基于改进的Cascade- RCNN 网络的人员检测算法
2021-12-01吉鹏飞
吉鹏飞
(浙江理工大学 信息学院,杭州 310018)
0 引言
行人检测目的是通过计算机自动识别当前画面中的行人并将其标定出来,是身份判定、姿态分析、目标追踪等研究的子任务。行人检测在视频监控、车辆辅助驾驶、智能交通等领域应用广泛[1]。影响行人检测准确率的主要因素有人员密集、背景繁杂、遮挡严重和目标形变等。目前行人检测主要分为基于传统机器学习和深度学习算法两种。
传统机器学习算法通过提取行人特征,如颜色特征、纹理特征等,通过分类器在图片中检测出所有目标。Vida 和Jones 等较早的提出了VJ 检测器并用于行人检测任务[2];Dalai 等提出了将HOG 结合SVM 用于行人检测[3];Wu 等提出了一种基于人体部件的Edgelet 特征,能够提高遮挡情景下的准确率[4];Felzenszwalb 等用DPM(Deformable Parts Model)算法检测行人,该算法能减弱人员形变带来的影响[5];P.Dollar 等提出积分通道特征(Integral Channel Feature,ICF)应用于行人检测、速度和精度有了很大提升[6];甘玲等采用聚合支持向量机(Ensemble SVM)分类器解决了正负样本数量相差过大的问题[7]。
深度学习算法主要是通过神经网络对大量的数据进行训练得到一个模型,图片输入后能直接找到所有目标。基于深度学习的行人检测算法可分为3类:
(1)基于深度置信网络(Deep Belief Networks,DBN),通过训练神经元间的权重,让整个神经网络按照最大概率来生成训练数据[8];
(2)基于卷积神经网络(Convolutional Neural Network,CNN)。双阶段CNN算法有 Faster-RCNN、MaskRCNN、CascadeRCNN 等,需要用算法先生成一定数量的候选框后才进行分类和回归,因此two-stage 准确率更高。单阶段CNN 算法如SSD,YOLO 等则直接进行分类和回归;
