基于FPGA 的模板匹配加速器的设计与实现
2021-12-01周仕杰
李 锋,周仕杰
(东华大学 计算机科学与技术学院,上海 201620)
0 引言
织物的瑕疵检测是织物质量控制中的重要一环,传统的人工验布方式存在着检测效率低下、漏检率高等缺陷,还会对工人本身的视力造成伤害,是提升织物生产效率的一大瓶颈[1]。为了改变这一现状,织物的瑕疵检测成为计算视觉领域的一大研究热点[2]。国内外已有不少基于计算机视觉技术的解决方案,但是这些方案在实时性、准确性、经济性及适用性上还不足以满足实际的生产需求,还需要进一步探索。
基于深度学习的方法可以很好地拟合大量非线性数据,在复杂的织物纹理背景下有着更好的检测效果,但是其面临数据集获取困难、难以增量学习、不可解释性等难题[3-4]。纯色织物的纹理是具有周期性的,传统的模板匹配的方式可以很好地增强瑕疵区域的显著性[5]。但是模板匹配算法本身计算量庞大,当前的通用CPU 架构无法满足实时计算需求。而FPGA 作为一种高性能、低功耗的可编程芯片,可以通过编程直接生成专用电路。与CPU 分时同步的并行方式不同,FPGA 利用电路的并行特性可实现真正的多核并行[6]。现有解决方案大多是将织物瑕疵检测算法部署在高性能服务器上,这些服务器大多采用通用PC 外接图像采集卡及图形加速卡的结构,成本较高[7]。近年来,随着SoC 技术不断成熟,FPGA+ARM 的异构平台(Zynq-7000 系列)的推出,使得高性能且低成本的软硬协同定制计算,逐渐成为织物瑕疵检测系统的首选解决方案[8]。
本文首先分析了运用于瑕疵检测领域的模板匹配算法,根据该算法的特点设计了相应的基于FPGA 的硬件加速器,并对加速器的访存时延、传输时延、计算时延等环节进行了优化。本方案在Zynq-7020 平台上实现,对该加速器进行了性能评估,并与通用CPU 的运行效果进行了对比。
1 瑕疵检测中的模板匹配算法
目前基于计算机视觉的瑕疵检测算法可大致分为4 类:基于结构的方法、基于统计的方法、基于频谱的方法和基于机器学习的方法[9]。其中,基于结构的方法通常是将织物的纹理视为纹理基元的组合,织物图案的纹理即为纹理基元的周期性排列。由于瑕疵会破坏织物纹理的周期性,可以使用无瑕疵的织物图像作为模板,通过模板匹配算法将织物图片与纹理模板相减,可以提取出拥有较好一致性与完整性的目标瑕疵,该方法可用于织物瑕疵图像的显著性检测,织物瑕疵图像的显著性检测就是将瑕疵区域定义为显著区域,其余纹理图案部分定义为低显著性区域[10-11]。
比较常见的基于灰度的图像匹配算法有平均绝对差算法(MAD)、绝对误差和算法(SAD)、误差平方和算法(SSD)、平均误差平方和算法(MSD)、归一化积相关算法(NCC)、序贯相似性检测算法(SSDA)等[12]。由于SAD 方法计算较为简单,适合FPGA 的实现,本文采用SAD 方法,基本原理如式(1)和(2):

其中,s(x,y)为待检测图像,其分辨率为m ×n,t(x,y)为模板图像,其分辨率为M × N,M >m,N >n。
将待检测图像在模板图像上滑动,如图1 所示。tij(x,y)为待检测图片覆盖到的模板图像区域,即子模板图,i、j为待检测图左上角在模板图像中的坐标位置,其中i、j的范围为:0 ≤i <M-m,0 ≤j <N- n。
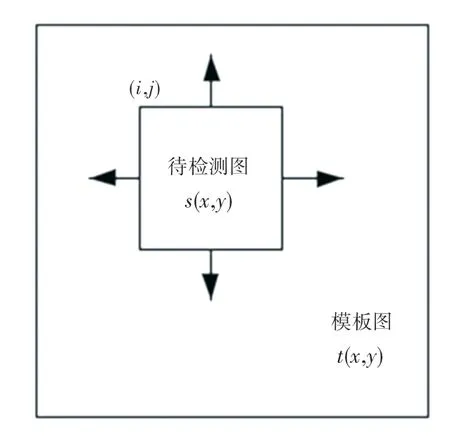
图1 模板匹配过程Fig.1 Template matching procedure
绝对误差和算法(SAD)将子模板图与待检测图像之间像素灰度的差的绝对值之和d(i,j)作为子模板图与待检测图之间的相似度,绝对差之和越小,表示待检测图与该位置的子模板图越相似,取使得d(i,j)最小的子模板图tij(x,y)作为模板匹配的结果图像I,计算公式如式(1)和(2)所示。然后将待检测图像与模板匹配的结果图像相减,定义为该待检测织物图像的显著性图像。
值得注意的是M-m与N-n的取值,即待检测图像与模板图像之间的大小关系。由于织物纹理存在周期性,将织物纹理抽象为一个正弦函数:

假设待检测图像所包含的纹理周期为:

模板图像所包含的纹理周期为:

若φ0≠φ1,则待检测图与模板图之间存在相位差,为了保证待检测图像是模板图像的子图,则须满足θ0≥θ1+2π,即模板图像须在横向及纵向上均比待检测图像大一个纹理周期。若织物纹理一个周期的像素大小为p ×q,则为一张分辨率为m ×n的待检测图像进行模板匹配运算,需进行m ×n ×p ×q次减法运算,该方法的计算量庞大,当前的通用CPU 无法满足其在实时场景中的算力需求,需要设计加速器。
2 基于FPGA 的模板匹配加速器设计
2.1 从模板匹配算法到FPGA 加速器
模板匹配是提取显著性图像的重要步骤,其速度直接影响整个瑕疵检测的实时性,为此设计了一个模板匹配加速器,作为一个外设挂载在操作系统之下,CPU 和加速器之间通过内部数据总线相连。此外加速器访问内存需要消耗大量时钟周期,因此被读入片上缓存的数据要尽可能得到复用,但片上缓存的大小有限,一帧4k 的完整织物图片无法直接存入片上缓存,因此每次将包含若干纹理周期的子图存入片上缓存。本文的论述主要基于像素大小为16×16 的子图,以及像素大小为24×24 的模板图,该方案适用于纹理周期小于8×8 的纯色织物图片。针对纹理周期较大的情况,可以考虑增大模板图,但这也意味着更大的计算量、更多的资源消耗。本文设计的加速器在每次启动的时候先将模板图像存入片上缓存,然后在完整的织物图像中依次为每一个子图执行模板匹配运算,并将结果不断写回内存,其工作流程如图2 所示。

图2 加速器工作流程Fig.2 Accelerator workflow
2.2 加速器结构
加速器采用了3 层存储架构,分别为片外缓存(DDR),片上缓存(BRAM),以及运算单元内部的寄存器,如图3 所示。加速器通过AXI4(Advanced eXtensible Interface 4)总线与PS(Processing System)的内存通信,两个AXI4 接口均工作在master 模式下,可对内存进行随机访问,其中input 接口负责将内存中的数据写入片上缓存,而output 接口负责将计算后的结果写回内存。此外该加速器的多个控制寄存器通过AXI4-Lite 总线实现与内存统一编址,该接口工作在slave 模式下,PS 端可通过AXI4-Lite总线来获取并控制PL(Programmable Logic)部分的加速器工作状态。

