基于策略增益均衡的异构无人机协同决策方法
2021-12-03费思邈李诗琪
费思邈,霍 琳,李诗琪
(1.沈阳飞机设计研究所, 沈阳 110035; 2.沈阳航空航天大学, 沈阳 110135)
1 引言
随着经济与科学技术的快速发展,高新技术越来越多的被运用在战争中,作战环境也变得越来越复杂恶劣。具有自主决策能力的无人机,由于不受飞行员的情绪和身体状况的影响,不会因为受到刺激而出现操纵失误,故而在这种变化中更能体现出优越性[1]。
但单个无人机作战能力有限。无人机集群灵活、自主、高效、可扩展,在协同作战时能降低作战成本、减少作战人员伤亡[2],同时又兼具了单个无人机对飞行员的依赖、环境适应性强的特点,是未来战争的重要发展趋势。从协同拓扑结构上来讲,无人机协同作战分为有中心协同与无中心协同2种。有中心协同把所有无人机看作一个整体,其中的核心决策节点决定每个无人机具体执行何种任务、何种动作,任务分配属于这种协同类型。无中心协同指的是每个无人机节点都看作独立的智能体,智能体本身通过对环境的感知、局部的认知实施决策行为,进而实现群体上的协同。随着单体无人机智能水平的提升,无中心协同以其对通讯的低水平以及高生存力等特点,更有希望实现复杂任务的协同决策。异构无人机的智能协同就是一种非常常见的无中心协同模式。
异构无人机智能协同策略学习的瓶颈主要体现在不同无人机同时决策产生的动作噪声会影响无人机对本机自身动作价值的评价,且随着集群规模的增加,联合动作序列的噪声呈指数增长[3]。由于算法设计的简单性和通用性,多智能体强化学习算法被广泛应用于异构无人机协同策略学习中[4]。但其中常用来训练的独立强化学习方法由于自身价值评价的不稳定性而无法保证收敛[5]。
为了解决这个问题,很多研究集中在集中式训练分布式执行的框架,直接构建所有智能体的联合动作值函数,该方法在小规模多智能体协同策略学习上展现出了很好的效果[6-7],假设联合动作函数和每个智能体动作函数的单调性的VDN算法[8]以及在其基础上做了非线性改进的QMix算法[9]。还有一种训练框架是集中式训练集中式执行,这种框架把整个群体看成一个超级大脑的单智能体,用一般强化学习算法进行求解。该框架在应用上的瓶颈主要体现在当智能体数量庞大时,动作空间维度快速增长,且在真实物理环境中智能体之间的通讯连接不可能像神经网络内部通讯那样迅速。此外,对于动作简单的智能体,如果动作只跟群体的平均行为相关,即使智能体规模巨大,也可采用基于平均场理论的MFMARL(mean field multi-agent reinforcement learning)算法[10-12]。然而目前为止,这类算法对于策略相对复杂的多智能体问题的有效性还有待考察。独立强化学习和集中式训练分布式执行框架以及MFMARL算法,均认为群体是由个体组成的,并且每个个体有一个策略用于输出个体的动作,群体的行为是由每个个体的行为涌现而出的。相对于独立强化学习而言,集中式训练分布式执行框架本质上是求所有智能体联合动作值函数。