(3)基于循环神经网络(Recurrent Neural Network,RNN),是一类在其演进方向进行递归且所有节点按链式连接的神经网络[9];LSTM(Long ShortTerm Memory networks)是最常见的循环神经网络。
虽然目前行人检测准确率已经较高,但仍然存在许多问题:
(1)预测目标框不佳,尽管能够检测出目标,但包围框有较大冗余或和实际目标框存在一定程度偏移;
(2)漏检,当目标在检测画面中较小或遮挡较多,难以查询出所有目标;
(3)误检,将一些类人目标错误的判别成行人。
1 本文算法
1.1 Cascade RCNN 网络
Faster-RCNN 是一种双阶段目标检测网络,其结构如图1 所示。Faster-RCNN 与单阶段网络不同的是在通过由多个卷积层、激励层和池化层组成的骨干特征提取网络后,不是直接进行分类和回归,而是要经过一个RPN 网络,图1 中红线标注的部分即是RPN 网络,其目的是为后续精确的分类和回归网络提供一定数量的候选框。ROI Pooling 的作用是将RPN 生成的候选框转变成某一特定大小的框,为之后更细致的分类和回归任务提供方便。
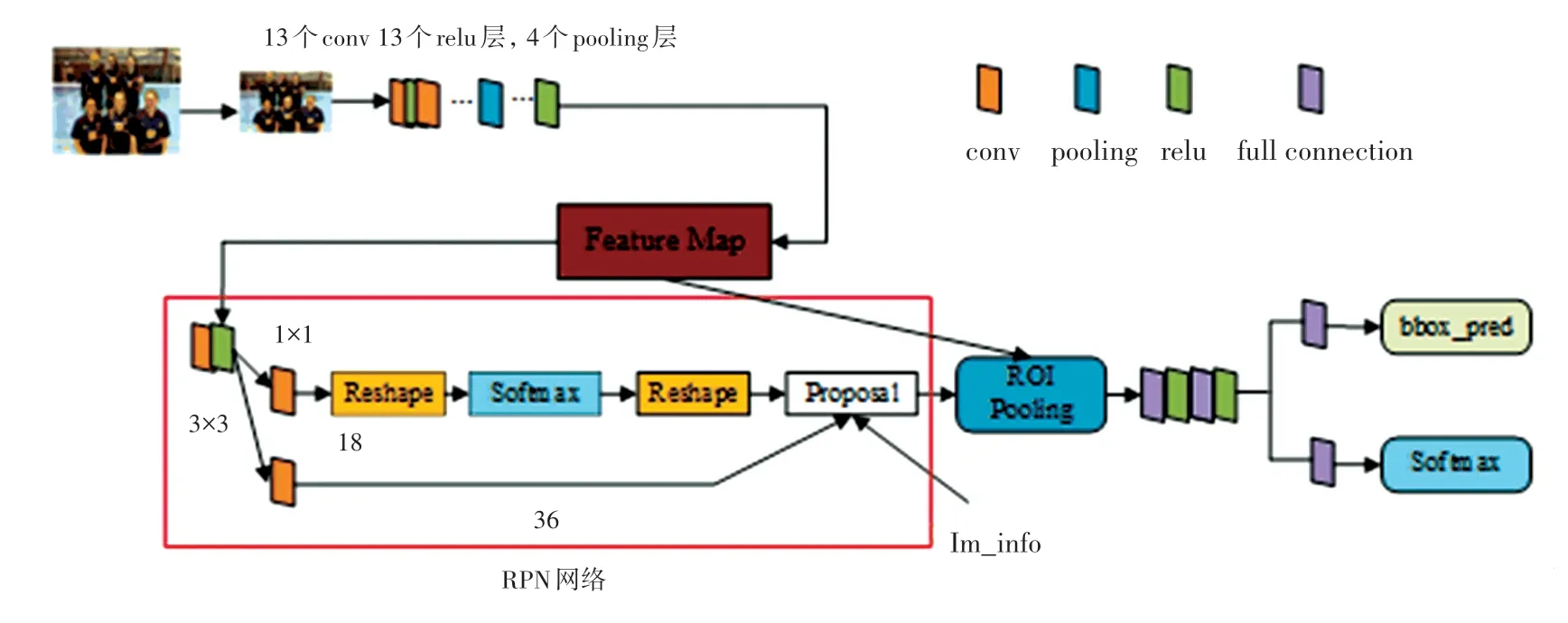
图1 Faster-RCNN 网络图Fig.1 Faster-RCNN network diagram
Cascade RCNN 是由Faster-RCNN 改进而来的,其结构如图2 所示。与Faster-RCNN 相比其最大的改进是级联多个不同IOU(Intersection over Union,预测框和实际框的交并比)的分类回归网络。通常IOU值较低时,会学习到很多背景特征信息,降低模型预测的准确率;而IOU值较高时尽管能够减小匹配的错误率,但这样会造成有效样本占比太小,出现过拟合的问题。Cascade R-CNN 是一种stage-bystage 的结构,上一个检测网络输出是后一个检测模型的输入,并且每个阶段的IOU阈值依次增加。与Faster-RCNN 一样,输入图片经过一个特征提取网络CNN 后,通过RPN 网络产生一定数量的proposals,图2 中B0就是proposals,与faster-Rcnn 一样要对这些proposals 进行精细的分类和回归,C 和B 分别代表分类和回归网络,H 代表网络头部。