图3 模板匹配加速器结构Fig.3 The structure of template matching accelerator
该加速器的主要运行时延由3 部分组成,分别为访存时延,即加速器通过AXI 总线在内存中随机寻址所消耗的时间;传输时延,即数据在AXI4 总线上传输所消耗的时间;以及计算时延,即模板匹配运算本身所消耗的时间。因此,可以从这3 个方面对加速器进行优化设计,提高资源利用率,提升加速器的算力。
2.3 加速器时延优化策略
2.3.1 访存时延的优化
访存时延的优化主要通过AXI4 总线的突发传输机制来实现。AXI4 总线中的突发传输是指在地址总线上进行一次地址传输后,可连续进行多次数据传输,即第一次地址传输中的地址作为起始地址,后续数据的存储地址在起始地址的基础上递增,AXI4 总线的最大突发传输长度为256[13]。得益于这一机制,在加速器顺序访问大量连续内存地址的过程中,其速率可近似为每个时钟周期访问一个内存数据。对于本文的模板匹配算法来说,每一次访存即是从一张完整的图片中选取一个16×16 的子图,也意味着每次只有16 个数据在内存中是顺序排列的,突发传输的长度被限制为16。实验结果显示,在突发传输长度为16,时钟频率为150 Mhz 的情况下,传输一张分辨率为1 024×1 024 的灰度图耗时约31 ms,如果选取的子图扩大为32×32,则突发传输的长度扩大为32,同样传输一张1 024×1 024的灰度图,则耗时约为19 ms。理论上子图宽度越大,访存时延越短,但是过大的子图纹理难以与模板图中的纹理对齐,获得的检测效果也越差;在不丢失图片几何特征的情况下,子图越小,越容易与模板图中的纹理对齐,获得的检测效果也越好。经实验,在大多数应用场景中分辨率为16×16 的子图在获得相对较好的检测效果的同时,也获得了相对较低的传输时延。
2.3.2 传输时延的优化
传输时延的优化主要通过时延折叠的方式来实现。该加速器的执行过程可抽象为3 个步骤:数据输入、数据计算、结果输出。由于三者是对同一组片上缓存中的数据进行操作,因此在未经优化的情况下这3 个步骤是一个串行的过程。常见的乒乓操作是例化两组片上缓存,在每组缓存上交替执行输入与输出的步骤,以实现输入与输出的时延折叠[14]。本文则进一步采用了三重缓冲的思想,例化了3 组片上缓存,将输入、计算、输出三者的时延折叠,在传统乒乓操作的基础上进一步优化传输时延,其时序图如图4 所示。

图4 采用三重缓冲后的时序图Fig.4 Time sequence with triple buffering
其中,同一种颜色代表同一组片上缓存,在某一时刻往第一组片上缓存中输入数据时,计算单元开始处理第二组片上缓存,同时将第三组片上缓存中的结果输出到内存中。3 组片上缓存交替执行各个步骤,构成一个三级流水线。
2.3.3 计算时延的优化
上文中提到完成一次模板匹配运算需进行m ×n × p × q次减法运算,因此对于16×16 的待检测子图及8×8 的纹理周期,完成一次模板匹配运算需进行16 384 次减法运算。如果加速器内只有一组运算单元,即使对整个运算过程进行了流水线优化,在运算单元的起始间隔为1 个时钟周期的情况下,仍旧需要16 384 个时钟周期才能完成一轮计算,完成一张1 024×1 024 图片的模板匹配运算,则至少需要447 ms。以16 的突发传输长度实现分辨率为1 024×1 024 图片的传输仅需31 ms,时延折叠方式,则会产生如图5 所示的时序图,此时的运算过程将成为性能瓶颈,因此需要对计算时延进行优化。

图5 计算时延优化前的时序Fig.5 Time sequence before computation delay optimization
虽然可以通过例化多组计算单元并行计算来达到优化的目的,但是模板图与待检测图存储在片上缓存即BRAM 中,而BRAM 本身的读写端口数是有限的,一般为两个,即一个时钟周期内只能读取两个数据。可将BRAM 进行分块,以此来增加接口数量,使得在一个周期内读取更多的数据,再通过例化多个计算单元实现并行计算[15]。
如图6 所示,将24×24 的模板图沿着x 方向划分成24 组数据,并存入24 块BRAM 中,将16×16的待检测图同样沿着x 方向划分成16 组数据,并存入16 块BRAM 中。每块BRAM 拥有两个端口,因此一个时钟周期内可读出32 组数据,同时再例化32 组计算单元实现并行计算,将原本16 384个时钟周期的运算时延缩减为512 个时钟周期。实测该方案为分辨率为1 024×1 024的图片进行模板匹配运算耗时约24 ms,此时的数据传输与计算过程的时延相差不大,时延得到充分折叠,时序如图7 所示,且消耗的资源也不多。

