基于判别子字典学习的图像分类优化方法
2021-12-01钟佳莹吕文涛
赵 雅,钟佳莹,吕文涛
(浙江理工大学 信息学院,杭州 310018)
0 引言
历年来,判别字典学习算法在处理视觉跟踪、计算机视觉和图像处理等各个领域都有着广泛的应用。文献[1]提出了一种通过共享特征的、具有特征结构的字典学习算法,针对每一类样本进行字典学习,并对字典进行聚类,从而将同一学习字典下相关联的数据点聚集在一起。文献[2]将原始数据的局部关系,整合到基本字典学习框架中。DDL(Discriminant Dictionary Learning,判别字典学习)算法模型,考虑了类内局部信息和类间特征模糊性。由于判别字典学习依赖于预先设置的系数矩阵的初始值和样本数量,因此该方法不建议直接应用于类间特征模糊度较大的图像目标。
基于以上描述,本文在文献[3]的基础上,改进并提出了基于判别子字典学习的图像分类优化方法。在目标函数的基础上,构造一个子字典的低秩约束项、标签信息约束项和拉普拉斯矩阵正则化项。针对每一类图像,学习其对应的特定字典,使字典中包含该类别的特定原子,规避不同子字典之间原子的相关性。通过标签信息约束项,将大系数集中在某一类别的特定原子上,加强判别能力。同时将原始样本映射到一个新的空间中,使同一类别的相邻点彼此靠近,增强子字典对同类样本的重构能力。为了提高分类的准确率和规避特征图像的字典中的重复原子,在分类过程中引入重建残差,通过重建残差估计测试样本的类别标签,提高字典的判别能力,得到算法的分类准确率。
1 本文算法
1.1 字典学习模型构建
设DC =[d1,…,dK]∈Rn×K表示第C类样本的学习字典,表示第C类训练样本。在提出的快速低秩的判别子字典学习算法[3]的基础上,加强子字典的约束重构能力,结合样本的标签信息提出以下目标函数:

1.2 标签矩阵
针对不同类别的样本,为了提高字典的判别能力,通过标签矩阵使大系数主要集中在同一类别的原子上,尽可能地保留同一类样本的标签属性并减少其它类别原子产生的误差影响,如图1 所示。定义一个标签矩阵Hc∈RK×K,标签矩阵的系数可定义为:
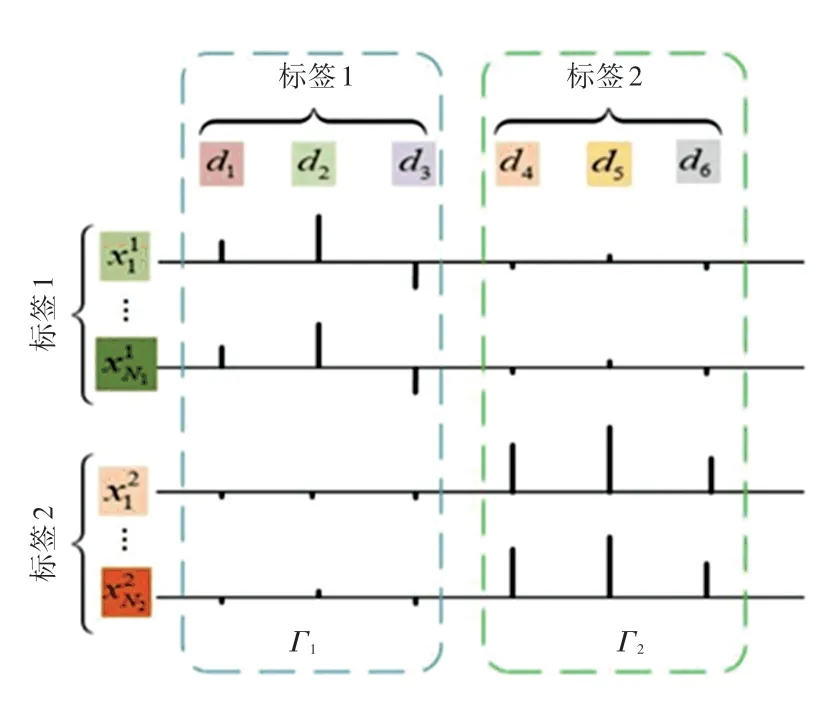
图1 标签矩阵示意图Fig.1 Schematic diagram of label matrix

