基于数字孪生和概率神经网络的矿用通风机预测性故障诊断研究
2021-11-30经海翔黄友锐徐善永唐超礼
经海翔, 黄友锐, 徐善永, 唐超礼
(安徽理工大学 电气与信息工程学院,安徽 淮南 232001)
0 引言
矿用通风机工作环境恶劣,工作时间长,一旦发生故障,会造成井下循环风量不足,瓦斯及其他有害气体浓度超限,导致重大安全事故的发生[1-2]。通风机的安全运行是保障矿工生命与井下安全作业的基础,对通风机进行实时监测与预测性故障诊断具有重要意义。
现有通风机故障诊断方法主要有基于信号处理、基于数学模型和基于机器学习的方法等。基于信号处理的诊断方法通过小波分析[3]、傅里叶变换[4-5]等方法分析信号时频特性与故障类型之间的关系,以实现故障诊断。这些方法不需要数学建模,实现简便,但是无法全面地提取信号特征,造成诊断结果误差较大。基于数学模型的故障诊断方法需建立能反映物理设备特性的数学模型,通过分析模型中输入量与输出量的对应关系,实现故障诊断[6-7]。但是很多设备的结构与运行规则相当复杂,其数学模型建立困难,甚至无法建立,导致这些方法实际应用很难实现。基于机器学习的故障诊断方法包括BP神经网络算法[8]、支持向量机[9]等,这些方法都是基于故障特征进行故障诊断,需用不同的方法提取多个故障特征,使用较为繁琐且故障诊断准确率较低。
针对现有通风机故障诊断方法存在的问题,本文提出了一种基于数字孪生和概率神经网络(Probabilistic Neural Network,PNN)的矿用通风机预测性故障诊断方法。搭建了通风机数字孪生模型,并以其为基础建立了通风机的预测性故障诊断模型。采用改进的鲸鱼优化算法(Improved Whale Optimization Algorithm, IWOA)优化的PNN对样本数据进行故障分析判别。对比通风机预测性故障诊断模型判断结果与实际情况是否相符,若判别错误,预测性故障诊断模型便会更新,重新学习故障规律,以此提高矿用通风机故障诊断的准确率。
1 通风机数字孪生模型构建
通风机数字孪生模型包括几何模型、物理模型、行为模型和规则模型4个部分,可实现通风机物理实体与虚拟空间数字孪生体的实时映射[10-11]。通风机物理实体及其数字孪生体如图1所示。
