基于工作流的统计年鉴数据清洗模型构建
2021-12-03李丹丹张玉尧郑国清
张 辉,魏 东,乔 璐,李丹丹,张玉尧,郑国清,冯 晓
(1. 河南省农业科学院农业经济与信息研究所,河南郑州 450002;2. 河南省智慧农业工程技术研究中心,河南郑州 450002)
随着大数据时代的到来,数据清洗逐渐成为各行各业数据治理中面临的重要工作[1‑4]。统计年鉴是我国重要的基础性数据资源,涉及众多行业和领域,具有权威性和广泛性。农业领域宏观决策及科学研究往往需要大量多种类统计年鉴数据作为支撑[5‑8]。然而,各种类统计年鉴分年度独立成册,经多年积累,具有体量大、文件格式多样、指标名称不一致等特征,提取跨年鉴、跨年度、多指标数据工作量大且繁琐,严重阻碍了统计年鉴的分析利用效率。目前,运用大数据理念实现统计年鉴传统功能的突破和拓展已成为年鉴工作者的共识[9‑10],数据清洗在其中扮演了关键角色。将分散的多年、多种类统计年鉴数据清洗整合成1 套高标准规范数据集,以实现综合快速查询,对于提升统计年鉴分析利用效率具有重要作用。
国内外很多学者对结构化数据清洗技术开展了研究,郝爽等[11]深入总结了数据缺失、数据冗余、数据冲突、数据错误等数据噪音的检测及消除技术研究进展,已有研究成果表明,统计年鉴数据清洗已具备技术基础。但是,统计年鉴数据的清洗涉及多类数据噪音的检测及消除,并需经过一系列数据抽取、转换、比对,过程繁杂。采用流程化集成清洗是完成过程繁杂清洗任务的有效手段。工作流建模技术是实现业务流程优化和整合,提高工作效率的核心技术[12],在网络安全漏洞管理[13]、建筑市场监管[14]、工业设计过程管理[15]、ERP 实施流程和业务管理[16]等众多领域得到了成功应用。武小平等[17]使用JavaEE 的分层模式和组件技术构建了一个基于工作流程的通用、可扩展的数据清洗系统,但该系统通过编程实现,技术门槛高。近年来,OpenRefine、Trifacta Wrangler、DataKleenr、Alteryx、KNIME、Rapid Miner、Weka 等非编程式可视化数据清洗、挖掘软件的出现,使得不懂编程的业务人员零代码完成数据清洗成为可能。其中,OpenRefine、Trifacta Wrangler、DataKleenr 功能较为单一,完成复杂的数据清洗任务需联合多个软件;Alteryx、KNIME、Rapid Miner、Weka 为综合型数据自助分析平台,可完成数据清洗、挖掘、分析、可视化展示等全过程[18‑19]。基于以上分析,提出采用Alteryx 建立基于工作流的数据清洗模型的方案清洗统计年鉴数据。
