基于NLP技术的装备故障文本匹配算法研究
2021-12-03祖月芳凌海风吕永顺
祖月芳,凌海风,吕永顺
(陆军工程大学 野战工程学院, 南京 210004)
1 相关研究
军事装备是军队战斗力的重要组成部分,装备运用过程中的故障可能直接影响装备任务的完成,因此装备故障的快速诊断维修一直是装备技术保障工作的重点和难点。当前装备故障诊断主要以人工现场诊断为主,基于当前的研究现状,本文依托在装备维修手册、装备履历书以及装备管理信息系统中大量存在的装备故障和维修的经验等数据,采用自然语言处理(NLP)技术实现装备故障文本的检索匹配,以提高装备故障的诊断能力。
装备故障文本的相似度计算必须将已有的结构化、半结构化以及非结构化的故障文本转化为让计算机理解的“自然语言”。目前常用计算文本相似度的方法是基于词向量的方法,它不仅充分考虑了语义特征并且解决了维度灾难的问题,具有良好的性能。1986年Hinton[1]提出了分布式词向量表示,不仅能够表示语义的相似度,而且使计算的难度大大降低了。2013年Tomas Mikolov等[2-3]推出了一款用于获取word vector的工具包Word2vec,它是在深度学习的基础上获取的一种词向量的分布式表达。
随着词向量模型的不断推进[4],词向量已经在自然语言处理方面得到了广泛应用,并取得了非常不错的效果。例如,文献[5]运用word vector训练得到的词向量,对搜索词的分类聚类进行了研究;文献[6]通过词向量特征构建了循环神经网络语言模型;文献[7]将词向量与LDA相融合,解决了短文本的分类问题;文献[8]通过求文本中词向量平均值得到文本向量。虽然以上方法运用词向量解决了文本的表示问题,但对文本中词汇的词性、语义以及文本中词语的位置关系考虑还不够周全。
2 基于NLP技术的装备故障文本相似度计算方法
针对以上算法中存在的不足,本文提出一种融合词性、语义[9]及词序因子的装备故障文本相似度计算方法。
2.1 词性[10]
对于装备故障现象来说,输入的一般都是短文本,区分词性对于故障特征的判断具有重要的影响。装备故障文本包含名词、动词、形容词、数词、代词、量词等6类实词,其中名词和形容词更正表征故障的原因和部位,因此应该赋予名词和形容词更高的权重。例如:“发动机冒黑烟”,“发动机”和“黑烟”都是名词,“黑烟”中的“黑”是形容词,它们比动词“冒”更能反映整个句子的意思。为了更清楚的表征装备故障文本中词语的词性特征,现将故障文本中名词、动词、形容词的权重调节为:
ωρi={scoremin,score-d}, 0<ωρ≤1
(1)
式(1)中:ωρi表示故障文本中词语i的词性权重因子;scoremin表示故障文本中词语的词性权重的下限值,且它的值一定大于0。根据装备故障文本的实际特征,将不同词性的下限值设定为:1>名词>形容词>动词>其他>0;d表示词性消减因子,用以说明故障文本中的特征词随词性的变化。以“发动机冒黑烟”为例,假设d=0.2,那么按照词性消减幅度,假定名词权重是1,即“发动机”和“黑烟”的权重为1,若句子中包含形容词,则形容词权重为1-0.2=0.8,那么动词“冒”的权重为0.6。若2个句子中词性不完全一致,那么以第一个故障文本中已存在的词性为基准,不存在的词性依据设定的词性下限值进行增减。
2.2 融合词汇语义和词性因素的装备故障文本相似度计算方法
针对装备故障文本的特征,在基于词汇语义信息的文本相似度计算方法[11]的基础上,引入词性因子[10],以提高装备故障文本相似度计算的精度,实现装备故障文本的快速检索和匹配。
2.2.1词汇语义的相似度计算
词向量训练模型最早是由Mikolov等[2-3]在2013年提出的,包括CBOW和Skip-Gram 2种模型。由于Skip-Gram模型高效、简便的特点,本文采用该模型对故障文本语料库进行训练,得到38 206个维度为200的词向量,然后通过计算向量距离的方法获得词汇间的语义相似度。之前相似度计算的方法已经被提出了很多种,这里我们采用最常用的几种计算相似度的方法。
1) 余弦相似度。向量的夹角余弦值可以体现2个向量在方向上的差异,余弦相似度就是把一个向量空间中2个夹角的余弦值作为衡量2个个体之间差异的大小。将向量计算的相似度归一化0-1,采用方法为:
simc(a,b)=0.5+0.5×cos(a,b)
2) 杰卡德相似度。杰卡德相似度一般被用来度量2个集合之间的差异大小。2个n维向量a与b间的杰卡德相似度为:
2个集合共有的元素越多,二者越相似;增加2个集合共有的元素作为分母是为了控制距离的取值范围。将其归一化后为:


