基于词义增强和注意力机制的Twitter情感分析研究*
2021-12-01蔡旭勋杨进才
蔡旭勋 杨进才
(华中师范大学计算机学院 武汉 430070)
1 引言
文本情感分析用于分析人们对特定实体的观点、情感、评价、态度和情感的文本分类计算方法,一直是自然语言处理的一个热门研究问题[1~2]。
基于深度学习的文本情感分析主要是使用神经网络对文本进行处理。情感词典在传统的情感分析任务中是极其重要的语料库[3],它统计了一些具有强烈情感色彩的词以及某些词的正负极性或者情感强度的分数。目前最常用的表示单词的方式是word2vec词向量[4],在Twitter这种非常特殊的语料中,经常会有一些情感符号或者表情[5],这些都是非常具有特色的情感标签,但词向量并不能对其进行表示,如果能够针对这些表情符号做相应的处理,就能更好地把握Twitter的情感走向。例如情感词典能够应用到情感特征显著的文本里面。
现有的关于情感分析的工作大多基于深度学习框架,忽视了这些传统特征对特定问题的作用。
2 相关工作
基于深度学习的文本情感分析主要方法有CNN和RNN。Yin等使用多通道多尺度对句子进行建模,此方法能够有效提取文本内特征[6],但是CNN方法的弊端在于它无法考虑句子内部及句子间的依赖关系。Ke等在LSTM之上额外引入了外部记忆单元,对句子进行建模,提升了模型对历史信息的处理能力[7]。韩萍等提出了多维自注意力机制对微博情感进行分析,能更高效地提取文本特征[8]。
上述工作利用深度学习进行文本分析,都没有考虑传统情感词典的作用,本文提出了用情感词典和深度学习结合的方法。本文首先收集常用的情感词典,包括经典的表情符号词典,然后对出现在Twitter中的具有感情色彩的词用词典中的情感值来向量化表示,针对CNN和LSTM模型的不足,本文在模型的选择上,采用基于注意力机制的双向长短期记忆网络(BiLSTM),同时提取句子的正序信息与逆序信息,注意力机制还能够自适应的选择句子中情感信息丰富的部分。
3 基于词义增强和注意力机制的情感分析模型