《中国统计年鉴》及《河南统计年鉴》等全国31个省(市、区)统计年鉴是我国最全面、最具权威性的综合统计年鉴,全面反映全国及各省(市、区)经济和社会发展情况,被农业领域研究人员广泛引用。鉴于此,以2000—2018 年上述统计年鉴为例,研究基于工作流的统计年鉴数据清洗模型构建方法,以期实现统计年鉴数据的高效整合,并为其他各类复杂数值类型结构化数据的清洗提供参考。
1 材料和方法
1.1 数据来源及预处理
通过统计局官网下载、购买等方式收集2000—2018 年《中国统计年鉴》及《河南统计年鉴》等全国31 个省(市、区)统计年鉴。年鉴数据整体情况如下:(1)数据体量大。包含33 万个文件、120 万张表单,总容量达21 GB。(2)数据更新速度快。每年新增6 万多张表单。(3)数据格式多样。包含html、xml、xls、xlsx、pdf 等多种格式。(4)文件呈现形式不确定。每个文件包含单张或多张表单,每张表单也可能由单张或多张表组成,例如从河南省统计局官网下载《河南统计年鉴(2017)》中“表7-13 河南与国外结成友好城市一览表”得到的“0713.xls”文件中包含了1 张表单“Sheet1”,“Sheet1”由左右排列的2张表组成。为便于清洗,采用开源的第三方工具DocToText 和基于Visual Basic 的脚本语言(Microsoft Visual Basic Script Edition,VBS)编程的方式将统计年鉴原始文件批量转换成xlsx 格式,按省份和年度分类存放于统一目录。
1.2 数据特征分析
《中国统计年鉴》与各省(市、区)统计年鉴存在整体架构、统计口径及数据不一致等问题;不同省(市、区)统计年鉴,也存在内容设置、整体架构、统计专题、指标内容不一致等问题[20]。随着经济社会发展变化,同一年鉴不同年度部分统计指标也发生了变迁[21]。正确解读统计年鉴内容架构[22]、主体分类[23]、指标体系[24]等特征是做好统计年鉴数据清洗工作的前提。另外,统计年鉴还具有如下特征:指标数值有整数、科学计数、小数、分数、比值、字符等多种类型;不同年度、不同种类年鉴同一指标的计量单位可能存在不一致现象;指标在时间上包含年鉴年度、统计年度、指标期间、月份数据等各种类型;指标在空间上除按全国和各省、自治区、直辖市、市(县)分组外,还有按东、中、西部及东北地区分组,按京津冀及长江经济带分组等多种分组方式。经分析,统计年鉴数据可通过指标名称、计量单位、指标数值、时间特征、空间特征和数据来源6个维度来规范标识。
