基于BP神经网络的电信用户流失预测研究
2021-12-01王小超
王小超 张 勇
(巢湖学院信息工程学院 安徽合肥 238000)
随着移动通信技术的快速发展,电信运营商的用户数量急剧增长,通信市场竞争日益激烈。通过利用电信应用系统产生的数据,建立预测模型,对可能出现流失的用户做出较为准确的预测,对于减少用户的流失,提高通信运营商的运营水平,有着较高的应用价值[1]。
本文以实际的电信应用数据为研究对象,采用了BP神经网络算法,研究了电信用户流失问题。通过训练数据建立了数据模型,通过对模型的优化,最终得到了实际可用的数据模型,有效对电信用户流失做出预测。
一、算法选择
该问题实际属于一个二值分类问题,即建立模型的目标是预测一个用户的流失或未流失。解决二值分类问题的算法较多,常用的算法有支持向量机SVM、随机森林RF算法、K近邻算法等。
通过初步的模型评估,随机森林与支持向量机SVM效果相当,KNN算法分类效果较差,而神经网络的效果较好。因此,本文在算法选择上,采用了BP神经网络算法,该算法具有应用广泛、泛化能力强、准确率高等特点。
二、BP神经网络算法
BP(back propagation)神经网络是应用最为广泛的神经网络,是一种按照误差反向传播的方式训练数据的多层前馈神经网络。典型的BP神经网络模型如图1所示。

图1 BP神经网络模型
BP神经网络模型经历了正向传播和反向传播两个过程。
(一)正向传播。以图1两层神经网络为例,在正向传播时,神经网络按照一下方式计算各层输出:
H=ø(XW1+b1)
O=HW2+b2
其中ø表示激活函数,常用的激活函数有sigmoid函数、ReLU函数,tanh函数。求得输出结果后计算误差函数E。
(二)反向传播。首先考虑输出层与中间层之间的权重w2jk的调整。若各层都使用激活函数sigmoid时,误差E对连接权重w2jk求导结果是:
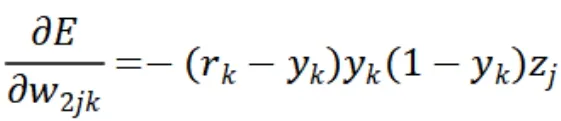
接下来对输入层与中间层之间的连接权重w1ij求导,计算结果如公式所示:
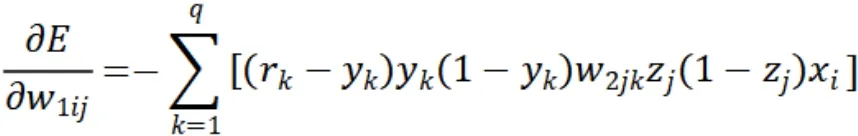
这样就可以根据各层的梯度更新w2jk和w1ij,偏置项的更新过程类似。
三、建立预测模型
防止用户流失、保留现有用户对于电信运营商降低运营成本、提高收益具有现实意义。建立较为精准的预测模型,运营商可以对可能出现流失的用户进行预测,通过增大政策引导来留住用户。整个模型建立过程,需要经历5个阶段:数据预处理,定义BP神经网络结构,在训练集上训练模型,为提升模型效率进行调参,最后进行评估模型。
