基于生成对抗自关注的点云补全网络
2021-11-28叶荆荆叶海良曹飞龙
叶荆荆,叶海良,曹飞龙
(中国计量大学 理学院,浙江 杭州 310018)
3D数据在不同领域有很多应用,包括自动驾驶、机器人、遥感、医疗和设计等领域[1]。在各种类型的3D数据描述中,点云以其数据量小、表现能力强等优点得以在3D数据处理中广泛应用。现实世界中的点云数据通常是通过激光扫描仪、相机或RGB-D扫描仪捕获的。但是,由于遮挡、光反射、材料表面的透明度以及传感器分辨率和视角的限制,会造成几何和语义信息的丢失,导致点云数据不完整。因此,修复不完整的点云具有重要意义。3D点云形状补全目标大致可分为两个:一是基于原始输入点云恢复目标物体的几何形状,二是基于给定的点云生成缺失的点云[2-3]。为了实现这两个目标,现有研究从不完整的点云输入中学习点云的缺失部分信息和形状信息[4]。近年来,对点云的深度学习已经变得非常繁荣,并且已经提出了许多方法来解决该领域的不同问题[5],但是使用深度神经网络[6]处理点云还存在独特挑战。1)非结构化性。点云是一系列不均匀的采样点。一方面,它使得各个点之间的相关性难以用于特征提取;另一方面,在图像、视频处理中广泛使用的卷积神经网络不能直接用于点云处理。2)无序性。与图像和视频不同,点云是一组没有特定顺序的点。
由于PointNet[7]的出现,基于学习的架构能够直接操作点云数据。Panos Achlioptas[8]等引入了第一个利用编码器解码器框架的基于深度学习的点云补全网络L-GAN。虽然L-GAN能够在一定程度上完成形状补全任务,但它的架构主要不是用来进行形状补全任务的,因此性能并不理想。Yang等引入了一个名为Folding[9]的新解码操作,作为2D到3D的映射。之后,点云补全网络(PCN)[10]采用首个基于学习的框架专注于形状补全任务,其采用折叠操作Folding来近似一个较为光滑的表面,进行形状补全。而随后出现的3D点云胶囊网络[11-12],其性能超过了其他方法,成为处理点云最先进的自动编码器,特别是在点云补全领域。
然而,上述方法不能有效提取物体的几何形状和局部细节特征。基于几何的方法利用部分上表面的几何特征来生成原始三维形状的缺失数据[13-14],而基于对齐的方法保持形状数据并搜索相似的区域来填充三维形状的不完整区域[15-17]。但这些方法是对整体形状的补全,忽略了精细结构信息,在补全过程中可能会出现过拟合的情况。
因此,为了同时保持全局几何特征和局部细节特征,本文提出了一种基于生成对抗自关注的深度神经网络用于缺失点云的补全。网络使用多层感知机(Multilayer Perceptron,MLP)来有效提取点云全局特征,并添加一个自关注模块来捕捉局部细节特征。接着再利用特征金字塔模块,完成主中心点坐标、次中心点坐标和细节点坐标的提取。最后使用带自关注模块的判别器对生成的点云进行优化,以使结果更加准确[18]。所提网络的主要贡献在于:1) 引入自关注模块[19]加强各个点之间的联系,保留了点云全局结构特征的同时也清晰地还原了局部重要细节;2) 使用自关注判别器网络来优化已补全的点云数据,有效解决了同一类别中不同物体的特征会相互影响的问题。
基于生成对抗网络架构,本文提出了带有自关注模块和金字塔特征提取块的点云补全网络。该网络能够有效提取点云特征并对点云的缺失部分进行补全和修复,并以对抗的方式来优化生成的点云,最终获得形状特征几何特征更加完整的点云物体,从而使3D点云的补全效果更好。
1 基于生成对抗自关注的3D点云补全模型
三维点云补全的目的是根据给定的输入点云生成完整的点云,补全的形状应该和目标物体真实形状一样。而点云补全应满足以下两点:补全后的三维点云和真实点云描述相同的几何特征;同时两者的误差应该尽可能小。为此,提出一种带自关注模块的生成对抗点云补全网络(Point Cloud Completion Networks based on Generative Adversarial Model with Self-Attention,PS-Net)。
1.1 生成对抗自关注模型结构
基于生成对抗自关注的点云补全模型包括生成器和判别器。如图1所示,生成器用于从输入的不完整点云中补全出点云的缺失部分,它由MLP特征提取块、自关注模块和特征金字塔解码器模块三部分组成。MLP特征提取块对输入的原始点云进行编码。自关注模块则负责捕捉细节特征,使生成点云的细节更加完整。从真实点云中采样的N个点记为X={x1,x2,…,xN}∈R3×N,且在深度网络中前一层的输出被用作后一层的输入,则MLP特征提取块和自关注模块的输出可以表述为如下形式:
F=Ψ(W′X),V=SA(Ψ(W″F))。

