基于机器学习的中耕期甘蔗幼苗识别定位*
2021-12-06李威李尚平潘家枫李凯华闫昱晓
李威,李尚平,潘家枫,李凯华,闫昱晓
(1.广西民族大学人工智能学院,南宁市,530006;2.广西大学机械工程学院,南宁市,530004)
0 引言
甘蔗作为我国热带及亚热带地区重要的糖料作物和经济作物,种植面积占常年糖料种植面积85%以上,产糖量占食糖总量的90%以上[1],而广西是我国最主要的甘蔗种植基地[2]。由于甘蔗前期种植管理作业季节短、自动化程度低,所以近年来国内研制的甘蔗中耕培土机械仍采用机械调整模式,中耕培土作业以人工操作为主、作业质量不稳定且效率较低。甘蔗是热带、亚热带的高秆作物,受到自然环境的影响,易出现倒伏现象,因此培土过程是甘蔗前期种植中最重要的工序之一,可以促进甘蔗根部的分蘖和生长从而防止倒伏,因不培土或培土不到位造成两侧垄出现“火山口”现象,导致甘蔗基部形成凹面,稳定性较差。同时倒伏现象对甘蔗机械化收割不利,易造成破头率增加,影响甘蔗宿根发芽,增加甘蔗的含杂率,造成蔗农的损失并降低糖厂的抽出率[3]。培土量的不适宜是培土过程中面临的难题,当供土量过多,培土高度过高会导致蔗苗被压倒,反之又会造成培土起不到相应的作用而引起倒伏。因此中耕培土的“火山口”现象问题成为制约甘蔗生产的主要因素之一,急需解决。
由于目前改进甘蔗中耕培土机的方式仍然采用传统的机械改良方法,对于中耕培土机智能化的应用还很缺乏。中耕培土机按照开沟培土工作部件划分,主要有犁铲式、螺旋式和圆盘式等结构[4]。如3ZSP-2型甘蔗中耕施肥培土机[5],在机架与培土犁的位置安装调节装置,通过调整培土犁的深浅来控制培土高度和培土行距,在培土犁上安装对应的调整螺栓,通过调整培土犁从而改变培土后垄的宽度。吕美巧等[6]研究设计圆盘式V型深沟起垄开沟刀,运动的轮轴输入动力,由十字万向节传动来带动圆盘刀座旋转,开出V型沟渠,偏置斜转刀盘能有效提高抛土刀的线速度及翻土、碎土、抛土的能力,在径向上增加了开沟深度。陈晓[7]研制的3ZP-0.8型甘蔗中耕培土机,采用正反转可调的旋耕滚刀装置,可正反转复式作业,具有良好的松土、碎土性能和拌合能力。虽然通过以上机械改良,中耕培土的作业质量和作业效率得到了显著地进步,但仍未能有效解决“火山口”的问题,同时甘蔗中耕培土机功能单一、机械种类繁多导致各个机型适应性不同,难以一机多用[8]。而我国甘蔗种植行距一般为0.7~1 m,广西部分地区会达到1.2~1.8 m,甘蔗种植行距的差异成为制约甘蔗机械化收获产量提高的主要因素之一[9]。因此中耕培土的幅宽应根据实际的甘蔗种植行间距确定,耕幅过宽会伤害到甘蔗幼苗及蔗根,过窄则会出现漏耕的情况。