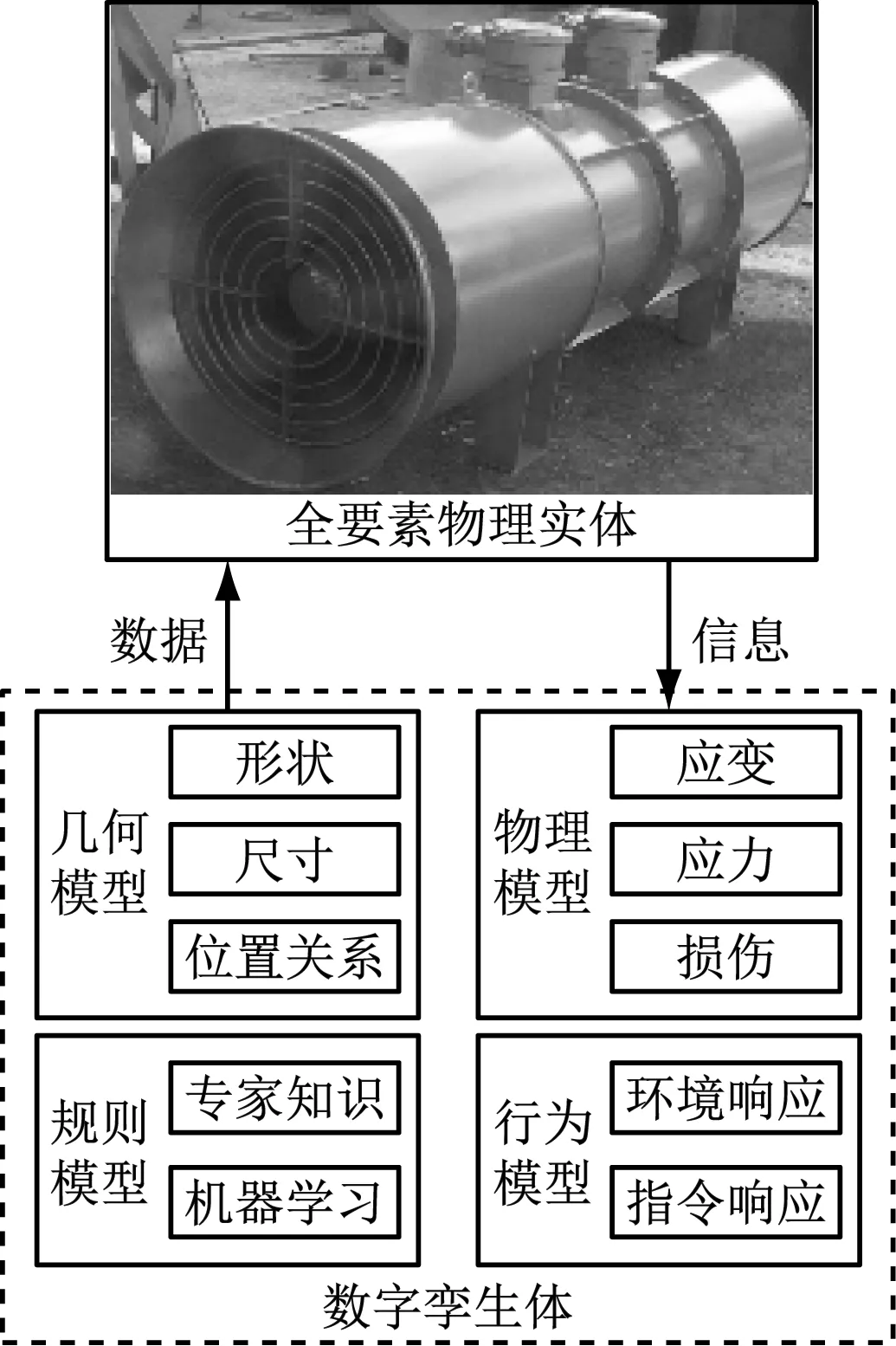
图1 通风机物理实体及其数字孪生体
(1)几何模型包括通风机的叶片长度、叶轮轮壳倾角、轴向间距等参数,体现了通风机内外部件的形状、尺寸和对应位置关系。使用Unity3D与3dsMax来构建模型。首先确定通风机整体及其子部件的形状与尺寸,然后在3dsMax中对子部件进行建模,建模完成后将子部件组合成整体即为通风机的几何模型,最后对模型进行轻量化处理,轻量化后的模型以fbx的格式导出。将导出的fbx文件导入Unity3D中,统一模型比例,将模型属性的缩放由0.01改成1,并在模型上以贴图的方式添加采集的真实通风机部件图片,使模型与真实设备外观更为相似。
(2)物理模型对应通风机实体的物理属性,如应变、应力、损伤等,是对通风机本身物理状态的实时映射,使用有限元分析软件SciFEA描述其物理属性。
(3)行为模型包括通风机对内外部环境和系统指令的动作响应,实现了通风机运行动作的实时映射,利用Petri网描述通风机系统的行为逻辑。
(4)规则模型是基于专家知识和机器学习将经验、历史关联数据、当前数据与通风机运行状态进行总结,挖掘设备的故障规则,从而提供故障预测功能。
通风机物理实体由PLC控制,Unity3D中的插件PREspective支持解读多种工业通信协议,可与不同厂家的PLC通信,获取通风机的实时数据,同时结合物理模型、历史运行等数据使物理实体被精确地映射到虚拟空间,从而达到虚实交互。
基于数字孪生的通风机预测性故障诊断模型如图2所示。其中物理实体由真实的通风机和监测设备(如传感器)所构成。数字孪生体是物理实体在虚拟模型中的实时映射。孪生数据存储中心是通风机关联数据的存储器,包含通风机物理实体的历史数据和实时数据以及通风机数字孪生体的几何模型数据、物理模型数据和行为模型数据。故障诊断服务是结合通风机的机械故障与动态信息的诊断方法,可提取设备故障数据,建立故障规律与故障数据特征值的对应关系。

图2 基于数字孪生的通风机预测性故障诊断模型