文本首先对Twitter文本进行预处理、分词、构建文本单词集;根据现有的词典对情感词以及表情符号进行语义增强,根据这些词在词典中的情感值以及情感极性对其进行向量化的表示,将此表示拼接到原有的词向量中;最后,将词向量化的文本表示和它对应的情感标签(连续或离散)作为训练样本输入到基于注意力机制的BiLSTM模型中。处理过程由文本预处理、训练模型、预测等几个模块组成。整体框架如图1所示。
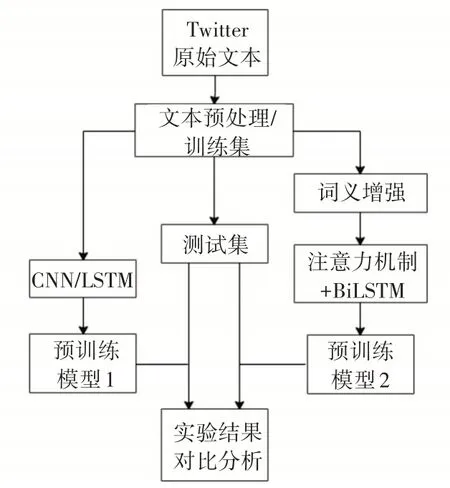
图1 文本情感分析整体框架
3.1 文本预处理
本文采用了SemEval 2018语义评测大赛的数据[9],三种数据集规模如表1所示。
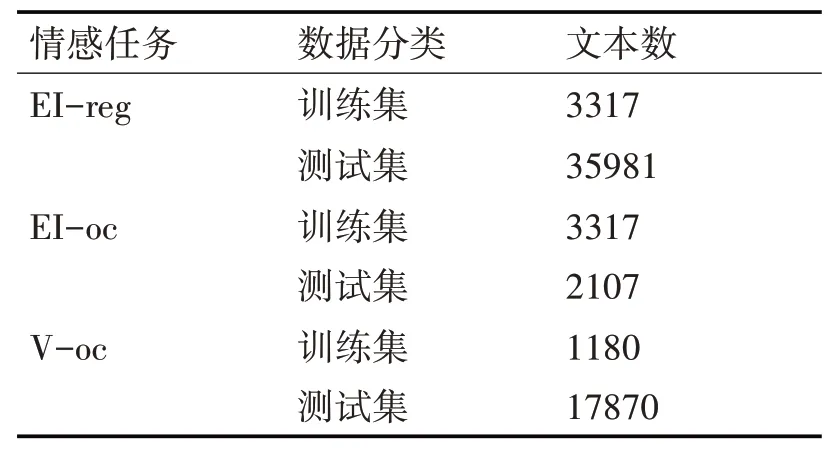
表1 本文采用所采用数据集
三种情感分析任务及其主要区别是:(情感强度回归任务(EI-reg)是给的一条Twitter然后判断它在anger和joy两种不同情感状态下情感得分(一个介于0到1之间的实数值);情感强度分类任务(EI-oc)是给定一条Twitter然后对它进行分类是属于anger或者joy中某一种情感,这是一个分类任务;基于Valence维度的情感回归任务(V-oc)是给定一条Twitter然后判断它在anger和joy两种不同情感状态下Valence维度的情感得分(一个介于0到1之间的实数值),这是一个回归任务。
文本预处理的过程主要分为以下几个步骤:1)对数据进行清洗,去除一些不正常的标点、网页标记符号和各种其他特殊符号,比如火星文字等;2)对阿拉伯数字进行处理,统一删除所有出现的数字,日期以及数字与字母的连写,如“r34”等;3)删除字母之间多余的空格,由于英文文本的特性,单词与单词之间只存在一个空格,因此需要把多余的空格删除;4)对文本进行分词处理,本文采用的分词器为NLTK[10];5)由于所采用的词向量是Glove[11],因此需要对文本中的大写字母进行转换。预处理前与预处理后的文本示例分别如图2和3所示。

图2 预处理前的文本

图3 预处理之后的文本
3.2 情感词典和词义增强