(一)数据字段。该模型的数据采用中国移动真实的公开数据集,每条数据包含18个特征,但不是所有的特征都与用户流失相关,去除个人客户ID字段后,用于建立模型的有17个特征,其中churn是标签字段。具体特征值如表1所示。

表1 用户流失相关属性
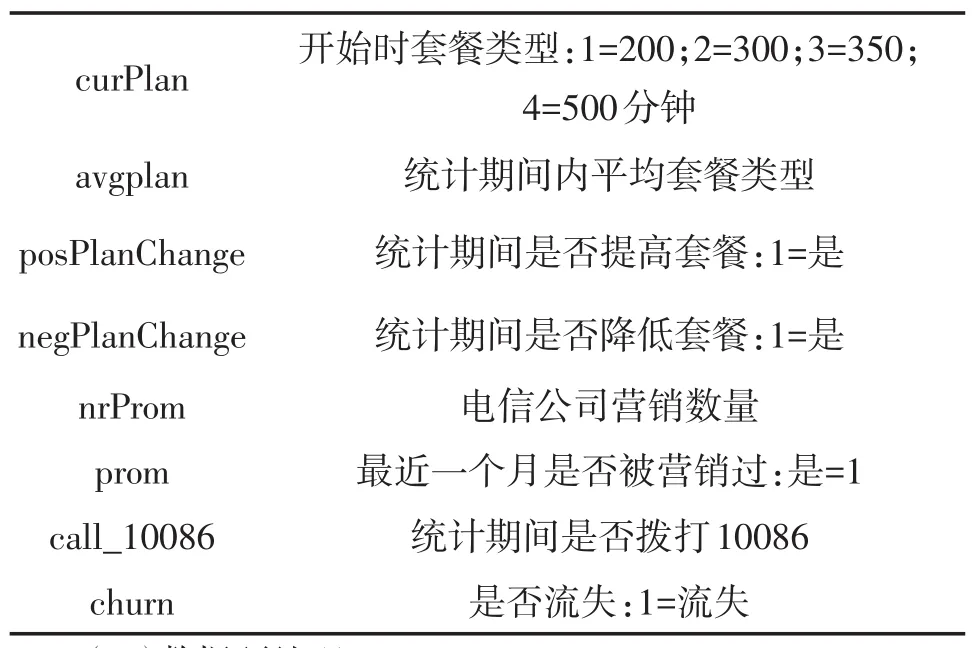
curPlan avgplan posPlanChange negPlanChange nrProm prom call_10086 churn开始时套餐类型:1=200;2=300;3=350;4=500分钟统计期间内平均套餐类型统计期间是否提高套餐:1=是统计期间是否降低套餐:1=是电信公司营销数量最近一个月是否被营销过:是=1统计期间是否拨打10086是否流失:1=流失
(二)数据预处理。
1.数据清洗。数据的清理过程主要是清除噪声和删除不一致的数据,而缺失值、噪声和不一致性都会导致不正确的数据,从而影响到数据的质量。数据清理的目标要完成数据的缺失值处理、光滑噪声数据并能够识别离群点,纠正数据中出现的不一致[2]。本文中对缺失值采用均值中位数填充的方法进行填充。对于离群点,通过数据可视化方式进行聚类,为避免离群点对模型造成不利影响,需要将离群点做删除处理。
2.数据规范化。数据规范化在神经网络分类中的作用尤为重要,规范化就是赋予所有的属性相同的权重,当不同特征的值域差异较大时,必须要完成数据规范化,这里采用的是最小-最大规范化方法,将每个特征的值域映射到[0,1]区间上。具体方法如下:
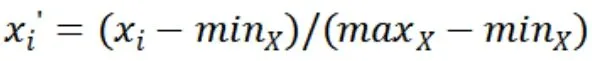
3.数据平衡。数据不平衡时,可能会造成预测结果的偏向。在分类问题中,主要考虑样本在不同分类上大致是均衡的。如本实验的样本数据流失用户数比非流失用户数要少得多,这样会使得训练得到的模型在预测时会偏向于非流失[3]。为解决数据不平衡的问题,并尽可能多的保留样本数据,采用了上采样的方式解决,即流失用户的样本集生成与非流失的样本集相同数量的样本。
4.数据集划分。在训练模型时,需要将整个的样本数据集划分成训练集和测试集,测试集用于最终的模型测试评估,而训练集用于模型的建立。在建立模型时,为测试模型训练时的效果,还应从训练集中取出一定比例的样本构成验证集,以便在训练过程中测试模型的效果。根据数据集大小,确定训练集和测试集比例,本文训练集与测试集按照7:3划分,训练集中的验证集按照交叉验证的方式划分。