对单表数据进行统一规范化处理及提取是统计年鉴数据清洗的关键。统计年鉴典型单表如图1所示,依据图1 中的十字线可将单表拆分为4 个区域。左上部分为表指标区域,通常包含表名称、表年度、表单位、表计算方法、表空间;左下部分为行指标区域,通常包含行名称、行单位、行年度、行计算方法、行空间;右上部分为列指标区域,通常包含列名称、列单位、列年度、列计算方法、列空间。从以上3 个区域提取指标名称、计量单位及数据对应的时间和空间特征。右下部分为数值区域,提取指标数值。
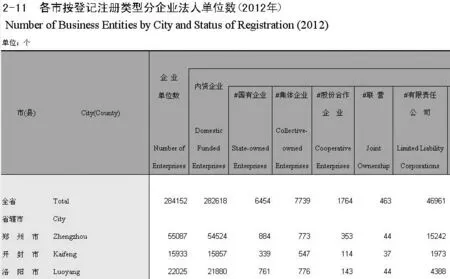
图1 《河南统计年鉴(2013)》典型单表示例Fig.1 Typical sigle table example in Henan Statistical Yearbook(2013)
指标名称提取较为复杂,通常涉及到行指标、列指标甚至表指标信息。如《中国统计年鉴(2017)》中“12—4 主要农业机械拥有量(年底数)”的指标名称来自行指标,并被拆分在多个单元格中;“20—18 按国际标准分类的发明和实用新型专利申请受理数与授权数”的指标名称需要将表指标、行指标和列指标组合后形成。同一指标名称在不同表中的提取方式也有所不同。如《中国统计年鉴(2017)》中“12—1 农业生产条件与农作物播种面积”和“12—4主要农业机械拥有量(年底数)”的“大中型拖拉机”“大中型拖拉机配套农具”等指标名称需分别在行指标和列指标中提取。不同年度年鉴中同一指标名称的表述也可能不一致。如《中国统计年鉴(2017)》中“1—2 国民经济和社会发展总量与速度指标”的指标名称“总人口(年末)”“城镇人口”“就业人员数”分别等同《中国统计年鉴(2001)》中“2—3 国民经济和社会发展总量与速度指标”的指标名称“年底总人口”“市镇人口”“从业人员数”。除上述情况外,还有其他特殊情况导致指标名称提取复杂。
1.3 数据清洗模型构建
在分析统计年鉴数据特征后,采用Alteryx Designer 2019.2 学习版,基于工作流技术构建统计年鉴数据清洗模型。Alteryx Designer 的基本工作原理是将数据处理过程工具化,将输入、转换、取样、模型、匹配、评估、验证、导出等数据清洗过程通过其内置工具或自定义宏采用流的方式关联起来,实现数据清洗全过程自动化。本研究构建的统计年鉴数据清洗模型如图2所示。模型包含提取目录及文件、提取文件中的表单、提取表单中表的内容、数据清洗及规范、规范标识数据的6个维度、数据重组和数据输出共7个步骤。