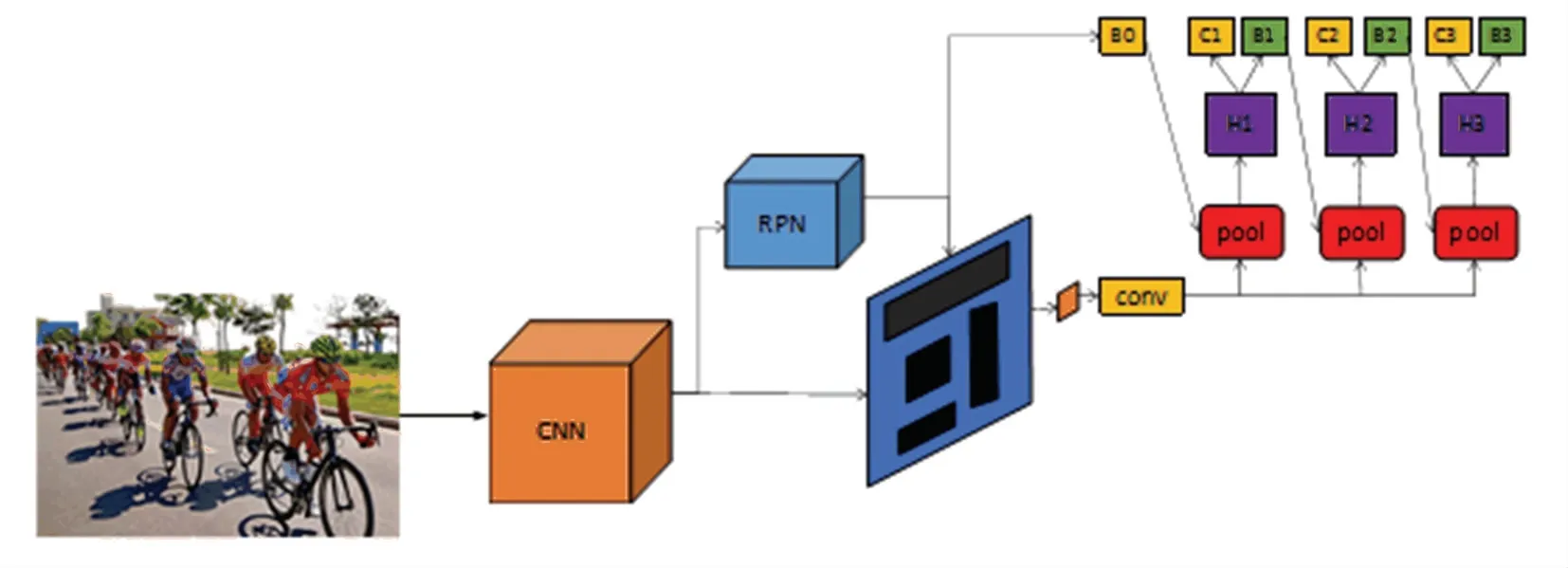
图2 Cascade RCNN 网络结构Fig.2 Cascade RCNN network structure
Cascade RCNN 的损失函数(1)为:
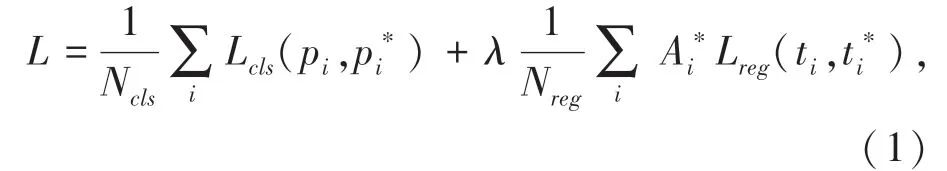
其中,pi和pi∗分别表示预测类别的概率和正负样本标签;ti和分别表示预测框和实际框的坐标;λ是回归损失占整个损失函数的比重。分类损失函数(2)为:
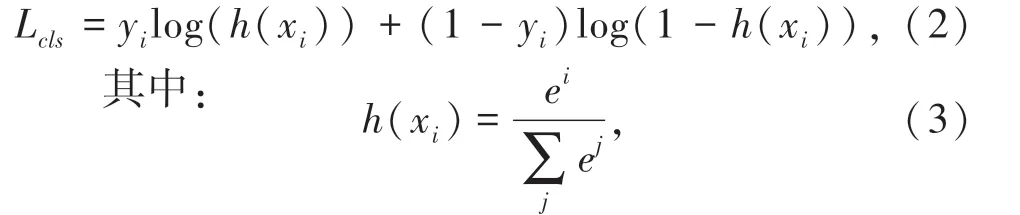
位置回归函数(4):
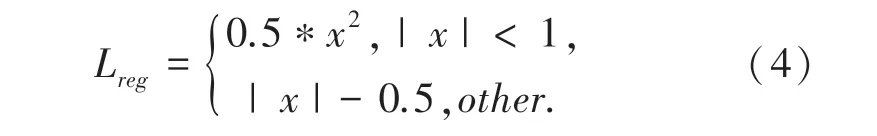
1.2 ResNeXt 特征提取网络
通常为了提升检测精度,会选择更加复杂的骨干特征提取网络,但这样会引入过多的参数,增加计算量。ResNet 是一种常用的特征提取网络,其结构如图3 左侧所示,学习的目标是目标值和输入的“差值”,这样能有效解决网络加深带来的梯度消失问题[10]。本文选用ResNeXt101 代替ResNet 作为最终模型的骨干特征提取网络,其结构如图3(b)所示,ResNeXt 瓶颈结构是在ResNet 基础上改进而来的。ResNext 用多路与ResNet 类似的拓扑结构的blocks 提取特征,最后融合多路特征,这样不仅可以减少计算量,而且模型拟合能力也得到了进一步提升。实践已经证明增加分组卷积的分支数比加深或加宽网络对准确率的提升更大。
1.3 生成更精确的预测框