图1 基于生成对抗自关注的3D点云形状补全模型结构(输入是不完整的点云,模型预测了点云的缺失部分)Figure 1 Architecture of 3D point cloud shape completion model based on generative adversarial self-attention PS-Net (The input is incomplete point cloud and the model predicts the missing point cloud)
其中,Ψ表示非线性激活函数,W′,W″表示特征融合阶段MLP的权重,SA表示自关注操作,F∈RC×N为MLP操作学习到的特征。
特征金字塔解码器以特征向量V为输入,输出补全的点云,从而补全缺失区域的形状。F1,F2,F3为特征向量V经过线性操作得到的特征信息,维度分别为1 024,512,256。该模块的描述如下:
其中,⊕代表拼接操作,Wi表示特征融合阶段MLP的权重,reshape是对特征维度进行变形操作。
特征金字塔解码器的基准是全连接的解码器,其对点云的整体几何形状有较好的预测能力。然而,因为只使用最后一层预测的形状,全连接解码器会造成局部几何信息的损失。现有研究结合全连接解码器与基于折叠的解码器,以加强局部几何形状的预测。但以FoldingNet为例,如果原始曲面是相对的,则基于折叠的解码器不能很好地处理类的不平衡和保留原始的复杂几何细节。针对该问题,受特征金字塔网络(Feature Pyramid Networks,FPN)的启发,本文设计了一个基于特征点的层次结构,该结构可以分层提取点云特征:先提取主要特征,然后提取中间特征,最后提取细节特征。经过这三部分特征的拼接融合,补全后的点云形状与现有方法的补全结果相比,局部细节信息更完整,CD损失(Chamfer Distance)更小。
为了更好地捕捉细节特征,提高特征提取的效率,所提模型在生成器的MLP特征提取块和判别器的特征融合后都增加了一个自关注模块。该模块结构如图2,输入特征分别通过MLP进入Q(Query)和K(Key),然后由Q和K生成注意力权重,经过计算得到最终的权重,而最终的输出就是注意力权重和输入特征的相乘。