通风机预测性故障诊断模型是以数字孪生模型为基础,结合专家知识、机器学习、历史数据搭建的,通过分析通风机的实时数据与运行状态之间的关系,不断学习并更新模型参数。当通风机处于正常工作状态时,仅需要将其运行数据保存到孪生数据存储中心;当通风机发生故障时,不仅要把故障数据保存到孪生数据存储中心,还需要采用专家知识与机器学习等方法对设备故障进行预测性诊断。若诊断结果不正确,则需要对通风机预测性故障诊断模型中的参数进行修正,直到故障判断准确。基于数字孪生的预测性故障诊断模型可以实现通风机的智能诊断与科学运维。
2 基于IWOA的PNN优化
2.1 PNN
PNN结构简单,训练速度快,是一种基于贝叶斯决策的前馈神经网络。PNN网络由输入层、隐含层、求和层和输出层[12-13]组成,如图3所示。通风机的实体数据实时更新至数字孪生模型中,利用PNN进行分析判别。
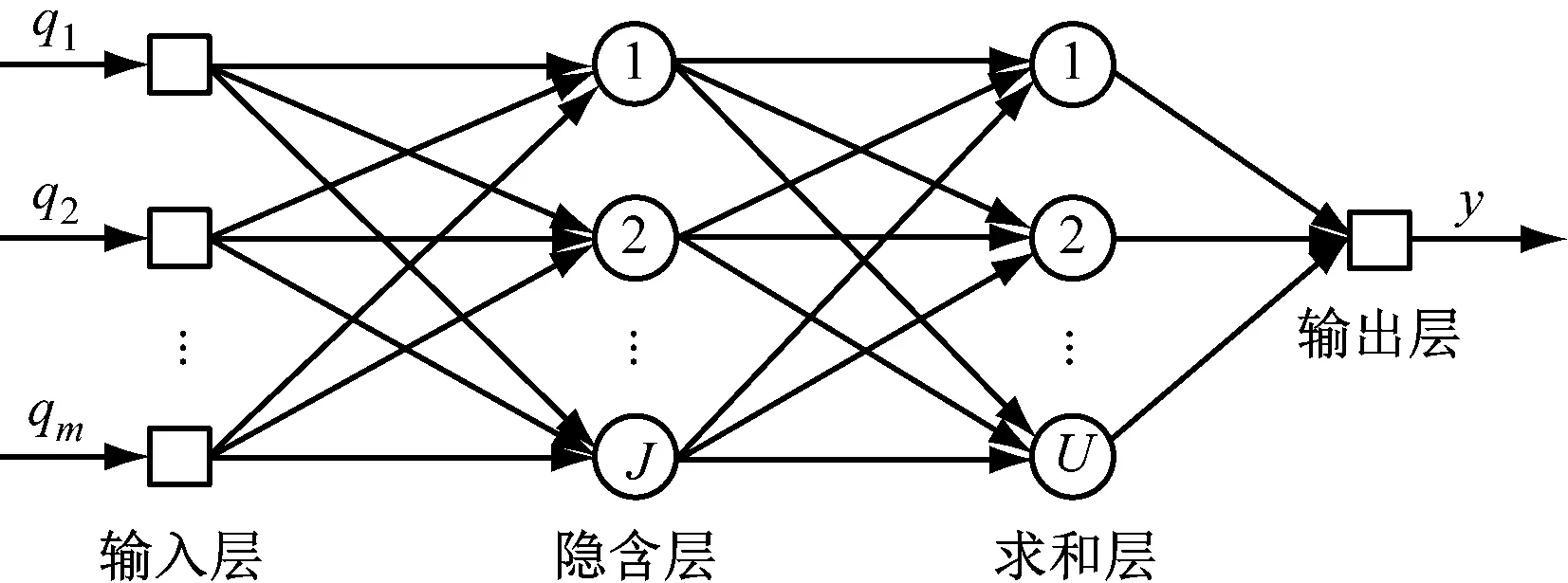
图3 PNN结构
输入层传递样本给隐含层,其神经元的个数与输入向量的维数相等。隐含层神经元个数与训练样本个数相等,J为隐含层神经元个数,U为训练样本类别数,y为输出层输出。训练样本每个模式与输入层之间的关系如下:
(1)
式中:q为输入的训练样本;qij为第v(v=1,2,…,m,m为训练样本维度)维训练样本的第j(j=1,2,…,J)个神经元的输出;σ为平滑因子。
根据贝叶斯分类原理,从求和层中找出阈值最大的概率密度函数作为分类结果。概率密度最大的输出为1,其余为0。
2.2 基于IWOA的PNN平滑因子优化
PNN不需要多次训练,但其平滑因子σ的值一般由人为给定,不能准确地描述样本的概率特性,所以PNN判别是否精准在于能否找到一个合适的σ值。本文采用IWOA对PNN的σ值进行寻优。
2.2.1 鲸鱼优化算法
鲸鱼优化算法(Whale Optimization Algorithm, WOA)于2016年被提出,是模拟自然界座头鲸的捕食过程而形成的一种新型群智能优化算法,原理简单、参数少、方便改进与实现。研究学者发现,WOA对神经网络中神经元的训练具有良好的效果,其收敛速度优于现有的算法,并且在大多数时刻都可以避免陷入局部最优[14-15]。在WOA中,目标是座头鲸搜索目标猎物时的最优解[16-17]。在本文中,座头鲸搜索目标猎物时最优解即是输出最优σ的鲸鱼位置。WOA的数学模型一般被描述为以下3个方面:
(1)包围猎物:座头鲸在狩猎时包围猎物的生物行为的数学模型为
D=|CX*(t)-X(t)|
(2)
X(t+1)=X*(t)-AD
(3)
式中:D为当前鲸鱼个体与最优鲸鱼个体之间的距离;C为系数向量,它的变化可以调整围绕最优鲸鱼个体的不同位置;X*(t)为最优鲸鱼个体所处位置,t为当前迭代次数;X(t)为当前鲸鱼个体所处位置;X(t+1)为鲸鱼个体下一时刻所处位置;A为系数向量,决定当前鲸鱼个体的步长,A越大,鲸鱼包围的步长也越大。
C=2r2
(4)
A=2a(r1-1)
(5)
(6)
式中:r1和r2为[0,1]范围内的随机数;a为控制参数向量,其取值从2减小到0,a的值影响A的取值,从而影响鲸鱼下一步的生物行为;Tmax为算法设定的最大迭代次数。
(2)捕食目标猎物:座头鲸发现猎物后,它们以螺旋状的捕食路径不断地逼近猎物。其狩猎行为的数学模型为
X(t+1)=X*(t)+Dpexp(bl)cos(2πl)
(7)
式中:Dp为当前鲸鱼个体与目标猎物之间的距离,Dp=|X*(t)-X(t)|;b为用来描述螺旋线形状的常数;l为[-1,1]范围内的随机数。
分析座头鲸捕食猎物的过程后发现,在追寻目标猎物的下一时刻点,它们会继续螺旋前进或选择收缩环绕,故定义有50%的概率进行其中某种行为。
(8)
式中k为[0,1]范围内的随机数。
收缩环绕是通过a的线性缩小实现的。由式(5)、式(6)可知,A的取值范围为[-a,a],当A处于[-1,1]时,表示鲸鱼的下一时刻处于当前个体与最优个体之间。
(3)搜索猎物:座头鲸在随机搜索猎物的过程中可能会出现A在[-1,1]范围之外的情况,此时的随机搜索个体称为搜索代理。鲸鱼优化算法设定搜索代理将远离当前最优个体,随机更新位置进行全局搜索,以此找到一个更合适的猎物。其过程的表示方程为
D=|CXrand-X(t)|
(9)
X(t+1)=Xrand-AD
(10)
式中Xrand为随机的搜索代理。
2.2.2 IWOA及其性能测试与分析
WOA具有参数少、运算快的优点,但其在处理较为复杂的非线性问题时还是会出现收敛速度慢和精度低的问题。因此,需要对其进行改进。