2.2.2融合词性、语义的文本相似度计算方法
结合装备故障文本的特点,以故障文本中词语的TF-IDF值[11]和词性权重的乘积作为权重,改进装备故障文本的相似度计算公式,使得装备故障文本特征向量的元素之间通过词汇语义以及词性的相似度建立联系。对于故障文本Di和Dj,的相似度计算公式为:
(2)
式(2)中:Sj,n表示由2.2.1节中几种向量相似度的计算方法得到的词汇之间的相似度;ωj和ωk是故障文本Di中的词汇,ωm和ωn是故障文本Dj中的词汇;T(ωj)表示ωj的TF-IDF值;ωρj表示ωj对应的词性权重;P取值在[0,1]之间,代表词汇相似度的阈值,sim介于[0,1]之间,表示文本的相似度值。
以下面表1中的3个句子为例,对融合词汇语义和词性的故障文本相似度计算方法进行介绍。

表1 文本数据处理
首先去除停用词,利用余弦相似度计算词汇之间的相似度,如图1、图2所示(每个词和它本身的相似度为1)。图中还给出了式(2)各部分的计算结果。这里以每个词在句子中的词频代替TF-IDF权重,以名词的权重为1,形容词权重为0.8,动词权重为0.6,其他类词权重为0.4为例,标注在记录词汇的方框内。

图1 文本D0与D1、D0与D2词性语义关系示意图

图2 文本D1与D2词性语义关系示意图
由式(2)可得引入词性语义计算结果,如表2所示。
由表2中的计算结果可知,引入词性因子后意思相近句子的相似度在一定程度上得到了提高,同时,对完全不相关的句子D0与D2以及D1与D2,2种方法的计算结果都稳定在0.5左右,这样的结果显然不符合预想的效果。鉴于这种情况,考虑加入词序因素进一步优化。
2.3 融合词性、语义和词序[10]因子的装备故障文本相似度计算方法
词序表示词语在句子中的先后顺序。在汉语表达中,词语位置的不同可能会改变词汇完全相同的2个句子的意思,以下面2个句子为例。
D3:那些上海来的小朋友很热情。
D4:那些小朋友来上海很热情。
在汉语表达中,经常存在类似D3与D4这样的句子,对其进行分词、去停用词等数据预处理工作后,它们会因为词序的不同,使句子的意思发生很大变化,因此在计算文本相似度时考虑词序相似度是非常有必要的。在2.2.2 融合词性、语义的文本相似度计算方法基础上,引入词序相似度,进一步优化装备故障文本相似度计算方法,提高故障文本匹配的精确度。
计算词序相似度使用较多的是采用向量距离的词序算法[12]。根据图1、图2中词汇之间的相似度计算结果可以看出,在采用余弦相似度进行特征词间的相似度时,还可以得出这样一个结论:词汇之间只要存在一定关联的或相似程度比较高时,特征词的相似度计算结果均在0.5以上。反之,如果词汇的关联度很小或基本不相似时,词汇的相似度计算结果没有超过0.5的。因此采用余弦相似度计算2个词汇之间的语义相似度,以0.5作为阀值可以区分特征词的语义是否相似。
结合语义的相似度计算可能存在2个文本中的特征词完全不同,但是文本意思表达基本一致的情况,提出一种新的词序相似度计算方法。其核心是文本D0与D1中的特征词相似度超过0.5的词的个数越多,并且D1达到D0的顺序所交换的词语次数越少(2个句子中的特征词相似度超过0.5则默认2个词应该位于同一位置,若有多个特征词相似度超过0.5,则默认相似度最高的2个词应该位于同一位置),则2个文本的词序相似度越大。
词序(Order)相似度公式为:
(3)
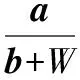
算法流程如下:
首先,找出待比较文本中相似度超过0.5的词汇的顺序向量。假定文本Di=(ω1,ω2,ω3,…,ωn)中的词汇对应的顺序索引为Vi=(ν1,ν2,ν3,…,νn)=(1,2,3…,n),文本Dj=(ω1,ω2,ω3,…,ωm)对应的顺序索引为Vj,以Vi为标准,将文本Dj与Di中的特征词进行相似度计算,Dj中特征词相似度超过0.5的按照Vi的顺序生成索引Vj,特征词相似度不超过0.5的词的位置直接去掉。以D0=(发动机,冒,黑烟)、D1=(内燃机,出现,黑烟)为例,将D0对应的顺序索引表示为V0=(1,2,3),那么D1对应的顺序索引为V1=(1,3)。
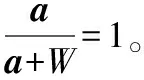
(4)
由式(4)可得,句子D0、D1、D2的相似度发生了很大变化,如表3所示。
通过表3的计算结果可以看出,引入词序相似度后,文本的相似度发生了很大变化。对于D0、D1、D23个文本,从对装备故障现象的理解来看,文本D0与D1描述的故障现象是非常相似的;而文本D0与D2以及D1与D2几乎没有关联性。这与融合词序相似度后的计算结果是相符的,并且融合词序后不相关句子的区分度更明显了,引入词性和词序因素,计算装备故障文本的相似度更符合人们的主观判断。