虽然该框架能降低同时决策的动作噪声带来的不稳定性,但无人机智能体数量较多时,联合动作值函数很难收敛;文献[8-9]等算法构建了近似联合动作值函数而不是直接求联合动作值函数本身,引入了很强的假设限制,即假设每个智能体都是无私的或者每个智能体的利益(奖赏)与群体的利益是正相关的。独立强化学习则并不存在这种假设限制,无人机智能体可通过自私的方式单独学习自己的动作值函数和策略模型。对于无人机编队的多智能体的合作博弈问题,虽然很多情况下,每个无人机智能体都以群体利益为中心对于群体本身说是最佳方案,但并不代表每个智能体以自私的方式优化自身行为会影响群体执行任务的成功率或效果。相反,在自然界和人类社会中,大多数群体行为均是以自身利益最大化最终涌现出群体更大的运行效能,例如资本家对自身财富的贪婪使得社会财富增加、社会协作和科技进步。
独立强化学习框架将单智能体强化学习算法直接套用在多智能体系统中,即每个智能体把其他智能体都当做环境中的因素,仍然按照单智能体学习的方式来更新策略。因此,独立强化学习算法有更好的应用前景,即使在无人机智能体交互类型未知或者其他无人机智能体数量不确定的环境中也适用。但纯粹的独立强化学习忽略了其他无人机智能体也具备决策的能力、所有个体的动作共同影响环境的状态,使得它很难稳定地学习并达到良好的效果。
近年来,基于独立强化学习思想衍生了一些精彩的工作。文献[13]允许智能体通过环境使用局部信息和间接协调并在环境中留下“痕迹”,激励其他智能体的后续行动。Daskalakis[14]认为:虽然独立策略梯度方法一般可能不会收敛,但遵循双时间刻度规则的策略梯度方法会收敛为纳什均衡。LI Hepen[15]提出了一种可以基于局部观察和私人奖励优化分布式策略的算法,虽然算法对异构智能体的效果还没有被有效证明,但从同构智能体的效果来看,其在保留独立强化学习几乎全部优势的同时有了质的飞跃。
本文以2个攻击型无人机以及3个干扰型无人机作为异构多智能体,通过无人机编队干扰4个地空雷达组成的封锁区,并攻击有价值目标为任务背景,运用独立强化学习多智能体学习框架,提出了一种仅仅通过控制独立强化学习中单个智能体的策略变化幅度和单个智能体自身奖赏设计,即可使单智能体自身利益最大化,实现任务想定目标的方法。通过奖赏函数的构造,提出的方法在某些情况可以覆盖多种博弈形式的多智能体强化学习问题[16]。
2 异构无人机群穿透打击任务想定
本文旨在研究异构无人机编队如何有效自主协作,学习到复杂的合作行为,研究任务背景为2个攻击型无人机以及3个干扰型无人机,通过干扰4个地空雷达组成的封锁区,并攻击有价值目标。具体的任务想定如下:
5架飞机对指定区域进行协同搜索与打击,包含3架干扰型无人机和2架攻击型无人机。干扰型无人机(干扰机)可干扰地空雷达以及有价值目标的探测雷达,攻击型无人机(攻击机)对被攻击目标进行自杀性攻击。当有一个无人机发现威胁或目标后,共享给其他无人机。集群发现地空雷达后,规避威胁,继续搜索目标,空中飞行过程中需要自主防止飞机间的相撞。搜索到被攻击目标后,2种无人机相互配合对有价值目标进行攻击,判断任务完成的条件为彻底击毁有价值目标。