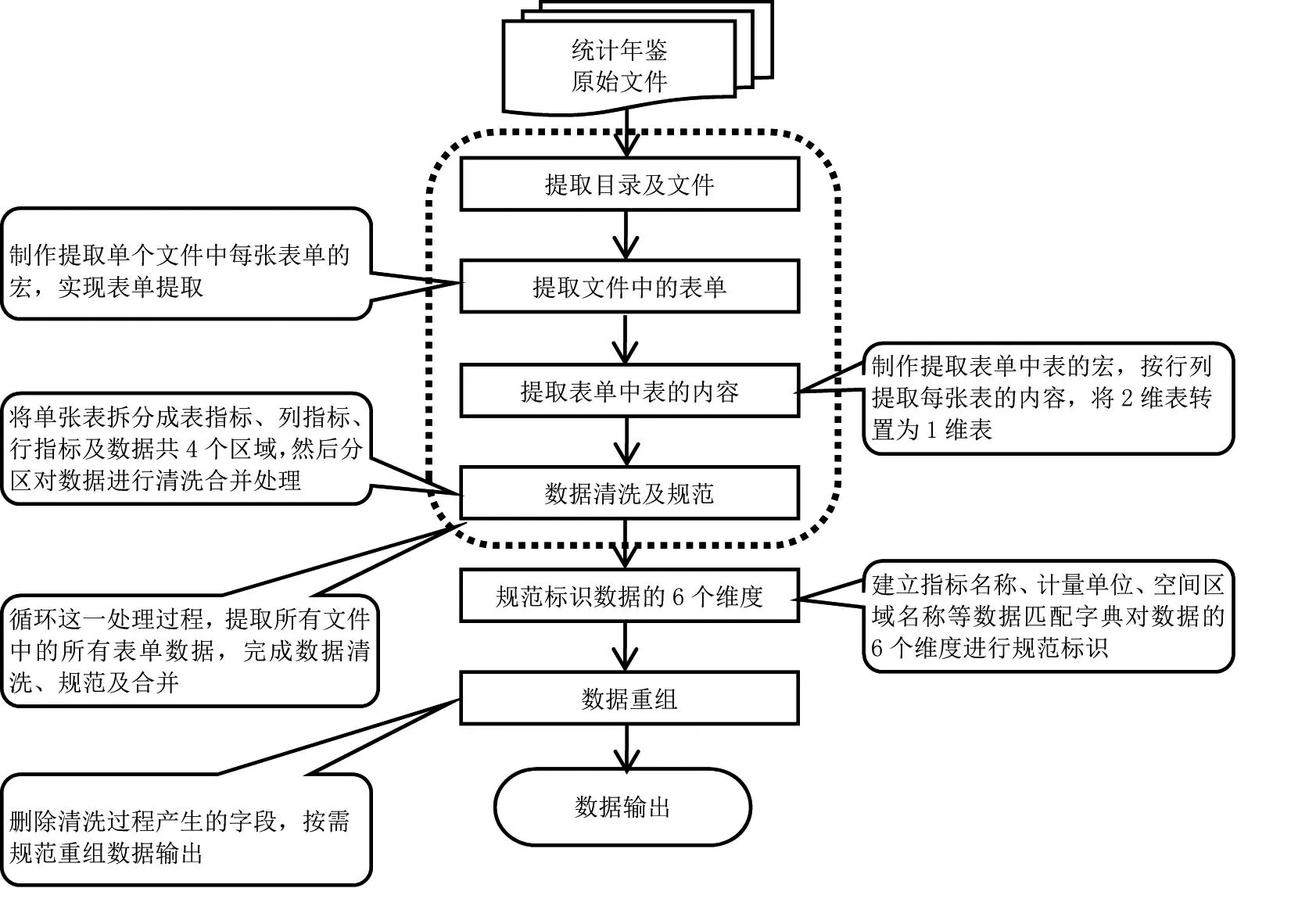
图2 统计年鉴数据清洗工作流模型Fig.2 Workflow model of statistical yearbook data cleaning
模型建立匹配数据字典对统计年鉴中指标名称、计量单位及空间区域表述等不一致问题进行了规范。为实现数据清洗全过程可追溯,模型所有中间步骤及最终清洗结果均记录了每条数据的文件及表单来源,所在表的行、列等原始信息,建模中可随时对各阶段清洗结果进行验证。为提高数据清洗效率,将提取目录及文件等重复流程制作成自定义宏,进行循环调用。
1.4 数据质量控制
1.4.1 重复指标数据处理 对于指标数值一致的重复数据删除重复即可,对于指标数值不一致的重复数据,取值规则为:(1)出版时间不同,取最新版年鉴的指标数值。(2)同期出版,取高级别年鉴的指标数值。(3)有修订说明,取修订后年鉴的指标数值。(4)重复多次,取出现次数最多的指标数值。(5)有多个不同指标数值,指标数值取中位数。
1.4.2 数据清洗质量验证 从以下3个方面对数据清洗质量进行验证:(1)模型构建过程中的随机验证。随机验证数据清洗阶段性成果的正确性及匹配数据字典设置的全面性,随时修改模型及完善匹配数据字典,及时避免错误发生。(2)最终清洗结果的单指标验证。在最终清洗结果中选择单个指标名称,从时间和空间2 个维度对统一计量单位后的指标数值进行时序比较验证。如指标数值序列通常随时间呈规律性变化,若某一指标数值某年度发生超出正常范围的突变,则追溯检查该指标数值出现质量问题的原因,从而修正完善模型。(3)最终清洗结果中关联关系指标的验证。如人均国民生产总值与国民生产总值和常住人口之间具有关联关系,当由国民生产总值和常住人口计算得到的人均国民生产总值与清洗提取的人均国民生产总值差距较大时,则需追溯检查这3 个指标数据出现偏差或错误的原因。
2 统计年鉴数据清洗模型构建关键技术实现及结果分析
2.1 单表数据分区拆分
单表数据分区拆分的关键是标识出数值区域,如图1中十字线右下角第1个数字(284 152)对应的单元格为数值区域的起始单元格,即表4 个区域拆分点所在单元格。单表分区拆分流程如图3 所示。首先,提取单表数据,新增2列用于标识表中每个单元格数据对应的行列序号。然后,取第1 个数值所在单元格作为初始拆分点进行拆分,定位数值区域每个单元格数值对应的行和列属性,将2 维矩阵表按行和列转置为1维表来表达每个数值与其对应行区域和列区域的关系(图4)。