在机器学习中,卷积神经网络[10-12]是一种前馈人工神经网络,已经广泛用于数据处理、图像类文本的识别[13]和医学图像[14-15]以及视频类数据识别[16]中,结合实际生活,例如道路探测[17]、天气预测[18]、人脸识别[19-20]和口罩佩戴检测[21]等,卷积神经网络的识别和分类功能都发挥了极大的作用。目前在农业领域,卷积神经网络广泛应用于农作物的病虫害识别[22]、定位识别[23]、果实识别[24]等,为卷积神经网络对中耕期甘蔗幼苗特征的识别提供参考。
本文提出一种基于机器学习的中耕期甘蔗幼苗识别定位和坐标分类计算方法,首先采用YOLOv4卷积神经网络建立中耕期甘蔗幼苗识别网络模型,对甘蔗的根部与土壤接触的局部区域进行识别定位和坐标获取,利用支持向量机将网络模型识别获取的坐标分类成两组数据,对应左右两垄的甘蔗植株,然后分别对每组坐标进行计算处理,实时得到两垄的倾斜值,最后通过倾斜值调整后犁及挡土板等设备,改变供土方向和供土量,从而提高培土的智能化、机械化,进一步解决由于甘蔗种植垄距的多变性引起的甘蔗培土的质量问题和机器种类复杂化产生的适应性问题,从而提高中耕培土的作业质量、作业效率,促进甘蔗生产的增产增收。
1 甘蔗智能中耕培土机的整机结构与工作原理
本课题组设计的甘蔗智能中耕培土机的主要结构如图1所示,由整垄辊、施肥装置、机架、控土组件、旋耕组件和培土装置六个部位组成。该甘蔗智能中耕培土机作业时的行驶速度为0.8~1.2 km/h,控土组件提前翻扣杂草残茬,发动机的动力通过变速齿轮箱传动到旋耕组件齿轮箱,带动左右旋耕刀转动,打碎泥土和杂草残渣,在培土装置的作用下,碎土向两侧抛撒到甘蔗的根部,整垄辊负责压实根部的碎土,同时肥料通过施肥装置排入两侧并被抛出的泥土覆盖,从而完成对甘蔗的施肥中耕培土作业。

图1 甘蔗智能中耕培土机结构图Fig.1 Structure diagram of the sugarcane intelligent field tillage machine1.培土装置 2.整垄辊 3.施肥装置 4.机架 5.控土组件 6.旋耕组件
根据中耕期甘蔗幼苗的培土需求,需要在较大范围的种植区域对左右两垄的甘蔗植株进行快速识别定位并计算垄中心位置的偏移程度,以便于及时对后犁等相关部件控制调整。
2 中耕期甘蔗幼苗识别模型
2.1 YOLOv4目标检测算法
YOLO[25]将对象检测框架作为回归问题,通过单个神经网络预测包围盒和类概率,实现直接对检测性能进行端到端的优化,完成对物体位置和类别的检测识别。相对于先产生候选区域再检测物体的策略,YOLO把候选区阶段和检测阶段合为一体,在实现快速识别目标的情况下仍然维持了较高的识别精度,从而可以满足动态检测多目标且较为复杂的中耕培土场景下完成对目标的识别。