本文采用每架无人机为一个单独智能体的无中心控制模式,即每架无人机根据自身探测结果和周围无人机探测结果决策期望的飞行速度矢量。干扰行为的有效距离是15 km,有效角度正负15°,如图1所示。当攻击机实施自杀式攻击的距离小于等于10 m,有价值目标被彻底击毁。飞机探测距离20 km,地空雷达能够发现并摧毁10 km内干扰角域以外所有的飞机。有价值目标自带的雷达探测距离10 km,有干扰时在干扰角度内无法攻击飞机,其他角度可以利用自带的1枚防空导弹,击毁10 km内的飞机。
初始化及整个仿真过程中任意2架无人机间距离应大于100 m,否则认为相撞,2架无人机均损失。

图1 突防任务想定示意图
3 多智能体策略增益均衡算法
本文针对上述任务背景,采用基于PPO(proximal policy optimization)近端策略优化方法[17]的独立强化学习框架,讨论如何仅通过控制独立强化学习中单个智能体的策略变化幅度和单个智能体自身的奖赏函数,使其以单智能体自身利益最大化为优化目标完成任务想定。在PPO算法本身新老策略的KL距离[18]限制基础上,提出了一种平衡协调机制,即群体策略变化幅度增益均衡协调机制,用于统一控制参与学习的异构智能体策略变化幅度,构建相对稳定的多智能体训练环境状态。
3.1 基于PPO的训练策略构建
根据任务想定,参与学习的无人机智能体包含2种异构策略:一类负责动态地干扰敌方探测,另一类负责攻击有价值目标。因此设计每个无人机智能体的策略时,也构建2种异构智能体的策略网络和估值网络,用于承载2种策略不同的价值评价。2种策略分别驱动2个攻击机和3个干扰机进行分布式序贯决策。2种策略在一场比赛中采集5条轨迹,并分成2组数据分别返回给2种策略,进行独立的强化学习策略评估和改进。在策略改进的过程中,为了减少由于2种策略相互影响,以及策略自身的改进幅度对自身和其他策略的影响,需要对每种策略更新幅度的KL距离限制进行控制,使整个学习过程平稳进行。
PPO算法优化目标为:
(1)

设定目标距离限制dtarg,根据dtarg与d的关系动态调整自适应因子β,调整方法如下:
(2)
(3)
3.2 2个阶段的学习训练模式
首先对于整体任务想定而言,攻击机与干扰机策略有2个共同的子任务:第1个子任务是搜索并发现抵近目标,第2个子任务是飞机间在飞行过程中的防撞。对于这2个子任务,2种策略有相同的价值评价,可以共享相同的动作值函数网络。其次对于个性化的子任务而言,攻击机策略个性化任务是躲避地空雷达搜索以及攻击有价值目标,而干扰机的个性化任务是在有价值目标或者地空雷达附近建立稳定的干扰区,保护攻击机不被防御系统攻击。这2种个性化任务相互交织、互为前提。攻击机个性化任务是否成功,依赖于干扰机能否根据攻击机的行进轨迹预先建立稳定的干扰区,而干扰机的个性化任务依赖于攻击机的飞行路线以及攻击行为。因此,为了平衡这种相互依赖的任务价值评价关系,本文提出2个阶段的训练模式。
为了让异构策略的独立强化学习的多智能体训练的每一种策略类型相互间充分适应,提出一种2个阶段的学习训练模式,具体为:
1) 将每一种策略的任务目标区分为所有策略共有的目标以及每一种策略特有的任务目标。然后先针对共性任务目标开展学习训练,再引入个性化任务目标开展训练。