与faster-rcnn 一样,为了更好地适应图片中目标形状、大小的变化,Cascade RCNN 也引入了anchor 机制,如图4 所示。在特征图上每个位置生成多个不同比例、不同尺度的anchor,每个anchor 都对应着原图一定大小形状的区域。Cascade RCNN有默认的anchor 尺度、长宽比,但如果用默认参数可能难以生成与实际需要相匹配的目标框。为此本文采用kmeans 聚类算法得到更适应实验数据集的anchor 长宽比例,其详细步骤为:
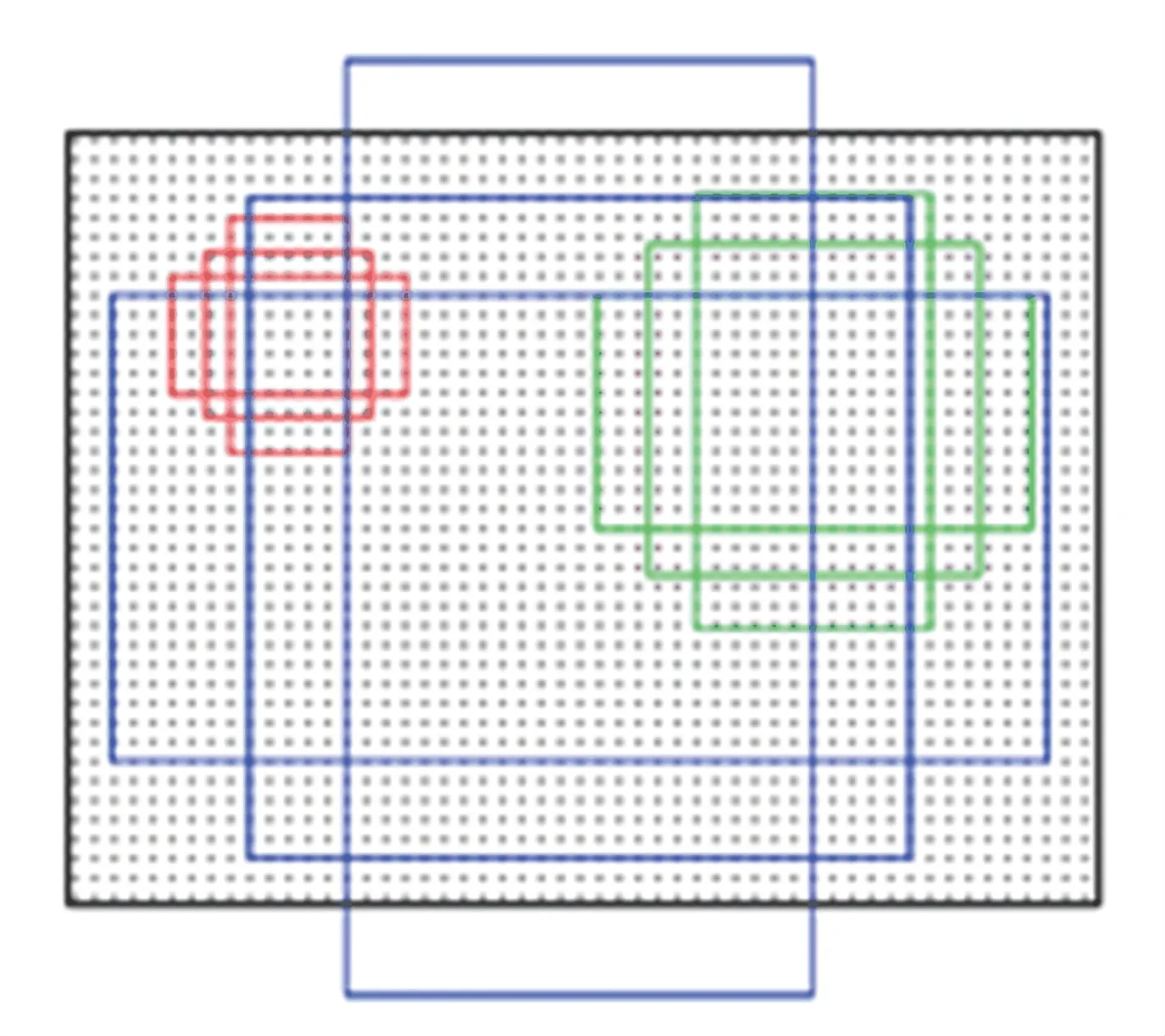
图4 anchor 机制Fig.4 Anchor mechanism
(1)将训练集中bounding box 对角坐标转变成高和宽的数据;
(2)在训练集中挑选k个bounding boxes 对k个anchor-box 初始化;
(3)算出所有的bounding box 和每个anchorbox 的IOU,将所有的bounding box 分类给与其误差d最小的anchor-box。用d(n,k)(d =1-IOU)来刻画第n个bounding box 和第k个anchor-box 间的误差;
(4)根据分类的结果找出每个anchor box 对应的bounding box 的长宽的中值,并用其来更新anchor box;
(5)重复上面的步骤,直到bounding box 的分类已经不再更新。
本文采用了多尺度训练和测试的方法,能够学习不同尺度目标下的特征,提高了模型的适应能力。实验中将训练集和测试集同时放大一定比例(双线性插值)一定程度上可以提高小尺度目标的检测准确率。
对于同一目标,根据模型可能会在其周围生成若干重叠率较高的预测框,如图5 所示。通常本文用NMS 只留下置信度最高的框,将其余的框排除。本文通过WBF(Weight BoxFusion)方式融合多个模型的结果,提高了目标检测的准确率,其可以修正单个模型预测不精确的问题,消除冗余的边界框,最终预测框坐标是多个模型预测框的坐标加权和,权重为相应的边界框置信度[11]。
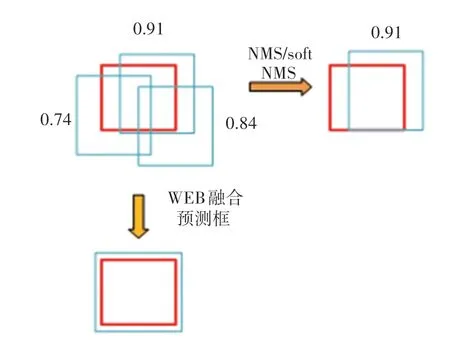