YOLOv4[26]是Alexey Bochkovskiy等于2020年提出的基于YOLOv3[27]改进的目标识别定位算法,YOLOv4相对于YOLOv3增加了许多小技巧,比如Mosaic数据增强、学习率余弦退火衰减等策略丰富数据集、减少GPU并完善了训练过程,YOLOv4虽然增加了网络的复杂度,但仍然维持与YOLOv3相同的每秒帧数传输个数。
检测过程:首先通过K×K个网格对输入图像进行划分,每个网格生成M个边界框,共计K×K×M个边界框,然后含有目标的网格需要对图片中的目标预测概率值、位置和置信度,所以这个网格的输出值为M个边界框的坐标、宽高、目标的置信度和预测概率值即共计N×(4+1+1)个值。YOLOv4的网络结构其主干特征提取网络为CSPDarkNet53网络,CSPnet网络结构是构建主干特征提取网络的核心,它将残差块的堆叠进行拆分,其中一部分作为主干部分进行残差块堆叠,另一部分作为一个大的残差边,将基础层的特征映射经过少量处理直接与主干部分进行特征矩阵相加,在减少计算量的同时保证准确率。

图2 网络模型结构图Fig.2 Network model structure diagram
在主干网络输出层前添加SPP模块等作为neck部分可以极大增加感受野,对主干特征提取网络生成的最底层有效特征层进行3次卷积后,分别利用4个不同尺度的最大池化核进行最大池化处理,然后对池化处理后的4个特征层进行拼接,采用特征金字塔网络对SPP模块处理后的特征层和主干特征提取网络生成的其他两个有效特征层进行反复上采样和下采样操作,实现特征的反复提取和融合。输出层的锚框机制和YOLOv3相同,应用在网络中的不同尺度特征图。
2.2 改进的YOLOv4中耕期甘蔗幼苗识别模型
YOLOv4的损失函数由检测回归损失,置信度损失,分类损失三部分组成,其中置信度损失和分类损失采用交叉熵函数计算。本文的网络模型通过不同尺度的边界框和特征图计算损失函数,用于检测大小不同的中耕期甘蔗幼苗,目标损失函数如式(1)所示。
Loss=LCiou+LConf+LCla

(1)
式中:LCiou——检测回归损失;
LConf——置信度损失;
LCla——分类损失;
Iou——候选框覆盖范围与标记框覆盖范围的交并比;
d——预测框、真实框中心点欧氏距离;
c——预测框、真实框最小包络框的对角线距离;
α、λnoobj——权重系数;
v——衡量长宽比一致性的参数;
K——划分的网格数;


Ci——第i个网格中存在甘蔗植株的预测置信度;

g——类别;
pi(g)——第i个网格中某个类别的样本概率;

其中α、v计算公式分别如式(2)、式(3)所示。
(2)
(3)
式中:wgt、hgt——真实框的宽、高;
w、h——预测框的宽、高。