图2 自关注机制模型Figure 2 Self-Attention mechanism model
判别器的作用是判断点云数据是真实的数据还是生成器生成的数据。为达成这一目的,本文首先使用MLP网络架构来提取全局特征,MLP是一种能有效整合局部和全局特征信息的轻量级网络。然后在特征拼接后加入自关注模块来更好地提取局部特征。与基本的MLP网络相比,自关注模块可以加强特征的聚合和后续特征提取能力。最后使用一组MLP和最大池化来产生全局信息,并通过全连接层进一步回归得到最终置信度y。如果置信度y接近1,说明判别器预测这个输入来自真实点云,否则来自生成器。判别器的输出可以被表示为:
X1=Ψ(WP),X2=X1⊕Maxpool(X1),y=Ψ(W(SA(X2)))。
其中W为MLP的权重,P可以是真实点云也可以是补全的点云。Maxpool是最大池化函数,该函数保证了对任意顺序的输入点集,其输出都保持不变,从而确保在点云特征提取过程中的位置不变性。
1.2 自关注模块
自关注机制广泛应用于点云数据处理,它使用一个可学习的网络来衡量每个通道的重要性,并产生更多的信息输出。
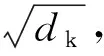
1.3 优化目标与网络训练
损失函数是输出点云和真实点云之间差距的度量。由于点云是不规则的,损失函数需要满足置换不变性。网络损失函数由两部分组成:多阶段补全损失(CD损失)和对抗损失。CD损失衡量的是点云缺失部分的真实值与预测值之间的差异。对抗性损失试图通过优化最大似然估计来使预测看起来更真实。在本模型中,选择CD损失作为衡量指标。
CD损失计算预测点云S1和真实点云S2之间的平均最近点距离:
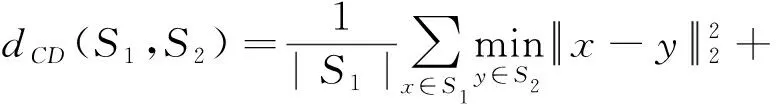
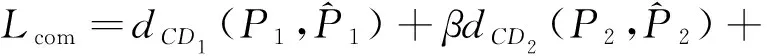
对抗损失可用最小平方损失表示:
则PS-Net的整体网络损失可以定义为
L=θcomLcom+θadvLadv。
其中θcom和θadv分别为满足下列条件的补全损失和对抗损失的权重:θcom+θadv=1。
2 实 验
本节首先阐述实验的具体细节。其次,展示了PS-Net的点云补全结果和消融实验。然后,研究了本方法在3D点云补全任务中的有效性。最后,对其有效性和复杂性进行了讨论。
2.1 数据生成和实验细节
Shape-Net[20]是一个由物体的三维CAD模型表示的大规模形状库。Shape-Net已经索引了超过300万个模型,包含来自多个语义类别的3D模型,其中22万个模型被分为3 135个类别。实验使用Shape-Net中的13个类别来训练模型。图像总数为14 473,其中11 705张图像用于训练,2 768张用于测试。实验采用稠密的原始点云数据,为使训练能够快速收敛并提高训练的稳定性,将采样点坐标值归一化到[0,1]区间内。对每个图像采样2 048个点作为真实的点云,再对图像随机采样得到不完整的点云。实验将缺失率为原始数据25%的缺损点云用于训练和测试,并将本文方法所得结果与其他方法进行对比。
实验在Pytorch上进行,优化器为Adam[21],学习率设置为0.000 1,批量为24。在判别器上应用批处理规范化(Batch Normalize,BN)[22]和ReLU激活函数,然后只在生成器上使用ReLU函数。
2.2 点云补全结果
为了定量评估所提PS-Net对三维点云的形状补全能力,将PS-Net与现有的几种3D点云补全方法进行了对比分析,包括LGAN-AE网络、PCN网络、3D点云胶囊网络(3D-Capsule)和PF-Net网络。其中,LGAN-AE网络以自动编码器和生成对抗网络为基本模块,编码器将数据点编码为潜在特征向量作为生成对抗网络的输入。PCN网络采用编码解码结构,其编码器通过权值共享的多层感知机、跳跃连接和最大池化层来提取点云全局特征,解码器分两步生成完整点云。3D点云胶囊网络同样采用编码解码结构,但其编码器通过多个具有不同权值的独立卷积,形成点胶囊。而解码器赋予这些胶囊随机2D网格并通过多层感知机生成多个点补丁。最后,将所有的补丁收集到一个点云中,实现对缺失点云形状的补全。PF-Net网络采用生成器-判别器模型,其生成器通过迭代最远点采样和多层感知机对采样点进行特征提取并生成点云的缺失部分。判别器对补全出的完整点云和真实点云进行判别,实现对生成器的改进。
由于现有的几种方法都是在不同的数据集上进行训练,不便于比较每种方法的性能,所以上述方法在训练和测试时都使用相同的数据集。需要强调的是,本方法都在未标记的数据集上进行训练。为了定量评价所提方法的性能,使用了两个评价指标[23-24]:P→GT(预测点到真实点)误差和GT→P(真实点到预测点)误差。P→GT误差计算从预测点云中的每个点到其最接近的真实值的平均最近点距离,指出了每个预测点和真实点之间的差异。GT→P误差计算真实点云中的每个点到预测点云中最接近点的平均最近点距离,显示了真实点云的形状被预测点覆盖的程度。
实验首先对13个类别物体(如飞机、帽子、汽车等)进行完整点云补全的测试,测试结果的P→GT误差和GT→P误差如表1所示。表1将所有误差值都扩大了1 000倍,并在表格最后一行中比较了所有类别的平均误差。在采样的2 048个点上,利用本文所提PS-Net网络进行点云补全,平均P→G误差/GT→P误差为0.554/0.418。相比编码解码结构的LGAN-AE网络和PCN网络,平均误差分别降低了1.315/1.197和1.248/1.244,补全精度具有明显的提高。对比3D胶囊网络和PF-Net网络,平均误差同样有所降低。而在表1的所有13个物体类别上,PS-Net补全结果的误差均小于LGAN-AE、PCN和3D胶囊网络;且在超过一半的物体类别上,其性能也优于PF-Net网络,说明本文方法补全的完整点云形状与真实点云形状更加接近。
由于本方法将不完整点云作为输入,只输出缺失部分的预测点云,因此不会改变原始点云的形状。考虑到完整点云的补全误差主要来自点云缺失部分中预测点云与原始点云的差异,所以为了保证模型的有效性,实验还计算了由512个点构成的缺失点云上的P→GT和GT→P误差,实验结果列于表2。表2中的误差值也都扩大了1 000倍,由表2可知,本文方法在两个误差指标上都表现良好。表1和表2中的结果表明,无论是在整体点云上还是在点云的缺失部分上,本方法都能以高精度和低缺失率生成点云。在图3中,可视化了8类目标物体(包括飞机、帽子、汽车、椅子、手枪等)的输出点云,输入点云全部来自测试集。由图3可知,PF-Net在对帽子这一物体的补全中出现了稀疏点云块,对杯子的补全结果也存在边缘点云的冗余,而本文方法生成的点云物体则比较均匀。并且对于所有目标物体,本方法补全结果在细节处的修复效果更好,有效保持了物体的精细结构。