其中,Hc(m,n)表示相应向量的第(m,n)个分量。
1.3 拉普拉斯正则化矩阵
对于目标函数中的拉普拉斯组正则化项,由于有C个不同类别的样本,因此构建图时,将属于同一类别的样本对应的顶点相互靠近并两两相连,构成一个紧密相连子图,从而形成C个互不相连的子图。已知训练样本和稀疏编码矩阵可以由一个N个点组成的直线来表示训练样本中第K个元素的图映射[1]:
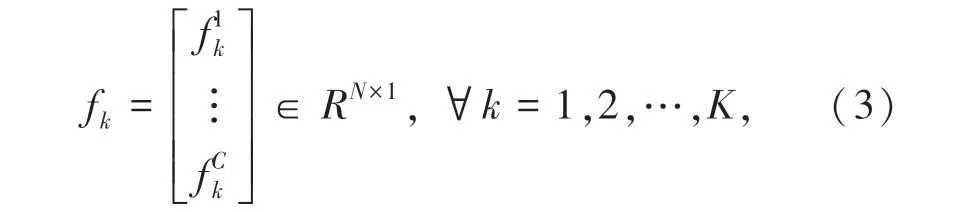
可以得到拉普拉斯映射中图的总间距:

则式(4)可以表示为:
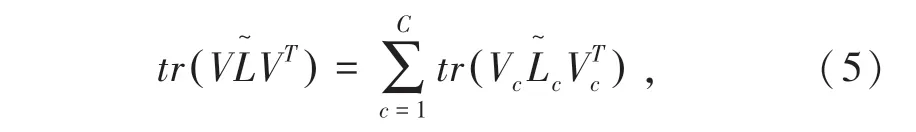
综上,对于第C类样本,本节所提出的目标函数可以表示为:
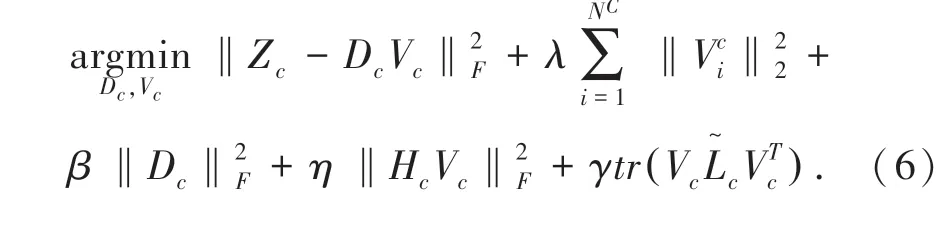
2 算法求解
由于目标函数现在是非凸函数,因此通过迭代逐步更新字典和稀疏表示矩阵来求解。本文分别从训练过程与测试过程上对算法进行分析。
2.1 训练过程
针对第C类样本,首先初始化学习字典和稀疏表示矩阵。随机初始化学习字典,在训练样本Zc中随机选取K个样本作为初始字典的原子。由基础的字典学习目标函数得到初始化的稀疏表示矩阵:

然后,固定字典,更新稀疏表示矩阵。由式(6)可以得到第C类样本的稀疏表示矩阵Vc:
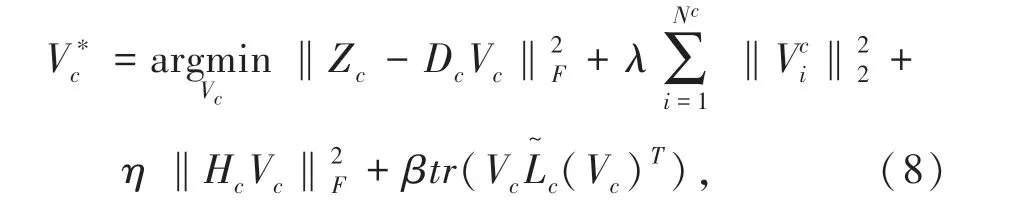
对第C类样本逐个更新稀疏表示矩阵,即
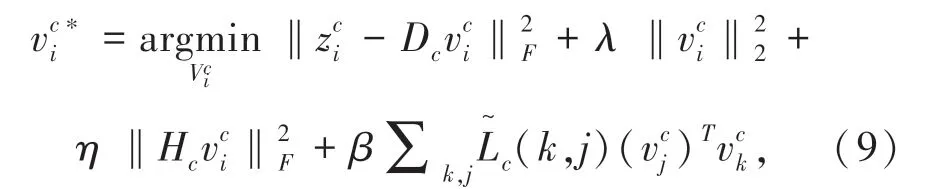
可以得到的解析解:
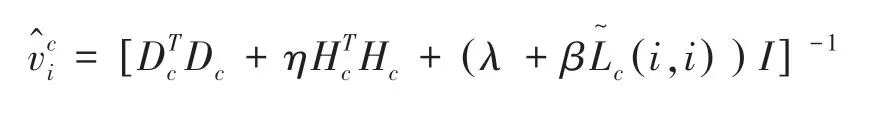