根据实际需要,对中耕期甘蔗幼苗的识别检测为二分类任务,只有正例与负例,且二者的概率和为1,所以针对分类损失函数进行简化,如式(4)所示。

(4)
式中:pi(o)——第i个网格中为甘蔗植株的样本概率;
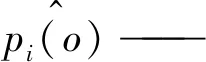
3 中耕期甘蔗幼苗识别试验
3.1 目标特征分析
本次研究对象为广西大学扶绥亚热带农牧产业协同创新基地的新植蔗株如图3所示。

图3 创新基地新植蔗株Fig.3 New sugarcane plants in the innovation base
中耕期甘蔗幼苗主要由根、茎、叶三部分组成,植株高度为40~50 cm,种植行距为1.2~1.4 m,需培土厚度为8~13 cm。虽然甘蔗的表面特征与土壤颜色具有明显差异性,但是其几何形状具有一定不规则性,因此在经过多次标定试验后,选取甘蔗根部与土壤接触的局部位置作为特征标记和特征识别区域。
3.2 图像采集与数据预处理
针对处于中耕期的甘蔗幼苗进行图片采集,采样方式为将摄像头摆放在拖拉机距离地面约90 cm的高度,沿着中耕培土机的行驶路径进行视频录制,视频分辨率为1 920像素×1 080像素,帧速率为120 fps,介于地形地貌的差异性,本次素材的采集在多个不同的甘蔗种植区域进行,每块区域的录制时长约60 s,共计约300 s。使用Adobe Premiere软件对录制的视频按帧截取图片并保存,筛选出450张图片通过Labelimg可视化图片标注工具对目标进行标记,将目标添加同一类标签并生成标记文件,按比例生成模型训练所需的训练集、验证集与测试集,其中250张作为训练集,50张作为验证集,150张作为测试集。训练集、验证集和数据集图片分辨率为416像素×416像素。
3.3 试验平台
本次试验的操作系统为Windows 10,处理器为AMD Ryzen5 3600 6-Core Processor,主频为3.60 GHz,动态加速频率可达4.20 GHz,显卡采用NVIDIA GeForce RTX 2070s,使用CUDA Toolkit和Cudnn神经加速器进行加速训练。在Spyder上使用python编程语言编写程序并调用Pytorch等框架,训练参数设置如下,批处理个数为6,学习率设置为0.001,选择Step模式更新学习率。
3.4 评价指标
在目标检测领域中,对于检测效果可以通过准确率P,召回率R和P-R曲线下的面积AP,即平均准确率进行评估。具体计算如式(5)~式(7)所示。
(5)
(6)

(7)
式中:TP——被正确分类的正样本,即预测框和真实框之间的置信度大于规定阈值的样本;
FP——被分配为正样本的负样本,即预测框和真实框的置信度小于规定的阈值的样本;