目前,有多种情感词典,对情感进行不同类别的 划 分 与 表 示。NRC Affect Intensity Lexicon[12]:NRC AI词典提供了每一个单词的情绪标签(正或负)和情感强度。在WASSA-2017[13]情绪强度共享任务(Shared Task on Emotion Intensity)中每种情绪都可用这个词典表示,词汇表中每一行是单词及其在四种基本情绪:愤怒、恐惧、悲伤和愉快(anger,fear,joy,sadness)下的不同情感值。NRC Emotion Lexicon & NRC Hashtag Emotion Lexicon[14,17]:NRC EL是一个在十种不同情绪下单个单词的离散情感强度值词典。NRC HEL通过与单词相关的主题标签的推文自动生成,它用浮点分数范围0~2.24的值来表示情感类别的强度。
类似的情感词典还有NRC Emoticon Lexicon&NRC Hashtag Sentiment Lexicon[15~16,18]这些情感词典都是针对常见的人可能出现情绪的表示,表示方式主要有离散型和连续型两种,都从不同的侧面表示出了当前单词所具有情感倾向和情感强度值。
本文词义增强的步骤如下所示:1)对Twitter中的单词用词向量进行表示,即将每一个单词表示成一个1*D维的向量(Glove);2)对Twitter中的每个单词如果能够在词典中找到,则词典中的情感值表示为表示第k个词典,i表示第i个单词;3)将情感值用多项式进行表示,多项式表示就是产生一个多项式的集合。例如,输入一个二维的样本[m,n],那么这个样本的二阶多项式特征集合为[1,m,n,m2,n2,mn],这样就可以将词典中的某个值表示成一个多项式特征的集合,如果在词典中找不到该词,那么将此值设置为0;4)将多项式特征向量直接拼接到原有的1*D维的向量之后,但是每个词典的情感值维度是不一样的,因此还需要进行矩阵标准化操作,即将矩阵变成标准正太分布N(0,1)。词义增强之后单词之间的相似度如表2所示。
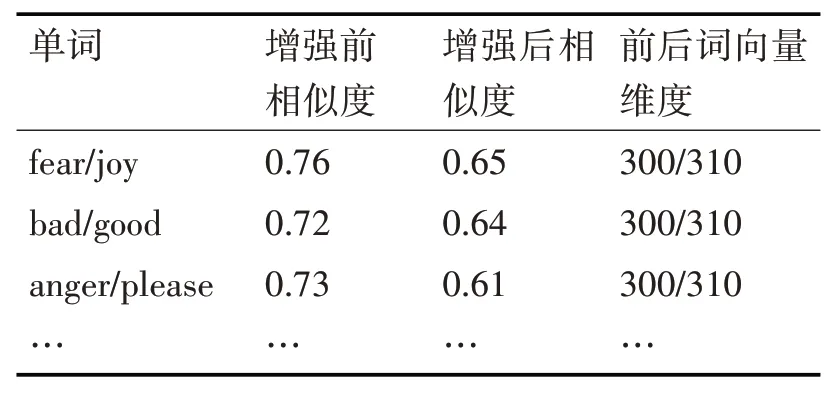