表3 融合词序相似度后的计算结果
3 实验与分析
在当前的相似度计算方法研究中,大多数是针对英文短文本,结合装备故障现象的特点,本文主要对比以下几种方法的计算效果对装备故障文本的相似度进行研究:
方法1:谷重阳等[11]提出的一种基于词汇语义的相似度计算方法,在计算时考虑语义并加入词频作为权重的方法,未考虑词性、词序等因素;
方法2:刘继明等[10]提出的一种基于句向量的文本相似度计算方法,在计算时从词性和词序方面优化了平反频率计算方法,未考虑词汇的语义因素,无法识别意思相近的词;
方法3:本文提出的融合词性、语义及词序的装备故障文本相似度计算方法。
为了进一步验证本文方法的有效性,本文从55 903条装备故障案例库中,选取2 000条故障文本作为训练集、348条故障文本作为测试集,并进行人工标记,将相似的句子标记为1,不相似的标记为0。
3.1 评价指标
对于故障文本匹配程度的好坏,采用精确率、召回率和F1-score值等3个常用的参数进行评价。精确率(precision)是匹配到的相关故障文本的条数占匹配到的故障文本条数的比例,衡量故障文本的查准率;召回率(recall)是匹配到的相关故障文本的条数占故障库中所有相关故障文本条数的比例,衡量故障文本的查全率;F1-score值是把精确率和召回率结合起来的评价指标。
从装备故障库中进行故障文本匹配时,把文本分成4类:TP表示匹配到的相关故障文本;FP表示匹配到的不相关的故障文本;FN表示表示相关但没有匹配到的故障文本;TN表示不相关且系统没有匹配到的故障文本。则:
3.2 装备故障文本相似度实验与分析
以发动机为例,采用不同的相似度计算方法计算词汇相似度得到的结果如表4所示。通过实验结果可以看出,运用余弦相似度计算词汇的相似度更能反映装备故障之间的差异。

表4 不同相似度计算方法计算词汇相似度结果
通过对数据进行对比分析,将文本相似度的阈值设置为0.80,对实验数据进一步统计计算,得出了3种方法的精确率、召回率以及F1-score值。3种方法的相似度结果如图3所示,由图3可知,在装备故障文本的相似度计算方面,本文方法较方法1和方法2精确率和召回率都有所提高,F1-score值甚至达到了0.868,说明了本文方法具有较高的查准率和查全率,更适合用于计算装备故障文本的相似度。
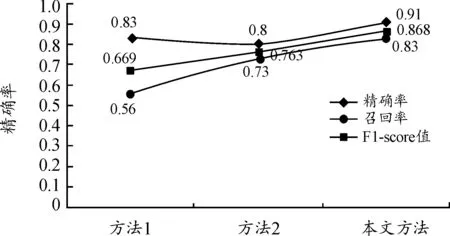
图3 3种方法的相似度曲线
3种方法的相似度占比如图4所示,将实验数据集的相似度结果分为4个相似度区间进行进一步分析得出,方法1中,所有故障文本的相似度计算结果都在0.45以上,然而事实上约一半以上的文本都是没有任何关联的,它们的相似度应该存在一部分为0的情况,这样的计算效果显然是不符合逻辑的。方法2在区间[0]的故障文本比例达到了89%,相似度值在0.8以上的故障文本只有2%,不存在故障文本相似度在(0.6,0.8]这个区间的,这对某些故障部位相关联的故障数据的匹配度不高,计算结果也不理想。本文方法中,区间为[0]的故障文本达到了47%,在(0.8,1.0]的文本约占3%,且在区间(0,0.6]和(0.6,0.8]之间的故障文本都存在,这样的计算结果与实际选择的实验数据更相符,更符合人们的主观判断。

图4 3种方法的相似度占比直方图
综合所述,本文的方法较方法1、方法2有更好的查全率和查准率,更符合客观实际。同时,通过方法2和方法3对比可知,引入词性和词序因子不仅提高了装备故障文本相似度计算的精确度,而且将完全不相关的句子可以更明确的区分开,这种计算方法显然更适合运用于装备故障文本的匹配。
4 结论
本文结合装备故障文本的特点,针对一词多义和词性、词序等可能对文本造成的影响,在词汇语义相似度计算的基础上,引入词性、词序因子优化装备故障文本相似度计算方法,在实验所用的语料库中较以往的方法得到了较好的准确率和召回率,有效提高了装备故障文本的匹配效果。