由于在WOA中,鲸鱼个体以最优鲸鱼位置来不断更新自身位置。为了增强WOA的局部寻优能力,对其位置公式进行改进,使鲸鱼下一时刻位置受到全局最优位置的引导,不断趋于全局最优位置,在多次迭代之后,局部最优位置将与全局最优位置重合,加快了算法的收敛速度。改进鲸鱼位置公式为
X′(t)=w×s1+(1-w)G
(11)
式中:X′(t)为改进后的目标鲸鱼位置;w为常数,恒等于0.5;s1为鲸鱼搜索代理的局部最优位置;G为全局最优位置。
众所周知,群智能算法的种群数量影响算法性能。种群数量过少会导致算法的搜索代理个数太少,很难找到较好的初始点进行寻优;种群数量过多,会大幅增加寻优时间,并且结果可能不会有很明显的提升。
为了得到最合适的种群规模,本文将鲸鱼种群数量分别设置为10,20,30,40,50,采用2个单峰基准函数和2个多峰基准函数对不同种群数量的IWOA进行测试。4个基准测试函数见表1,其中xi为自变量,i=1,2,…,n,n为维度。单峰基准函数测试结果见表2。

表1 4个基准测试函数

表2 单峰基准函数测试结果
由表2可看出:f1(x)、f2(x)测试时,鲸鱼种群数量超过30时,f1(x)和f2(x)的最优值仅仅上升了几个数量级。
f3(x)、f4(x)测试时,5种种群数量的IWOA都寻到了最优值,通过比较它们达到最优值时的迭代次数,发现种群数量超过30时的迭代次数没有明显的减少。故将IWOA的种群数量设置为30最为合理。
为了测试IWOA的性能,将其与WOA、粒子群算法(PSO)、遗传算法(GA)进行比较。在对比前,先要对IWOA和对比算法进行参数设置:WOA的种群数量为30,最大迭代次数为500;IWOA的种群数量为30,最大迭代次数为500;PSO的种群数量为30,每个粒子个体学习因子c1为2,社会学习因子c2为2,惯性权重为0.9,最大迭代次数为500;GA的种群数量为30,交叉概率为0.8,变异概率为0.2,最大迭代次数为500。然后利用单峰基准函数f1(x)和f2(x)测试算法的收敛速度与精度,利用多峰基准函数f3(x)和f4(x)测试算法的全局寻优能力。