(三)建立BP神经网络模型。模型建立是该问题的核心部分,应综合考虑数据样本集的情况和实际问题的目标,选择合适的模型,使用训练集对模型进行训练,使得模型能够反映数据之间的内在关系[4]。建模的过程是一个反复迭代的过程,通过反复调整参数得到合适的数据模型。
1.确定模型,构建两层模型。为了提高精度,可以通过增加网络的隐藏层的层数或者增加隐藏层神经元个数两种方式实现。考虑到模型复杂度以及时间效率,本文采用了两层的BP神经网络模型,包含了1个输入层,1个隐藏层,1个输出层,采用该两层模型实现电信用户流失预测模型。
BP神经网络模型建立需要经过反复迭代,先正向传播计算各层输出,再通过计算误差E,反向传播不断更新各层的权重参数与偏置项。BP神经网络模型的训练流程如图2所示。
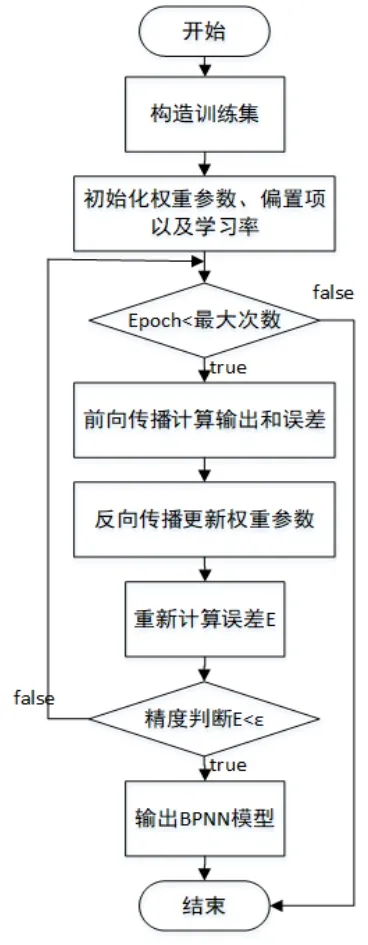
图2 BPNN训练流程
先通过初始化的权重参数,偏置项以及学习率等超参数建立模型结构,执行神经网络正向传播过程,得到前向计算的输出,通过计算期望输入r和网络实际输出y计算最小二乘误差函数E。以该误差函数E为目标函数,模型的训练目标就是让实际的计算输出与期望输出接近,即E值趋近于0。因此,模型的训练过程就是不断调整各层的权重参数W,使得最小二乘误差函数E趋近于0。
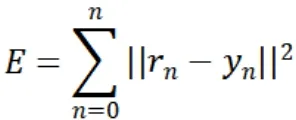
rn表示第n个样本的期望输出值,yn表示个样本的网络实际输出值。
2.参数设置。隐藏层结点个数nh:采用下面常用的经验值计算方法得到隐藏层结点个数,ni表示输入层节点数为16,n0表示输出层节点数为2,在实验阶段将m从1调整到10,根据实际的测试结果调整隐藏层结点个数。初始值取m=1,计算得到隐藏层结点个数为5。
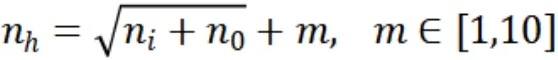
学习率Ƞ:学习率Ƞ的设置比较关键,学习率过小,收敛过程较慢,消耗大量的模型训练时间,学习率过大,每次权值参数修正也增大,可能会造成收敛过程的跳跃,可能会收敛到一个非最小值点,甚至不收敛。为了选取合适的学习率,每次迭代时学习率不是固定的,学习率依赖于上一次的迭代的学习率,整体逐渐递减。学习率Ƞ经验值一般取0.01到0.8之间,本文初始的学习率Ƞ设置为0.1。
