基于改进随机森林优化算法在医疗数据中的应用研究
2021-12-01苏前敏郭晶磊沈宙锋
朱 城,苏前敏,郭晶磊,沈宙锋
(1 上海工程技术大学 电子与电气工程学院,上海 201620;2 上海中医药大学,上海 201203)
0 引言
国外研究人员早在2007 年就将大数据运用在流感预测上,根据用户网络搜索的关键词来判别流感是否爆发、流感预测,比当时的疾控中心还能早两周就预测出流感发病率[1]。精准智能医疗可以实现对未知病人是否患病情况进行智能预测,常用于肿瘤疾病的预测[2]。如华大基因等公司最近更是推出了自主研究的肿瘤基因检测服务,通过采取患者样本,对患者的癌组织进行相关基因分析,实现乳腺癌等癌症患者的早期检测[3]。
当前,众多学者、专家在医疗数据领域运用多种机器学习算法进行了分析和预测。提出了使用支持向量机建立模型对乳腺癌数据进行处理分析,发现基于K-medoids 聚类和支持向量机的改进算法(KD-SVM)分类精准率优于H-SVM 算法[4];提出了决策树机器学习算法在乳腺癌诊断中的应用,预测准确率达96%[5];研究了联合决策树及logistic 回归,建立乳腺癌相对风险预测模型,在保证模型检测准确率的同时通过logistic 组合模型能够对患病的危险特征进行捕捉和判断[6];提出了基于随机森林的乳腺癌计算机辅助诊断研究,相比决策树,使用随机森林算法构建模型,最终的检测准确率高达96.93%,又有了新的提升[7]。
本文应用了对医疗数据预测率较高的随机森林模型,通过改进减少特征维数的方式和将遗传算法的理论应用于参数调优,提出一种改进的随机森林多模型复合优化算法。
1 算法优化简介
1.1 SelectKbest 变量筛算法
SelectKbest 变量筛算法是在n堆数据中寻求价值最优的k类数据[8],每堆数据中有一定的特性vi和wj,可令某组数据的特定值S ={i1,i2,i3,…,ikx},表示为式(1):

输入中包括n堆数据,并且含有k类需要保留的数据,符合条件为:wj(1 ≤k≤n≤100 000),数据特性vi符合条件为(0 ≤vi≤106,0 ≤wj≤106),vi和wj的总和不超过107。

对比Xt的值,当所计算的值不再大于X时停止,而最终的Xt的值就是选取k类数据所计算出的值。
1.2 随机森林分类模型
随机森林以获取最后阶段的最优输出为目的,对数据集进行重复采样的优化模型。随机放回的抽样模式与传统不放回的样品抽样有相似点,但却并不独立,所以有式(4):

随机森林算法属于bagging 算法的一种,也属于bagging 算法的一种加强算法[9],样本的数据集输入为式(5):

迭代次数为t次,即是对训练集进行t =1,2,...,t次分别采样,得到最终的集合Et,所得集合的算术平均值就是最后的模型输出。随机森林建模过程如下:

输入训练集A和测试集B,B为储存样本。在B的样本量中选择一定量的特征因子,借助决策树来获取最合适的分割位置,并不断重复。将重复的结果存储到Cx中,在所有的结果中得到最终的样本预测值Exp。
1.3 基于遗传算法的超参调优方法
本文以遗传函数的思想对参数进行优化,参数的优化问题可以定义为多目标优化问题,即可以用数学模型(6)规划。

式中,V-min 表示向量极小化,即向量目标f(x)中的各个子目标函数都尽可能极小化。
遗传函数的参数寻优首先就要进行编码,编码方式采用二进制,根据模型参数的类型选择染色体的长度,计算二进制所对应的十进制数[10],式(7):

产生初始化群体,计算适应度即衡量交叉验证评价标准的值,进入繁衍迭代循环,根据不同的交叉和变异比例进行繁衍复制,若达到设定的迭代次数,则终止繁衍,否则继续迭代繁衍,在最终的“族群”中得出最优解。
2 实验与验证
2.1 数据集
本文所使用的实验数据来自威斯康星州诊断性乳腺癌数据库的乳腺癌数据集,在主流的癌症肿瘤智能医疗探索中,大多数研究是针对肿瘤的细胞核的特征进行分析,包括乳腺癌细胞核光滑性、凹陷点数标准差等数十个量化特征因子[11]。
癌症肿瘤数据之所以难以分析,是由于每一个特征连续型变量的变化都与其它的很多指标相联系,一个特征的变化又会导致更多指标发生变化。在对任何一个数据集进行分析处理的时候,过多的特征因子很容易降低模型的运行效率,而且很容易导致过拟合[12],每一个变量又是连续变化的,所以所得出模型的结果也会随之变化。
2.2 特征因子的筛选
通过spss 工具对乳腺癌数据集进行因子分析。对数据集进行KMO 检验和巴特利特检验,KMO 检验是用于比较变量相关系数和偏相关系数的指标,KMO值越接近于1,证明变量间的相关性越强。巴特利特球形检验是一种检验各个变量之间相关性程度的检验方法。一般在做因子分析之前都要进行巴特利特球形检验,用于判断变量是否适合用于做因子分析。通过检验乳腺癌数据集变量的KMO值为0.832,说明30 个变量间共线性很强,见表1。