图5 NMS 和WBF 处理重叠框Fig.5 NMS and WBF processing overlapping boxes
WBF 的主要步骤:
(1)将N个模型的所有预测框按得分降序输入到List B 中;
(2)新建两个空的ListL和ListF。遍历B,在F中寻找和其匹配的框(IOU >阈值),如果找到,就将其插入到L[i]中,i表示该框在F中的下标;如果未找到,直接将其插入到L和F的末尾;
(3)利用L[i]处所有的m个框(L与F可能是一对多的关系)加权计算F[i]框的坐标(x1,y1,x2,y2)和得分C,式(5)~式(7):
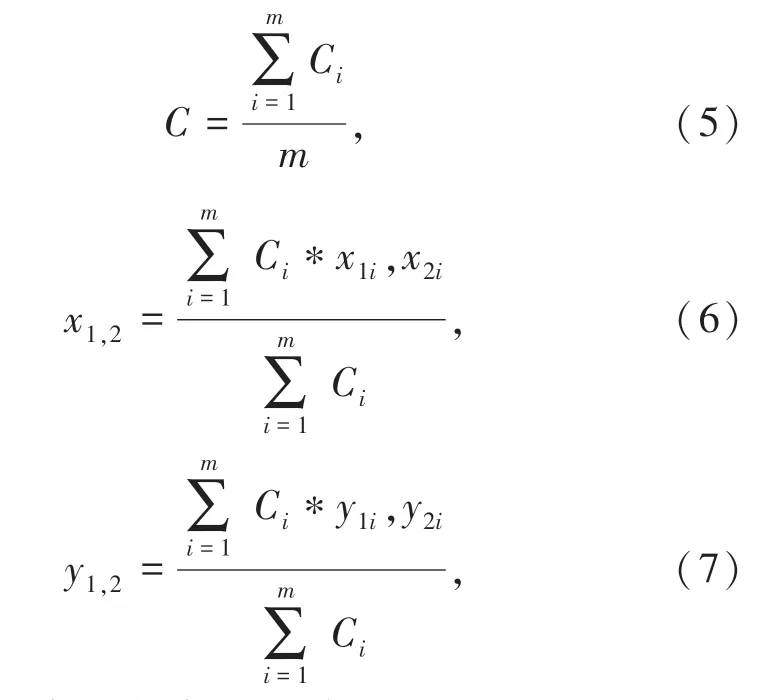
(4)如果B 中每个框都处理完了,再次对F得分更新,式(8):
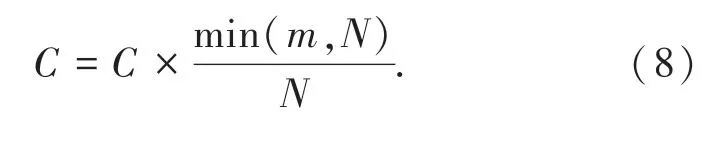
1.4 SWA 融合多模型
为了提高训练出的模型的稳定性和泛化能力,本文采用了SWA(Stochastic Weight Averaging)方法融合多个训练周期的模型,该方法可以在一定程度上提高目标检测的准确率,并且不会增加额外的计算量[12],融合第i轮模型后的公式(9):
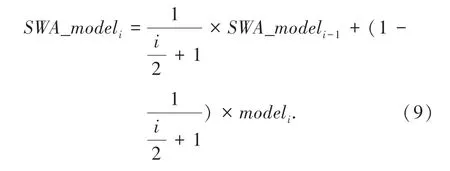
本文一共训练20 轮得到20 个模型。根据式(9),本文采用第9~19 轮阶段参数模型加权融合为最终模型。
2 实验设计及结果分析
2.1 实验环境及数据集
实验基于CentOS 操作系统,Python3.6,pytorch1.4,cuda10.1,GPU 型号为tesla T4,显存为15G,CPU 型号为Intel(R)Xeon(R)Silver 4110,2.10GHz。实验用的人体检测数据集是Crowd-Human,训练和测试的图片有1.5w 和5k 张,共340k 个人体目标,并且有场景多样、尺度各异,部分目标还存在一定的遮挡。
为了增加数据集的多样性,提高模型的泛化能力,本文尝试了一些数据增强方法,如水平翻转、GridMask、高斯模糊、颜色抖动等。实验学习率初始值为12×10-4,一共经历20 轮训练。