(1)单峰基准函数性能测试:GA、PSO、WOA、IWOA在单峰基准函数寻优时的进化曲线如图4、图5所示。由图4、图5可看出:在迭代初期,IWOA收敛速度与WOA、GA和PSO相差不大,但从20次迭代开始直到迭代结束,IWOA的收敛速度都明显快于其他3种算法。其收敛精度也是最好的,说明IWOA不论在寻优速度还是在收敛精度上都优于WOA、GA和PSO。

图4 GA、PSO、WOA、IWOA在单峰基准函数f1(x)寻优时的进化曲线
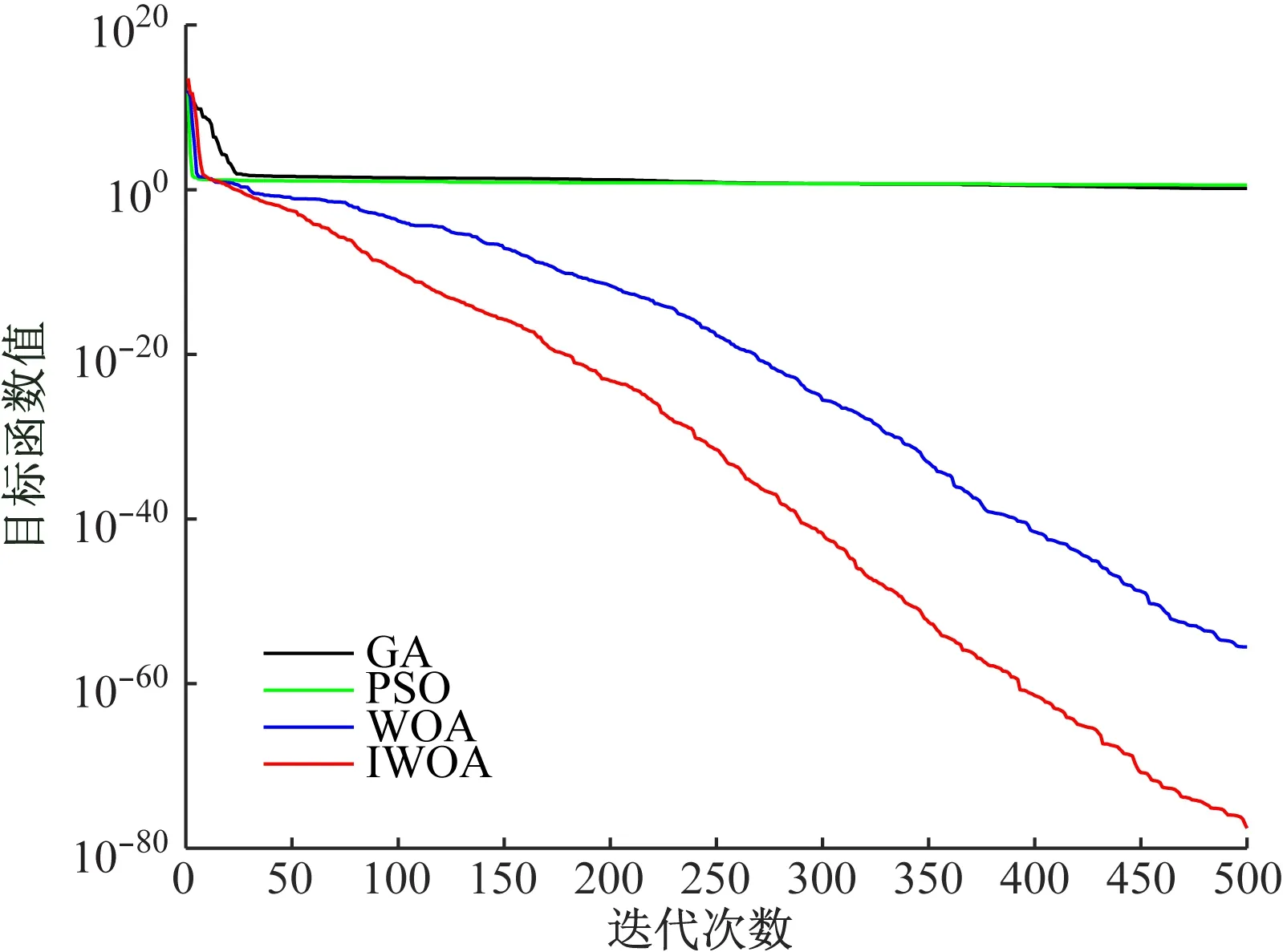
图5 GA、PSO、WOA、IWOA在单峰基准函数f2(x)寻优时的进化曲线
(2)多峰基准函数性能测试:GA、PSO、WOA、IWOA在多峰基准函数寻优时的进化曲线如图6、图7所示。由图6、图7可看出:IWOA的收敛速度明显快于其他3种算法,在150次迭代以内就可以寻找到全局最优解,并且其进化曲线出现拐点的时间最短,说明IWOA更容易跳出局部最优,完成全局寻优。
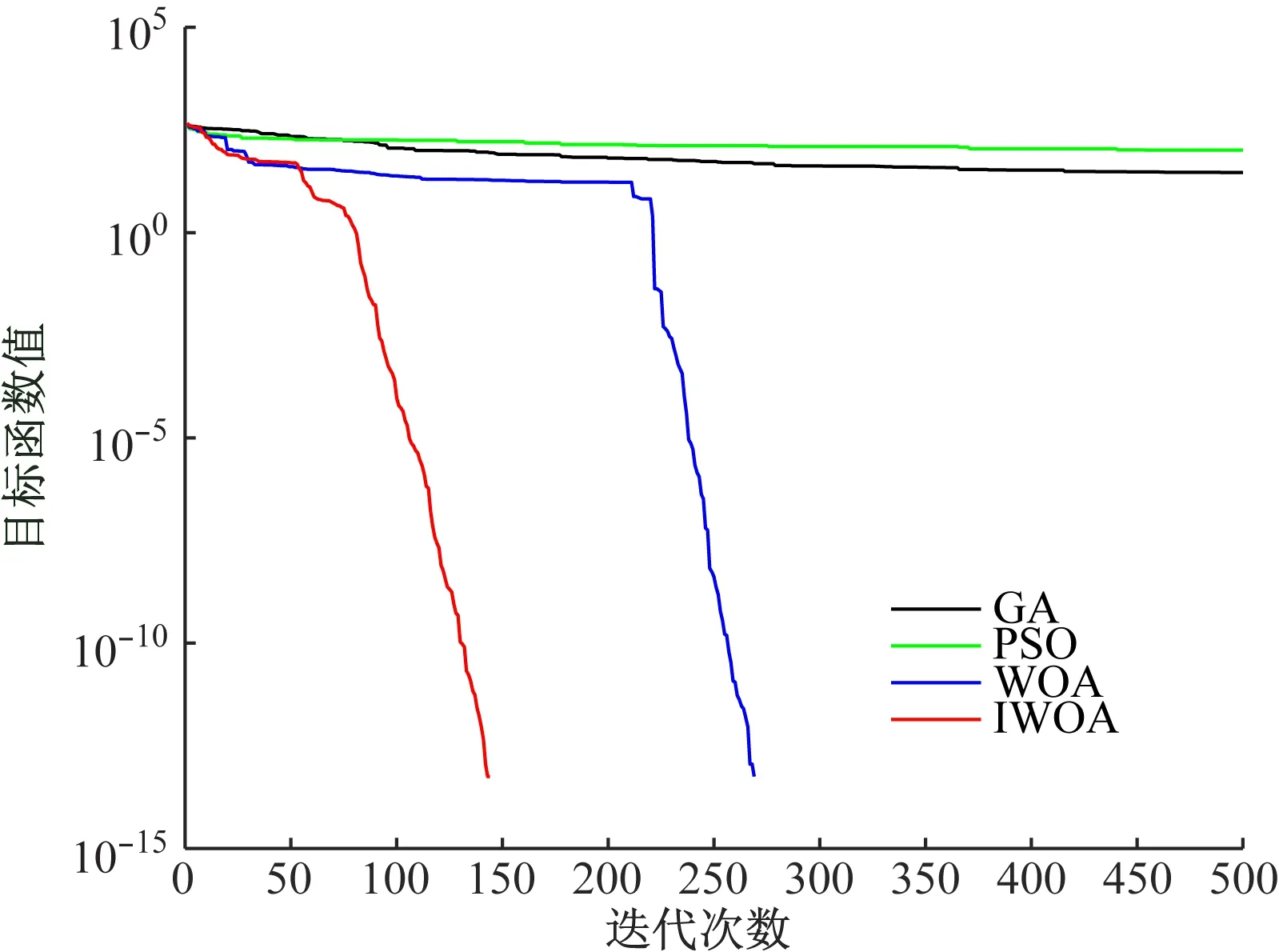
图6 GA、PSO、WOA、IWOA在多峰基准函数f3(x)寻优时的进化曲线

图7 GA、PSO、WOA、IWOA在多峰基准函数f4(x)寻优时的进化曲线
2.2.3 平滑因子优化流程
为了提高PNN的故障诊断速度和精度,采用IWOA来优化PNN的平滑因子。
(1)归一化故障样本数据,对故障种类进行编号,确定适应度函数为PNN输出值和真实值的均方差。
(2)设置鲸鱼优化算法的种群规模、迭代次数,并随机初始化鲸鱼位置。
(3)计算鲸鱼个体的适应度值,并通过式(3)、式(8)、式(10)和式(11)来更新鲸鱼个体下一时刻的位置。
(4)计算适应度函数的值,当适应度取得理论最优值或者达到最大迭代次数,记录当前最优鲸鱼位置并进入步骤(5),否则返回步骤(3)。
(5)输出最优鲸鱼位置,此时的σ值为IWOA求取的最优值,将最优σ值赋予PNN,即可获得最精准的PNN。
3 基于数字孪生和PNN的通风机预测性故障诊断
基于数字孪生和PNN的通风机预测性故障诊断流程如图8所示。
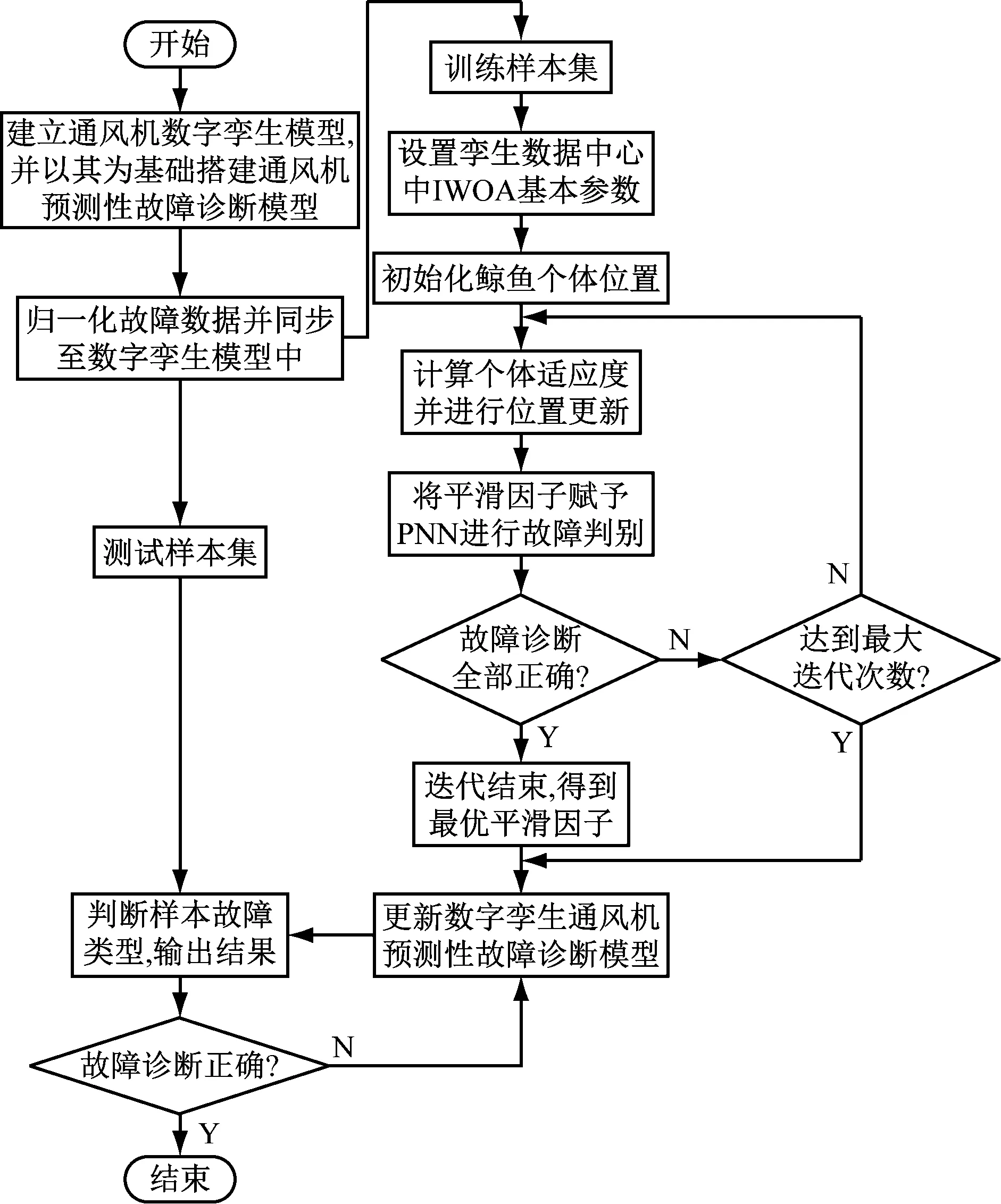
图8 基于数字孪生和PNN的通风机预测性故障诊断流程
(1)建立高保真度的通风机数字孪生模型,并以数字孪生模型为基础,结合专家知识、机器学习、历史故障数据等搭建通风机预测性故障诊断模型。