3.网络训练过程。正向传播过程:根据规划的BP神经模型结构,输入层采用W1x1+b1线性函数计算,在隐藏层使用目前最为流行的ReLU函数ReLU = max(0,W1x1+b1)作为激活函数,该函数提供了一个简单的非线性变换,且具有很好的可导特性,便于在反向传播时计算梯度。输出层使用线性函数W2x2+b2得到输出,正向传播过程如图3所示。
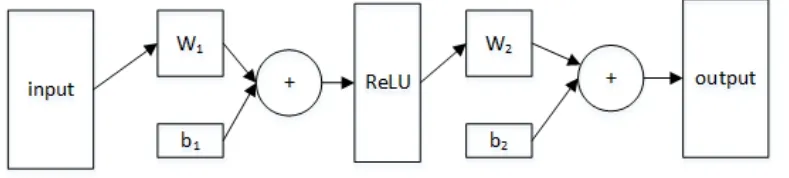
图3 正向传播过程
在计算损失函数值时,还应考虑正则化惩罚项,本文使用L2类型的正则化惩罚项,因此最终的的损失值loss计算如下:

data_loss是使用了softmax函数的交叉熵损失,其中表示第i个样本的预测值y(i)取到真实值ri的概率,reg_loss是L2正则化损失函数,reg是惩罚因子,表示惩罚的力度。
反向传播过程:为了更新W1,b1,W2,b2参数,反向传播就是计算梯度的过程,从最后的损失函数反向逐层求导。首先对softmax函数反向传播求导,符号d表示求导:
dscores=正确分类概率值-1
再对W2x2+b2线性计算中的各个参数求导。符号×表示矩阵乘法,下面公式同样。
dx2=dscores×W2
dw2=dscores×x2
db2=dscores
接着对ReLU函数求导,因为RelU=max(0,x),求x求导,若x>0,导数为1,若x<=0,导数为0。因此Relu求导如下:
drelu=dx
drelu[x<=0]=0
最后对W1x1+b1反向求导。
dx1=drelu×W1
dw1=drelu×x1
db1=drelu
完成反向传播,后更新权值参数,更新参数时使用Adam优化算法,更有效地更新网络权重。
m=b1⋆m+(1-b1)⋆dx
v=b2⋆v+(1-b2)⋆dx^2
W+=-learning_rate⋆m/sqrt(v)
五、算例分析
(一)模型准确率。基于以上算法训练的BP神经网络模型,在验证集和测试集上测试模型的分类效果。实际测试的结果如图4所示。从如图4(a)图中可以看出,执行了10次epoch后模型准确率趋于稳定,以100作为一次batch_size迭代计算,打印了损失函数与迭代次数的关系图,当迭代次数超过50次时,损失函数趋于收敛。从图4(b)图可以看出,最终验证集的模型准确率达到88.3%,测试集的模型准确率达到了84.8%,具有较高的准确度,且没有出现过拟合问题。
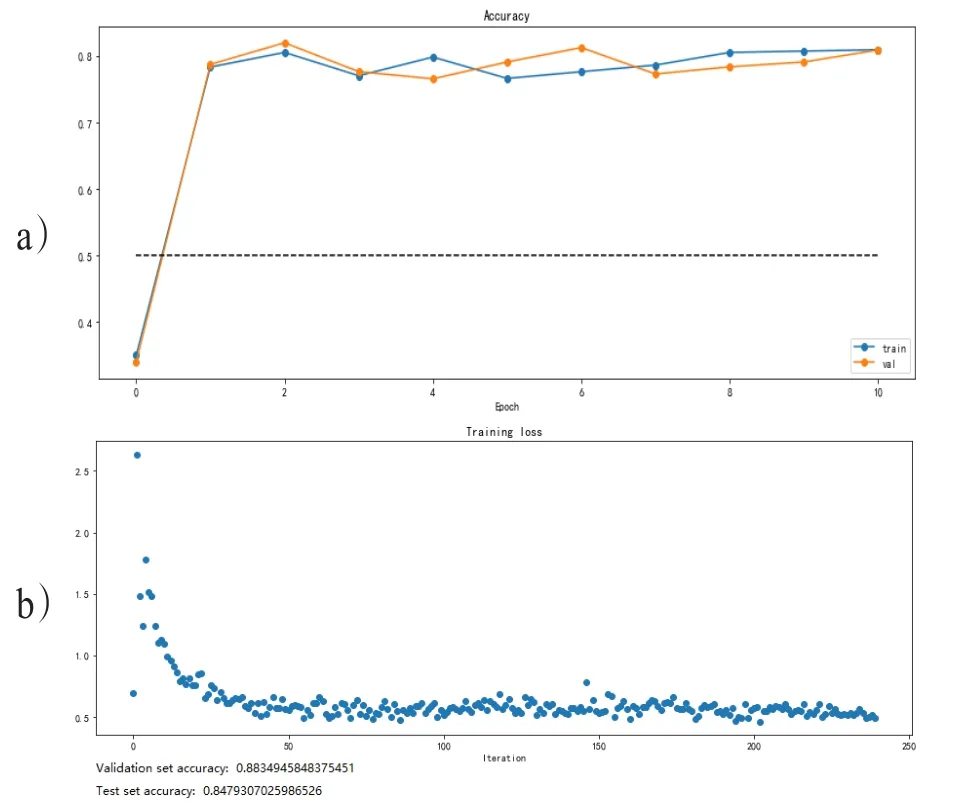
图4 BPNN模型预测结果