FP——被分配为负样本的正样本;
N——测试集中所有图片的个数。
4 蔗垄定位的试验数据处理
根据甘蔗中耕培土的实际需求,为了能够判断中耕培土机左右两垄甘蔗植株的总体排列方向以及两垄中心位置的偏移程度,通过YOLOv4网络模型对甘蔗植株进行预测,获取目标预测框下端边界的中间点坐标作为一株甘蔗植株的坐标信息。为了对两垄甘蔗植株坐标数据分别计算处理,先利用支持向量机将坐标根据垄的类别进行分类,共分成两组坐标数据,分别对应左、右两垄甘蔗植株的位置,再计算出左右两垄的倾斜值并传递给后续设备,为甘蔗中耕培土机解决“火山口”问题做出前期工作。
4.1 坐标分类
在机器学习领域,SVM(Support Vector Machine),即支持向量机,是一个有监督的学习模型,通常用来进行分类以及回归分析。原理是通过内积函数定义的非线性变换将输入空间变换到一个高维空间,然后在这个空间中求最优分类面[28]。SVM的分类性能受到诸多因素影响,其中两个因素较为关键[29]:(1)误差惩罚参数C;(2)核函数形式及其参数。
本次从YOLOv4网络模型预测的坐标数据中筛选出100组用于分类试验,其中训练集60组,测试集40组。分类试验选择线性核函数,设置误差惩罚参数从10到100,对训练集和测试集的准确率进行统计,结果如图4所示。最终当误差惩罚参数C为11~13时,训练集准确率达到95.6%,测试集准确率达到92.60%,此时效果最佳。误差惩罚参数为80以后出现过拟合现象,准确率明显降低。
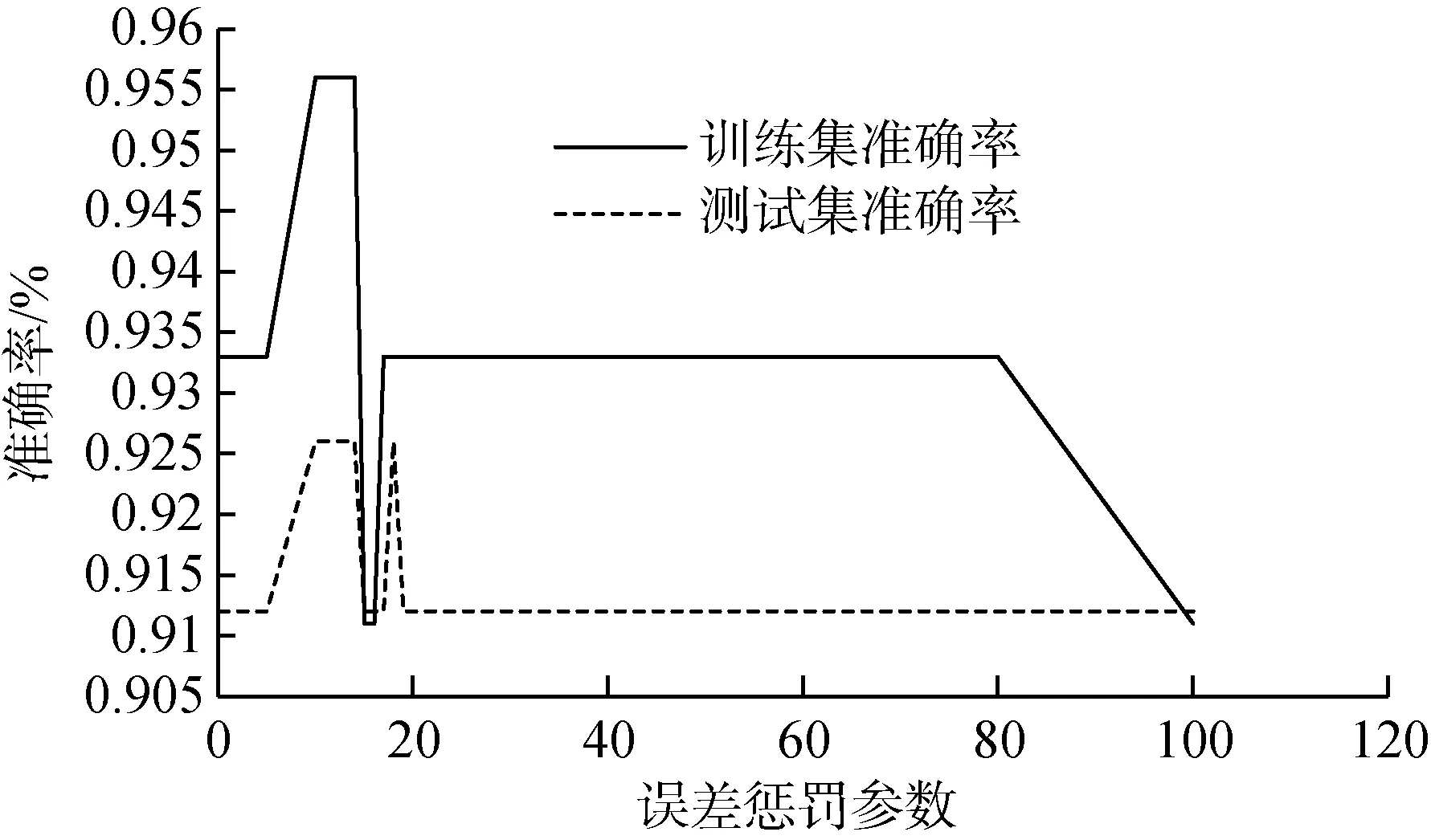
图4 误差惩罚参数对准确率的影响Fig.4 Influence of error penalty parameters on accuracy
4.2 垄距定位的数据计算
由于预测框的预测顺序与甘蔗植株的实际排列顺序具有差异性,并且可能存在偏差较大的预测坐标,例如获取了被误识别为目标的其他区域的坐标,所以读取分类后的左右两垄坐标数据,对每组数据分别按以下步骤进行计算斜率。
1)分别以第1,2,3…m株甘蔗植株与土壤接触点的坐标为基准,计算该坐标与其他坐标斜率的绝对值如式(8)所示,共得到m组斜率数据,每组数据舍弃最大值和最小值,计算余下斜率的平均值,得到斜率的平均值k1,k2,k3…km。
(8)
式中:ki——斜率;
m——基准坐标的个数;
xi、xj——第i、j株的横坐标;
yi、yj——第i、j株的纵坐标。
2)计算k1,k2,k3…km的标准差S,若S>1,则说明k1,k2,k3…km的离散程度较大,所以以中值M作为最终倾斜值;若0≤S≤1,则取平均值Ka为最终倾斜值,如式(9)所示。
(9)
式中:L——倾斜值;
M——斜率的中值;
S——斜率的标准差;