表1 13类物体完整点云补全结果的P→GT误差/GT→P误差

表2 13类物体缺失点云补全结果的P→GT误差/GT→P误差
2.3 消融实验
对判别器的分析。本节对有无判别器的PS-Net模型进行对比实验,分析判别器的重要性,实验结果列于表3。结果表明,带判别器的模型优于不带判别器的模型,P→GT和GT→P误差更小,对点云补全的精度和完整度更高。
对自关注机制的分析。为了证明自关注机制的作用,在Shape-Net上分别训练了没有自关注的模型和带有自关注的模型。并在测试集上实验验证其点云补全的准确性,结果如表3所示。结果表明,在PS-Net模型中加入自关注机制更有利于特征获取,显著减小了点云补全的误差,提高了补全精度。有无判别器与有无自关注机制的对比消融实验都选择飞机这一类别,并且都以一个不完整点云作为输入,以对缺失部分补全后的完整点云作为输出,输出点云形状如图4所示。从图4的对比可知,带判别器和自关注机制的PS-Net不仅能准确地恢复出全局形状特征,而且对局部细节的补全效果也更好。
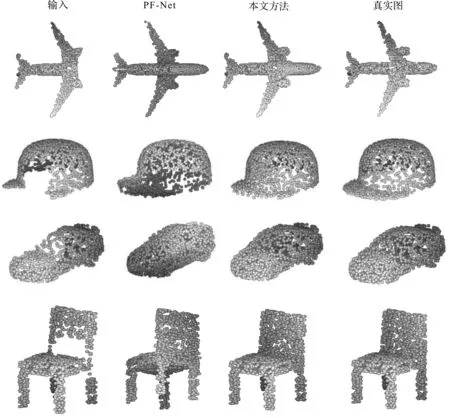

图3 其他方法与本方法补全结果的对比Figure 3 Comparison of completion results between other methods and our method

图4 消融实验的对比Figure 4 Comparison of ablation experiments

表3 无判别器的PS-Net和无自关注机制的PS-Net在Shape-Net上的消融实验结果
迭代次数的分析。本节讨论了迭代次数对点云补全结果的影响。训练了0次迭代、40次迭代、80次迭代、120次迭代、160次迭代和200次迭代的结果可视化在图5中。如图5所示,3D点云数据集上的训练次数越多,补全修复后的点和形状就越接近真实值和真实形状。

图5 迭代次数对汽车点云补全的影响Figure 5 Influence of iteration numbers on car point cloud completion
2.4 讨 论
PS-Net如何提取更多的细节信息。自关注本质上是捕获数据或特征内部相关性[25],从而可以学习任意两个点云之间的依赖关系进而获得详细的信息[26]。基于此,在生成器框架中加入自关注,并使用特征金字塔网络来分层提取点云特征,从而能在PS-Net框架中嵌入更多细节信息。
此外,本文做了消融实验来说明PS-Net可以提取更多的形状信息。深度学习网络是复杂多通道的,如果有些通道对其他通道来说是多余的,那么可以使用自关注机制来加权包含重要信息的通道。通过这种方式,所提出的PS-Net也可以通过自关注机制提取更多的信息[27-28]。
复杂性分析。本文从参数个数和计算成本两个方面分析了该方法的复杂性。由于简化了特征提取方法,因此在参数数量上,本方法与基准方法PF-Net[29]相比没有额外的参数。而对于计算成本,本方法具有与PF-Net相同的计算成本。
3 结 语
针对三维点云形状补全难以恢复局部细节的问题,本文提出了一种基于自关注的点云补全模型PS-Net。该模型可以有效利用输入不完整点云中的局部区域特征来对整体形状进行补全。并且模型使用自关注机制来提取输入点云的局部重要细节信息和几何形状信息。此外,模型使用特征金字塔网络的三个分支来提取点云的全局和精细结构信息。最后,利用CD损失使模型具有更好的生成能力。在Shape-Net上的点云补全实验结果证明了PS-Net的优越性,该方法优于现有的一些点云形状补全方法。另一方面,从可视化角度本文也更好地实现了对点云缺失形状的补全。