2.2 实验设计及实验评价指标
CrowdHuman 数据集采用JI(Jaccard Index)评测,被定义为式(10):
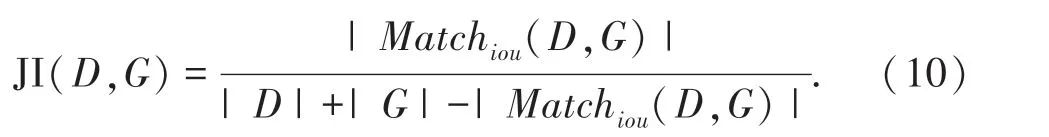
其中,|D |和|G |分别表示预测框和标注框的数量,|Matchiou(D,G)|是两者匹配的数量(评判标准是IOU >Threshold),本文IOU阈值为0.5。
为了证明提出的改进之处的实用性,本文主要设计了3 个实验:ResNeXt101 代替ResNet 实验、kmeans 聚类算法生成anchor 长宽比实验和引入WBF 算法实验。
2.3 kmeans 生成anchor 比例前后对比实验
通过观察训练集,发现大多数对象的纵横比都大于1.0,为了得到更好的纵横比的anchor,本文采用kmeans 聚类算法得到anchor 的长宽比为[1.05,1.84,3.21],为了使用方便,本文将其取整[1.0,2.0,3.0](Cascade- RCNN 默认的比例为[0.5,1,2])。由于实验数据集中的图片尺度差异较大,其短边几百像素至几千像素不等。为此,本文通过多尺度训练的方式将训练集中的图片短边做一定程度的缩放或放大,长边按相同比例缩小或放大,结果见表1。

表1 kmeans 得到anchor 比例前后对比结果Tab.1 Comparison results before and after the anchor ratio obtained by kmeans
从表1 中对比发现1 440~1 760 的训练尺度较较小的704~1 024 尺度得分大幅提高,提高了4.7%(数据集中有较多的小目标),用kmeans 聚类算法能够获得更好的包围框,其准确率提升了0.7%。
2.4 ResNeXt 作为骨干网络及引入WBF 实验