Ka——平均斜率。
其中S和Ka的计算公式如式(10)、式(11)所示。
(10)
(11)
5 试验结果分析
5.1 识别模型性能分析
将处理后的数据集输入网络中进行迭代训练,训练完成后,使用可视化工具读取最新的Pytorch日志文件,呈现当前程序运行的最新状态,得到训练集损失函数下降曲线如图5所示,从图中曲线可以得出,当模型在经过少量迭代次数训练时,训练损失快速下降,在经过500次迭代后,训练损失下降放缓,1 000次迭代后,训练损失值稳定在50左右,说明已经出现过拟合现象。当损失值取得最小值时,以此时的权值文件作为网络最终的训练结果即最优权值文件,然后在YOLOv4网络模型中加载最优权值文件对测试集图片进行识别测试,结合本次识别目标,使用TP表示正确检测到的甘蔗植株,FP表示检测到其他物体误判断为甘蔗植株,FN表示没有检测到的甘蔗植株。共测试3组图片,其中每组图片由测试集中随机选取的100张图片组成,图片包含不同光线下的目标。置信度阈值设置为0.5时,3组模型性能试验平均值结果:TP为1 096,FP为217,FN为196,准确率为83.47%,召回率为84.83%,每幅图片平均识别时间为0.21 s。
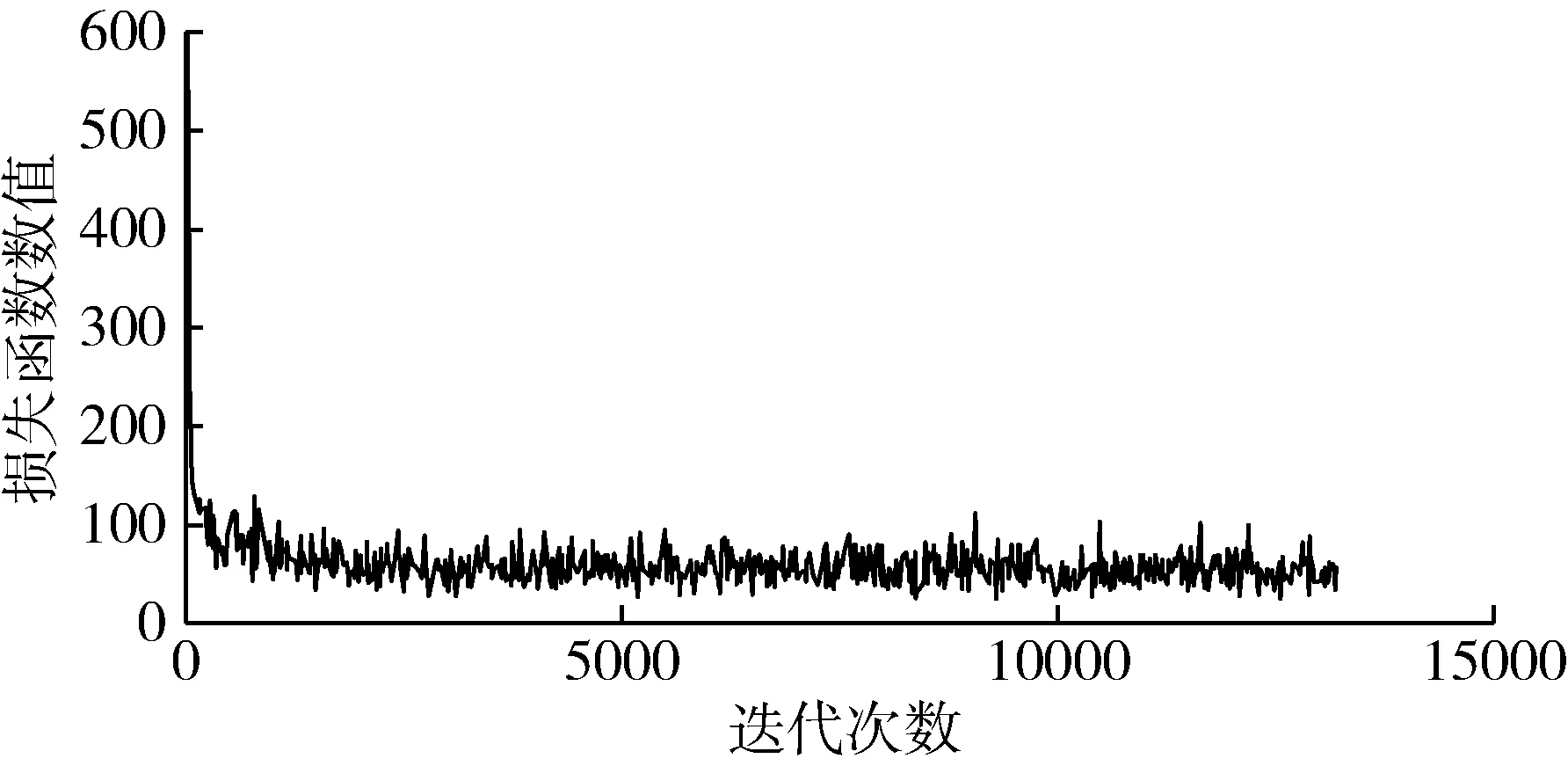
图5 中耕期甘蔗幼苗识别损失函数曲线Fig.5 Recognition loss function curve of sugarcane seedlings in intertillage period
5.2 识别试验测试结果分析
对3组测试集进行试验后,结果如图6(a)所示,测试图片中灰色矩形框内为网络模型标记的甘蔗植株的位置,白色矩形框内为甘蔗植株由于分蘖产生的多个标记结果重叠的区域或偏移程度较大的目标,白色斜线的矩形框内为网络模型预测错误的甘蔗植株的位置。

(a)模型测试结果
在实际甘蔗中耕培土过程的应用中,拍摄设备实时拍摄出图像后,运用识别网络模型对中耕培土机左右两垄中耕期甘蔗幼苗进行识别定位和坐标获取,根据实际需要,调整置信度阈值以减少其他区域被误识别的现象,从而提高识别准确率P。根据多次测试,阈值设置为0.7时,虽然识别出的甘蔗植株数量由1 096减少至763,召回率由84.43%下降至59.06%,但准确率由83.47%提升到95.50%,此时所采集的样本图片的平均识别株数为18,每幅图片平均识别时间为0.20 s,在保证了有足够目标坐标数据的前提下,减少了数据分类以及计算处理的工作量,提升了处理效率和数据计算的准确率,结果如图6(b)所示。置信度阈值调整前后的评估数据对比如表1所示。