(2)将归一化后的故障数据分为训练集与测试集同步至数字孪生模型中。
(3)采用IWOA通过包围猎物、捕食猎物和搜索猎物的生物行为来求取平滑因子σ的值并赋予PNN。当故障诊断准确率最高或者达到最大迭代次数时迭代结束,此时的σ值为适合PNN分类判别的最优值。
(4)用测试集测试优化后的PNN,若PNN的故障判别正确,则测试下一个样本;若判别错误,则需要更新数字孪生通风机预测性故障诊断模型,使其对故障规律重新学习,提高通风机的预测性故障诊断精度。
4 实验与结果分析
矿用通风机在运行过程中主要会出现5种机械故障:转子不对中、转子不平衡、转子弯曲、轴承故障及联结松动。为了验证本文提出的诊断方法的有效性,使用100组通风机故障数据进行检测。其中60组数据作为训练样本集,40组数据作为测试样本集。此外,对训练样本数据进行编号,与通风机5种不同的故障相互对应:转子不对中编号为1,共5组数据;转子不平衡编号为2,共5组数据;转子弯曲编号为3,共8组数据;轴承故障编号为4,共10组数据;联结松动编号为5,共12组数据。采集到的通风机故障实际数据的特征值及其故障类别编号见表3。可看出不同参数的取值范围具有很大的差异性。为了不影响PNN训练速度和精度,需要对求得的特征参量进行归一化处理,归一化处理公式为

表3 通风机测试样本数据的特征值
(12)
式中:H*为归一化后的特征值;H为初始特征值;Hmin为最小的特征值;Hmax为最大的特征值。
在通风机故障诊断前,需要对WOA进行参数设定,本文设定鲸鱼的种群数量为30,最大迭代次数为30次,平滑因子σ是寻优的鲸鱼个体。经过算法的迭代优化,得到最优平滑因子σ的值为0.008 7,此时的PNN分析判别故障数据最准确。
将IWOA优化后的PNN与优化前的PNN进行对比。优化前PNN的σ值分别设置为0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0,优化后的σ值为0.008 7,测试结果见表4、表5。通过对比表4与表5后发现,在IWOA寻得最优σ值后,PNN的故障诊断精度有大幅度的上升,避免了人为给定σ值对诊断结果的影响。