转置的同时,新增1列对单元格中的数值进行字符转数值再转字符操作,若新增列值与单元格中的数值相同,则此单元格中数值为有效数值,否则为非数值区域数据。另外,为区分行指标区域和列指标区域出现的数值为年度信息还是指标数值,还需判别整行及整列的数值是否全在1900—2020内,若是则标识该行或列为年度信息,否则标识为指标数值。最后,依据最终获取的数值区域的行最小值和列最小值所对应的单元格作为拆分点,将单表拆分为表指标、列指标、行指标、数值区域四部分。
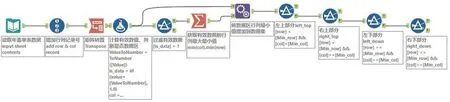
图3 单表分区拆分流程Fig.3 Partitioning process of single table
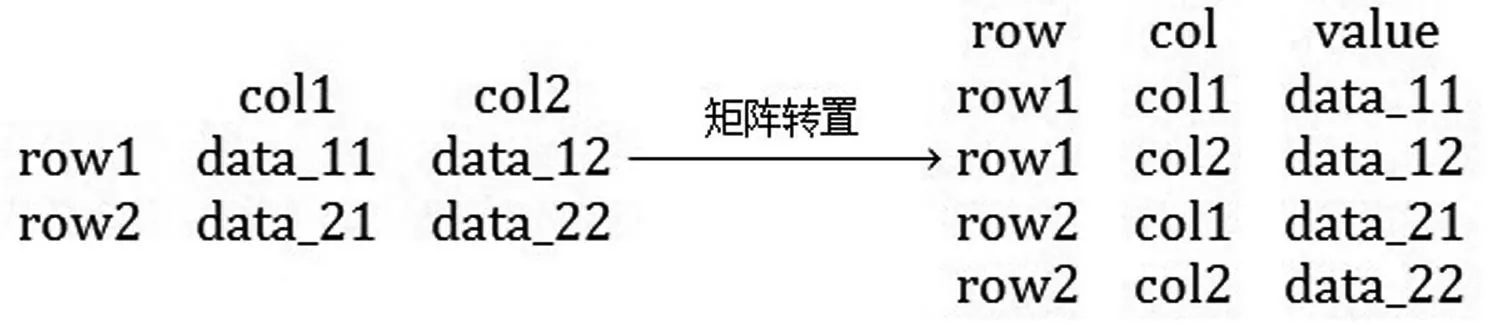
图4 单表数据矩阵转置Fig.4 Data matrix transposition of single table
2.2 单表数据分区提取
首先,提取表指标区域数据,提取流程如图5所示。使用正则表达式(表|d+-d+.*)提取“以数字开头+中文”或“表+数字+中文”的表名称信息为table_name 列,表名称中通常含有指标名称、指标年度、指标所属区域等信息。使用正则表达式(19|20d{2})提取年度信息为table_year 列;使用正则表达式((?<=单位:).*)提取计量单位信息为table_unit列。

图5 单表表指标区域数据提取流程Fig.5 Table indicator regional data extraction process of single table
其次,提取行、列指标区域数据。以列指标区域数据提取为例,因列指标信息通常分散于同一列的不同行单元格内,要先将同一列不同行的单元格数据进行合并,提取列名称信息为col_name 列;再用正则表达式提取列年度信息为col_year 列、列计量单位信息为col_unit 列,若无这些信息则输出空值null。类似,提取行名称信息row_name 列、行年度信息row_year列、行计量单位信息row_unit列。
最后,以文件名FileName 为关键列,对表指标区域、行指标区域和列指标区域数据进行交集处理。合并table_name、col_name 和row_name 列为con_name 列,合并table_year、col_year 和row_year 列为con_year 列,合并table_unit、col_unit 和row_unit列为con_unit 列。 再以con_name、con_year 和con_unit 列为关键列与数值区域进行交集运算,初步完成单表提取。图6为年鉴单表数据提取流程。