2) 在整个训练过程中,周期性调整每一种策略的目标距离限制,目的是当一种策略大幅更新时其他策略相对稳定。
第1阶段,主要体现在优势函数的迭代更新过程,即需要将每一种策略的估值函数Vφ(st)区分成针对共性任务目标的估值函数,以及针对差异化个性任务目标的估值函数,Vφ(st)=Vφc(st)+Vφs(st),相应的模型参数φc∪φs=φ。需要注意的是,对于所有策略来说,Vφc(st)的参数φc可以是共享的。该策略的奖赏函数同样区分成共性和个性奖赏的和,即,R(st,at,st+1)=Rc(st,at,st+1)+Rs(st,at,st+1),训练过程首先固定该策略对应估值函数参数φs,可以是初始化状态。同时令Rs(st,at,st+1)≡0,开展所有策略的迭代训练,优化L(θ,φc)。本阶段,策略改进的目标距离限制dt arg为常数。策略的平均累计奖赏值收敛后开展第,2阶段的全局训练,还原Rs(st,at,st+1),同时引入第2种机制,优化L(θ,φ)。
第2阶段,主要作用在全局训练中,以本文的2种策略为例,个性化子任务与共有子任务的奖赏均有效,即,R(st,at,st+1)=Rc(st,at,st+1)+Rs(st,at,st+1),并在训练过程中,同时更新θ与φ,但采用钟摆式策略改进幅度,也就是说,2种策略的新老策略KL距离限制随着迭代次数的增加,周期性此消彼长的变化,即每种策略的更新幅度交替进行。例如,当攻击机策略更新幅度限制较大时,干扰机策略保持相对平稳的状态,因此攻击机策略就会在相对平稳的环境中训练,经过一段时间的训练,攻击机策略的更新幅度限制降低,而干扰机策略更新幅度限制增加,使得干扰机策略能够基于相对稳定的攻击机当前策略响应进行最优的训练。这种机制在一定程度上解偶了2种目标迥异的策略在同时训练过程中的相互干扰,并交替式在对方策略稳定的基础上,朝向自身任务目标方向更新。经过一段时间的交互式训练,随着2种策略平均累积奖赏逐渐收敛,2种策略改进幅度的钟摆幅度也将阻尼式收敛,这种振幅收敛方式有利于2种异构策略的融合训练。
3.3 群体策略幅度增益均衡机制
在3.1节算法策略幅度变化KL限制的基础上,本文提出了一种平衡协调机制,可以用表示为:

(4)
式(4)中,d是带阻尼钟摆效应的平衡因子。d表示为:
(5)
式(5)中:titer是训练迭代次数,完成一次所有策略的评估和改进即为一代;T为总训练代数;Ts为钟摆效应周期。
具体算法如下:
群体策略幅度增益均衡算法
Step1: 定义攻击机与干扰机的策略及动作之函数πθ1,πθ2,Vφ1,Vφ2,Rc(st,at,st+1),Rs(st,at,st+1)其中πθ1,πθ2为攻击机和干扰机的策略网络,Vφ1=Vφc1+Vφs1,Vφ2=Vφc2+Vφs2分别是攻击机和干扰机个性化任务的估值函数网络以及共性任务估值函数网络。
Step2: 针对共性任务的策略训练,屏蔽个性化任务奖赏函数,固定Vφs1及Vφs2,Rs(st,at,st+1)≡0,dtarg=c,更新θ1,θ2与φc1,φc2来优化每个策略,直到平均累计奖赏值收敛或到规定的迭代次数。

4 仿真实验