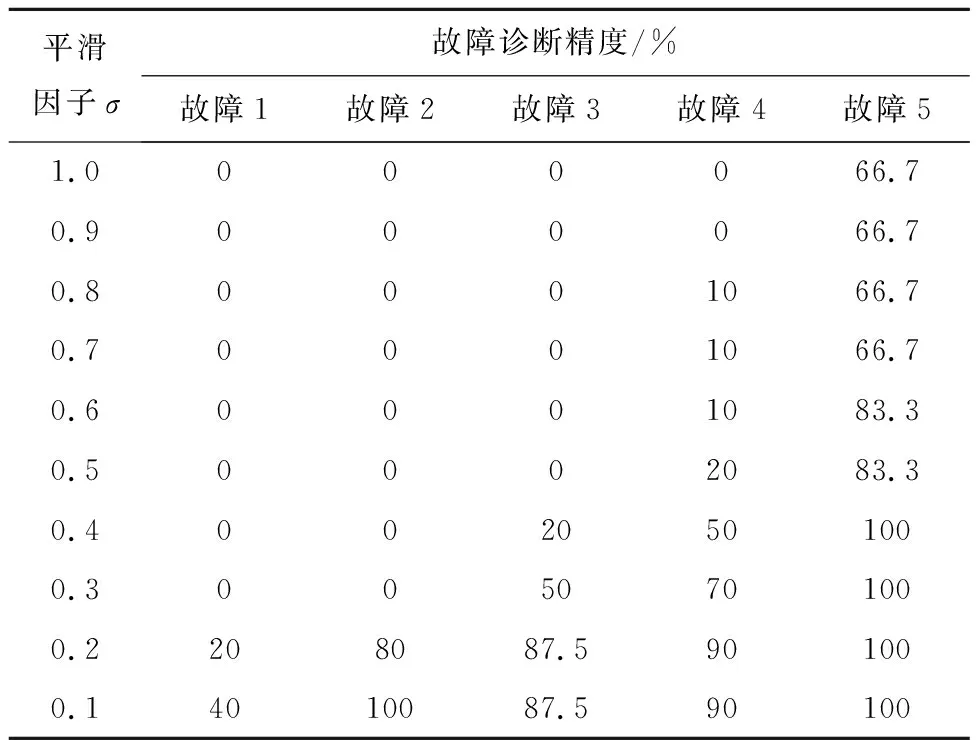
表4 优化前的PNN测试结果
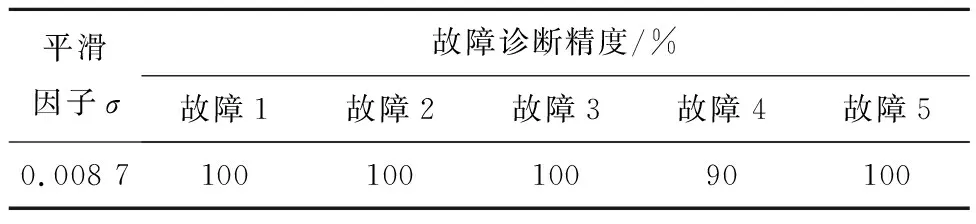
表5 优化后的PNN测试结果
优化后的PNN故障诊断结果与实际分类对比如图9所示。
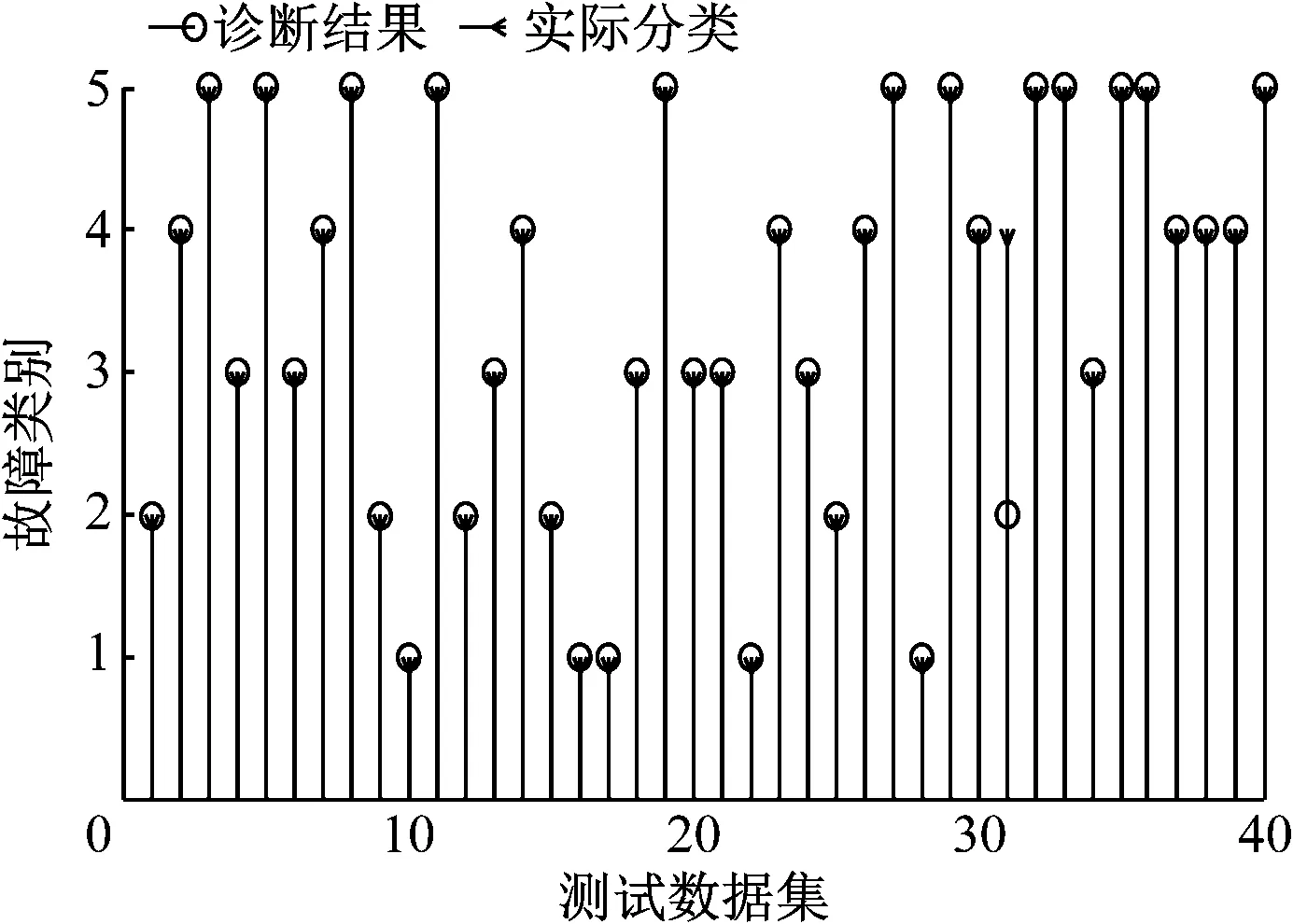
图9 优化后的PNN故障诊断结果与实际分类对比
从图9可看出,在进行测试的40组数据中,只有1组实际为故障4的数据被错分为故障2,其他的诊断结果都与故障的实际分类结果相符合,故障分类正确率达到了97.5%。
此外,将IWOA优化后的PNN故障诊断精度与WOA、GA、PSO优化后的PNN故障诊断精度进行比较,所得结果见表6。

表6 各种算法优化后的PNN故障诊断精度对比
(1)GA算法:最大迭代次数为30,种群规模为30,变异概率为0.2,交叉概率为0.8,GA优化后的PNN故障诊断精度为75.0%。
(2)PSO算法:种群规模为30,每个粒子个体学习因子c1为2,社会学习因子c2为2,惯性权重为0.9,最大迭代次数为30。PSO优化后的PNN故障诊断精度为85.0%。
(3)经过WOA优化后的PNN故障诊断精度为90%,而IWOA优化后的PNN故障诊断断精度达到了97.5%。
综上所述,IWOA优化后的PNN在故障诊断速度和故障诊断精度上都优于传统的故障诊断算法,并且可以满足通风机的故障诊断需求。
5 结论
(1)提出了一种基于数字孪生和PNN的矿用通风机预测性故障诊断方法。首先建立了通风机的数字孪生模型,并以数字孪生模型为基础,结合专家知识、机器学习、历史数据等建立了最初的通风机预测性故障诊断模型;然后采集通风机运行数据并实时映射至数字孪生模型中;最后利用IWOA优化后的PNN对通风机进行预测性故障诊断,若诊断错误,预测性故障诊断模型便会重新学习故障规律,并更新参数,进而提高预测性故障诊断的准确率。
(2)实验结果表明,与GA、PSO、WOA优化后的PNN故障诊断精度相比,IWOA优化后的PNN故障诊断效果更好,精度高达97.5%,说明基于数字孪生和PNN的矿用通风机预测性故障诊断方法的故障诊断准确率高,可以满足通风机故障诊断要求的实时性与准确性。