表2 词义增强前后相似度比较
从表2中可以看出通过词义增强之后,词向量的维度增加了,单词之间的余弦相似度也发生了变化,主要是因为以前的300维词向量是一个平均意义上的词向量,比如bad和good,它是基于大量文本训练出来的,但是这样平均意义上的词向量并不能适用于所有的场景。因此,词义增强之后的词相似度发生了变化,主要原因在于good在joy这种语义下它表达的情感要比其他情况更为强烈,bad在fear这种语义下它也有表现更为强烈。
3.3 基于注意力机制的BiLSTM模型
双向长短期记忆网络BiLSTM,其中一个重要的概念就是“门”,它控制信息通过的量,实质上就是一个σ函数,σ的表示式为σ(t)=1/(1+e-t),该函数最重要的一个特征是,它可以把任意实数值映射到(0,1)区间上,而且,绝大部分的值都是非常接近0或者1的,这样函数能够决定让多少信息通过这个门结构。在LSTM中,一共有三种门结构,分别是遗忘门(forget gate)、输入门(input gate)与输出门(output gate)。如图4所示的是一个LSTM的神经元及其内部结构,图中圆框部分是加法和乘法运算,方框部分是激活函数σ或者tanh,Xt是t时刻的输入,at-1和Ct-1是上下文信息,ot是t时刻的输出。BiLSTM的结构是一个前向循环神网络和后向循环神经网络组成。
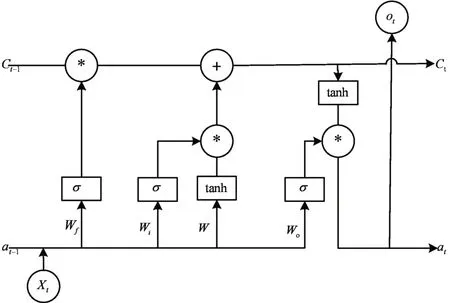
图4 LSTM神经元内部结构
注意力机制可以理解为从大量信息中有选择地筛选出权重不同的信息,权重越大则代表对该部分的关注度越高。在情感分析任务中加入注意力机制,可以使神经网络更多地关注文本中包含情感信息较多的部分,从而使得情感分析的效果更好。时序问题中的注意力机制大部分是基于编解码结构,本文采用的结构也是基于此构建的,假设t时刻BiLSTM隐藏的输出为ht,那么把ht输入到注意力机制中去,可以得到etj,etj表示编码器在时刻t的状态对解码器中j状态输出的影响程度,最后通过softmax函数对etj进行归一化处理,从而获得每一个时刻隐藏状态对解码输出的影响,即在时间维度上的注意力值。注意力机制计算过程如式(1)(2)所示。