图6 BRAM 分块过程Fig.6 BRAM partition process

图7 计算时延优化后的时序Fig.7 Time sequence after computation delay optimization
如果将所有BRAM 彻底分块,即把模板图与待检测图的每一个数据都存储在一个单独的寄存器中,例化256 组计算单元,以实现在64 个周期内完成一次模板匹配运算,该方案虽然可行但是访存时延就会成为瓶颈,同时这种方案会消耗大量不必要的逻辑资源。
3 实验评估
3.1 实验环境
使用搭载Zynq-7020 芯片的Pynq-Z2 开发板,Zynq-7020 异构平台由双核ARM Cortex-A9 与Artix-7 FPGA 组成。其中FPGA 部分的资源包括可编程逻辑单元85 K、片上缓存BRAM 4.9 Mb、DSP切片220 个,双核A9 的时钟频率为667 MHz,板载512 MB 内存。采用工厂中常见的的4 K 工业线扫相机作为数据输入源,像素频率为24 MHz,该类相机每分钟可采集宽度约1 m、长度约85 m 的织物图像。开发板通过转接板扩展出Camera Link 接口与线扫相机连接。FPGA 部分除了包含模板匹配算法加速器,还集成了用于将Camera Link 差分信号解析为RGB 数据,并将RGB 数据转为AXI4-Stream 总线数据传入内存的一系列相关IP 核。其中模板匹配加速器的资源消耗见表1。

表1 模板匹配加速器资源耗费Tab.1 Template matching accelerator resource consumption
其中,LUT(Look-Up-Table)为查找表;FF(Flip Flop)为触发器;BRAMs为大小为36 Kb 的片上缓存数量;DSP(Digital Signal Processing)为数字信号处理器,以上均为FPGA 内部资源;f代表该加速器的工作时钟频率。
与之对比的通用PC 机,采用CPU i7-8750H,6 核12 线程,默认主频2.2 GHz,搭载16 Gb 内存,通过PCIE(peripheral component interconnect express)外接图像采集卡的方式来连接线扫相机。
在成本的方面,传统的PC 级板卡式结构中仅一张专业的Camera Link 图像采集卡价格就千元以上,一台高性能主机的价格也普遍在5 000 元以上。相比之下,一块搭载Zynq-7020 的开发板价格仅为1 000 元左右,成本降低了6 倍以上。
3.2 性能对比
本文设计的模板匹配加速器的处理效果在观感上与通用CPU 的处理效果一致,无论是通用CPU还是本文设计的加速器,都很好地消除了织物的纹理背景,凸显了瑕疵区域。由于本文中的模板匹配算法是以子图为单位进行处理的,因此处理结果存在轻微网格效应,通过OTSU 或TRIANGLE 自适应二值化及一些基本形态学操作后可以轻松消除这一现象,处理效果如图8 所示。此外,对织物原图进行诸如保边滤波、纹理提取等预处理步骤之后,再对纹理特征进行模板匹配,可以更好地消除噪声及光照不均所带来的干扰,获得更好的检测效果。

图8 加速器处理结果Fig.8 Accelerator processing result
在检测速度上,通用PC 与本文设计的加速器对比见表2。处理一张分辨率为1 024×1 024 的图片,使用同样的算法,基础频率为2.2 GHz 的i7-8750H 耗时0.324 s,无法跟上线扫相机24 MHz 的像素频率,时常出现漏帧现象。相比之下,本文设计的模板匹配加速器,在PL 部分时钟频率为150 MHz的Zynq-7020 平台上耗时仅为0.031 s,速度是CPU的10.5 倍,相当于33 MHz 的像素处理频率,该速率大于工业线扫相机24 MHz 的像素频率。工厂中普遍采用4 个像素覆盖1 mm 的织物长度,以此来估算,对于4k 分辨率的线扫相机,本系统每分钟可处理的织物面积约为120 m2,大于每分钟85 m2的速率要求,满足了实时性需求。

表2 本文加速器与通用PC 对比Tab.2 The accelerator compared with general PC
4 结束语
为了将织物瑕疵检测算法更有效地部署到实际生产环境中,本文对瑕疵检测领域的模板匹配算法进行了改进,为该算法设计了一种基于FPGA 的算法加速器,并对该加速器的各项处理时延进行了优化。最终该加速器在Zynq-7000 系列异构平台上获得了33 MHz 的像素处理频率,相当于每分钟可处理面积约120 m2的织物图片,满足了工业领域的实时性需求。设计过程中采用SoC 技术取代了传统的PC 级板卡式结构,使织物瑕疵检测系统的成本降低了6 倍以上。