2.3 制作单表数据提取宏批量提取单表数据
鉴于单表数据提取方法基本一致,将单表数据提取流程制作成自定义宏,即可将所有类似单表通过循环调用宏的方式进行数据批量提取及合并输出。图7为年鉴单表数据提取宏的工作流程。为节约时间,可先随机提取33万个原始文件中的1%,利用制作的宏提取数据后追溯验证并修正宏,之后再进行所有单表数据的正式提取。图8为随机抽取文件循环调用宏批量提取单表数据的流程。
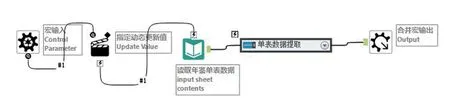
图7 单表数据提取宏Fig.7 Data extraction macro of single table
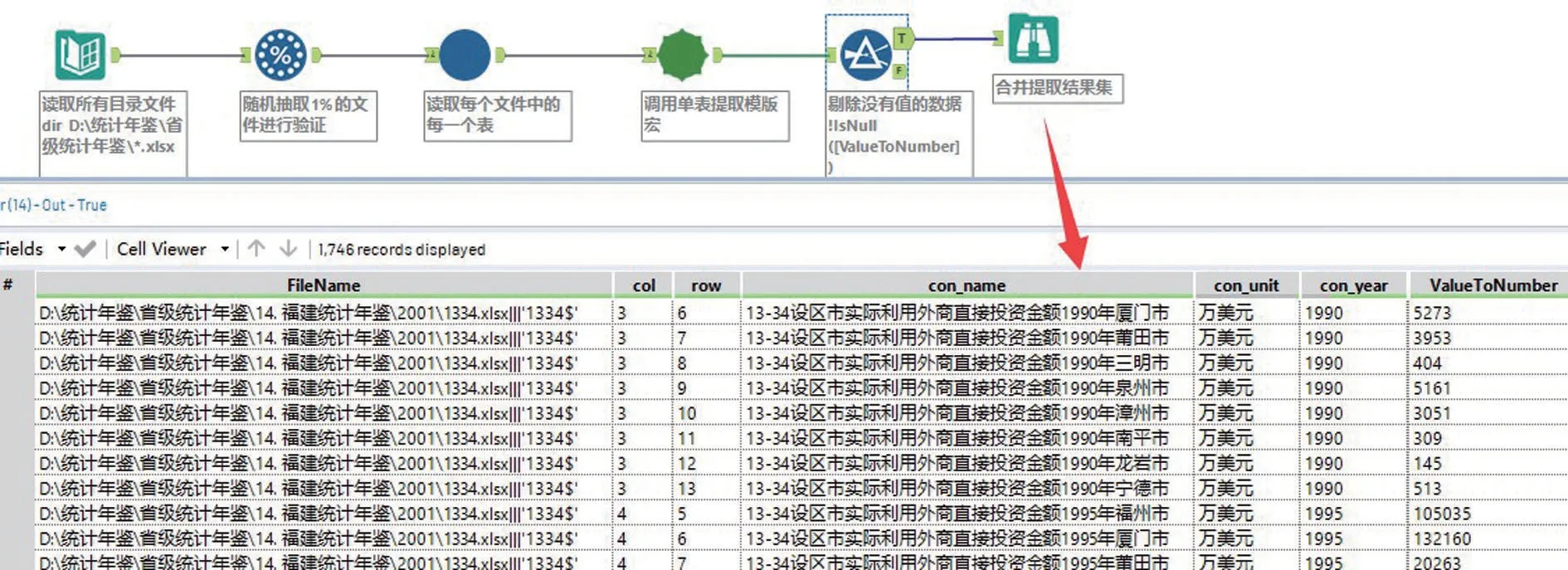
图8 随机抽取文件循环调用宏批量提取单表数据Fig.8 Randomly extracting file and recycling macro to extract data of single table
2.4 建立匹配数据字典规范标识数据
2.4.1 指标名称匹配数据字典 鉴于不同年度、不同年鉴统计指标名称表述上略有差别,建立指标名称匹配数据字典进行规范(表1)。如将国民生产总值、国内生产总值、GDP统一规范为国民生产总值。

表1 指标名称匹配数据字典(部分内容)Tab.1 Indicator name matching data dictionary(partial contents)
2.4.2 计量单位匹配数据字典 为统一指标计量单位,以基本计量单位作为清洗后的计量单位,按照计量单位与基本计量单位的换算系数,建立计量单位匹配数据字典进行规范(表2)。如某指标计量单位在某些年度为万元,而在另一些年度为亿元,将基本计量单位设置为元,则换算系数分别是10 000和100 000 000。

表2 计量单位匹配数据字典(部分内容)Tab.2 Measurement unit matching data dictionary(partial contents)
2.4.3 空间区域名称匹配数据字典 为统一年鉴空间区域名称,建立空间区域名称匹配数据字典进行规范(表3)。如将内蒙、内蒙古、内蒙古自治区、内蒙自治区、蒙统一规范为内蒙古自治区。

表3 空间区域名称匹配数据字典(部分内容)Tab.3 Spatial region name matching data dictionary(partial contents)