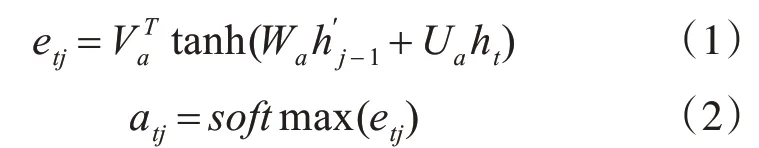
通过注意力机制的使用,在模型中不仅可以将权重进行重新分配给每一个隐藏状态,还结合了编码器和解码器两部分的状态,这样比单一的模型具有更好的效果。
综上,本文采用的基于注意力机制和双向长短期记忆网络(BiLSTM)模型结构如图5所示,文本序列进行向量化表示之后首先经过BiLSTM,接着计算t时刻的注意力向量,然后再输入到BiLSTM里面,经过两层BiLSTM处理之后,经过Flatten层再接上一个Dense层,最后输出层进行分类或者回归的处理。
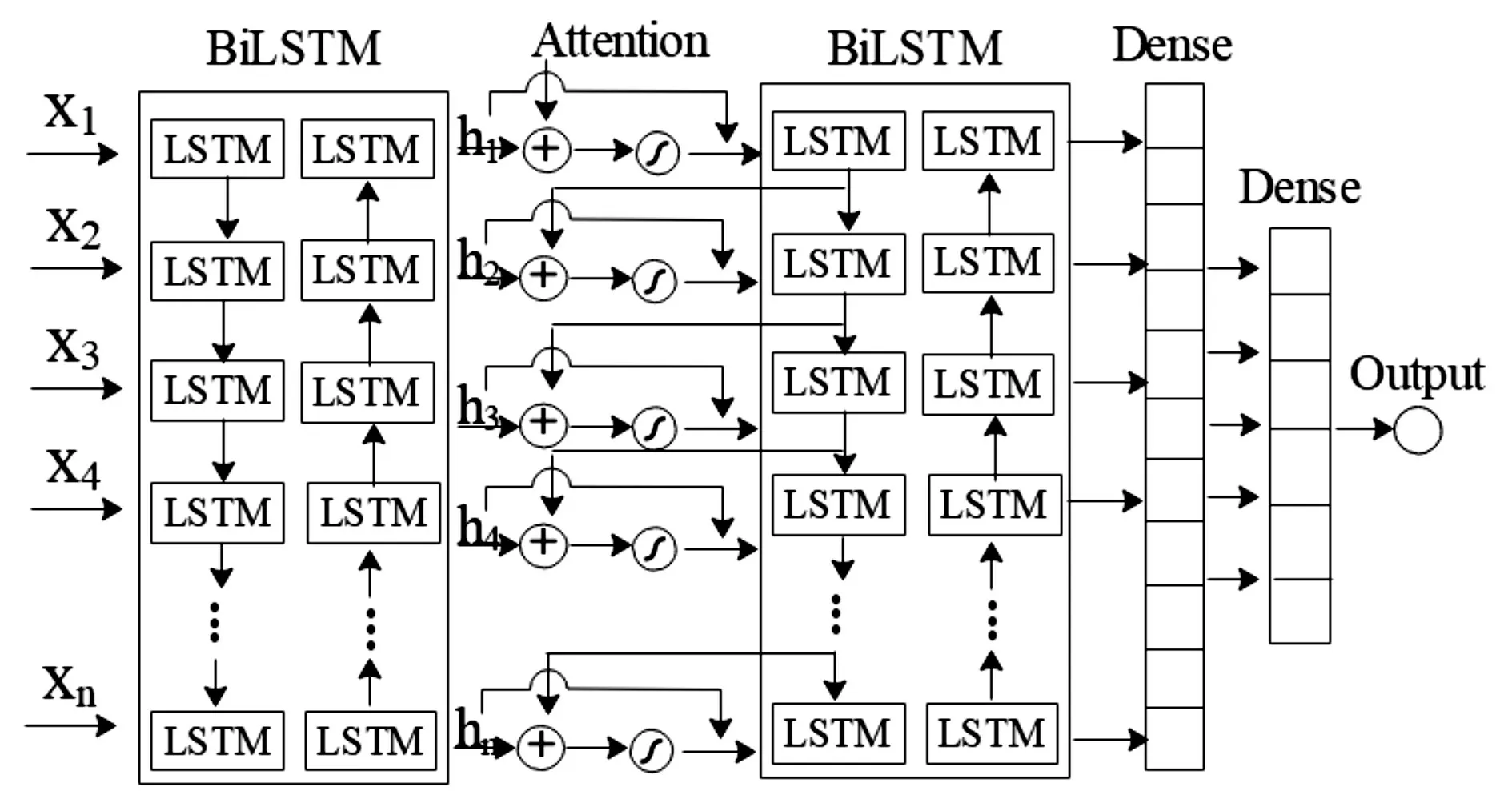
图5 基于注意力机制的BiLSTM情感分析模型
4 实验结果
4.1 实验参数设定
本文相关实验超参数设置如下:两层BiLSTM神经元个数分别为256,128;两个全连接层神经元个数为128,64,Dropout大小为0.25;batch size大小为64,训练epoch大小为10;Glove词向量维度为
300。
4.2 实验评价指标
本文用皮尔森相关系数作为实验评价指标,该系数是用来反映两个变量线性相关程度的统计量。两个变量之间的皮尔森相关系数为两个变量之间协方差和标准差的商。协方差的计算公式如下:
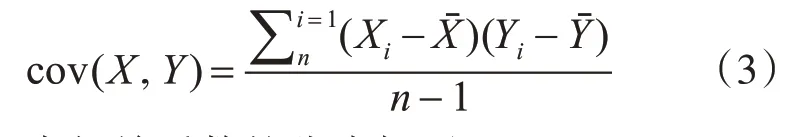
皮尔森相关系数的公式如下:
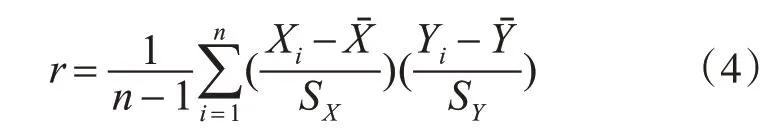
皮尔森系数r的取值总是在-1.0~1.0之间,其中n为样本量,r描述的是两个变量间线性相关强弱的程度,r的绝对值越大表明相关性越强,实验的预测值和真实值之间的关联度越强,也说明模型越好,实验效果越好。
4.3 实验结果分析