固定稀疏表示矩阵,逐列更新子字典。即第C类样本对应的字典求解公式为:

为了充分利用已经更新的字典,选择按原子依次更新字典,则式(11)可以改为:

对上式求解,可以得到
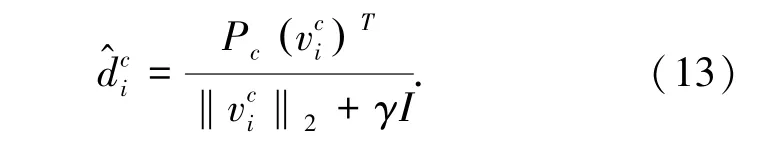
2.2 测试过程

理想情况下,所获得的稀疏编码向量中的原子,除了与zi所属类别相关的原子外,其它原子应为0。因此,针对这种情况,定义一个选择算子δi(),使获得的算子元素除了所属类标签的原子外,其余全部为0。对测试样本在这一子类上计算重建残差:

由于有C个子字典,因此测试样本zc可以得到C个重建残差,对每个重建残差进行判断,该测试样本的最佳类别就是其最小残差所对应的类别的归属类:
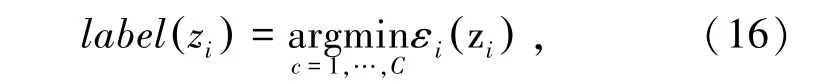
综上,基于子分类的判别字典学习图像分类优化算法步骤如下:
(1)输入训练样本Z =[Z1,…,ZC]以及参数λ、β、γ、η;
(2)计算:通过式(17)初始化。