表1 置信度阈值调整前后评估数据对比Tab.1 Comparison of evaluation data before and after the confidence threshold adjustment
5.3 蔗垄的定位试验结果分析
将识别网络模型获取的甘蔗植株的坐标数据输入分类模型中进行分类,每幅图像中数据的平均分类时间约为2 ms,完成分类后的部分坐标如表2所示。左侧垄的甘蔗植株坐标顺序对应样本图片中左侧垄的左下方至右上方的顺序,横坐标逐渐增加,纵坐标逐渐降低;右侧垄的甘蔗植株坐标顺序对应样本图片中右侧垄的左上方至右下方的顺序,横坐标逐渐增加,纵坐标也逐渐增加。经过垄距定位的数据计算,左侧垄的倾斜值为1.27,右侧垄的倾斜值为0.92。对多张样本图片重复进行识别试验与蔗垄的定位试验,最终获得倾斜值的范围为0.7~1.4,将倾斜值输入后续设备,设备根据倾斜值的大小进行调整从而改变供土方向和供土量。

表2 分类后的部分坐标Tab.2 Part of the coordinates after classification
6 结论
本文提出了基于机器学习的中耕期甘蔗幼苗识别定位和坐标分类计算方法,结合甘蔗中耕培土问题的实际需要,针对甘蔗中耕培土机左右两垄甘蔗植株存在培土不到位的情况,即“火山口”现象,通过YOLOv4网络建立识别网络模型,调整YOLOv4预测网络的置信度阈值对中耕期甘蔗幼苗根部和土壤接触的局部区域进行识别定位和坐标获取,然后运用支持向量机将坐标数据根据左右两垄分成两组,并分别对每组坐标数据进行计算处理,实时得到两组坐标数据的倾斜量,后续设备根据倾斜量的数值大小进行调整,以改变供土量和供土方向。
1)通过试验测试表明,基于YOLOv4网络模型的中耕期甘蔗幼苗识别模型对每幅测试图片的平均识别时间满足甘蔗智能中耕培土机作业时0.8~1.2 km/h的行驶速度,YOLOv4目标检测算法可以应用于实际的甘蔗中耕培土过程中,实现中耕期甘蔗幼苗快速准确的识别和定位。当根据需求调整YOLOv4预测网络的置信度阈值为0.7时,准确率可达到95.50%,所采集的样本图片的平均识别株数约为18,平均识别时间约为0.20 s,在保证有足够甘蔗植株坐标信息的前提下,减少了数据分类以及计算的工作量,提升了处理效率和数据计算的准确率。
2)经过分类测试试验,基于支持向量机对YOLOv4网络模型识别获取的坐标数据分类准确率为92.60%,每幅图像中数据的平均分类时间约为2 ms,表明可以快速准确地对中耕期甘蔗幼苗的坐标信息进行分类,满足判断实际空间分布的计算需要。
3)经过对每组坐标数据的计算处理,倾斜值的范围为0.7~1.4,根据识别、计算获得的斜率值参数,对后犁、挡泥板等部件进行实时调整,改变供土方向和供土量,为开发智能甘蔗中耕培土机、解决甘蔗中耕的“火山口”问题提供理论与技术基础。