为测试不同骨干特征提取网络的性能,本文选择了Res50、Res101 和ResNeXt101 作为特征提取网络。同时为了提高准确率,将Res101 和ResNeXt101 得到的模型通过WBF 算法融合预测框,最后加入kmeans聚类算法,得到最终目标检测结果,见表2。
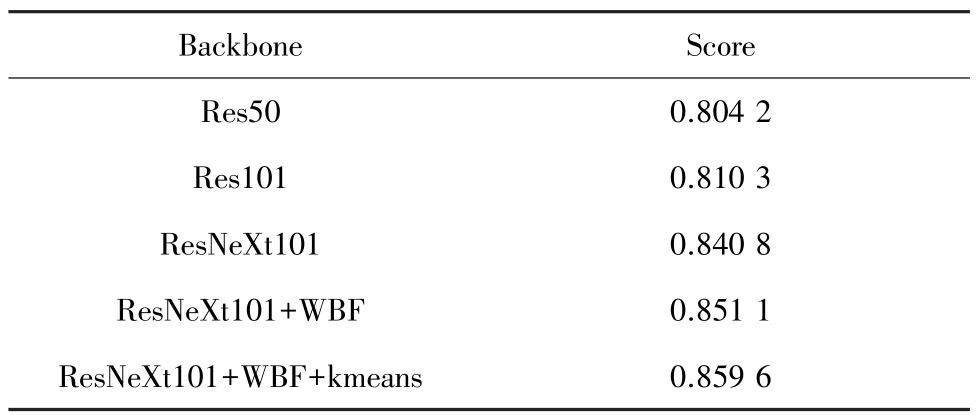
表2 不同特征提取网络对比实验Tab.2 Comparison experiments of different feature extraction networks
从表2 可以看出,更深层次的Res101 比浅层的Res50 特征提取网络效果要好,融合多路特征的ResNeXt101 网络比Res101 得分提高3.7%,使用WBF 融合后得分提高约1.2% 。实验结果显示ResNeXt 作为骨干网络比ResNet 性能有很大提升,用ResNeXt101 和Res101 做WBF 融合后较未融合前准确率也有一些提升,最后加入kmeans 聚类算法,较基础Cascade RCNN 整体性能提升近6%。提升前后的对比如图6 所示,图6(a)标注的1 和2 框均要比左侧的更好,同时发现当遮挡较严重时,本文的算法也很难检测出来。

图6 算法提升前后对比图Fig.6 Comparison chart before and after algorithm upgrade
3 结束语
在人员密集的场景下,难免会发生遮挡、较大程度的形变等问题,本文提出的基于改进的Cascade-RCNN 的目标检测网络能够有效提高目标检测的准确率,减小漏检的概率。实验结果表明用ResNeXt101网络作为基础骨干网络,在不增加计算量的基础上融合多路特征,能够获得更细致的特征进而提高检测的准确率。用本文所述的kmeans 聚类算法得到的anchor 比例能得到更适合当前数据集的目标框,通过WBF 算法融合多个模型的检测结果能够得到更加准确的预测框。整体而言,改进的Cascade-RCNN 算法较基础的Cascade- RCNN 算法的人员检测性能有很大提升,但对于一些重叠较大、尺度过小的目标,本文的方法依旧无能为力,这也是后续研究的难点。