(二)召回率。为验证预测电信用户流失的准确率,采用模型准确率在当前场景下不是非常合适。该问题只需考虑用户实际流失的情况,当预测用户会流失实际情况也流失了,表明预测正确。而当预测用户不会流失,没有采取任何的措施,实际情况用户流失了,这时电信公司就会产生损失。这就表明,即使模型分类的准确率很高,也可能会出现大量用户流失被预测成非流失,造成损失。因此采用召回率recall值衡量模型准确率更为合适,即recall=TP/(TP+FN)。其中,TP表示预测会流失实际也流失的数量,FN表示预测非流失实际流失的数量。recall取[0,1]之间的值。图5为模型在测试集上的混淆矩阵,计算召回率:

图5 BPNN测试集的混淆矩阵
recall=TP/(TP+FN)=393/(78+393)=83.4%以召回率评估模型,仍然具有较高精度。
(三)算法对比。将BP神经网络模型,与SVM,RF,KNN算法在测试集上的预测结果进行对比,结果如表2所示,由结果可知,从准确率指标上看,BP神经网络模型的准确率最高达到了84.8%,SVM与RF模型准确率相当,而KNN算法的精确度较低。从召回率指标上看,BPNN仍然具有较高的精度,预测集上达到了83.4%。而SVM,RF算法虽然模型准确率较高,召回率的精度却并不高,KNN算法的召回率效果较差。
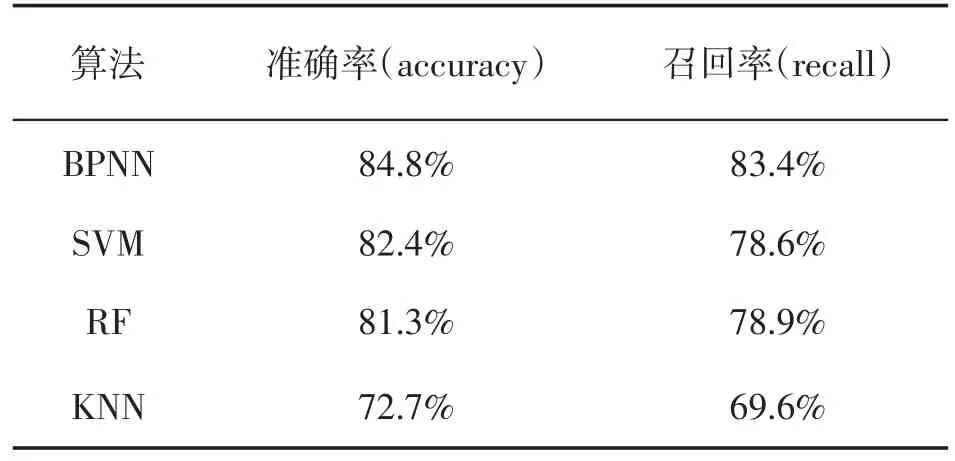
表2 各算法评估结果对比
本文采用的BP神经网络算法经过反向误差传播更新模型参数,能够使得模型的构建更加准确,通过调节正则化惩罚项,激活函数,学习率,隐藏层深度,隐藏层节点数等超参数,可以具有更优的用户流失预测准确度。
四、结语
本文开展了基于BP神经网络算法的电信用户流失预测应用研究,结果表明:BPNN模型训练结果在准确率方面表现出色。
BP神经网络算法相比于SVM,RF,KNN等算法,通过调参可以训练得到更加准确的预测模型,在实际的用户流失预测中具有更高的模型准确率与召回率。
本文中仅基于BP神经网络算法建立了用户流失的预测模型。实际上,影响电信用户流失的原因较为复杂,分析的内容除了预测模型外,还应涉及用户分组,流失用户特征分析等方面[5]。为达到更好的分析效果,可进行用户分组,对样本数据进行聚类分析,计算每个组中用户流失的比重,找到流失率最高的分组,还可以开展流失用户特征分析,对流失用户做因子分析,找到重要的影响特征,对具有容易流失特征的用户做体验改善方案[6]。这样通过多方面的数据分析,有助于模型进一步的优化,支撑电信运营商的运行决策。