表1 本文使用数据集KMO 和巴特比特检验Tab.1 The data set KMO and Butterbite test used in this article
在碎石图1 中可以清楚地看到30 个变量因子的特征值变化趋势。根据已设定的特征值提取参数,最终提取了6 个特征值大于1 的特征变量,对6个特征因子特征值进行旋转后,方差和特征根发生变化,这6 个因子累计可以解释88.759%的方差因素,解释力度非常强。
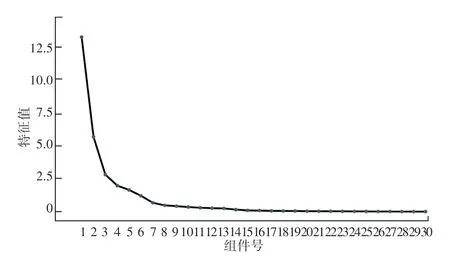
图1 30 个变量特征值碎石图Fig.1 Crushed stone map of 30 variable eigenvalues
为了提高模型的表现力,对数据集进行数据筛选,找到能够达到模型效果最大化的变量筛选方法和筛选方案。在选择变量筛选方法时,需要对变量筛选的方法充分理解,对数据集样本的大小、实现的难易程度有所评估[13]。现在常用的变量筛选方法有比例法、方差法、SelectKbest 变量筛选法和模型筛选法,见表2。针对乳腺癌数据集变量间存在的特殊性共线性关系,选用比例法和方差法时,模型得分反而降低。而选用SelectKbest 变量筛选法可以自主控制想保留的变量因子个数,通过穷举法判别保留不同的变量因子个数时模型的表现性,找到变量筛选的最佳参数。当保留的变量因子从1~6 个逐渐上升时,模型的得分呈现大幅度提高,符合因子分析的结果,通过调节K值的参数分析得出,保留15个变量因子时,模型得分超过不进行变量筛选时的模型得分,而当保留16 个变量因子时,模型的得分达到最高,如图2 所示。

表2 常见变量筛选与无特征筛选乳腺癌分类器模型得分Tab.2 Common variable screening methods and five-feature screening of breast cancer classifier model scores

图2 K 值不同与模型得分的关系Fig.2 The relationship between different K values and model scores
2.3 参数调优
随机森林分类器的结果作为输入值送入遗传算法超参数调优的模型中,首先产生足够数量染色体的种群,在本文中,一条染色体代表一组超参数,而每组超参数中的任意一个参数就是染色体上的基因。通过定义交叉验证的评价指标,计算超参数优化的适应性函数。整个迭代过程遗传算法主要运用两种方式来创建新一代,一是交叉的方式,二是变异的方式。通过改变随机森林中的树木数量和深度及叶子数在每一次迭代中删除表现型最差的参数组合,选择表现最好的机组参数组合进入下一次迭代,经过足够的迭代次数后,最终选择出最优的参数组合[14]。
通过遗传函数对随机森林的参数进行优化,流程如图3 所示。随机生成一个基因序列产生第一个染色体,再生成一个基因序列,产生第二个染色体,重复到生成指定个染色体之后进行交叉和变异;对结果进行评估,选择最优的几个染色体进行下一次的迭代;重复进行交叉和变异,达到迭代次数后停止计算。设定迭代次数为10 次,在第六次迭代之后就达到了模型的最大得分,第七次迭代之后模型得分不再变化。遗传函数10 次迭代的模型最终参数设置如下:

图3 参数调优流程图Fig.3 Parameter tuning flowchart

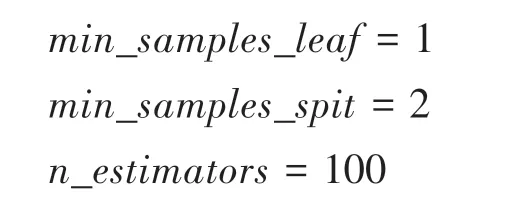
遗传函数10 次迭代的模型最佳得分见表3。为了展示实验结果的科学性,分别与单个参数网格调参、多参数网格调参、随机网格调参的方式对精确率、召回率、F1 分值、AUC值进行比较。见表4 经过结果对比发现,通过遗传函数对模型进行优化的结果在交叉验证精准值、召回率、F1 分值、AUC值等方面的准确率均超出使用单个网格、多个网格及随机网格等调参方法对模型进行优化的结果。
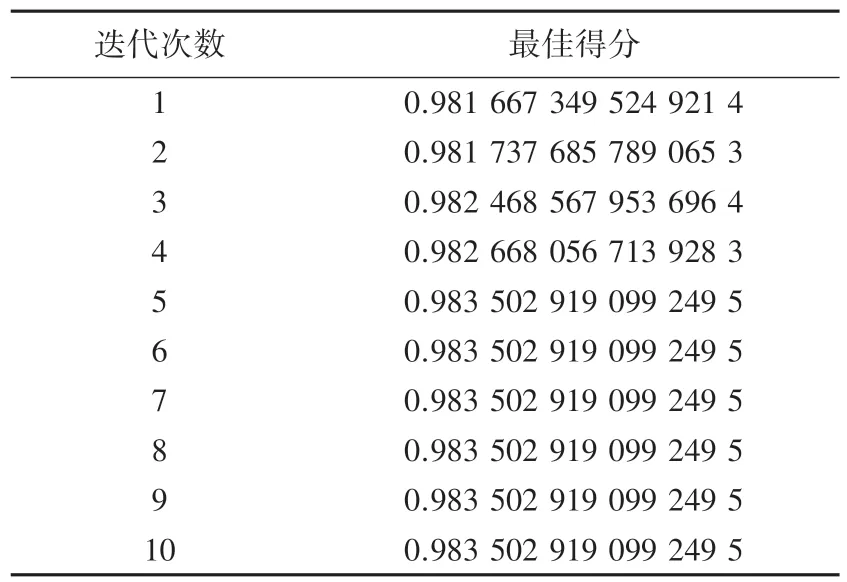
表3 遗传函数10 次迭代模型最佳得分Tab.3 The best model for ten iterations of genetic function

表4 不同的参数调优性能指数Tab.4 Different parameter tuning performance indexes
根据精准率和召回率分别构建以遗传函数进行参数优化和以多网格调参优化后的模型PR 曲线图和两个模型最后的ROC 曲线如图4 所示,可以看到遗传函数参数优化后的模型的P-R 曲线完全将多网格调参后的模型P-R 曲线覆盖,而从ROC 曲线图来看,遗传函数参数优化后的模型所表现的ROC曲线面积更大。由此分析可以得出,通过遗传函数进行参数优化后的模型性能要高于多网格调参后的模型性能。
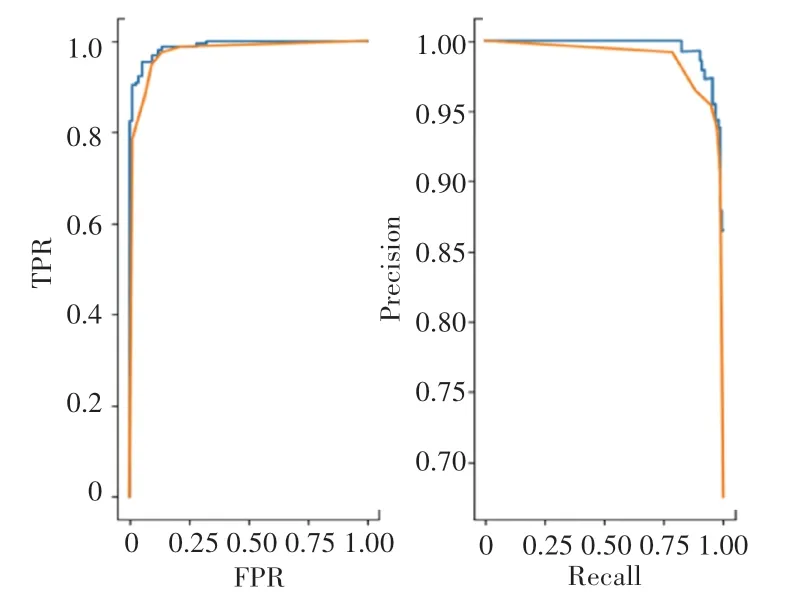
图4 随机森林参数优化和网格调参参数优化的ROC 和PR 曲线对比Fig.4 Comparison of ROC and PR curves of random forest parameter optimization and grid parameter optimization
对模型进行KS 检验,结果得出乳腺癌分类器的KS 值达到0.85,如图5 所示,证明模型鉴别癌细胞与正常细胞的能力很强。

图5 模型的KS 验证Fig.5 KS verification of the model
3 结束语
(1)对于一般的医学临床数据集,由于特征因子之间共线性较强,通过试验发现选用比例法和方差法以及模型验证法时,模型得分反而降低。而选用Kbest 变量筛选法可以自主控制想保留的变量因子个数,减少了因子间共线性强对模型的影响,通过对比不同特征因子模型的表现性的变化来筛选特征,找到变量筛选的最佳参数;
(2)采用遗传算法对随机森林分类模型进行超参数调优后,目标模型的精准率达到0.980 2,相比于运用多网格的调参方法提升了0.17,不仅提高了模型的预测准确度,从模型的召回率、F1 分值、AUC值进行比较分析,也提升了模型的鲁棒性。
优化后的随机森林算法模型能够最大限度程度上让模型的表现性达到最大,便于对强共线性特征数据的分析,优化参数寻优结构,为临床数据处理和疾病预测提供了一种新思路。
