况。 从文体上看,无论是英语源语、汉语翻译还是作为类比的原创汉语,各文体中短语结构和句子结构的依存关系使用存在较大的差异。 对于英语源语,说明性较强的科技文体中,名词结构的修饰关系出现的频数最高,描述主谓结构的成分关系和复合型小句关系相对较少。 叙事性较强的文学文体则大量运用描述主谓结构的成分关系和小句关系,描写名词结构的修饰关系和功能关系则相对较少。 此外,社科和新闻文本兼具叙事和议论的特点,对于短语结构和句子结构的使用居中。 类比库中,各文体中描写句中成分关系的比重较高,这与汉语SVO 型语言密切相关。 此外,翻译汉语依存关系使用的分布呈现出独立于英语源语和汉语原创语言的特点,在句法关系上呈现出翻译汉语的特征。各文体中绝大多数语法关系类型的使用介于原创汉语和英语之间,可观察到翻译汉语中大量语法资源的异常使用,例如翻译汉语各文体功能性关系中的限定(det)关系数量远高于原创汉语,而限定(det)关系是英语源语的典型特征。
本文通过计算句子的平均依存距离来考察各文体中英语源语、翻译汉语和原创汉语在句法复杂度上的差异性。 依存距离指依存关系中支配节点和从属节点按照其在句子中出现的先后顺序所标记的位置的距离(Hudson 1995),依存距离可以测量人类理解或者产出语句的认知负荷,且依存距离越大,句子的复杂度越高。 本文分别对科技、新闻、社科和文学4 类文体的英语源语,汉语翻译和汉语原创语抽样文本中的句子平均依存距离进行分析,结果如表6所示。

表6 英—汉翻译和汉语原创文本句子的平均依存距离对比
首先,英、汉语言在平均依存距离上呈现出明显的差异性。 4 类文体中,汉语原创语言的平均依存距离均大于英语源语的平均依存距离,且句子依存距离的标准差均显著高于英语源语,呈现出句子平均依存距离的多样性。 此外,秦洪武和周霞(2019:435)也指出,汉语句段的扩展主要依赖修饰成分的前置,形成时间顺序上的铺排,进而导致汉语依存距离较英语短,主从关系少,流水句多,理解上的认知负荷偏小。
其次,翻译汉语在句子的平均依存距离上呈现出独立于英语源语和原创汉语的特征。 从文体分布上来看,汉语翻译中科技文体和文学文体的平均依存距离最小,社科最大,新闻居中,表现出与英语源语相类似的分布特征。 但从平均依存距离的大小来看,翻译汉语均高于英语源语,可能是受到汉语母语的影响。 此外,翻译汉语句子平均依存距离的标准差高于原创英语又低于原创汉语,处于二者之间。 通过对翻译汉语和原创汉语的对比分析,本文也发现除科技文体外,翻译汉语平均依存距离呈现出接近或略高于原创汉语的现象,这是由于英语可通过从属小句等句法关系将句中动词中心和名词中心的修饰成分后置,而汉语难以后置,只能通过修饰成分的大量前置来达到与英语同样的效果,进而造成翻译汉语依存距离的增加,是典型的翻译显化现象。 需要指出的是,对于说明性较强的科技文体,其平均句长较其它文体更长,在汉译时大量采用增加流水语句或拆分句子的译法,导致其平均句长降低,是翻译的简化现象。
综上所述,无论是语法资源的运用还是句子的复杂度的考察,翻译汉语较之原创语言或源语言均呈现出其独立的特征,且均可通过依存句法的分析来反映较为显著的特点。 因而如果将自动句法分析的结果运用于语言研究,不仅可反应语料库中文本的语法资源的分布情况,亦可反映句法复杂度特征,因而在实证研究中,具有较为广泛的适用性。
4 结束语
对语料库进行句法标注,可进一步提升语料库的使用价值,有助于开展更深层次的语言研究。语料库句法分析工具的信度不仅决定语料库建库的质量,也对以此开展的实证研究具有重要的影响。 信度的考察依赖于对特定理论的完整性、研究单位的可界定性、数据分析的准确性、研究的适用性和所观察现象与研究目标关系的显著性的研究(Artstein, Poesio 2008)。 刘鼎甲、 王克非(2018)的研究已对前两者做过讨论,本研究旨在对当前句法分析方法和工具的准确性进行实证分析,考察句法分析方法在跨语言、跨文体研究中的适用性和特征的显著性,以期对自动句法分析方法在实证语言研究中的信度做初步探索。 本文认为,使用自动分析工具进行句法分析的准确性已可满足各类实证研究的需求,但应对所分析的语言、文体和句子的长度有针对性的控制,以获得更为可信的结果。 此外,选择基于深度学习和人工神经网络的Stanford Parser 分析准确性最好,较之Mate Parser 和Malt Parser 可大大提升研究的精准性。 最后,本文认为,使用自动句法分析工具开展实证研究已可满足基本的需求,且自动分析的结果无论是在语法资源运用的考察,还是句子复杂度的考察,均呈现出可区分性的特征,因而具有较高的适用性。 需要指出的是,如果使用自动分析工具进行面向语料库研制的句法加工,其精度仍有相当程度的欠缺。 为保证语料库的可用性,应根据本文所发现的典型错误类型辅以有针对性的人工校对。