为了更加直观地体现并验证利用上述方法训练多智能体无人机编队协同执行复杂任务的效果,设定2个攻击型无人机以及3个干扰型无人机通过干扰4个地面雷达,通过封锁区并攻击有价值目标为作战任务,进行仿真实验。实验通过控制独立强化学习中单个智能体的策略变化幅度和单个智能体自身奖赏设计,使其仅仅通过优化单智能体自身利益最大化,实现防撞路径规划、干扰压制以及有效利用干扰区攻击有价值目标。
4.1 任务想定抽象
所考虑的战场范围为100 km×100 km的矩形区域,集群从西向东搜索有价值目标,决策周期1 min。敌方目标分布在战场东部区域,有价值目标被4个地空雷达防空系统包围,基本上封锁了被保护的有价值目标。地空雷达防御系统,具备探测和打击功能。有价值目标是无人机集群的核心打击目标,它同时也具备探测和攻击功能。从经验上来说进攻思路是:由干扰机撕裂地空雷达防空系统的封锁,构建一片小范围的安全区域,攻击机沿着动态变化的安全区域进入封锁区。同时干扰机在有价值目标的攻击路线上构建干扰安全区域,攻击机沿着新的安全区域进攻有价值目标,还要考虑全程的相互避障。
总体上,若想成功完成打击任务,需要所有无人机智能体自我学习出如下群体策略能力:① 相互之间防撞能力;② 干扰机主动构建出对攻击机有利的安全区;③ 攻击机主动识别安全区位置和角度,并利用安全区实施攻击;④ 干扰机和攻击机相互配合动态调整干扰区的位置,运送足够多的攻击机去攻击有价值目标。这个无人机群体的攻击行为由每个智能无人机自主决定并实施,需要他们通过各自策略的学习最终涌现出群体上有效的进攻行为。
4.2 单个智能体马尔可夫决策过程构建
攻击机的任务是不与友机相撞,并且在干扰机的掩护下攻击有价值目标。干扰机的任务是不与友机相撞,并且通过干扰敌方雷达来构建安全区掩护攻击机完成任务。
观测空间:对于攻击机与干扰机来说,其策略的输入是智能体的观测量相同,均由x维度向量构成,主要包含自身位置坐标,其他友军的位置坐标以及存活状态,敌方单位位置坐标。以战场西南方为坐标原点,智能体不允许出战场,敌方单位在未被发现时坐标为-1。
动作空间:假设攻击机发现目标后可以自动攻击,干扰机可以进行全程干扰,因此对于攻击机和干扰机来说,策略的输出是智能体所做的动作相同,由y维度向量构成,分别代表东西方向与南北方向的速度。
干扰机和攻击机策略模型输入分别如表1、表2所示,其中,计算本机与其他无人机坐标之差,默认被摧毁的无人机坐标差认为0。

表1 干扰机策略模型输入

表2 攻击机策略模型输入
状态转移:由于2种机型的动作空间均为2个方向的速度,因此状态转移方程可直接用运动方程表示,为了统一维护所有智能体的状态,构建一个全局性的矩阵,矩阵包含3列,前2列代表每个无人机的坐标,第3列代表每个无人机是否存活,矩阵的行代表不同的无人机。每一个决策周期均维护这个矩阵。