在多方面情感强度回归任务(EI-reg)上,本文进行了多组对比试验,实验结果如表3所示。表中结果表示的模型在测试集上预测的值和实际值之间的皮尔森相关系数,其中#表示该模型进行了词义增强。从表3可以看出,本文提出的模型BiL⁃STM(att)在anger和joy的强度值上的皮尔森系数最高,BiLSTM对句子进行训练,可以更好地捕捉双向的语义依赖信息,加入注意力机制,使隐藏层的不同权重输出在最终的句子表达中发挥不同的作用。对比其他的深度学习模型,本文提出的BiL⁃STM(att)模型效果是最好的。对比CNN和CNN(#)、LSTM和LSTM(#)的结果可以看出,本文提出的词义增强模型比没有进行词义增强的模型效果更好。
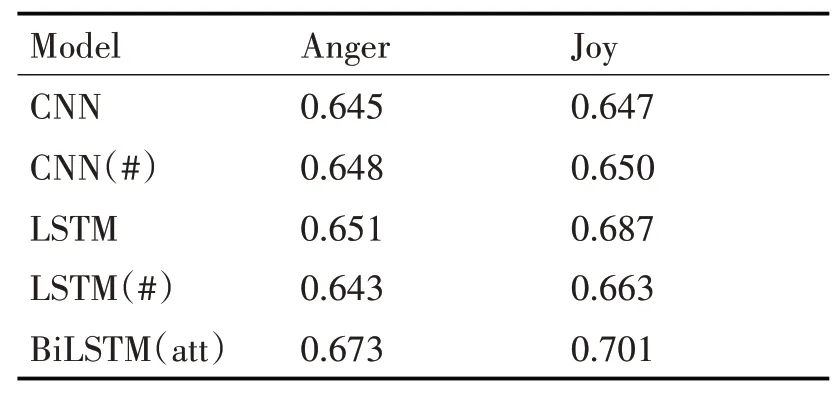
表3 多方面情感强度回归任务(EI-reg)上的结果
在多方面情感强度分类任务(EI-oc)上,实验结果如表4所示。可以发现本文提出的模型依然具有最好的效果。
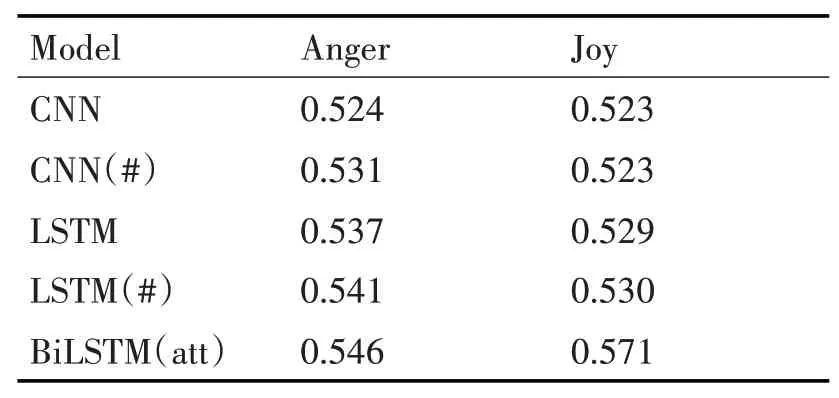
表4 多方面情感强度分类任务(EI-oc)上的结果
在基于Valence维度的情感回归任务(V-reg)上,本文实验结果如表5所示,MAE表示损失计算是平均绝对误差,Ensemble表示对多个模型进行融合,最后取所有的10次结果作为最好的Valence值,经过多次实验,发现效果最好的模型是本文提出的双层BiLSTM(att)模型。
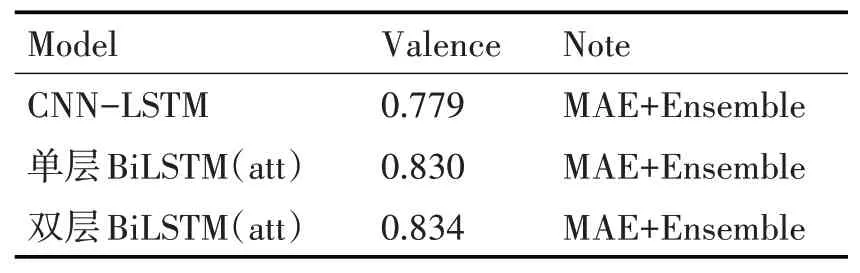
表5 Valence维度回归任务(V-reg)上的结果
5 结语
本文提出了一种基于词义增强和注意力机制的Twitter文本情感分析方法。提出的词义增强的方法,不仅能够增强词义和语义信息,还克服了其他文本处理方法只利用单一词向量的缺点。通过对情感词进行词义增强,可以提取单词更多的情感特征,有助于提升情感分类和情感回归的效果。
利用词义增强后的词向量,和对应的情感强度标签匹配在一起,作为训练样本输入到基于注意力机制的双向长短期记忆网络(BiLSTM),不仅能够提取句子的正序信息,还能够提取其逆序信息。此外,注意力机制还能够自适应的选择句子中情感信息较多的部分。实验结果表明本文提出的方法相比其他情感分析方法具有更好的效果。