(3)固定字典:通过式(10)逐列更新稀疏表示系数;
(4)固定稀疏表示系数:通过式(13)逐列更新字典;
(5)重复步骤3 和步骤4,直到算法收敛或达到所设定的迭代次数;
(6)输出学习字典Dlen。
3 实验结果与分析
本节将提出的新算法与多种方法进行比较。所有算法均基于Matlab R2016b 进行编写,并在联想天翼的windows 7 系统中运行,具有3.20-GHz Intel Core i5-6500 CPU 和4.0GB 内存。
(1)ExtendedYaleB 数据集[4]:由来自38 个人在64 种照明条件下的2 440张人脸图像组成。每类图像约有64 张,图像尺寸设置为192×168。选取每类的32 张图像作为训练集,剩余图像作为测试集。通过交叉验证获得参数,见表2。为了确保算法的准确性,选取10 次实验结果的平均值,作为最终准确率,其结果见表3。由此可见,本文所提算法具有更好的精度,且高于文献[3]的算法准确率。
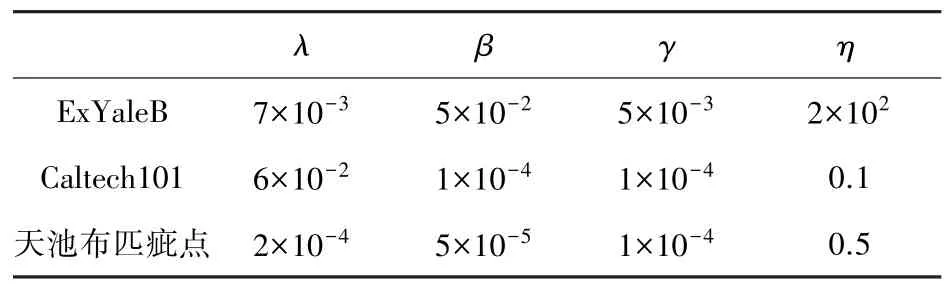
表2 不同数据集的参数设置Tab.2 Parameter settings on different databases
(2)Caltech 101 数据集[5]:由来自101 个对象类别和一个背景类别的9 144 幅图像组成。每类图像的张数不等,类别包含蝴蝶、美洲狮、美洲驼、人脸、手风琴、海豚等目标。该数据集中各类样本之间不仅千差万别,同类样本内也在形状上各有差异,该数据集具有较高的复杂性。针对该情况,本文实验选取了6 类图片,每类图像中选用32 张、64 张和80张进行训练,类别的剩余图片进行测试。
实验首先对每类图片进行特征提取,从16×16色块中提取筛选描述符,这些色块使用步长为6 的网格进行密集采样;然后基于提取的具有3x1、1、2x2 和4x4 网格的筛分特征提取空间金字塔特征[6]。采用标准的k 均值聚类训练,用于空间金字塔的码本,其中k =1 024。最后,PCA 将空间金字塔特征从21 504维缩减为3 000个维度。由表3 可见本文所提算法较其他算法获得了更好的性能。
(3)天池布匹疵点数据集:由32 类不同疵点共1 996张图像组成。每类图像张数不等,分别有擦洞、吊经、污渍、粗纱、破边等多种类别。将天池布匹疵点图像分为正常图像与疵点图像两种类别,选取每类200 张图像作为训练样本,剩余图像作为测试样本。图像尺寸均调整为256×256。在特征提取阶段,为了获得更准确的特征信息,将疵点图像等分为16×16 的图像块。对每个图像块进行LBP 算子子分类,然后对每个窗口提取GLCM 和HOG 特征,将所有图像块的特征组成该图像的特征向量,用来表示该图像的特征信息。以这种方法,使每个图像的特征信息以不同的结果多次出现在特征向量中。实验结果见表3,本文的算法精度同样取得了明显的提升。
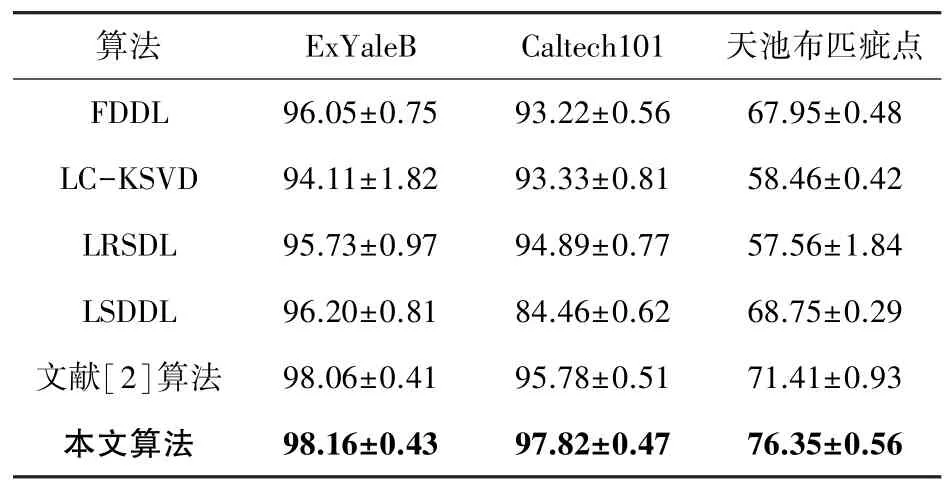
表3 不同数据集的分类准确率Tab.3 Classification accuracy on different databases
4 结束语
在本文中,研究了一个基于判别子字典学习的图像分类优化方法,主要针对如何减少类间模糊和类内差异的问题。通过拉普拉斯正则化矩阵、标签信息矩阵和字典约束项,设计特定于每个子类的字典,使子字典中包含该类别的特定原子,减弱不同子字典之间原子的相关性,放大该类别特定原子的系数,将样本的类别标签信息和空间几何结构整合到字典学习的目标函数中,从而增加子字典的判别重构能力。同时,本文在3 个不同的图像数据集上进行了实验,证明了该方法的可靠性。后续工作可以结合特定图像的特征提取方法,在图像分类、纹理识别等方面做进一步研究。