奖赏函数:对于干扰机和攻击机,观测空间、动作空间和状态转移基本上遵循相同的形式,然而奖赏函数由于任务内涵的不同,整体结构也不同。因此,需要针对不同种类的智能体设计不同的奖赏函数。每个智能体奖赏函数分为2个部分:第1部分,称之为共性奖赏函数,用于奖励或惩罚任务内涵中相同的任务导向,在本文的想定任务中,共性任务包含2个方面:① 多个无人机智能体之间时刻保持大于某个防撞距离,防止智能体之间相撞损毁;② 每个无人机智能体尽快发现目标并朝敌方目标抵近。第2部分,称之为个性奖赏函数,对于攻击机来说,个性化奖赏函数是引导智能体进入干扰机构建的安全区,并伺机攻击敌方有价值目标。而对干扰机来说,是引导智能体构建合理的动态安全区,护送攻击机安全地攻击。因此,2种无人机智能体策略对应的奖赏函数如表3、表4所示。

表3 干扰机奖赏类别

表4 攻击机奖赏类别
策略形态:2种策略均采用4层256节点全连接神经网络表示。
4.3 策略训练对比及结果分析
整个无人机编队协同训练任务采用分布式训练方式,主训练节点采用2块Nvidia Tesla v100 32G GPU开展集中式神经网络训练,采样节点构建128个worker用于并行采样,每个worker占用1核CPU,分布在2台64核CPU,256G内存的服务器上。根据上述策略幅度增益均衡机制算法,首先进行共性奖赏训练,即奖赏函数中表3、表4第3列,共性奖赏所在的奖赏描述生效。主要目的是让每个智能体学会一些通用的策略准则,例如主动寻找有价值目标以及相互之间的防撞。迭代n次以后,开展针对个性奖赏训练,并运用策略变化幅度动态平衡技术,周期性更新每种策略的更新幅度。具体训练结果如图2~图4所示,其中,绿线是采用KL距离限制的策略幅度增益均衡机制算法训练得到的结果,红线是除了策略幅度增益均衡机制外其他训练参数均相同的独立强化学习算法的训练结果。
分别训练后,策略幅度增益均衡机制算法经过30轮左右的迭代,学习到了完成任务的方法,并在探索关闭的情况下可以稳定地完成任务,实现了异构多智能体的稳定自主协同合作完成想定任务,如图5所示。而独立强化学习算法经过100轮的训练仍然没有找到完成任务的方法,并且平均奖赏曲线抖动很大、训练效果不稳定。最终结果是攻击机和干扰机没有有效配合,导致攻击机一直处于被防空导弹击落的状态。
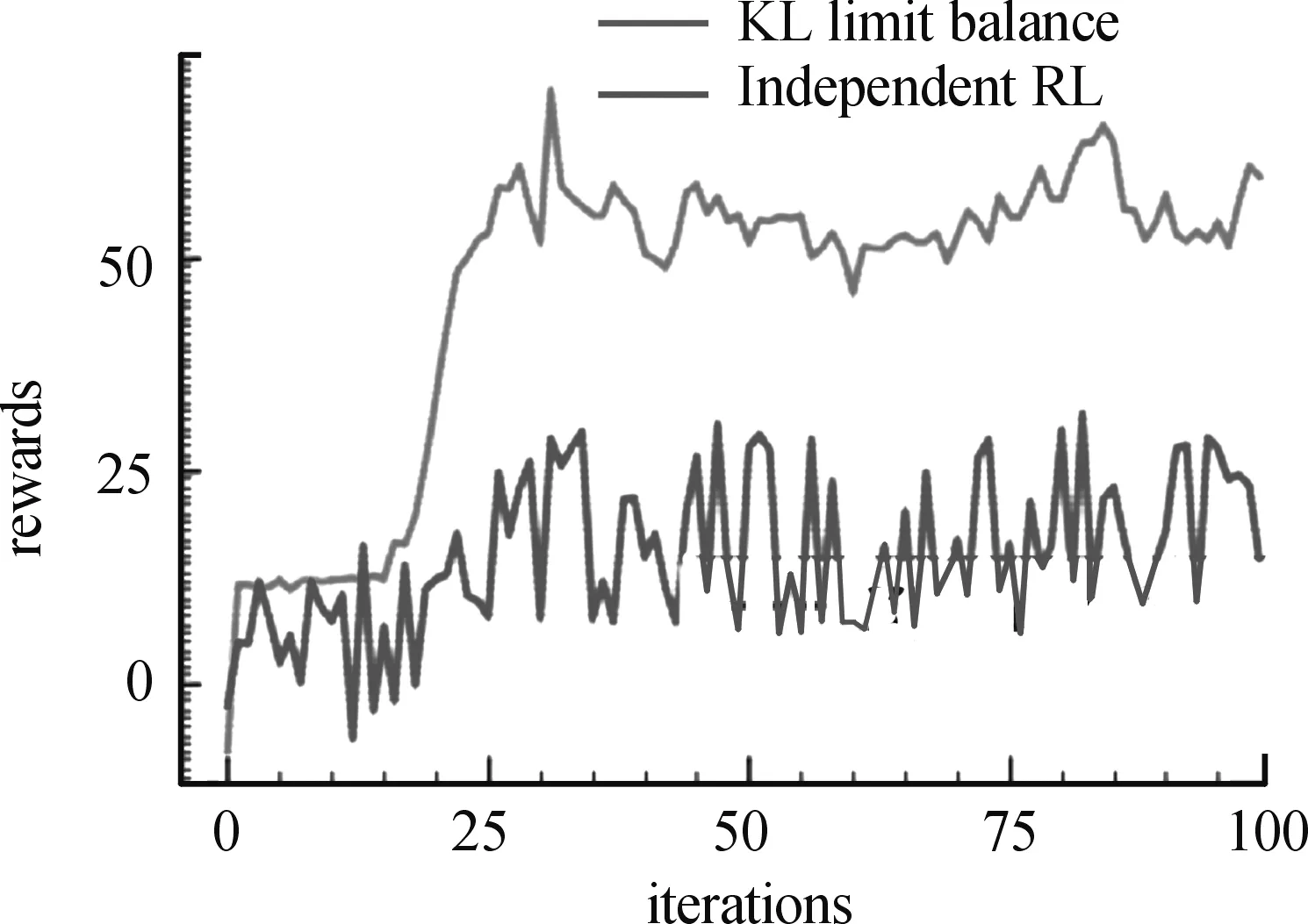
图2 训练结果与独立强化学习的训练曲线(攻击机奖赏)

图3 训练结果与独立强化学习的训练曲线(干扰机奖赏)

图4 训练结果与独立强化学习的训练曲线(平均奖赏)
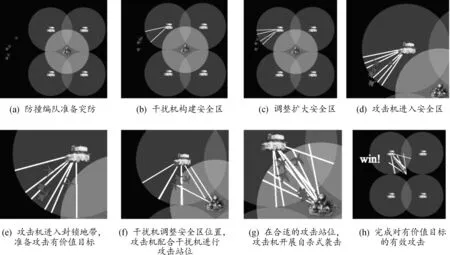
图5 策略增益均衡机制算法训练的2种异构智能体的行为表现示意图
5 结论
本文以异构无人机集群执行复杂任务为背景,基于独立独立强化学习的多智能体框架,提出了一种新的群体策略变化幅度增益均衡协调机制与一种两阶段的训练方式,使其仅通过单智能体自身利益最大化学会协同,完成复杂任务,构建相对稳定的多智能体训练环境状态,训练并实现异构无人机编队的智能协同合作策略。通过仿真实验证实,本文提出的算法策略学习效果远好于改良之前的独立强化学习算法。该试验任务想定面向的是智能体之间的合作博弈场景,然而本方法涉及到合作博弈问题的部分是奖赏函数的构建,即,将奖赏函数区分为共性奖赏和个性奖赏。策略变化幅度均衡部分,并没有涉及到合作博弈假设,在某些情况下策略变化幅度均衡机制可以覆盖多种博弈形式的多智能体强化学习问题。