2.4.4 利用匹配数据字典规范标识数据 图9为利用匹配数据字典规范标识数据的流程。在用匹配数据字典对提取的原始数据进行匹配前,要先对数据进行预处理,其中,主要包括将所有全角字符转换为半角,去掉所有空格和非法字符(如换行符、回车符)等。
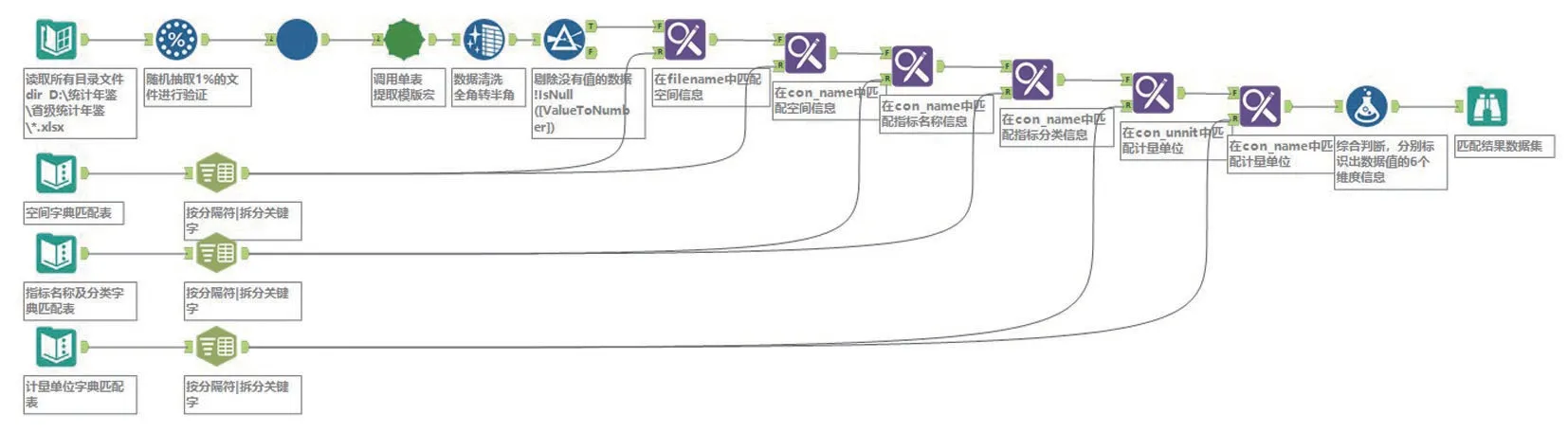
图9 利用匹配数据字典规范标识数据Fig.9 Identifying data by matching data dictionary
2.5 年鉴清洗结果
利用构建的数据清洗模型将本研究中分散获取的容量达21 GB、包含33 万个文件和120 万张表单的统计年鉴原始数据最终整合成1 套包含6 000多万条指标数据序列的高标准规范数据集。每条指标数据都清楚地由指标名称、计量单位、指标数值等6个维度标识,实现了不同年度、不同年鉴数据的综合快速查询。图10 为最终输出的统计年鉴数据清洗结果。采用Win10 操作系统,16 GB 内存的笔记本电脑,构建的基于工作流的统计年鉴数据清洗模型,用时4~5 h 即完成本研究中统计年鉴数据清洗任务,高效便捷。
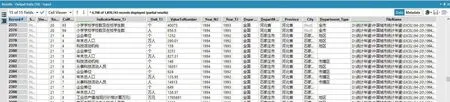
图10 统计年鉴数据最终清洗结果Fig.10 Final cleaning results of statistical yearbook data
3 结论与讨论
目前,对多年度、多种类统计年鉴数据清洗的研究较少。本研究采用Alteryx Designer 2019.2 学习版,以拖拽控件到面板并设置控件属性的可视化操作方式构建了基于工作流的统计年鉴数据清洗模型,实现了2000—2018 年《中国统计年鉴》及《河南统计年鉴》等全国31 个省(市、区)统计年鉴数据的清洗。经测试,模型同样胜任《中国城市统计年鉴》《中国旅游年鉴》等其他统计年鉴数据的清洗。本研究为统计年鉴数据清洗及整合提供了一套易操作且灵活性强的解决方案。
另外,本研究建立的模型还有如下不足之处有待解决:对于Excel 中的嵌套表和含有多张表的表单,需拆分成单张表处理。不适用于非数值型数据的清洗。数据清洗过程高度依赖人工建立的匹配数据字典规范标识数据,字典完备性直接决定数据清洗准确性。下一步计划开展Alteryx Designer 挂接人工智能(Artificial intelligence,AI)开展结构化数据自动处理方面的研究,以期进一步提升数据清洗模型构建效率。
